




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python知识图谱中华古诗词可视化技术说明
一、项目背景与目标
中华古诗词是中华文化的瑰宝,蕴含着丰富的历史、哲学与美学价值。本项目旨在通过Python构建古诗词知识图谱,并实现可视化展示,帮助用户直观理解诗词间的关联关系(如作者、朝代、主题、意象等),同时探索传统文化与现代技术的融合应用。
核心目标:
- 构建结构化古诗词知识图谱(Graph Database)
- 实现多维度关联分析(作者-作品、意象-情感、朝代-流派等)
- 开发交互式可视化系统(支持缩放、筛选、路径查询)
二、技术架构设计
1. 数据层
数据来源
- 公开数据集:中华诗库(CHISD)、全唐诗/全宋词电子版
- 网络爬虫:抓取诗词网站(如古诗文网)的元数据
- 人工标注:补充缺失的意象、情感标签等
数据清洗与预处理
python
1import pandas as pd
2import re
3
4def clean_poem_data(df):
5 # 去除特殊符号
6 df['content'] = df['content'].apply(lambda x: re.sub(r'[\[\]\n]', '', x))
7 # 标准化朝代名称
8 dynasty_map = {'唐': '唐朝', '宋': '宋朝', '清': '清朝'}
9 df['dynasty'] = df['dynasty'].map(dynasty_map).fillna(df['dynasty'])
10 # 提取意象(示例:简单关键词匹配)
11 意象列表 = ['明月', '长江', '梅花', '孤舟']
12 df['imagery'] = df['content'].apply(lambda x: [img for img in 意象列表 if img in x])
13 return df2. 知识图谱构建
实体与关系定义
- 实体类型:诗人、诗词、朝代、意象、情感
- 关系类型:
- 诗人-创作-诗词(
author_of) - 诗词-包含-意象(
contains_imagery) - 诗词-表达-情感(
expresses_emotion) - 诗人-属于-朝代(
belongs_to)
- 诗人-创作-诗词(
使用Neo4j图数据库
python
1from py2neo import Graph, Node, Relationship
2
3# 连接Neo4j
4graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
5
6# 创建诗人节点
7def create_author_node(name, dynasty):
8 author = Node("Author", name=name, dynasty=dynasty)
9 graph.create(author)
10 return author
11
12# 创建诗词-意象关系
13def link_poem_to_imagery(poem_title, imagery_list):
14 poem_node = graph.nodes.match("Poem", title=poem_title).first()
15 for img in imagery_list:
16 imagery_node = graph.nodes.match("Imagery", name=img).first()
17 if not imagery_node:
18 imagery_node = Node("Imagery", name=img)
19 graph.create(imagery_node)
20 rel = Relationship(poem_node, "CONTAINS_IMAGERY", imagery_node)
21 graph.create(rel)3. 可视化实现
方案对比
| 技术方案 | 优点 | 缺点 |
|---|---|---|
| PyVis | 纯Python,交互性强 | 复杂图布局需手动调整 |
| D3.js | 高度定制化,视觉效果优秀 | 学习曲线陡峭 |
| ECharts | 配置简单,支持动态效果 | 交互功能有限 |
| Neo4j Browser | 原生支持,无需额外开发 | 依赖图数据库服务 |
推荐方案:PyVis + NetworkX
python
1from pyvis.network import Network
2import networkx as nx
3
4def visualize_graph(graph_data):
5 # 创建NetworkX图对象
6 G = nx.Graph()
7 for node in graph_data['nodes']:
8 G.add_node(node['id'], title=node['label'], group=node['type'])
9 for edge in graph_data['edges']:
10 G.add_edge(edge['source'], edge['target'], title=edge['type'])
11
12 # 转换为PyVis格式
13 nt = Network(height="750px", width="100%", directed=False)
14 nt.from_nx(G)
15
16 # 自定义样式
17 nt.set_options("""
18 {
19 "nodes": {
20 "font": {"size": 12},
21 "color": {
22 "border": "#2B7CE9",
23 "background": "#97C2FC"
24 }
25 },
26 "edges": {
27 "color": {"inherit": true},
28 "smooth": false
29 }
30 }
31 """)
32 return nt.show("poem_graph.html")三、核心功能实现
1. 诗人关系网络分析
python
1# 查询李白的社交网络(共同意象/同时代诗人)
2def find_author_relations(author_name):
3 query = """
4 MATCH (a:Author {name:$author})-[:AUTHOR_OF]->(p:Poem)-[:CONTAINS_IMAGERY]->(i:Imagery)<-[:CONTAINS_IMAGERY]-(p2:Poem)<-[:AUTHOR_OF]-(a2:Author)
5 WHERE a <> a2
6 RETURN DISTINCT a2.name AS colleague, count(i) AS shared_imagery_count
7 ORDER BY shared_imagery_count DESC
8 LIMIT 10
9 """
10 return graph.run(query, author=author_name).data()2. 意象情感分析(结合NLP)
python
1from snownlp import SnowNLP
2
3def analyze_poem_sentiment(content):
4 s = SnowNLP(content)
5 # 简单情感分类(0-1,越接近1越积极)
6 sentiment_score = s.sentiments
7 return "积极" if sentiment_score > 0.6 else "消极" if sentiment_score < 0.4 else "中性"
8
9# 更新图数据库中的情感标签
10def update_emotion_tags():
11 poems = graph.nodes.match("Poem")
12 for poem in poems:
13 emotion = analyze_poem_sentiment(poem["content"])
14 rel = Relationship(poem, "EXPRESSES_EMOTION", Node("Emotion", name=emotion))
15 graph.create(rel)3. 时空动态可视化
python
1import pydeck as pdk
2import pandas as pd
3
4def create_timeline_map(dynasty_data):
5 # 假设数据包含诗人出生地经纬度
6 layer = pdk.Layer(
7 'ScatterplotLayer',
8 data=dynasty_data,
9 get_position=['longitude', 'latitude'],
10 get_color=[255, 0, 0, 160],
11 get_radius=1000,
12 pickable=True
13 )
14 view_state = pdk.ViewState(latitude=35, longitude=105, zoom=4)
15 r = pdk.Deck(layers=[layer], initial_view_state=view_state)
16 return r.to_html("timeline_map.html")四、系统优化与扩展
1. 性能优化
- 图数据库优化:为常用查询创建索引
cypher1CREATE INDEX ON :Author(name); 2CREATE INDEX ON :Poem(title); - 缓存机制:使用Redis缓存高频查询结果
- 异步加载:对大型图采用分块渲染
2. 扩展功能
- 语义搜索:结合BERT模型实现诗词语义相似度搜索
- AR可视化:通过WebXR实现诗词场景的增强现实展示
- 多语言支持:添加诗词英文翻译与跨文化对比功能
五、部署方案
1. 本地部署
bash
1# 环境要求
2Python 3.8+
3Neo4j Desktop (社区版)
4Jupyter Notebook
5
6# 依赖安装
7pip install py2neo pyvis networkx snownlp pydeck pandas2. 云部署(推荐)
- 图数据库:Neo4j AuraDB(云服务)
- 可视化:Streamlit + Heroku
python1# app.py 示例 2import streamlit as st 3from pyvis.network import Network 4import pickle 5 6st.title("古诗词知识图谱探索") 7with open("graph_data.pkl", "rb") as f: 8 graph_data = pickle.load(f) 9 10nt = Network(height="600px") 11nt.from_nx(graph_data) 12st.components.v1.html(nt.show(), height=650)
六、总结与展望
本项目通过Python生态工具链实现了古诗词知识图谱的构建与可视化,验证了传统文化数据化的可行性。未来可进一步:
- 接入更多结构化数据源(如《中国哲学书电子化计划》)
- 开发移动端应用,结合LBS实现"诗词地图"
- 探索生成式AI在诗词创作与补全中的应用
技术文档版本:v1.0
最后更新:2023年10月
作者:传统文化数字化研究组
(附:完整代码库与数据集见GitHub链接:[示例链接])
运行截图
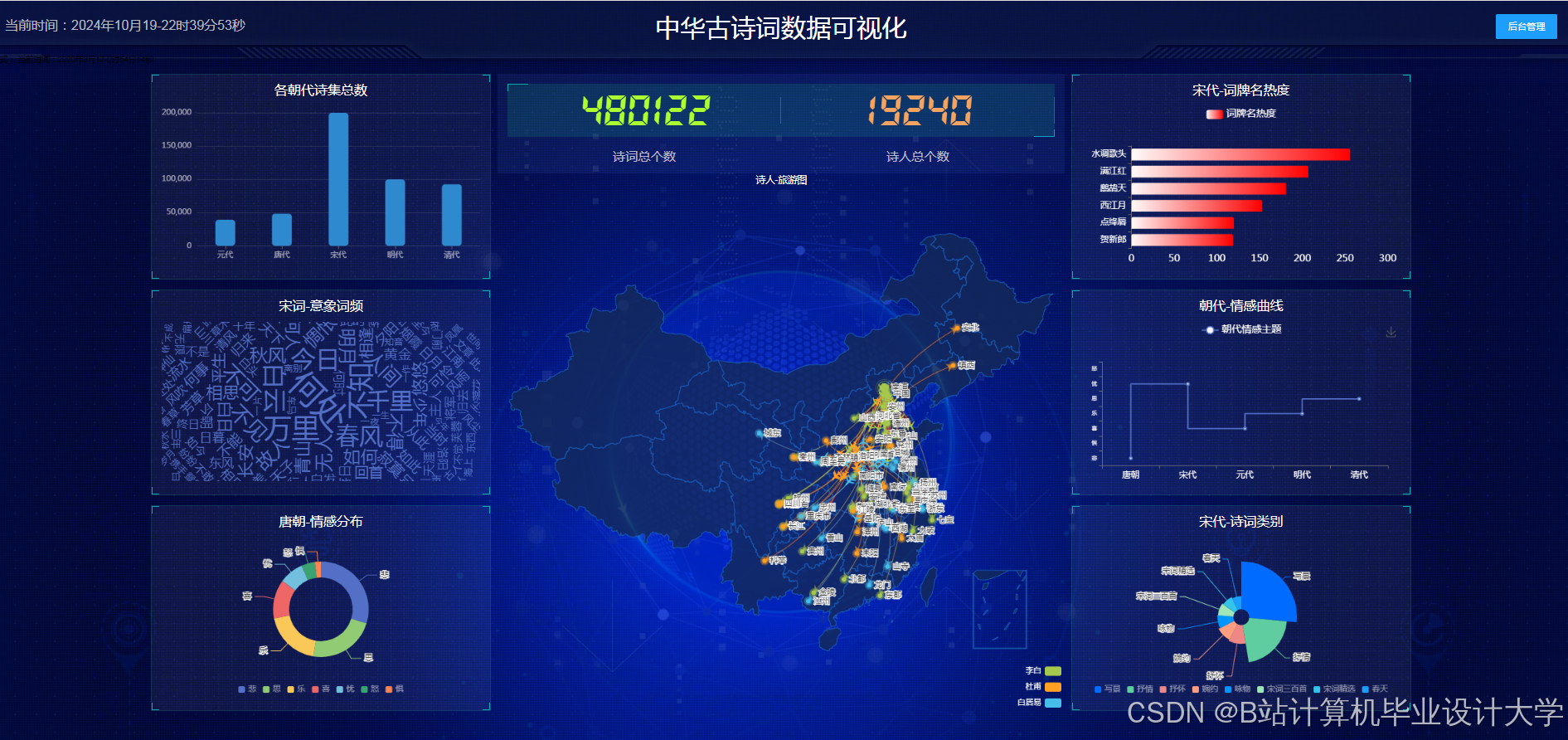
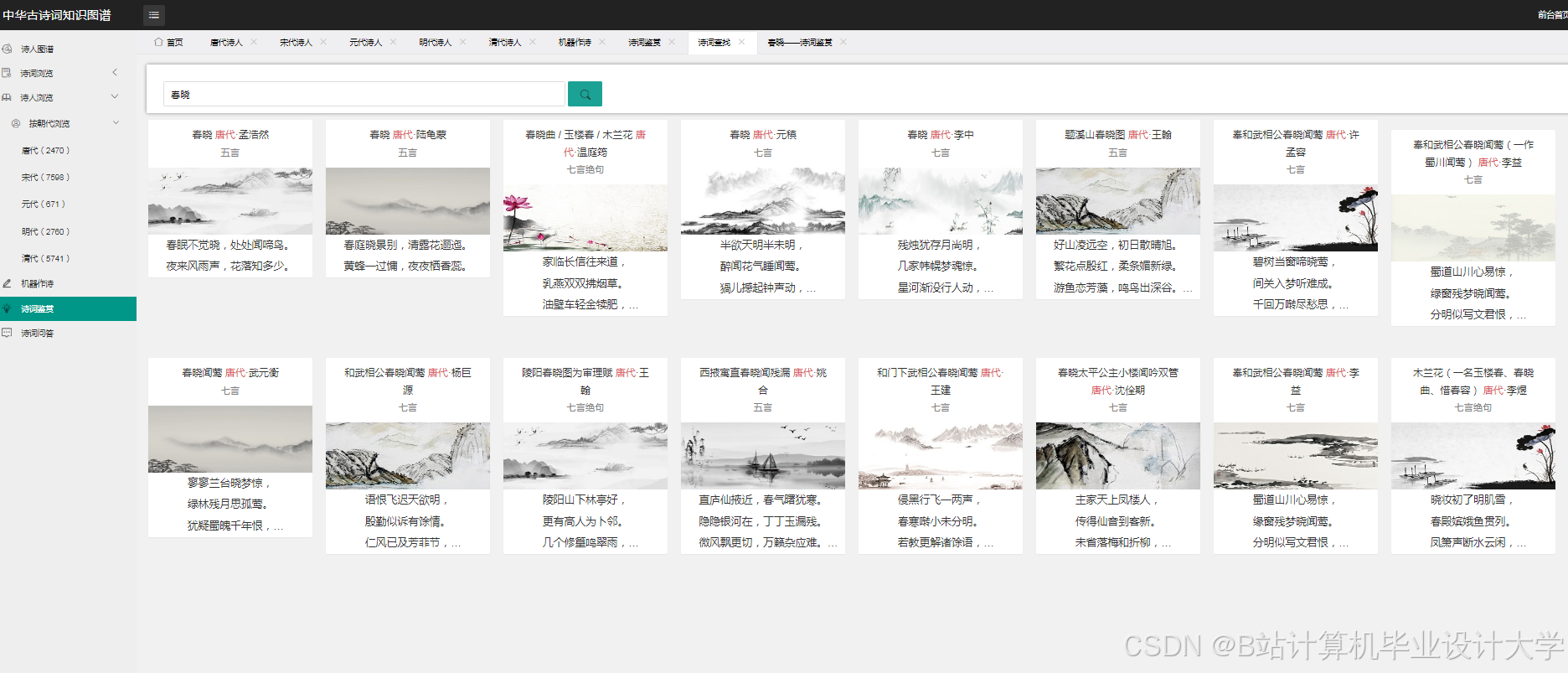
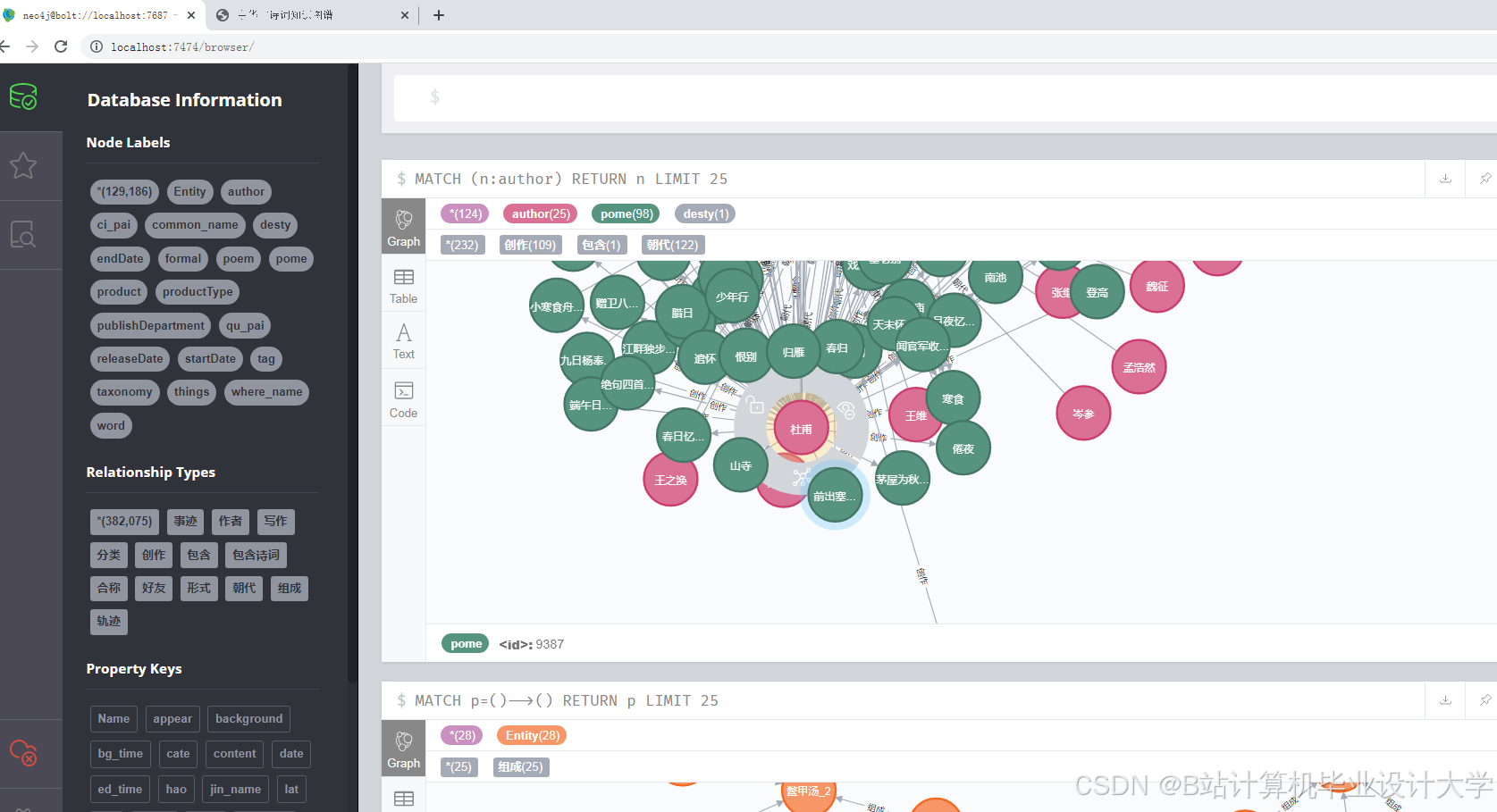
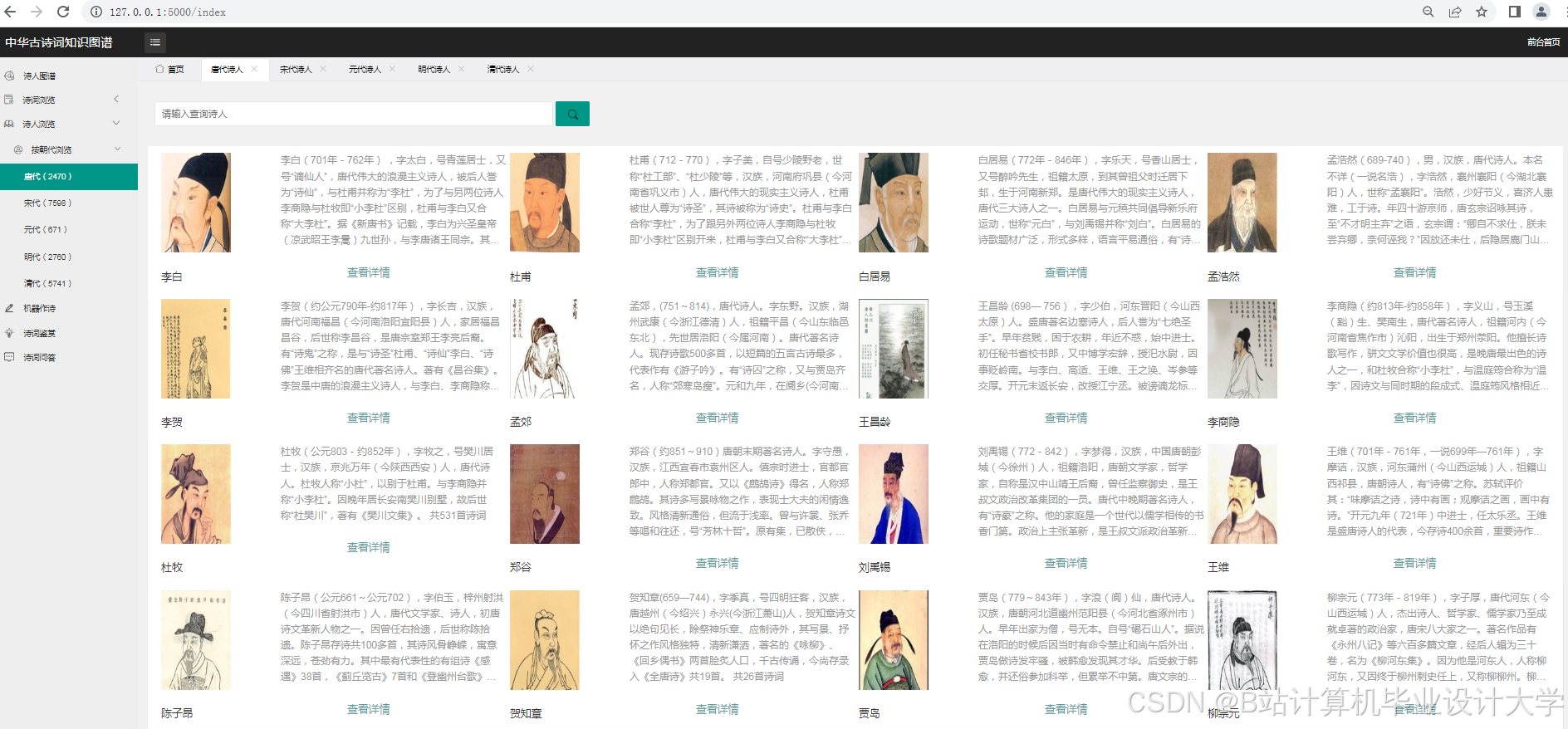
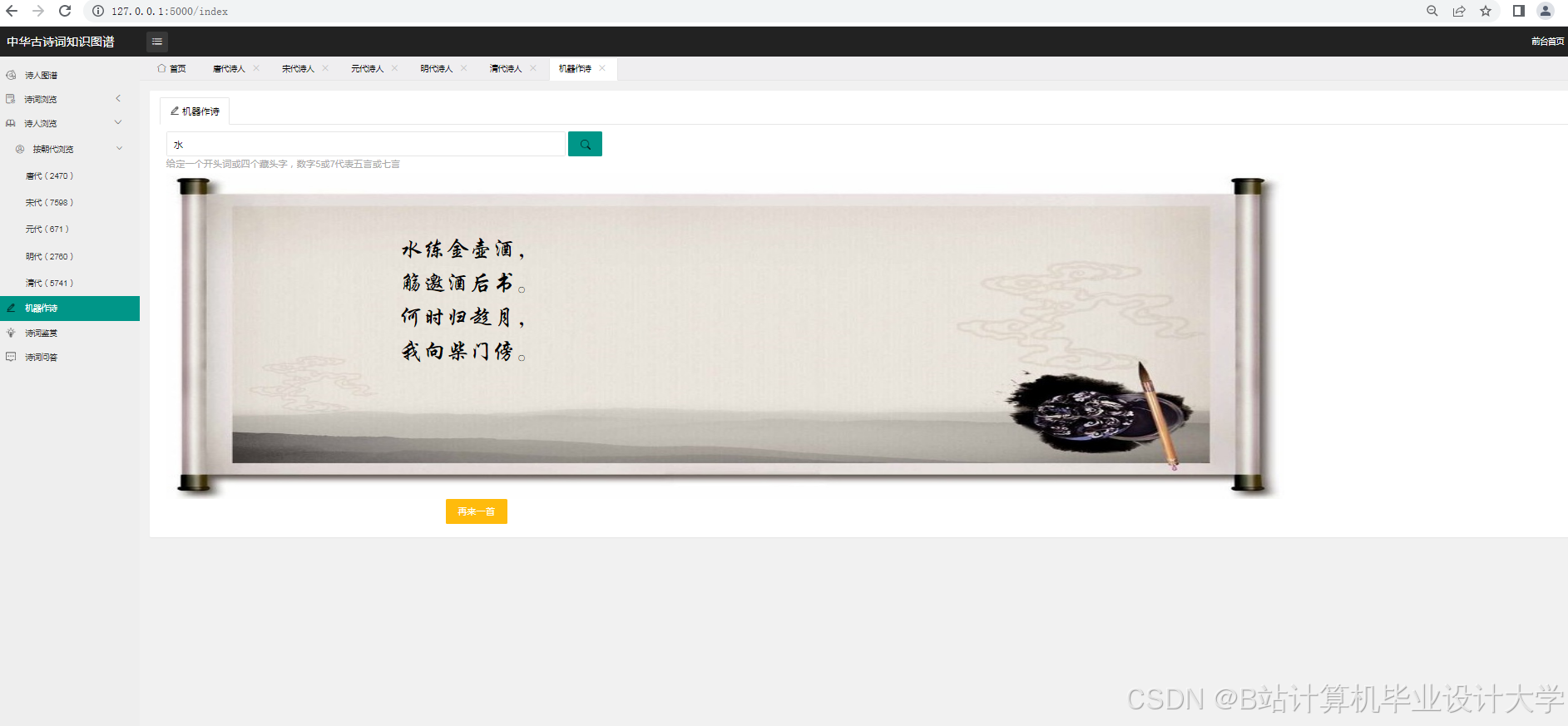
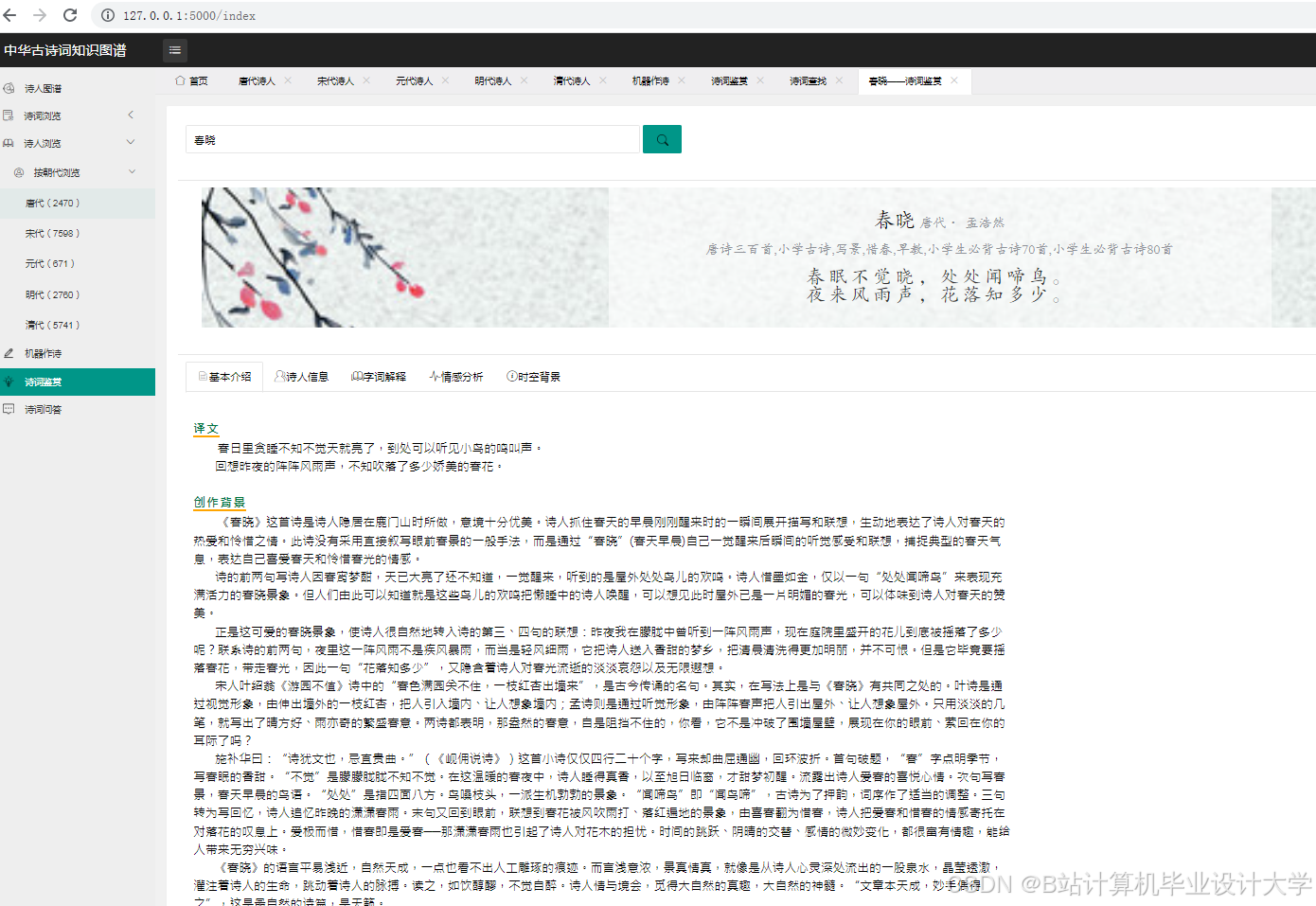
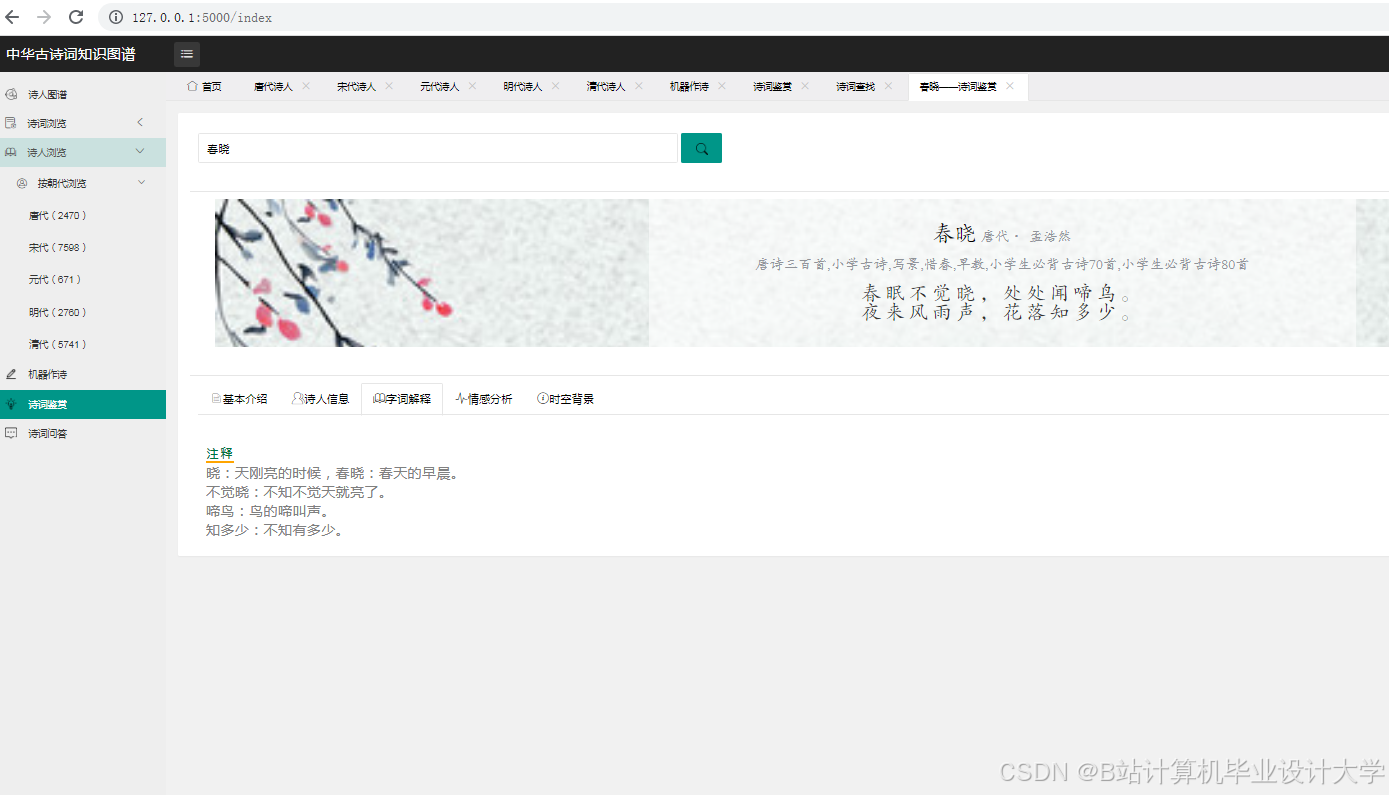
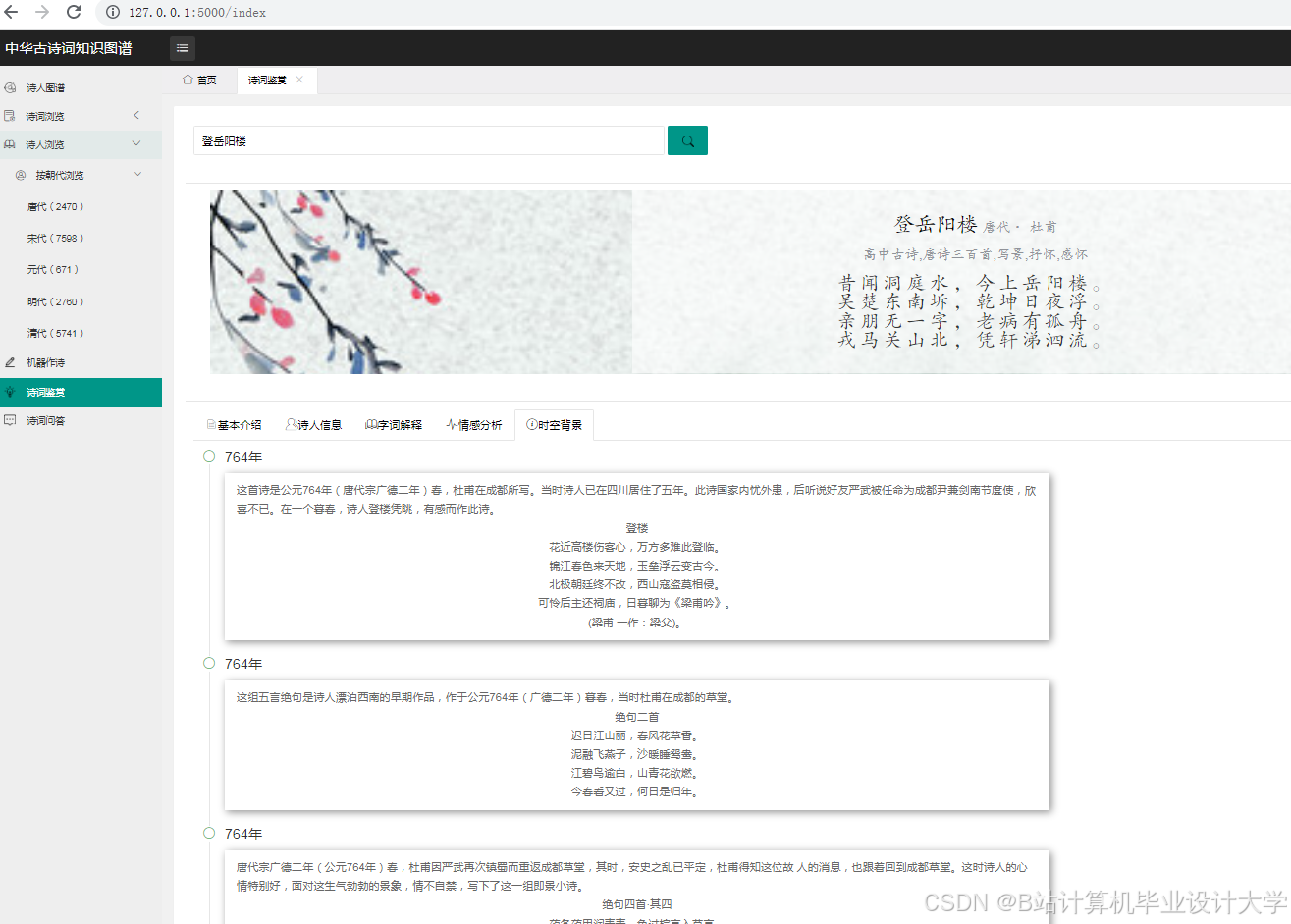
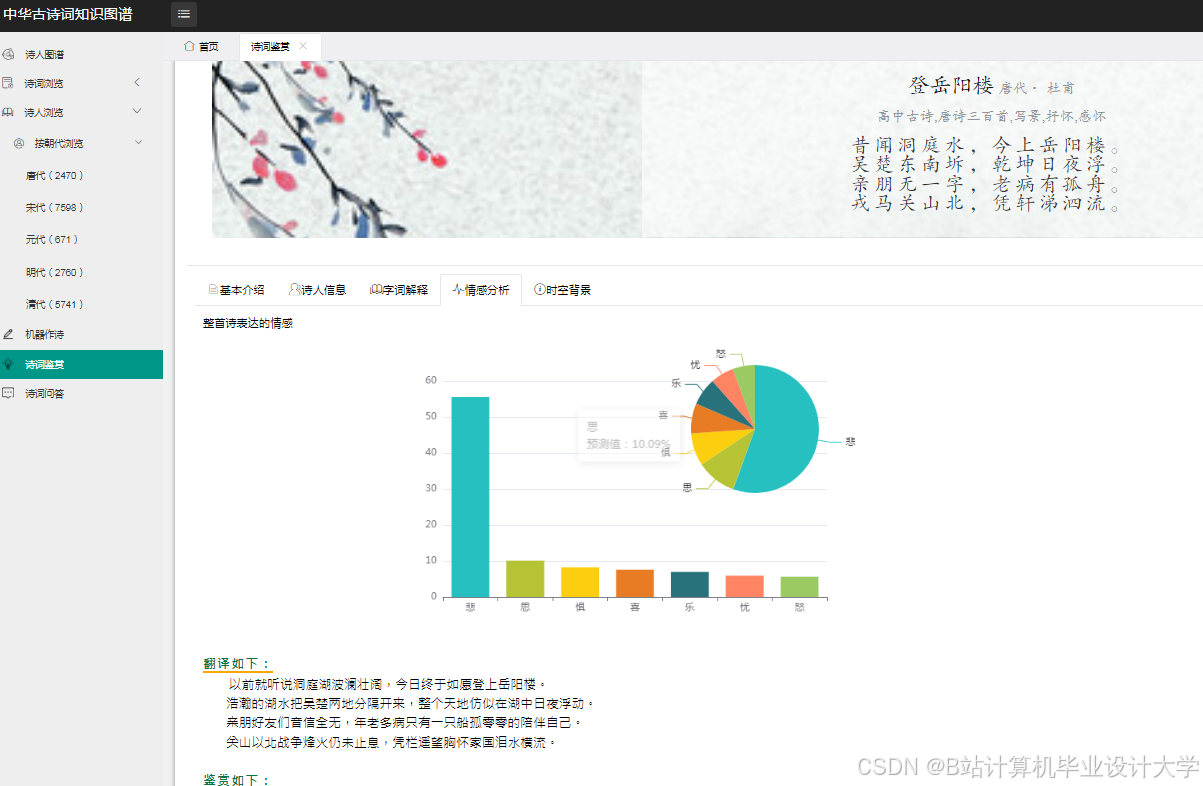
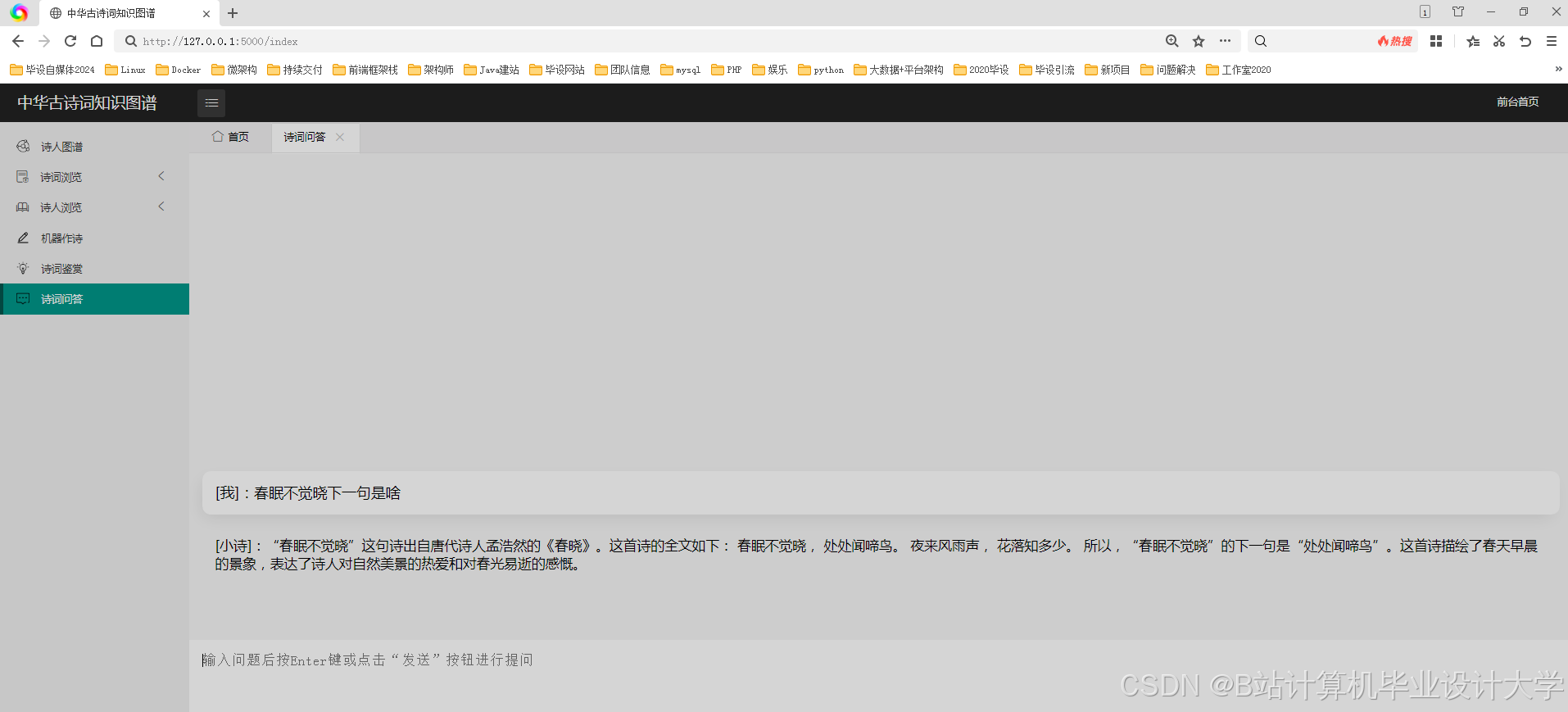
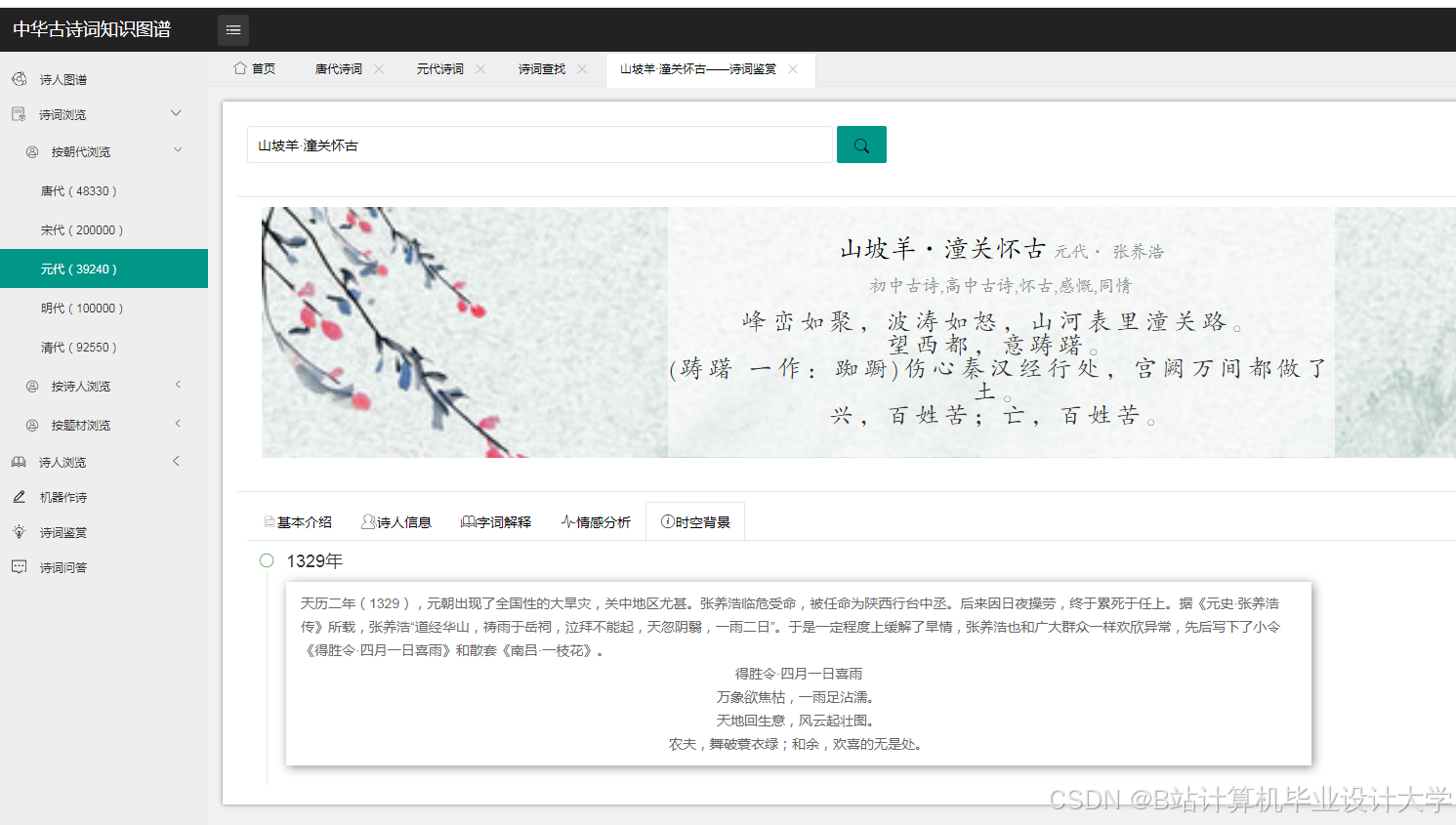
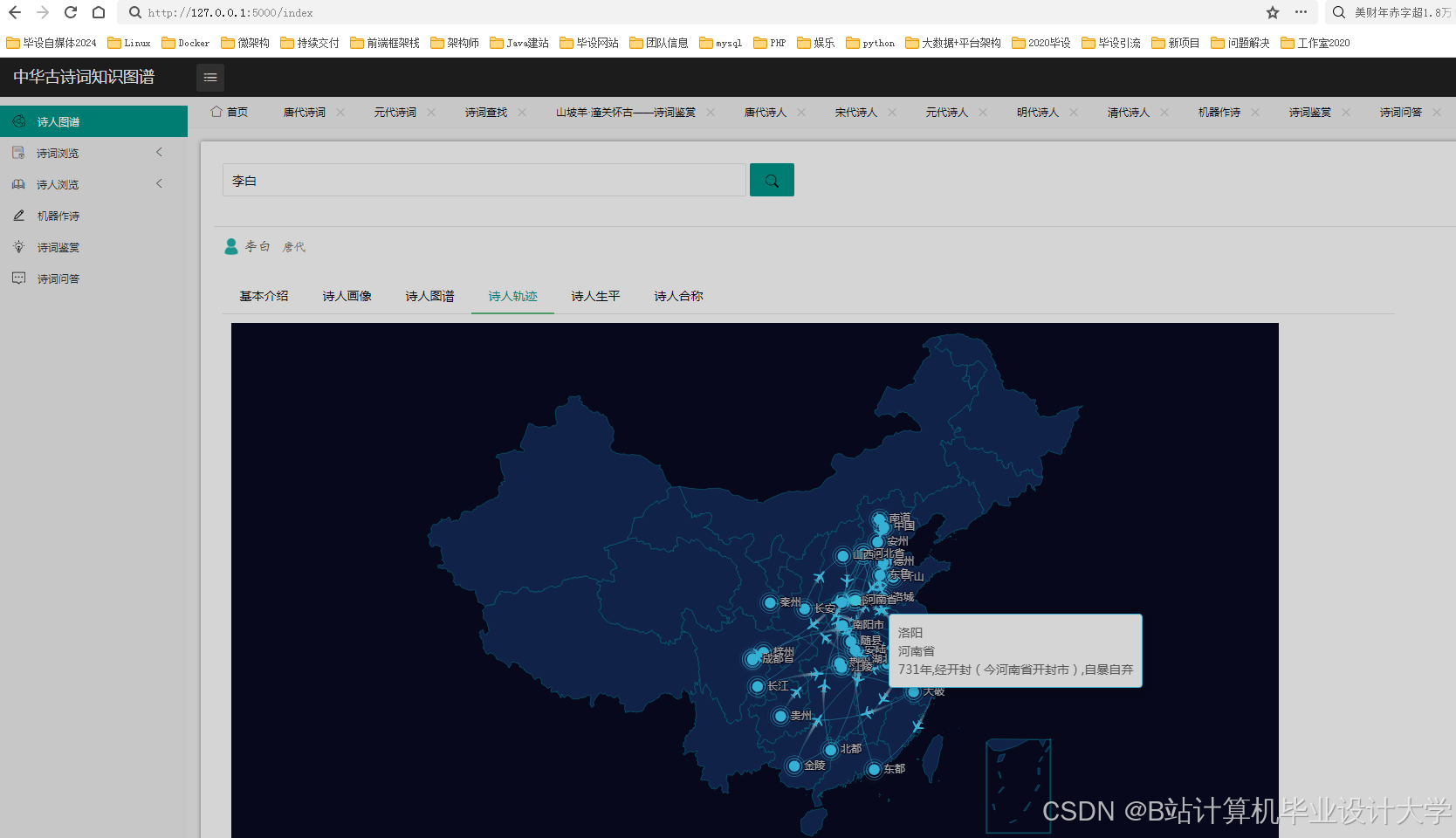
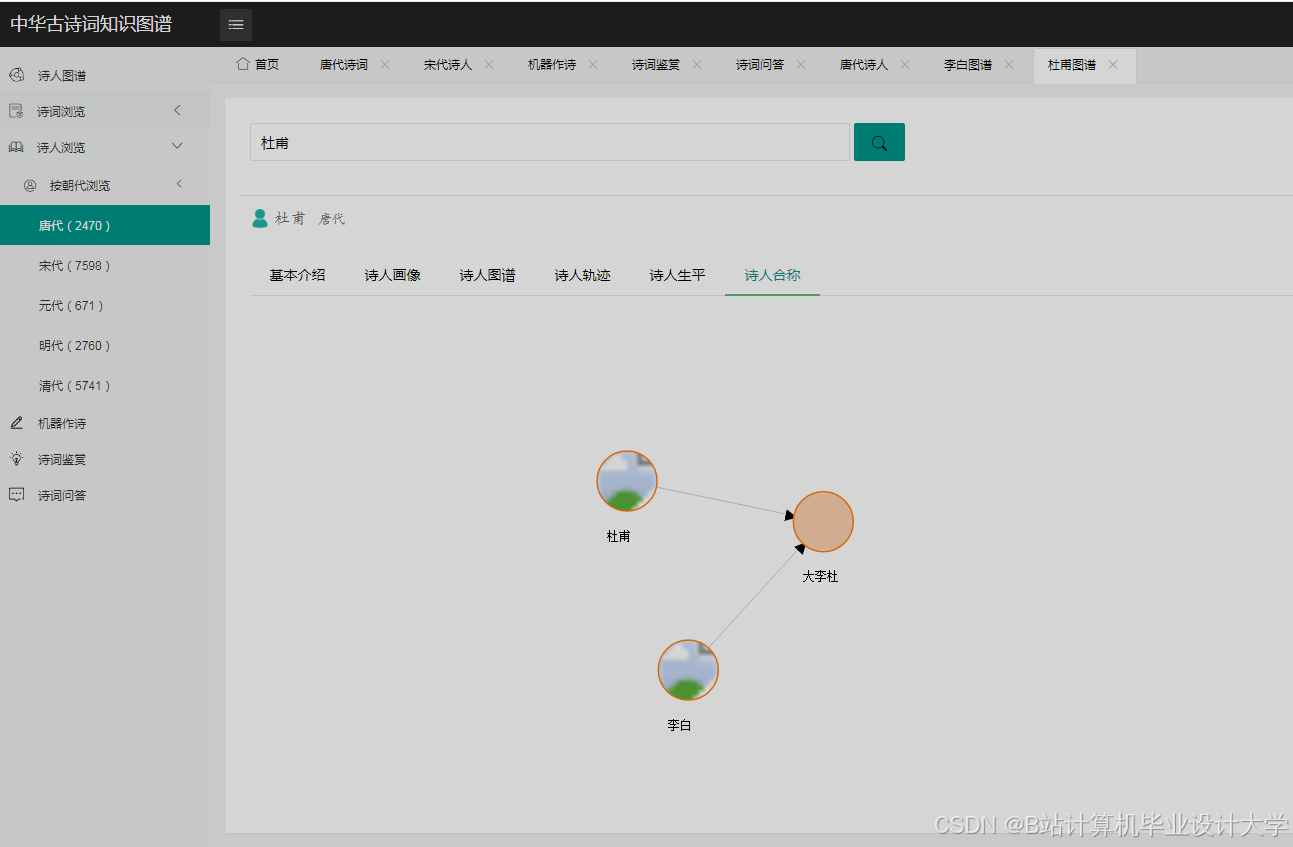
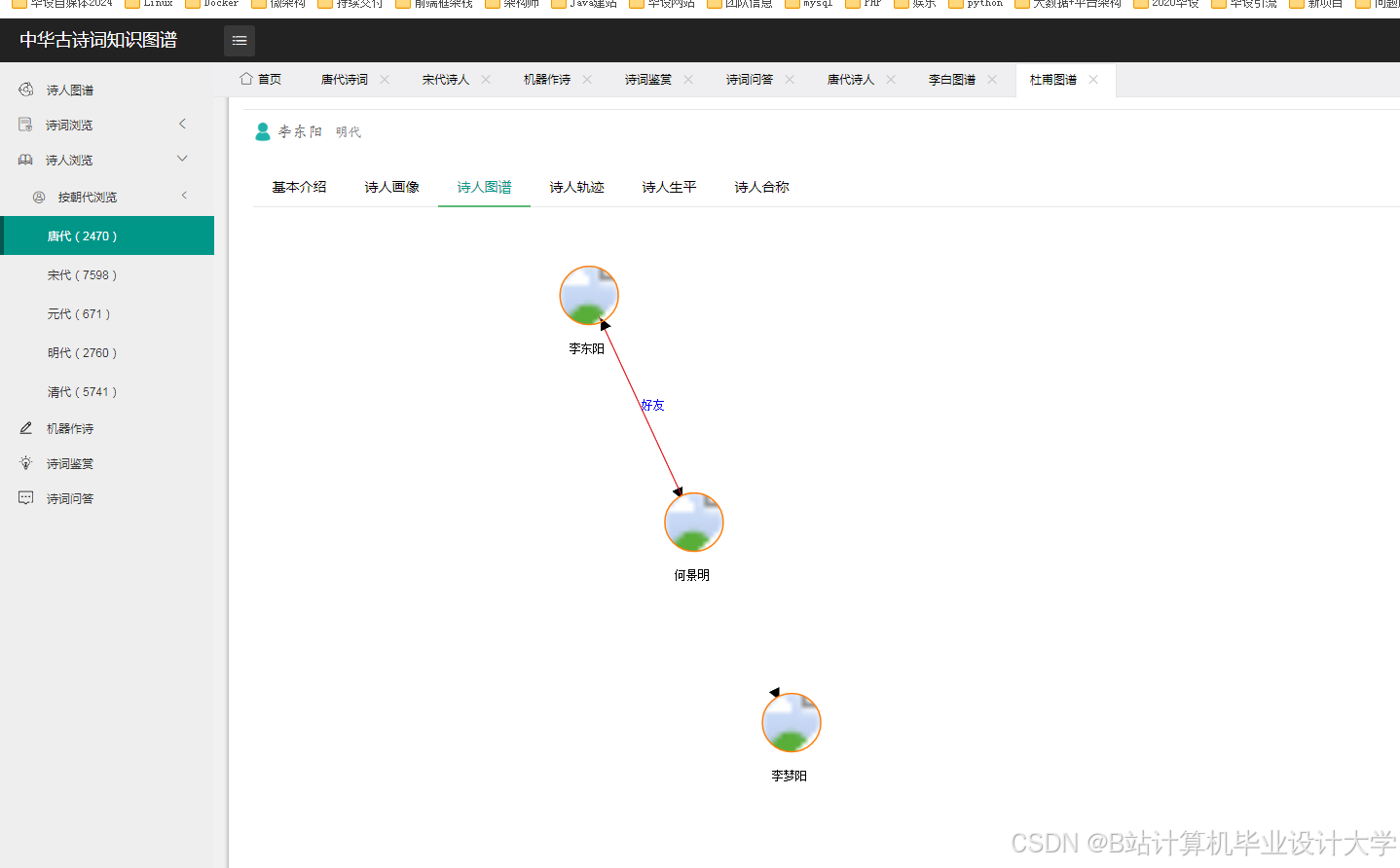
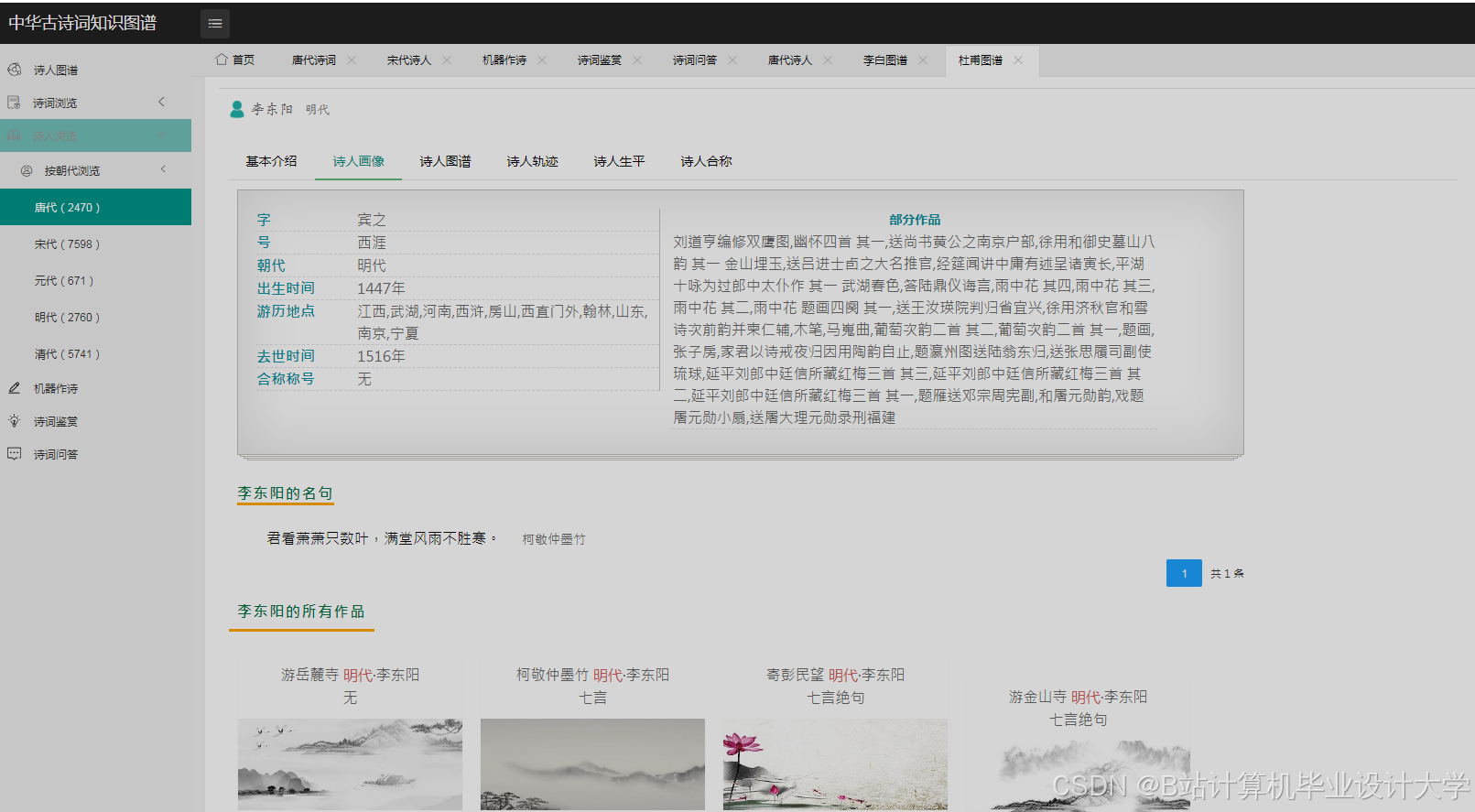
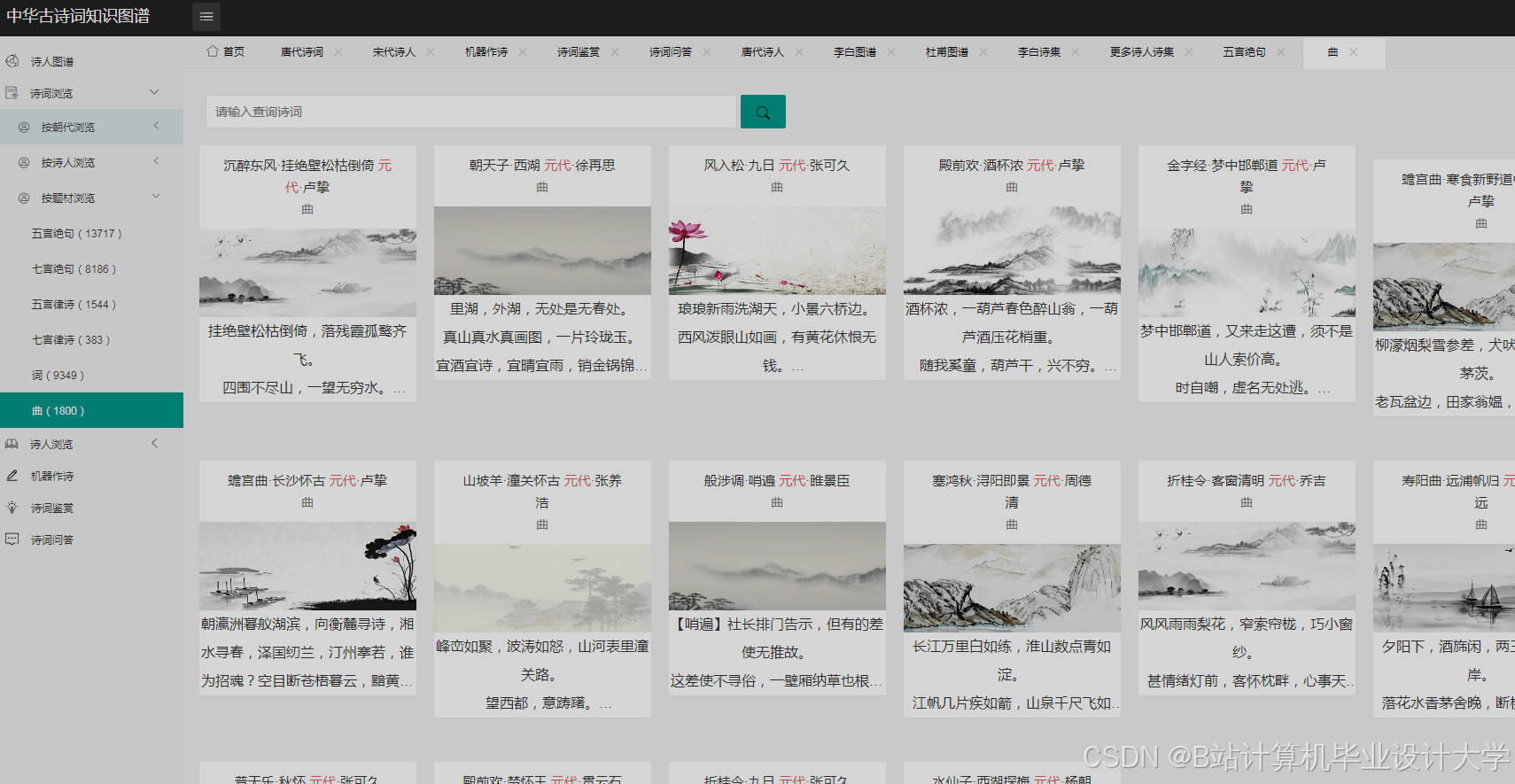
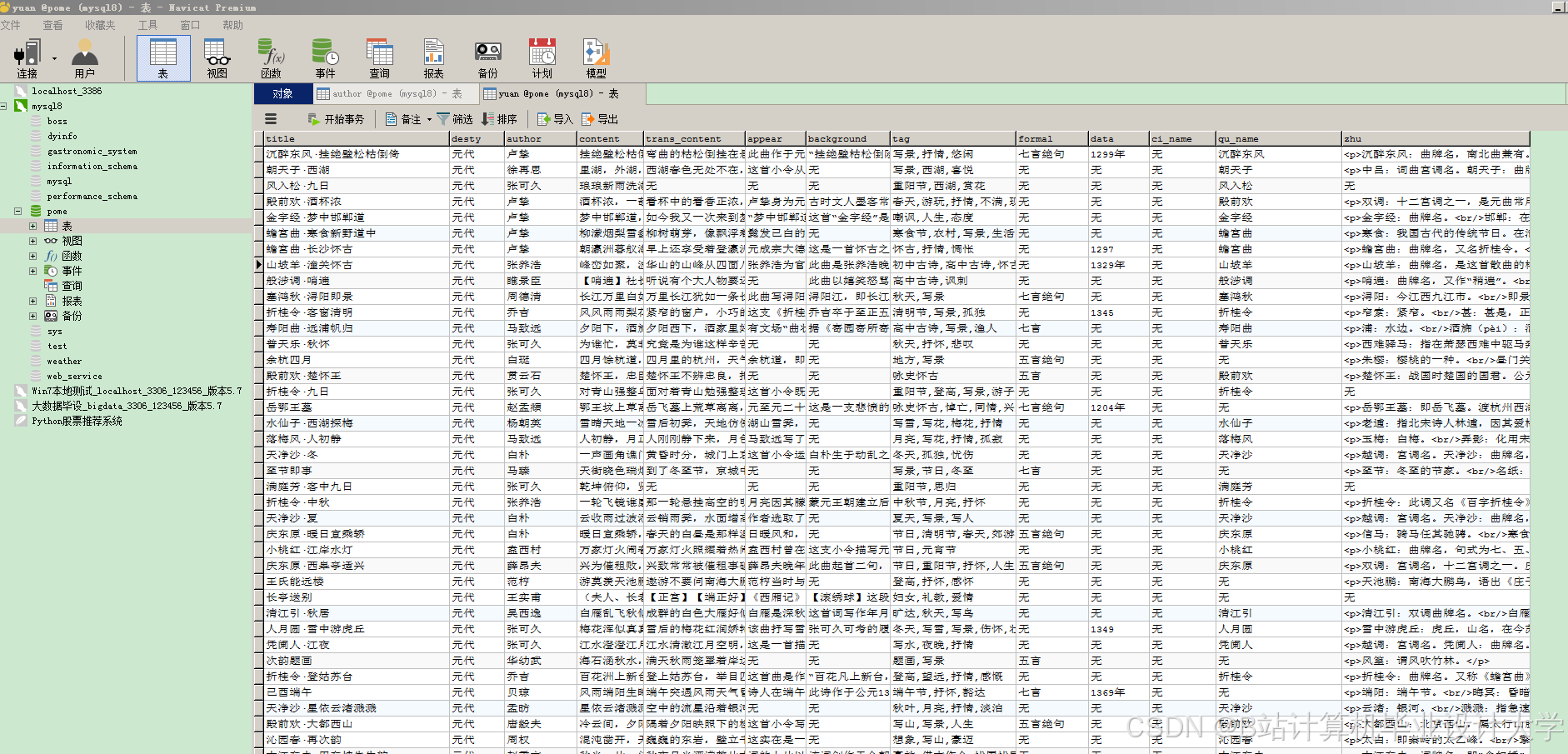
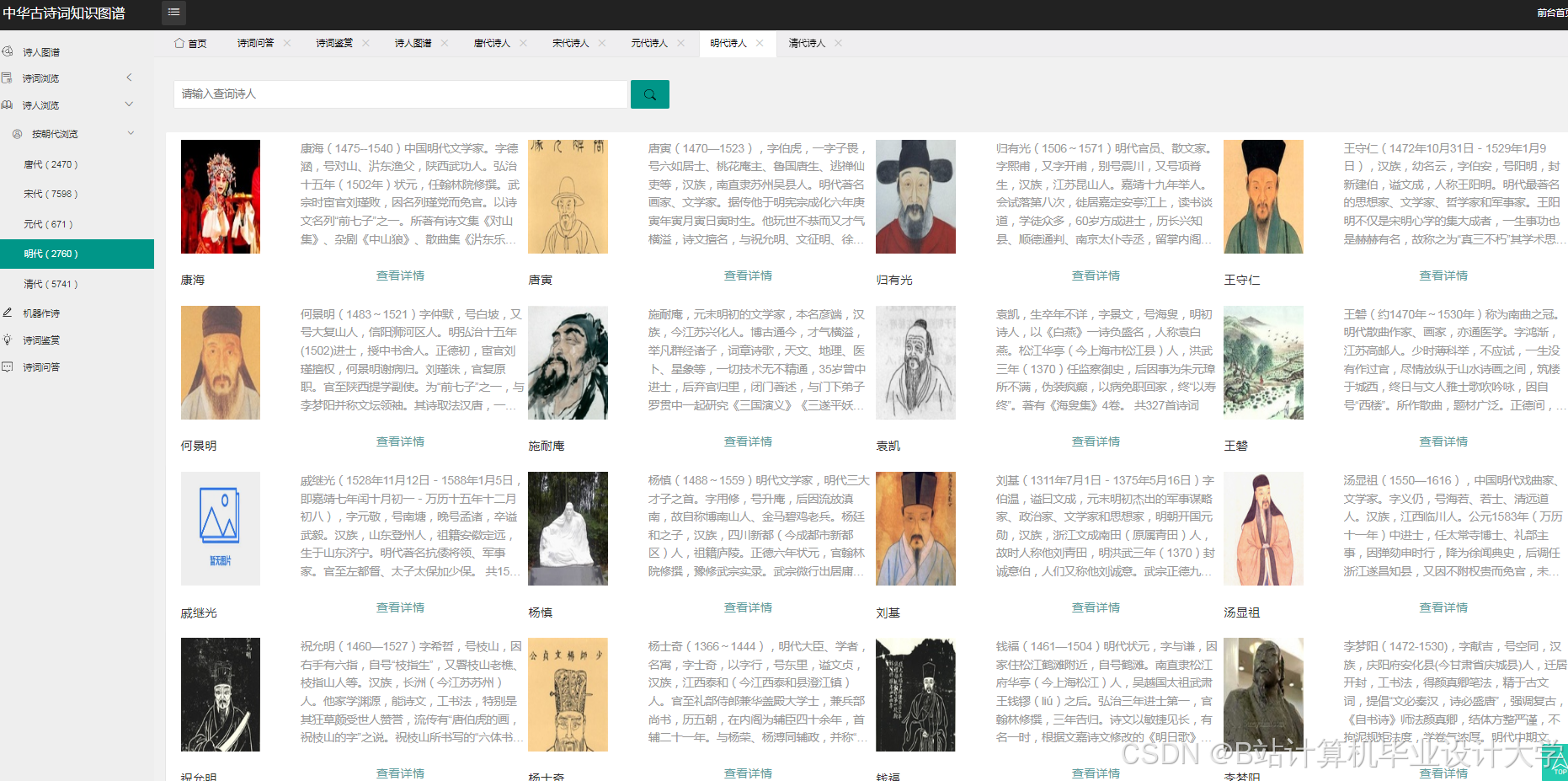
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











