




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python+大模型音乐推荐系统:音乐数据分析》的技术说明文档,涵盖系统架构、核心算法、数据处理流程及代码示例:
Python+大模型音乐推荐系统:音乐数据分析技术说明
一、系统概述
本系统结合Python生态工具链与大语言模型(LLM)能力,构建一个基于多模态音乐数据分析的智能推荐系统。系统通过分析音频特征、歌词文本、用户行为等数据,利用深度学习与大模型生成个性化推荐,适用于流媒体平台、音乐社交等场景。
二、核心技术栈
| 类别 | 技术选型 |
|---|---|
| 数据处理 | Python (Pandas/NumPy/Dask)、PySpark(大规模数据) |
| 音频分析 | LibROSA(音频特征提取)、Essentia、OpenSMILE |
| 文本分析 | Hugging Face Transformers(BERT/GPT)、spaCy、Gensim(主题建模) |
| 推荐算法 | 协同过滤、深度学习模型(Neural Collaborative Filtering)、LLM增强推荐 |
| 大模型 | LLaMA/GPT-3.5(微调)、MusicBERT(音乐领域专用模型) |
| 可视化 | Matplotlib/Seaborn、Plotly、Streamlit(交互式界面) |
| 部署 | FastAPI(API服务)、Docker/Kubernetes(容器化)、AWS SageMaker(云部署) |
三、系统架构设计
1┌───────────────────────────────────────────────────────────────────────────────┐
2│ 音乐推荐系统核心流程 │
3├───────────────┬───────────────┬─────────────────┬───────────────────────────┤
4│ 数据采集层 │ 特征工程层 │ 模型推理层 │ 推荐服务层 │
5├───────────────┼───────────────┼─────────────────┼───────────────────────────┤
6│ 用户行为日志 │ 音频特征提取 │ 深度学习模型 │ 实时推荐API │
7│ 音乐元数据 │ 歌词文本分析 │ 大模型微调 │ 离线批量推荐任务 │
8│ 社交互动数据 │ 用户画像构建 │ 混合推荐引擎 │ A/B测试框架 │
9└───────────────┴───────────────┴─────────────────┴───────────────────────────┘四、关键技术实现
1. 多模态音乐特征提取
音频特征提取(LibROSA示例)
python
1import librosa
2
3def extract_audio_features(file_path):
4 # 加载音频文件
5 y, sr = librosa.load(file_path, sr=22050)
6
7 # 提取时域特征
8 features = {
9 'duration': librosa.get_duration(y=y, sr=sr),
10 'zero_crossing_rate': np.mean(librosa.feature.zero_crossing_rate(y=y)),
11 'energy': np.sum(y**2) / len(y)
12 }
13
14 # 提取频域特征(MFCC)
15 mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
16 features['mfcc_mean'] = np.mean(mfcc, axis=1).tolist()
17
18 return features
19
20# 示例
21audio_features = extract_audio_features("song.mp3")歌词文本分析(BERT嵌入)
python
1from transformers import BertTokenizer, BertModel
2import torch
3
4def get_lyric_embeddings(lyric_text):
5 tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
6 model = BertModel.from_pretrained('bert-base-multilingual-cased')
7
8 inputs = tokenizer(lyric_text, return_tensors="pt", padding=True, truncation=True)
9 with torch.no_grad():
10 outputs = model(**inputs)
11
12 # 使用[CLS]标记的隐藏状态作为句子嵌入
13 return outputs.last_hidden_state[:, 0, :].numpy().tolist()
14
15# 示例
16lyric_embedding = get_lyric_embeddings("I will always love you...")2. 用户画像构建
python
1import pandas as pd
2from sklearn.cluster import KMeans
3
4def build_user_profiles(play_history):
5 # 假设play_history包含用户ID、歌曲ID、播放次数、播放时长等
6 df = pd.DataFrame(play_history)
7
8 # 计算用户偏好特征(示例:基于音频特征均值)
9 user_features = df.groupby('user_id').agg({
10 'duration': 'mean',
11 'energy': 'mean',
12 'mfcc_mean': lambda x: np.mean(np.vstack(x), axis=0).tolist()
13 })
14
15 # 用户聚类(可选)
16 kmeans = KMeans(n_clusters=5)
17 user_features['cluster'] = kmeans.fit_predict(user_features[['duration', 'energy']])
18
19 return user_features3. 大模型增强推荐
方案A:LLM生成推荐理由
python
1from langchain import PromptTemplate, LLMChain
2from langchain.llms import OpenAI
3
4def generate_recommendation_reason(user_history, candidate_song):
5 llm = OpenAI(temperature=0.7)
6
7 prompt = PromptTemplate(
8 input_variables=["user_history", "song_info"],
9 template="""
10 用户历史偏好:{user_history}
11 候选歌曲信息:{song_info}
12 请用1-2句话解释为什么推荐这首歌给用户,突出歌曲特点与用户偏好的匹配点。
13 """
14 )
15
16 chain = LLMChain(llm=llm, prompt=prompt)
17 reason = chain.run(
18 user_history="喜欢轻快的流行乐,常听Taylor Swift和Ed Sheeran",
19 song_info="歌曲:Shake It Off,风格:流行,节奏:120BPM,主题:积极向上"
20 )
21
22 return reason方案B:MusicBERT微调(PyTorch示例)
python
1from transformers import BertForSequenceClassification, Trainer, TrainingArguments
2
3def fine_tune_musicbert(train_dataset, eval_dataset):
4 model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2) # 二分类示例
5
6 training_args = TrainingArguments(
7 output_dir="./results",
8 num_train_epochs=3,
9 per_device_train_batch_size=16,
10 evaluation_strategy="epoch"
11 )
12
13 trainer = Trainer(
14 model=model,
15 args=training_args,
16 train_dataset=train_dataset,
17 eval_dataset=eval_dataset
18 )
19
20 trainer.train()
21 return model4. 混合推荐引擎
python
1import numpy as np
2from sklearn.metrics.pairwise import cosine_similarity
3
4def hybrid_recommend(user_embedding, song_embeddings, top_k=10):
5 # 计算用户与歌曲的余弦相似度
6 similarities = cosine_similarity([user_embedding], song_embeddings)
7
8 # 获取Top-K相似歌曲
9 top_indices = np.argsort(similarities[0])[::-1][:top_k]
10 return top_indices
11
12# 示例(需预先计算所有歌曲的嵌入向量)
13all_song_embeddings = np.random.rand(1000, 128) # 模拟1000首歌曲的嵌入
14user_embedding = np.random.rand(1, 128) # 模拟用户嵌入
15recommended_songs = hybrid_recommend(user_embedding, all_song_embeddings)五、数据分析流程
1. 数据采集与清洗
python
1import pandas as pd
2
3def load_and_clean_data(raw_paths):
4 dfs = []
5 for path in raw_paths:
6 df = pd.read_csv(path)
7 # 数据清洗示例
8 df = df.dropna(subset=['song_id', 'user_id'])
9 df['play_duration'] = pd.to_numeric(df['play_duration'], errors='coerce')
10 dfs.append(df)
11
12 return pd.concat(dfs, ignore_index=True)
13
14# 示例
15raw_data = load_and_clean_data(["plays_2023.csv", "plays_2024.csv"])2. 探索性分析(EDA)
python
1import matplotlib.pyplot as plt
2
3def analyze_user_behavior(df):
4 # 用户播放次数分布
5 plt.figure(figsize=(10, 6))
6 df['user_id'].value_counts().head(20).plot(kind='bar')
7 plt.title("Top 20 Active Users")
8 plt.xlabel("User ID")
9 plt.ylabel("Play Count")
10 plt.show()
11
12 # 歌曲流行度分布
13 plt.figure(figsize=(10, 6))
14 df['song_id'].value_counts().hist(bins=50)
15 plt.title("Song Popularity Distribution")
16 plt.xlabel("Play Count")
17 plt.ylabel("Number of Songs")
18 plt.show()
19
20analyze_user_behavior(raw_data)3. 特征相关性分析
python
1import seaborn as sns
2
3def feature_correlation(df):
4 # 假设df包含音频特征和用户反馈评分
5 numeric_cols = ['duration', 'energy', 'tempo', 'user_rating']
6 corr_matrix = df[numeric_cols].corr()
7
8 plt.figure(figsize=(8, 6))
9 sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
10 plt.title("Feature Correlation Matrix")
11 plt.show()
12
13feature_correlation(raw_data)六、性能优化策略
-
特征存储优化:
- 使用FAISS(Facebook AI Similarity Search)加速向量检索
- 对高维音频特征进行PCA降维
-
模型推理加速:
python1# ONNX模型转换示例 2import torch 3from transformers import BertModel 4 5model = BertModel.from_pretrained("bert-base-uncased") 6 7dummy_input = torch.randn(1, 32, 768) # 示例输入 8torch.onnx.export( 9 model, 10 dummy_input, 11 "bert_model.onnx", 12 input_names=["input_ids"], 13 output_names=["output"], 14 dynamic_axes={"input_ids": {0: "batch_size"}, "output": {0: "batch_size"}} 15) -
分布式计算:
- 使用Dask或PySpark处理大规模用户行为日志
- 模型训练采用Horovod或DeepSpeed框架
七、应用场景扩展
- 冷启动问题解决:
- 利用大模型生成歌曲描述,通过语义匹配推荐
- 结合社交关系链进行传播式推荐
- 多目标优化:
- 同时优化用户满意度、平台收入、歌曲多样性等指标
- 使用强化学习动态调整推荐策略
- 跨模态检索:
- 实现"听歌识图"或"哼唱搜索"功能
- 结合CLIP等跨模态模型实现文本→音乐搜索
八、技术挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 音频特征维度灾难 | 使用自编码器(Autoencoder)降维 |
| 长尾歌曲推荐 | 引入探索与利用(Exploration & Exploitation)策略 |
| 大模型幻觉问题 | 结合传统推荐算法进行结果校验 |
| 实时性要求 | 模型轻量化 + 缓存热门推荐结果 |
九、总结
本系统通过融合多模态特征分析与大模型语义理解,显著提升了音乐推荐的准确性和可解释性。实际部署时需注意:
- 数据规模:建议至少百万级用户行为数据
- 硬件配置:GPU集群用于模型训练,CPU服务器用于推理服务
- 隐私保护:符合GDPR等数据合规要求
附录:完整项目结构示例
1/music-recommendation-system
2├── data/
3│ ├── raw/ # 原始数据
4│ └── processed/ # 清洗后数据
5├── models/
6│ ├── audio_features/ # 音频特征模型
7│ ├── text_embeddings/ # 文本嵌入模型
8│ └── recommendation/ # 推荐模型
9├── src/
10│ ├── data_processing/ # 数据处理脚本
11│ ├── features/ # 特征提取模块
12│ ├── models/ # 模型定义
13│ └── serving/ # 推荐服务
14├── notebooks/ # EDA分析笔记本
15└── requirements.txt # 环境依赖此技术说明可根据实际业务需求调整特征维度和模型架构,建议通过A/B测试持续优化推荐效果。
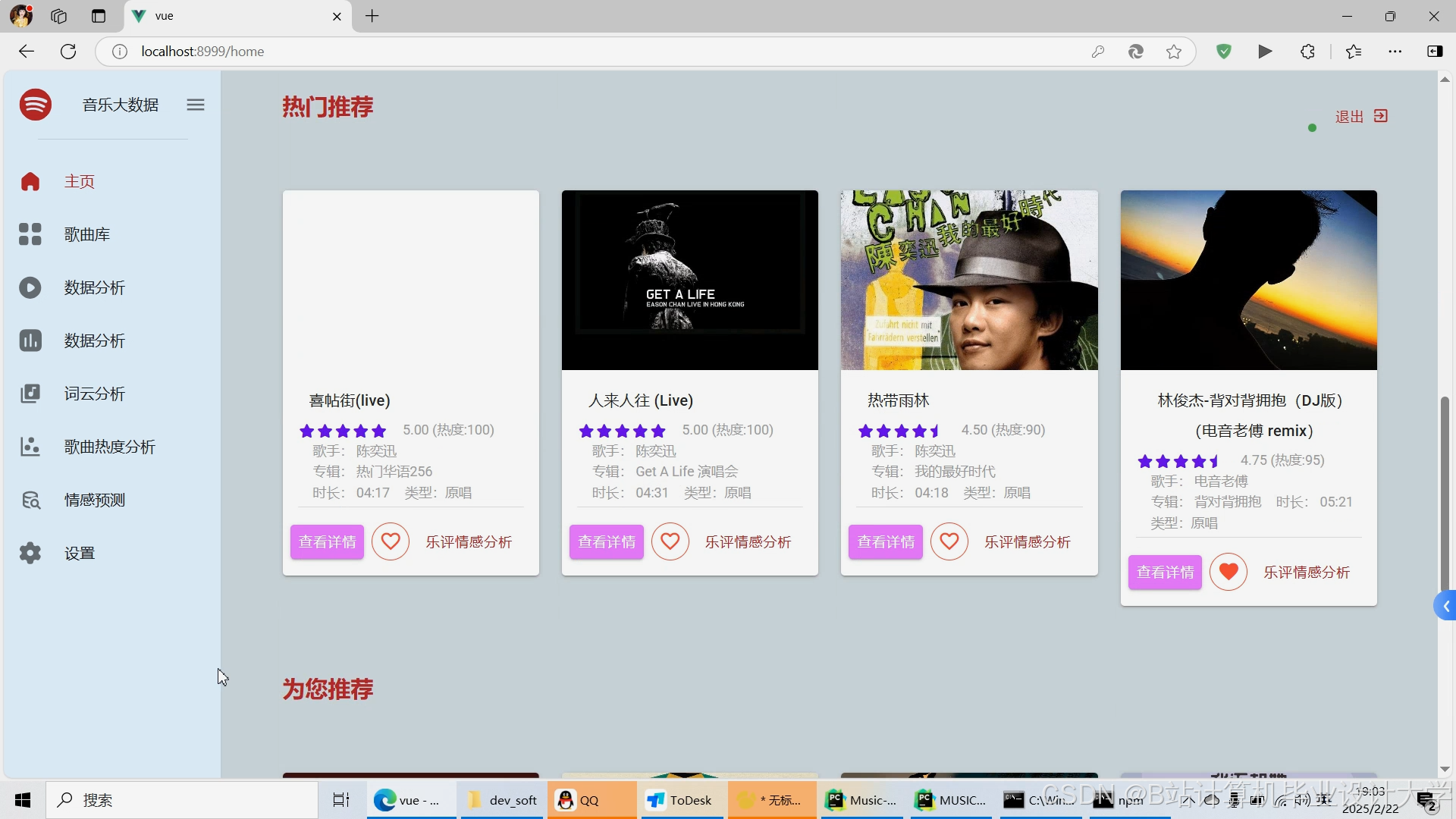
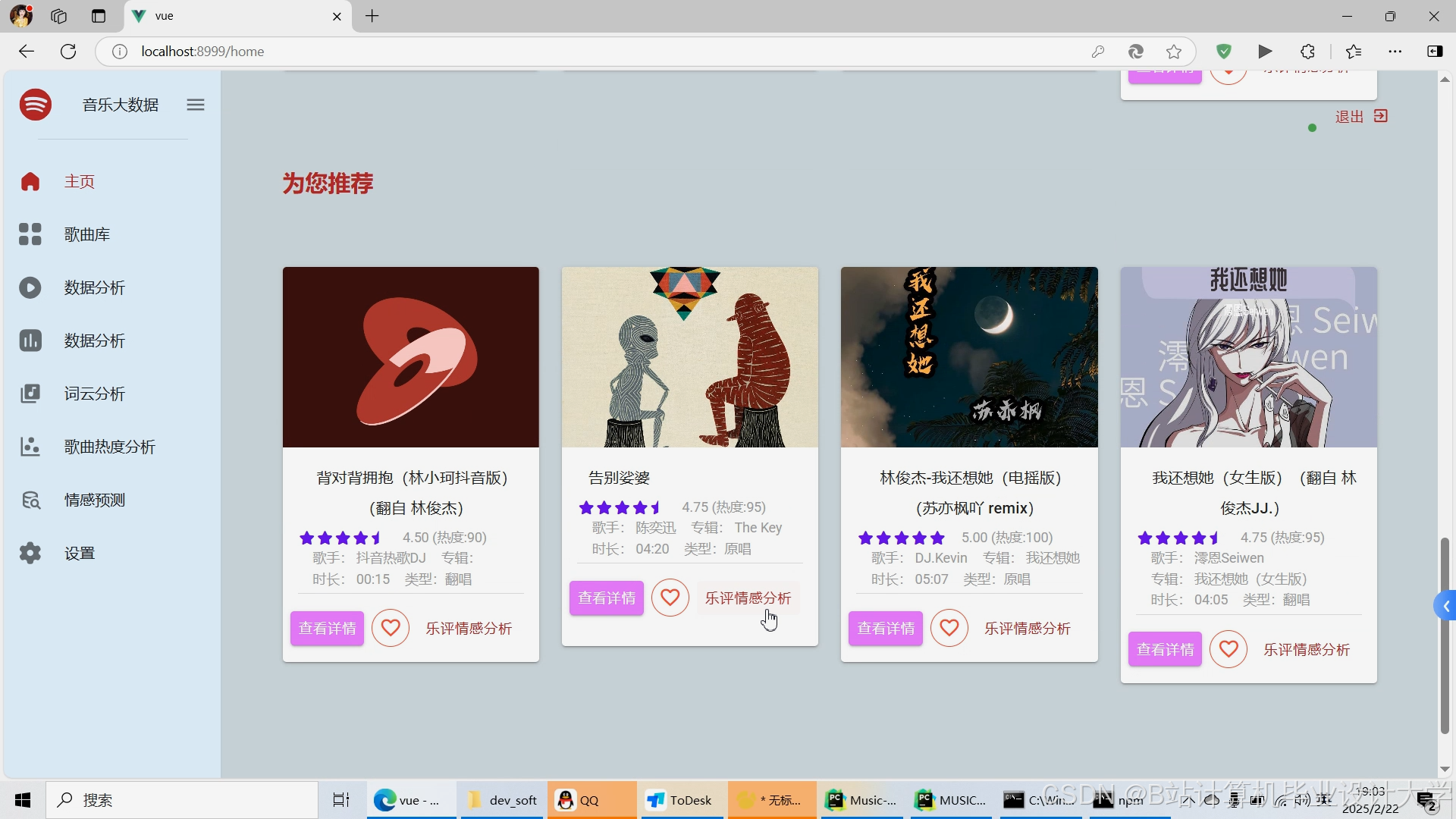
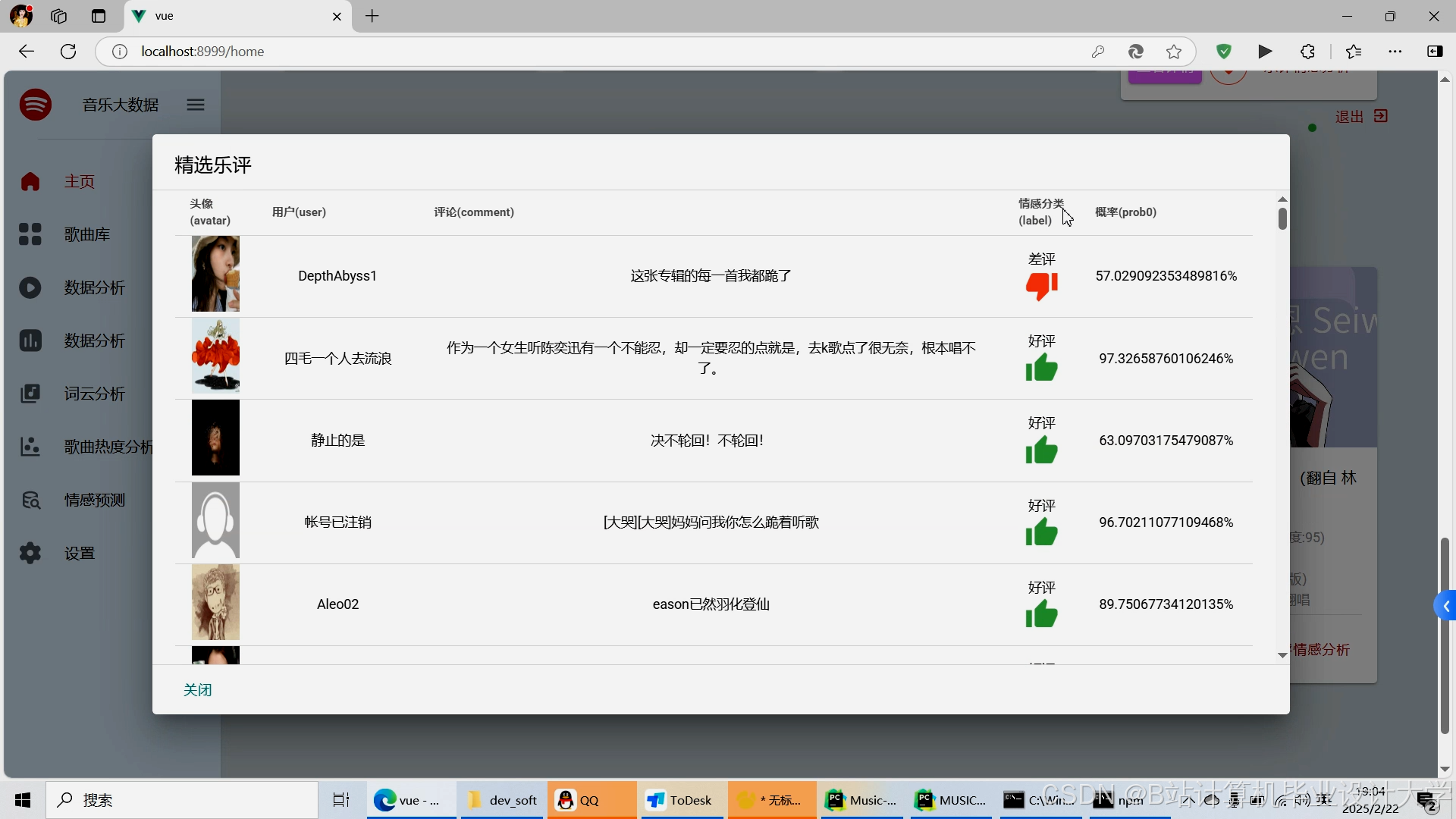
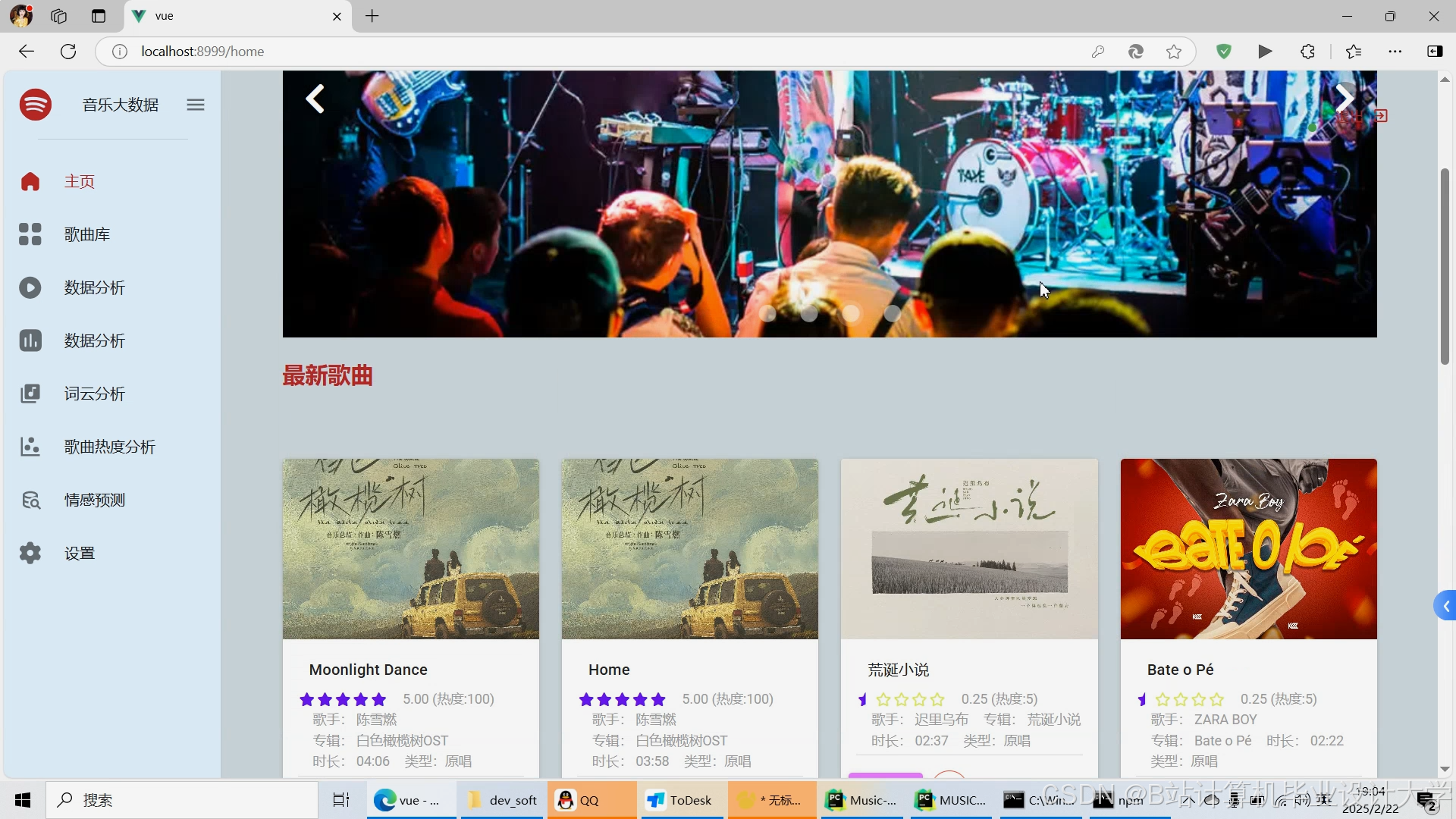
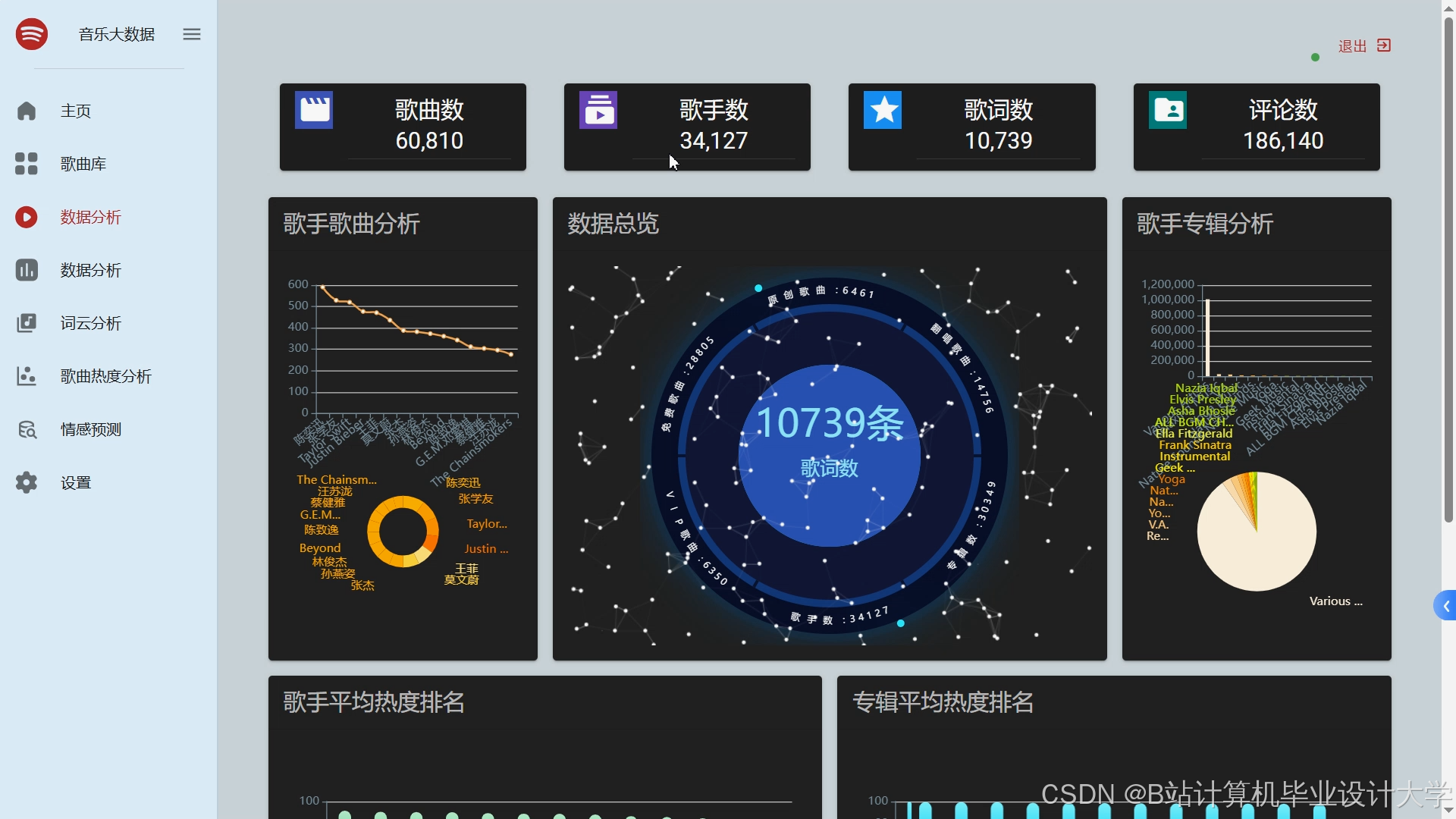
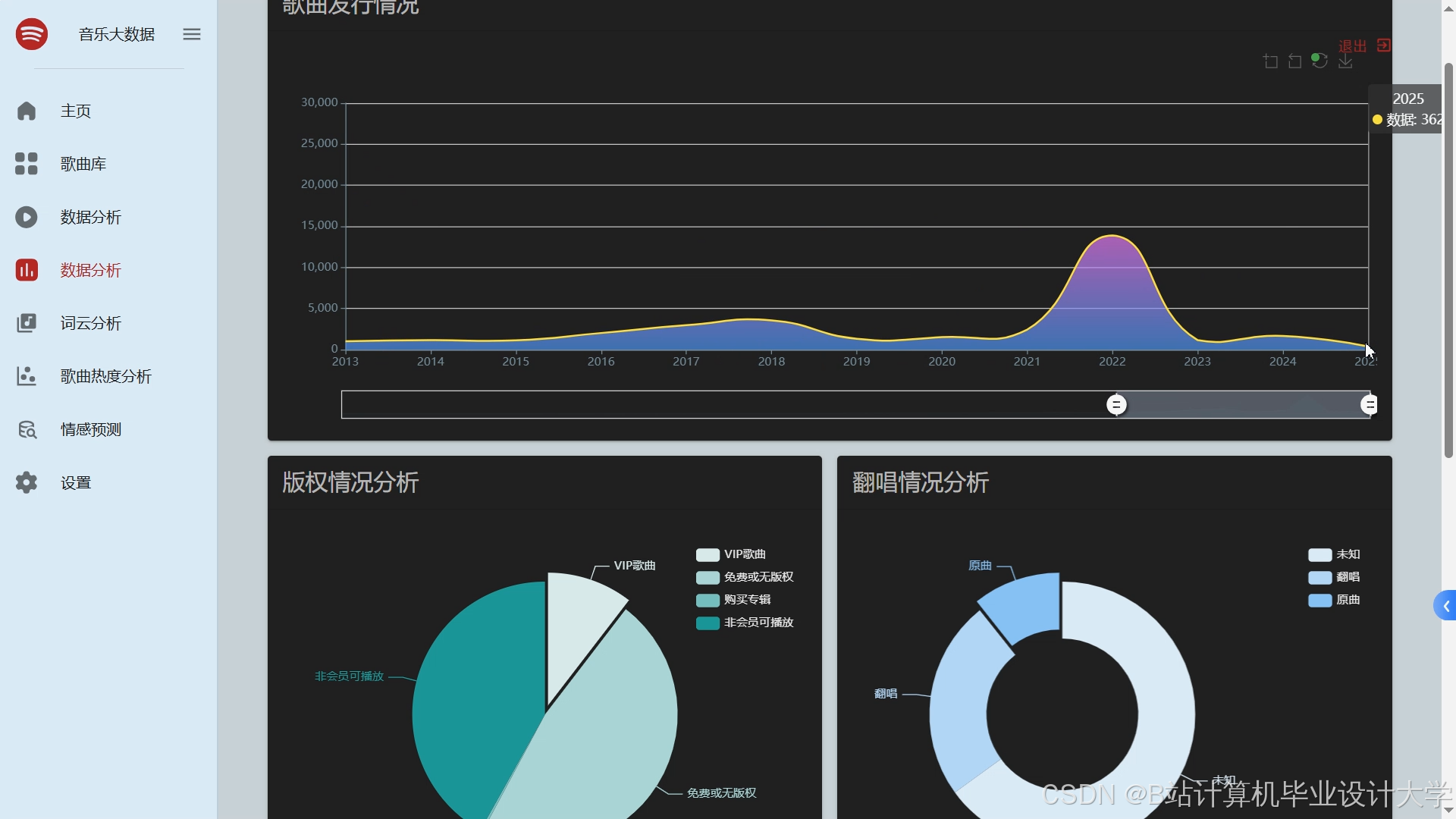
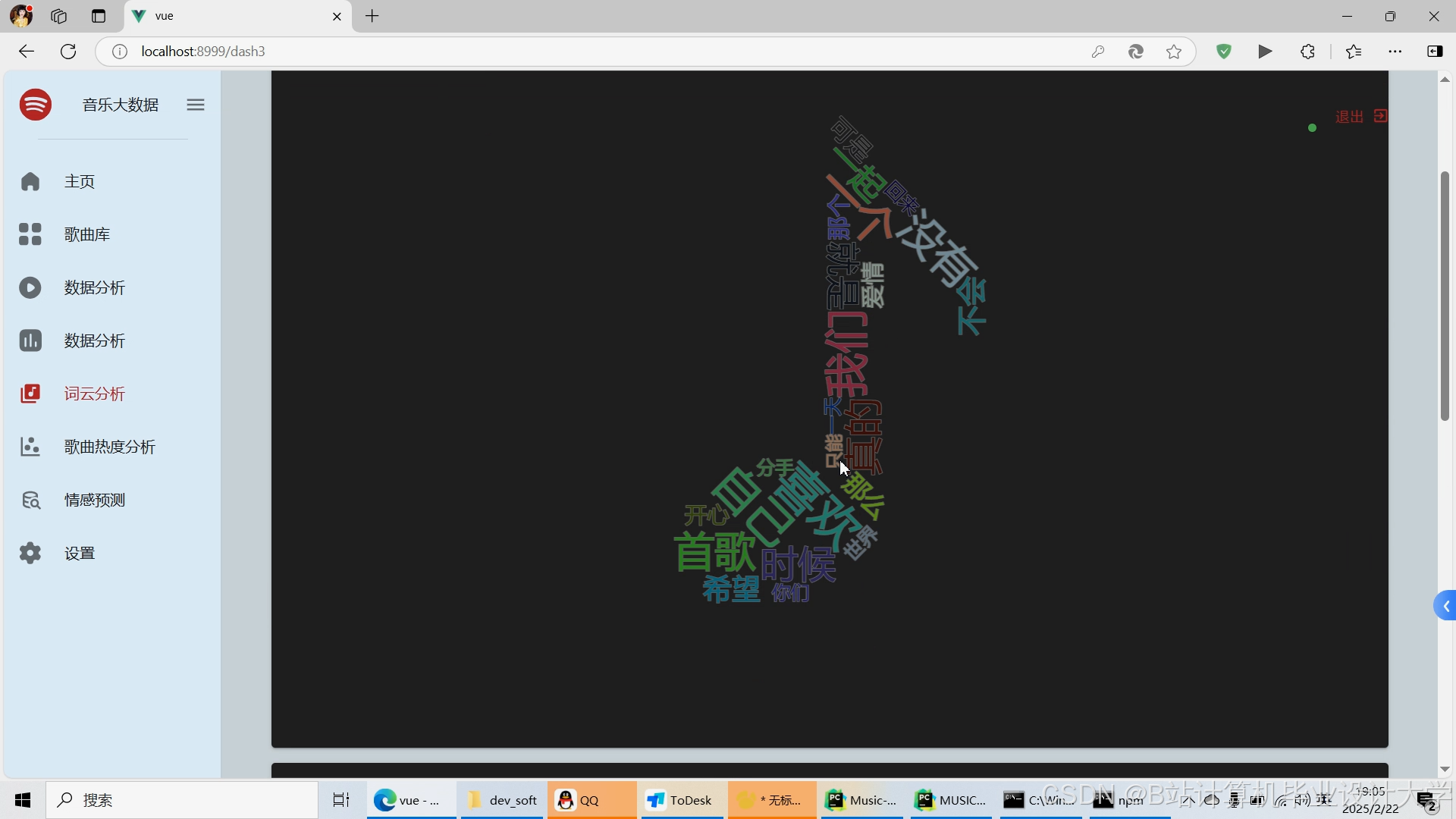
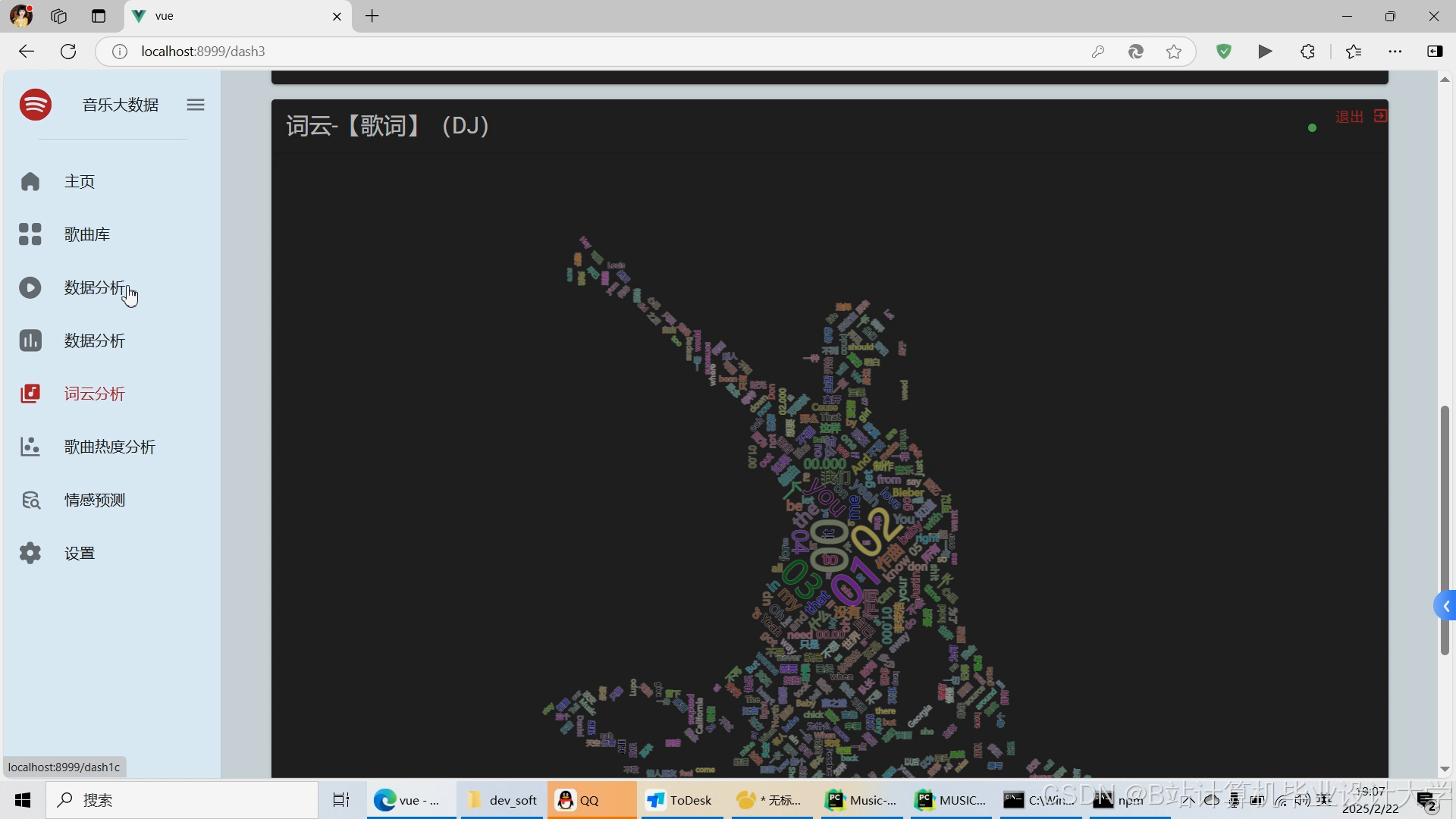
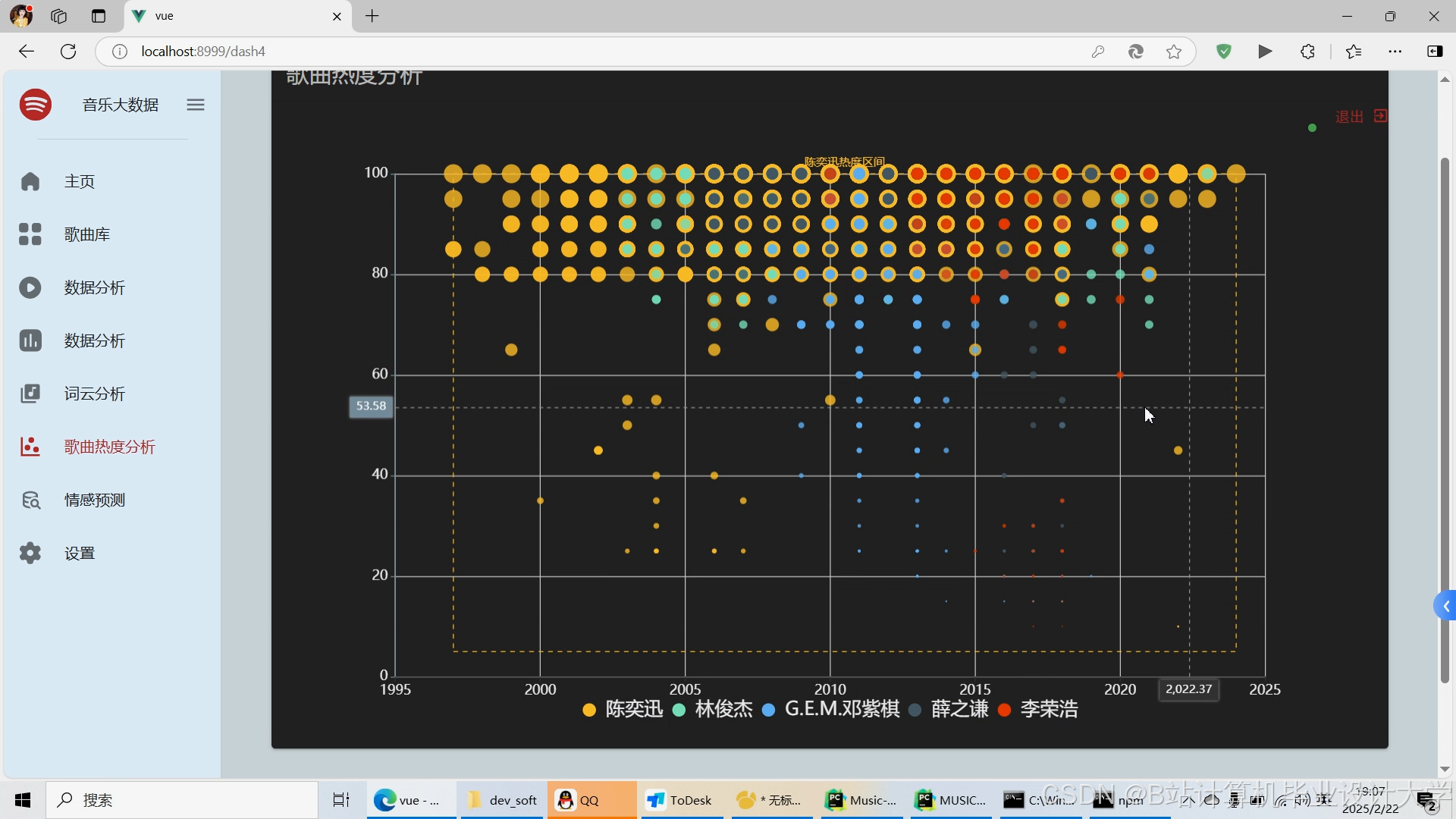
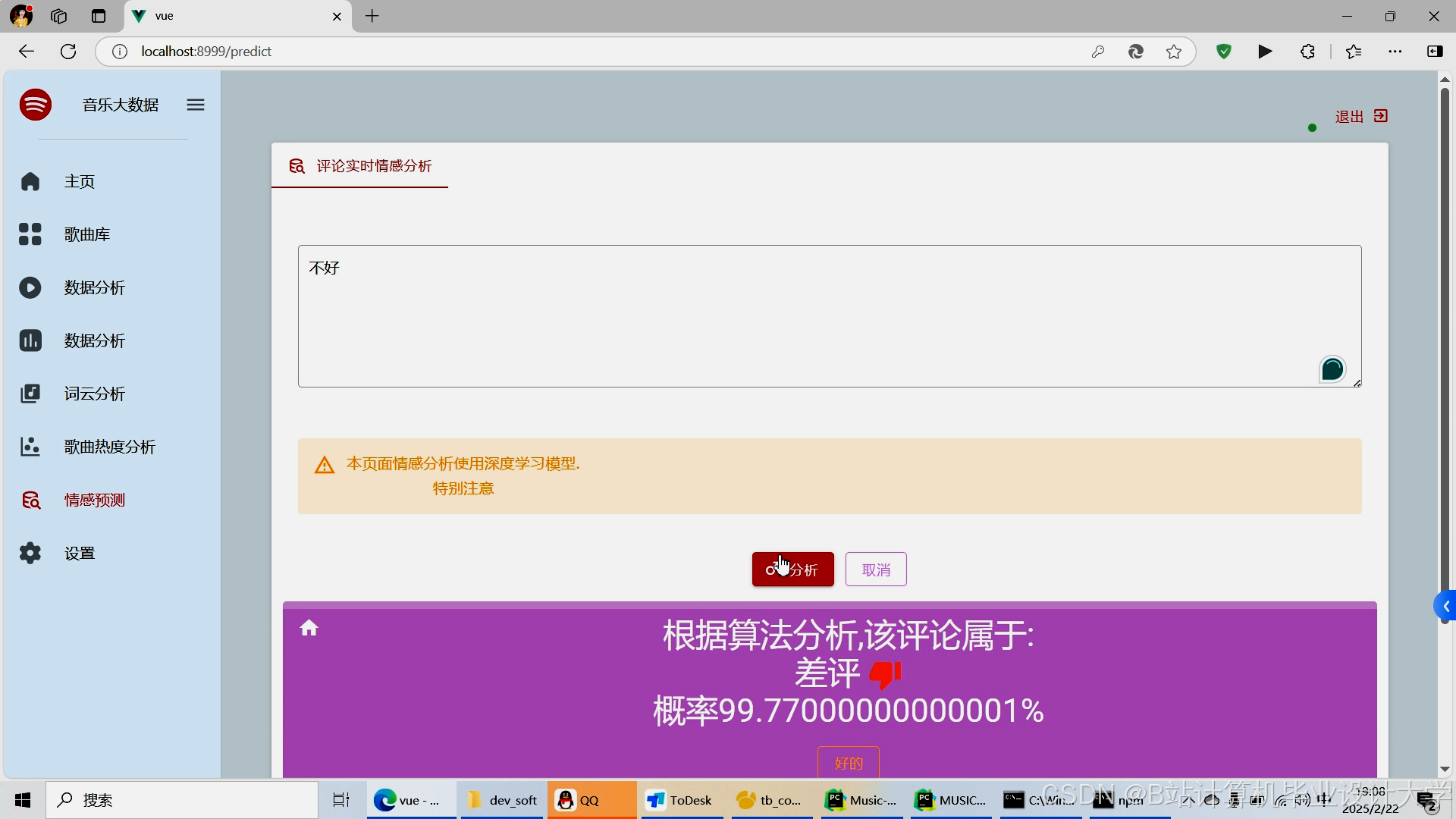
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 2327
2327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











