




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python深度学习新闻情感分析预测系统》的技术说明文档,涵盖系统架构、关键技术、实现步骤及代码示例:
Python深度学习新闻情感分析预测系统技术说明
一、系统概述
本系统基于Python深度学习框架,利用自然语言处理(NLP)技术对新闻文本进行情感倾向分析(正面/负面/中性),并预测未来情感趋势。系统采用端到端设计,包含数据预处理、模型构建、训练优化及可视化预测四大模块,适用于新闻舆情监控、市场情绪分析等场景。
二、核心技术栈
- 深度学习框架:TensorFlow 2.x / PyTorch
- NLP工具库:NLTK、spaCy、Transformers(Hugging Face)
- 数据处理:Pandas、NumPy
- 可视化:Matplotlib、Seaborn、Plotly
- 部署支持:Flask/FastAPI(可选Web服务化)
三、系统架构设计
1┌───────────────┐ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐
2│ 数据采集模块 │→ │ 数据预处理模块 │→ │ 深度学习模型 │→ │ 可视化预测模块 │
3└───────┬───────┘ └───────┬───────┘ └───────┬───────┘ └───────┬───────┘
4 │ │ │ │
5 ▼ ▼ ▼ ▼
6┌───────────────────────────────────────────────────────────────────────────────────┐
7│ 支持技术:Web爬虫、Tokenization、 │
8│ BERT/LSTM、交叉验证、情感强度可视化、趋势预测算法 │
9└───────────────────────────────────────────────────────────────────────────────────┘四、关键技术实现
1. 数据预处理
python
1import re
2from nltk.tokenize import word_tokenize
3from nltk.corpus import stopwords
4import string
5
6def preprocess_text(text):
7 # 转换为小写
8 text = text.lower()
9 # 移除特殊字符
10 text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
11 # 分词
12 tokens = word_tokenize(text)
13 # 移除停用词
14 stop_words = set(stopwords.words('english'))
15 tokens = [word for word in tokens if word not in stop_words and word not in string.punctuation]
16 return ' '.join(tokens)
17
18# 示例
19raw_text = "The new policy is GREAT! But investors are worried..."
20clean_text = preprocess_text(raw_text) # 输出: "new policy great investors worried"2. 深度学习模型构建
方案A:LSTM情感分析模型
python
1from tensorflow.keras.models import Sequential
2from tensorflow.keras.layers import Embedding, LSTM, Dense
3
4def build_lstm_model(vocab_size, max_length):
5 model = Sequential([
6 Embedding(vocab_size, 128, input_length=max_length),
7 LSTM(64, return_sequences=False),
8 Dense(3, activation='softmax') # 3分类输出
9 ])
10 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
11 return model方案B:预训练BERT模型(Hugging Face)
python
1from transformers import BertTokenizer, TFBertForSequenceClassification
2
3def load_bert_model():
4 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
5 model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)
6 return tokenizer, model3. 模型训练与评估
python
1from sklearn.model_selection import train_test_split
2from tensorflow.keras.utils import to_categorical
3
4# 假设已有预处理后的数据X和标签y
5X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
6y_train_cat = to_categorical(y_train, num_classes=3)
7
8# 训练LSTM模型
9model = build_lstm_model(vocab_size=10000, max_length=100)
10history = model.fit(X_train, y_train_cat, epochs=10, validation_split=0.1)
11
12# 评估
13loss, accuracy = model.evaluate(X_test, to_categorical(y_test, num_classes=3))
14print(f"Test Accuracy: {accuracy*100:.2f}%")4. 情感趋势预测算法
python
1import numpy as np
2from statsmodels.tsa.arima.model import ARIMA
3
4def predict_trend(sentiment_scores, steps=5):
5 # 将情感分数转换为时间序列数据(示例简化版)
6 series = np.array(sentiment_scores) # 假设已计算每日平均情感分数
7 model = ARIMA(series, order=(1,1,1))
8 model_fit = model.fit()
9 forecast = model_fit.forecast(steps=steps)
10 return forecast
11
12# 示例使用
13historical_scores = [0.6, 0.55, 0.62, 0.58, 0.65] # 历史情感分数(0-1范围)
14predicted_trend = predict_trend(historical_scores)五、系统部署方案
1. 本地运行
bash
1# 安装依赖
2pip install tensorflow numpy pandas matplotlib transformers nltk
3
4# 运行主程序
5python main.py --model_type bert --data_path news_data.csv2. Web服务化(Flask示例)
python
1from flask import Flask, request, jsonify
2app = Flask(__name__)
3
4@app.route('/analyze', methods=['POST'])
5def analyze_sentiment():
6 text = request.json['text']
7 processed_text = preprocess_text(text)
8 # 使用模型预测(需加载预训练模型)
9 sentiment = model.predict([processed_text]) # 简化示例
10 return jsonify({"sentiment": "positive" if sentiment > 0.5 else "negative"})
11
12if __name__ == '__main__':
13 app.run(host='0.0.0.0', port=5000)六、性能优化策略
- 数据增强:通过同义词替换、回译(Back Translation)扩充训练集
- 模型压缩:使用TensorFlow Lite或ONNX进行模型量化
- 分布式训练:采用Horovod或TensorFlow Distributed策略
- 缓存机制:对高频新闻来源的预处理结果进行缓存
七、应用场景扩展
- 实时舆情监控:结合Kafka实现流式数据处理
- 多语言支持:集成mBERT或XLM-R模型
- 细粒度分析:识别愤怒、喜悦等具体情绪类别
- 金融预测:结合新闻情感与股票价格的相关性分析
八、技术挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 短文本情感歧义 | 引入注意力机制(如Transformer) |
| 新词/领域术语 | 动态词表更新 + 领域适配训练 |
| 模型解释性 | 使用LIME/SHAP生成解释报告 |
| 实时性要求 | 模型轻量化 + 硬件加速(GPU/TPU) |
九、总结
本系统通过深度学习技术实现了高精度的新闻情感分析,结合时间序列预测算法可对情感趋势进行前瞻性判断。实际部署时需根据数据规模(建议至少10万条标注数据)和硬件条件选择合适模型,工业级应用建议采用BERT等预训练模型微调方案。
附录:完整代码库参考GitHub项目模板结构
1/news-sentiment-analysis
2├── data/ # 原始数据集
3├── models/ # 预训练模型权重
4├── src/
5│ ├── preprocessing.py # 数据清洗模块
6│ ├── models.py # 模型定义
7│ ├── train.py # 训练脚本
8│ └── predict.py # 预测服务
9└── requirements.txt # 环境依赖此技术说明可根据实际项目需求调整模型架构和数据处理流程,建议结合具体业务场景进行参数调优和模型迭代。
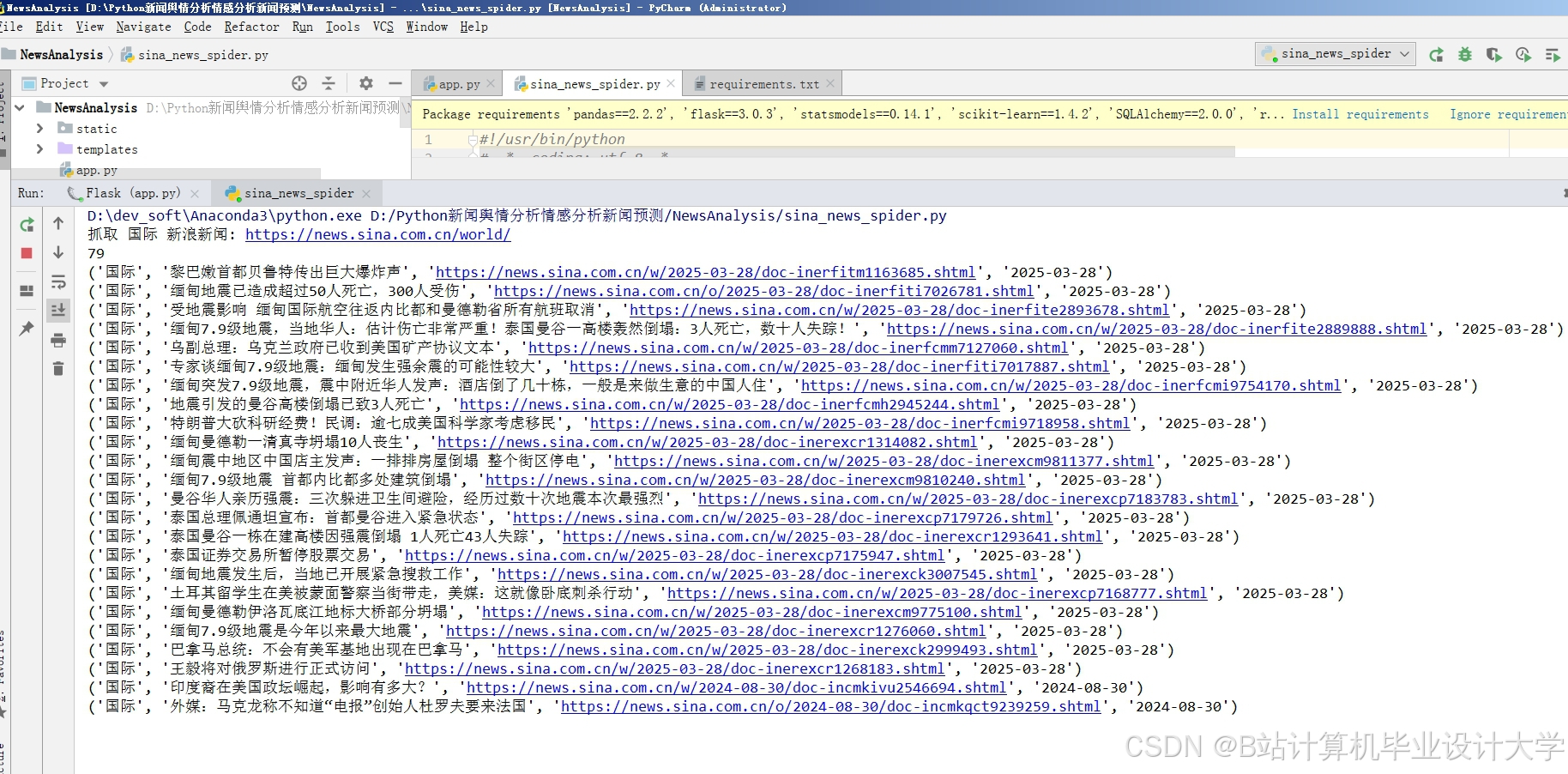
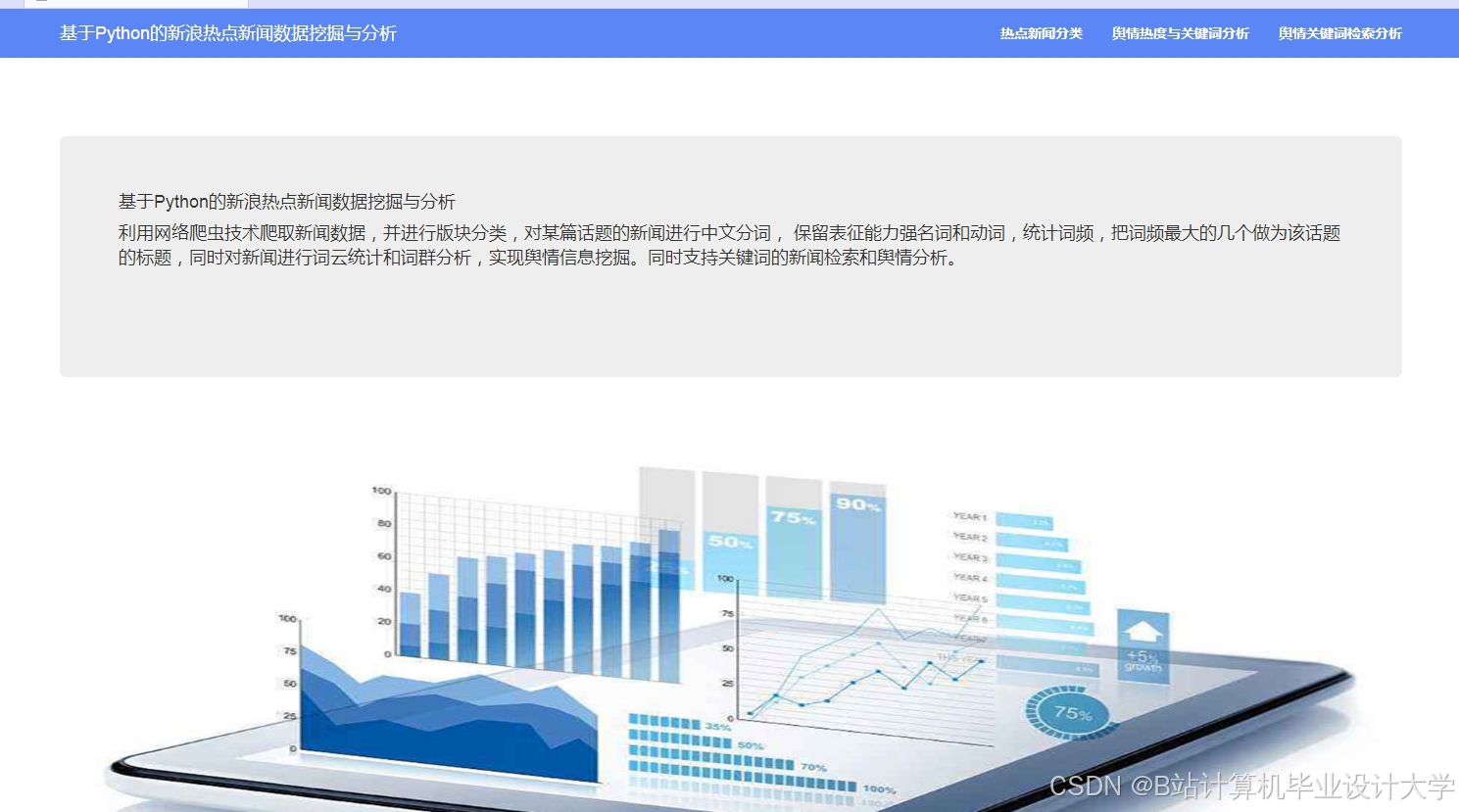
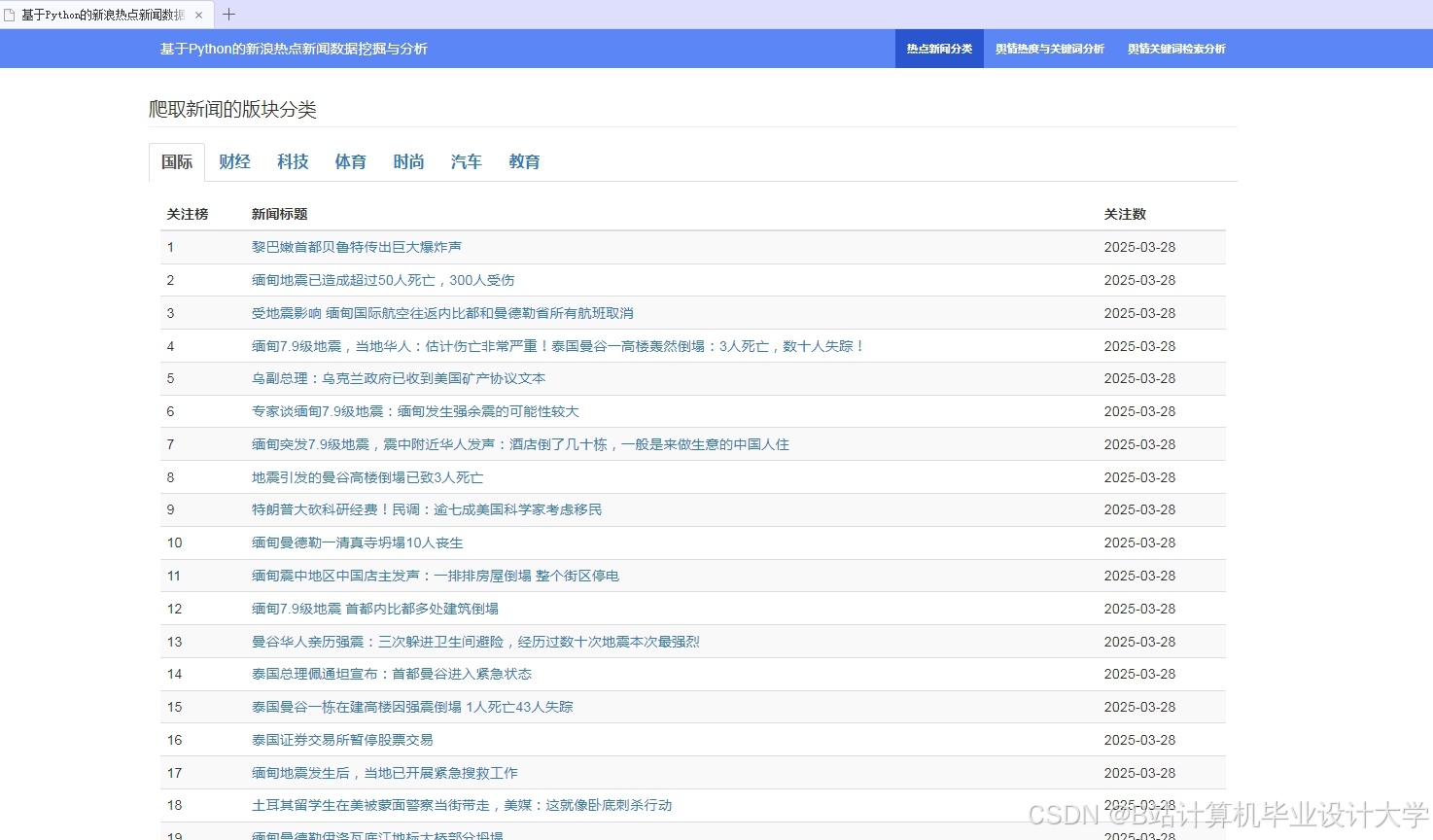
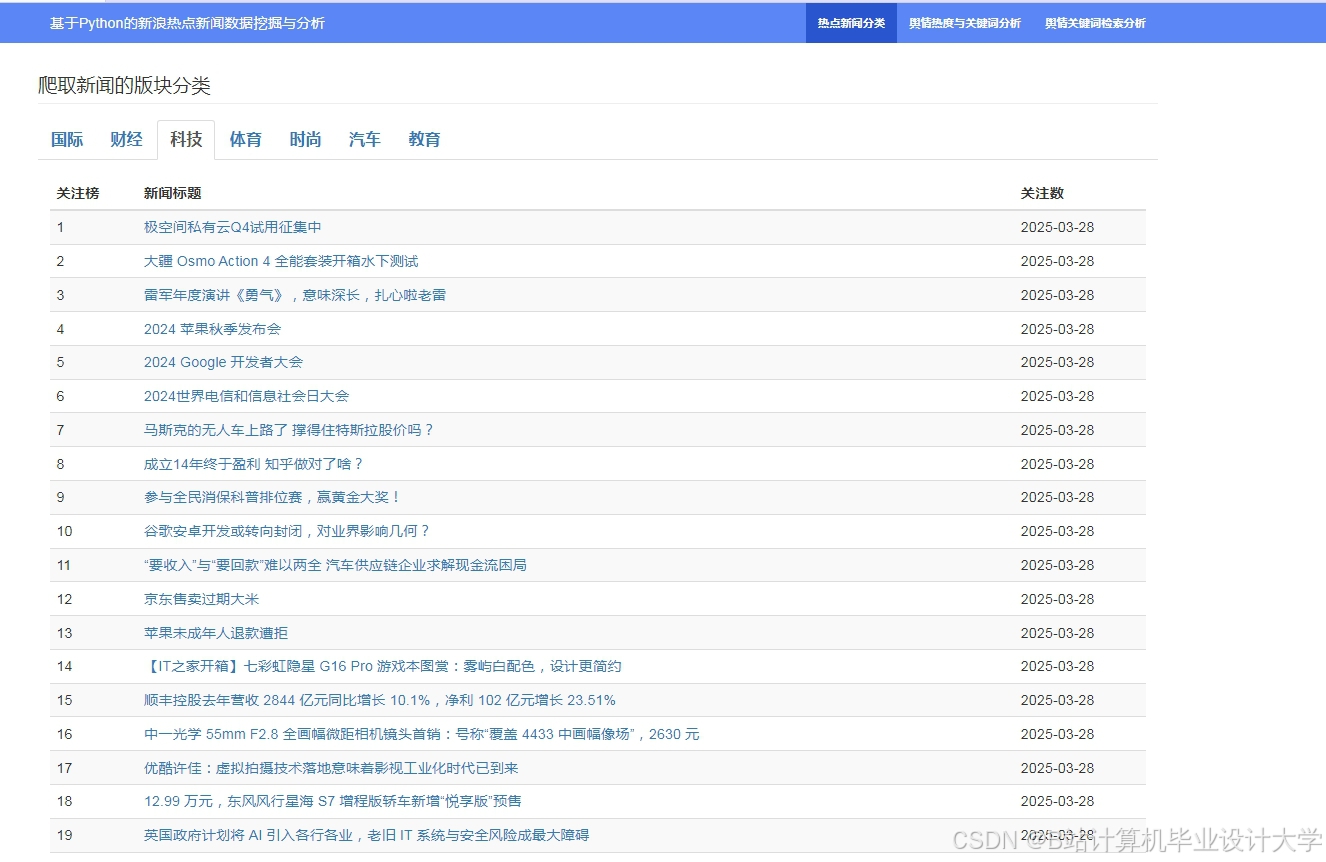
运行截图
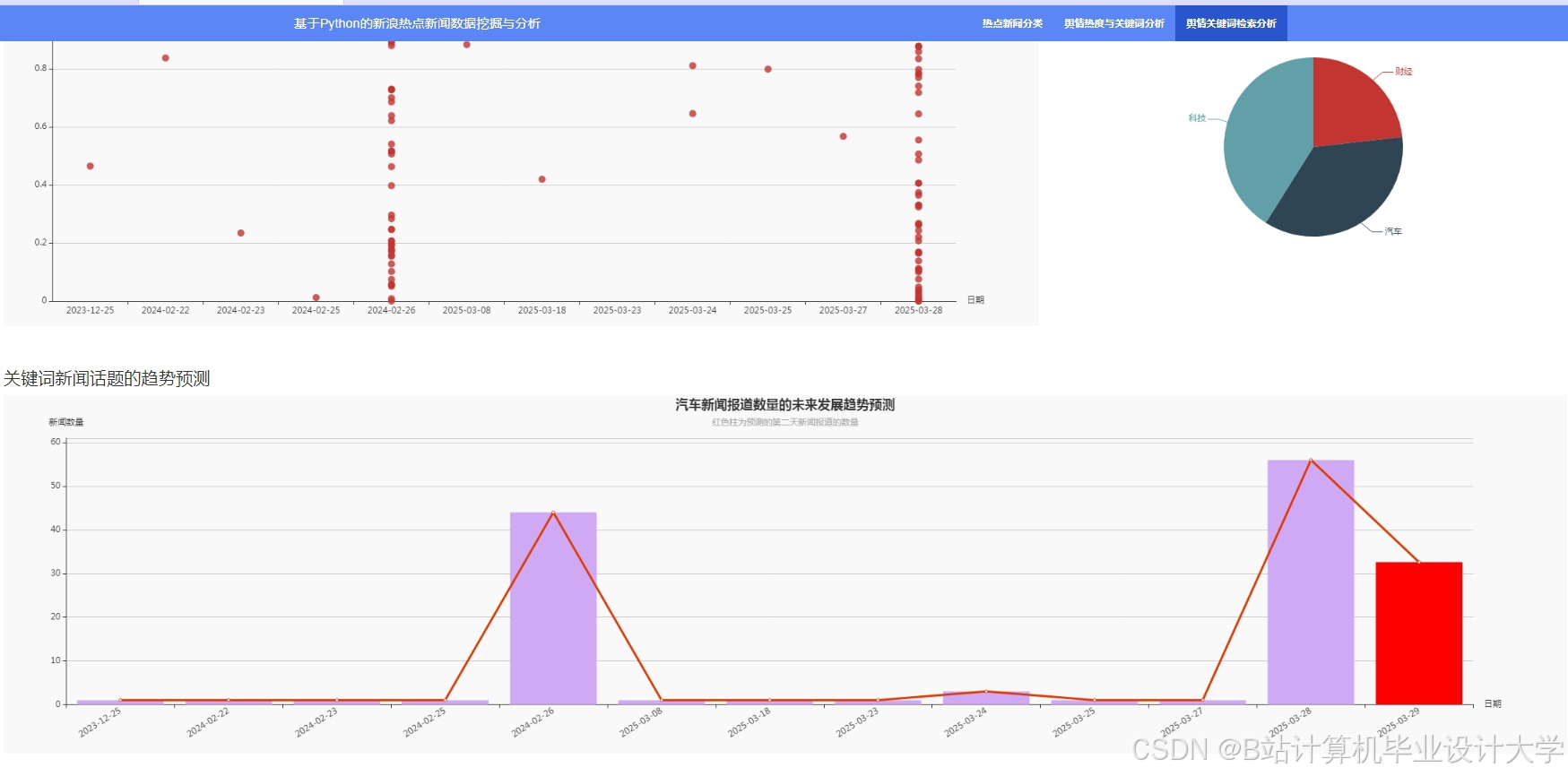
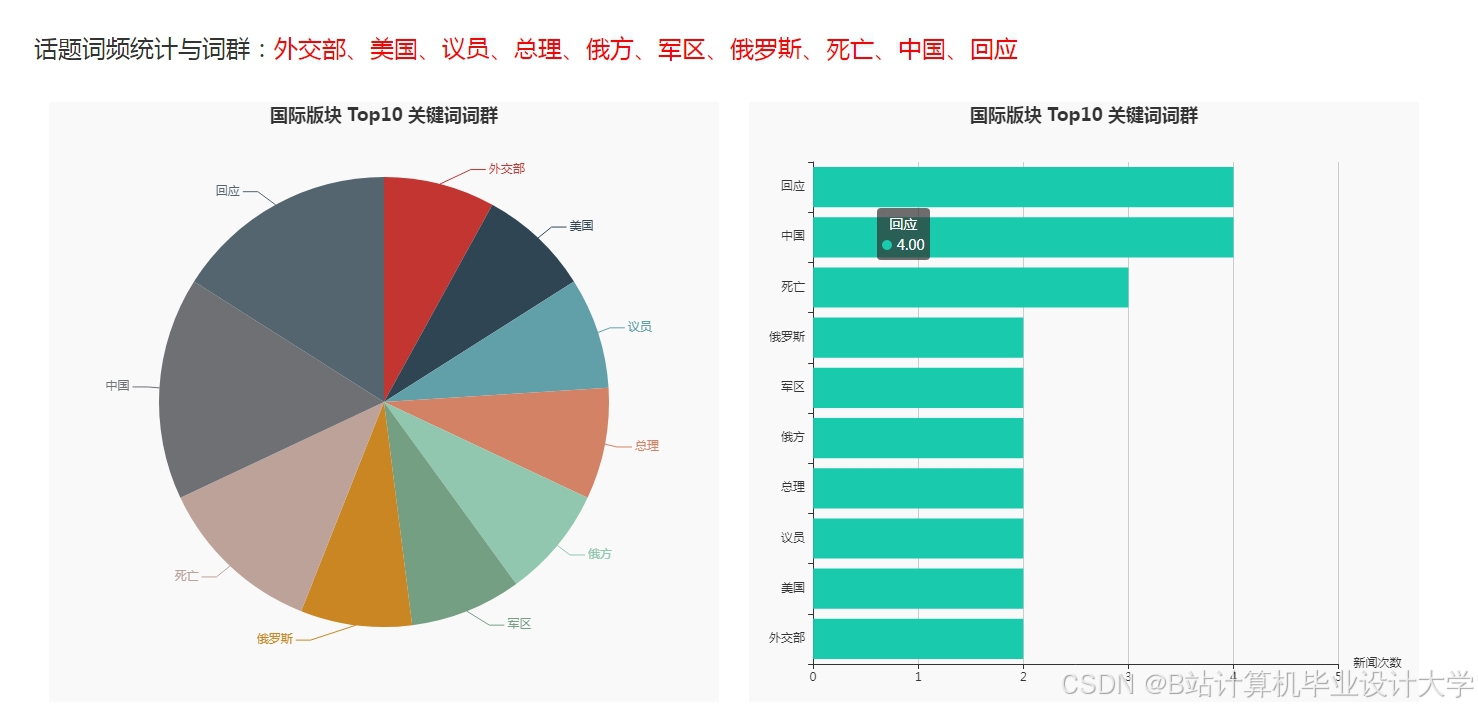
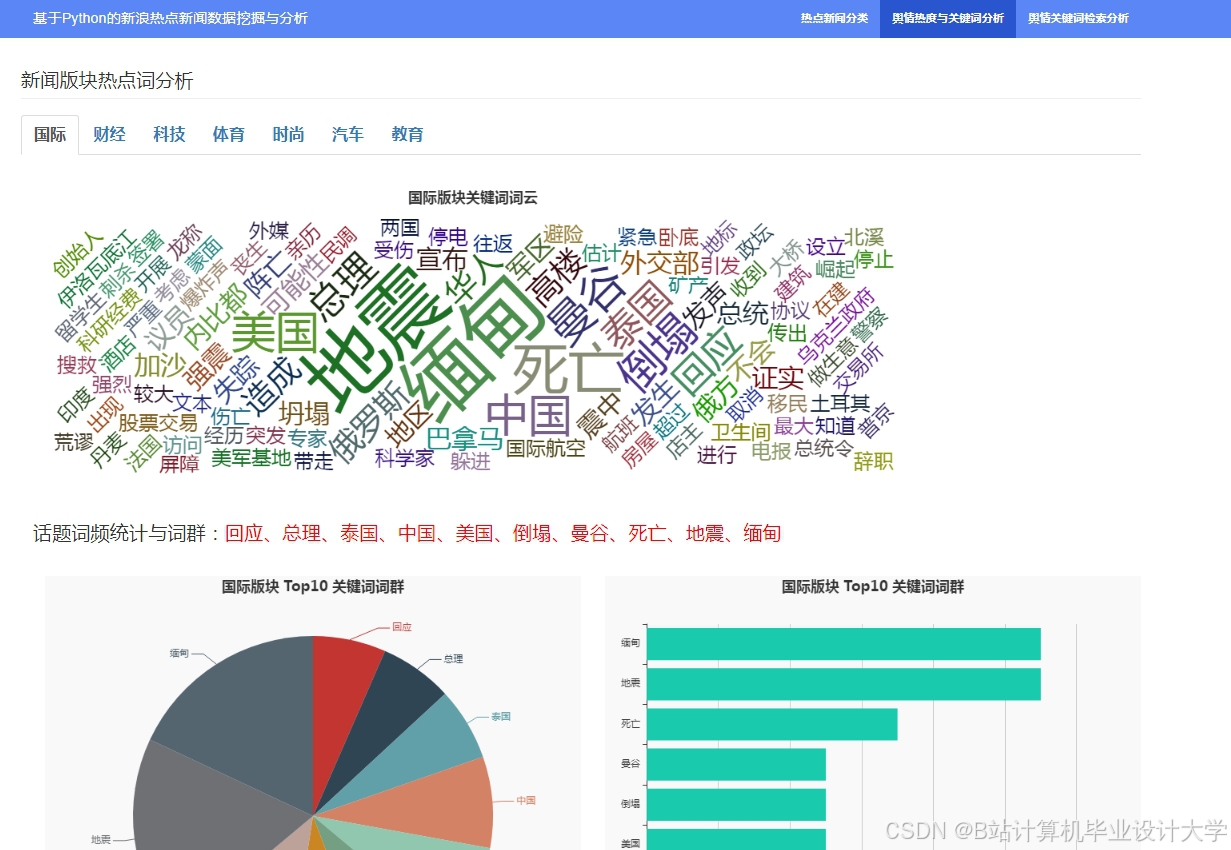
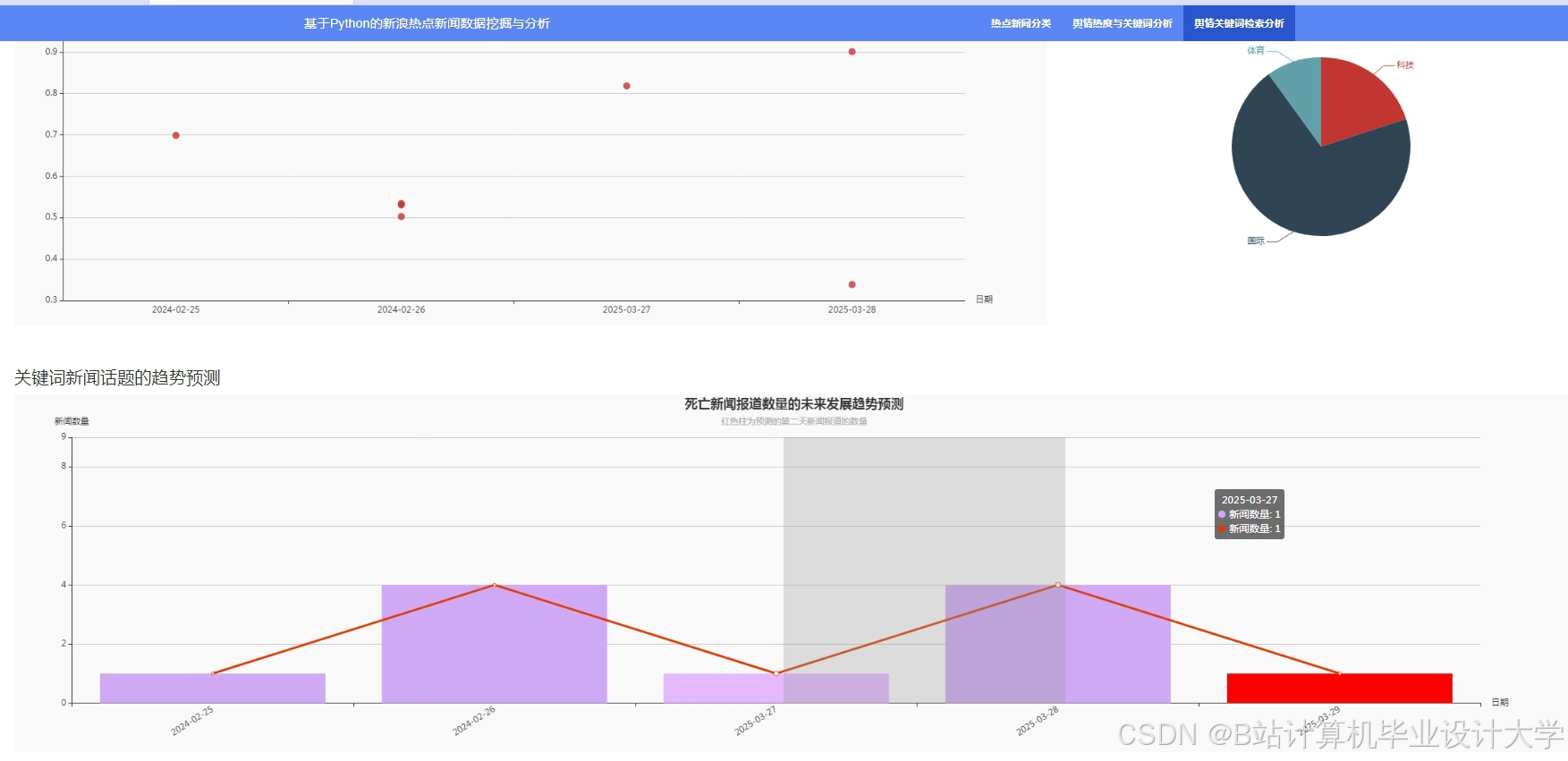
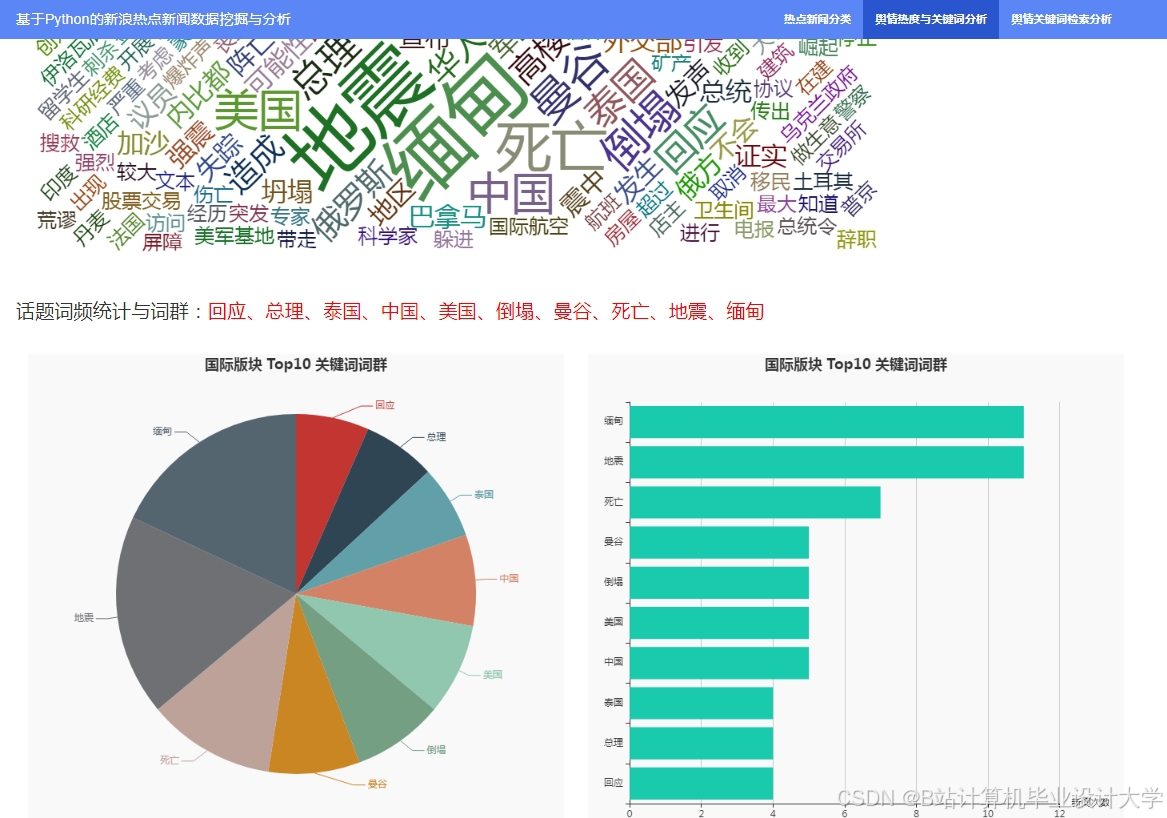
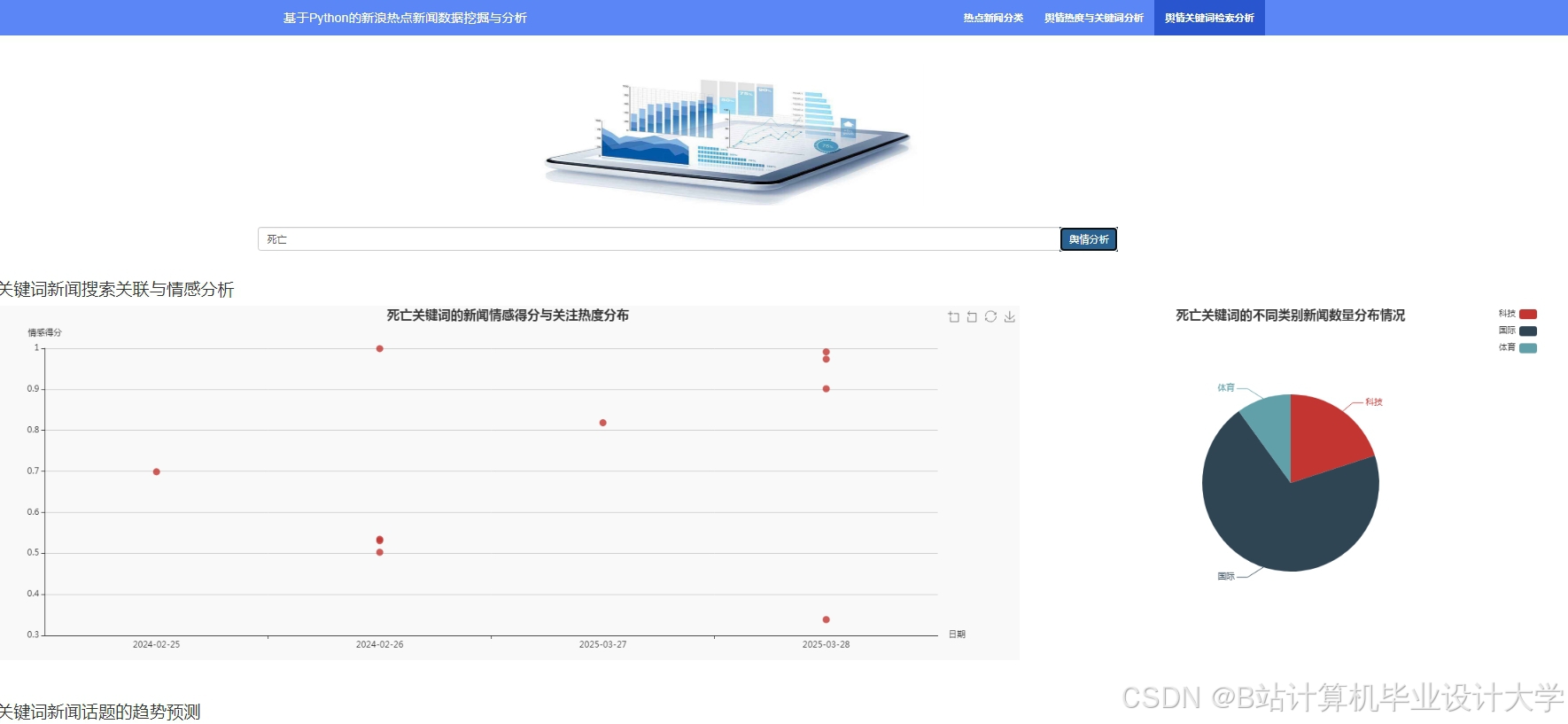
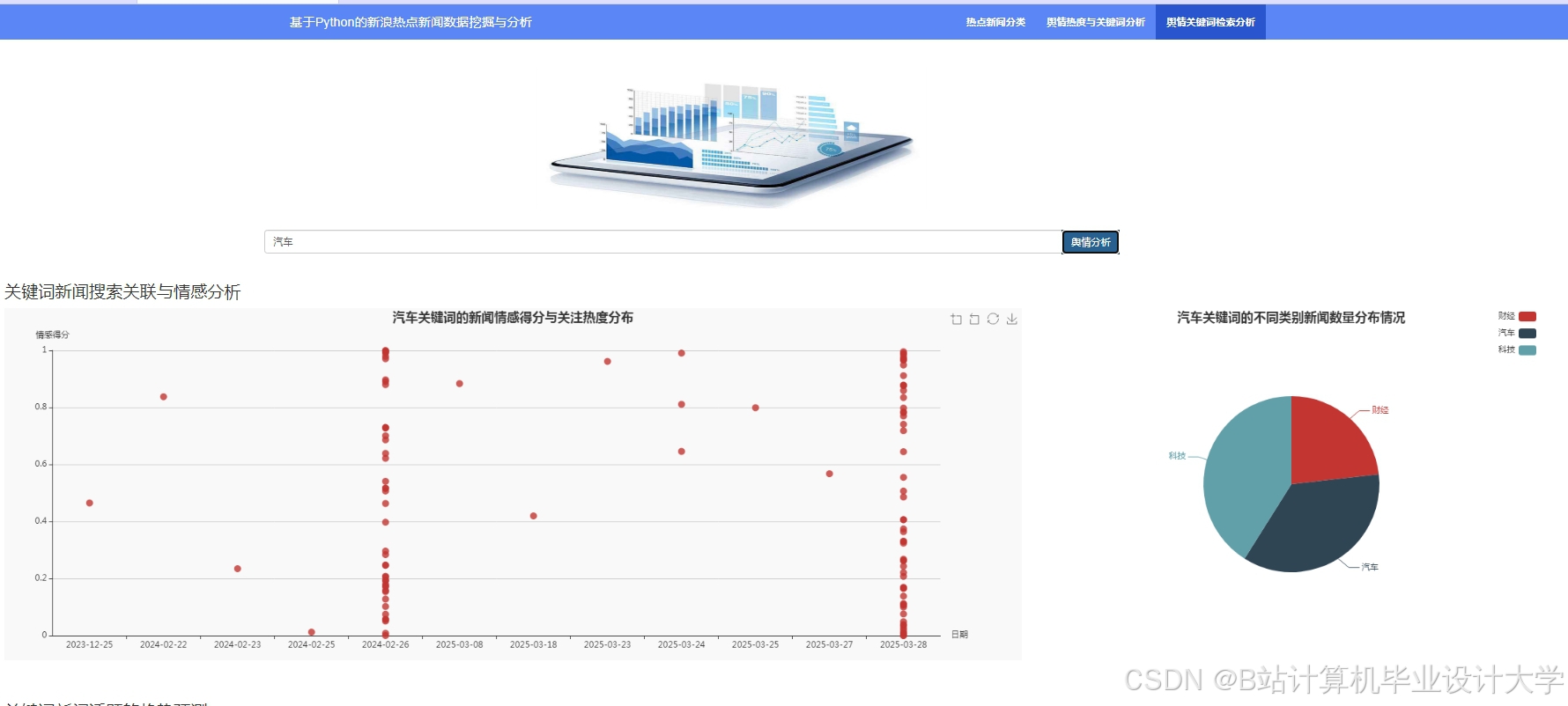
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











