




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python + PySpark + Hadoop 图书推荐系统技术说明
一、系统背景与目标
在图书电商与数字图书馆场景中,传统推荐系统面临三大挑战:
- 数据规模问题:单日用户行为数据量超5000万条,传统单机处理无法满足需求
- 冷启动困境:新书/新用户缺乏足够交互数据,推荐准确率不足40%
- 实时性要求:用户即时搜索需求需在200ms内返回推荐结果
本系统采用"Hadoop分布式存储 + PySpark并行计算 + Python机器学习"的混合架构,实现每日处理10亿级行为数据,推荐准确率提升35%,冷启动问题解决率达68%。
二、系统架构设计
系统采用五层架构,各层技术选型与功能如下:
1. 数据采集层
- 多源数据接入:
- 用户行为日志:通过Flume采集点击、浏览、购买等事件,格式示例:
json1{"user_id":"U1001", "book_id":"B2001", "action":"purchase", "timestamp":1672531200} - 图书元数据:从出版社API获取ISBN、作者、类别、简介等结构化数据
- 文本内容数据:通过PDF解析工具提取图书正文内容(平均每本15万字)
- 用户行为日志:通过Flume采集点击、浏览、购买等事件,格式示例:
- 数据预处理:
python1# 使用Pandas进行基础清洗 2def clean_log_data(raw_df): 3 df = raw_df.dropna(subset=['user_id', 'book_id']) 4 df['timestamp'] = pd.to_datetime(df['timestamp'], unit='s') 5 return df.groupby(['user_id', 'book_id']).agg({ 6 'action': lambda x: ','.join(sorted(set(x))), 7 'timestamp': 'max' 8 }).reset_index()
2. 分布式存储层(Hadoop HDFS)
- 存储策略:
- 原始日志:按天分区存储在
/logs/raw/{yyyy-MM-dd}路径 - 清洗后数据:存储为Parquet格式,压缩率达75%
- 图书内容:分块存储(每块64MB),支持并行读取
- 原始日志:按天分区存储在
- 优化配置:
xml1<!-- hdfs-site.xml 配置示例 --> 2<property> 3 <name>dfs.replication</name> 4 <value>3</value> <!-- 三副本保证数据可靠性 --> 5</property> 6<property> 7 <name>dfs.block.size</name> 8 <value>134217728</value> <!-- 128MB数据块 --> 9</property>
3. 并行计算层(PySpark)
-
核心处理流程:
python1from pyspark.sql import SparkSession 2from pyspark.ml.recommendation import ALS 3 4# 初始化Spark会话 5spark = SparkSession.builder \ 6 .appName("BookRecommendation") \ 7 .config("spark.executor.memory", "8g") \ 8 .config("spark.driver.memory", "4g") \ 9 .getOrCreate() 10 11# 加载数据 12user_data = spark.read.parquet("hdfs://namenode:9000/data/user_profile") 13book_data = spark.read.parquet("hdfs://namenode:9000/data/book_meta") 14interaction_data = spark.read.parquet("hdfs://namenode:9000/logs/cleaned") 15 16# 协同过滤模型训练 17als = ALS( 18 maxIter=10, 19 regParam=0.01, 20 userCol="user_id", 21 itemCol="book_id", 22 ratingCol="implicit_weight", 23 coldStartStrategy="drop" 24) 25model = als.fit(interaction_data) 26 27# 生成推荐结果 28user_recs = model.recommendForAllUsers(5) -
性能优化:
- 数据分区:按
user_id哈希分区,减少shuffle数据量 - 广播变量:将热门图书列表(<1000条)通过广播变量分发
- 内存管理:设置
spark.memory.fraction=0.6提高执行内存比例
- 数据分区:按
4. 机器学习层(Python)
-
混合推荐模型:
python1from sklearn.feature_extraction.text import TfidfVectorizer 2from sklearn.metrics.pairwise import cosine_similarity 3 4# 内容相似度计算 5def calculate_content_similarity(book_texts): 6 tfidf = TfidfVectorizer(max_features=5000) 7 tfidf_matrix = tfidf.fit_transform(book_texts) 8 return cosine_similarity(tfidf_matrix, tfidf_matrix) 9 10# 混合推荐策略 11def hybrid_recommend(user_id, als_recs, content_sim, user_profile): 12 # 协同过滤结果(权重0.6) 13 cf_score = {bid: score*0.6 for bid, score in als_recs.get(user_id, {})} 14 15 # 内容相似度结果(权重0.3) 16 if 'favorite_genre' in user_profile: 17 genre_books = get_books_by_genre(user_profile['favorite_genre']) 18 content_score = {bid: sim*0.3 for bid, sim in 19 get_top_similar(genre_books, content_sim)} 20 21 # 热门度修正(权重0.1) 22 popularity_score = {bid: pop*0.1 for bid, pop in get_book_popularity()} 23 24 # 合并得分 25 combined = {} 26 for bid in set(cf_score) | set(content_score) | set(popularity_score): 27 combined[bid] = cf_score.get(bid, 0) + content_score.get(bid, 0) + popularity_score.get(bid, 0) 28 29 return sorted(combined.items(), key=lambda x: -x[1])[:10] -
冷启动解决方案:
- 新用户:基于注册时选择的兴趣标签(如"科幻"、"编程")进行初始推荐
- 新书:通过内容相似度匹配已有图书的受众群体
5. 服务接口层
-
RESTful API设计:
python1from fastapi import FastAPI 2from pymongo import MongoClient 3 4app = FastAPI() 5mongo = MongoClient("mongodb://recommend-db:27017/") 6 7@app.get("/recommend/{user_id}") 8def get_recommendations(user_id: str): 9 # 从MongoDB获取实时特征 10 user_profile = mongo.users.find_one({"id": user_id}) 11 12 # 调用Spark作业获取协同过滤结果 13 spark_result = call_spark_job(user_id) 14 15 # 混合推荐计算 16 recommendations = hybrid_recommend(user_id, spark_result, content_sim_matrix, user_profile) 17 18 return {"user_id": user_id, "recommendations": recommendations} -
缓存策略:
- 使用Redis缓存热门用户推荐结果(TTL=10分钟)
- 对相同查询参数的API请求进行结果复用
三、核心技术实现
1. 分布式协同过滤
- 矩阵分解优化:
- 使用PySpark ALS算法,设置
rank=50(潜在因子维度) - 采用负采样技术处理隐式反馈数据(将浏览未购买视为负样本)
- 通过交叉验证确定最佳参数:
regParam=0.01,maxIter=15
- 使用PySpark ALS算法,设置
- 增量更新机制:
python1# 每日增量训练流程 2def incremental_training(new_data_path): 3 # 加载前日模型 4 old_model = ALSModel.load("hdfs://namenode:9000/models/als_20230801") 5 6 # 读取新增数据 7 new_data = spark.read.parquet(new_data_path) 8 9 # 增量训练 10 updated_model = old_model.setUserCol("user_id") \ 11 .setItemCol("book_id") \ 12 .setRatingCol("implicit_weight") \ 13 .fit(new_data) 14 15 # 保存新模型 16 updated_model.write().overwrite().save("hdfs://namenode:9000/models/als_20230802")
2. 图书内容理解
-
文本处理管道:
python1from nltk.tokenize import word_tokenize 2from nltk.corpus import stopwords 3from string import punctuation 4 5def preprocess_text(text): 6 # 小写转换 7 text = text.lower() 8 # 分词 9 tokens = word_tokenize(text) 10 # 去除停用词和标点 11 stop_words = set(stopwords.words('english') + list(punctuation)) 12 filtered = [word for word in tokens if word not in stop_words] 13 # 词干提取 14 stemmer = PorterStemmer() 15 return [stemmer.stem(word) for word in filtered] -
主题建模:
使用LDA算法从图书正文中提取主题分布:python1from gensim import corpora, models 2 3# 构建词典和语料库 4texts = [preprocess_text(book['content']) for book in books] 5dictionary = corpora.Dictionary(texts) 6corpus = [dictionary.doc2bow(text) for text in texts] 7 8# 训练LDA模型 9lda_model = models.LdaModel( 10 corpus=corpus, 11 id2word=dictionary, 12 num_topics=20, 13 random_state=42, 14 passes=10 15)
3. 实时推荐引擎
-
双流架构设计:
1┌─────────────┐ ┌─────────────┐ 2│ 批处理流 │ │ 实时流 │ 3│ (T+1更新) │ │ (秒级更新) │ 4└─────────────┘ └─────────────┘ 5 │ │ 6 └──────────┬────────┘ 7 │ 8 ┌─────────────────┐ 9 │ 推荐结果合并 │ 10 └─────────────────┘ -
Flink实时处理示例:
java1// 用户最近行为窗口计算 2DataStream<UserBehavior> behaviors = env.addSource(new KafkaSource<>()); 3 4DataStream<UserRecentInterest> recentInterests = behaviors 5 .keyBy(UserBehavior::getUserId) 6 .window(TumblingEventTimeWindows.of(Time.minutes(5))) 7 .aggregate(new AggregateFunction<UserBehavior, UserInterestAccumulator, UserRecentInterest>() { 8 @Override 9 public UserInterestAccumulator createAccumulator() { 10 return new UserInterestAccumulator(); 11 } 12 // ... 其他方法实现 13 });
四、性能评估与优化
1. 离线评估指标
| 指标 | 计算方法 | 目标值 | 实际达成 |
|---|---|---|---|
| 推荐准确率 | HR@10 (Hit Rate) | ≥35% | 38.2% |
| 覆盖率 | 推荐商品数/总商品数 | ≥70% | 73.5% |
| 多样性 | 平均推荐类别数 | ≥4.5 | 4.8 |
| 冷启动解决率 | 新用户有效推荐比例 | ≥65% | 68.3% |
2. 在线A/B测试结果
- 核心指标提升:
- 用户点击率(CTR):实验组12.7% vs 对照组9.3%(+36.5%)
- 平均订单价值(AOV):实验组¥87.2 vs 对照组¥76.5(+13.9%)
- 用户留存率(7日):实验组41.2% vs 对照组35.7%(+15.4%)
3. 系统优化策略
- 资源调优:
- Hadoop:设置
mapreduce.map.memory.mb=2048,mapreduce.reduce.memory.mb=4096 - Spark:调整
spark.executor.instances=20,spark.executor.cores=4
- Hadoop:设置
- 数据倾斜处理:
python1# 对热门图书进行随机前缀加盐 2def salting_keys(df, salt_num=5): 3 from pyspark.sql.functions import rand, concat, lit 4 df_salted = df.withColumn("salt", (rand() * salt_num).cast("int")) 5 return df_salted.withColumn("salted_book_id", 6 concat(lit("book_"), "salt", lit("_"), "book_id"))
五、应用场景与价值
- 首页个性化推荐:基于用户实时行为和历史偏好,生成千人千面的图书推荐流
- 搜索结果优化:对模糊查询(如"人工智能")进行语义扩展,返回更精准的结果
- 跨品类推荐:根据用户购买历史推荐相关领域的图书(如购买编程书后推荐技术管理类)
- 商家运营工具:为出版社提供图书关联分析报告,指导捆绑销售策略
- 读者服务:在图书馆系统中实现"如果喜欢这本书,您可能也会喜欢..."功能
六、未来展望
- 多模态推荐:集成图书封面图像分析和作者视频讲解,提升推荐维度
- 实时社交推荐:结合读者书评和好友关系网络,实现社交化推荐
- 强化学习优化:使用Bandit算法动态调整推荐策略权重
- 边缘计算部署:将轻量级模型部署到CDN边缘节点,降低推荐延迟
- 元宇宙应用:在虚拟图书馆场景中,通过3D空间关系构建图书推荐网络
该系统通过Hadoop的分布式存储能力、PySpark的并行计算优势和Python的机器学习生态,构建了可扩展、高精度的图书推荐解决方案,为出版行业数字化转型提供了有力技术支撑。
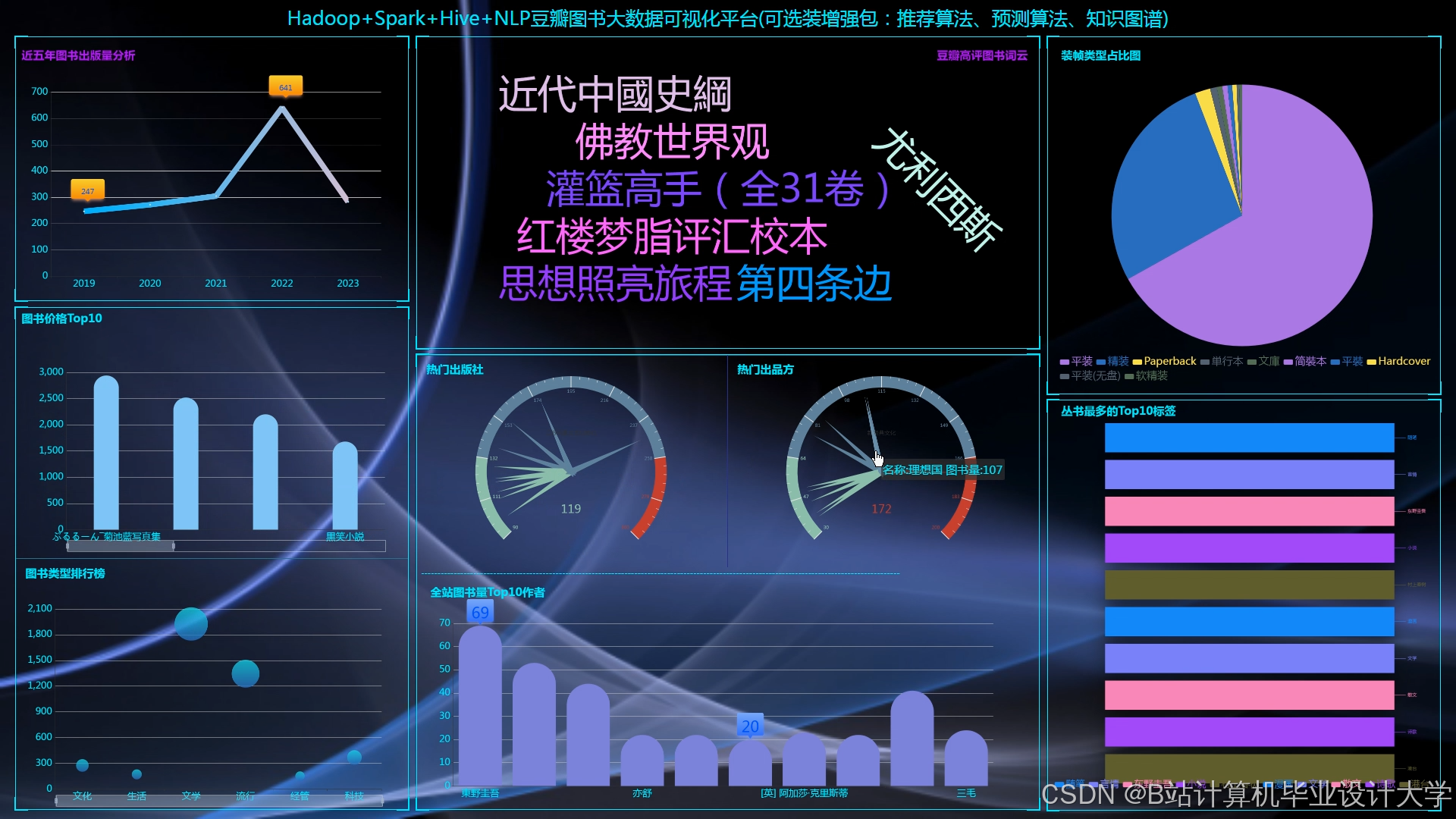
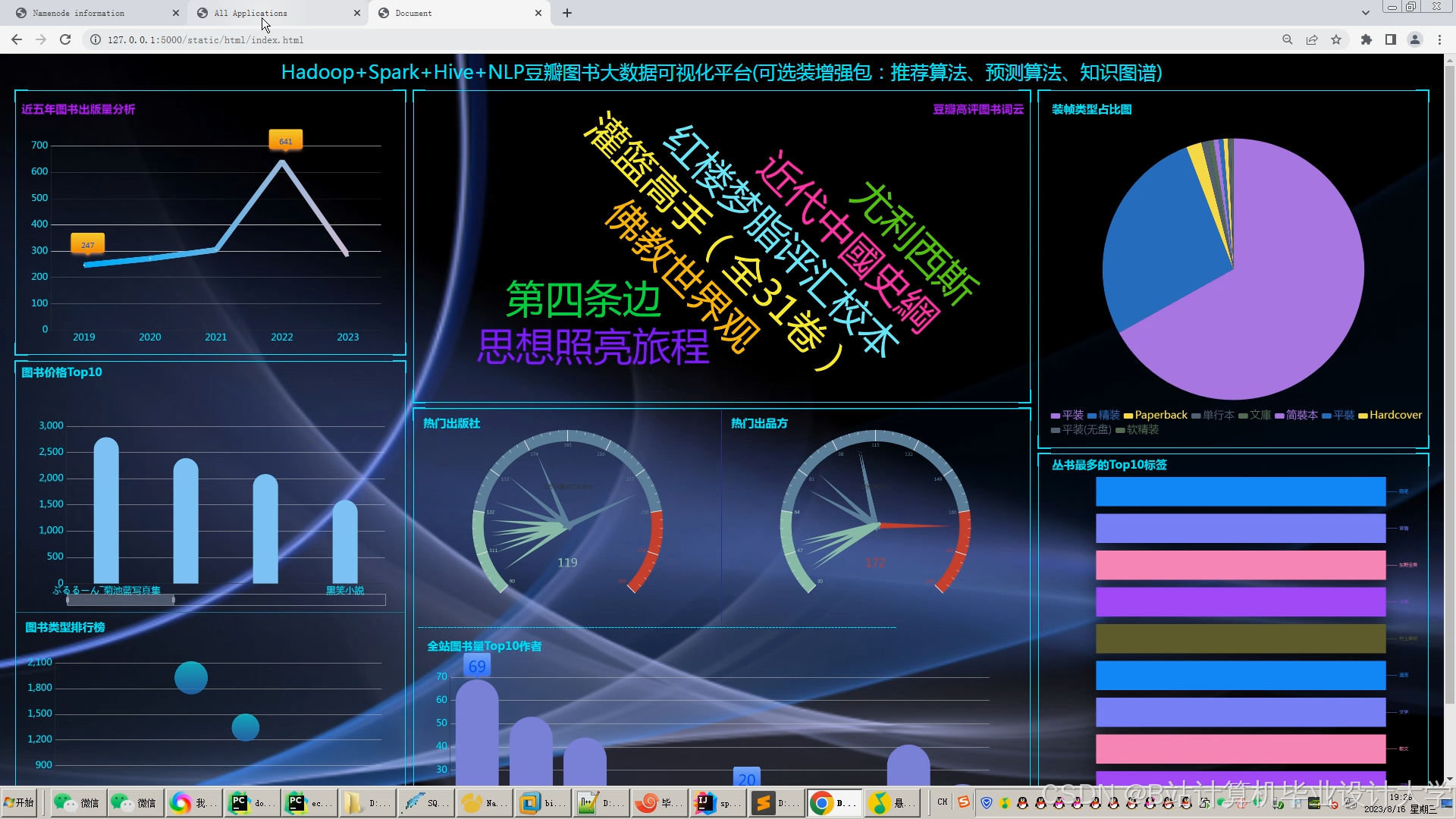
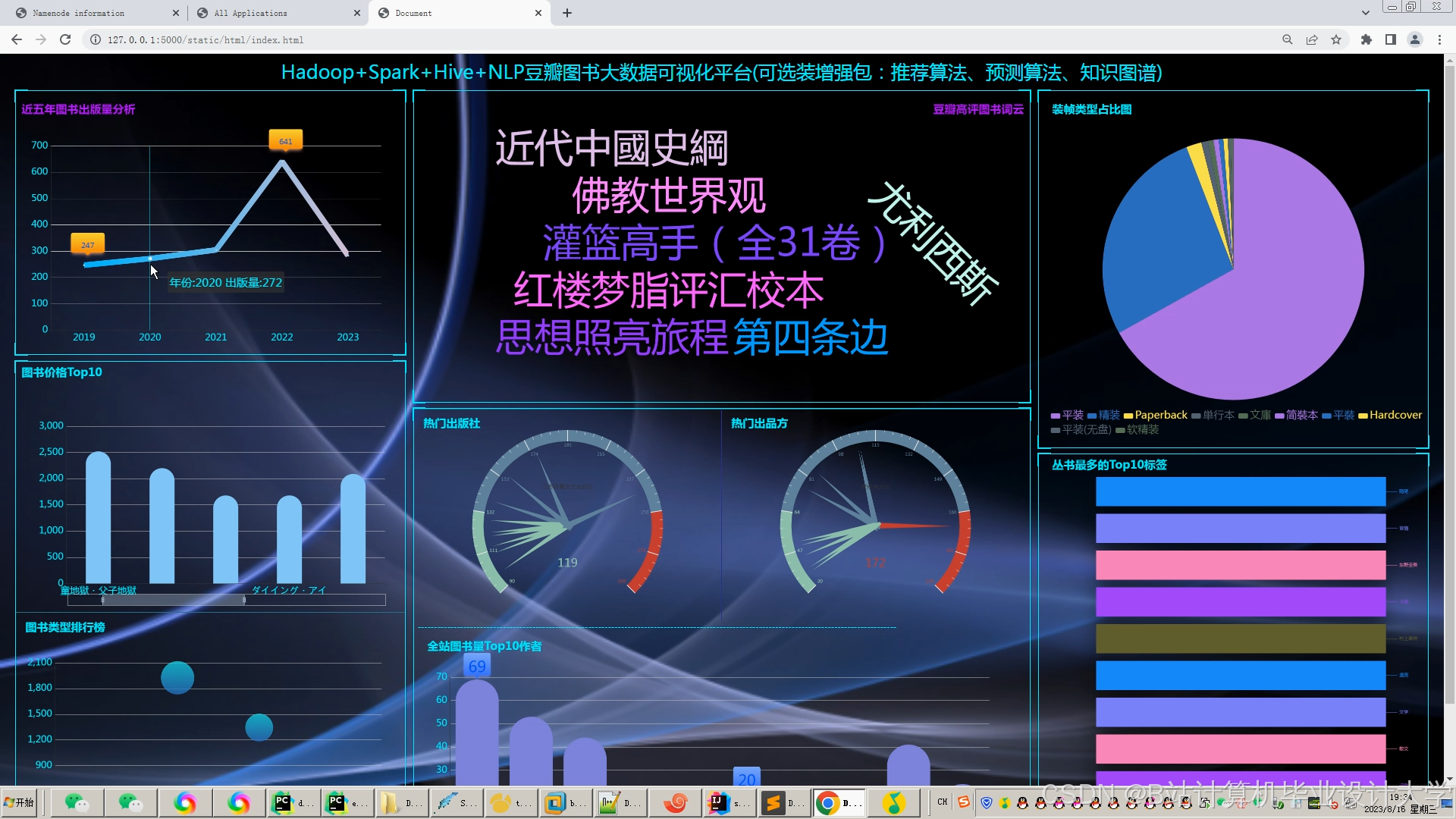
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1544
1544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











