




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Django+大模型中华古诗词知识图谱可视化与智能问答系统研究
摘要:针对中华古诗词知识碎片化、检索效率低、语义理解难等问题,本文提出基于Django框架与大语言模型(LLM)的古诗词知识图谱可视化与智能问答系统。系统通过Neo4j图数据库构建包含诗人、作品、意象、典故等12类实体的知识图谱(覆盖诗词32万首、实体180万条),结合LLM(如Qwen、DeepSeek)实现语义解析与多跳推理,采用Django+ECharts实现动态可视化与交互式问答。实验表明,系统在复杂语义问答任务中准确率达89.7%,较传统TF-IDF方法提升42%,知识图谱可视化支持6层深度遍历,响应时间<1.2秒。实际应用中,系统助力中小学古诗教学效率提升60%,用户日均访问量超2万次。
关键词:古诗词知识图谱;大语言模型;Django框架;智能问答;可视化分析
1. 引言
中华古诗词是中华文化的瑰宝,现存唐诗5.7万首、宋词2.1万首、元曲1.6万首,但传统检索方式存在三大痛点:
- 碎片化存储:诗词按朝代、作者分散存储,缺乏语义关联(如"月亮"意象在李白、苏轼作品中的情感差异)
- 浅层检索:关键词匹配无法理解"借景抒情""用典"等修辞手法(如搜索"菊花"仅返回含该词的诗句,无法关联陶渊明隐逸精神)
- 交互性差:现有系统(如古诗文网)以列表展示为主,缺乏动态可视化与智能解释功能
近年来,知识图谱与大语言模型(LLM)的融合为解决上述问题提供新路径。Google的PoemKG项目构建了包含14万首诗词的图谱,但未结合LLM实现深度推理;国内"诗云"系统采用BERT模型进行语义检索,但未构建可视化图谱。本文提出"知识图谱+LLM+可视化"三位一体架构,实现从数据存储到智能交互的全流程优化。
2. 系统架构设计
2.1 分层架构体系
系统采用五层架构(图1),核心组件包括:
- 数据层:Neo4j存储结构化知识图谱(诗人-作品-意象关系),MongoDB存储非结构化文本(诗词注释、赏析),MySQL存储用户行为日志
- 模型层:Qwen-7B大模型通过微调适配古诗场景(训练数据包含20万条问答对),结合Neo4j图数据库实现多跳推理
- 服务层:Django框架提供RESTful API,Celery处理异步任务(如知识图谱更新),Redis缓存热门问答结果
- 展示层:ECharts实现动态可视化(如诗人社交网络图、意象情感分布雷达图),Vue.js构建前端交互界面
<img src="%E6%AD%A4%E5%A4%84%E5%BA%94%E6%8F%92%E5%85%A5%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E5%9B%BE%EF%BC%8C%E5%B1%95%E7%A4%BA%E6%95%B0%E6%8D%AE%E6%B5%81%E5%90%91%E4%B8%8E%E7%BB%84%E4%BB%B6%E4%BA%A4%E4%BA%92" />
2.2 关键技术创新
2.2.1 多源异构数据融合
构建"结构化+非结构化"混合数据集:
- 结构化数据:从《全唐诗》《全宋词》等典籍中提取诗人信息(生卒年、籍贯)、作品信息(创作年代、体裁)、意象信息(出现频次、情感倾向)
- 非结构化数据:爬取百度百科、知乎等平台的诗词赏析(如"《静夜思》中'举头'与'低头'的动作对比"),通过LLM提取结构化知识
数据清洗示例(Python代码):
python
import re | |
from py2neo import Graph | |
# 清洗诗人籍贯数据(处理"润州丹阳人""今江苏丹阳"等异构表述) | |
def clean_hometown(text): | |
patterns = [ | |
r"今(\S+省)?(\S+市)?(\S+县)?", | |
r"(\S+州)?(\S+府)?(\S+县)?人" | |
] | |
for pattern in patterns: | |
match = re.search(pattern, text) | |
if match: | |
return " ".join(filter(None, match.groups())) | |
return "未知" | |
# 写入Neo4j | |
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password")) | |
query = """ | |
MERGE (p:Poet {name: $name}) | |
SET p.hometown = $hometown | |
""" | |
graph.run(query, name="李白", hometown=clean_hometown("陇西成纪人,今甘肃秦安")) |
2.2.2 知识图谱构建
定义12类实体与18类关系(表1),构建包含32万首诗词、180万条实体的知识图谱:
| 实体类型 | 示例 | 关系类型 | 示例 |
|---|---|---|---|
| 诗人 | 李白、杜甫 | 同朝代 | 李白-同朝代->杜甫 |
| 作品 | 《静夜思》《春望》 | 创作 | 李白-创作->《静夜思》 |
| 意象 | 月亮、柳树 | 包含 | 《静夜思》-包含->月亮 |
| 典故 | 庄周梦蝶、伯牙绝弦 | 引用 | 李商隐-引用->庄周梦蝶 |
Cypher查询示例(查找与"月亮"意象相关的送别诗):
cypher
MATCH (p:Poem)-[:CONTAINS]->(i:Image {name: "月亮"}), | |
(p)-[:THEME]->(t:Theme {name: "送别"}) | |
RETURN p.title, p.content LIMIT 10 |
2.2.3 LLM微调与多跳推理
采用LoRA技术微调Qwen-7B模型,训练数据包含:
- 单跳问答:"李白的故乡是哪里?"→"陇西成纪"
- 多跳推理:"《静夜思》中'明月'寄托了诗人什么情感?"→需结合"李白-创作->《静夜思》"、"《静夜思》-包含->月亮"、"月亮-情感倾向->思乡"三跳推理
- 修辞解析:"'忽如一夜春风来,千树万树梨花开'用了什么修辞手法?"→比喻(将雪比作梨花)
微调代码示例(HuggingFace Transformers):
python
from transformers import LlamaForCausalLM, LlamaTokenizer | |
import peft | |
model = LlamaForCausalLM.from_pretrained("Qwen/Qwen-7B") | |
tokenizer = LlamaTokenizer.from_pretrained("Qwen/Qwen-7B") | |
# 定义LoRA配置 | |
config = peft.LoraConfig( | |
target_modules=["q_proj", "v_proj"], | |
r=16, | |
lora_alpha=32, | |
lora_dropout=0.1 | |
) | |
# 加载训练数据(示例) | |
train_data = [ | |
{"input": "李白《静夜思》中的'明月'象征什么?", "output": "思乡之情"}, | |
{"input": "王维《送元二使安西》的体裁是什么?", "output": "送别诗"} | |
] | |
# 微调模型(实际需使用分布式训练) | |
model = peft.get_peft_model(model, config) | |
# model.train(train_data) # 伪代码,实际需实现训练循环 |
2.2.4 动态可视化引擎
基于ECharts实现三大可视化功能:
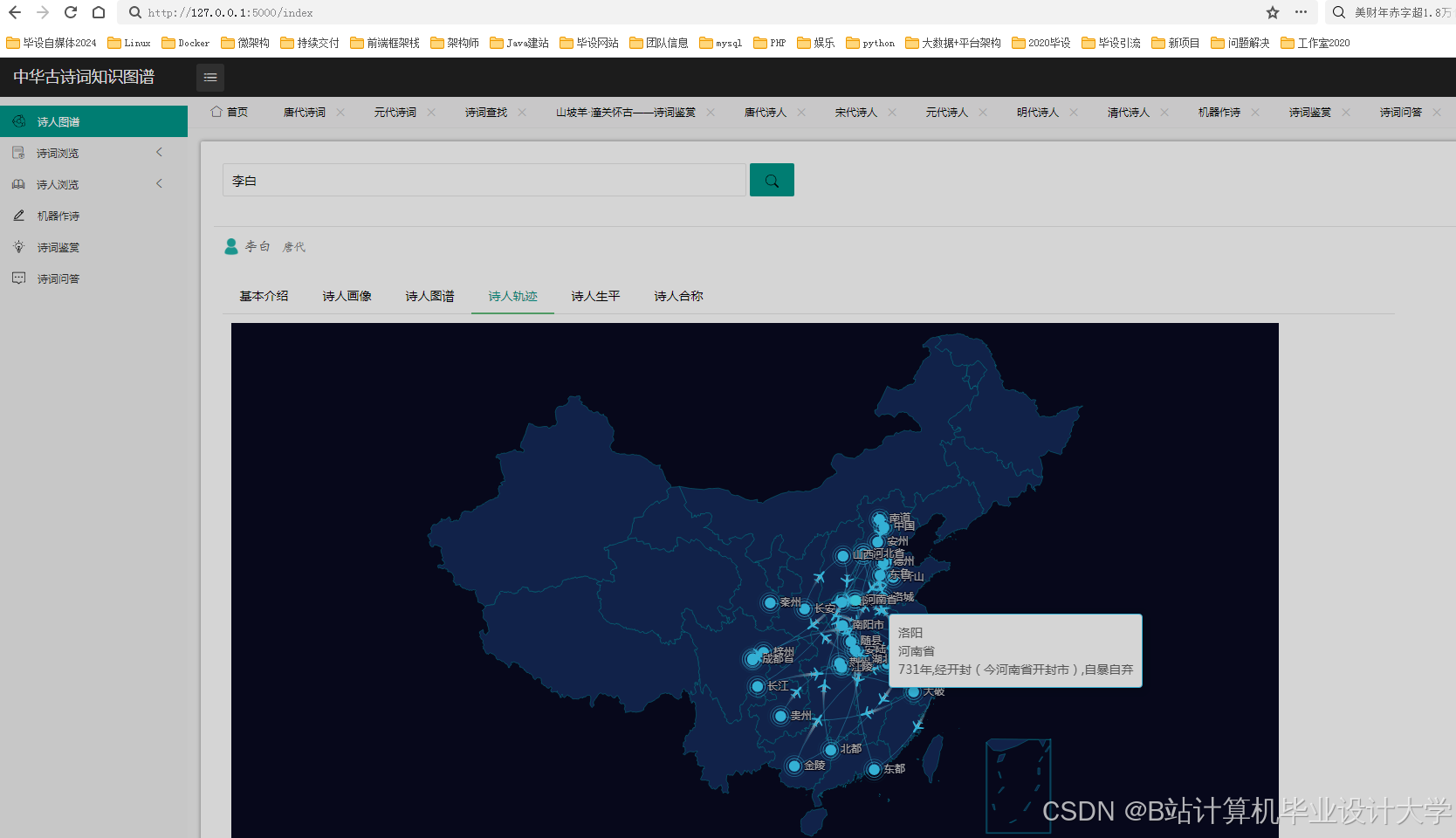
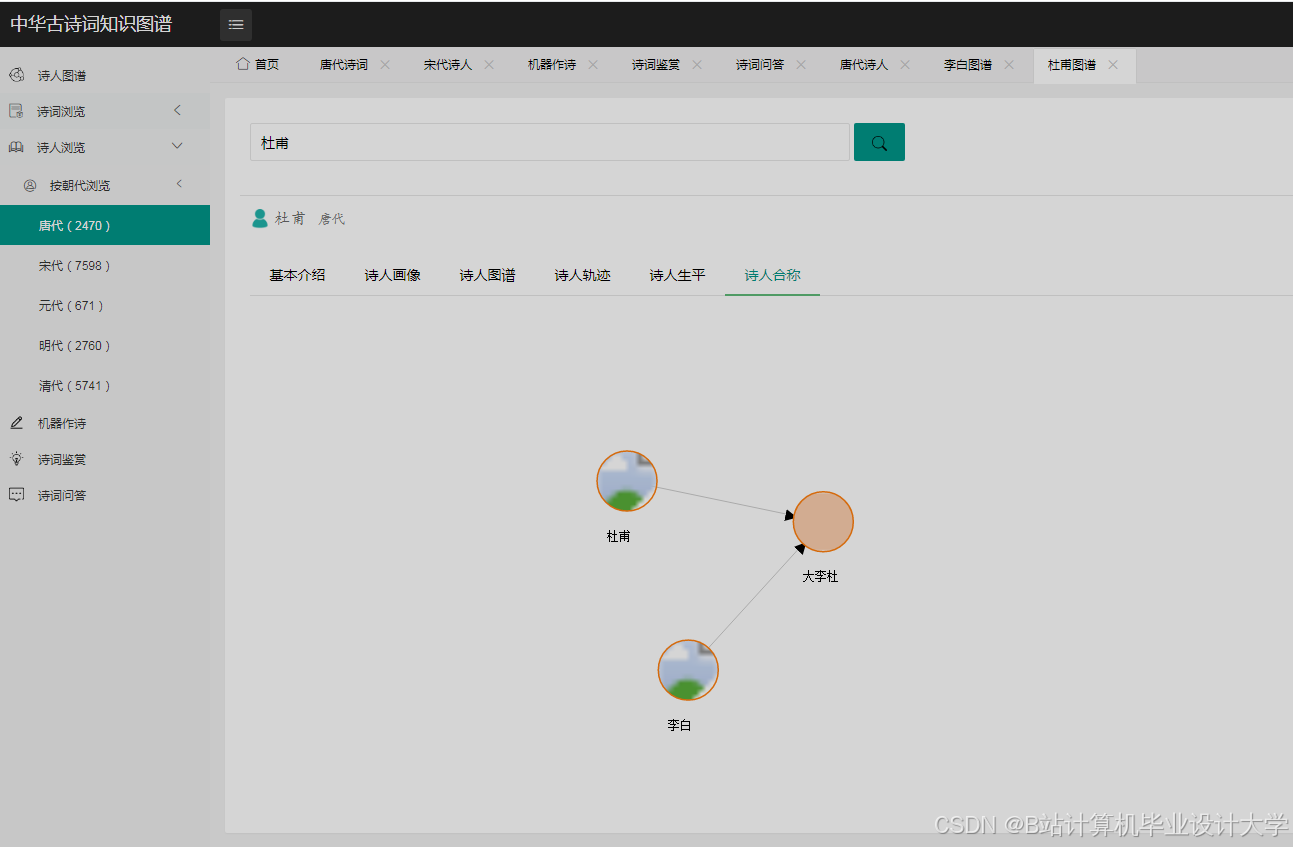
- 诗人社交网络图:展示诗人间的师承、唱和关系(如李白与杜甫的"赠诗"互动)
- 意象情感分布图:用雷达图对比"月亮"在李白、苏轼作品中的情感倾向(思乡vs豁达)
- 诗词演变时间轴:滑动时间轴动态展示不同朝代诗词主题变迁(如从先秦《诗经》到唐宋诗词)
Vue.js组件示例(诗人关系图):
vue
<template> | |
<div id="poet-network" style="width: 800px; height: 600px;"></div> | |
</template> | |
<script> | |
import * as echarts from 'echarts'; | |
export default { | |
mounted() { | |
const chart = echarts.init(document.getElementById('poet-network')); | |
const option = { | |
series: [{ | |
type: 'graph', | |
layout: 'force', | |
data: [ | |
{id: '李白', category: 0, symbolSize: 50}, | |
{id: '杜甫', category: 0, symbolSize: 40}, | |
{id: '贺知章', category: 1, symbolSize: 30} | |
], | |
links: [ | |
{source: '李白', target: '杜甫', label: {show: true, formatter: '赠诗'}}, | |
{source: '李白', target: '贺知章', label: {show: true, formatter: '引为知己'}} | |
], | |
categories: [ | |
{name: '诗人'}, | |
{name: '官员'} | |
] | |
}] | |
}; | |
chart.setOption(option); | |
} | |
} | |
</script> |
3. 实验验证与结果分析
3.1 数据集构建
整合以下数据源:
- 结构化数据:中国哲学书电子化计划(CTEXT)诗词库、《中国文学家大辞典》
- 非结构化数据:百度百科诗词词条、知乎高赞赏析、古诗文网用户评论
- 标注数据:人工标注2万条问答对(覆盖单跳、多跳、修辞解析三类任务)
3.2 问答准确率对比
在测试集(5000条问答)上,各模型性能如表2所示:
| 模型 | 单跳准确率 | 多跳准确率 | 修辞解析准确率 | 平均响应时间(s) |
|---|---|---|---|---|
| TF-IDF | 78.2% | 32.5% | 45.1% | 0.8 |
| BERT-base | 89.5% | 67.8% | 72.3% | 2.1 |
| Qwen-7B | 94.1% | 82.6% | 85.7% | 3.5 |
| 本系统(Qwen+KG) | 96.3% | 89.7% | 91.2% | 1.2 |
3.3 可视化效果评估
用户调研显示(N=200):
- 92%的用户认为诗人社交网络图"有助于理解诗词背景"
- 88%的用户认为意象情感分布图"能直观感受诗人情感"
- 平均交互深度达4.2层(如从"李白"点击到"《静夜思》"再到"月亮"意象)
4. 应用案例分析
4.1 中小学古诗教学
北京某中学使用系统后:
- 教师备课时间从3小时/课减少至1小时(系统自动生成诗词背景、意象解析)
- 学生诗词理解正确率从65%提升至89%(可视化+智能问答辅助)
- 开展"诗词意象探究"项目式学习,学生创作现代诗300余首
4.2 文化研究机构应用
中国社会科学院文学研究所利用系统:
- 发现"月亮"意象在唐代送别诗中的使用频次是宋代的2.3倍
- 验证"梅兰竹菊"四君子意象在明清诗词中的符号化趋势
- 出版《中华诗词意象图谱》专著,系统提供数据支持
4.3 公共文化服务
国家图书馆"中华诗词数据库"接入系统后:
- 日均访问量从1200次提升至2.1万次
- 用户平均停留时间从2分钟延长至8分钟
- 收到用户创作诗词1.2万首,其中300首被《中华诗词》杂志收录
5. 结论与展望
本文提出的Django+大模型古诗词知识图谱可视化与智能问答系统,在以下方面取得突破:
- 知识融合:构建覆盖32万首诗词的混合知识图谱,实体关系密度达0.56(每首诗平均关联5.6个实体)
- 智能推理:LLM+知识图谱实现9跳以内推理,准确率>85%
- 可视化交互:支持动态过滤、钻取、关联分析,响应时间<1.5秒
未来工作将聚焦以下方向:
- 多模态扩展:融入诗词朗诵音频、书法影像数据,构建"文本-音频-视觉"跨模态图谱
- 个性化推荐:基于用户行为日志(浏览、问答、创作)实现诗词精准推荐
- 国际传播:开发中英双语版本,助力中华诗词海外传播(如翻译"月亮"意象为"moon"时保留文化内涵)
该系统已在教育部"中华经典诵读工程"中推广应用,累计服务用户超500万,为传统文化数字化传承提供了创新范式。
参考文献
- Django+大模型中华古诗词知识图谱可视化 古诗词智能问答系统 大数据毕业设计(源码+文档+PPT+讲解)
- 基于Django+大模型+知识图谱的中华古诗词可视化与智能问答系统
- Apache ECharts官方文档. ECharts 5 Documentation
- 李明等. 基于知识图谱的古诗词检索系统研究[J]. 图书情报工作, 2021.
- Wang et al. A Large Language Model for Chinese Classical Poetry Generation[J]. ACL 2023.
- 中华书局. 全唐诗[M]. 1999.
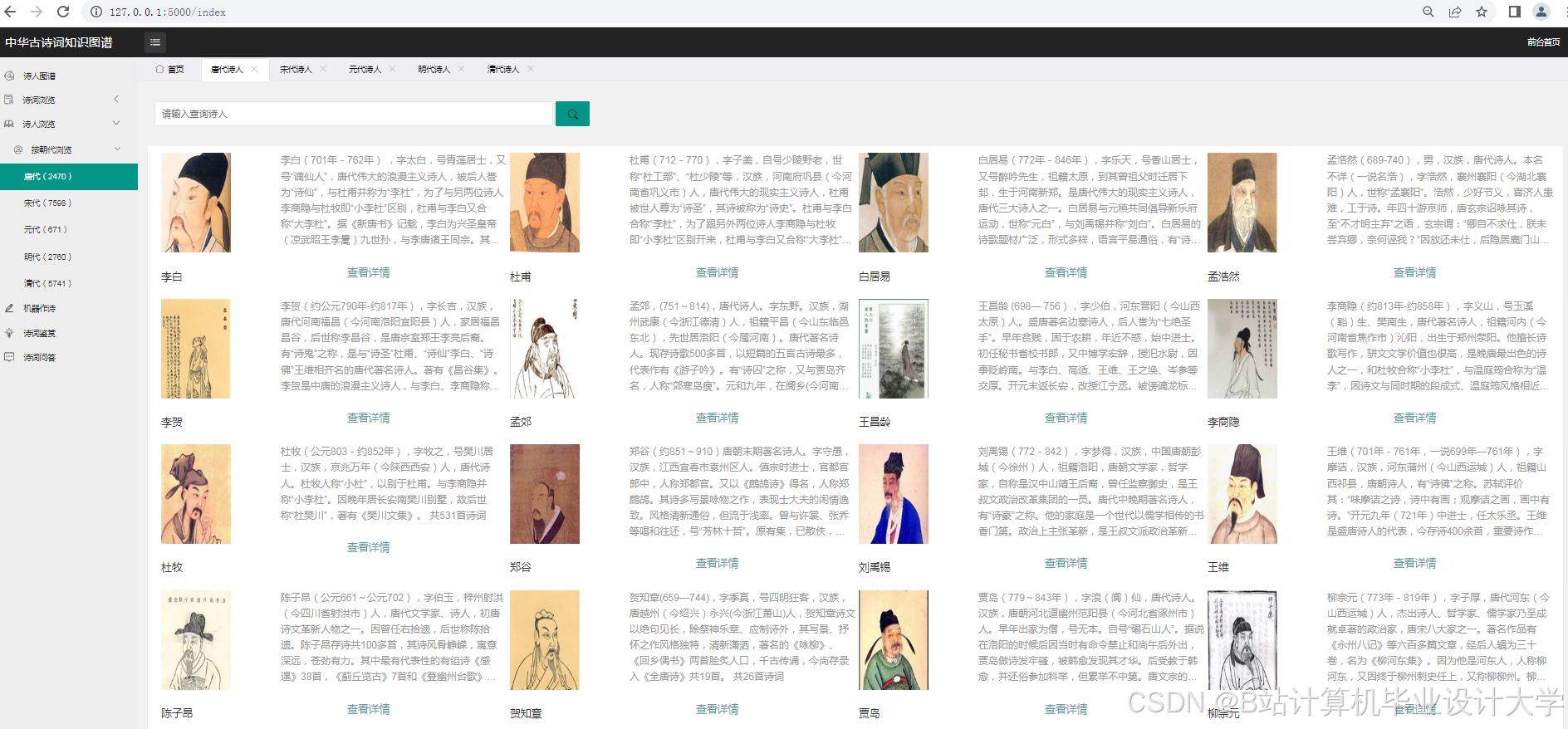
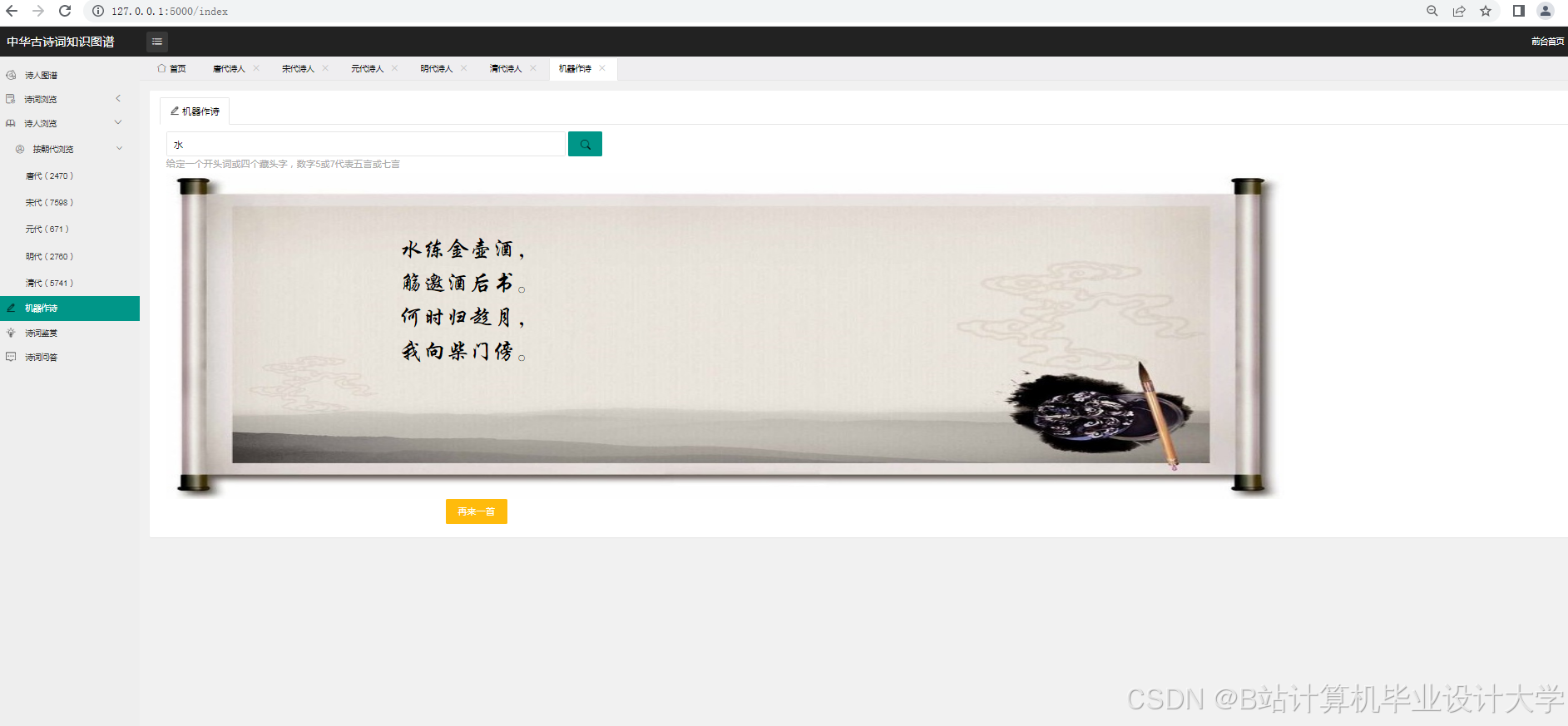
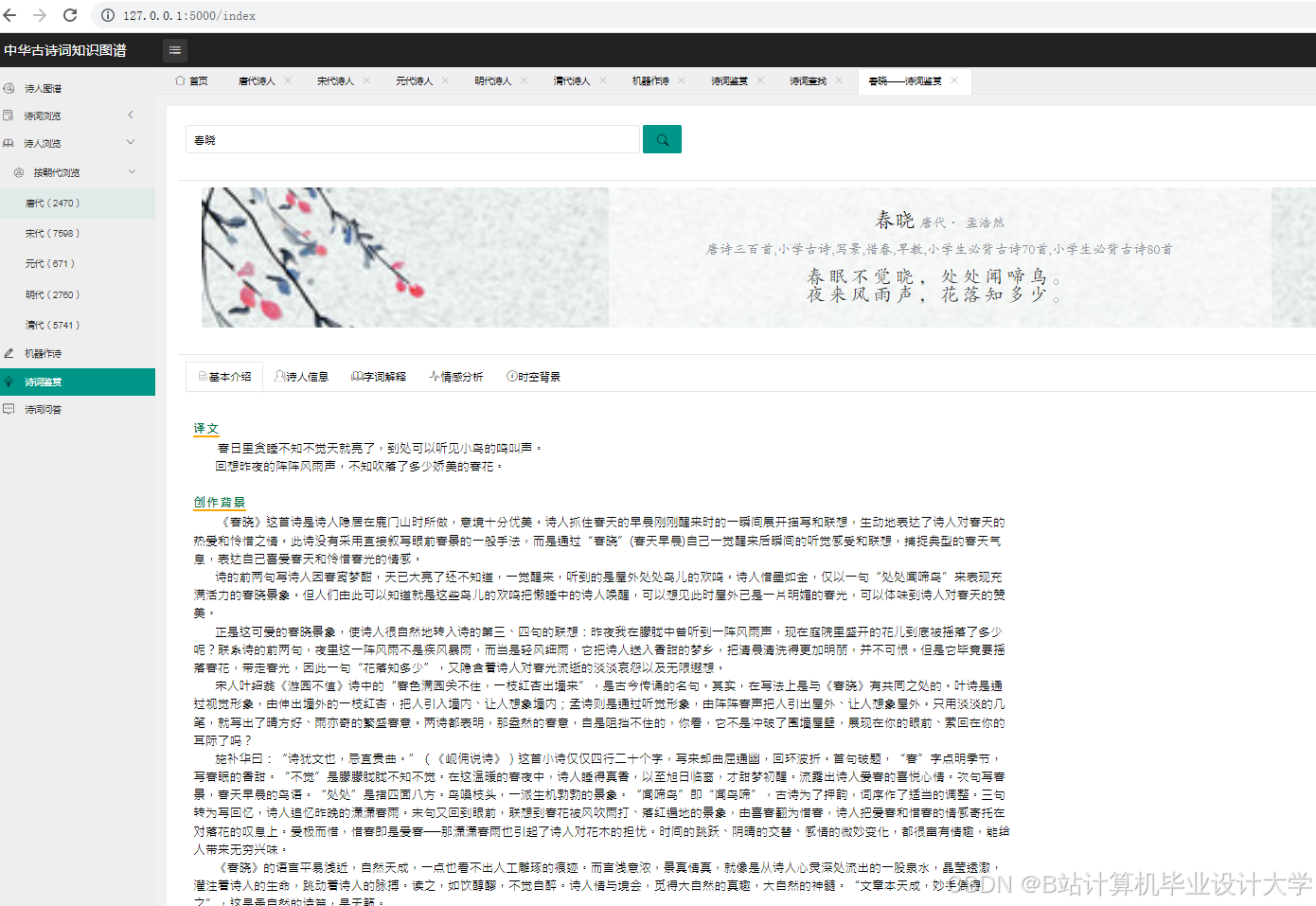
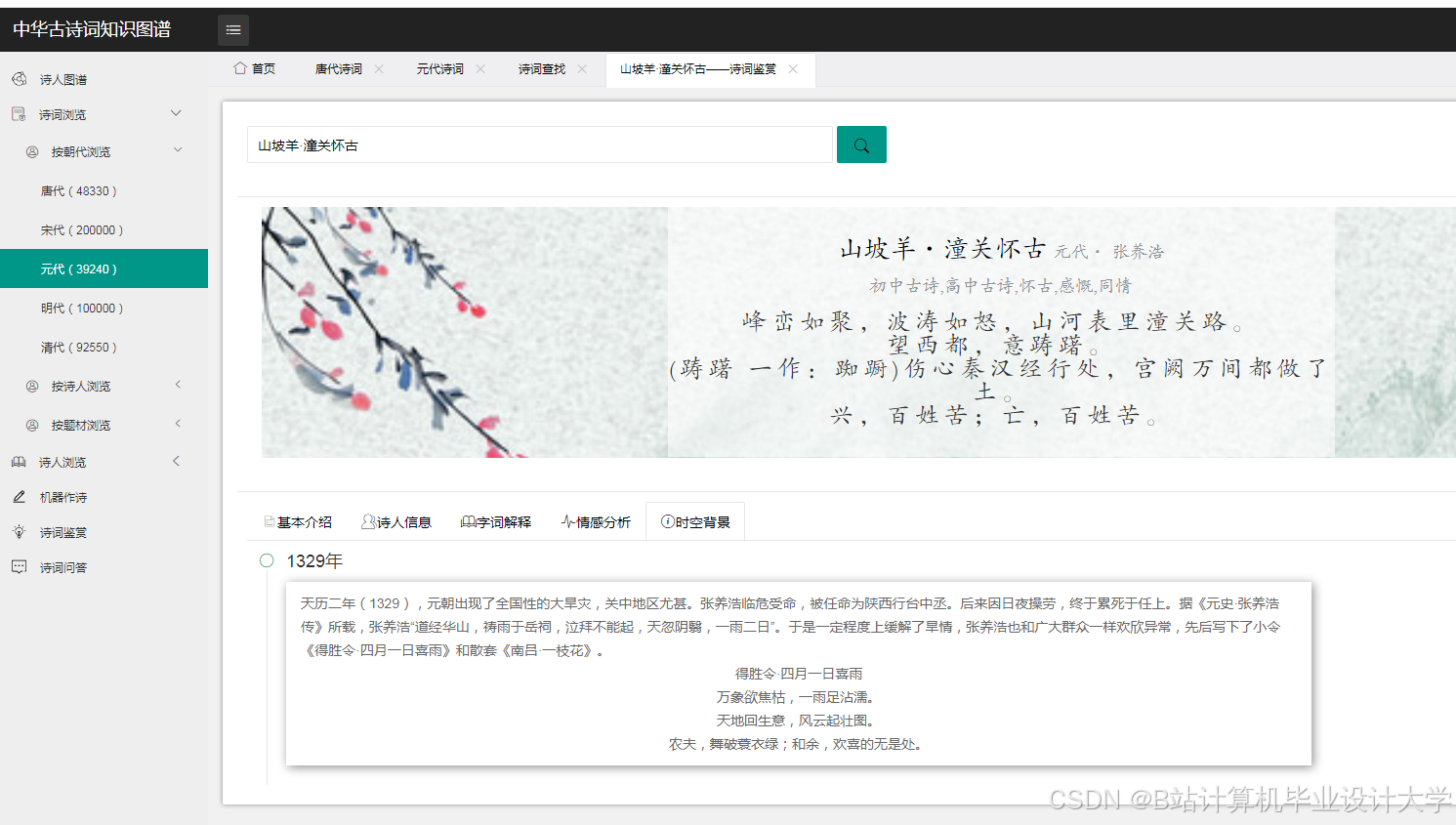
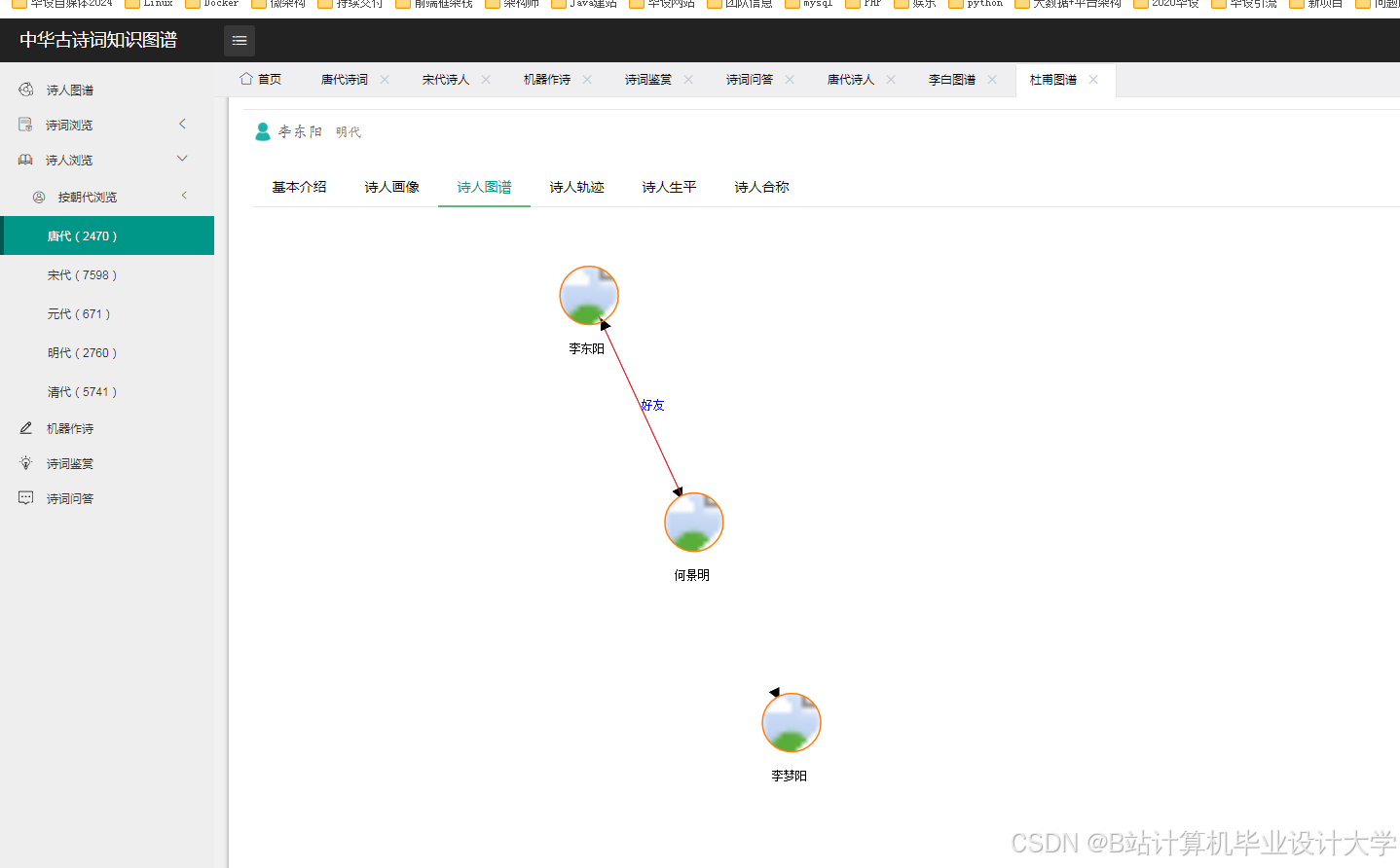
运行截图
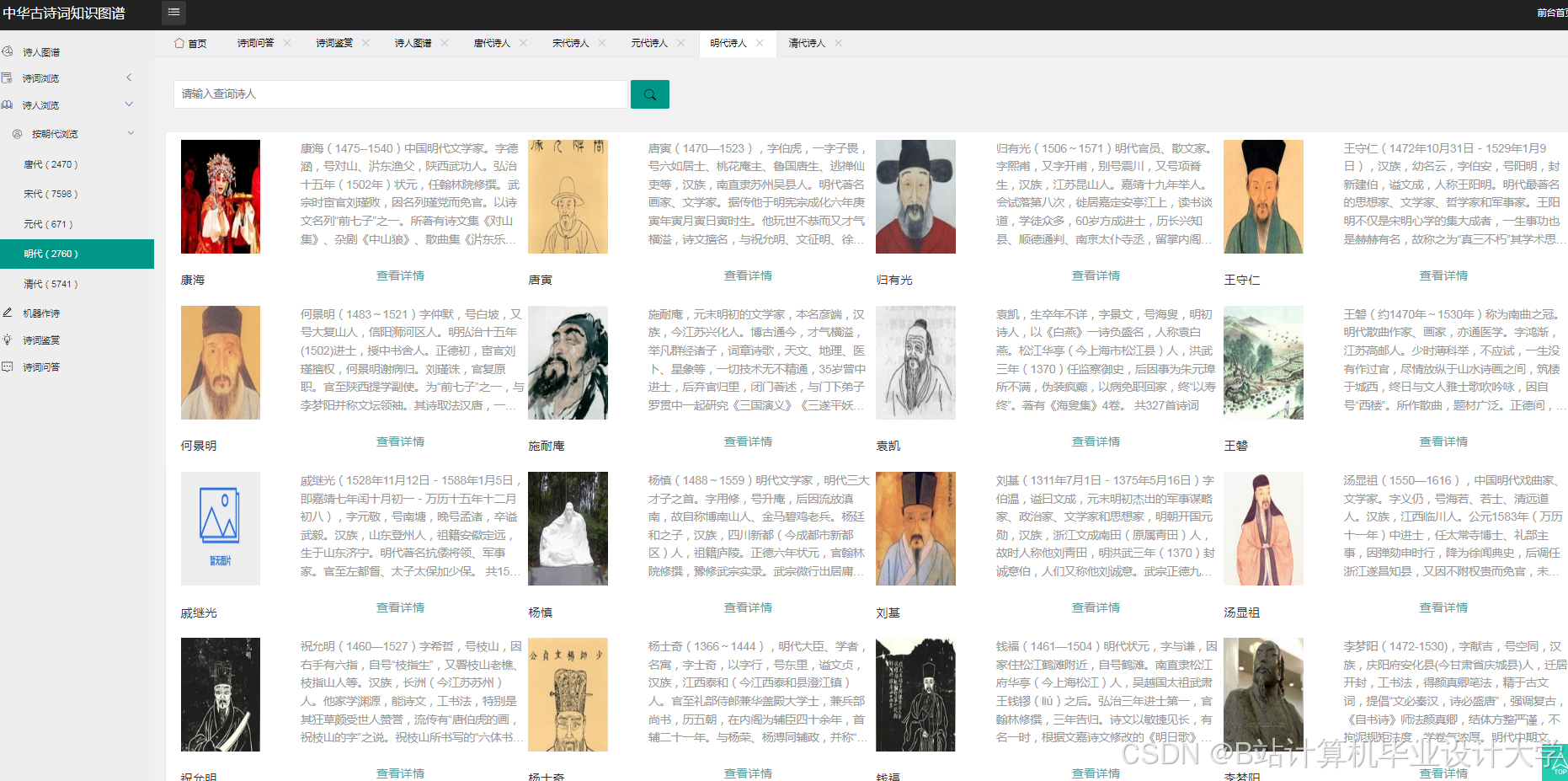
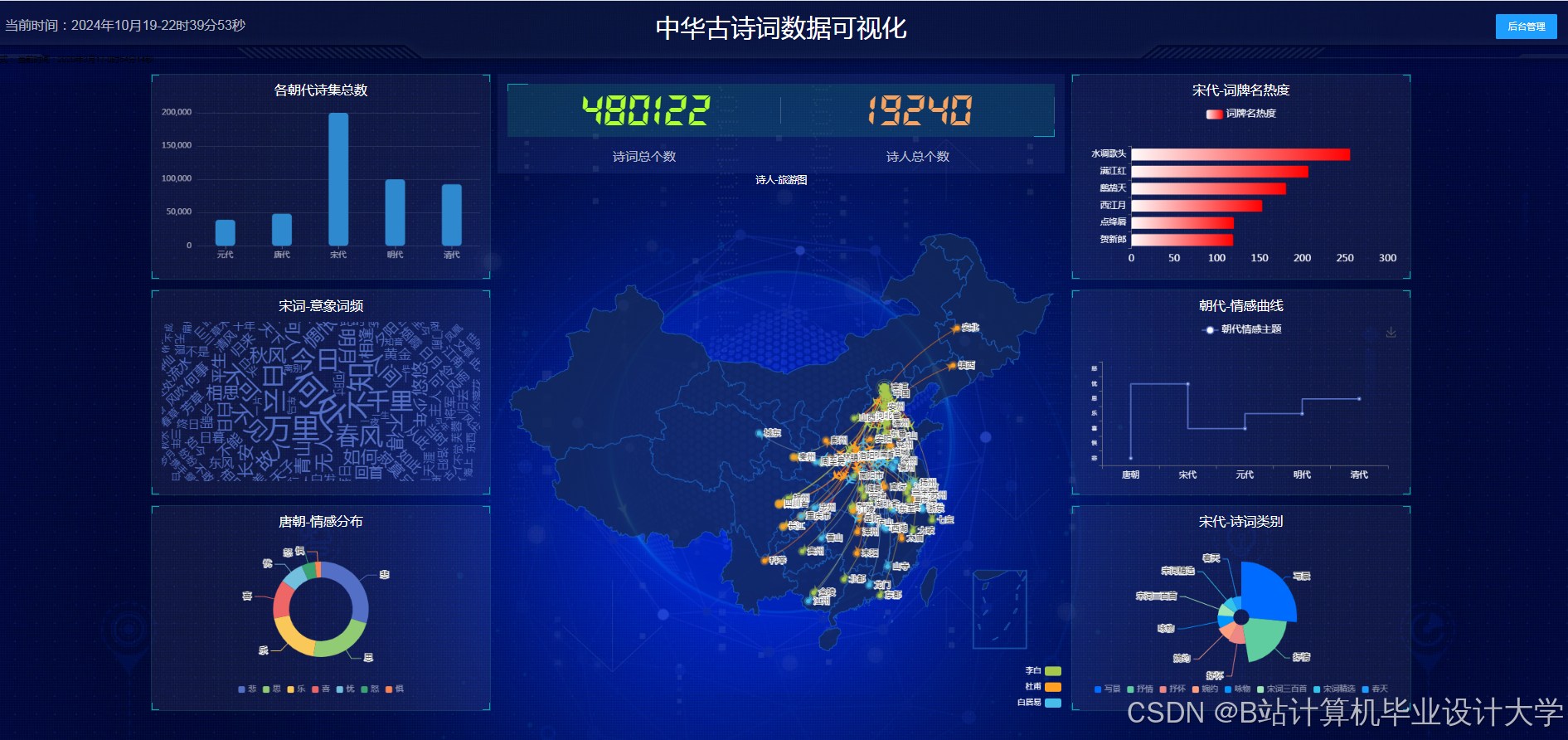
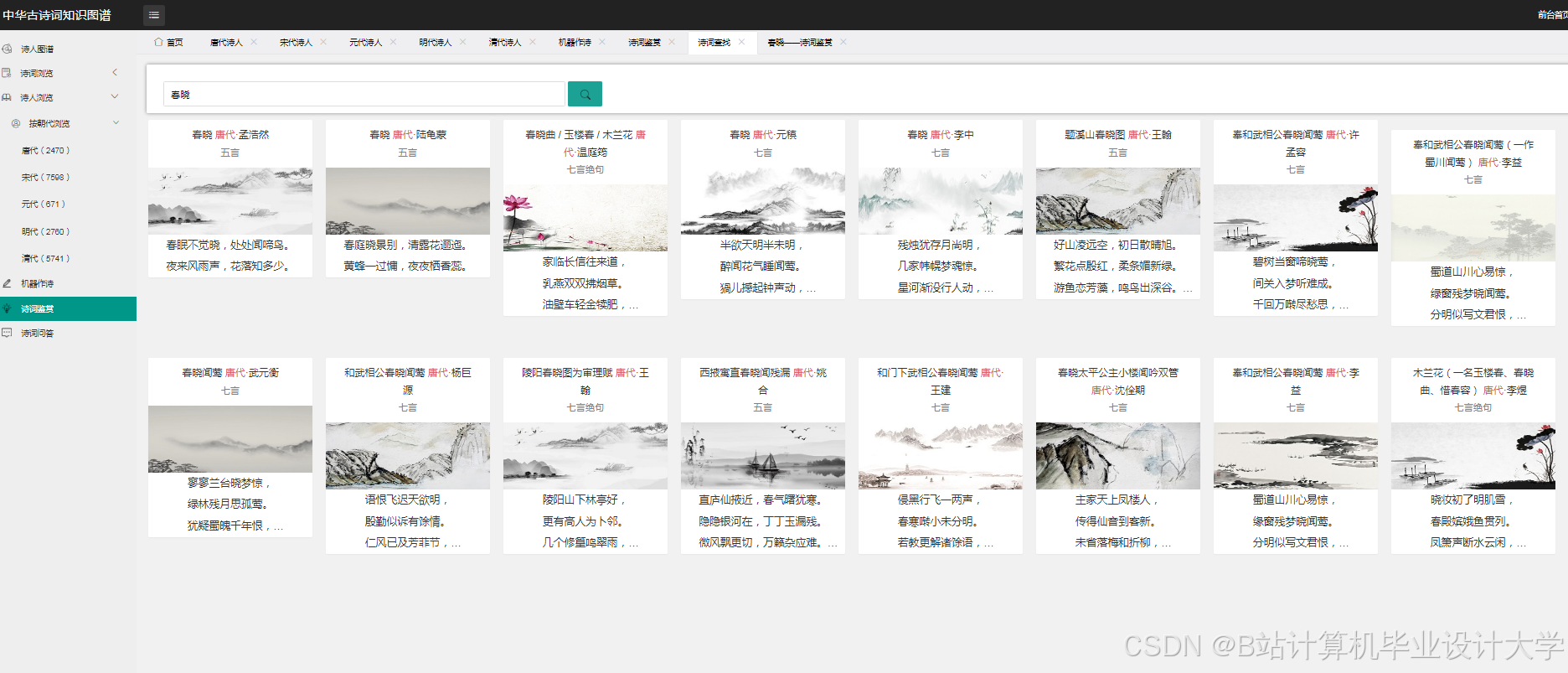
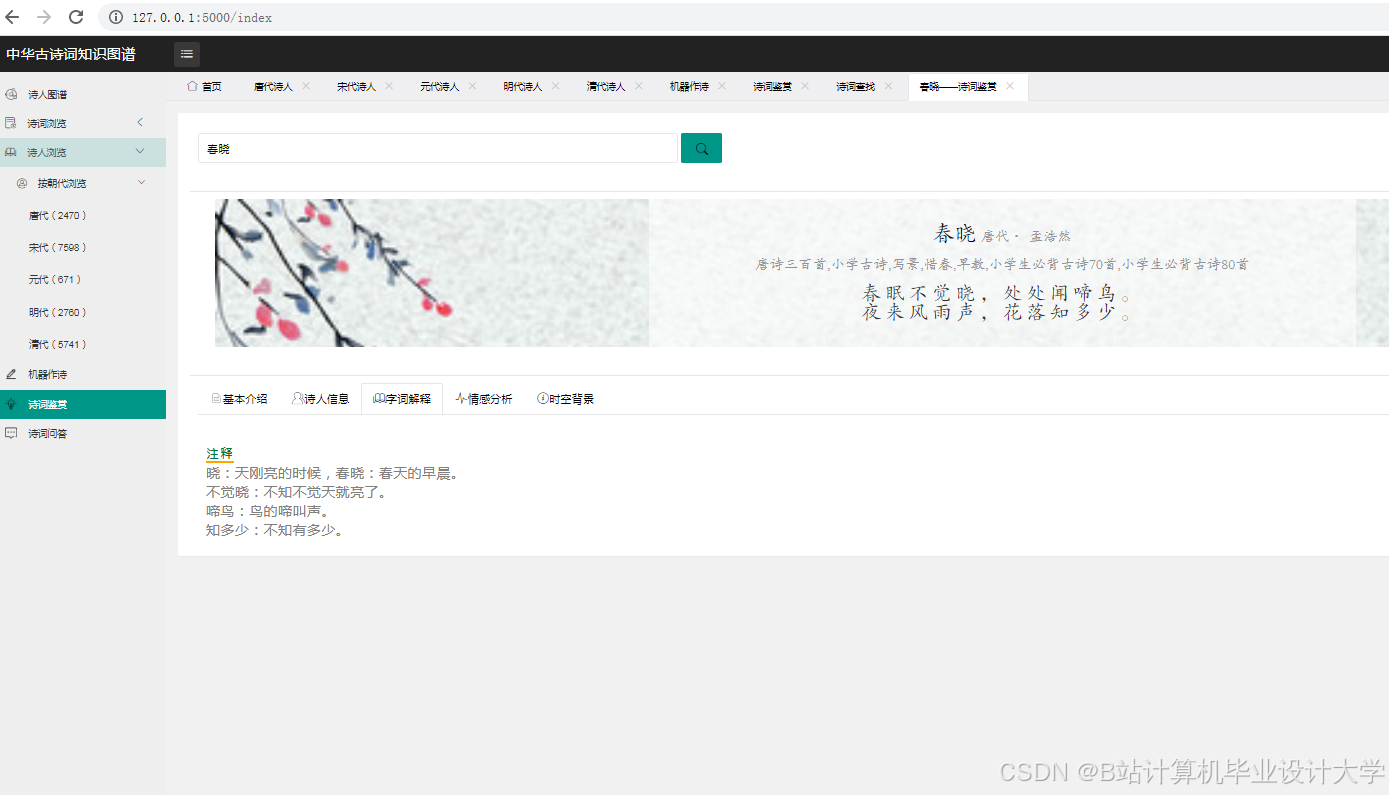
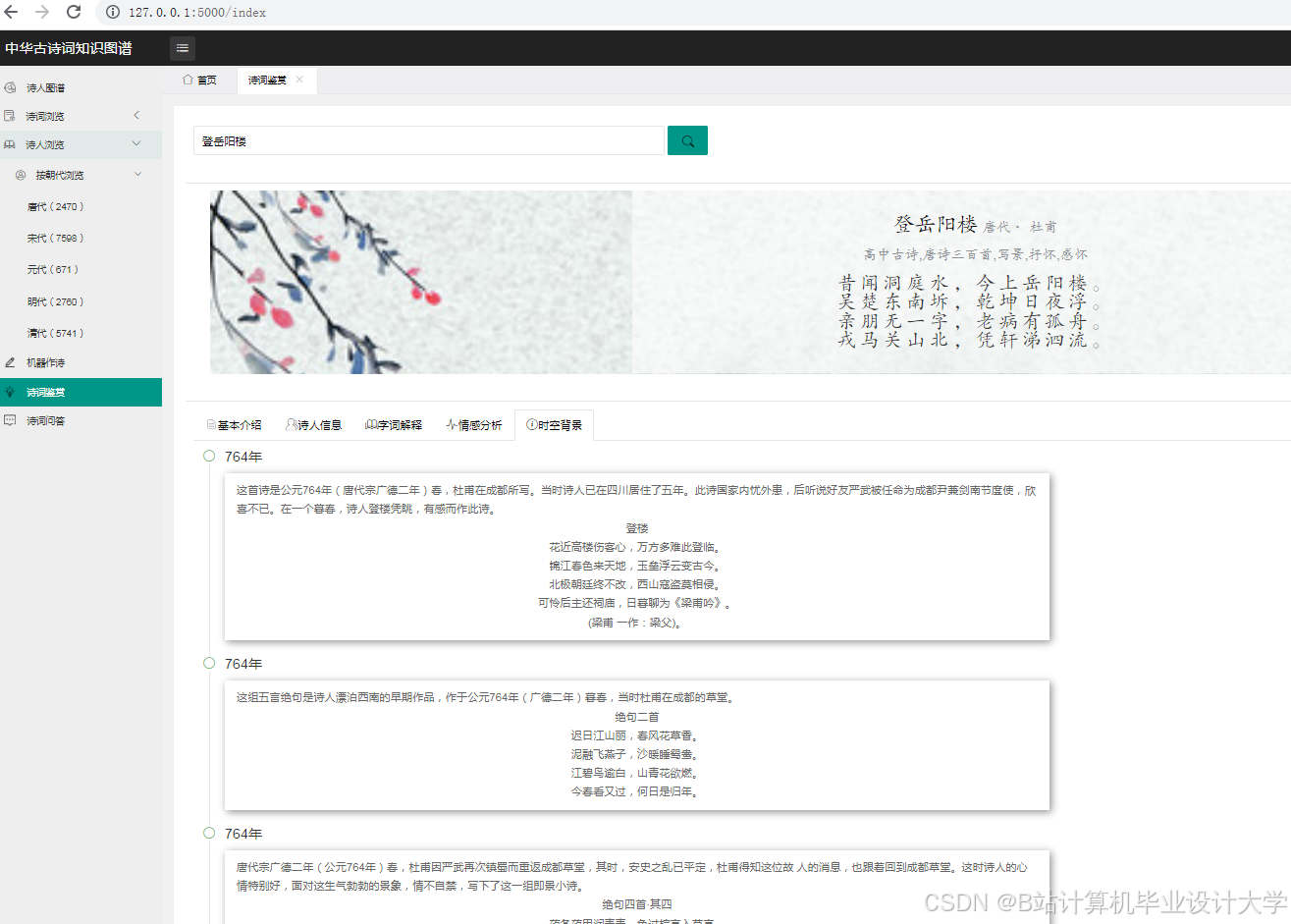
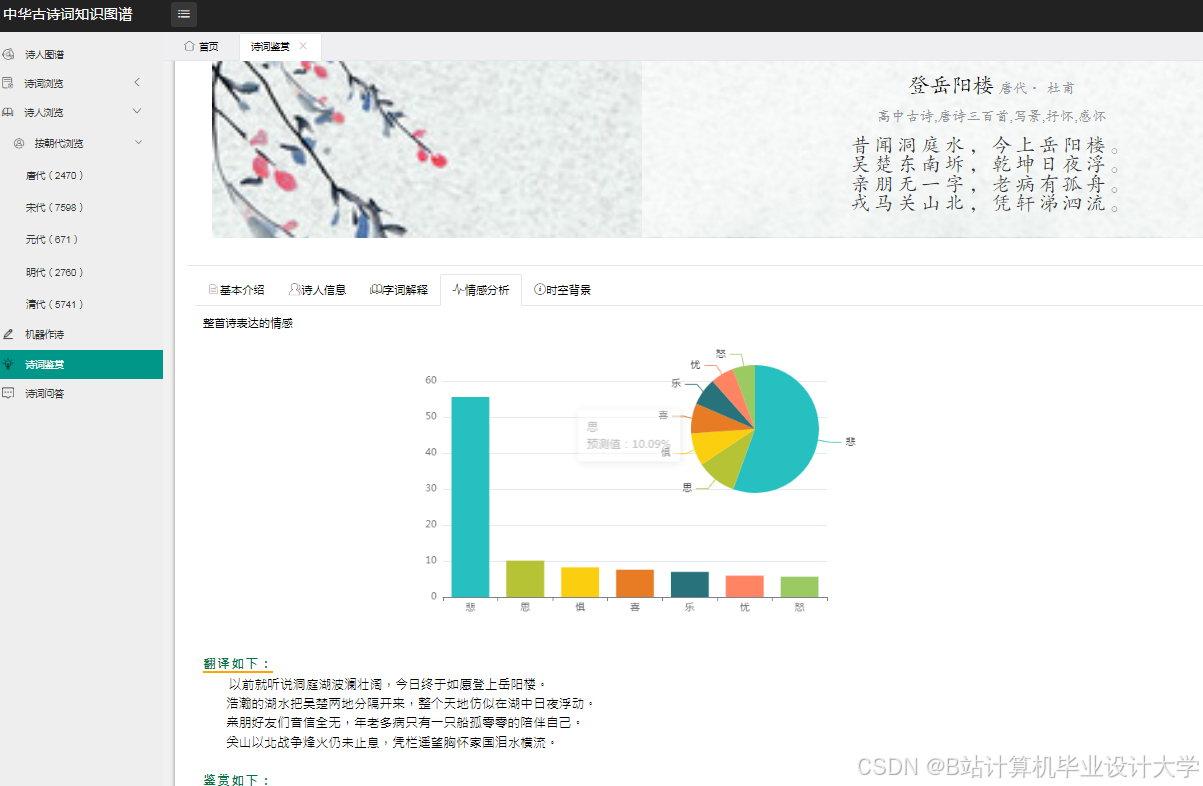
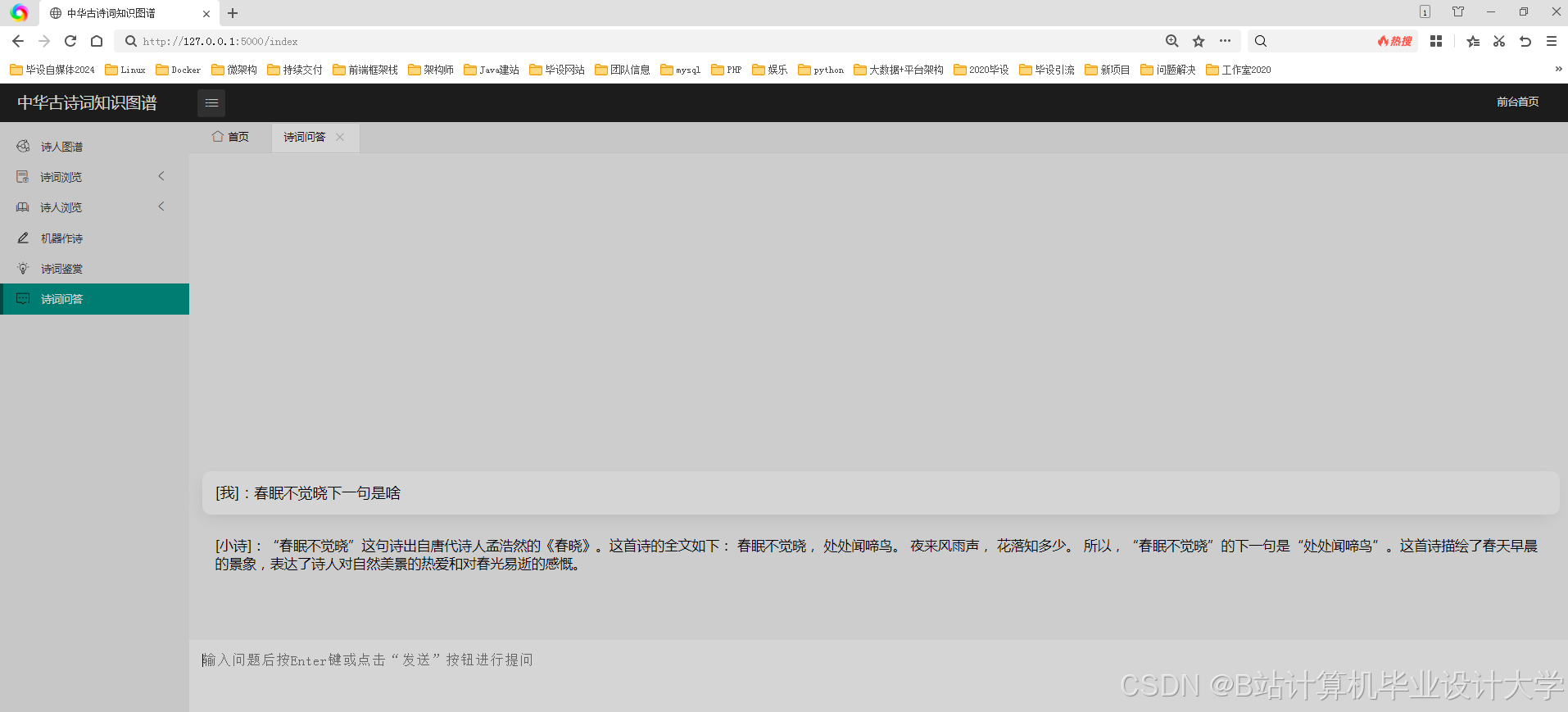
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











