




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python + PySpark + Hadoop 视频推荐系统技术说明
一、系统概述
本视频推荐系统采用Python + PySpark + Hadoop技术栈构建,结合分布式计算与机器学习算法,实现海量视频数据的个性化推荐。系统具备以下核心能力:
- 高并发处理:支持百万级用户实时推荐请求
- 弹性扩展:基于Hadoop集群动态扩展计算资源
- 多算法融合:集成协同过滤、内容推荐和混合策略
- 全流程管理:覆盖数据采集、存储、计算到服务接口的全链路
二、技术架构详解
1. 分层架构设计
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ | |
│ 数据层 │ ←→ │ 计算层 │ ←→ │ 服务层 │ | |
└─────────────┘ └─────────────┘ └─────────────┘ | |
↑ ↑ ↑ | |
│ │ │ | |
┌─────────────────────────────────────────────┐ | |
│ 基础设施层 │ | |
│ Hadoop HDFS + YARN + ZooKeeper │ | |
└─────────────────────────────────────────────┘ |
2. 组件职责划分
| 组件 | 技术选型 | 核心功能 |
|---|---|---|
| 数据存储 | HDFS + HBase | 分布式存储视频元数据和用户行为日志 |
| 资源管理 | YARN | 统一调度Spark和MapReduce任务 |
| 批处理引擎 | PySpark | 离线训练推荐模型 |
| 流处理引擎 | Spark Streaming | 实时处理用户点击行为 |
| 服务接口 | Flask + Gunicorn | 提供RESTful推荐API |
| 缓存加速 | Redis | 存储热门推荐结果 |
三、核心模块实现
1. 数据采集与预处理
数据源:
- 用户行为日志(点击/播放/收藏/评分)
- 视频元数据(标题/标签/分类/时长)
- 用户画像(年龄/性别/地域/兴趣标签)
预处理流程:
python
from pyspark.sql import functions as F | |
# 原始数据清洗示例 | |
def clean_ratings(raw_df): | |
return (raw_df | |
.filter(F.col("rating").between(1, 5)) # 过滤无效评分 | |
.withColumn("timestamp", F.from_unixtime("timestamp")) # 时间格式转换 | |
.repartition(100) # 按用户ID哈希分区 | |
) | |
# 特征工程示例 | |
def extract_features(video_df): | |
from pyspark.ml.feature import StringIndexer, OneHotEncoder | |
# 标签编码 | |
tag_indexer = StringIndexer(inputCol="tags", outputCol="tag_indices") | |
tag_encoder = OneHotEncoder(inputCol="tag_indices", outputCol="tag_vectors") | |
pipeline = Pipeline(stages=[tag_indexer, tag_encoder]) | |
return pipeline.fit(video_df).transform(video_df) |
2. 推荐算法实现
(1) 协同过滤(ALS算法)
python
from pyspark.ml.recommendation import ALS | |
def train_als_model(train_df): | |
als = ALS( | |
maxIter=15, | |
regParam=0.1, | |
rank=100, # 隐语义维度 | |
userCol="user_id", | |
itemCol="video_id", | |
ratingCol="rating", | |
coldStartStrategy="drop" # 冷启动处理 | |
) | |
return als.fit(train_df) | |
# 生成用户推荐 | |
def generate_recommendations(model, user_ids, top_n=10): | |
return model.recommendForUserSubset( | |
spark.createDataFrame(user_ids, "string"), | |
top_n | |
) |
(2) 内容相似度推荐
python
from pyspark.ml.feature import VectorAssembler | |
from pyspark.ml.linalg import Vectors | |
def content_based_rec(user_id, video_df, user_profile): | |
# 构建视频特征矩阵 | |
assembler = VectorAssembler( | |
inputCols=["duration", "popularity"] + ["tag_" + str(i) for i in range(20)], | |
outputCol="features" | |
) | |
video_vec = assembler.transform(video_df) | |
# 计算余弦相似度 | |
from pyspark.ml.stat import Correlation | |
matrix = Correlation.corr(video_vec, "features").collect()[0][0] | |
similarities = matrix.toArray() | |
# 返回相似度最高的视频 | |
return sorted(zip(video_ids, similarities), key=lambda x: -x[1])[:10] |
(3) 混合推荐策略
python
def hybrid_recommend(user_id, als_model, video_df, alpha=0.7): | |
# 获取协同过滤推荐 | |
cf_recs = generate_recommendations(als_model, [user_id]).first()["recommendations"] | |
# 获取内容推荐(需先构建用户画像) | |
user_tags = get_user_tags(user_id) # 从HBase获取用户兴趣标签 | |
content_recs = content_based_filtering(video_df, user_tags) | |
# 加权融合 | |
def score_fusion(cf_item, content_item): | |
cf_score = cf_item["rating"] if cf_item else 0 | |
content_score = content_item["score"] if content_item else 0 | |
return alpha * cf_score + (1-alpha) * content_score | |
return merge_and_rank(cf_recs, content_recs, score_fusion) |
3. 实时推荐处理
python
from pyspark.streaming import StreamingContext | |
from pyspark.streaming.kafka import KafkaUtils | |
def process_realtime_clicks(zkQuorum, groupId, topics): | |
ssc = StreamingContext(spark.sparkContext, batchDuration=10) # 10秒批次 | |
# Kafka流接入 | |
kvs = KafkaUtils.createStream( | |
ssc, zkQuorum, groupId, {t: 1 for t in topics} | |
) | |
# 实时更新用户兴趣 | |
def update_user_profile(new_clicks, current_profile): | |
if current_profile is None: | |
return new_clicks | |
return current_profile.union(new_clicks) # 简单合并示例 | |
# 状态管理 | |
user_profiles = kvs.map(parse_click) \ | |
.groupByKey() \ | |
.updateStateByKey(update_user_profile) | |
# 触发实时推荐 | |
user_profiles.foreachRDD(lambda rdd: rdd.foreachPartition(trigger_realtime_rec)) | |
return ssc |
四、性能优化技术
1. 计算层优化
-
数据分区:
python# 按用户ID哈希分区,避免数据倾斜ratings_df.repartition(200, "user_id")# 广播小表(如视频元数据)video_broadcast = spark.sparkContext.broadcast(video_dict) -
内存管理:
bash# Spark配置参数示例spark-submit \--executor-memory 8G \--driver-memory 4G \--conf spark.sql.shuffle.partitions=200 \--conf spark.kryoserializer.buffer.max=512m \rec_system.py
2. 存储层优化
-
HDFS参数调优:
xml<!-- hdfs-site.xml配置示例 --><property><name>dfs.block.size</name><value>268435456</value> <!-- 256MB块大小 --></property><property><name>dfs.replication</name><value>3</value> <!-- 3副本 --></property> -
HBase列族设计:
表名: user_recs列族:cf1: 存储ALS推荐结果 (timestamp, rec_list)cf2: 存储内容推荐结果 (tag_scores, last_updated)
3. 服务层优化
-
API响应加速:
python# 使用LRU缓存热门推荐from functools import lru_cache@lru_cache(maxsize=10000)def get_cached_rec(user_id):# 从Redis获取缓存结果cached = redis.get(f"rec:{user_id}")if cached:return json.loads(cached)# 缓存未命中时计算并存储recs = compute_recommendations(user_id)redis.setex(f"rec:{user_id}", 3600, json.dumps(recs))return recs -
异步任务处理:
python# 使用Celery处理耗时推荐任务from celery import Celeryapp = Celery('rec_tasks', broker='redis://localhost:6379/0')@app.taskdef async_recommend(user_id):# 复杂推荐计算return heavy_recommendation_logic(user_id)
五、部署与运维
1. 集群部署方案
| 节点类型 | 数量 | 配置 | 部署服务 |
|---|---|---|---|
| Master节点 | 1 | 16核32G 500GB SSD | NameNode, ResourceManager |
| Worker节点 | 4 | 32核64G 2TB HDD x3 | DataNode, NodeManager, Spark Worker |
| Edge节点 | 1 | 8核16G | Spark Driver, Web服务 |
2. 监控告警体系
- Prometheus + Grafana:
- 监控指标:
- JVM内存使用率
- Spark任务延迟
- HDFS读写吞吐量
- API响应时间P99
- 监控指标:
- ELK日志系统:
Filebeat → Logstash → Elasticsearch → Kibana
3. 故障处理流程
- 推荐服务不可用:
- 检查Gunicorn进程状态
- 查看Spark Driver日志
- 验证Redis连接
- 推荐质量下降:
- 检查模型训练数据分布
- 监控NDCG@10指标变化
- 对比A/B测试结果
- 集群性能瓶颈:
- 使用Ganglia监控资源使用
- 调整YARN队列资源配额
- 优化HDFS块大小和副本数
六、技术选型依据
- 为什么选择PySpark:
- 比原生Spark更简洁的Python API
- 支持Pandas UDF加速数据处理
- 与Scikit-learn生态无缝集成
- Hadoop的必要性:
- HDFS提供高可靠存储(3副本机制)
- YARN实现多计算框架统一调度
- 成熟的企业级支持
- Python的优势:
- 快速原型开发(比Java快3-5倍)
- 丰富的机器学习库(TensorFlow/PyTorch)
- 活跃的社区支持
七、未来演进方向
- 算法升级:
- 引入Graph Neural Network处理用户-视频关系图
- 实现多目标优化(点击率+播放时长+完播率)
- 架构优化:
- 用Ray替代Spark实现更高效的并行计算
- 引入Alluxio加速数据访问
- 实时性增强:
- Flink流处理引擎替代Spark Streaming
- 实现毫秒级实时推荐更新
本技术说明详细阐述了基于Python+PySpark+Hadoop的视频推荐系统实现方案,通过分层架构设计和多维度优化,实现了高性能、可扩展的个性化推荐服务,为大规模视频平台提供了完整的技术解决方案。
运行截图
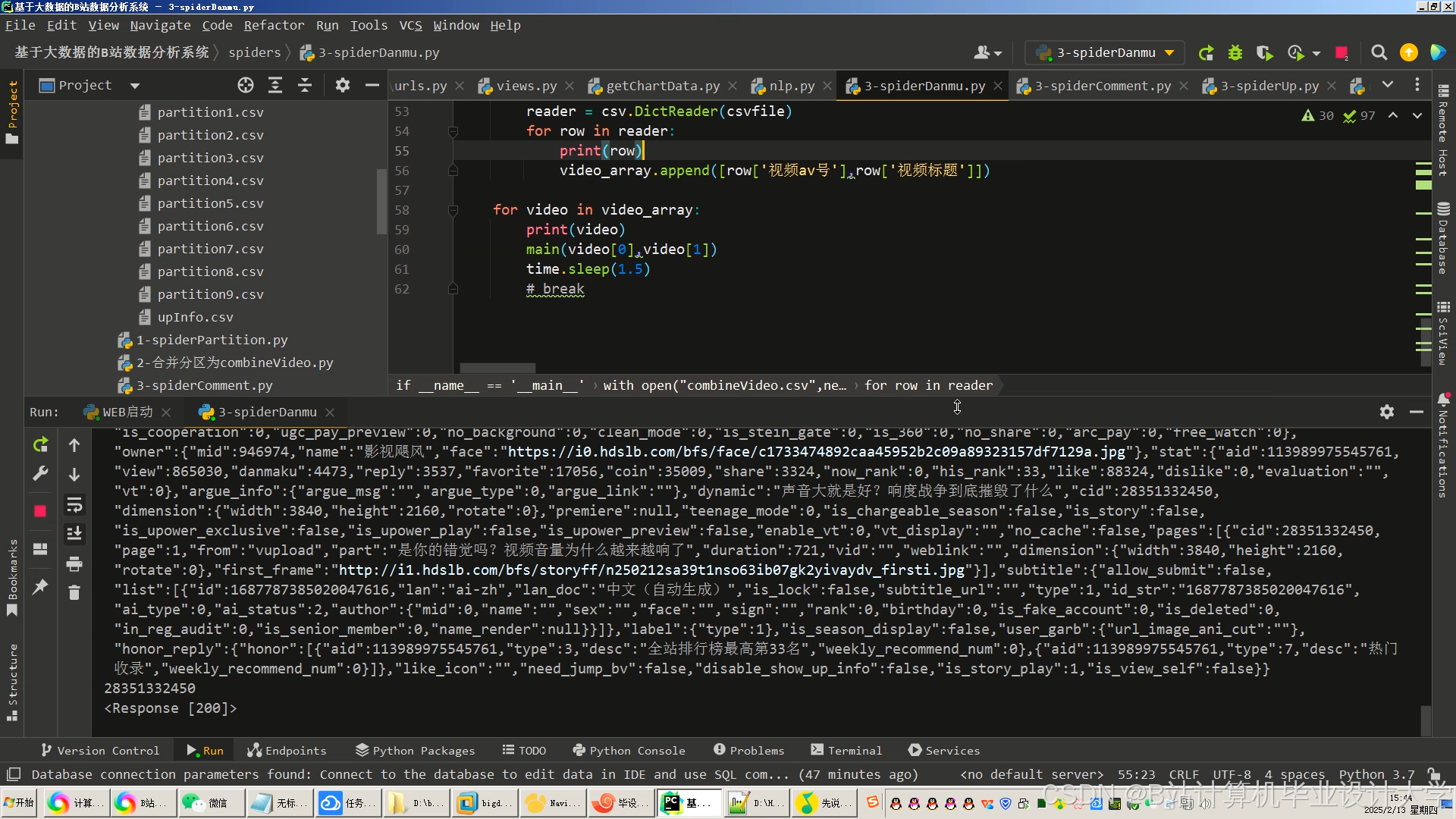
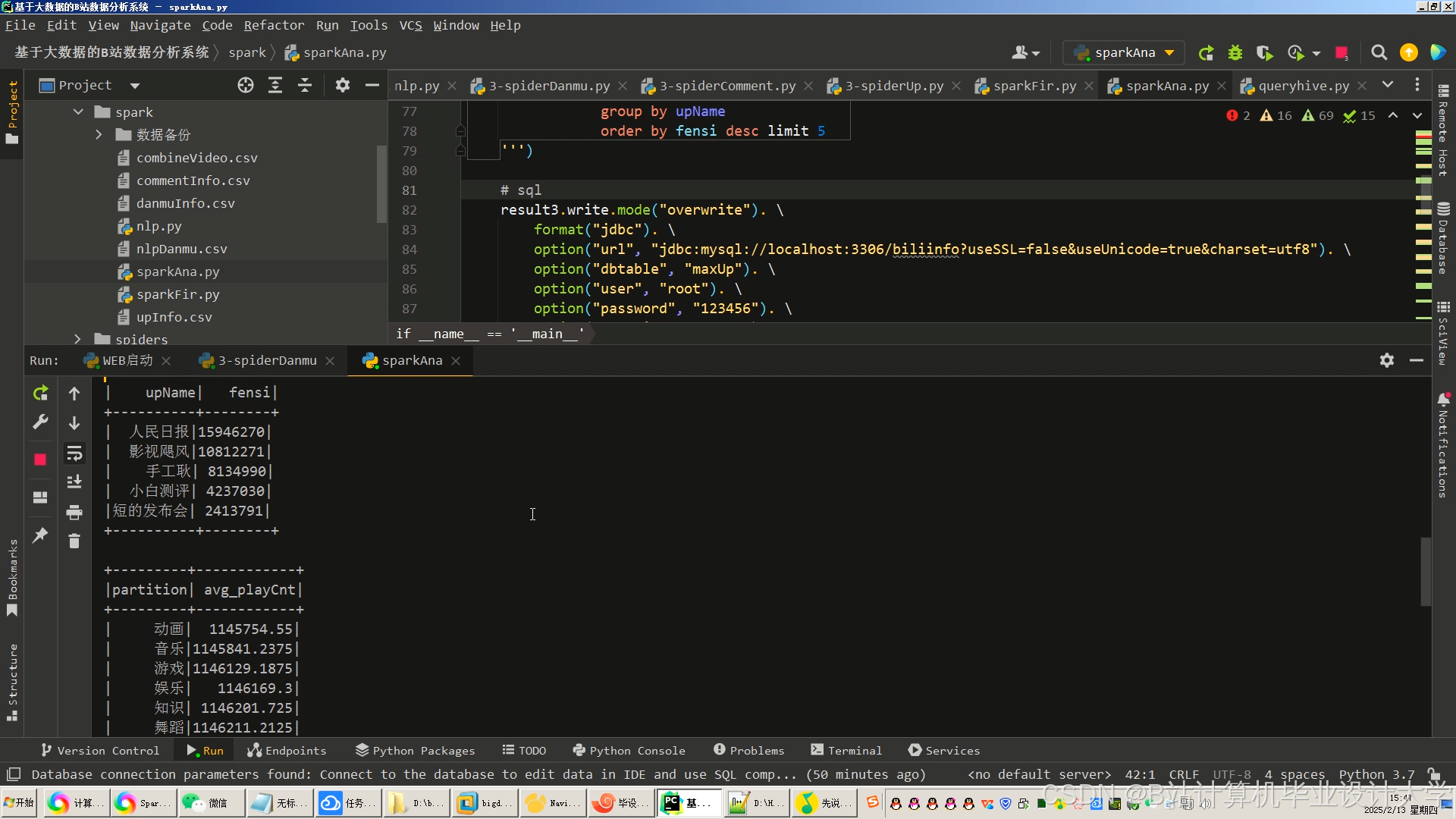
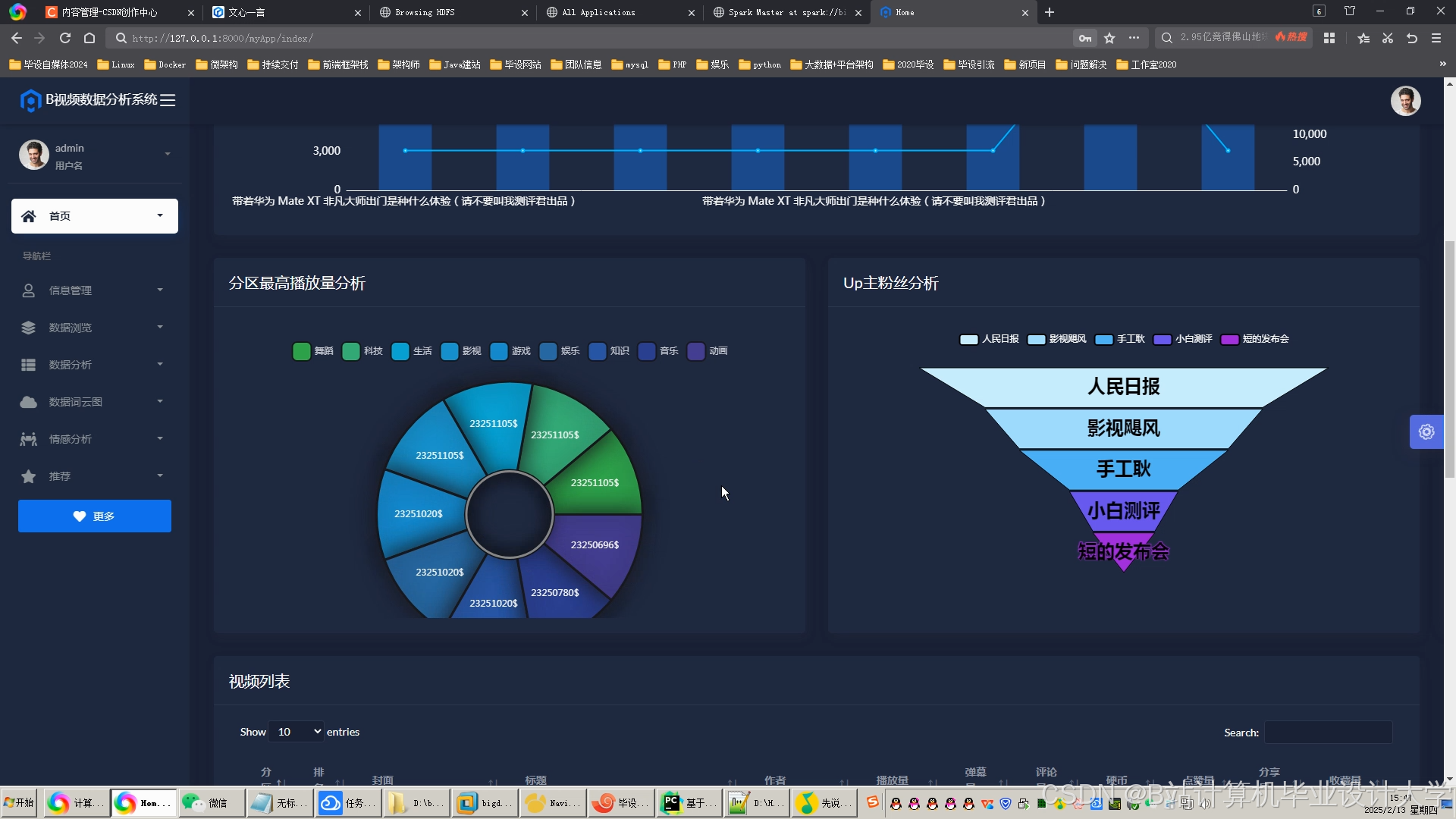
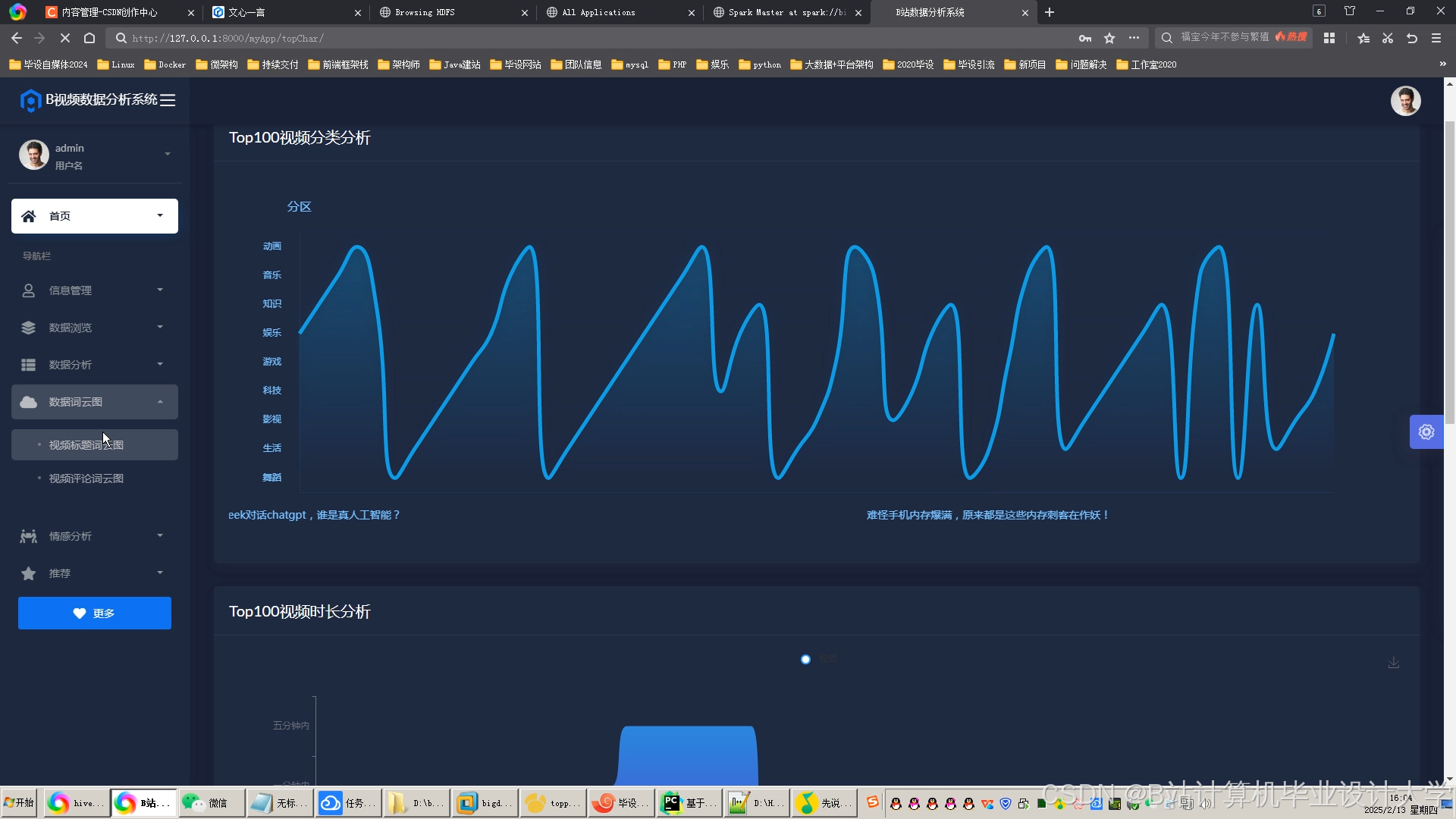
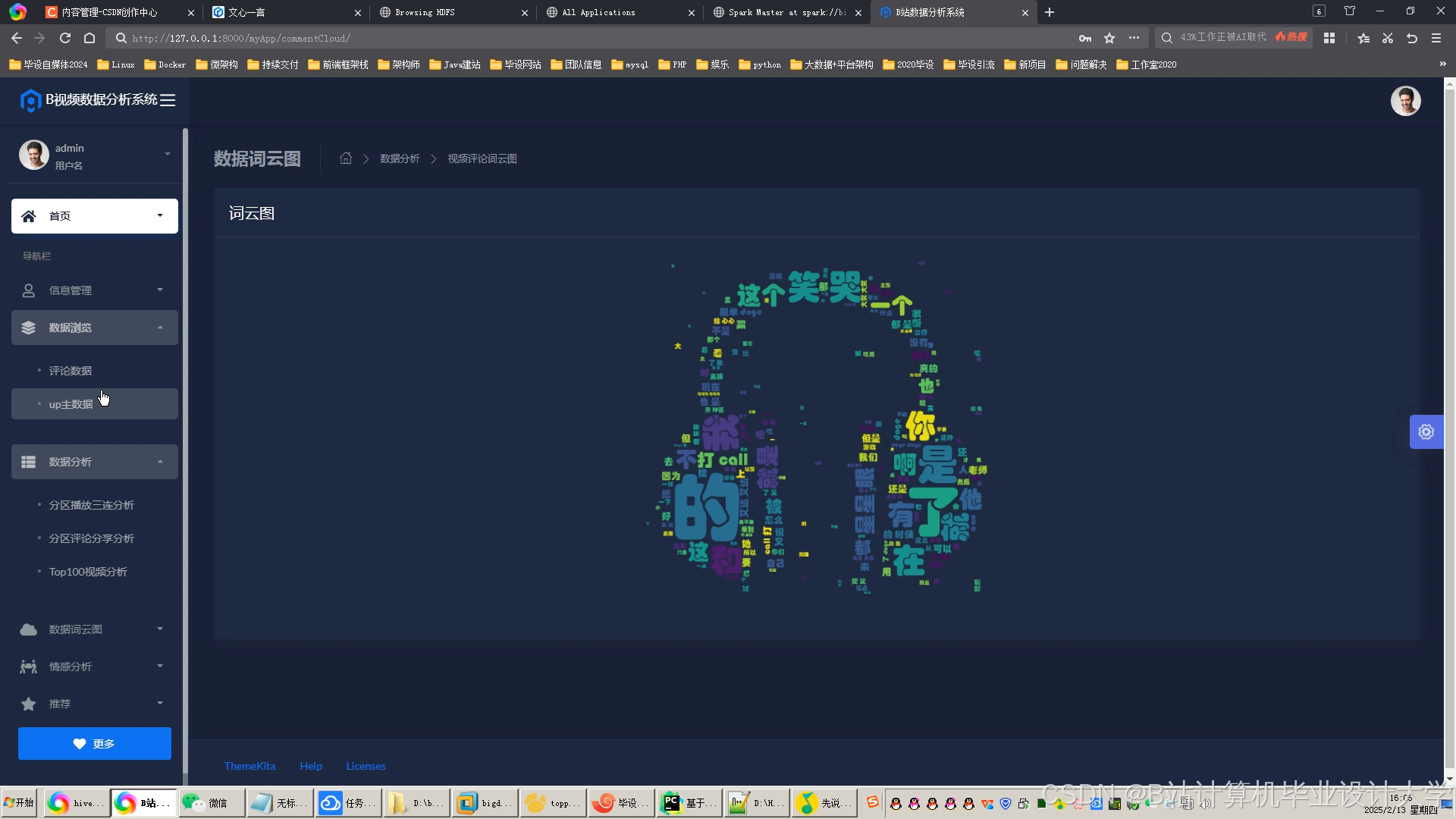
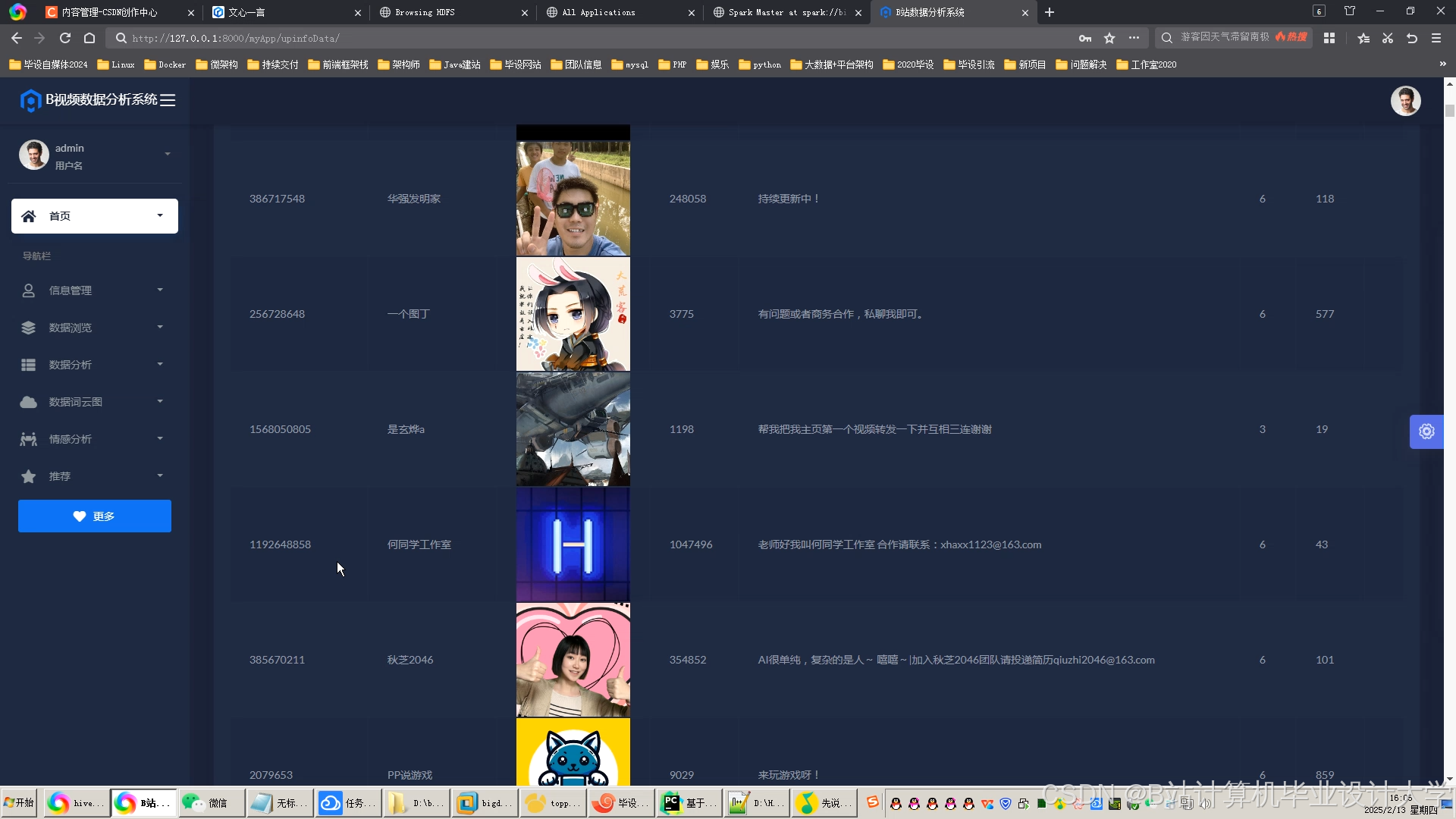
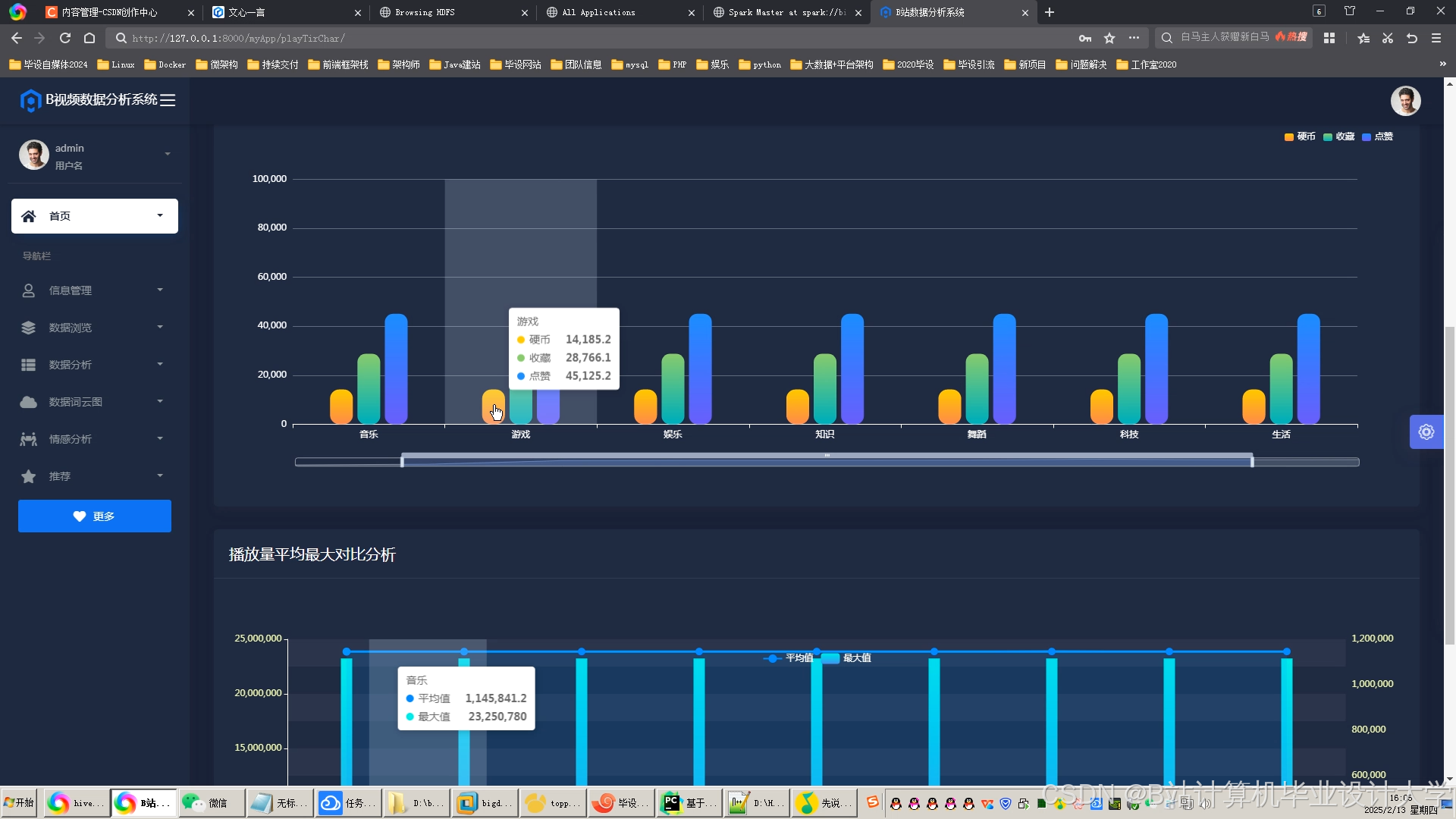
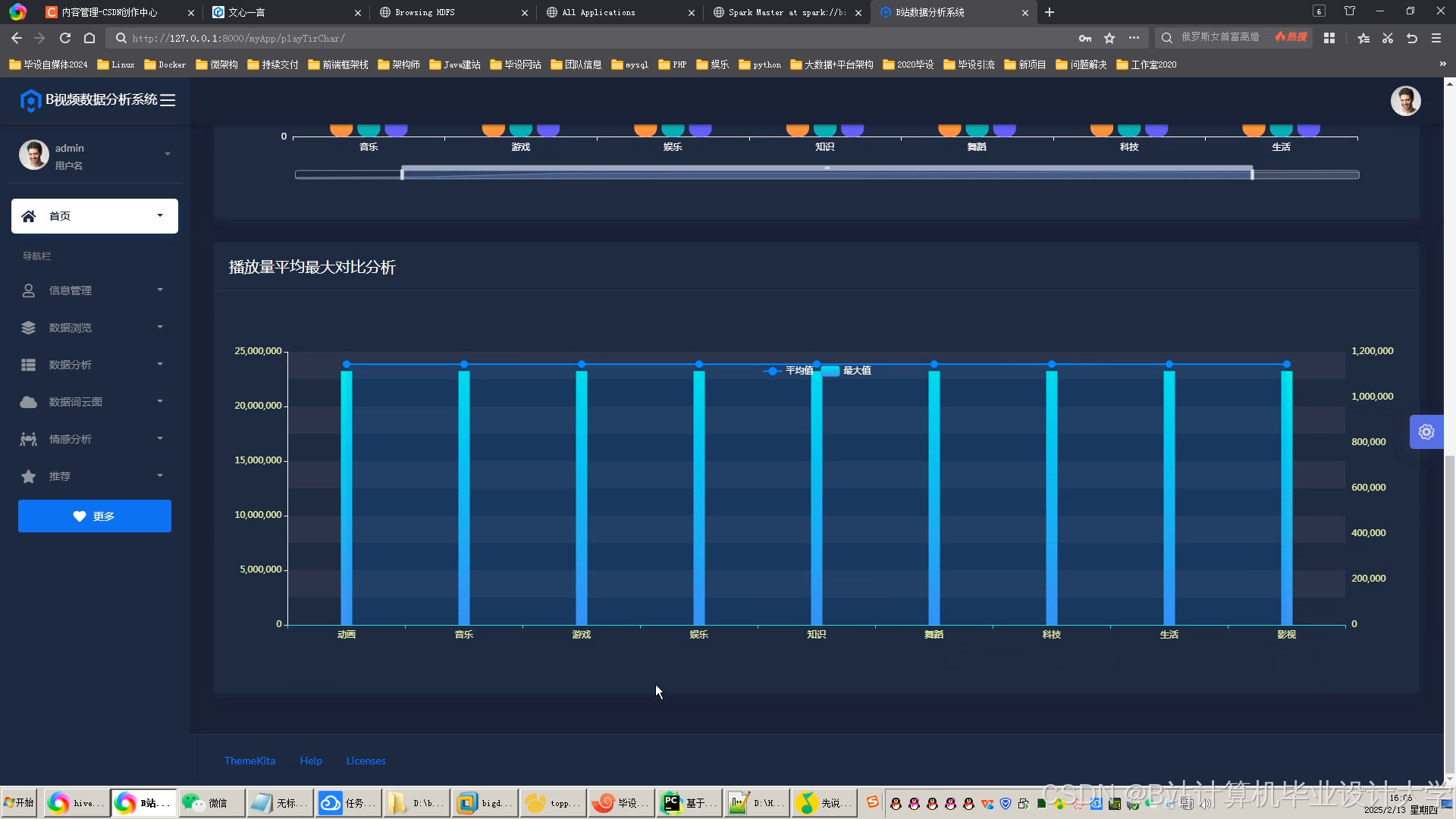
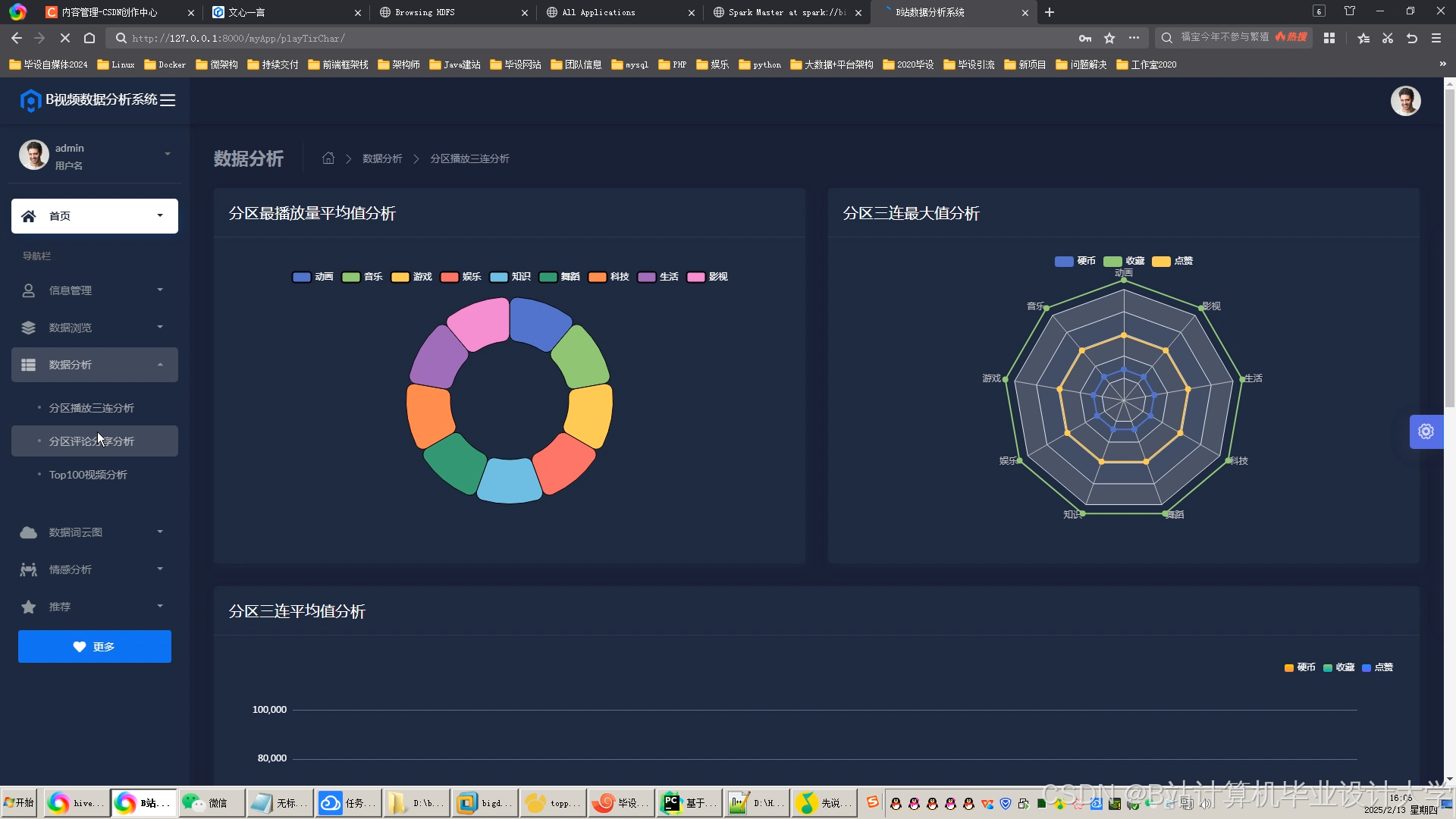
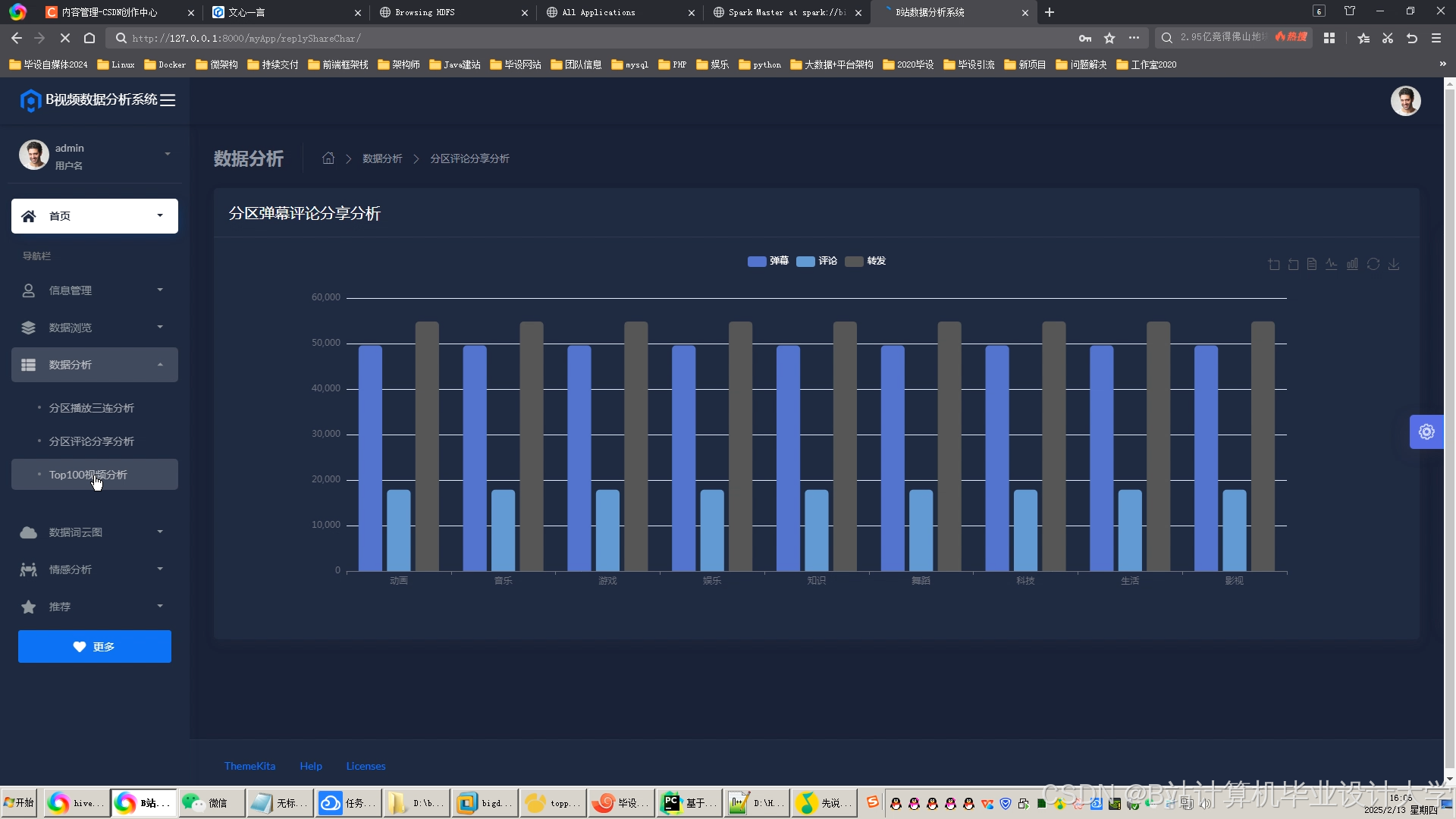
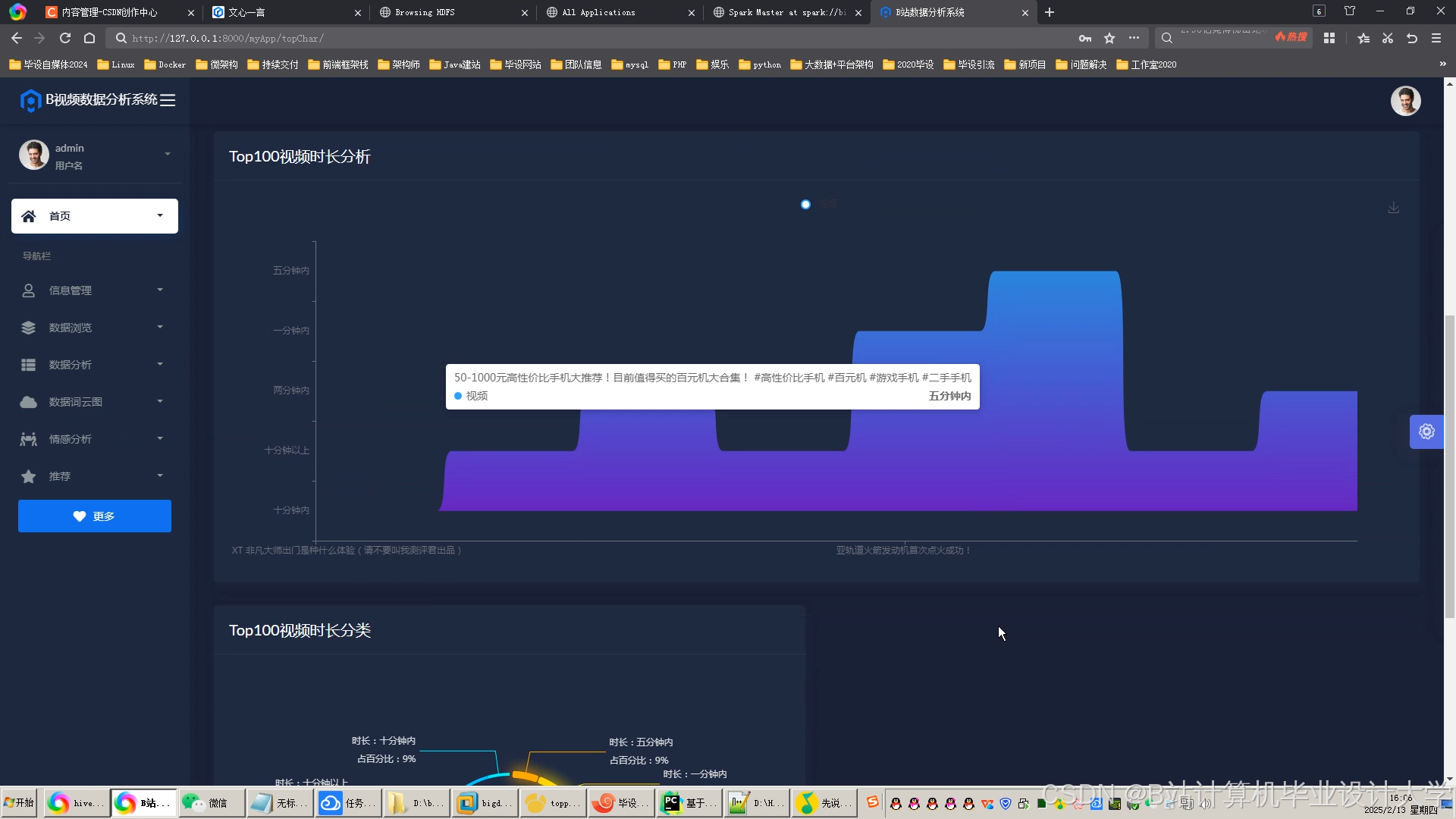
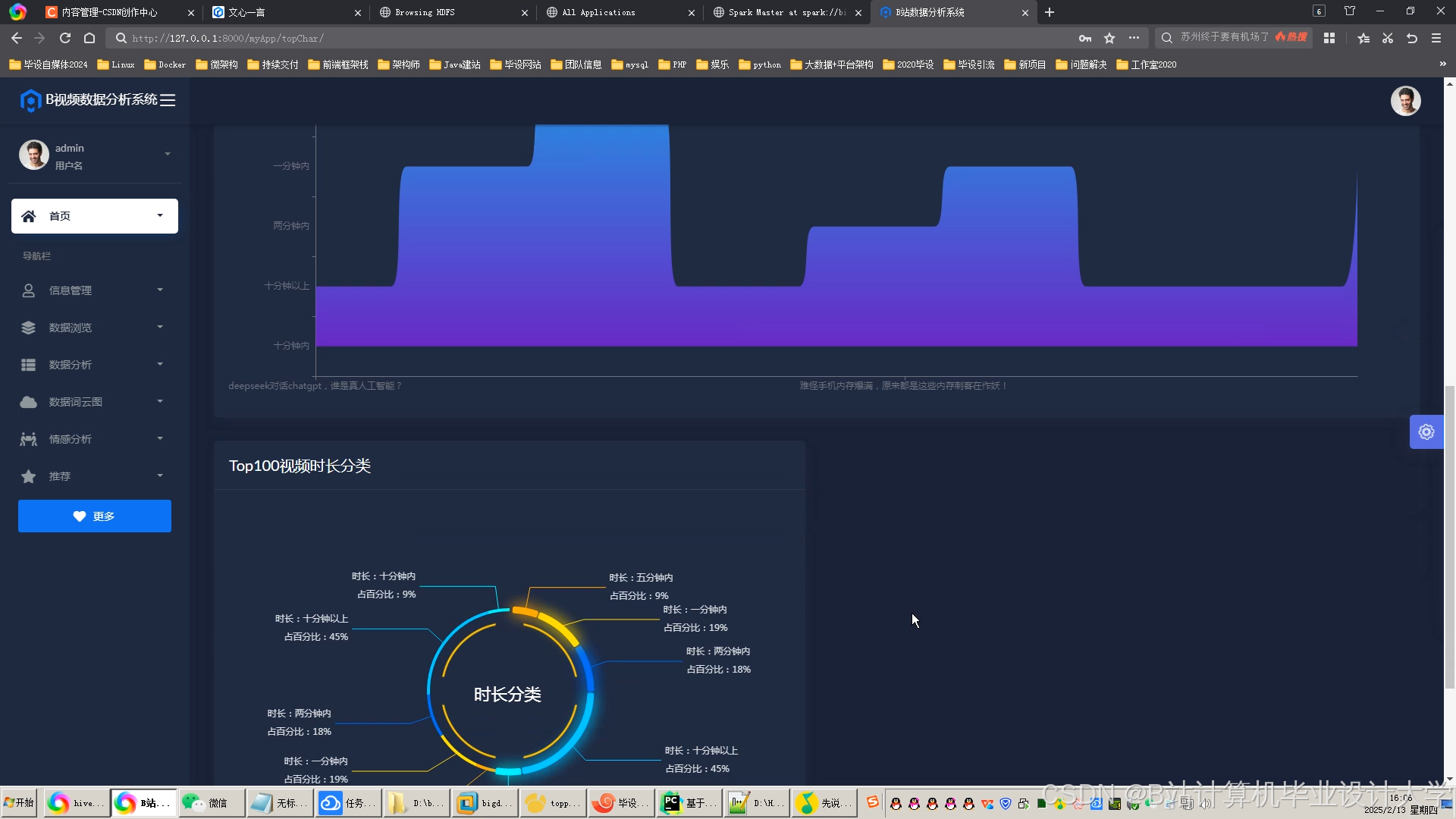
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











