




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
任务书:基于Python+PySpark+Hadoop的视频推荐系统开发
一、任务背景
随着短视频平台和在线教育网站的快速发展,视频推荐系统成为提升用户体验和平台收益的核心模块。传统推荐系统面临数据规模大、实时性要求高、特征维度复杂等挑战。本任务旨在构建一个基于Python(算法开发) + PySpark(分布式计算) + Hadoop(分布式存储)的视频推荐系统,实现高效、可扩展的个性化推荐服务。
二、任务目标
- 技术目标
- 构建分布式推荐系统架构,支持TB级视频数据的存储与处理。
- 实现基于协同过滤、内容过滤和图神经网络的混合推荐算法。
- 开发实时推荐引擎,支持用户行为数据的实时更新与模型增量学习。
- 业务目标
- 提升推荐准确率(Precision@10 ≥ 35%)。
- 降低推荐响应时间(< 200ms)。
- 提高用户观看时长(平均增加15%以上)。
三、任务范围
1. 系统功能模块
| 模块名称 | 功能描述 |
|---|---|
| 数据采集与存储 | 从MySQL、Kafka、HDFS等多源采集用户行为、视频元数据,存储至Hadoop生态(HDFS + HBase)。 |
| 特征工程 | 提取用户画像(年龄、兴趣标签)、视频特征(文本、图像、音频)、上下文特征(时间、设备)。 |
| 推荐算法 | 实现以下算法: - 基于ALS的协同过滤(PySpark MLlib) - 基于BERT的内容过滤(Python + PyTorch) - 基于GraphSAGE的图神经网络(PySpark GraphX) |
| 实时推荐引擎 | 使用PySpark Structured Streaming处理实时点击流,动态更新推荐结果。 |
| 评估与优化 | 离线评估(Precision/NDCG) + 在线A/B测试(CTR/观看时长)。 |
2. 技术栈
| 组件 | 版本 | 用途 |
|---|---|---|
| Python | 3.9+ | 算法开发(PyTorch/TensorFlow) |
| PySpark | 3.3.0 | 分布式计算(MLlib/GraphX) |
| Hadoop | 3.3.4 | 分布式存储(HDFS/HBase) |
| Kafka | 3.2.0 | 实时数据流传输 |
| FastAPI | 0.85.0 | 推荐服务API |
四、任务分解与分工
1. 团队分工
| 角色 | 职责 |
|---|---|
| 项目经理 | 制定计划、协调资源、监控进度 |
| 算法工程师 | 设计推荐算法、特征工程、模型训练 |
| 大数据工程师 | 搭建Hadoop/Spark集群、优化数据管道 |
| 后端开发 | 实现推荐API、服务部署与监控 |
| 测试工程师 | 设计测试用例、性能调优、A/B测试 |
2. 任务里程碑
| 阶段 | 时间 | 交付物 |
|---|---|---|
| 需求分析 | 第1周 | 《需求规格说明书》 |
| 架构设计 | 第2周 | 《系统架构图》《技术选型报告》 |
| 数据层开发 | 第3-4周 | Hadoop集群部署、数据采集脚本 |
| 算法开发 | 第5-7周 | 混合推荐模型代码、特征工程脚本 |
| 实时引擎开发 | 第8周 | Spark Streaming处理逻辑、增量学习机制 |
| 服务层开发 | 第9周 | FastAPI接口、负载均衡配置 |
| 测试与优化 | 第10周 | 性能测试报告、A/B测试结果 |
| 项目验收 | 第11周 | 系统部署文档、用户手册 |
五、技术要求
- 数据存储要求
- HDFS存储原始视频元数据和用户行为日志。
- HBase存储用户画像和实时推荐结果(低延迟查询)。
- 计算性能要求
- 批处理任务(如模型训练)需在10分钟内完成(集群规模:3 Worker节点)。
- 实时推荐延迟 < 200ms(P99)。
- 算法精度要求
- 离线评估指标:
- Precision@10 ≥ 35%
- NDCG@10 ≥ 0.45
- 在线评估指标:
- 用户点击率(CTR)提升 ≥ 15%
- 平均观看时长增加 ≥ 15%
- 离线评估指标:
六、资源需求
| 资源类型 | 规格 | 数量 | 用途 |
|---|---|---|---|
| 服务器 | 32核CPU/256GB内存/4TB SSD | 4台 | Hadoop集群(1 Master + 3 Worker) |
| 网络 | 10Gbps Infiniband | - | 集群内部通信 |
| 开发机 | 16核CPU/64GB内存/1TB SSD | 5台 | 算法开发、测试环境 |
| 云服务 | AWS EMR/阿里云MaxCompute | - | 备用计算资源 |
七、风险管理
| 风险类型 | 描述 | 应对措施 |
|---|---|---|
| 数据延迟 | Kafka消息堆积导致实时推荐延迟 | 增加Consumer Group、优化分区策略 |
| 模型过拟合 | 训练数据不足导致推荐偏差 | 引入正则化、交叉验证、数据增强 |
| 集群故障 | Hadoop/Spark节点宕机 | 启用HDFS HA、Spark Checkpoint机制 |
| 算法性能瓶颈 | 图神经网络计算耗时过长 | 采用采样策略(Neighbor Sampling)、模型压缩 |
八、验收标准
- 功能验收
- 系统支持TB级数据存储与处理。
- 混合推荐算法正常运行,结果可解释。
- 实时推荐延迟 < 200ms(P99)。
- 性能验收
- 集群吞吐量 ≥ 10万条/秒(用户行为日志处理)。
- 模型训练时间 ≤ 10分钟(ALS协同过滤)。
- 文档验收
- 提供完整的《系统设计文档》《测试报告》《用户手册》。
任务书签署
项目经理:________________
日期:________________
备注:本任务书需经项目评审委员会审核通过后生效,后续可根据实际情况调整任务分工和时间节点。
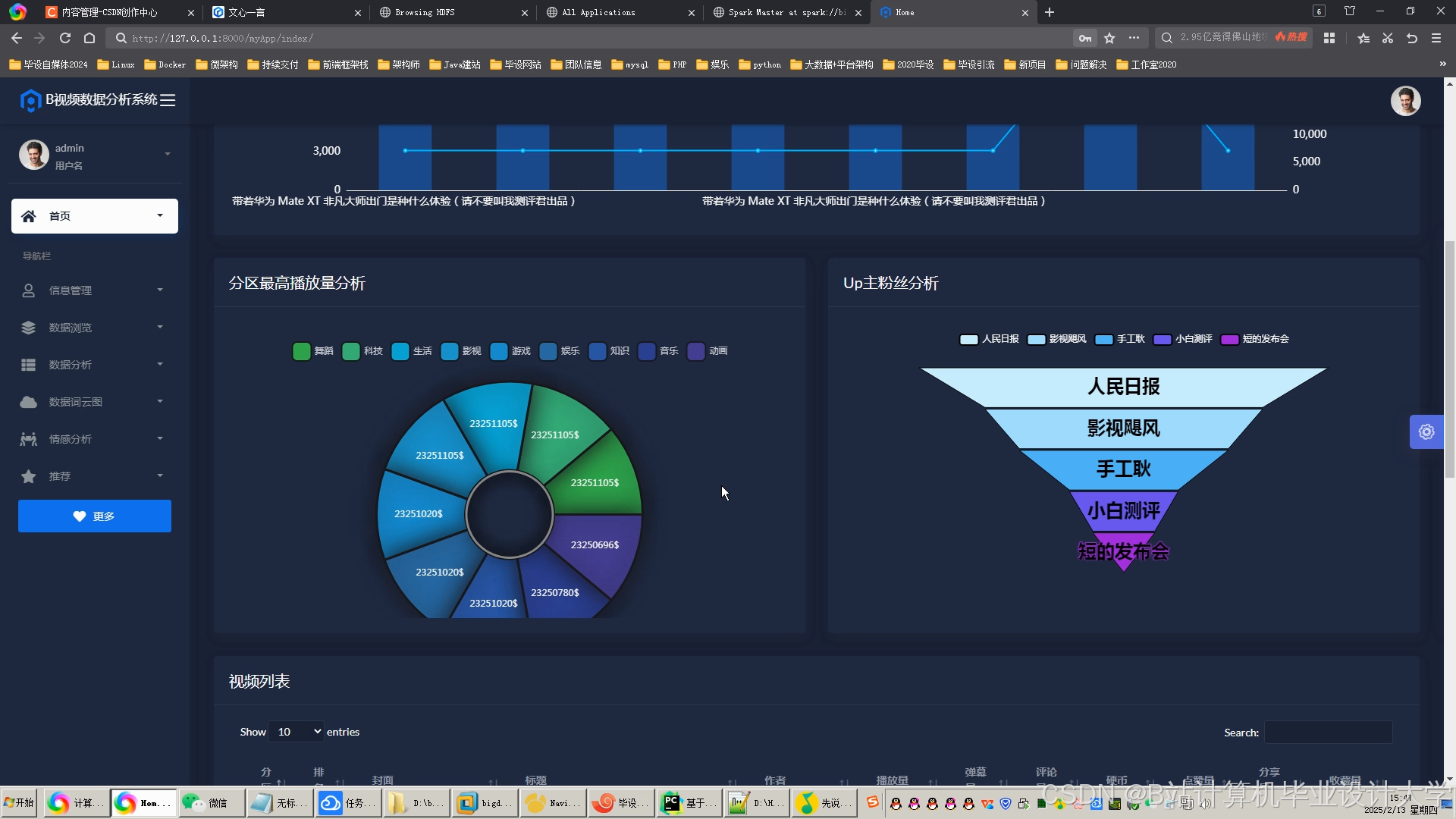
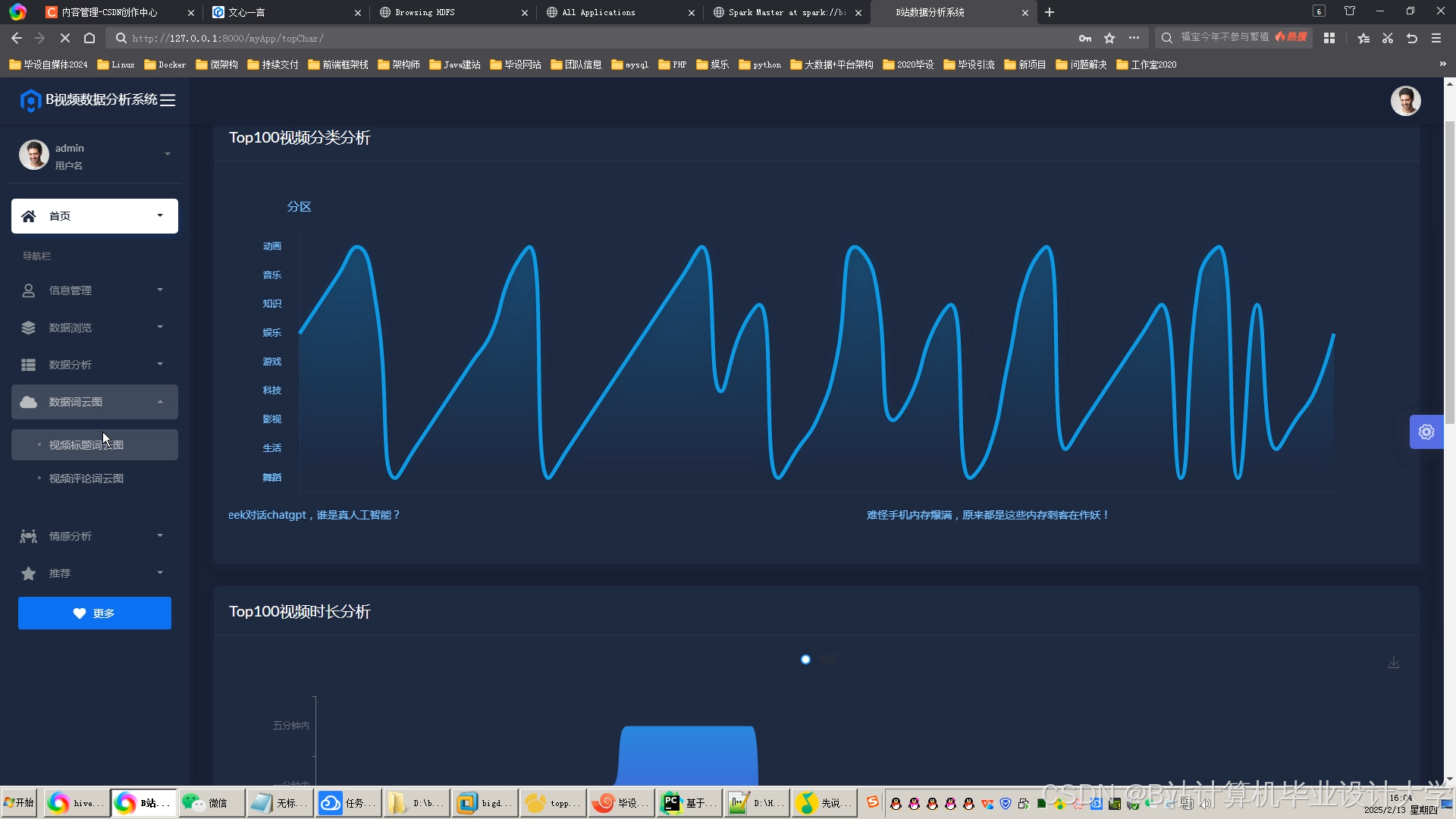
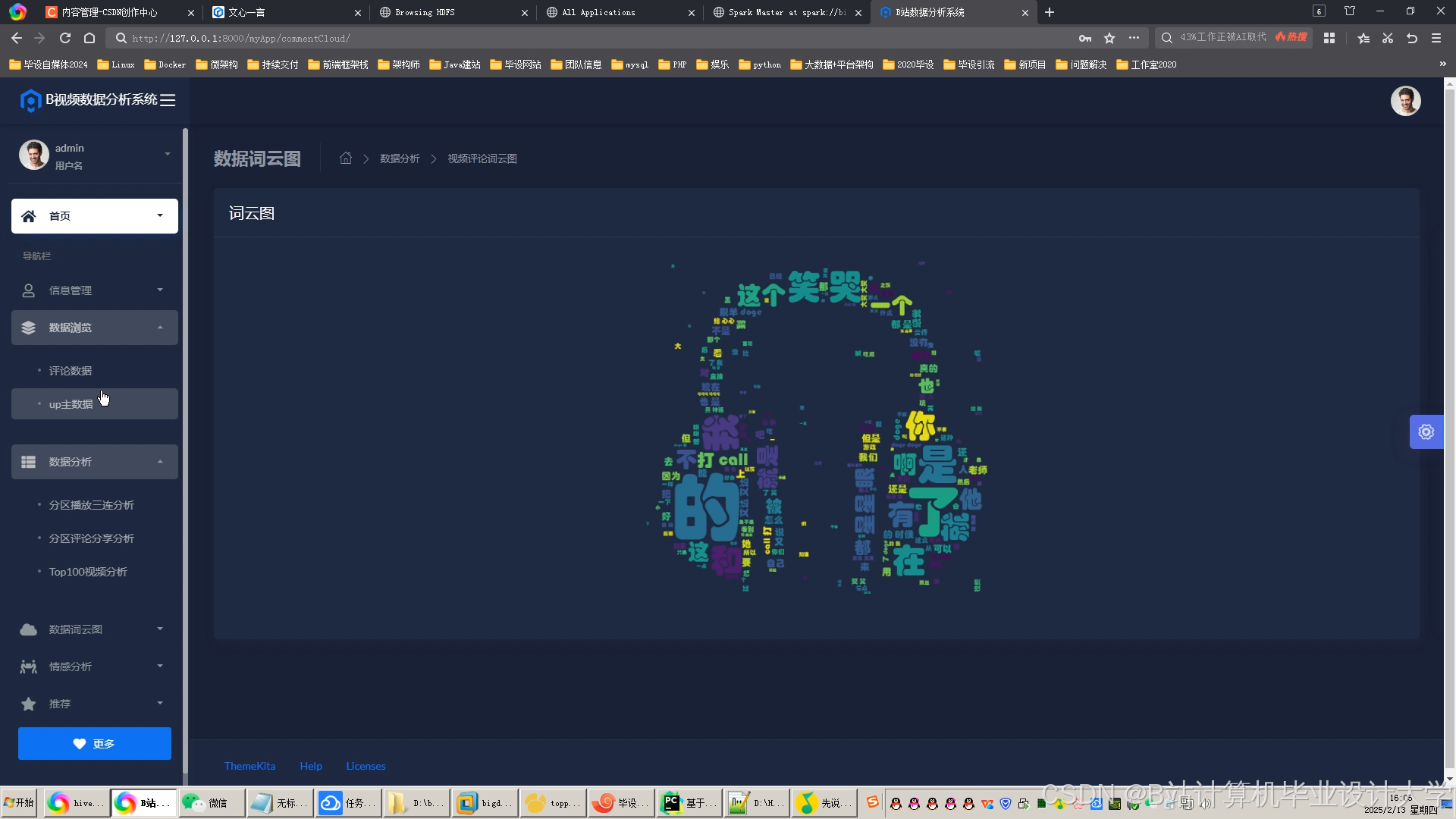
运行截图
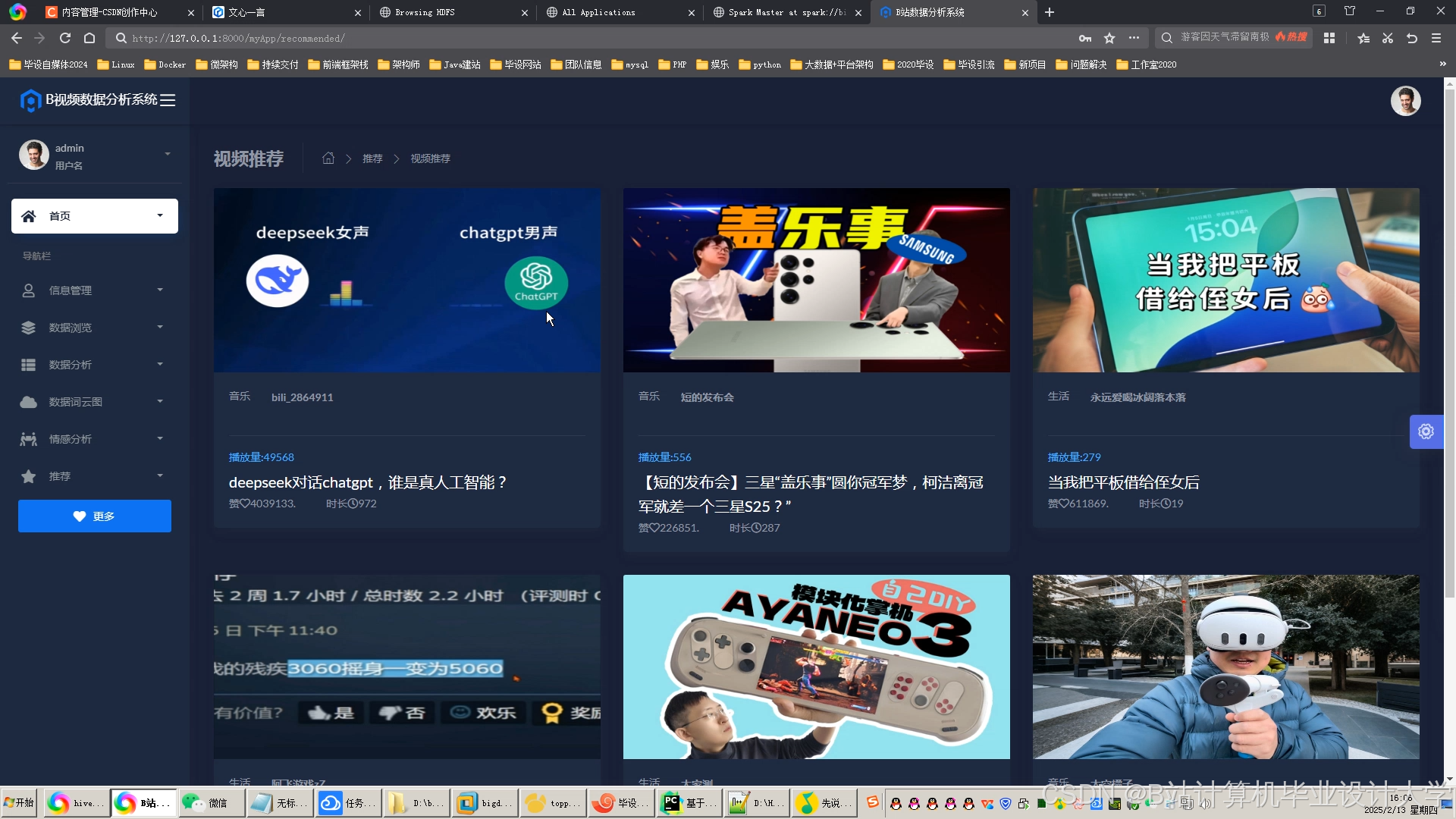
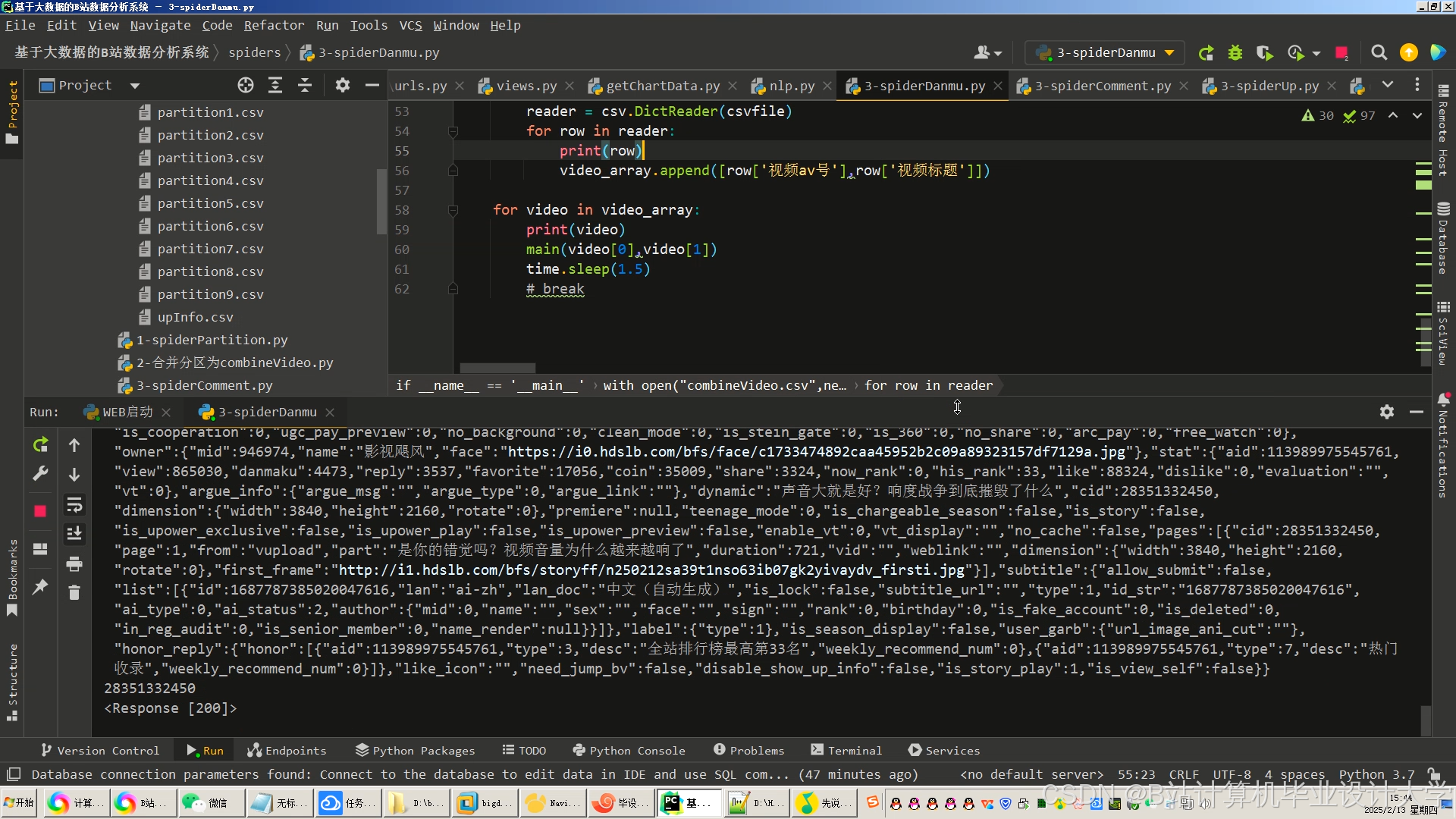
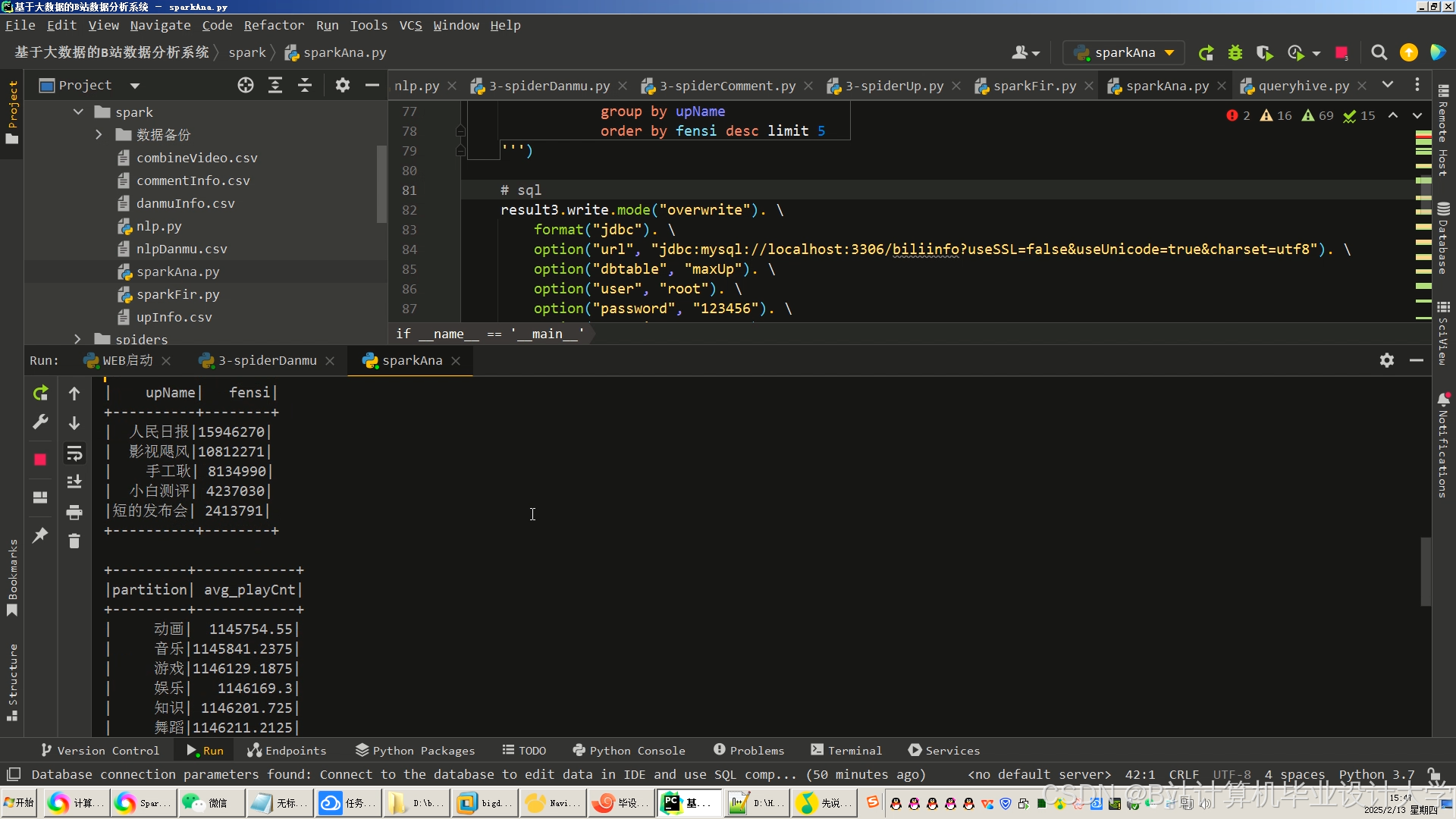
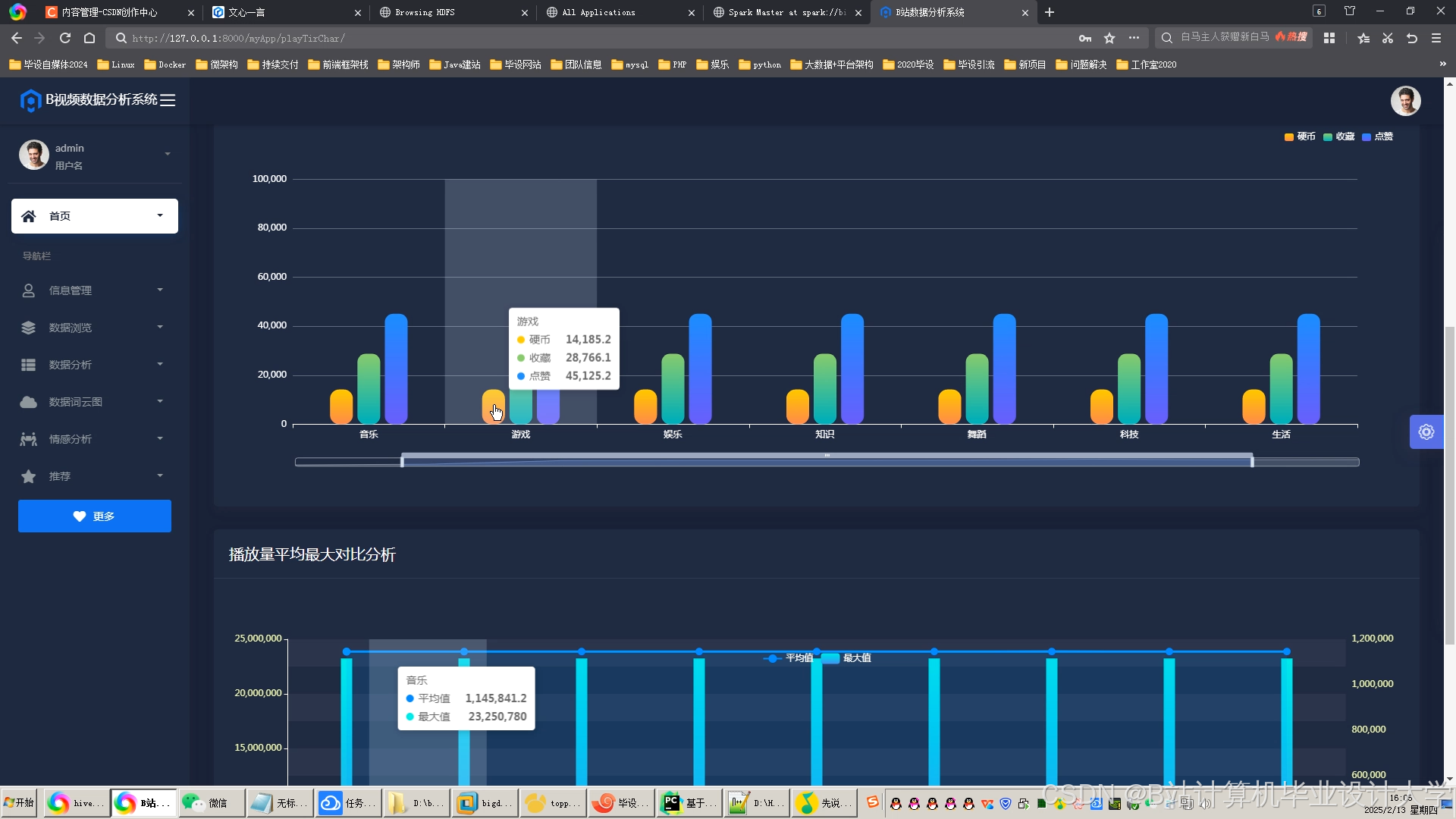
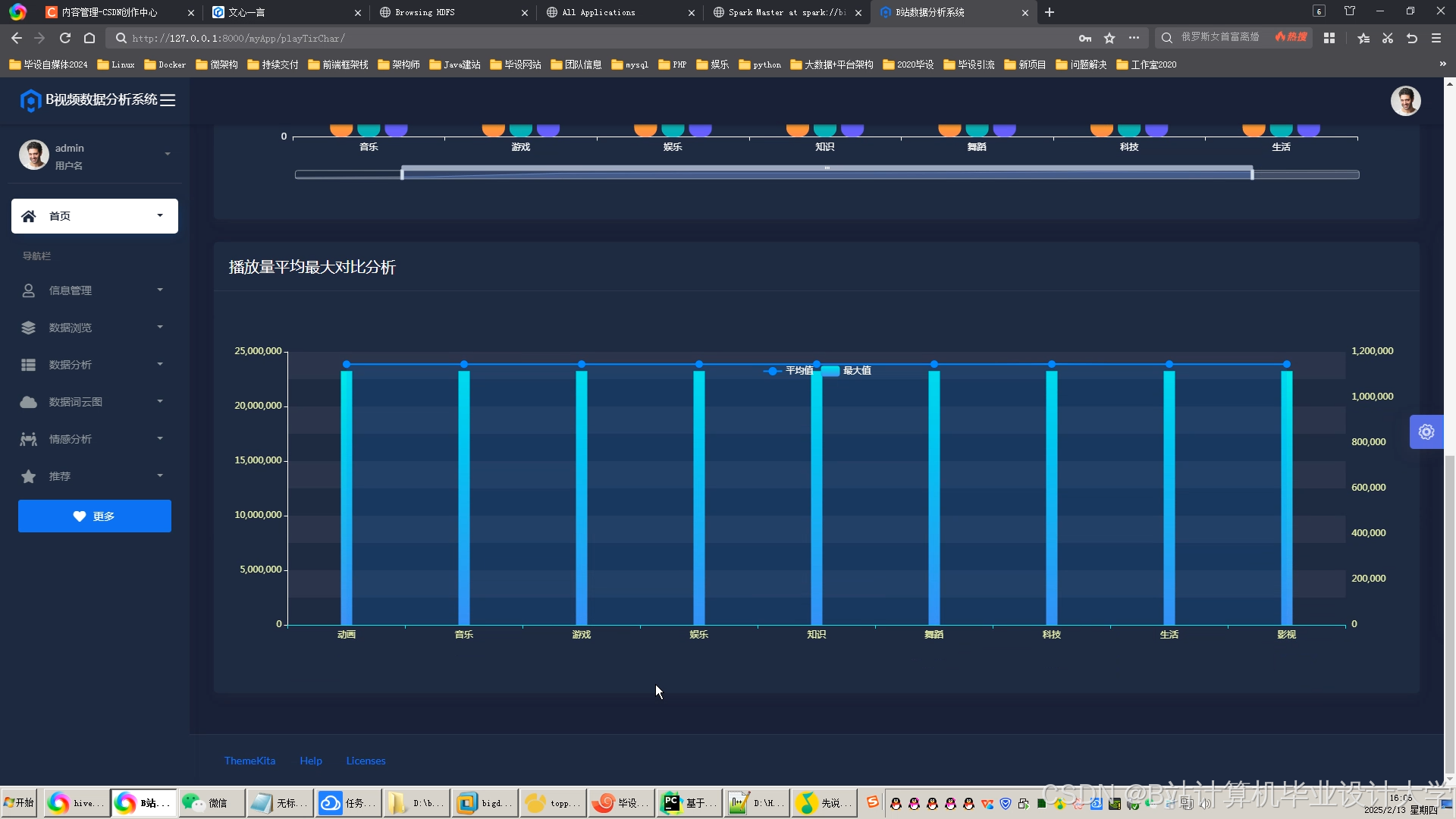
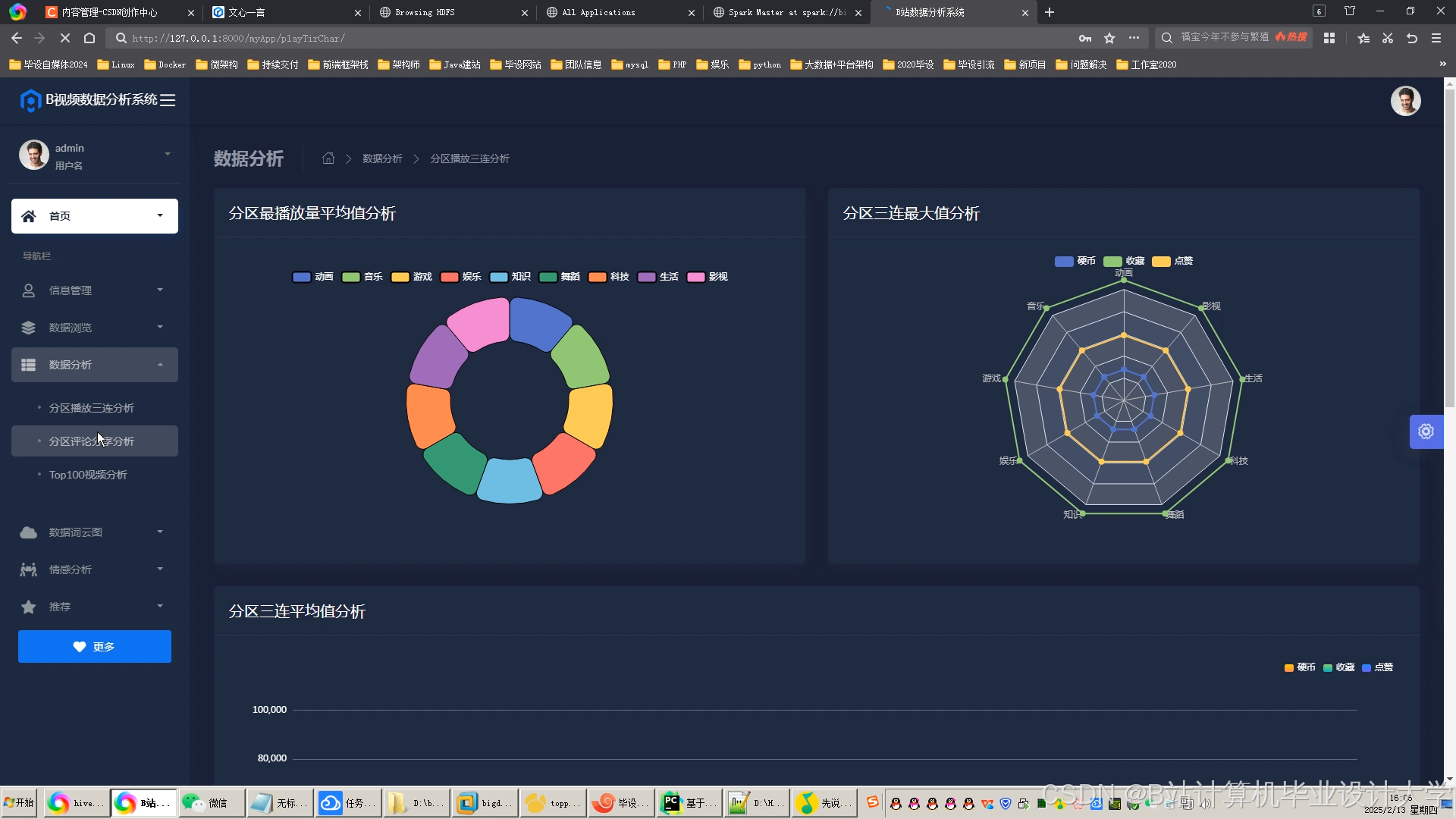
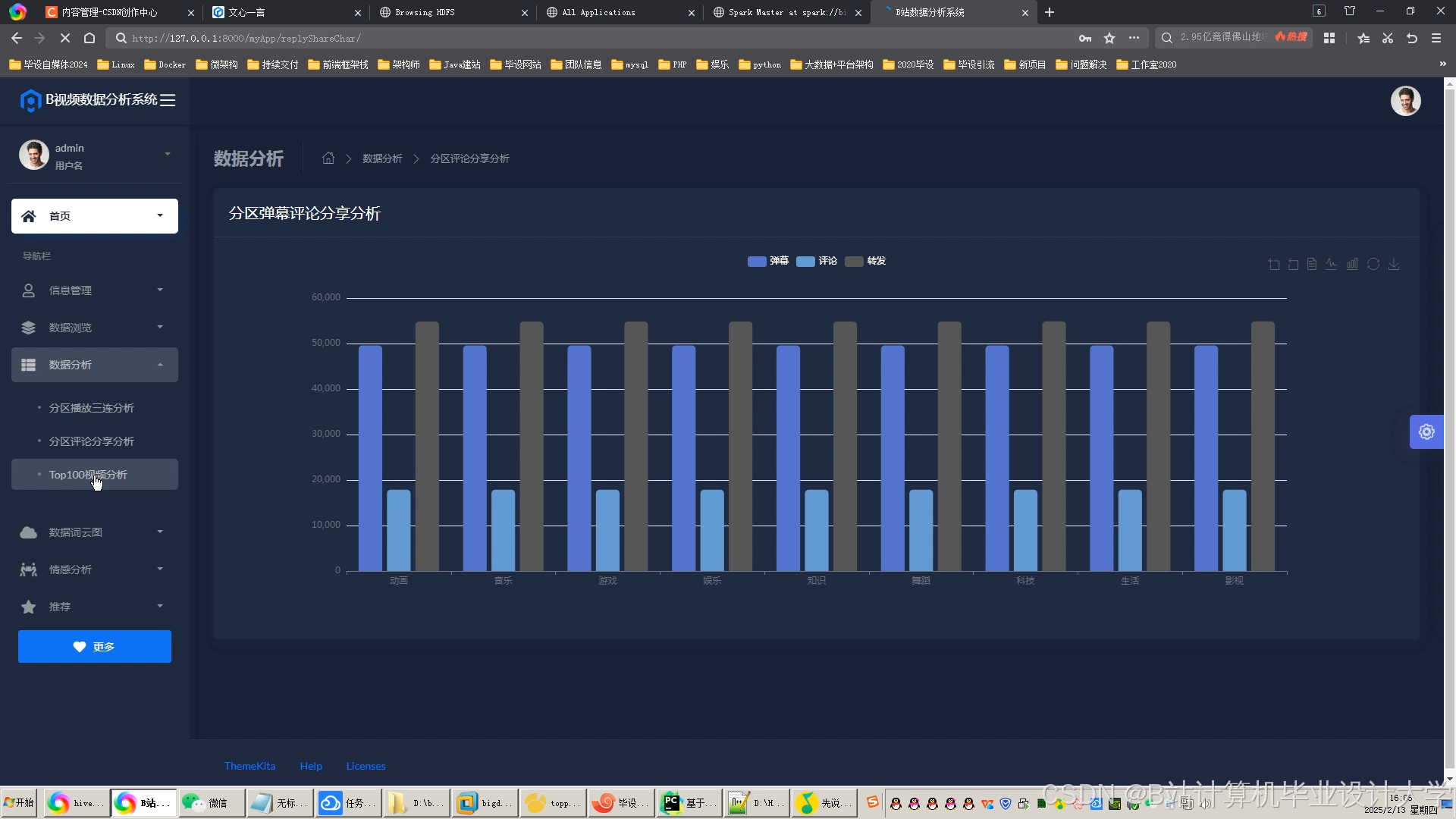
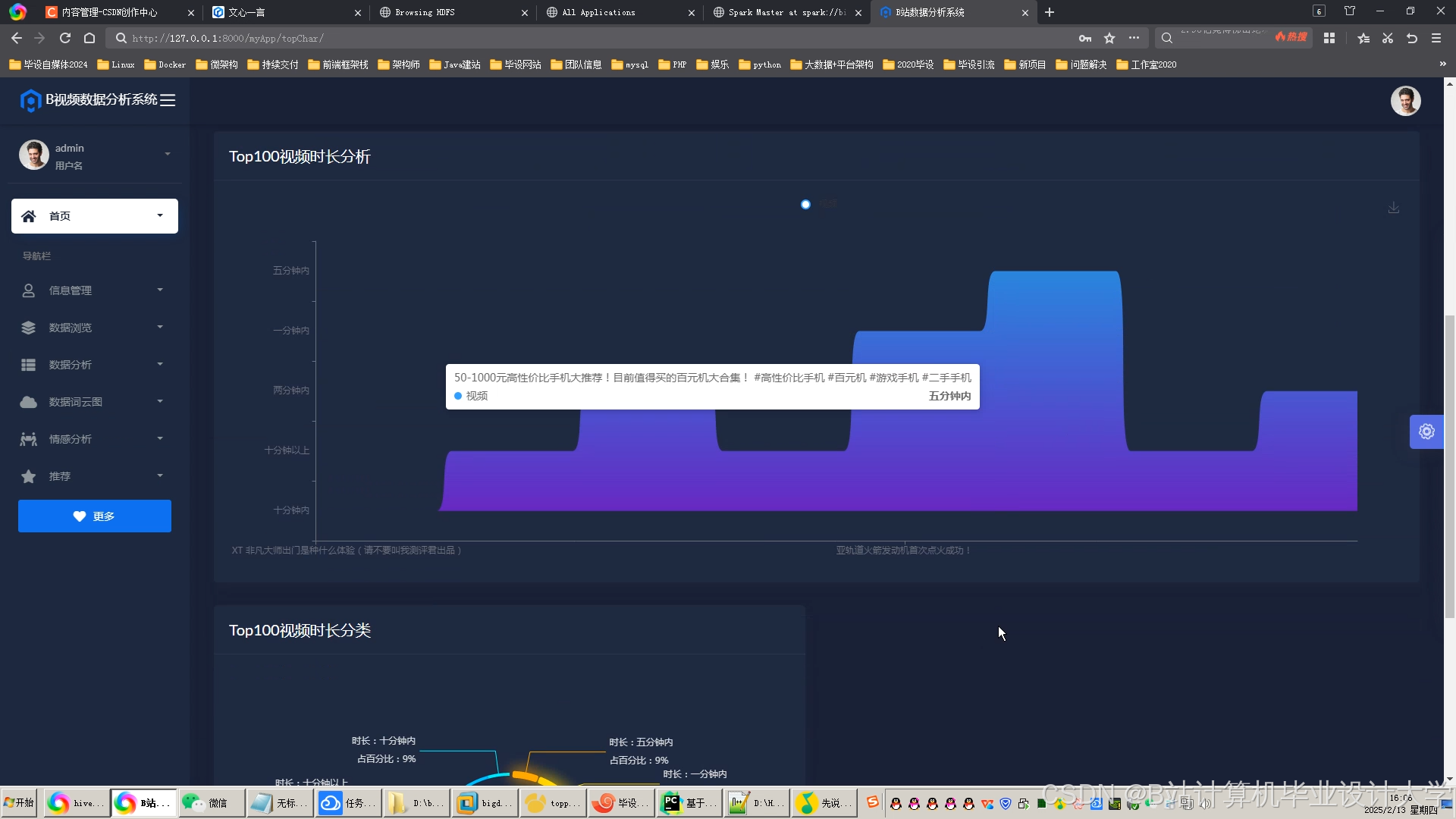
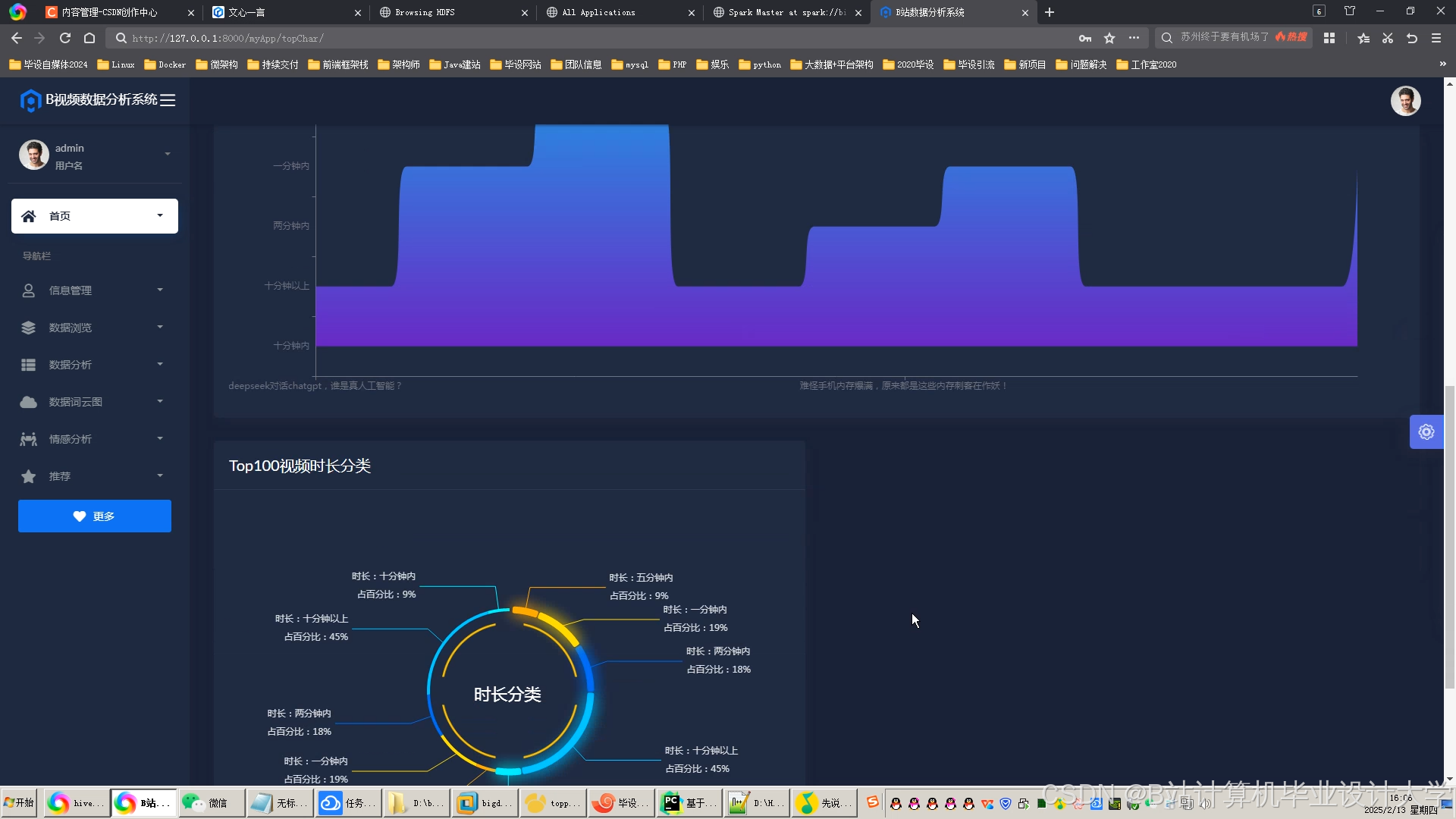
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











