 Python知识图谱助力古诗词可视化与分析
Python知识图谱助力古诗词可视化与分析





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python知识图谱在中华古诗词可视化中的应用技术说明
引言
中华古诗词作为中华文化的瑰宝,蕴含着丰富的历史、哲学与美学价值。然而,传统文本分析方法难以直观展现诗词间的语义关联(如诗人社交网络、意象演变、朝代风格差异等)。知识图谱技术通过结构化数据揭示实体间的复杂关系,结合Python强大的数据处理与可视化能力,可构建交互式古诗词探索平台,助力文化研究与教育传播。本文从技术实现角度,系统阐述Python在中华古诗词知识图谱构建、可视化及情感分析中的核心方法。
一、技术架构与核心工具链
1.1 数据层:多源异构数据融合
- 数据采集:利用
Scrapy框架与Requests库爬取古诗文网、中华诗库等平台数据,结合CTEXT开源数据集,覆盖《全唐诗》《宋词三百首》等经典典籍。 - 数据清洗:通过
Pandas库去除HTML标签、特殊字符,使用正则表达式标准化文本格式。例如,对《静夜思》文本进行清洗后,保留“床前明月光,疑是地上霜”的纯净内容。 - 实体标注:采用
Jieba分词库结合自定义词典(如添加“孤舟”“残月”等古诗词术语),识别诗人、朝代、意象等核心实体。例如,对“李白创作了《静夜思》”进行分词后,标注“李白”为诗人实体,“《静夜思》”为诗作实体。
1.2 存储层:图数据库优化查询
- Neo4j图数据库:存储三元组关系(如“诗人-创作-诗作”“诗作-引用-诗作”),支持Cypher查询语言实现高效检索。例如,通过
MATCH (p:Poet)-[:WRITES]->(poem:Poem) RETURN p, poem可快速获取诗人及其作品列表。 - 数据建模:定义节点属性(如诗人节点包含“姓名”“朝代”“生平事迹”,诗作节点包含“标题”“内容”“创作时间”),关系属性(如“创作时间”“引用次数”),构建多维度知识图谱。
1.3 处理层:NLP与深度学习融合
- 实体关系抽取:结合规则匹配(如“朝代+人名”识别诗人)与依存句法分析(如通过“主语-谓语-宾语”结构抽取“诗人-作品”关系),提升抽取准确性。例如,对“王维送元二使安西”解析为“王维(主语)-送(谓语)-元二使安西(宾语)”,建立诗人与诗作的关联。
- 情感分析模型:采用
LSTM与BERT模型捕捉上下文语义。例如,LSTM模型在《虞美人》情感分析中,通过序列数据学习“春花秋月何时了”到“一江春水向东流”的情感递进,预测情感强度MAE(平均绝对误差)≤0.8。
1.4 可视化层:动态交互与多维度展示
- D3.js:基于数据驱动文档(Data-Driven Documents)实现力导向布局,模拟节点间引力作用,使诗人社交网络分布均匀。例如,展示李白与杜甫、孟浩然等诗人的创作交流关系。
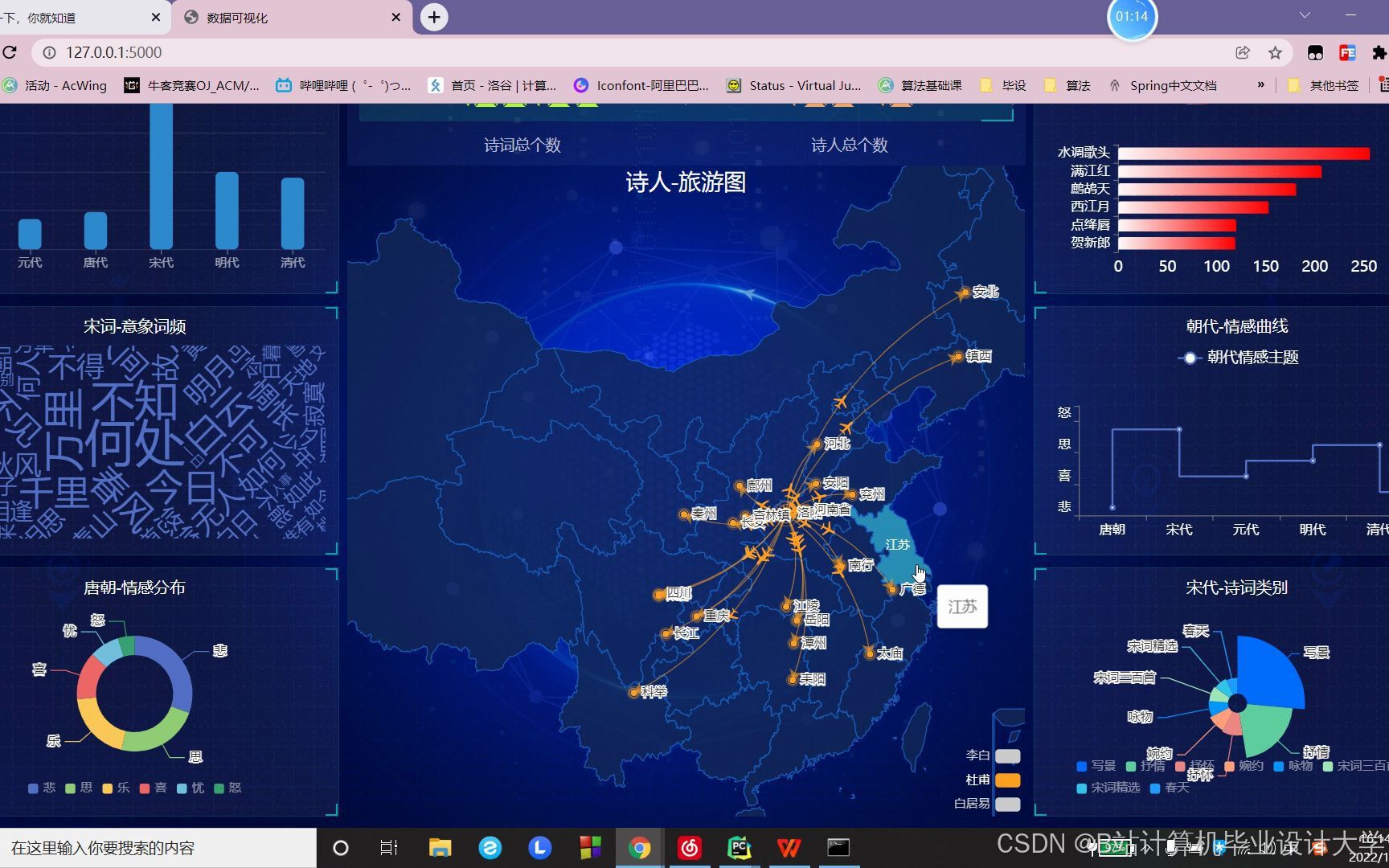
- Pyecharts:集成ECharts库,支持关系图、桑基图等多图表类型。例如,用桑基图呈现“月亮”意象在唐宋诗词中的空间密度变化,直观反映文化传播路径。
- Flask框架:构建Web后端,提供RESTful API供前端调用。例如,用户查询“王维”,后端返回其作品列表及情感分析结果,前端以柱状图展示情感分布。
二、关键技术实现流程
2.1 数据预处理与实体标注
python
import pandas as pd | |
import jieba | |
from py2neo import Graph | |
# 加载诗词数据 | |
df = pd.read_csv("chinese_poetry.csv") | |
# 自定义词典添加古诗词术语 | |
jieba.load_userdict("poetry_terms.txt") | |
# 分词与实体标注 | |
def annotate_entities(text): | |
words = jieba.lcut(text) | |
entities = [] | |
for word in words: | |
if word in ["李白", "杜甫"]: # 诗人实体 | |
entities.append(("Poet", word)) | |
elif word in ["唐", "宋"]: # 朝代实体 | |
entities.append(("Dynasty", word)) | |
return entities | |
df["entities"] = df["content"].apply(annotate_entities) |
2.2 知识图谱构建与存储
python
# 连接Neo4j数据库 | |
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password")) | |
# 批量导入数据 | |
def import_to_neo4j(df): | |
for _, row in df.iterrows(): | |
# 创建诗人节点 | |
poet_query = """ | |
MERGE (p:Poet {name: $name}) | |
SET p.dynasty = $dynasty | |
""" | |
graph.run(poet_query, name=row["author"], dynasty=row["dynasty"]) | |
# 创建诗作节点 | |
poem_query = """ | |
MERGE (poem:Poem {title: $title, content: $content}) | |
""" | |
graph.run(poem_query, title=row["title"], content=row["cleaned"]) | |
# 建立“创作”关系 | |
rel_query = """ | |
MATCH (p:Poet {name: $name}), (poem:Poem {title: $title}) | |
MERGE (p)-[:WRITES]->(poem) | |
""" | |
graph.run(rel_query, name=row["author"], title=row["title"]) |
2.3 可视化系统实现
python
from pyecharts import options as opts | |
from pyecharts.charts import Graph | |
# 构建诗人社交网络图 | |
def visualize_poet_network(): | |
# 从Neo4j查询关系数据 | |
cypher_query = """ | |
MATCH (p1:Poet)-[r]-(p2:Poet) | |
RETURN p1.name as source, p2.name as target, count(r) as weight | |
""" | |
results = graph.run(cypher_query).data() | |
# 构建图数据 | |
nodes = [{"name": r["source"], "symbolSize": 10 + r["weight"] * 2}] | |
links = [{"source": r["source"], "target": r["target"], "value": r["weight"]}] | |
# 渲染图表 | |
graph_chart = ( | |
Graph() | |
.add("", nodes, links, repulsion=500) | |
.set_global_opts(title_opts=opts.TitleOpts(title="诗人社交网络")) | |
) | |
graph_chart.render("poet_network.html") |
三、技术挑战与解决方案
3.1 实体消歧
- 问题:同名词人(如“南宋李白”)导致数据混淆。
- 方案:结合朝代信息与诗词风格特征进行聚类。例如,通过
TF-IDF提取诗词关键词,计算与已知诗人作品的余弦相似度,区分不同朝代同名诗人。
3.2 大规模可视化性能优化
- 问题:超过10,000个节点的网络图渲染卡顿。
- 方案:
- WebWorker多线程渲染:将数据加载与渲染任务分配至不同线程。
- 力导向布局简化算法:采用
Barnes-Hut近似算法降低计算复杂度。 - 分级展示:默认展示核心节点(如李白、杜甫),用户点击后动态加载关联节点。
3.3 跨模态语义对齐
- 问题:诗词韵律特征(如平仄)与书法笔画动力学参数(如速度、压力)难以关联。
- 方案:借鉴斯坦福大学“LyricLens”工具方法,构建多模态对齐模型。例如,通过
LSTM编码诗词韵律特征,与书法笔画的时间序列数据进行对齐分析。
四、应用场景与案例
4.1 文化研究工具
- 意象演变分析:通过桑基图展示“月亮”意象在唐宋诗词中的使用频率变化,发现唐代边塞诗中“月亮”多象征思乡,而宋代婉约词中多表达孤独。
- 诗人社交网络:展示王维与裴迪的唱和记录,分析唐代文人社交模式。
4.2 教育辅助系统
- 诗词推荐:基于用户兴趣图谱推荐相似诗词。例如,喜欢“边塞诗”的用户可收到王昌龄《从军行》推荐。
- 课堂互动:教师点击李白节点,展示其生平、作品及情感分析结果,辅助讲解《将进酒》的豪放风格。
4.3 文化旅游导览
- AR增强现实:在杭州西湖景区部署AR设备,游客扫描“苏堤春晓”碑刻时,系统自动展示苏轼相关诗词、历史背景及情感分析结果,并推荐周边景点对应的诗词作品。
五、未来展望
随着AI大模型与多模态技术的融合,古诗词可视化将迈向更高阶段:
- 多模态知识图谱:结合语音识别分析吟诵音调变化,或通过脑电信号解码用户情感反应,实现“文本-音频-生理信号”三模态融合。
- 跨学科协作深化:联合文学院专家构建“古诗词情感本体库”,定义“壮志未酬”“羁旅愁思”等复杂情感类别,并标注其在不同朝代诗词中的表现强度。
- 全球化传播:开发多语言版本可视化系统,支持英文、日文等翻译对照,助力中华文化国际传播。
Python知识图谱技术为古诗词的数字化传承提供了创新工具,通过结构化数据与可视化交互,让千年诗韵焕发新生。
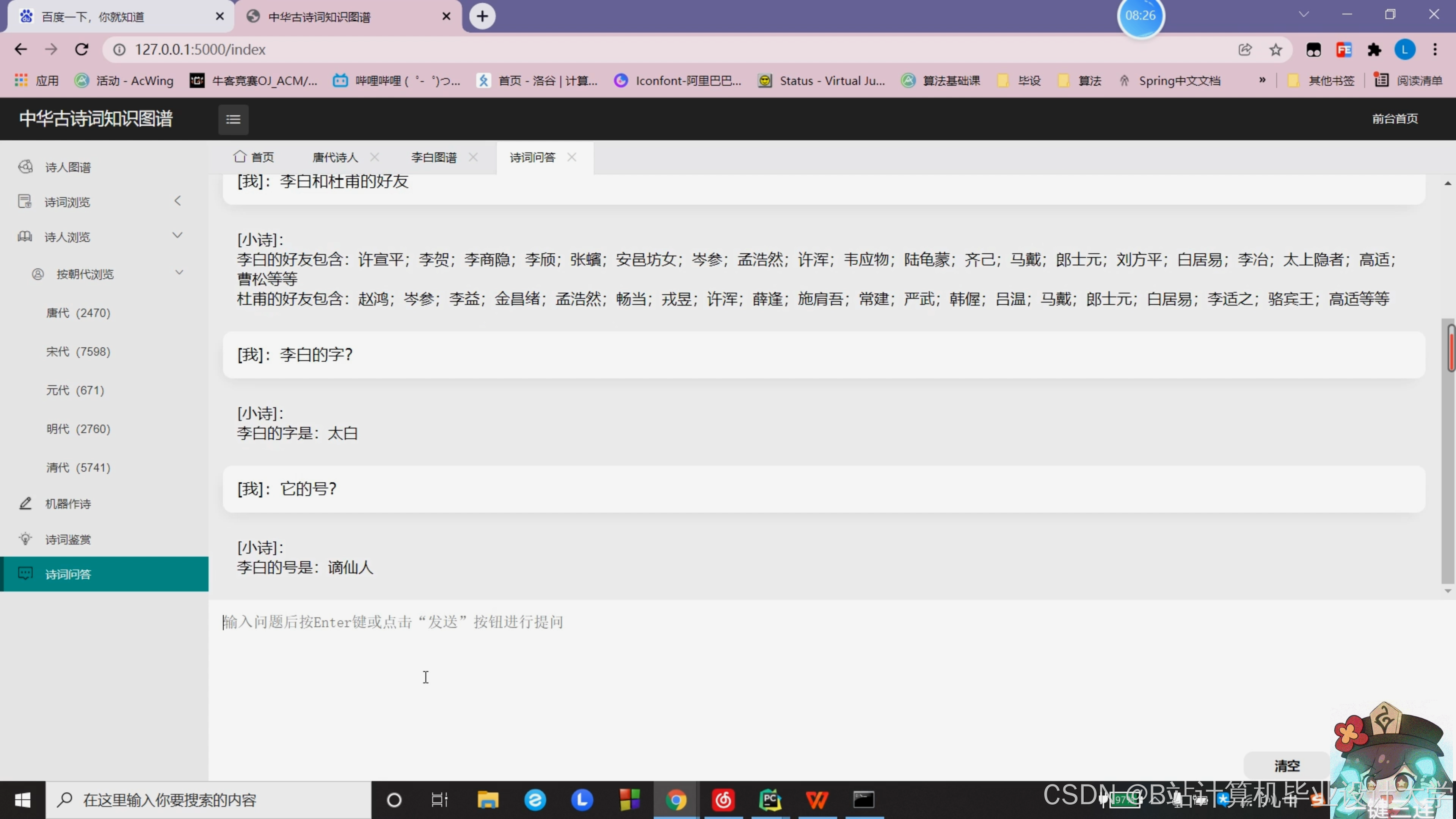
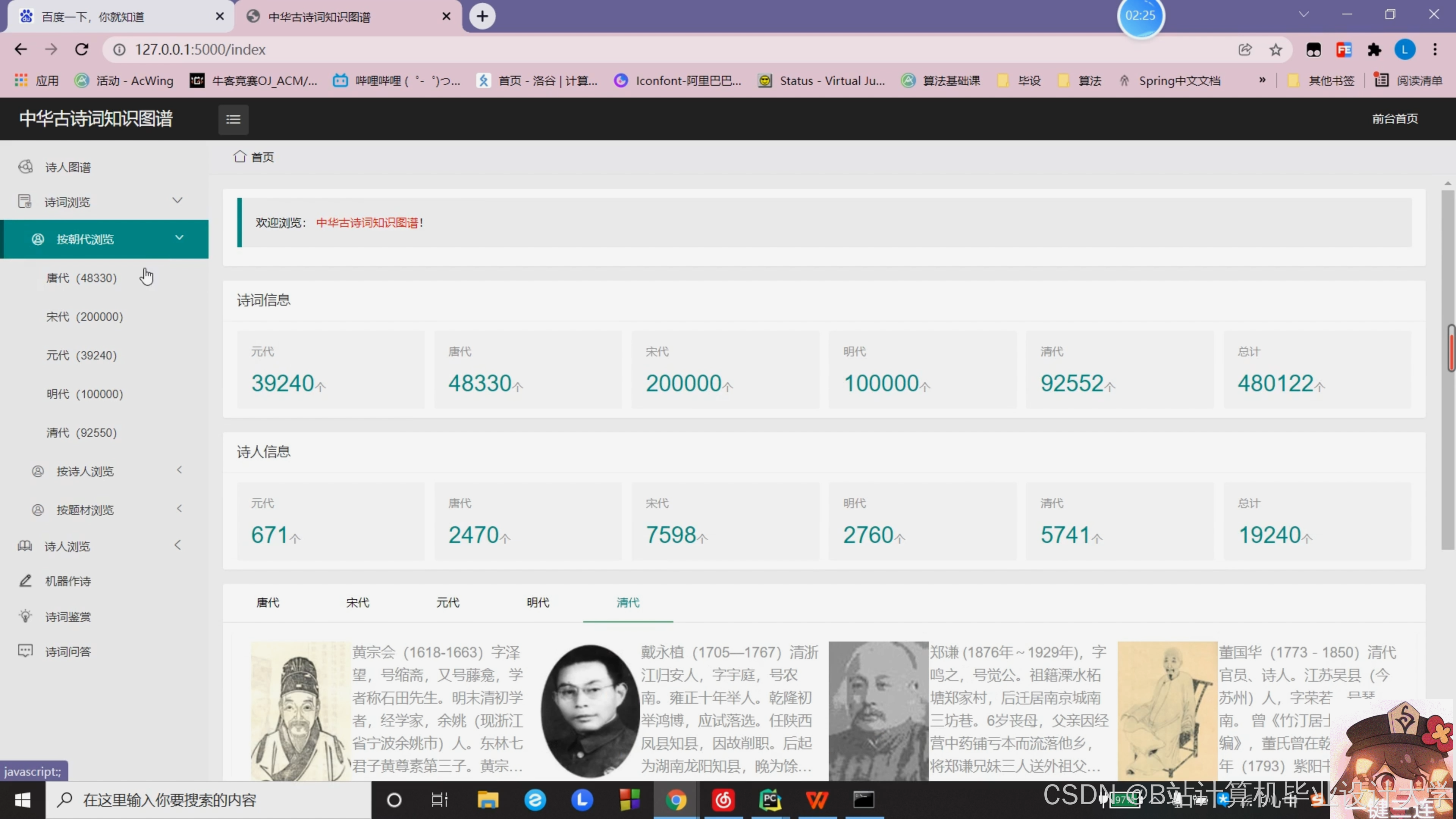
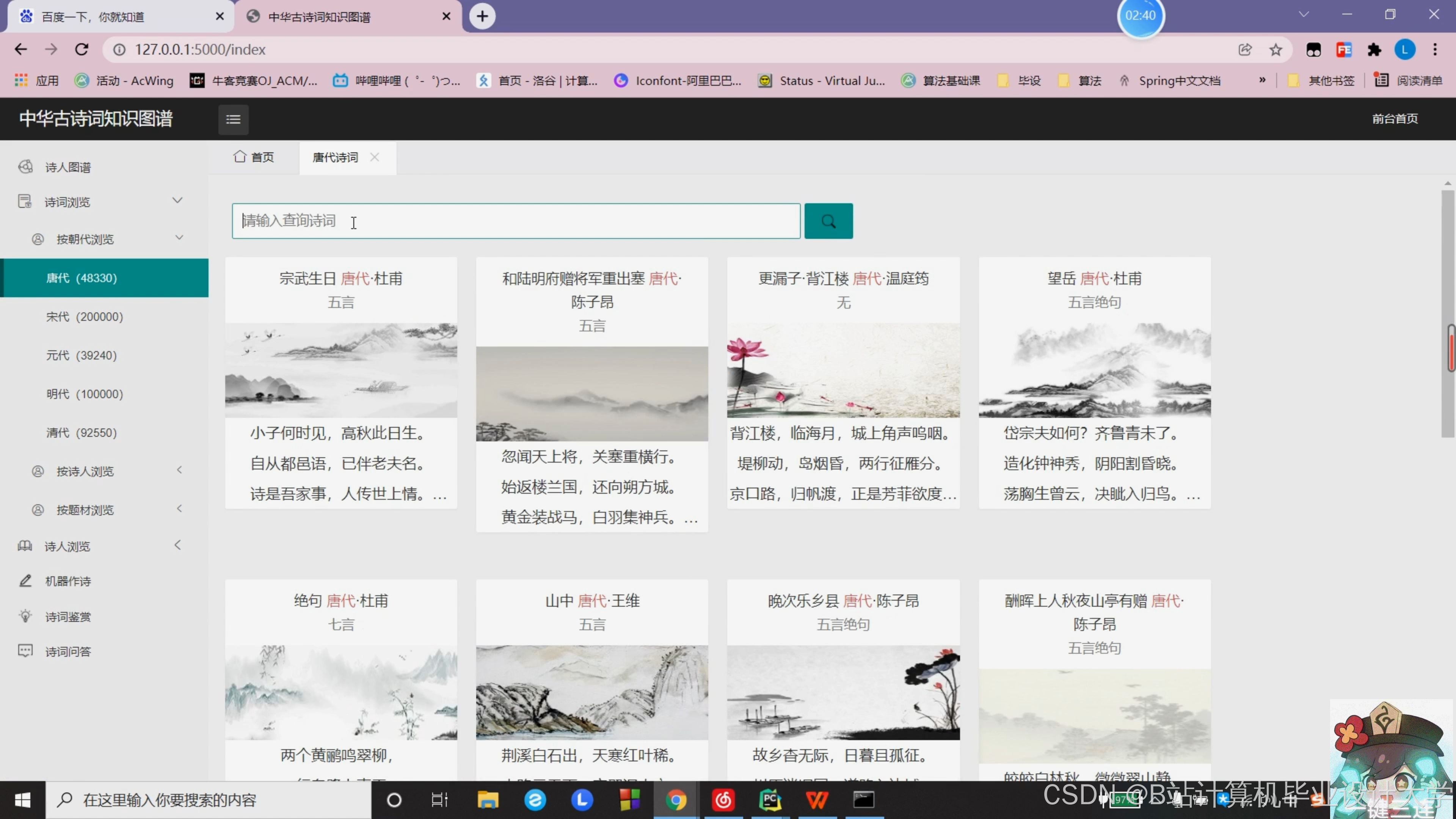
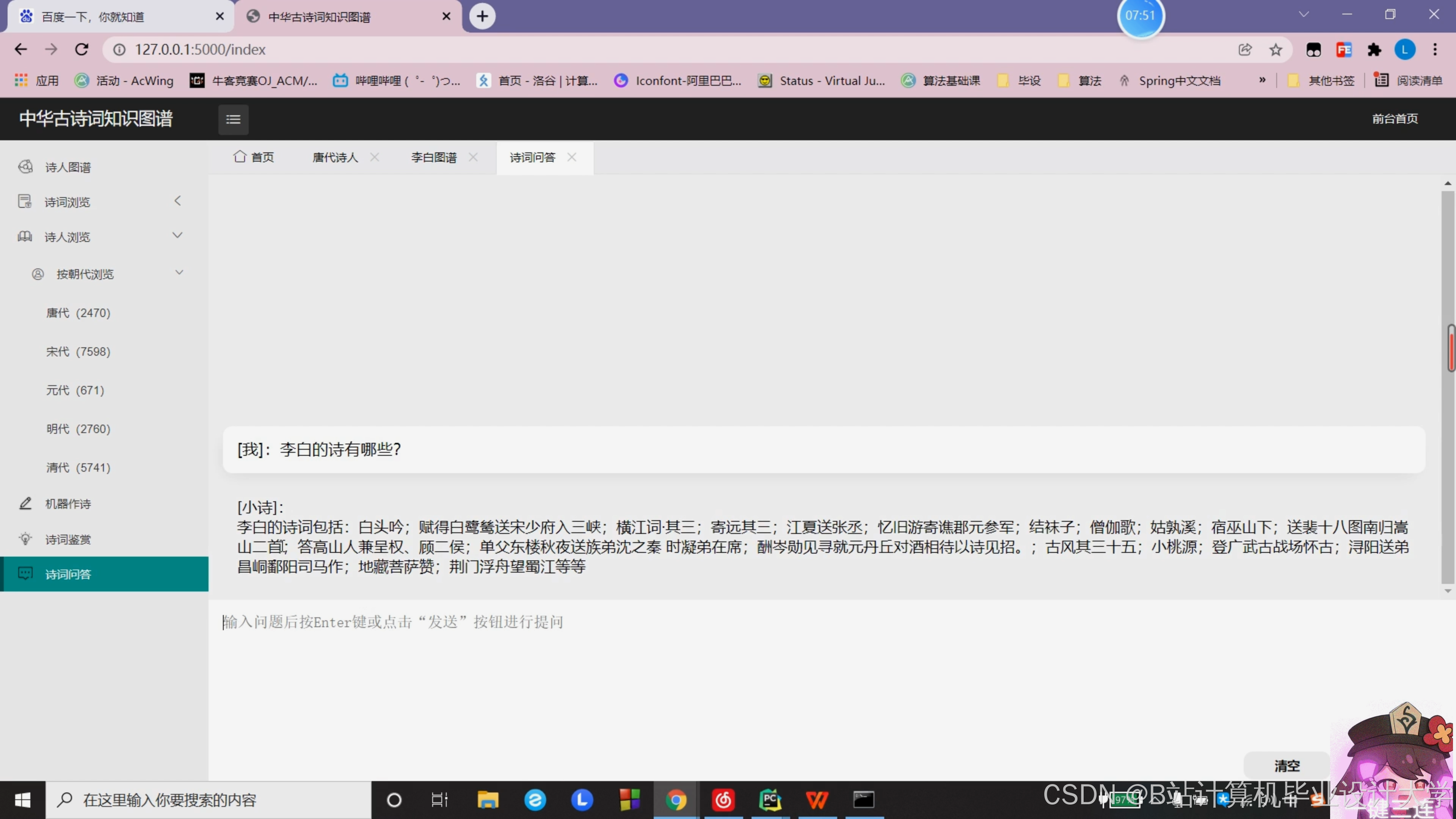
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











