




目录
3.2.3 MicrosoftTranslateManager 处理音频以及文本输出
1 目前方案
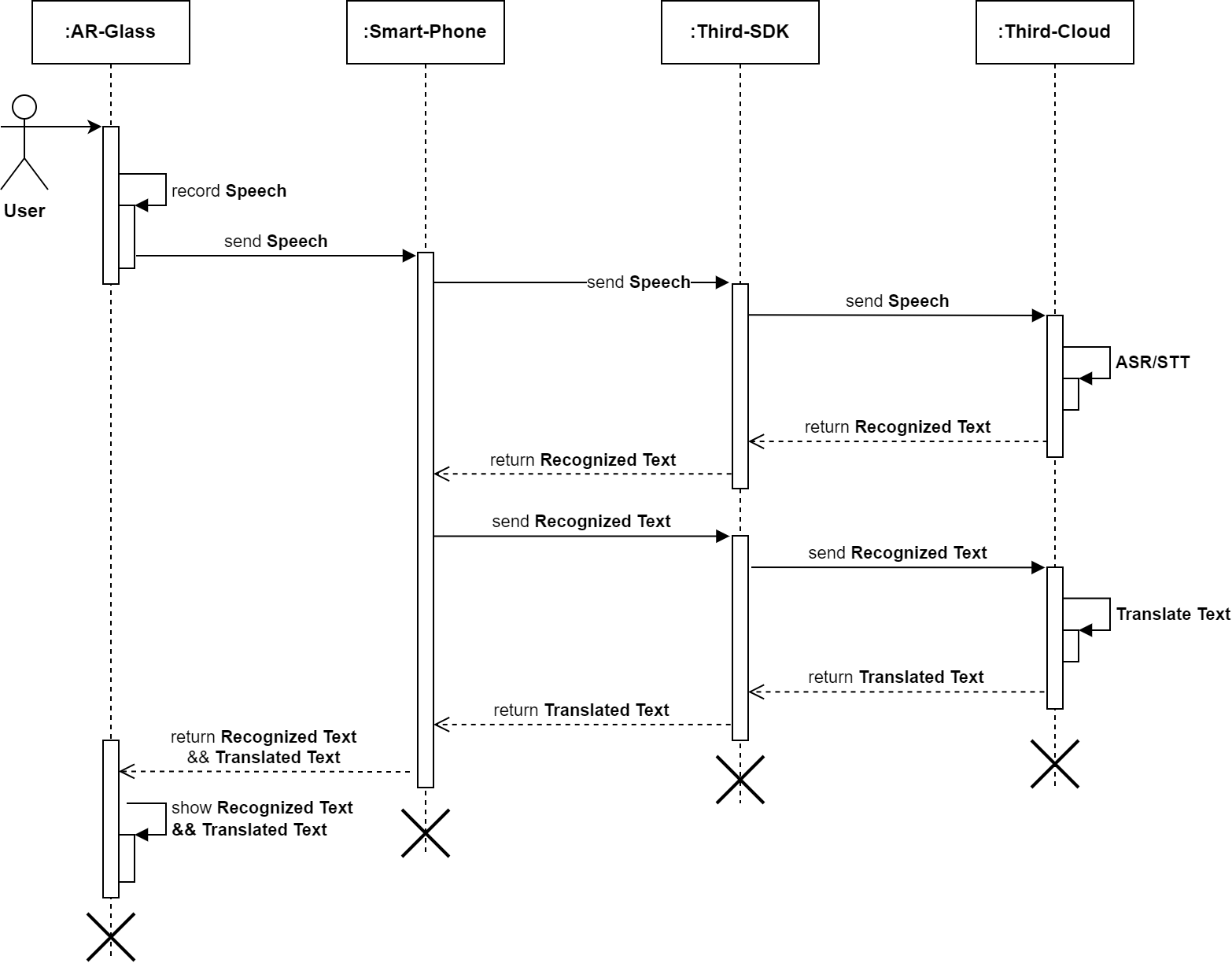
技术方案:Speech+ASR/STT+Translate,区分国内/国际。
-
国内:ASR/STT使用讯飞,Translate使用公司后台接口(后台内部使用Google Translate);
-
国际:ASR/STT使用谷歌/微软,Translate使用公司后台接口(后台内部使用Google Translate);
2 方案调研
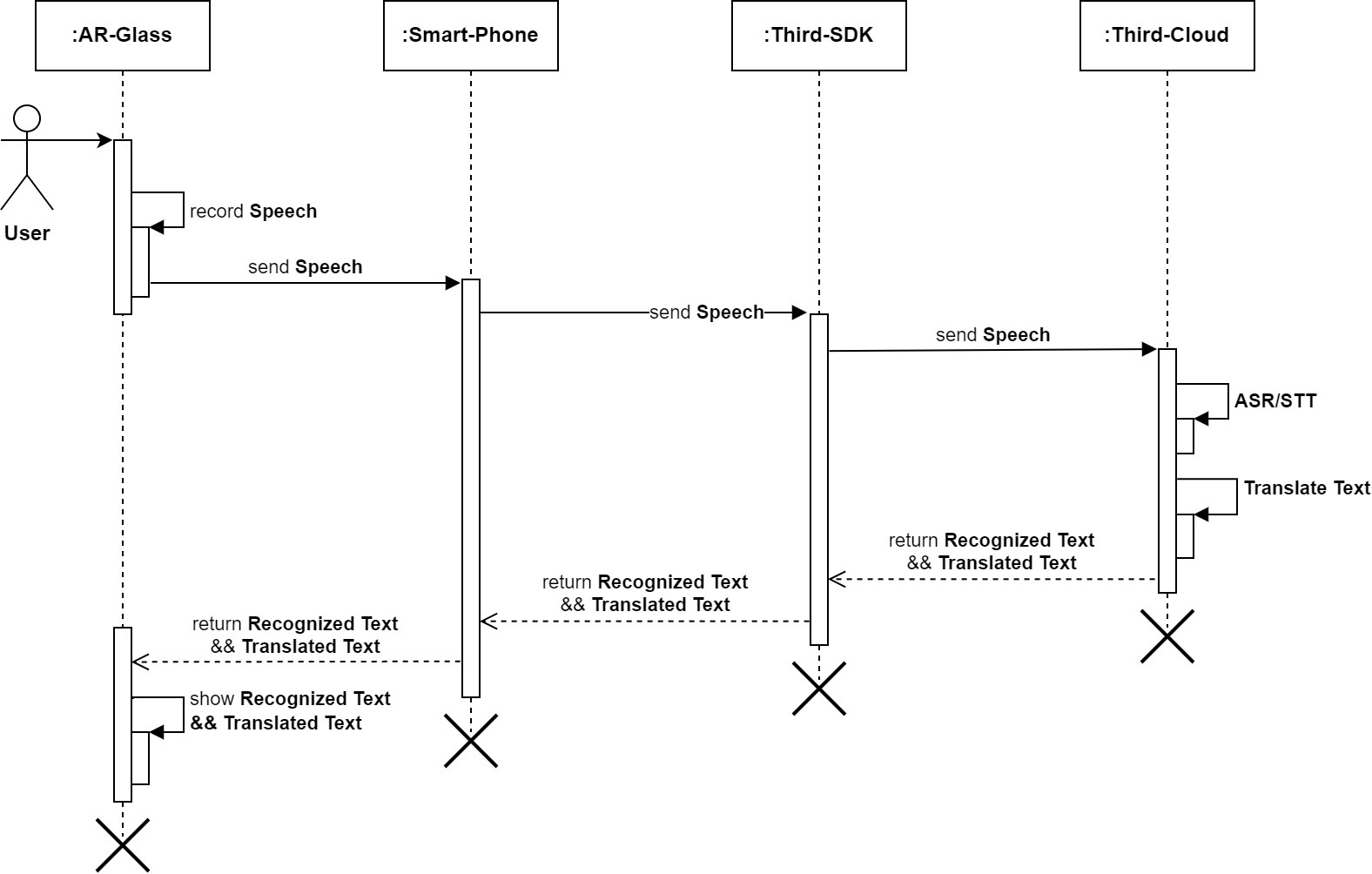
技术方案:Speech+Translate,不区分国内/国际。
2.1 国内方案调研
2.1.1 国内方案调研——讯飞
-
目前只支持中文-英文的互译,国际多语言场景需求暂不满足;
-
目前暂不支持源语言的自动识别,默认中英文模式(中文英文均可识别);
——parameter.ist.language_type 语言过滤筛选,取值如下:
1:中英文模式,中文英文均可识别(默认)
2:中文模式,可识别出简单英文
3:英文模式,只识别出英文
4:纯中文模式,只识别出中文
注意:中文引擎支持该参数,其他语言不支持。
-
同声传译 API 文档:https://www.xfyun.cn/doc/nlp/simultaneous-interpretation/API.html;——讯飞STT(语音识别-语音听写)、TTS(语音合成-在线语音合成)都要单独付费开通,STT开通了普通话和英语,TTS开通了普通话,TTS可以试用英语等语言,TTS效果不佳可能是使用免费的播报导致
2.1.2 国内方案调研——阿里云百炼
-
gummy-realtime-v1 模型,目前只能在中国大陆使用,国际多语言场景需求暂不满足;
-
语音翻译——实时语音翻译-Gummy文档:https://help.aliyun.com/zh/model-studio/real-time-speech-translation;
-
语音翻译——实时长语音翻译(Gummy)-Android SDK:https://help.aliyun.com/zh/model-studio/android-sdk-for-gummy-1,源语言默认为auto。
2.1.3 国内方案调研——豆包
-
豆包语音同传大模型,目前只支持中英互译,国际多语言场景需求暂不满足,仅支持企业认证客户接入,个人客户暂不支持接入,目前只支持WebSocket协议接入;
-
Seed LiveInterpret 2.0,2025年7月推出,人工评测翻译准确率 74.8%,平均延迟低至 3 秒内,具有实时声音复刻功能;
-
火山引擎——豆包语音-同声传译2.0:https://www.volcengine.com/docs/6561/1631605。
2.1.4 国内方案调研——小结
| 维度 | 讯飞 | 阿里云百炼 (Gummy) | 豆包 (Seed LiveInterpret 2.0) |
| 多语种支持 | ❌ 仅中英 | ⚠️ 主要中英, 但可通过 language_code 支持部分国际语言(zh/en/ja/ko/yue/de/fr/ru/es/it/pt/id/ar/th) | ❌ 仅中英 |
| 自动识别源语言) | ❌ 不支持(必须设置 language_type) | ✔ 可设置 | ❌ 不支持自动识别(需指定 CH→EN / EN→CH) |
| 移动端 / AR 眼镜支持度 | ✔ 可支持(需自行封装 SDK + 多服务组合) | ✔ 官方 Android SDK,易于集成 | ✔ WebSocket 协议,可移动端接入但需自行封装 |
| 接入门槛 | 中等:STT/TTS 需分别付费;同传功能企业账号无法免费试用 | 中等:模型区域受限,仅中国大陆可用 | 高:仅企业客户可接入,同传接口不对个人开放 |
| 延迟表现 | 中等(官方未公布同传延迟,通常 2–5 秒) | 较低(实时语音翻译设计目标低延迟) | 很低(官方平均 <3 秒) |
| 翻译质量(中英) | 稳定、行业成熟度高 | 良好(Gummy 模型质量) | 较强(官方人工评测 74.8%) |
-
其他如百度智能云、腾讯云等方案,技术成熟但整体体验弱于主流三家;
-
当前百炼支持部分的多语种且自动识别,但只能在中国大陆使用;豆包延迟和翻译质量最好,讯飞已经接入STT和TTS,但讯飞和豆包只支持中英;
-
目前国内的方案,暂不同时满足多语言且国际国内都可用。
2.2 国际方案调研
2.2.1 国际方案调研——微软
-
目前可以满足,支持多语言、国内国际都可用、支持自动识别,缺点是比较贵;
-
语音服务文档-实时语音翻译:https://learn.microsoft.com/zh-cn/azure/ai-services/speech-service/speech-translation。
2.2.2 国际方案调研——谷歌
-
谷歌暂无语音翻译集成方案,需要通过:STT方案:https://cloud.google.com/speech-to-text + Translate方案:https://docs.cloud.google.com/translate;
-
谷歌国内不可用,不支持自动识别。
2.2.3 国际方案调研——小结
| 方案 | 多语言支持 | 自动语种识别 | 可用地区 | 价格 | 备注 |
| 微软 Azure | ✔ 76 种语言 | ✔ 自动识别 | 全球可用(含中国) | 较贵 | 提供一体化服务,实时翻译 |
| 谷歌 Cloud | ✔ 支持多语种(STT + Translate) | ❌ 不支持自动识别 | 国内不可用(需VPN) | 按需计费 | 需要手动组合多个API,延迟可能较高 |
-
首选微软:适合需要高质量、跨语言/跨地区、自动语种识别的实时语音翻译应用,虽然价格较高,但提供了一体化的实时语音翻译解决方案,且全球可用;
-
谷歌暂无语音翻译集成方案,国内不可用且不能自动识别,和现有方案一样,需要拆分为ASR/STT+Translate。
2.3 方案调研小结
-
目前国内国际通用,且支持多语言,以及自动识别,同时满足的方案只有微软方案;
-
如果区分国内国际,国际可用微软,国内可从百炼/豆包/讯飞方案择优选择。
3 微软方案验证
3.1 关键流程业务
SimultaneousTask:通过一个SimultaneousTask任务类,管理AR眼镜的音频输入、源语言与翻译语言文本输出到AR眼镜、以及实时翻译/同声传译功能的流程管理。
MicrosoftTranslateManager:实时翻译/同声传译功能实现的关键类,建立与Microsoft的API连接,将音频流传给Microsoft并从中获取源语言与翻译语言文本,同时通过回调对外提供实时翻译结果。
3.2 实时翻译技术实现
Gradle引入:implementation "com.microsoft.cognitiveservices.speech:client-sdk:1.47.0"
3.2.1 实时翻译初始化
初始化实时翻译的源语言、目标语言设置,并记录AR眼镜的拾音状态以及是否在实时翻译功能界面等。
class SimultaneousTask {
companion object {
val SIMULTANEOUS_SOURCE = "SIMULTANEOUS_SOURCE"
val SIMULTANEOUS_TARGET = "SIMULTANEOUS_TARGET"
val SIMULTANEOUS_SOURCE_DISPLAY = "SIMULTANEOUS_SOURCE_DISPLAY"
}
private val TAG = this::class.java.simpleName
private val SIMULTANEOUS_SOURCE_DISPLAY = "SIMULTANEOUS_SOURCE_DISPLAY"
private val MSG_STT_FINAL = 1
private var messageId: Byte = 0
private var languageCodeSource: String =
MMKV.defaultMMKV().decodeString(SIMULTANEOUS_SOURCE, StandardLanguage.ENGLISH.code)
.toString()
private var languageCodeTarget: String =
MMKV.defaultMMKV().decodeString(SIMULTANEOUS_TARGET, StandardLanguage.CHINESE.code)
.toString()
private var isSpeeching = false
private var isGlassBackground = false
init {
languageCodeSource =
MMKV.defaultMMKV().decodeString(SIMULTANEOUS_SOURCE, StandardLanguage.ENGLISH.code)
.toString()
languageCodeTarget =
MMKV.defaultMMKV().decodeString(SIMULTANEOUS_TARGET, StandardLanguage.CHINESE.code)
.toString()
MicrosoftTranslateManager.getInstance().initTranslate(languageCodeSource, languageCodeTarget)
MicrosoftTranslateManager.getInstance().addTranslateCallback(translateCallback)
isGlassBackground = false
}
}3.2.2 获取 AR 眼镜音频输入
获取AR眼镜的音频输入,并最终会将音频送到MicrosoftTranslateManager音频处理模块。
其中,目前方案需要将AR眼镜的Opus音频格式数据,解包并转化为PCM格式后传给Microsoft;但据了解Microsoft是支持ogg封装的Opus格式输入,后期可讨论优化流程。
override fun onStream(
p0: String?,
p1: BizType?,
p2: Int,
p3: Short,
p4: Short,
p5: Byte,
p6: Int,
byteArray: ByteArray?
) {
Log.i(TAG, "onStream isSpeeching:$isSpeeching, isGlassBackground:$isGlassBackground")
if (isSpeeching && !isGlassBackground) {
byteArray?.let {
MicrosoftTranslateManager.getInstance().sendTranslateAudioStream(it, source = 8)
}
}
}3.2.3 MicrosoftTranslateManager 处理音频以及文本输出
需要去微软申请SPEECH_SUBSCRIPTION_KEY,同时验证region使用“”eastasia”时,在国内国际IP都可以使用微软提供的实时翻译功能。
class MicrosoftTranslateManager {
private var translateCallbacks = LinkedList<MicrosoftTranslateCallback>()
private var sourceLanguageCode = StandardLanguage.CHINESE.code
private var translateLanguageCode = StandardLanguage.ENGLISH.code
private var speechTranslationConfig: SpeechTranslationConfig? = null
private var pushAudioInputStream = PushAudioInputStream.create()
private var translationRecognizer: TranslationRecognizer? = null
private val mHandler = Handler(Looper.getMainLooper())
private var isRecognizing = false
private var streamInited = false
private var tempInited = false
companion object {
private const val SPEECH_SUBSCRIPTION_KEY = "***"
private const val SERVICE_REGION = "eastasia"
private val TAG = "MicrosoftTranslate"
private val mInstance by lazy { MicrosoftTranslateManager() }
fun getInstance(): MicrosoftTranslateManager = mInstance
}
fun initTranslate(source: String, translate: String) {
Log.i(TAG, "initTranslate: source=$source,translate=$translate")
sourceLanguageCode = source
translateLanguageCode = translate
speechTranslationConfig =
SpeechTranslationConfig.fromSubscription(SPEECH_SUBSCRIPTION_KEY, SERVICE_REGION)
try {
if (isRecognizing) {
translationRecognizer?.stopContinuousRecognitionAsync()
removeEventListener()
streamInited = false
isRecognizing = false
mHandler.removeCallbacksAndMessages(null)
}
} catch (e: Exception) {
Log.e(TAG, "setLanguageCode ERROR:${e.message}")
}
}
fun addTranslateCallback(listener: MicrosoftTranslateCallback) {
synchronized(this) {
if (!translateCallbacks.contains(listener)) translateCallbacks.add(listener)
Log.i(TAG, "addTranslateCallback size:${translateCallbacks.size}")
}
}
fun sendAudioStream(data: ByteArray) {
try {
if (!isRecognizing) {
Log.i(TAG, "sendAudioStream start")
isRecognizing = true
streamInited = false
mHandler.postDelayed({ startRecognition() }, 200)
}
if (streamInited) pushAudioInputStream.write(data)
if (streamInited != tempInited) {
tempInited = streamInited
Log.i(TAG, "sendAudioStream data, streamInited:$streamInited")
}
} catch (e: Exception) {
Log.e(TAG, "sendAudioStream ERROR:${e.message}")
}
}
fun stopAudioStream() {
Log.i(TAG, "stopAudioStream isRecognizing:$isRecognizing")
try {
if (isRecognizing) {
streamInited = false
isRecognizing = false
mHandler.removeCallbacksAndMessages(null)
translationRecognizer?.stopContinuousRecognitionAsync()
removeEventListener()
}
} catch (e: Exception) {
Log.e(TAG, "stopAudioStream ERROR:${e.message}")
}
}
fun removeTranslateCallback(listener: MicrosoftTranslateCallback) {
synchronized(this) {
if (translateCallbacks.contains(listener)) translateCallbacks.remove(listener)
Log.i(TAG, "removeTranslateCallback size:${translateCallbacks.size}")
}
}
fun releaseTranslate() {
Log.i(TAG, "releaseTranslate")
try {
if (isRecognizing) translationRecognizer?.stopContinuousRecognitionAsync()
translationRecognizer?.close()
speechTranslationConfig?.close()
speechTranslationConfig = null
mHandler.removeCallbacksAndMessages(null)
} catch (e: Exception) {
// TODO:
Log.e(TAG, "release ERROR:${e.message}")
}
}
private fun startRecognition() {
Log.i(TAG, "startRecognition: isRecognizing=$isRecognizing")
try {
if (isRecognizing) {
initStreamInput()
translationRecognizer?.recognizeOnceAsync()
streamInited = true
mHandler.removeCallbacksAndMessages(null)
}
} catch (e: Exception) {
Log.e(TAG, "startRecognition ERROR:${e.message}")
}
}
private fun initStreamInput() {
Log.i(TAG, "initStreamInput")
try {
removeEventListener()
val audioConfig = AudioConfig.fromStreamInput(pushAudioInputStream)
speechTranslationConfig?.speechRecognitionLanguage =
getSpeechLanguage(sourceLanguageCode)
speechTranslationConfig?.addTargetLanguage(getTranslateLanguage(translateLanguageCode))
translationRecognizer = TranslationRecognizer(speechTranslationConfig, audioConfig)
addEventListener()
} catch (e: Exception) {
Log.e(TAG, "initStreamInput ERROR:${e.message}")
mHandler.postDelayed({
initStreamInput()
}, 200)
}
}
private fun getSpeechLanguage(code: String): String {
return when (code) {
StandardLanguage.ENGLISH.code -> MicrosoftLanguage.ENGLISH.code
StandardLanguage.CHINESE.code -> MicrosoftLanguage.CHINESE.code
else -> MicrosoftLanguage.ENGLISH.code
}
}
private fun getTranslateLanguage(code: String): String {
return when (code) {
StandardLanguage.ENGLISH.code -> "en-US"
StandardLanguage.CHINESE.code -> "zh-Hans"
else -> "zh-Hans"
}
}
private fun addEventListener() {
translationRecognizer?.apply {
sessionStarted?.addEventListener(startEvent)
sessionStopped?.addEventListener(stopEvent)
recognizing?.addEventListener(recognizingEvent)
recognized?.addEventListener(recognizedEvent)
canceled?.addEventListener(canceledEvent)
}
}
private fun removeEventListener() {
translationRecognizer?.apply {
sessionStarted?.removeEventListener(startEvent)
sessionStopped?.removeEventListener(stopEvent)
recognizing?.removeEventListener(recognizingEvent)
recognized?.removeEventListener(recognizedEvent)
canceled?.removeEventListener(canceledEvent)
}
}
private var startEvent = EventHandler<SessionEventArgs?> { sender, e ->
Log.i(TAG, "onStart")
translateCallbacks.forEach { it.onStart() }
}
private var stopEvent = EventHandler<SessionEventArgs> { sender, e ->
Log.i(TAG, "onStop")
translateCallbacks.forEach { it.onComplete() }
removeEventListener()
isRecognizing = false
streamInited = false
}
private var recognizingEvent = EventHandler<TranslationRecognitionEventArgs> { sender, e ->
// 流式识别到的内容
val source = e.result.text
Log.i(TAG, "recognizing, source=${source}, translate:${e.result.translations}")
for ((language, translation) in e.result.translations) {
translateCallbacks.forEach { it.onTranslated(false, source, translation) }
}
}
private var recognizedEvent = EventHandler<TranslationRecognitionEventArgs> { sender, e ->
// 识别到的最终结果
val source = e.result.text
Log.i(TAG, "recognized, source=${source}, translate:${e.result.translations}")
for ((language, translation) in e.result.translations) {
translateCallbacks.forEach { it.onTranslated(true, source, translation) }
}
}
private var canceledEvent = EventHandler<TranslationRecognitionCanceledEventArgs> { sender, e ->
Log.i(TAG, "onCanceled:$e")
translateCallbacks.forEach { it.onError(e.toString()) }
}
}interface MicrosoftTranslateCallback {
fun onStart()
fun onTranslated(isFinal: Boolean, text: String, trans: String)
fun onComplete()
fun onError(message: String)
}
enum class StandardLanguage(val code: String) {
CHINESE("zh-CN"), ENGLISH("en"),
}
/**
* 微软STT&TTS。
*
* 参考:https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=stt
*/
enum class MicrosoftLanguage(val code: String, val voiceName: String) {
CHINESE("zh-CN", "zh-CN-XiaomoNeural"), // 简体中文
TAIWAN("zh-TW", "zh-TW-HsiaoChenNeural"), // 繁体中文
JAPANESE("ja-JP", "ja-JP-NanamiNeural"), // 日语
ENGLISH("en-US", "en-US-AvaMultilingualNeural"), // 英语
SPANISH("es-ES", "es-ES-ElviraNeural"), // 西班牙语
FRENCH("fr-FR", "fr-FR-DeniseNeural"), // 法语
PT("pt-PT", "pt-PT-RaquelNeural"), // 葡萄牙语
VI("vi-VN", "vi-VN-HoaiMyNeural"), // 越南牙语
GERMAN("de-DE", "de-DE-KatjaNeural"), // 德语
}3.2.4 SimultaneousTask 处理文本返回
监听实时翻译接口MicrosoftTranslateCallback,onTranslated方法中获取到文本内容后,调用蓝牙私有协议将文本传给AR眼镜做显示。
private val translateCallback = object : MicrosoftTranslateCallback {
override fun onStart() {}
override fun onComplete() {}
override fun onTranslated(isFinal: Boolean, text: String, trans: String) {
if (isGlassBackground) return
mHandler.removeMessages(MSG_STT_FINAL)
Log.i(TAG, "msgId:$messageId, isFinal:${isFinal},text:${text}, trans:${trans}")
if (isFinal) {
mHandler.sendEmptyMessage(MSG_STT_FINAL)
if (trans.isEmpty()) {
nextRecord()
}
} else {
if (trans.isNotEmpty()) {
mHandler.sendEmptyMessageDelayed(MSG_STT_FINAL, 2000)
}
}
if (trans.isNotEmpty()) {
languageCodeTarget = MMKV.defaultMMKV()
.decodeString(SIMULTANEOUS_TARGET, StandardLanguage.CHINESE.code).toString()
translate(isFinal, text, trans)
}
}
override fun onError(message: String) {
if (isGlassBackground) return
Log.e(TAG, "onError:${message}")
mHandler.sendEmptyMessage(MSG_STT_FINAL)
nextRecord()
}
}
private fun translate(isFinal: Boolean, text: String, trans: String) {
if (isGlassBackground) return
DeviceManager.getInstance().sendCommData(
CommSimulContent(
messageId,
if (MMKV.defaultMMKV().decodeBool(SIMULTANEOUS_SOURCE_DISPLAY, true)) text else "",
trans
)
)
Log.i(TAG, "Translated: msgId:$messageId, isFinal:$isFinal, text:\$, trans:$trans")
if (isFinal) nextRecord()
}3.2.5 实时翻译结束
fun release() {
MicrosoftTranslateManager.getInstance().stopTranslateAudioStream()
MicrosoftTranslateManager.getInstance().releaseTranslate()
MicrosoftTranslateManager.getInstance().removeTranslateCallback(translateCallback)
messageId = 1
isGlassBackground = false
}3.3 实时翻译效果小结
目前看中英互译的效果还不错,同时国内国际通用、支持多语言、以及自动识别。
总的来说,微软方案可行。

















 1914
1914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









