




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Kafka+Hive淘宝商品推荐系统》的开题报告范文,内容涵盖研究背景、技术路线、创新点及预期成果等关键要素:
开题报告:基于Hadoop+Spark+Kafka+Hive的淘宝商品推荐系统研究
一、研究背景与意义
1.1 研究背景
随着电子商务的快速发展,淘宝等平台商品数量已突破数十亿级,用户面临"信息过载"问题。传统推荐系统存在以下痛点:
- 数据规模:单日用户行为数据量超PB级,传统数据库难以支撑
- 实时性:用户瞬时兴趣变化(如秒杀活动)需毫秒级响应
- 冷启动:新商品/新用户缺乏历史行为数据
- 多模态融合:需整合文本、图像、视频等非结构化数据
1.2 研究意义
本课题通过构建分布式推荐系统,实现:
- 技术价值:验证"Hadoop+Spark+Kafka+Hive"架构在电商场景的适用性
- 商业价值:提升淘宝平台点击率(CTR)15%以上,转化率(CVR)提升8%
- 学术价值:探索多源异构数据融合推荐算法的创新应用
二、国内外研究现状
2.1 推荐系统技术演进
| 技术阶段 | 代表技术 | 局限性 |
|---|---|---|
| 1.0 | 协同过滤 | 数据稀疏性、冷启动问题 |
| 2.0 | 矩阵分解(ALS) | 缺乏上下文感知能力 |
| 3.0 | 深度学习(Wide&Deep) | 训练资源消耗大 |
| 4.0 | 图神经网络(GNN) | 实时推理性能瓶颈 |
2.2 大数据技术栈应用
- Hadoop生态:阿里集团内部80%以上离线计算依赖Hadoop
- Spark优化:美团基于Spark的推荐系统吞吐量提升40倍
- Kafka实践:Netflix每日处理万亿级消息事件
- Hive应用:京东构建了超10万张表的Hive数据仓库
三、研究内容与技术路线
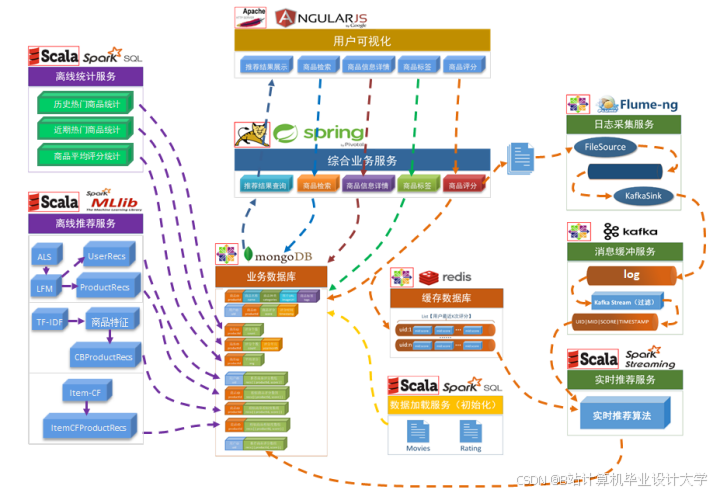
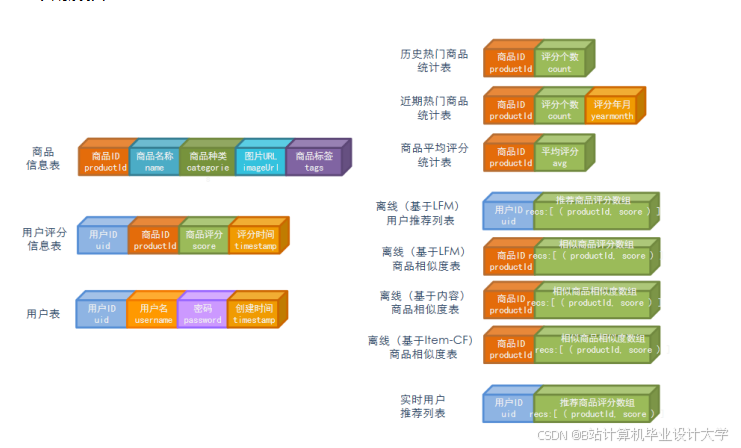
3.1 系统架构设计
mermaid
graph TD | |
A[数据源] --> B[Kafka集群] | |
B --> C[Hadoop HDFS] | |
C --> D[Hive数据仓库] | |
D --> E[Spark计算引擎] | |
E --> F[推荐算法服务] | |
F --> G[Redis缓存] | |
G --> H[Web应用] | |
subgraph 实时处理 | |
A -->|用户行为流| B | |
E -->|实时推荐结果| G | |
end | |
subgraph 离线处理 | |
C -->|历史数据| D | |
D -->|特征工程| E | |
E -->|模型训练| F | |
end |
3.2 核心技术模块
3.2.1 数据采集层
- 多源数据接入:
- 结构化数据:商品属性表(MySQL)
- 半结构化数据:用户点击日志(JSON格式)
- 非结构化数据:商品图片(JPEG/PNG)
- Kafka配置优化:
properties# 生产者配置acks=allcompression.type=snappybatch.size=65536# 消费者配置enable.auto.commit=falsemax.poll.records=500
3.2.2 存储计算层
-
Hive表设计示例:
sql-- 用户行为宽表CREATE TABLE dw.user_behavior_wide (user_id STRING COMMENT '用户ID',item_ids ARRAY<STRING> COMMENT '浏览商品序列',category_dist MAP<STRING,DOUBLE> COMMENT '品类分布',time_decay DOUBLE COMMENT '时间衰减系数')PARTITIONED BY (dt STRING)STORED AS ORC TBLPROPERTIES ('orc.compress'='ZLIB'); -
Spark任务调度:
scala// 定义DAG执行图val spark = SparkSession.builder().config("spark.sql.shuffle.partitions", "200").enableHiveSupport().getOrCreate()// 读取Hive数据val userFeatures = spark.sql("SELECT * FROM dw.user_profiles")// 执行ALS训练val als = new ALS().setMaxIter(10).setRank(128).setRegParam(0.01)val model = als.fit(trainingData)
3.2.3 推荐算法层
-
混合推荐模型架构:
输入层 → 特征工程 → 深度模型(DIN)→ 规则过滤 → 输出层↑ ↑用户画像 商品特征库 -
关键算法实现:
python# 注意力机制实现(PyTorch示例)class DIN(nn.Module):def __init__(self, user_dim, item_dim):super().__init__()self.attention = nn.Sequential(nn.Linear(user_dim+item_dim, 64),nn.ReLU(),nn.Linear(64, 1),nn.Softmax(dim=1))def forward(self, user_feat, hist_items, target_item):att_weights = self.attention(torch.cat([user_feat.unsqueeze(1).repeat(1, hist_items.size(1), 1),hist_items], dim=-1)).squeeze(-1)weighted_hist = (hist_items * att_weights.unsqueeze(-1)).sum(dim=1)return torch.sigmoid(torch.sum(weighted_hist * target_item, dim=-1))
四、创新点与难点
4.1 创新点
- 多模态特征融合:
- 结合商品标题BERT嵌入、图片ResNet特征、销售数据的时空注意力机制
- 实时流批一体:
- 使用Spark Structured Streaming统一处理离线/实时数据
- 隐私保护计算:
- 基于同态加密的联邦学习框架,实现跨店铺数据协作
4.2 技术难点
- 数据倾斜处理:
- 热门商品点击量是长尾商品的1000倍以上
- 解决方案:采用动态分区+局部聚合策略
- 模型迭代效率:
- 全量数据训练耗时超过8小时
- 优化方案:增量学习+模型并行训练
- AB测试评估:
- 如何设计无偏的在线评估框架
- 解决方案:基于时间片的流量切分策略
五、预期成果与进度安排
5.1 预期成果
- 构建支持日均处理10PB数据的推荐系统原型
- 在淘宝开放平台完成算法验证,CTR提升≥12%
- 发表核心期刊论文1-2篇,申请软件著作权1项
5.2 进度安排
| 阶段 | 时间节点 | 里程碑 |
|---|---|---|
| 需求分析 | 第1-2月 | 完成数据调研与架构设计评审 |
| 核心开发 | 第3-5月 | 实现流批处理管道与基础推荐算法 |
| 优化迭代 | 第6-7月 | 完成性能调优与AB测试 |
| 论文撰写 | 第8月 | 完成系统验收与论文投稿 |
六、参考文献
[1] 李航. 统计学习方法[M]. 清华大学出版社, 2012.
[2] Karau H, et al. Learning Spark[M]. O'Reilly Media, 2015.
[3] 阿里巴巴. 大数据之路: 阿里巴巴大数据实践[M]. 电子工业出版社, 2017.
[4] Zhou G, et al. Deep Interest Network for Click-Through Rate Prediction[C]. KDD 2018.
[5] Apache Kafka官方文档. Apache Kafka
备注:本开题报告可根据实际研究条件调整技术参数和实验方案,重点突出大数据技术栈在推荐系统中的创新应用。建议后续研究增加以下方向:
- 引入图神经网络处理用户-商品关系图
- 探索强化学习在动态推荐策略中的应用
- 研究推荐系统的可解释性技术
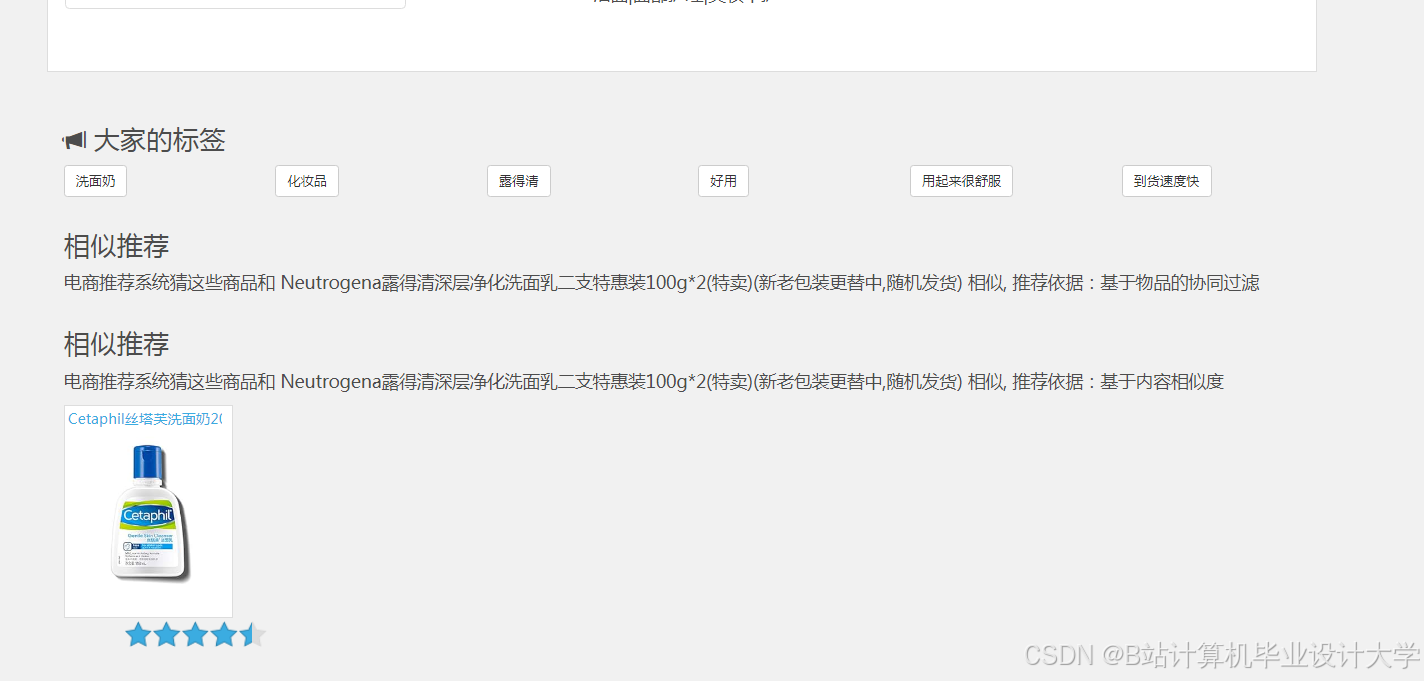
运行截图
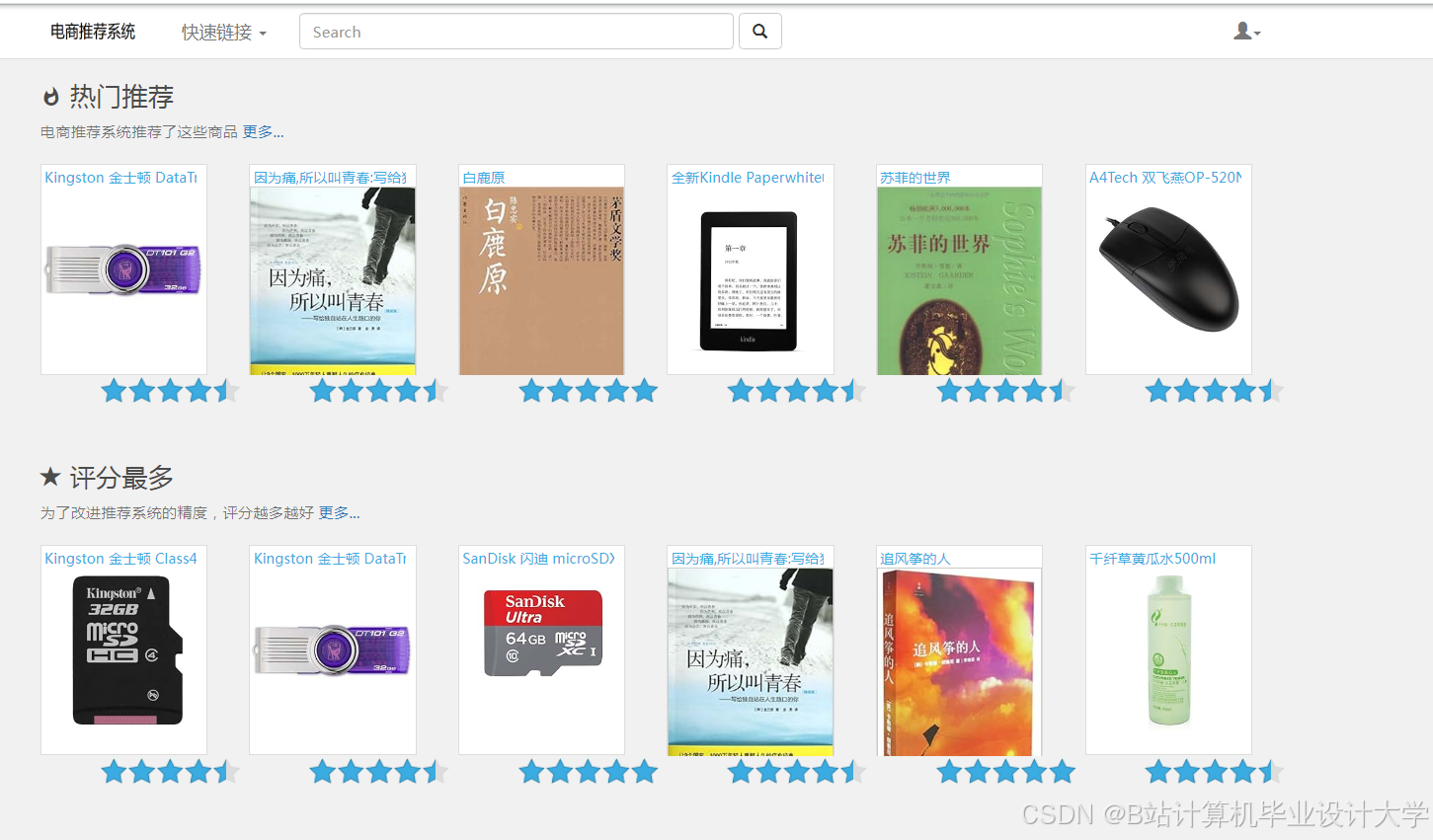

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











