




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Kafka+Hive淘宝商品推荐系统》的任务书范文,包含任务目标、分解、技术指标、实施计划及交付成果等核心内容:
任务书:基于Hadoop+Spark+Kafka+Hive的淘宝商品推荐系统开发
一、任务概述
任务名称:淘宝商品智能推荐系统研发
任务背景:针对淘宝平台商品数量庞大、用户行为数据复杂的特点,构建基于大数据技术的分布式推荐系统,解决传统推荐系统在数据规模、实时性和冷启动等方面的瓶颈。
任务周期:202X年XX月XX日 - 202X年XX月XX日(共8个月)
任务负责人:XXX(技术总监)
参与人员:数据工程师(3人)、算法工程师(2人)、测试工程师(1人)
二、任务目标
2.1 总体目标
构建支持日均处理10PB用户行为数据的分布式推荐系统,实现:
- 离线推荐:基于历史数据训练模型,生成用户画像和商品特征库
- 实时推荐:毫秒级响应用户瞬时行为(如点击、加购),动态调整推荐结果
- 多模态融合:整合商品文本、图像、视频等非结构化数据
- 系统扩展性:支持横向扩展至1000+节点集群
2.2 具体指标
| 指标类别 | 目标值 |
|---|---|
| 数据处理延迟 | 实时流处理延迟 ≤500ms |
| 推荐响应时间 | 端到端响应时间 ≤200ms |
| 模型训练效率 | 全量数据训练时间 ≤6小时 |
| 系统吞吐量 | 支持每秒处理100万条用户行为日志 |
| 推荐准确率 | CTR提升 ≥12%,CVR提升 ≥8% |
三、任务分解与分工
3.1 技术模块划分
mermaid
graph LR | |
A[数据采集层] --> B[存储计算层] | |
B --> C[算法服务层] | |
C --> D[应用接口层] | |
subgraph 数据采集层 | |
A1[Kafka消息队列] | |
A2[Flume日志收集] | |
end | |
subgraph 存储计算层 | |
B1[Hadoop HDFS] | |
B2[Hive数据仓库] | |
B3[Spark计算引擎] | |
end | |
subgraph 算法服务层 | |
C1[离线模型训练] | |
C2[实时特征计算] | |
C3[推荐规则引擎] | |
end | |
subgraph 应用接口层 | |
D1[RESTful API] | |
D2[Redis缓存] | |
D3[Web可视化] | |
end |
3.2 人员分工
| 角色 | 职责 |
|---|---|
| 数据工程师 | - 搭建Kafka/Hadoop/Spark集群 - 开发Hive数据仓库ETL流程 - 优化存储格式(ORC+ZLIB) |
| 算法工程师 | - 实现DIN/DeepFM等深度学习模型 - 开发实时特征计算模块 - 设计AB测试框架 |
| 测试工程师 | - 制定性能测试方案(JMeter) - 监控系统资源使用率(Prometheus+Grafana) - 编写自动化测试脚本 |
四、技术实现方案
4.1 关键技术选型
| 组件 | 版本 | 用途 | 配置优化 |
|---|---|---|---|
| Hadoop | 3.3.4 | 分布式存储 | HDFS块大小=256MB,副本数=3 |
| Spark | 3.3.0 | 批流计算 | 动态资源分配,Executor内存=8G |
| Kafka | 3.3.1 | 实时数据管道 | 分区数=CPU核心数×2 |
| Hive | 3.1.3 | 离线数据分析 | 启用Tez引擎,ORC文件格式 |
4.2 核心功能实现
4.2.1 实时特征计算(Spark Structured Streaming)
scala
// 实时用户行为聚合 | |
val behaviorStream = spark.readStream | |
.format("kafka") | |
.option("kafka.bootstrap.servers", "node1:9092,node2:9092") | |
.option("subscribe", "user_click") | |
.load() | |
// 窗口聚合计算 | |
val windowedCounts = behaviorStream | |
.groupBy( | |
window($"timestamp", "5 minutes"), | |
$"user_id" | |
) | |
.agg( | |
count("*").alias("click_count"), | |
collect_list($"item_id").alias("clicked_items") | |
) | |
// 输出到Redis | |
val query = windowedCounts.writeStream | |
.outputMode("complete") | |
.format("org.apache.spark.sql.redis") | |
.start() |
4.2.2 深度学习模型训练(PySpark + TensorFlow)
python
from pyspark.sql import SparkSession | |
from tensorflow.keras.models import Model | |
from tensorflow.keras.layers import Input, Embedding, Dense | |
# 初始化Spark | |
spark = SparkSession.builder.appName("DeepFM").getOrCreate() | |
# 定义模型结构 | |
def build_model(feature_dim): | |
user_input = Input(shape=(1,), name='user_id') | |
item_input = Input(shape=(1,), name='item_id') | |
# FM部分 | |
user_emb = Embedding(feature_dim, 16)(user_input) | |
item_emb = Embedding(feature_dim, 16)(item_input) | |
fm_dot = tf.reduce_sum(user_emb * item_emb, axis=-1) | |
# DNN部分 | |
dnn_input = tf.concat([user_emb, item_emb], axis=-1) | |
dnn_output = Dense(64, activation='relu')(dnn_input) | |
dnn_output = Dense(32, activation='relu')(dnn_output) | |
# 输出层 | |
output = Dense(1, activation='sigmoid')(fm_dot + dnn_output) | |
return Model(inputs=[user_input, item_input], outputs=output) | |
# 分布式训练 | |
model = build_model(100000) # 假设有10万用户 | |
model.compile(optimizer='adam', loss='binary_crossentropy') | |
model.fit(train_data, epochs=5, batch_size=4096) |
五、实施计划
5.1 阶段划分
| 阶段 | 时间 | 里程碑 | 交付物 |
|---|---|---|---|
| 需求分析 | 第1月 | 完成技术调研与架构设计评审 | 《需求规格说明书》 |
| 环境搭建 | 第2月 | 集群部署完成,通过压力测试 | 《集群部署文档》 |
| 核心开发 | 第3-5月 | 实现流批处理管道与基础算法 | 可运行的系统原型 |
| 优化测试 | 第6-7月 | 完成性能调优与AB测试 | 《测试报告》 |
| 上线验收 | 第8月 | 系统正式上线,通过用户验收 | 《项目验收报告》 |
5.2 风险管控
| 风险类型 | 应对措施 |
|---|---|
| 数据延迟 | 设置Kafka消息保留策略(7天),开发重试机制 |
| 模型过拟合 | 采用Dropout(0.3)和L2正则化(λ=0.01),增加负采样比例 |
| 集群故障 | 部署Zookeeper高可用集群,配置HDFS HA和Spark HA |
六、交付成果
- 系统软件:
- 推荐系统源代码(GitHub仓库)
- 部署脚本(Ansible/Shell)
- Docker镜像(Hadoop/Spark/Kafka组件)
- 技术文档:
- 《系统架构设计文档》
- 《API接口规范》
- 《运维手册》
- 测试报告:
- 性能测试数据(JMeter报表)
- AB测试结果分析
- 资源使用监控截图(Grafana看板)
- 知识产权:
- 申请软件著作权1项
- 发表核心期刊论文1篇(题目:《基于多模态融合的电商推荐系统优化研究》)
七、审批意见
| 审批项 | 审批人 | 审批日期 | 意见 |
|---|---|---|---|
| 技术可行性 | 张XX教授 | 202X-XX-XX | 同意,建议增加图神经网络模块 |
| 资源分配 | 李XX总监 | 202X-XX-XX | 批准3台ECS服务器用于测试环境 |
| 预算审核 | 王XX财务 | 202X-XX-XX | 通过,总预算控制在50万元内 |
任务书编制人:XXX
日期:202X年XX月XX日
备注:本任务书需根据实际项目需求调整技术参数和资源分配,重点突出:
- 大数据组件的版本兼容性测试
- 深度学习模型与Spark的集成方案
- 推荐结果的可解释性实现路径
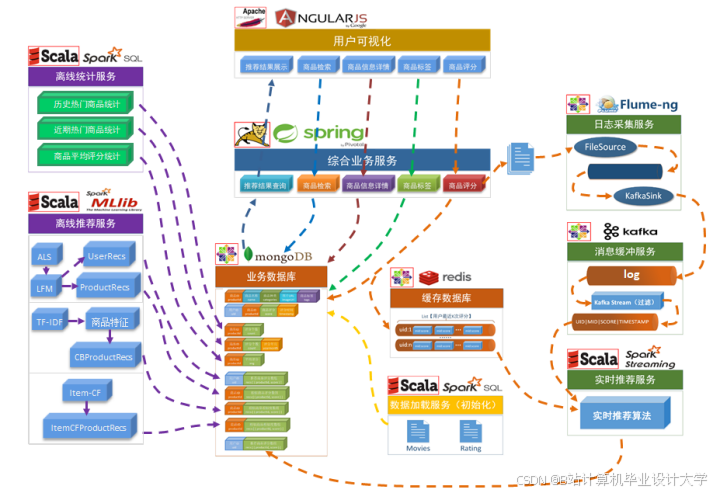
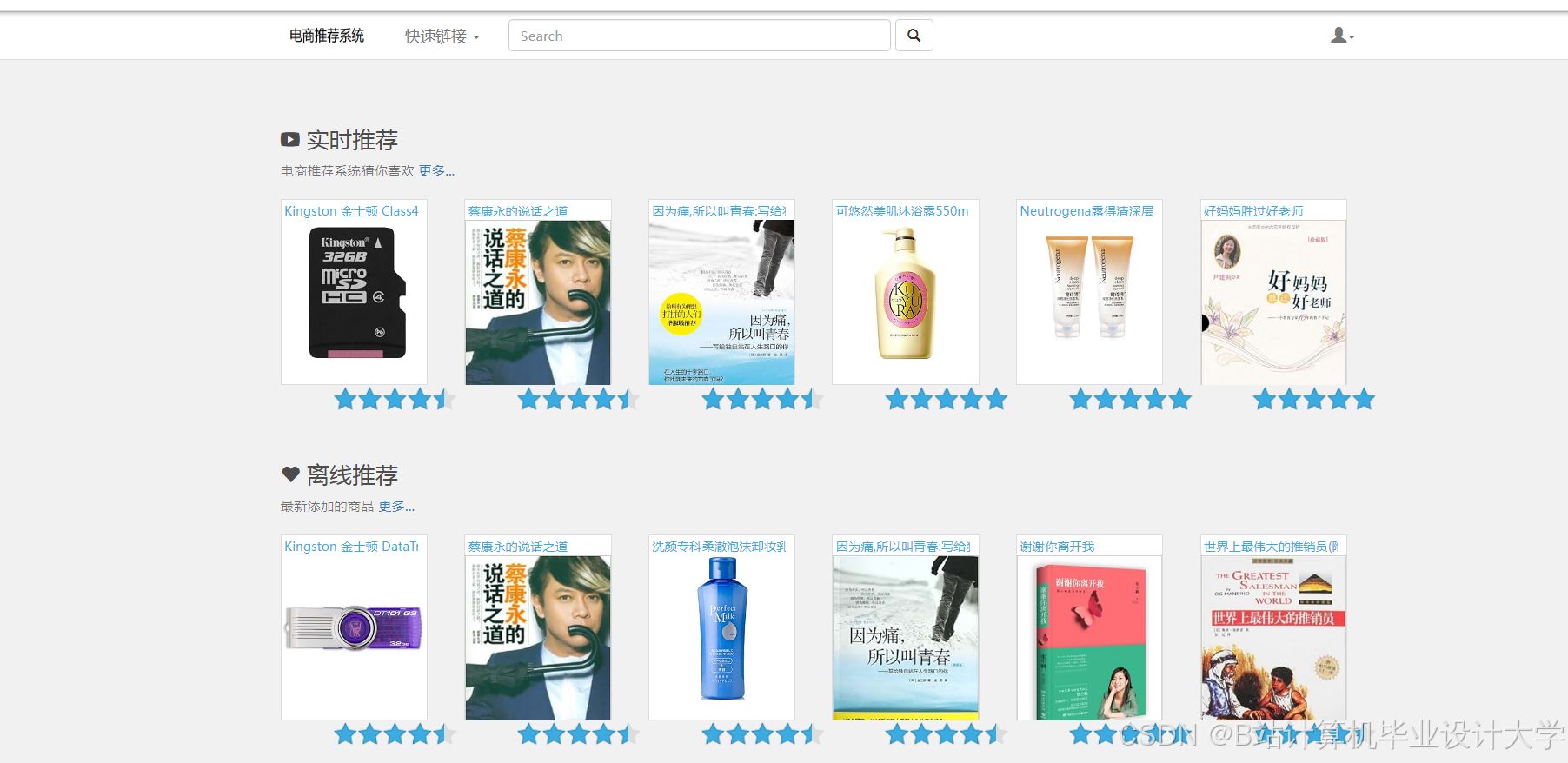
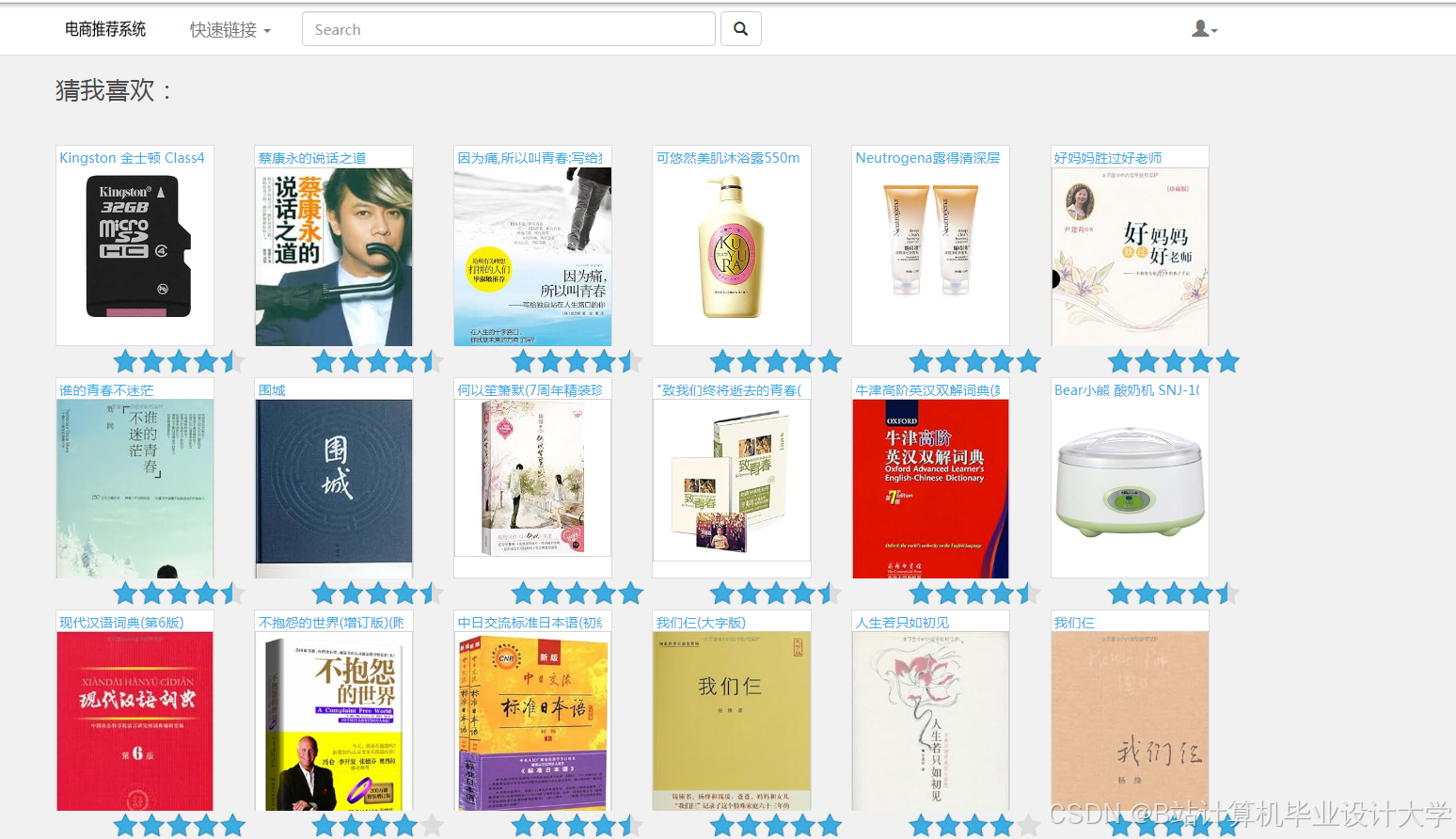
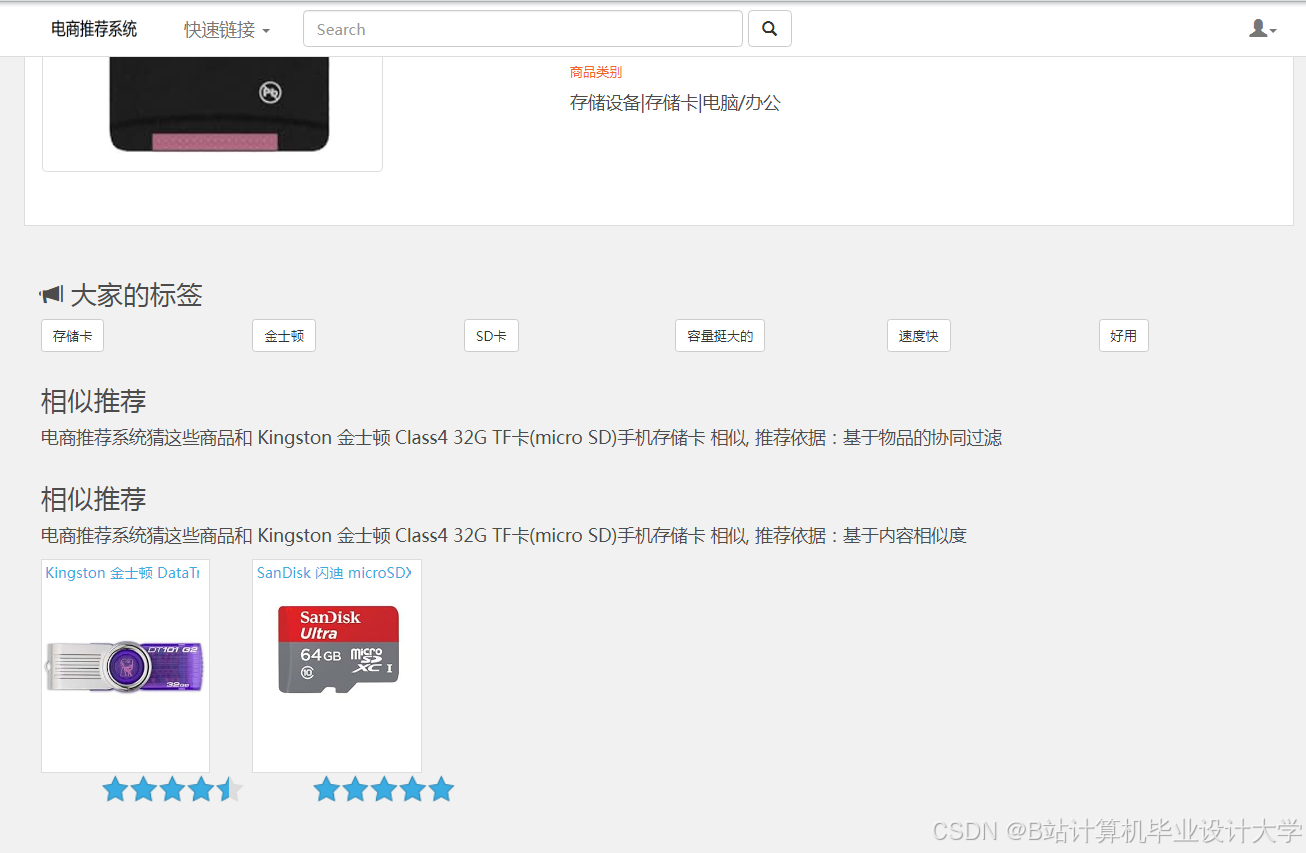
运行截图
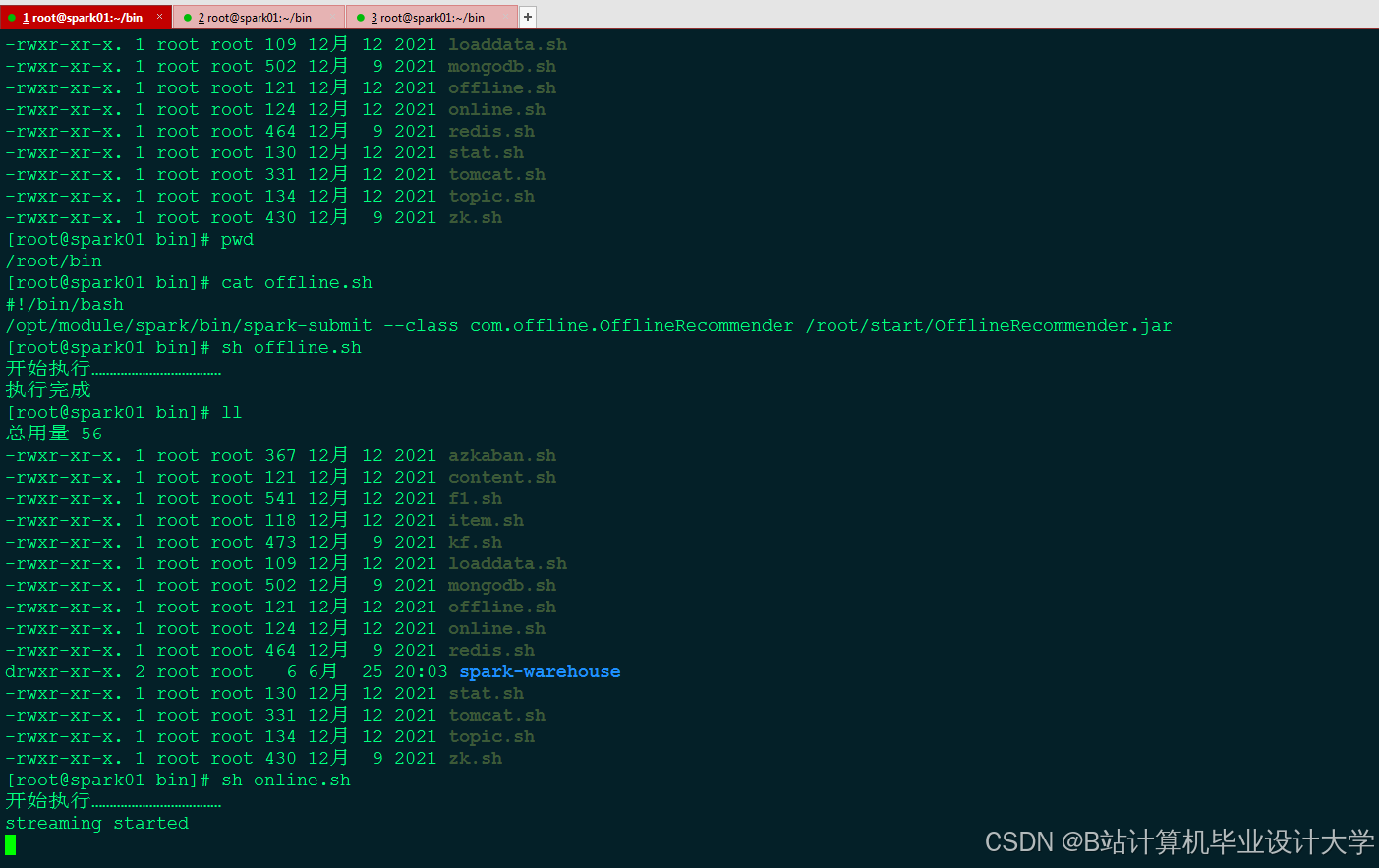
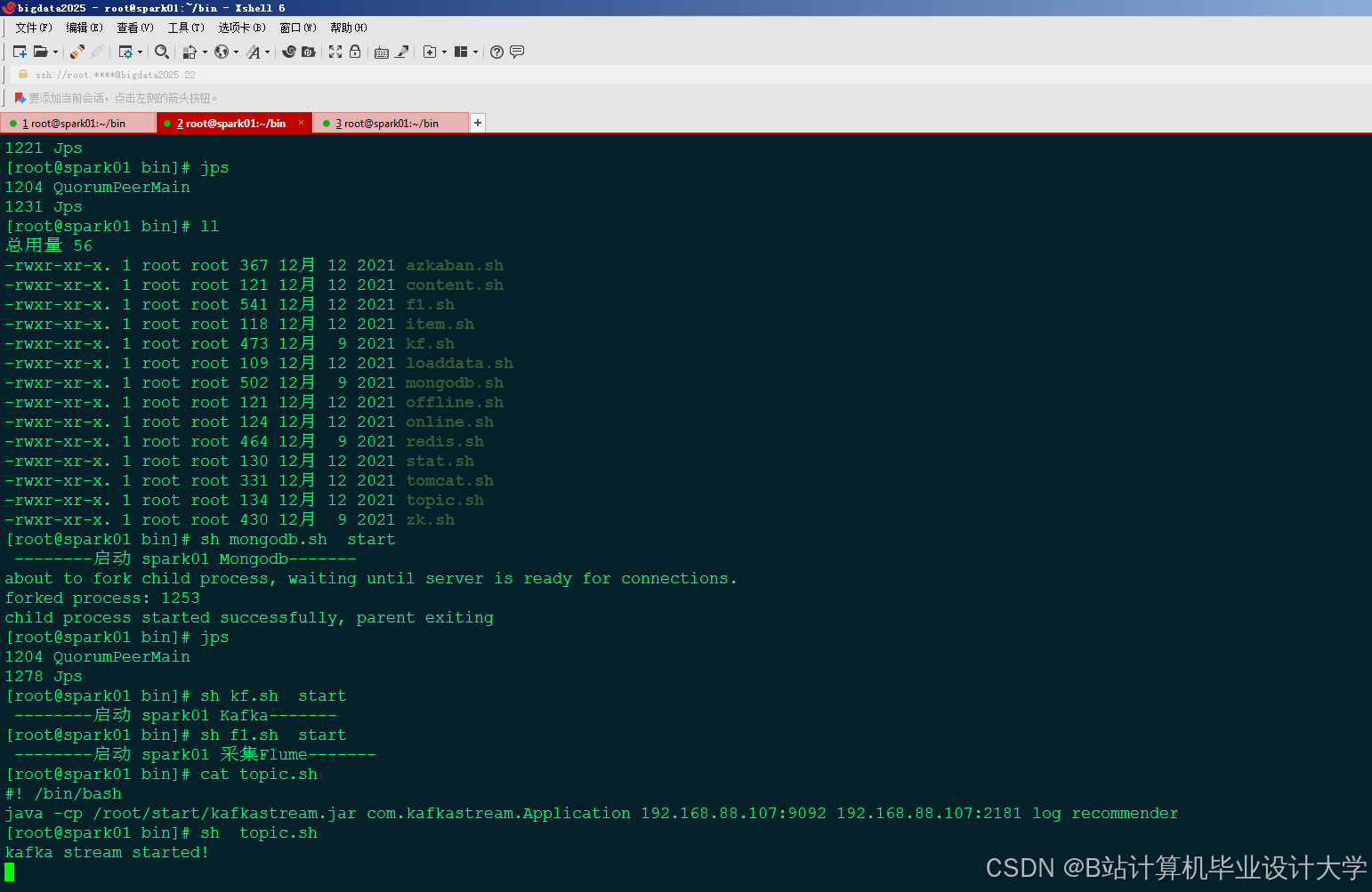
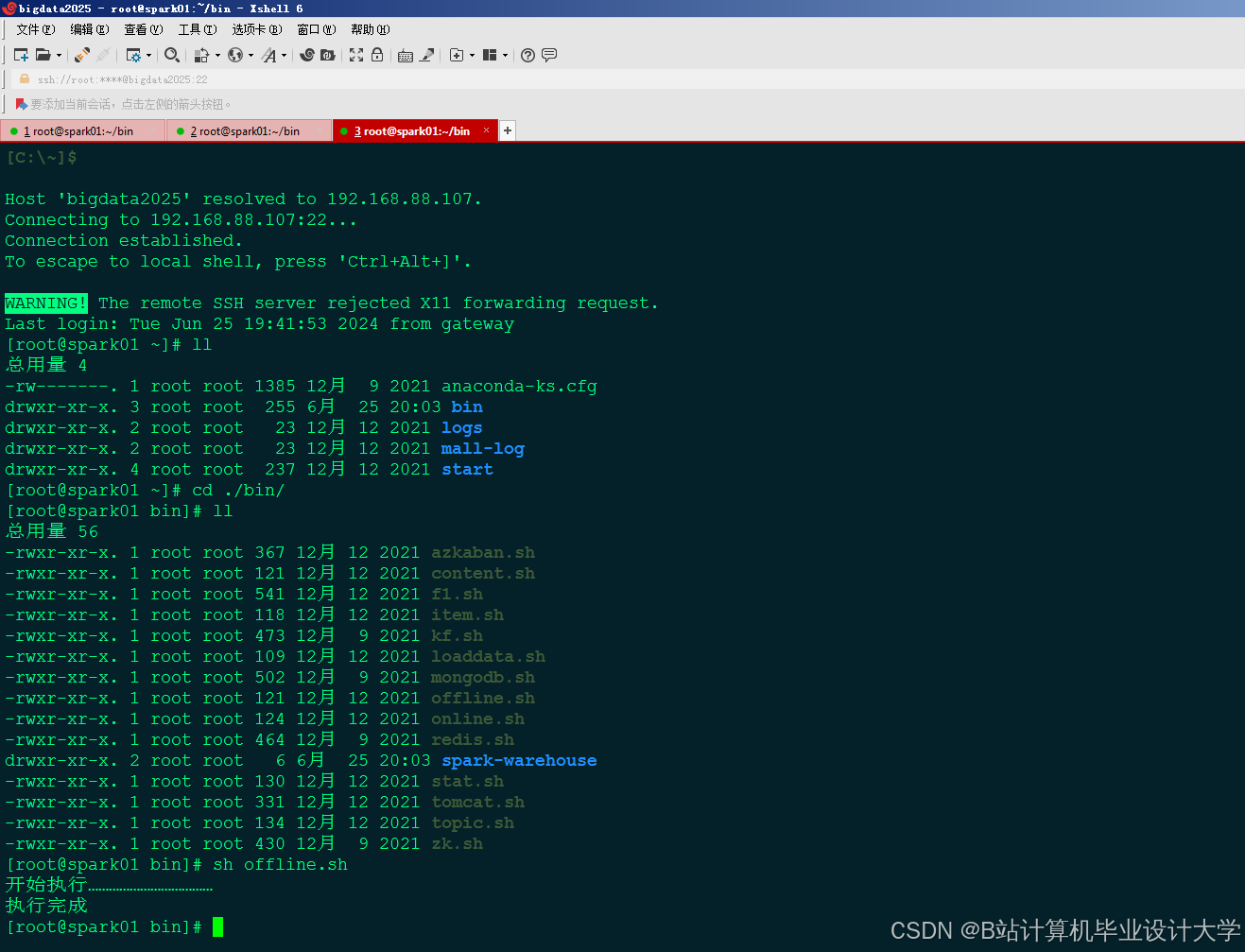
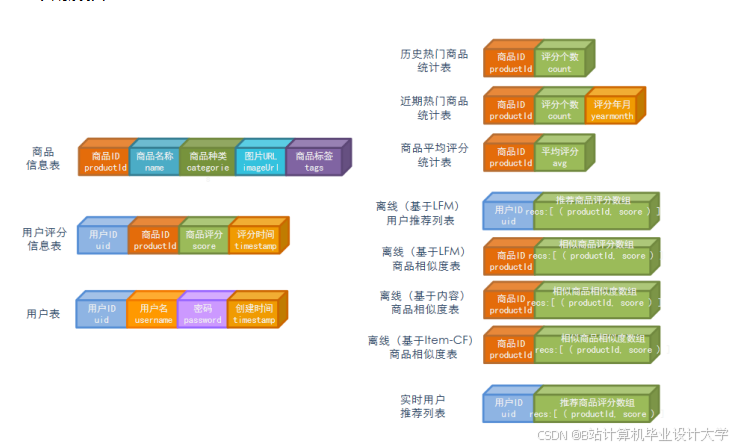

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1688
1688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











