




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
任务书:基于Hadoop+PySpark+Scrapy爬虫的视频推荐系统开发
一、项目背景与目标
1.1 项目背景
随着互联网视频内容的爆发式增长(如抖音、B站日均上传视频超千万条),用户面临“信息过载”问题,传统推荐系统依赖单一平台内部数据,存在以下缺陷:
- 数据维度单一:仅利用用户观看历史、点赞等行为数据,忽略外部热点事件、社交媒体讨论等动态信息。
- 冷启动问题严重:新用户或新视频缺乏历史行为数据,推荐质量显著下降。
- 实时性不足:静态模型无法捕捉用户兴趣突变(如突发热点事件相关视频需求激增)。
1.2 项目目标
开发一个基于多源数据融合的实时视频推荐系统,通过整合以下技术解决上述问题:
- Scrapy爬虫:从豆瓣电影、微博热搜、知乎话题等多平台抓取视频相关数据(评分、评论、热度趋势)。
- Hadoop+PySpark:利用分布式存储与计算能力处理海量数据(PB级),支持实时特征工程与模型训练。
- 混合推荐算法:结合协同过滤(捕捉用户群体行为)与内容推荐(利用爬取的文本/图像特征),提升推荐多样性与冷启动性能。
预期成果:
- 系统支持10万级用户与百万级视频的实时推荐,推荐准确率(Precision@10)较传统方法提升10%-15%。
- 冷启动场景下(如新用户/新视频),推荐覆盖率提升至80%以上。
- 系统响应时间≤500ms(90%请求),支持横向扩展以应对数据量增长。
二、项目范围与功能模块
2.1 项目范围
- 数据源:豆瓣电影、微博热搜、B站弹幕、YouTube公开数据集(如MovieLens)。
- 技术栈:
- 爬虫层:Scrapy + Scrapy-Redis + Splash(动态页面渲染)。
- 存储层:Hadoop HDFS(原始数据) + Hive(结构化数据查询)。
- 计算层:PySpark(离线处理) + PySpark Streaming(实时特征更新)。
- 推荐层:Flask API(推荐服务) + Redis(缓存热门结果)。
- 用户群体:视频平台运营方、终端用户(需登录测试账号验证推荐效果)。
2.2 功能模块
| 模块 | 功能描述 |
|---|---|
| 多源数据爬取 | 定时爬取豆瓣评分、微博热搜、B站弹幕等数据,支持动态页面渲染与反爬策略。 |
| 数据存储与管理 | 原始数据存储至HDFS,结构化数据导入Hive表,支持按日期/数据源分区查询。 |
| 分布式数据处理 | 使用PySpark清洗数据(去重、填充缺失值)、提取特征(用户画像、视频标签)。 |
| 混合推荐模型 | 结合协同过滤(UserCF/ItemCF)与内容推荐(Word2Vec文本相似度),加权融合结果。 |
| 实时推荐服务 | 通过Flask API接收用户请求,调用PySpark模型生成推荐列表,缓存至Redis。 |
| 系统监控与日志 | 记录爬虫运行状态、模型训练耗时、推荐响应时间等指标,支持异常报警。 |
三、技术方案与实施计划
3.1 技术方案
3.1.1 多源数据爬取
- 爬虫设计:
- 使用Scrapy框架实现分布式爬虫,通过Scrapy-Redis管理请求队列与去重。
- 针对动态页面(如B站弹幕、微博热搜),集成Splash模拟浏览器行为。
- 反爬策略:代理IP池(如Bright Data)、随机User-Agent、请求间隔随机化(2-5秒)。
- 数据示例:
json{"video_id": "12345","title": "AI生成视频技术解析","platform": "B站","views": 100000,"comments": [{"user": "张三", "content": "讲解很清晰!", "sentiment": "positive"},{"user": "李四", "content": "代码能开源吗?", "sentiment": "neutral"}],"weibo_hot_score": 85 // 微博热搜关联度评分}
3.1.2 分布式数据处理
- 数据清洗:
- 使用PySpark过滤无效数据(如评分为0的记录、重复评论)。
- 填充缺失值:用户年龄缺失时填充同地区均值,视频标签缺失时通过NLP提取关键词(如使用TextBlob进行情感分析)。
- 特征提取:
- 用户特征:年龄、性别、地域、历史观看品类偏好(如科技、娱乐)。
- 视频特征:时长、类别、评分、评论情感极性(positive/negative/neutral)。
- 实时特征:用户最近1小时的点击序列、当前热点事件关联度(通过爬取的微博热搜计算TF-IDF)。
3.1.3 混合推荐模型
- 协同过滤模块:
- 基于用户的协同过滤(UserCF):计算用户相似度(余弦相似度),推荐相似用户观看过的视频。
- 基于物品的协同过滤(ItemCF):计算视频相似度(Jaccard相似度),推荐与用户历史观看视频相似的内容。
- 内容推荐模块:
- 使用Word2Vec将视频标题/描述转换为向量,计算与用户兴趣向量的余弦相似度。
- 结合爬取的评分数据,对高评分视频赋予更高权重(如评分≥4.5的视频权重+20%)。
- 模型融合:
- 加权融合:协同过滤(60%)+ 内容推荐(40%),权重通过网格搜索优化。
- 冷启动处理:新用户默认推荐热点视频(根据微博热搜排序),新视频通过内容相似度推荐给潜在用户。
3.1.4 实时推荐服务
- API设计:
python# Flask API示例@app.route('/recommend', methods=['POST'])def recommend():user_id = request.json['user_id']# 从Redis获取用户实时特征user_features = redis.get(f"user:{user_id}")# 调用PySpark模型生成推荐列表recommendations = spark_model.predict(user_features)return jsonify({"recommendations": recommendations[:10]}) - 缓存策略:
- 对热门视频的推荐结果缓存至Redis(TTL=10分钟),减少重复计算。
- 使用LRU(最近最少使用)算法淘汰冷门数据。
3.2 实施计划
| 阶段 | 时间 | 任务 | 交付物 |
|---|---|---|---|
| 需求分析 | 第1周 | 调研视频平台需求,明确数据源、功能模块与技术指标。 | 需求规格说明书 |
| 系统设计 | 第2-3周 | 完成系统架构设计、数据库设计、API接口定义。 | 系统设计文档、UML图 |
| 数据爬取 | 第4-5周 | 实现Scrapy爬虫,爬取豆瓣、微博等数据,存储至HDFS。 | 爬虫代码、样例数据集 |
| 数据处理 | 第6-7周 | 使用PySpark清洗数据并提取特征,生成训练集。 | 特征工程代码、清洗后数据集 |
| 模型训练 | 第8-9周 | 训练混合推荐模型,在MovieLens数据集上验证效果。 | 模型代码、评估报告(Precision@K) |
| 系统实现 | 第10-11周 | 开发Flask推荐服务,集成Redis缓存,完成前后端联调。 | 系统原型、测试账号 |
| 测试优化 | 第12周 | 部署系统至测试环境,收集用户反馈,优化推荐算法与爬虫策略。 | 测试报告、优化方案 |
| 验收交付 | 第13周 | 提交最终代码、文档,进行项目验收。 | 完整系统、用户手册、技术文档 |
四、资源需求与风险管理
4.1 资源需求
- 硬件资源:
- 爬虫集群:3台云服务器(4核8G,用于分布式爬取)。
- Hadoop集群:5台云服务器(8核16G,用于存储与计算)。
- 推荐服务:1台云服务器(4核8G,部署Flask API与Redis)。
- 软件资源:
- 操作系统:Ubuntu 20.04。
- 开发工具:PyCharm、Postman(API测试)、Jupyter Notebook(模型调试)。
- 依赖库:Scrapy 2.11、PySpark 3.5、Flask 2.3、Redis 7.0。
4.2 风险管理
| 风险类型 | 描述 | 应对措施 |
|---|---|---|
| 数据质量风险 | 爬取数据存在噪声(如虚假评论、刷分行为),影响推荐效果。 | 引入数据清洗规则(如过滤评分异常值)、人工抽检。 |
| 反爬风险 | 目标网站更新反爬策略(如验证码、IP封禁),导致爬虫失效。 | 定期更新代理IP池、集成验证码识别服务(如2Captcha)。 |
| 性能风险 | 系统响应时间超标(如推荐耗时>1秒),影响用户体验。 | 优化模型复杂度(如减少特征维度)、增加缓存命中率。 |
| 法律风险 | 爬取数据涉及版权或隐私(如用户评论中的个人信息)。 | 仅爬取公开数据、匿名化处理用户信息、遵守Robots协议。 |
五、验收标准与交付成果
5.1 验收标准
- 功能完整性:系统实现需求规格说明书中的所有功能模块(如爬虫、推荐、缓存)。
- 性能指标:
- 推荐响应时间≤500ms(90%请求)。
- 系统支持10万级用户与百万级视频的实时推荐。
- 准确率要求:
- Precision@10(前10个推荐中用户实际点击的比例)≥0.35。
- 冷启动场景下推荐覆盖率≥80%。
5.2 交付成果
- 系统原型:可运行的视频推荐系统,包含爬虫、数据处理、推荐服务与监控模块。
- 技术文档:
- 系统设计文档(架构图、数据库设计、API接口)。
- 用户手册(系统部署、操作指南、测试账号)。
- 开发文档(代码注释、依赖库说明、环境配置)。
- 实验报告:在MovieLens数据集上对比不同推荐算法的准确率、召回率与F1值。
任务书签署:
项目负责人:__________________
日期:__________________
(注:实际任务书需根据项目规模与团队分工调整细节)
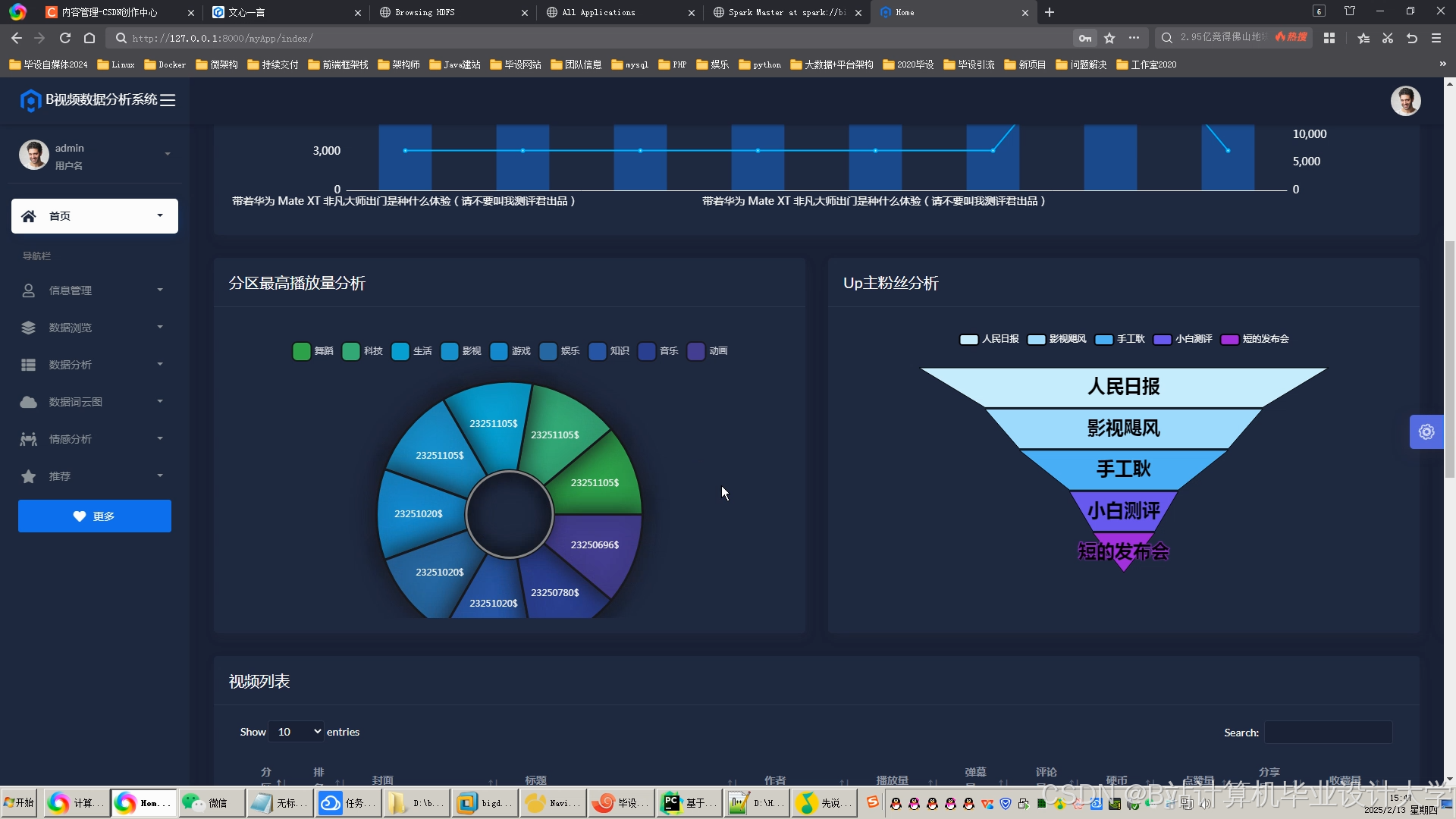
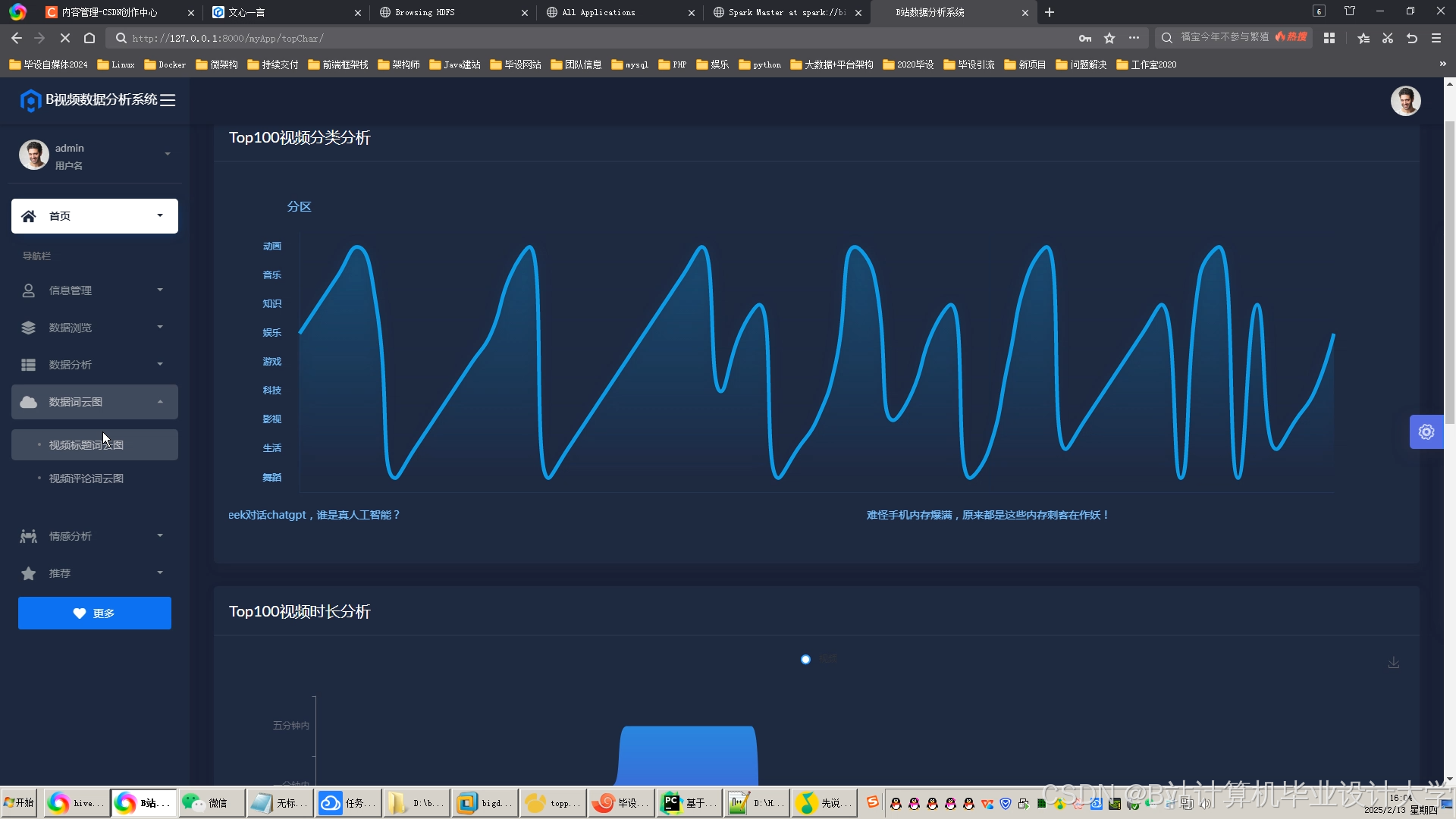
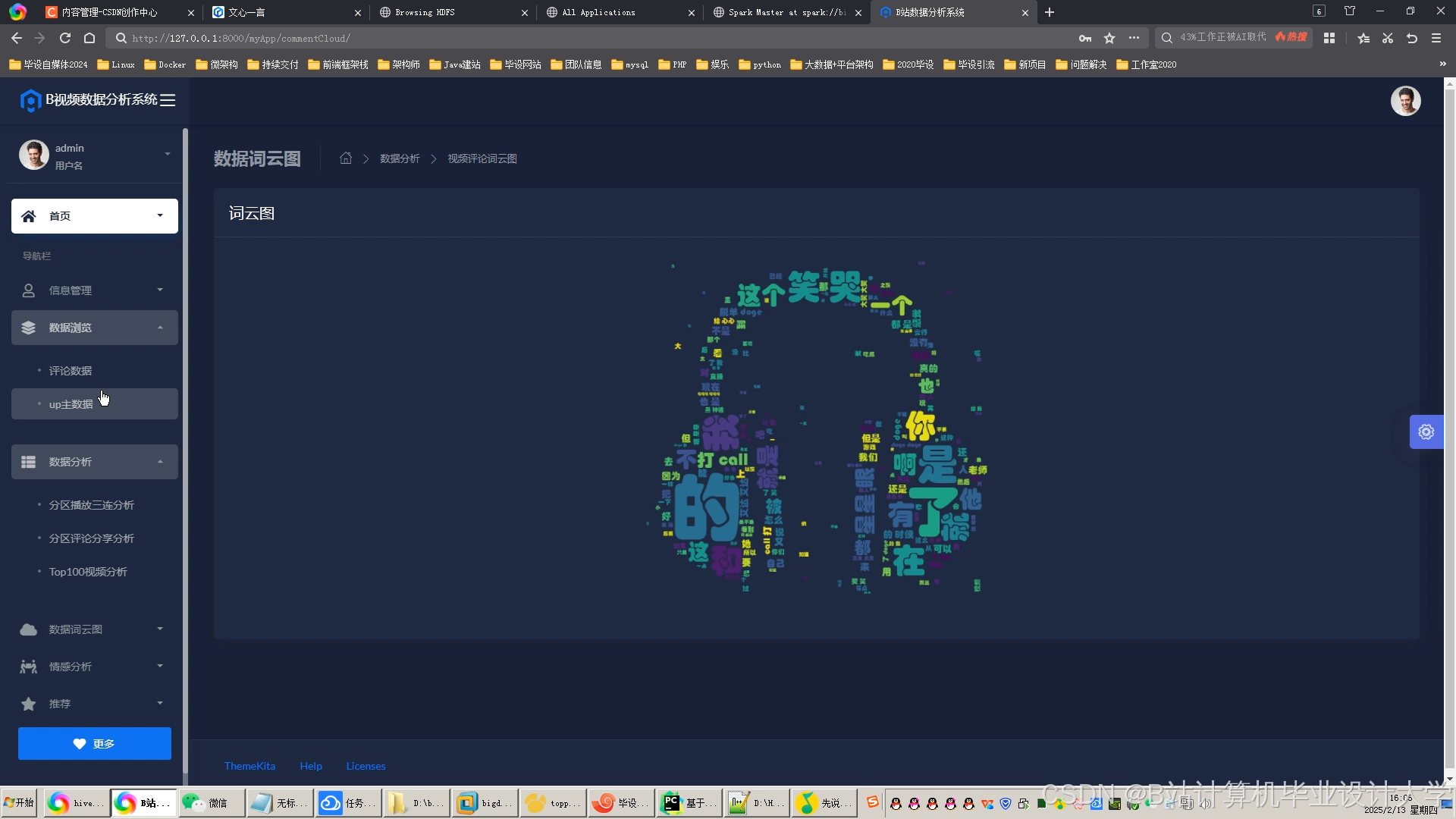
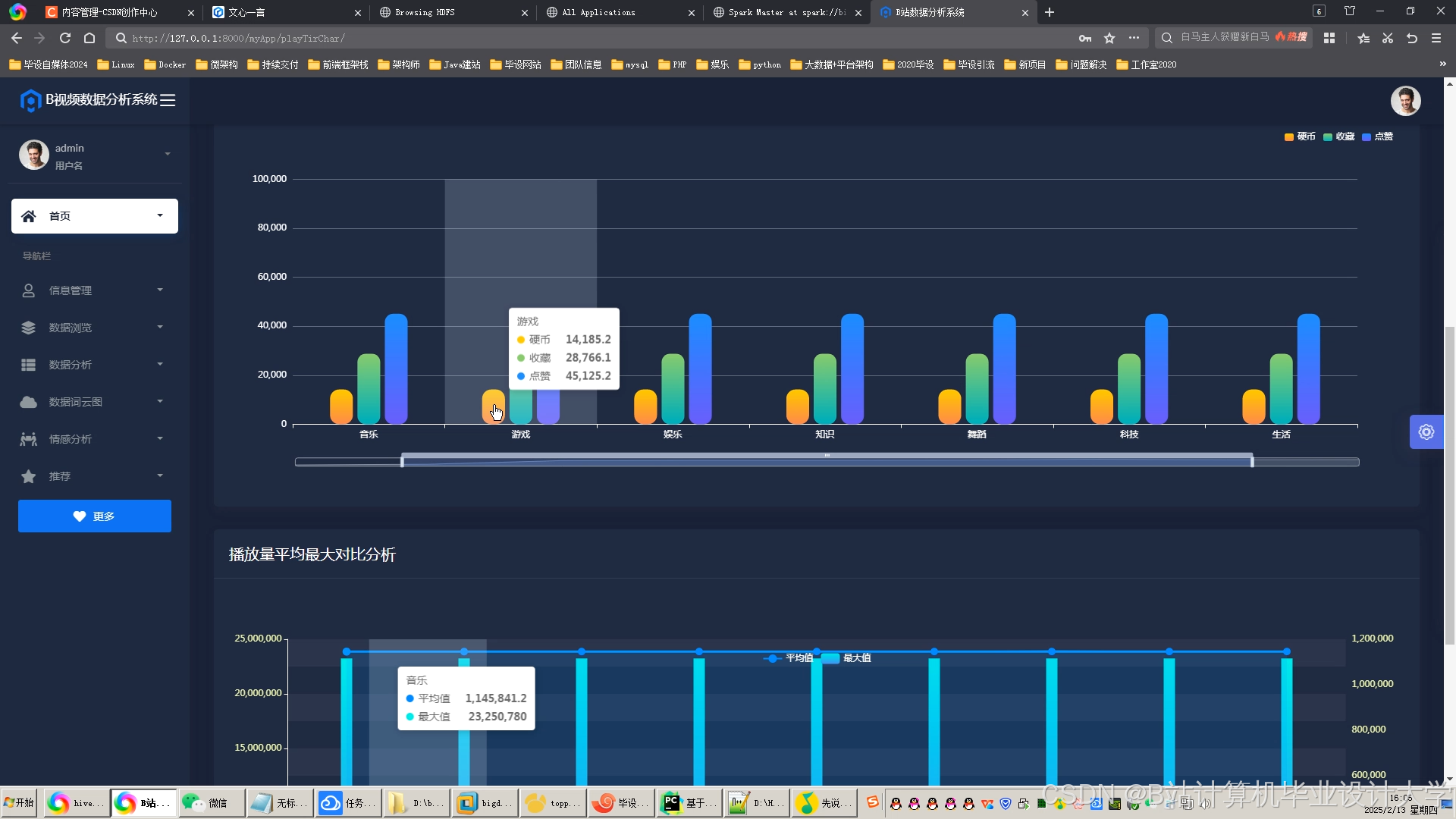
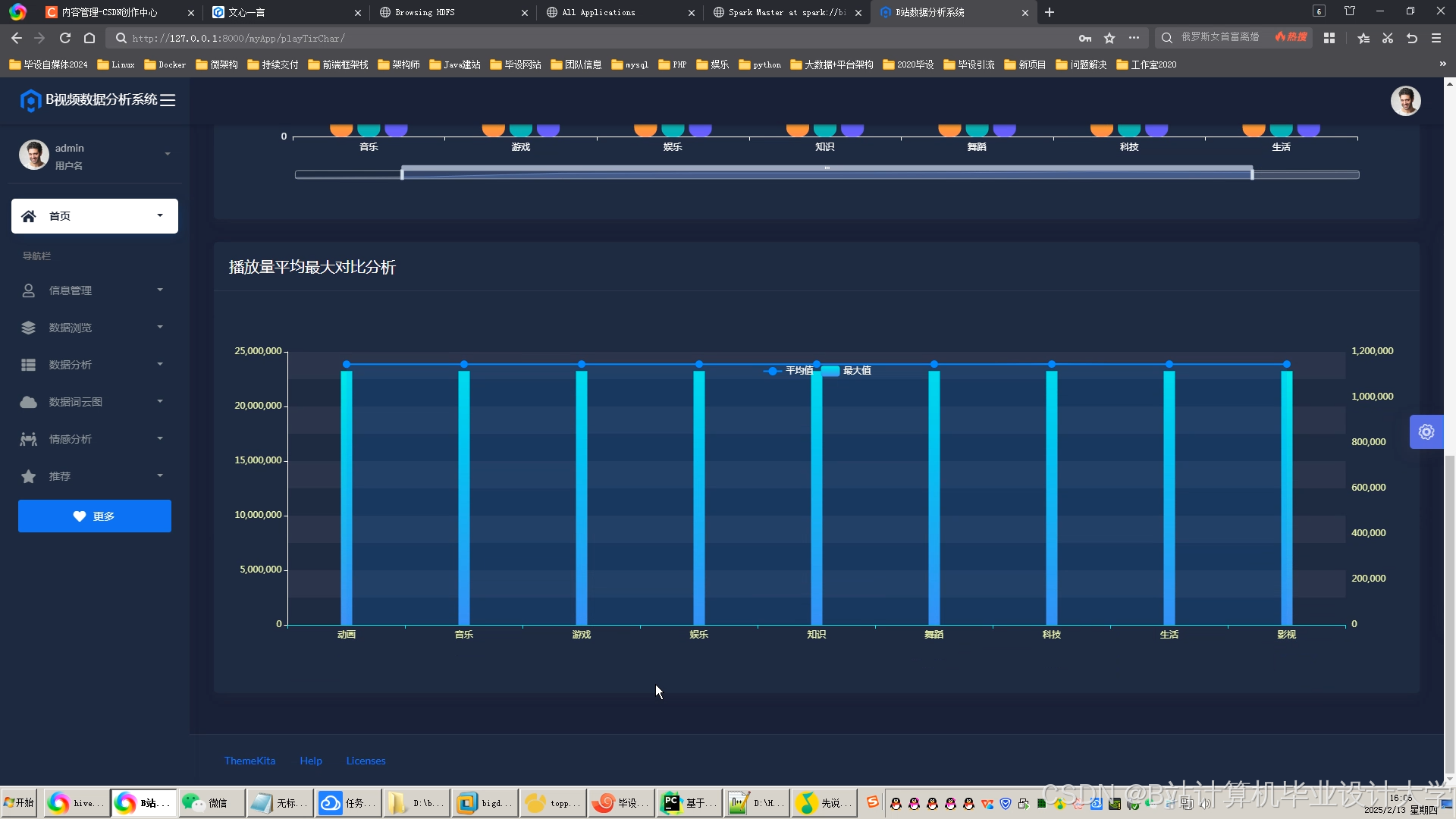
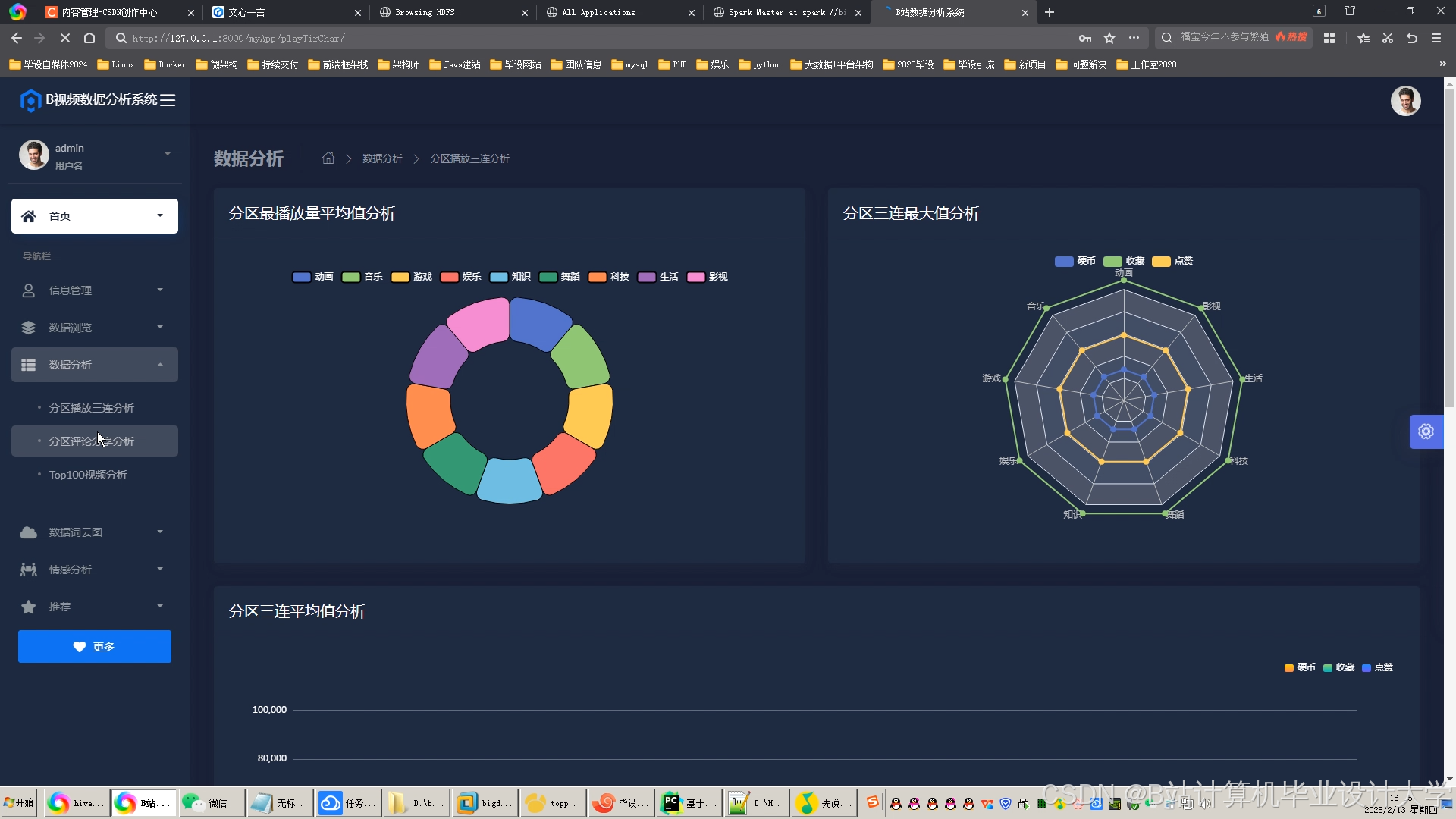
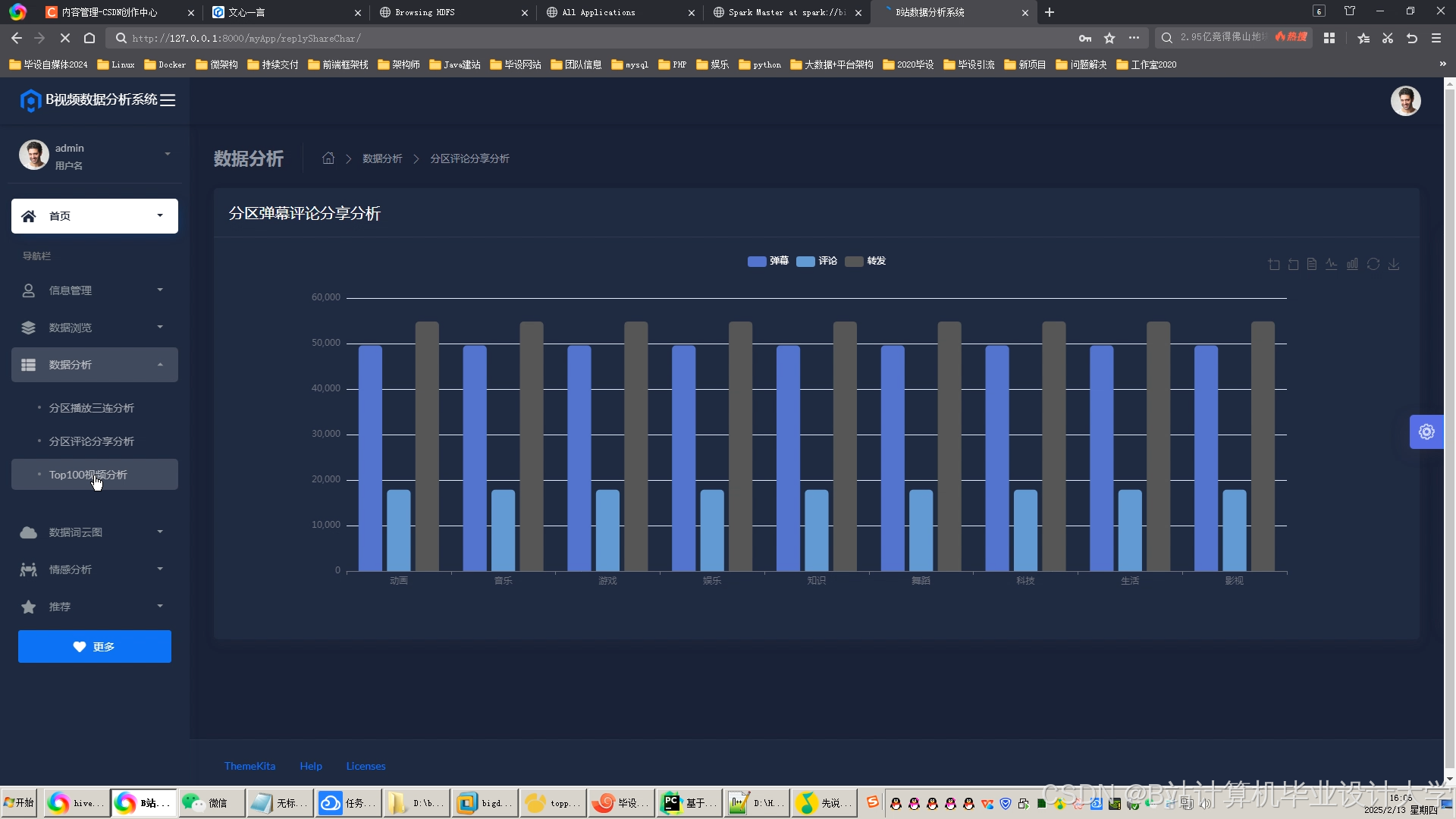
运行截图
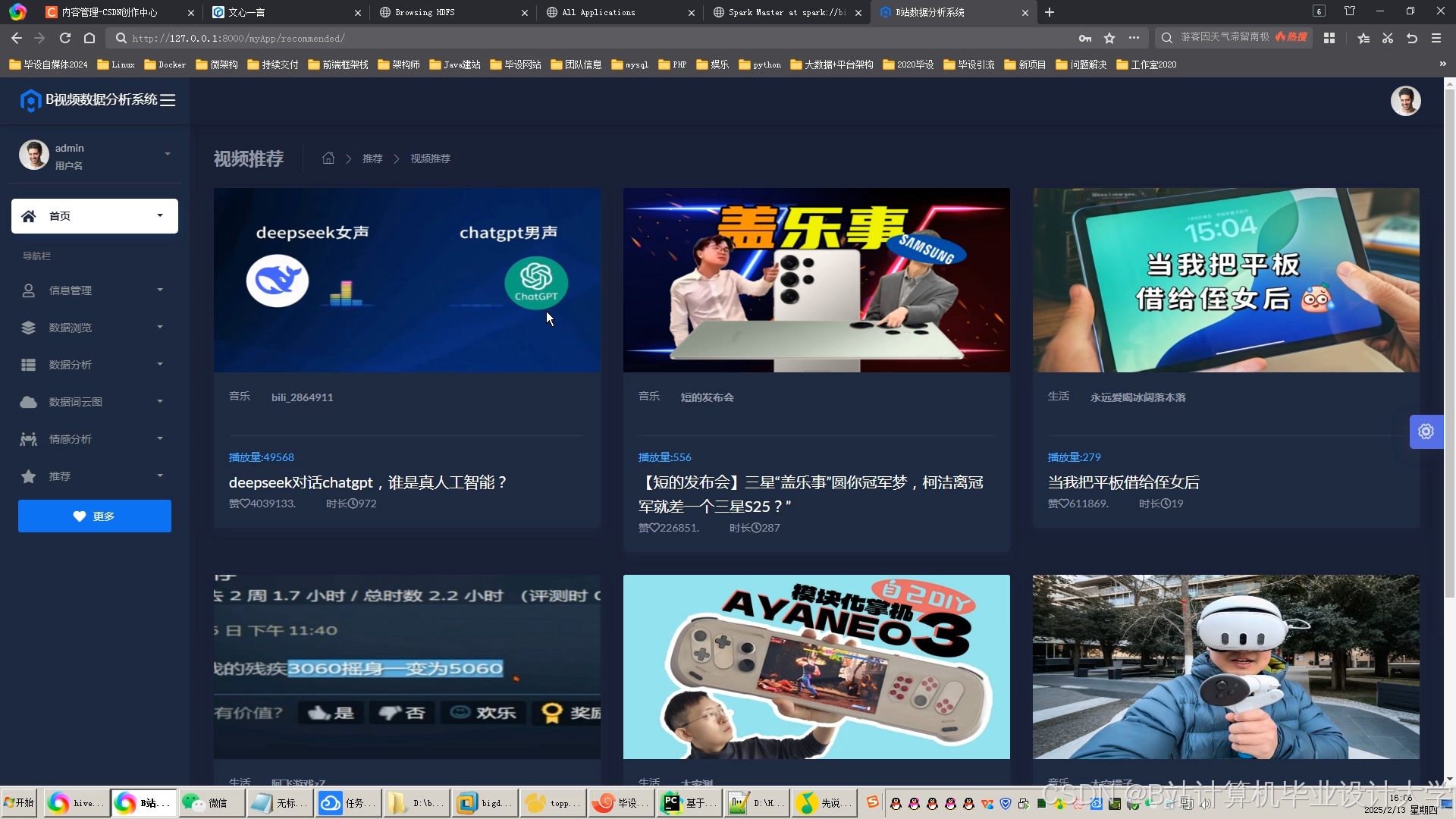
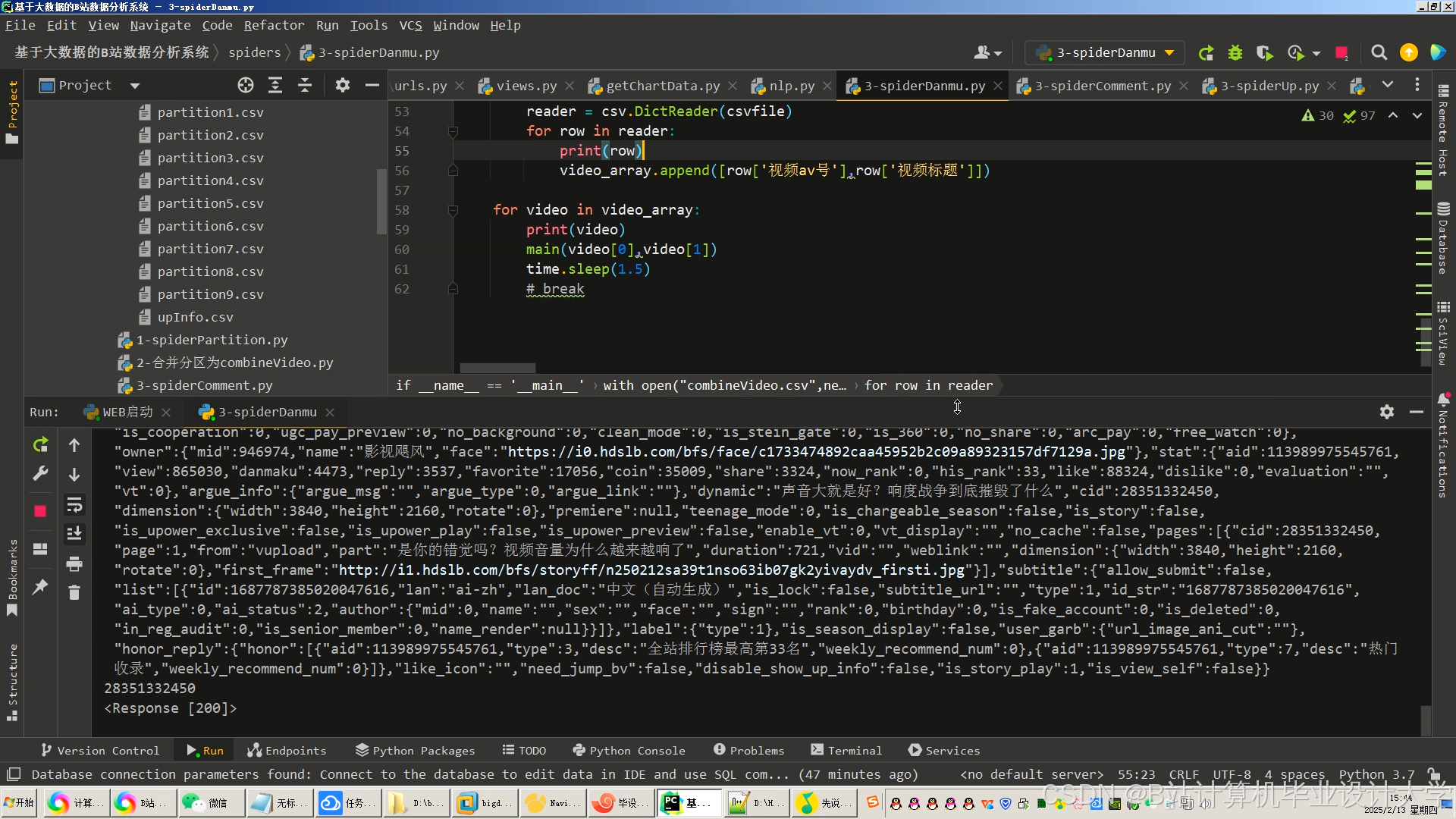
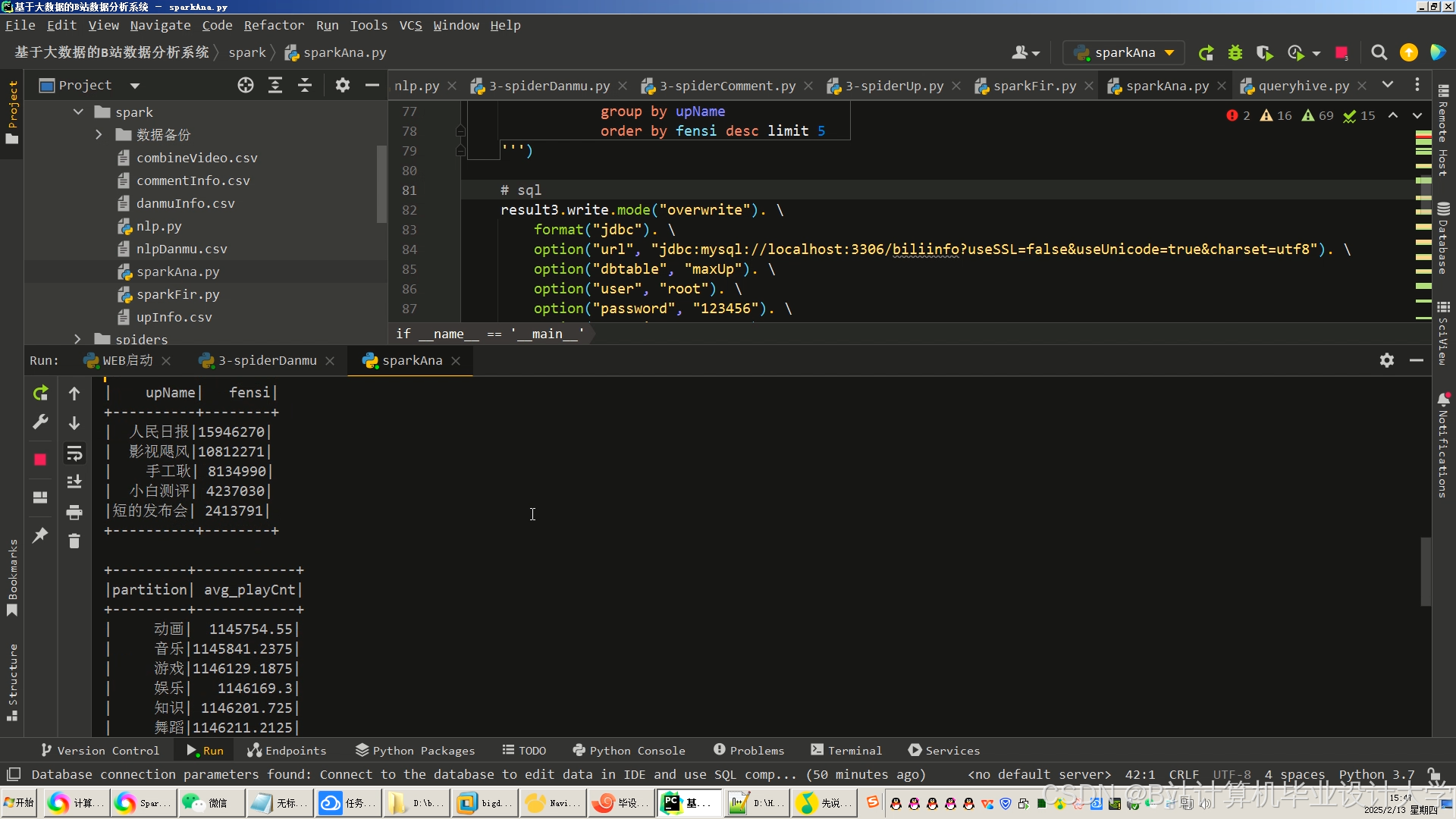
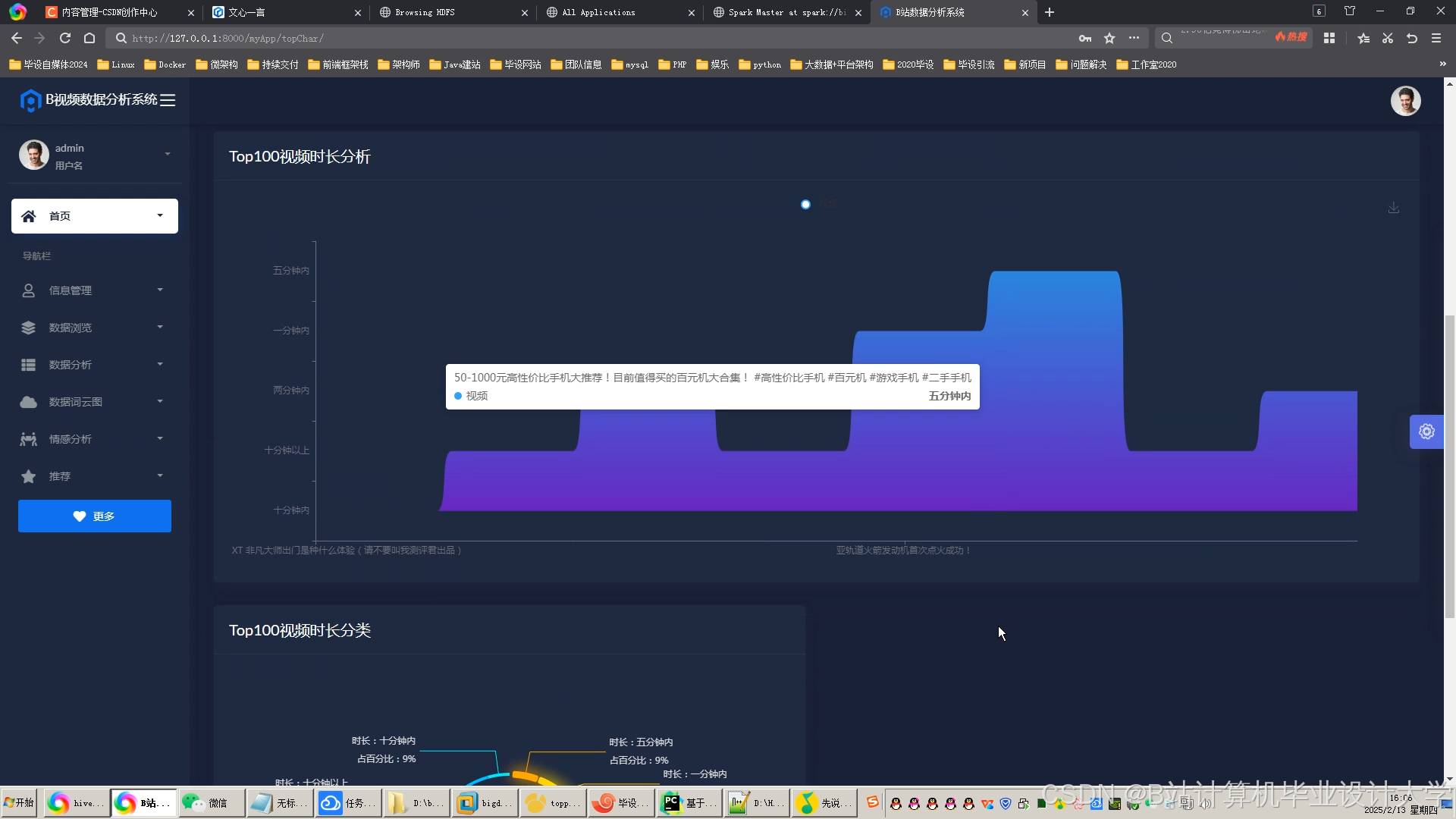
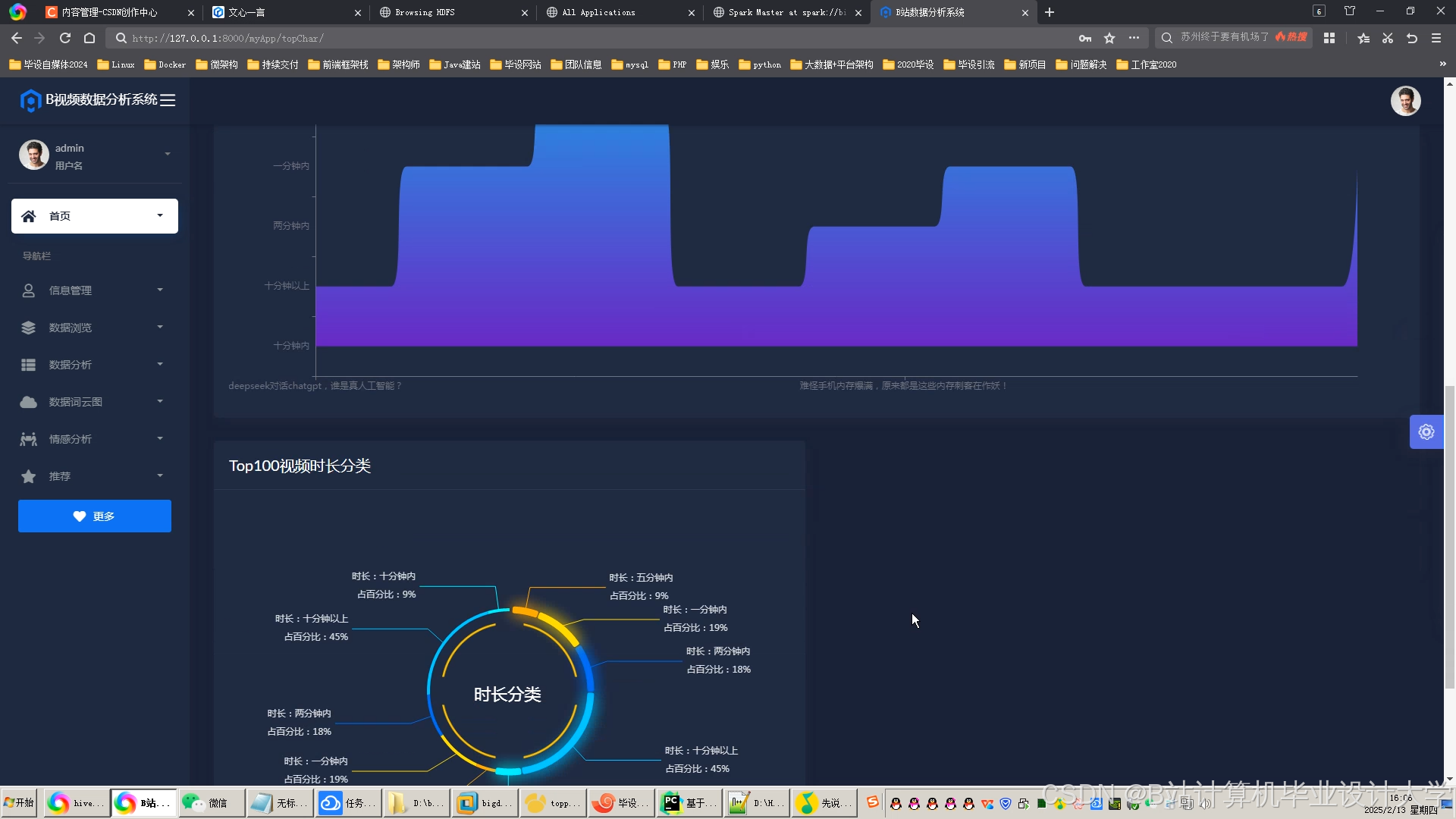
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











