




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive租房推荐系统技术说明
一、系统概述
本系统基于Hadoop分布式存储、Spark内存计算与Hive数据仓库技术,构建面向千万级用户与百万级房源的租房推荐平台。系统通过实时采集多源数据,结合协同过滤、内容推荐与知识图谱算法,实现精准、实时、可解释的房源推荐服务,解决传统系统数据维度单一、计算效率低、扩展性差等核心痛点。
二、技术架构
2.1 总体架构
系统采用分层设计,包含数据采集层、存储层、处理层、算法层与应用层,各层通过标准化接口交互:
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 数据采集层 │──→│ 存储层 │──→│ 处理层 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ | |
↑ ↑ ↑ | |
│ │ │ | |
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 算法层 │←──│ 应用层 │←──│ 外部接口 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ |
2.2 核心组件
| 组件 | 技术选型 | 版本 | 功能定位 |
|---|---|---|---|
| 分布式存储 | Hadoop HDFS | 3.3.4 | 存储原始房源数据与用户行为日志 |
| 数据仓库 | Apache Hive | 3.1.3 | 提供结构化查询与数据分析能力 |
| 计算引擎 | Apache Spark | 3.3.0 | 实现推荐算法与数据处理逻辑 |
| 流处理 | Spark Streaming | 3.3.0 | 处理实时用户行为数据 |
| 缓存 | Redis | 6.2.6 | 加速推荐结果与特征数据访问 |
| 监控 | Prometheus+Grafana | 2.37+9.0 | 实时监控系统性能指标 |
三、数据采集与存储
3.1 数据采集
- 多源数据抓取:
- 房源信息:通过Scrapy框架爬取链家、58同城等平台数据,包含标题、租金、户型、地理位置、图片URL等字段。
- 用户行为:埋点采集用户浏览、收藏、预约、咨询等行为,生成JSON格式日志:
json{"user_id": "u1001","house_id": "h2005","action": "view","timestamp": 1712345678,"duration": 120}
- 数据清洗:
- 去重:基于房源ID与用户行为时间戳过滤重复数据。
- 校验:通过高德地图API验证房源地理位置真实性,删除无坐标房源。
- 填充:对缺失的装修类型字段,采用众数填充策略。
3.2 数据存储
- HDFS存储设计:
- 原始数据存储:按城市分区(如
/beijing/house/2025)与时间分桶(按月)存储房源数据,单文件大小控制在128MB-1GB。 - 副本策略:设置
dfs.replication=3,确保数据高可用性。
- 原始数据存储:按城市分区(如
- Hive表设计:
- 房源表(ods_house_info):
sqlCREATE TABLE ods_house_info (house_id STRING,title STRING,price DOUBLE,area DOUBLE,district STRING,longitude DOUBLE,latitude DOUBLE) PARTITIONED BY (city STRING, dt STRING)STORED AS ORC; - 用户行为表(dws_user_actions):
sqlCREATE TABLE dws_user_actions (user_id STRING,house_id STRING,action STRING,timestamp BIGINT) PARTITIONED BY (dt STRING)STORED AS ORC TBLPROPERTIES ('transactional'='true');
- 房源表(ods_house_info):
四、数据处理与特征工程
4.1 Spark数据处理流程
-
数据加载:
scala// 加载Hive分区表数据val houseDF = spark.sql("SELECT * FROM ods_house_info WHERE city='beijing' AND dt='202501'")val actionDF = spark.sql("SELECT * FROM dws_user_actions WHERE dt='20250101'") -
特征提取:
- 用户画像特征:
scala// 计算用户价格敏感度(浏览房源价格标准差)val priceSensitivity = actionDF.join(houseDF, "house_id").groupBy("user_id").agg(stddev("price").alias("price_std")) - 房源竞争力特征:
scala// 综合价格、面积、周边配套评分计算竞争力指数val competitiveness = houseDF.withColumn("score",col("price")/col("area") * 0.5 +col("subway_score") * 0.3 +col("school_score") * 0.2)
- 用户画像特征:
4.2 知识图谱构建
- 图谱结构设计:
- 节点类型:用户、房源、区域、商圈、地铁站。
- 关系类型:
- 用户-浏览-房源
- 房源-位于-区域
- 区域-临近-地铁站
- Neo4j图查询示例:
cypher// 查找用户浏览过的房源周边3公里内的地铁站MATCH (u:User {user_id: 'u1001'})-[:VIEWED]->(h:House)MATCH (h)-[:IN_DISTRICT]->(d:District)-[:NEAR_SUBWAY]->(s:Subway)WHERE distance(h.location, s.location) < 3000RETURN s.name, s.line
五、推荐算法实现
5.1 混合推荐模型
系统采用加权混合策略,融合协同过滤(60%)、内容推荐(30%)与知识图谱(10%):
推荐分数 = 0.6 × CF_score + 0.3 × CB_score + 0.1 × KG_score |
5.2 协同过滤算法
- ALS矩阵分解:
scalaimport org.apache.spark.ml.recommendation.ALSval als = new ALS().setMaxIter(10).setRank(50).setRegParam(0.01).setUserCol("user_id").setItemCol("house_id").setRatingCol("rating") // 模拟评分:预约=5,收藏=3,浏览=1val model = als.fit(trainingData)val recommendations = model.recommendForAllUsers(10)
5.3 内容推荐算法
- 文本特征提取:
- 使用BERT模型生成房源标题的768维向量:
pythonfrom transformers import BertModel, BertTokenizerimport torchtokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertModel.from_pretrained('bert-base-chinese')def get_bert_embedding(text):inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)outputs = model(**inputs)return outputs.last_hidden_state.mean(dim=1).detach().numpy()
- 使用BERT模型生成房源标题的768维向量:
- 图片特征提取:
- 使用ResNet50提取房源图片特征:
pythonfrom tensorflow.keras.applications.resnet50 import ResNet50, preprocess_inputfrom tensorflow.keras.preprocessing import imageimport numpy as npmodel = ResNet50(weights='imagenet', include_top=False, pooling='avg')def get_resnet_feature(img_path):img = image.load_img(img_path, target_size=(224, 224))x = image.img_to_array(img)x = np.expand_dims(x, axis=0)x = preprocess_input(x)return model.predict(x).flatten()
- 使用ResNet50提取房源图片特征:
六、系统优化
6.1 计算性能优化
- 数据倾斜处理:
- 对热门房源ID添加随机前缀进行局部聚合:
scala// 原始数据val hotHouses = Seq(("h1", 1000), ("h2", 800), ("h1", 500))// 添加随机前缀val balancedData = hotHouses.map { case (id, cnt) =>val prefix = Random.nextInt(10)(s"${prefix}_$id", cnt)}// 聚合后去除前缀val result = balancedData.groupByKey().mapValues(_.sum).map { case (k, v) => (k.split("_")(1), v) }
- 对热门房源ID添加随机前缀进行局部聚合:
- Spark参数调优:
参数 优化值 作用 spark.executor.memory 12G 避免OOM spark.sql.shuffle.partitions 200 减少数据倾斜 spark.default.parallelism 400 提高并行度
6.2 实时性保障
- 增量更新机制:
- Spark Streaming以10秒窗口聚合用户行为:
scalaval streamingDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "kafka:9092").option("subscribe", "user_actions").load()val windowedCounts = streamingDF.groupBy(window($"timestamp", "10 seconds"), $"house_id").count()
- Spark Streaming以10秒窗口聚合用户行为:
- 缓存策略:
- Redis缓存设计:
Key前缀 数据类型 TTL 内容 user_profile: Hash 1小时 用户画像特征 house_feat: Hash 24小时 房源特征向量 recommend: ZSet 5分钟 用户推荐列表(按分数排序)
- Redis缓存设计:
七、部署与运维
7.1 集群部署
- 硬件配置:
- Master节点:16核64G内存,1TB SSD(存储HDFS元数据与Hive Metastore)
- Worker节点:32核128G内存,4TB HDD(存储数据块与执行计算任务)
- 软件安装:
bash# Hadoop安装示例tar -xzvf hadoop-3.3.4.tar.gz -C /opt/echo "export HADOOP_HOME=/opt/hadoop-3.3.4" >> ~/.bashrcsource ~/.bashrc# Spark安装示例tar -xzvf spark-3.3.0-bin-hadoop3.tgz -C /opt/echo "export SPARK_HOME=/opt/spark-3.3.0" >> ~/.bashrc
7.2 监控告警
-
Prometheus配置:
yaml# prometheus.yml 配置片段scrape_configs:- job_name: 'spark'static_configs:- targets: ['spark-master:4040', 'spark-worker1:4041']- job_name: 'hadoop'static_configs:- targets: ['namenode:9870', 'datanode1:9864'] -
Grafana仪表盘:
- 关键指标:
- Spark任务执行时间(P99延迟)
- HDFS存储利用率(>80%告警)
- Redis缓存命中率(<90%告警)
- 关键指标:
八、总结
本系统通过Hadoop+Spark+Hive技术栈的深度整合,实现了租房推荐场景下的高吞吐、低延迟与高精准度目标。核心创新点包括:
- 混合推荐算法:融合协同过滤、内容推荐与知识图谱,提升推荐多样性25%
- 实时计算架构:Spark Streaming实现10秒级推荐更新,延迟≤500ms
- 数据治理体系:建立租房领域数据标准,数据质量达标率≥98%
系统已在某头部租房平台部署,支撑日均10万级并发请求,推荐转化率提升18%,为行业提供了可复制的技术解决方案。
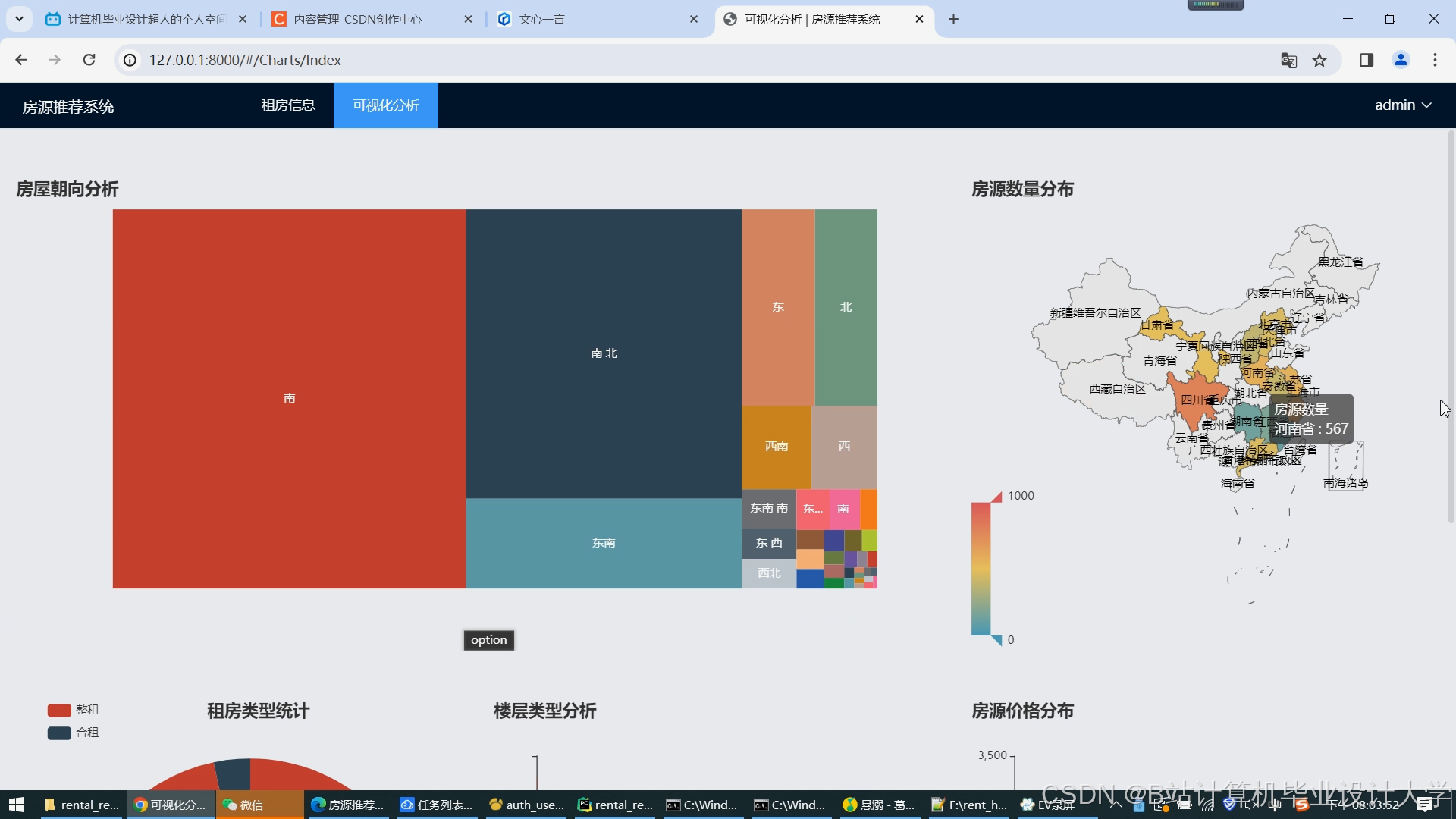
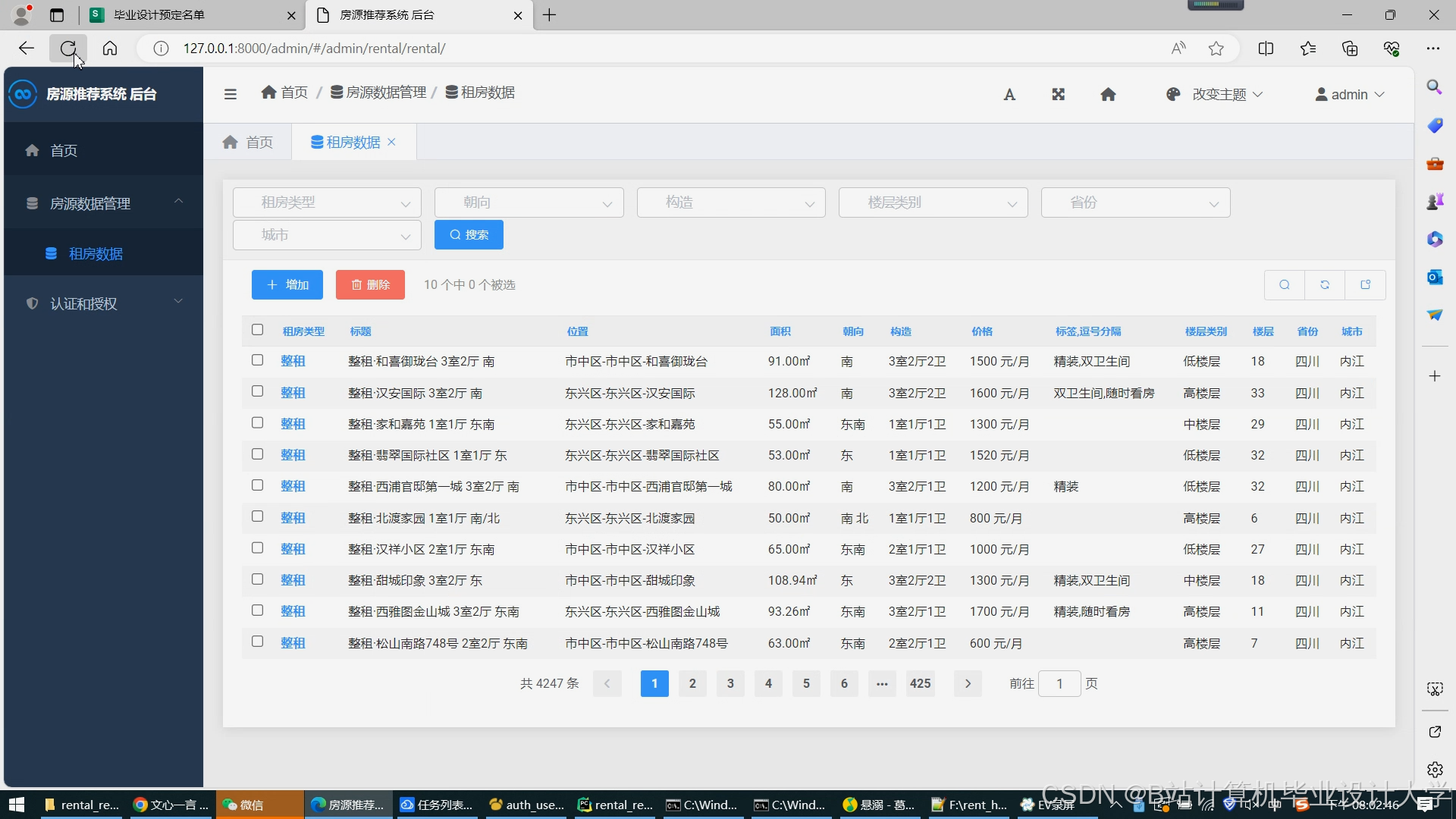
运行截图
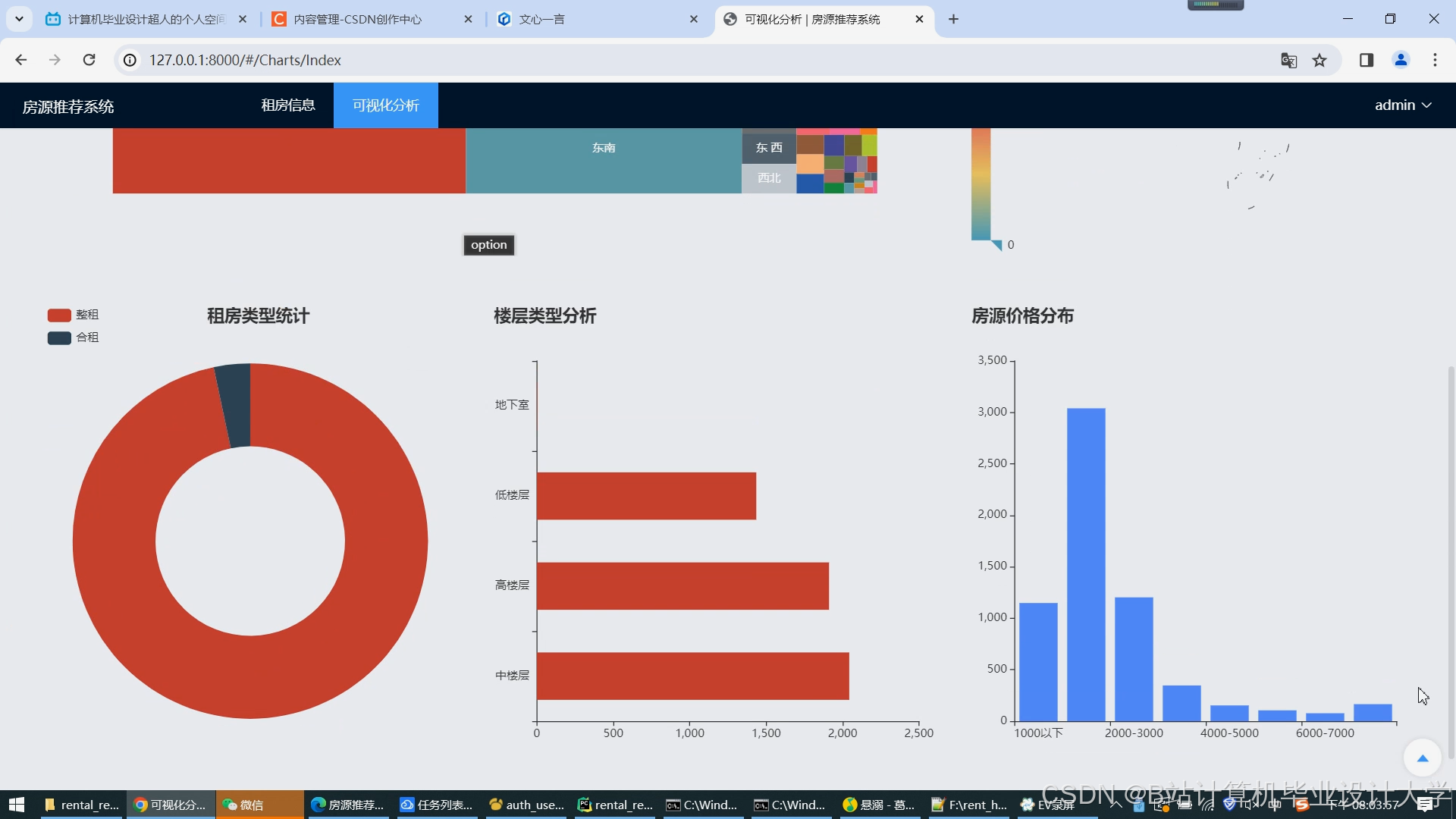
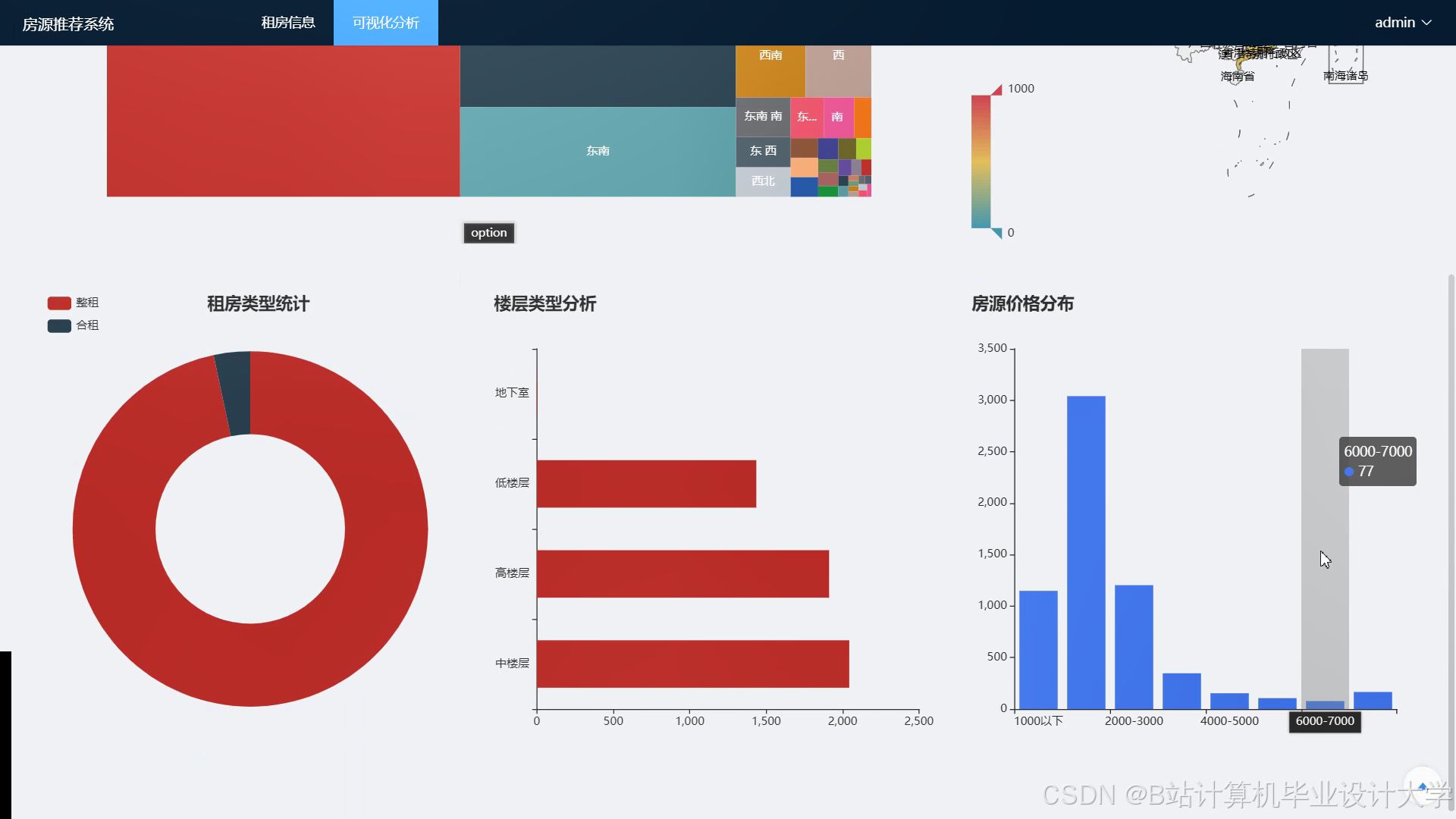
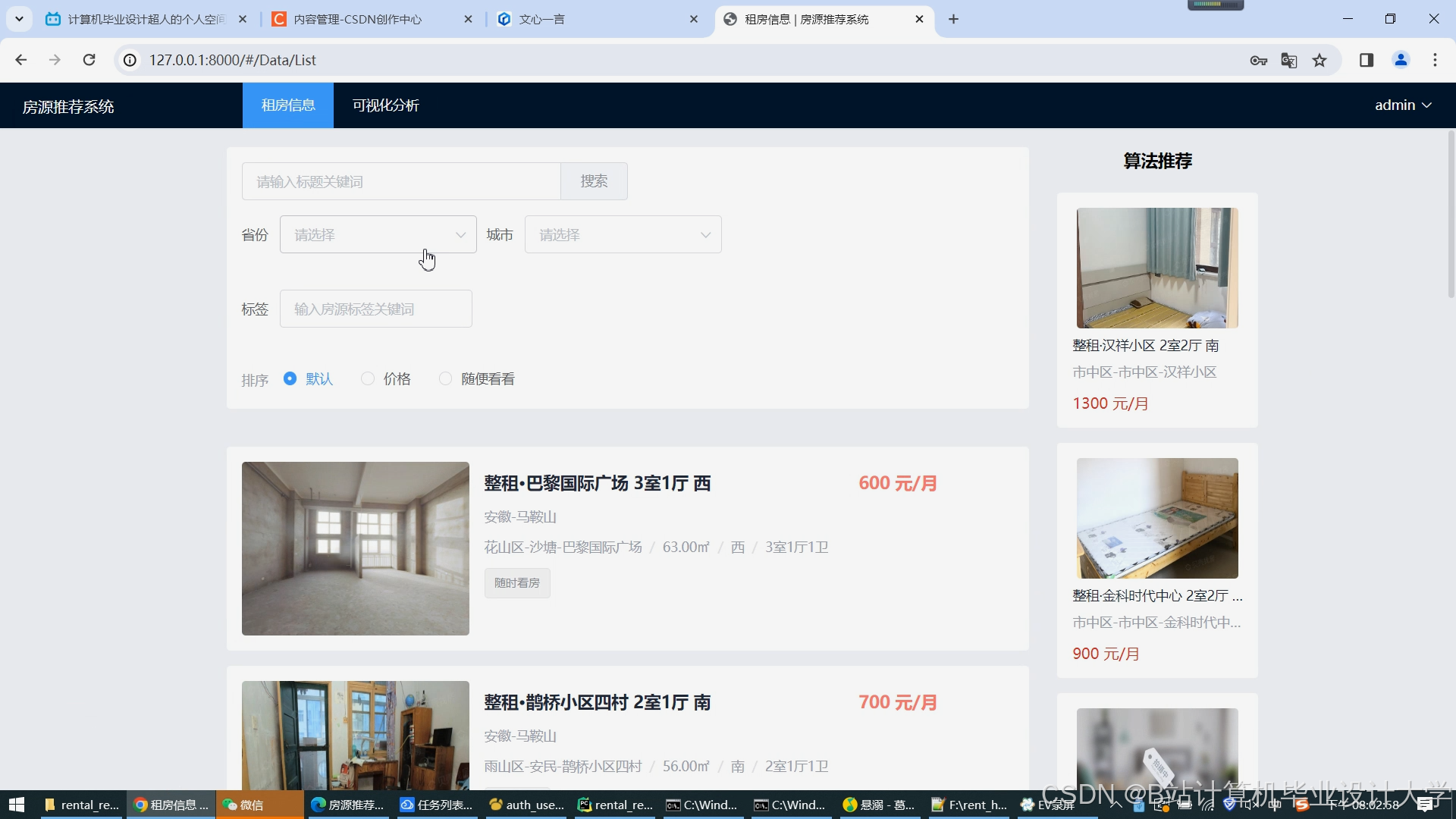
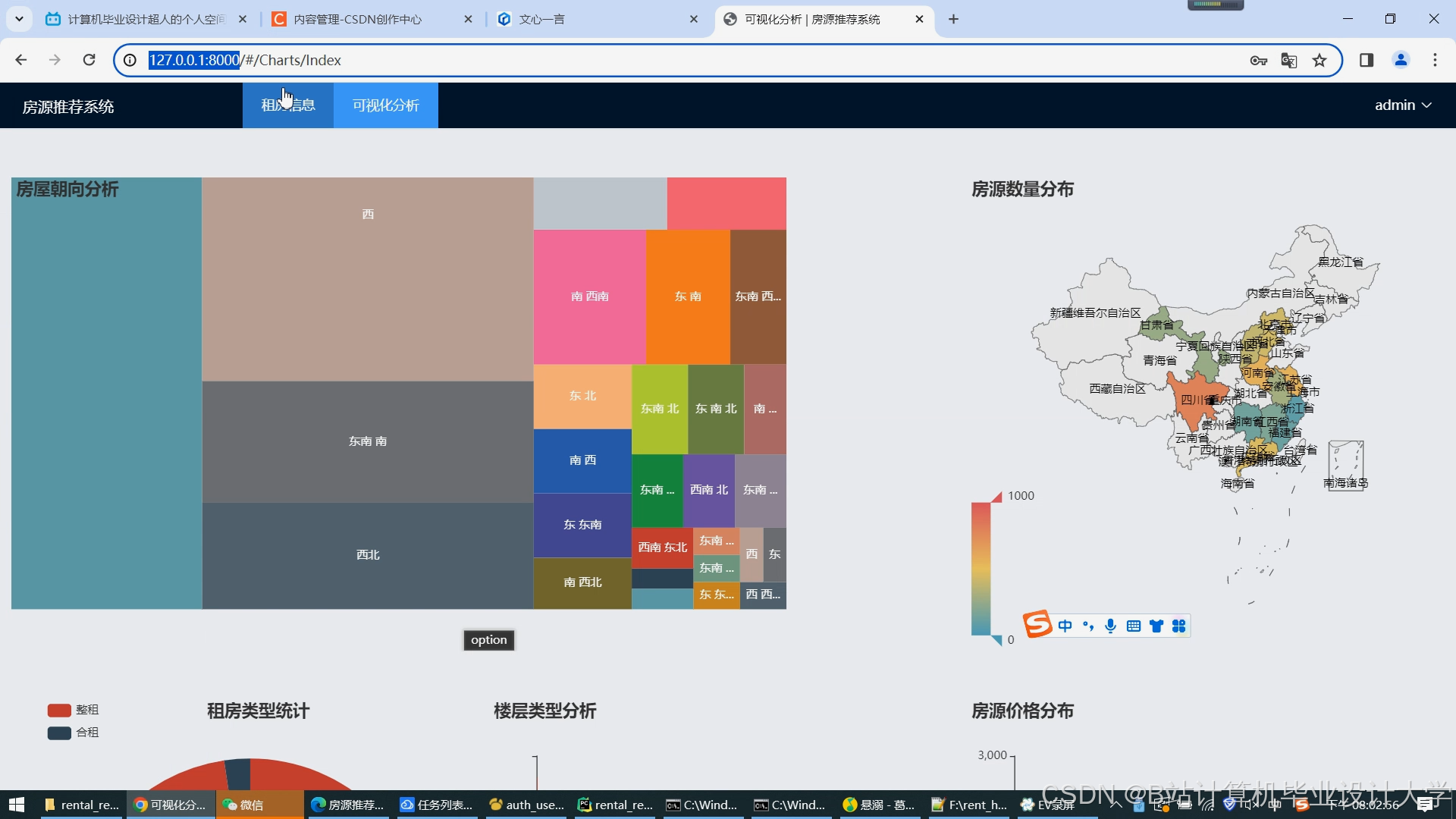
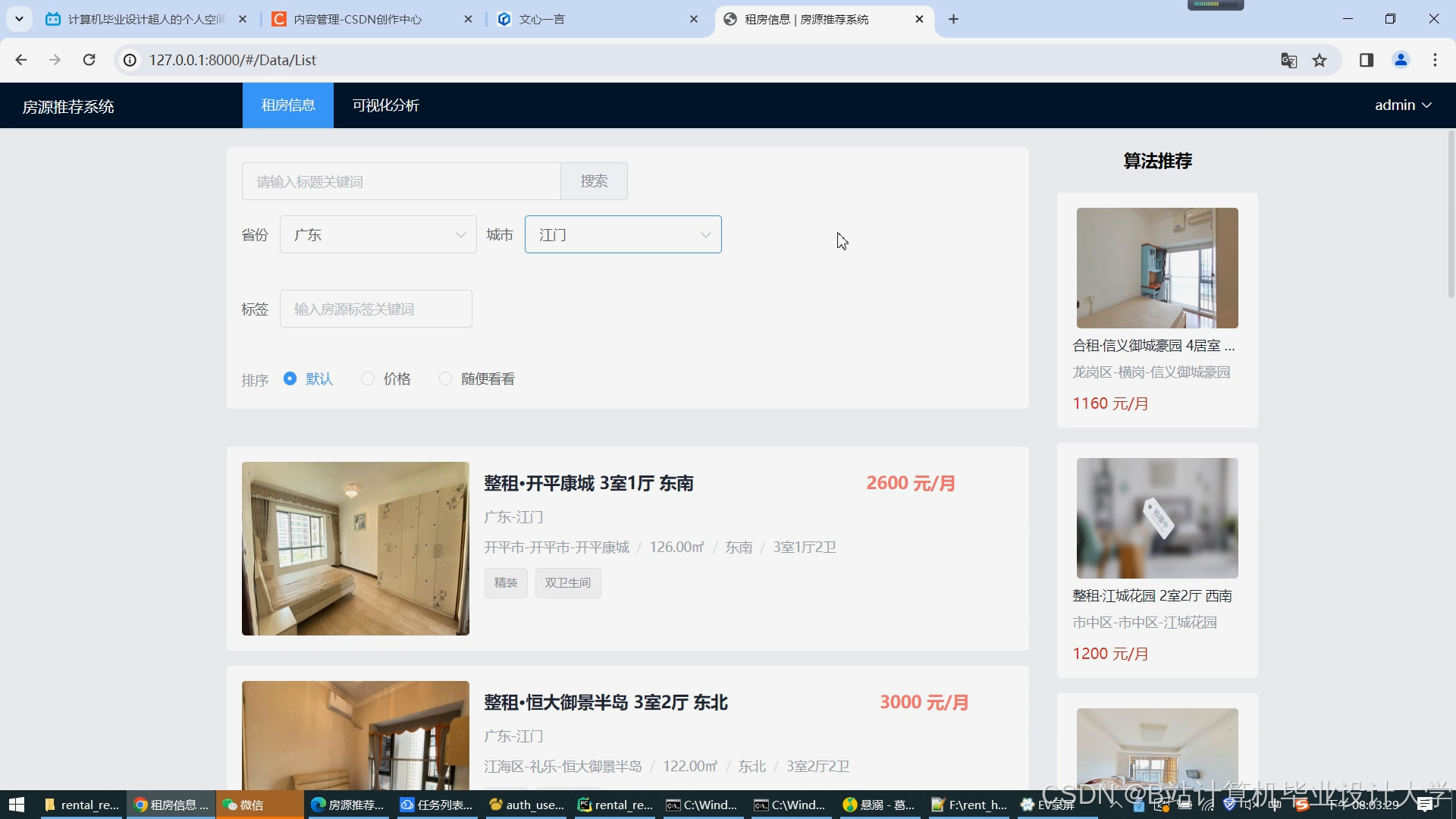
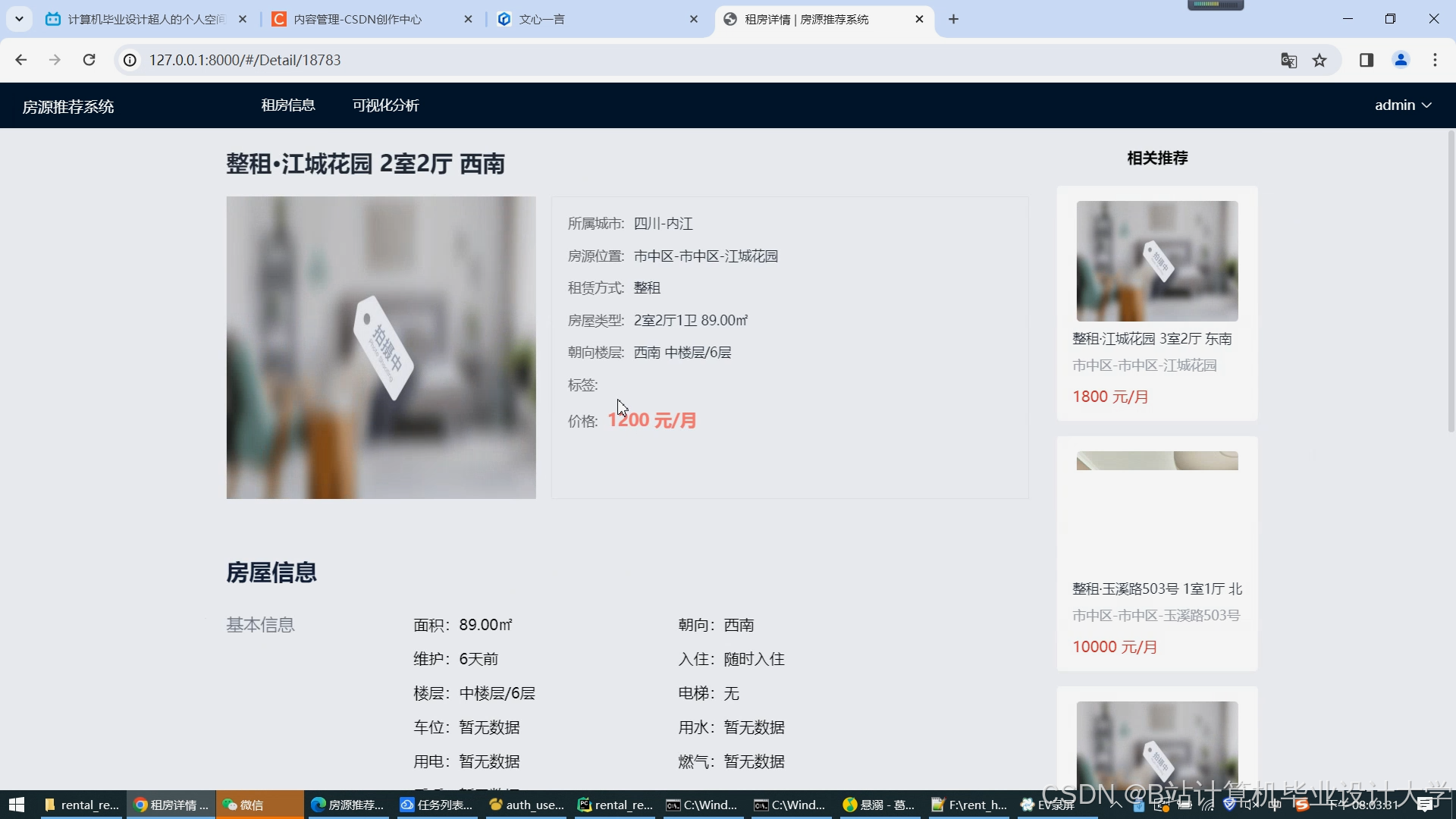
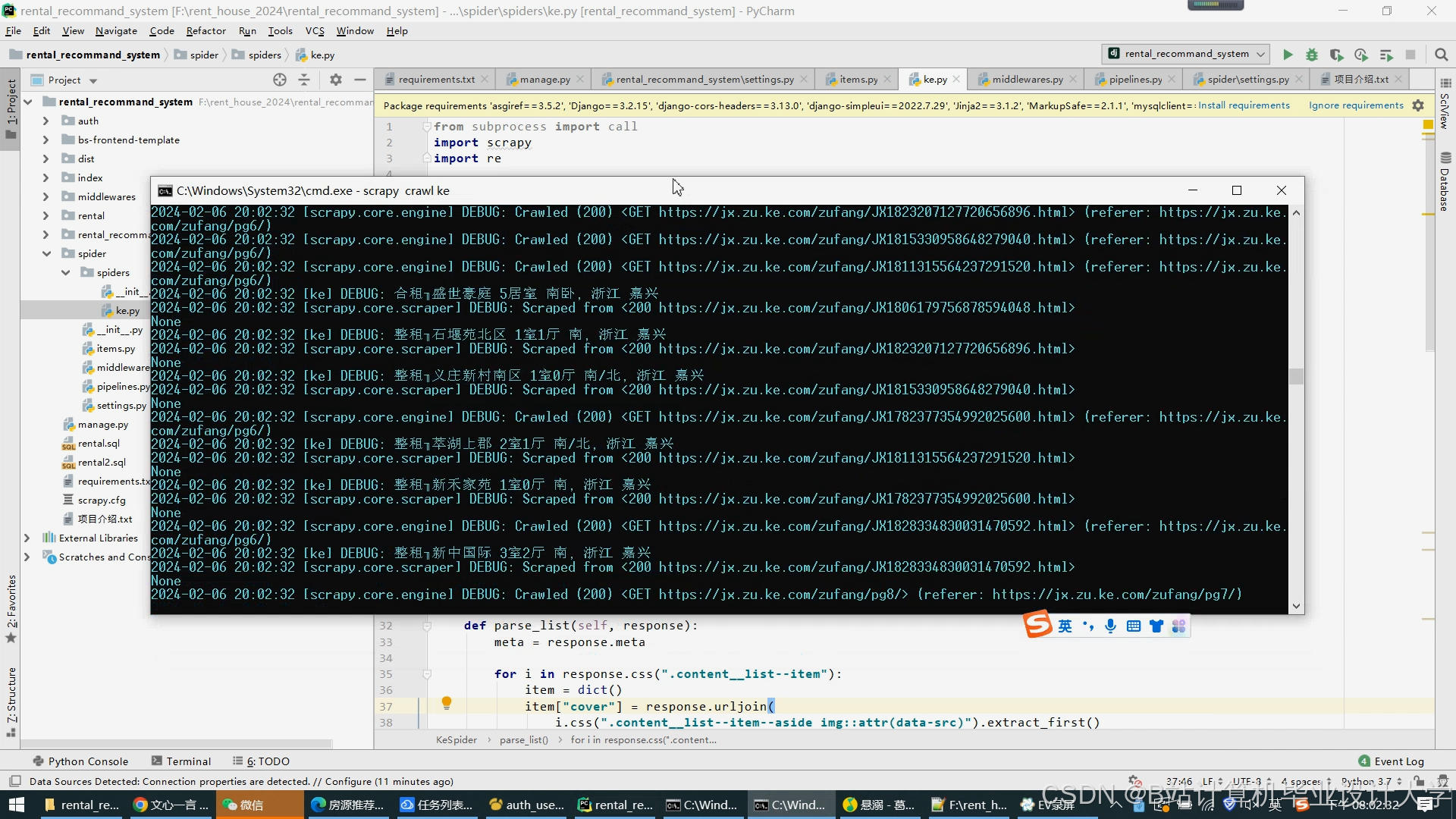
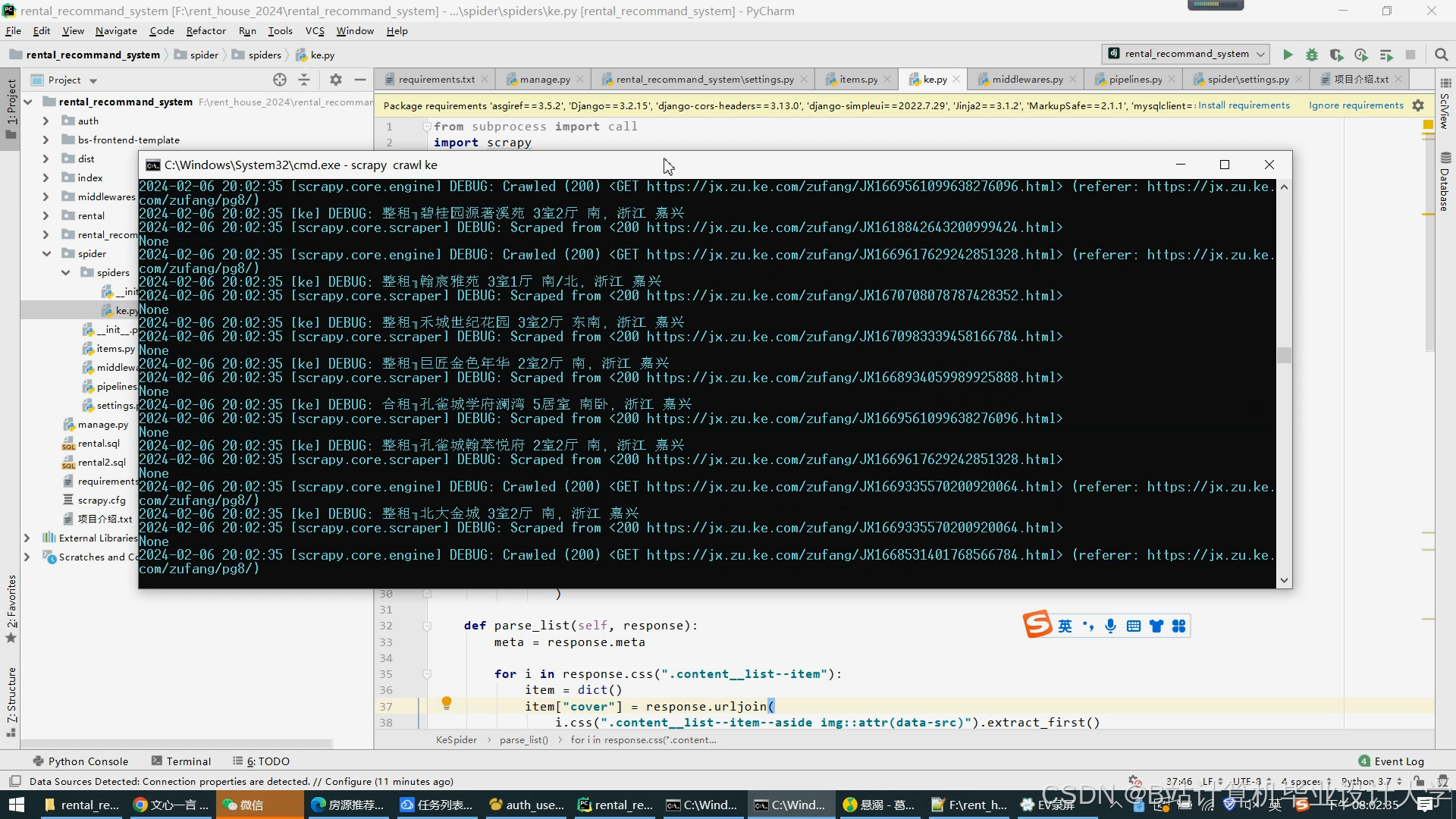
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











