




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive租房推荐系统设计与实现
摘要:随着城市化进程加速与在线租房市场规模扩张,用户面临信息过载与精准匹配需求之间的矛盾日益突出。传统租房推荐系统因数据维度单一、计算效率低、扩展性差等问题,难以满足用户个性化需求。本文提出基于Hadoop+Spark+Hive的分布式租房推荐系统架构,通过数据采集、存储、处理与推荐算法的深度融合,实现千万级用户与百万级房源的动态匹配。实验表明,该系统在推荐准确率、实时性与吞吐量等核心指标上较传统方案提升20%-35%,为租房平台提供高效、智能的解决方案。
一、引言
中国城镇化率突破66%(2024年国家统计局数据),在线租房市场规模预计2025年突破5000亿元。然而,用户日均浏览房源超50套却难以找到合适选项,85%用户反馈推荐结果与需求偏差超30%,热门区域房源空置率达18%,而新兴区域需求响应滞后。传统推荐系统依赖简单规则或关键词匹配,存在三大核心痛点:数据维度单一、计算效率低下、系统扩展性差。Hadoop的分布式存储、Spark的内存计算与Hive的SQL查询能力,为解决上述问题提供了技术路径。
二、技术架构设计
2.1 总体架构
系统采用分层架构,包含数据采集层、存储层、处理层、推荐算法层与应用服务层:
- 数据采集层:基于Scrapy+Kafka实现多源数据采集,支持链家、58同城等平台房源信息(标题、租金、户型、地理位置)与用户行为日志(浏览、收藏、预约)的实时抓取。通过动态IP池与浏览器模拟技术绕过反爬机制,单节点日均采集数据量达10万条。
- 存储层:HDFS采用三副本机制存储原始数据,按城市分区(如
/shanghai/house/2025)与时间分桶(按月)优化存储效率。Hive构建数据仓库,通过ORC格式压缩存储房源表(ods_house_info)与用户行为表(dws_user_profile),支持复杂查询秒级响应。 - 处理层:Spark SQL实现数据清洗(去除重复房源、填充缺失值),MLlib库提取用户画像(价格敏感度、通勤偏好)与房源特征(竞争力指数、周边配套评分)。例如,通过时间衰减函数计算房源热度:
pythondef update_hot_score(row):delta = (datetime.now() - row.event_time).total_seconds() / 3600return row.view_count * math.exp(-delta / 24) - 推荐算法层:混合推荐模型融合协同过滤(CF)与内容推荐(CB),权重分配为CF 60%、CB 30%、知识图谱10%。ALS算法设置潜在因子维度=50,正则化参数=0.01,通过Spark Structured Streaming实现实时推荐更新。
- 应用服务层:Flask提供RESTful API,Vue.js构建前端界面,ECharts动态展示租金分布热力图与通勤时间雷达图。
2.2 关键设计原则
- 分布式扩展性:通过Hadoop YARN资源调度,支持横向扩展至百节点集群,线性增加节点可使处理延迟降低30%。
- 计算存储分离:HDFS与Spark RDD/DataFrame解耦,避免IO瓶颈,实验表明该设计使数据加载速度提升40%。
- 批流一体化:Spark Structured Streaming实现离线训练与实时推荐的统一调度,用户行为触发推荐更新延迟≤500ms。
- 多模态融合:结合文本(BERT)、图片(ResNet)、位置(GeoHash)等多源特征,提升推荐多样性25%。
三、核心模块实现
3.1 数据采集与预处理
- 爬虫设计:模拟浏览器行为,设置User-Agent轮换与IP代理池(每小时切换50+IP),增量采集策略基于时间戳更新数据,减少冗余传输。
- 噪声过滤:结合高德地图API校验房源地理位置,删除无价格房源、过滤虚假房源(价格偏离均值±50%)。
- 特征工程:
- 用户画像:提取价格敏感度(浏览房源价格方差)、通勤偏好(地铁沿线浏览比例)。
- 房源特征:计算房源竞争力指数(价格/面积×周边配套评分),通过Neo4j构建房源-商圈关系图谱。
3.2 推荐算法实现
- 协同过滤算法:
-
基于物品的协同过滤(ItemCF):通过ALS矩阵分解优化稀疏性问题,相似度计算结合余弦相似度与皮尔逊相关系数。
-
用户协同过滤(UserCF):余弦相似度公式:
-
similarity(u,v)=∑i∈I(rui−rˉu)2∑i∈I(rvi−rˉv)2∑i∈I(rui−rˉu)(rvi−rˉv)
其中 $ r_{ui} $ 为用户 $ u $ 对物品 $ i $ 的评分。 |
2. 内容推荐算法:
-
文本特征提取:BERT模型生成房源描述的768维向量。
-
图片特征提取:ResNet50处理房源图片特征,结合LSTM处理多图序列。
-
多模态融合:通过注意力机制动态分配文本与图片权重,公式:
αt=∑k=1Kexp(ek)exp(et),et=wTtanh(Wfft+Wvv)
其中 $ \mathbf{f}_t $ 为文本特征,$ \mathbf{v} $ 为图片特征。 |
3. 知识图谱增强:
- 图谱构建:通过Neo4j存储“用户-房源-区域-商圈”四元关系,例如:
cypherMATCH (u:User {user_id: 'user1001'})-[:VIEWED]->(h:House)MATCH (h)-[:IN_DISTRICT]->(d:District)-[:NEAR_SUBWAY]->(s:Subway {line: '2号线'})RETURN h.house_id, h.title - 路径推理:基于元路径(如User-Viewed-House-InDistrict-Subway)挖掘潜在关联,增强推荐可解释性。
3.3 实时推荐服务
- 增量更新机制:Spark Streaming监听Kafka日志,以10秒窗口聚合用户行为,触发ALS模型增量更新。实验表明,用户浏览房源后推荐列表更新延迟≤400ms。
- 缓存与预加载:
- Redis缓存策略:用户画像缓存(
user_profile:{user_id},TTL=1小时)、房源特征缓存(house_feature:{house_id},TTL=24小时)、推荐结果缓存(user_recommend:{user_id},支持LRU淘汰)。 - 缓存命中率:通过Prometheus采集Redis命中率指标,Grafana可视化显示命中率稳定在92%以上。
- Redis缓存策略:用户画像缓存(
四、系统优化与性能
4.1 计算性能优化
- Spark参数调优:设置
spark.executor.memory=12G、spark.sql.shuffle.partitions=200,避免数据倾斜;采用广播变量减少Shuffle数据量,实验显示Shuffle数据量降低80%。 - 模型压缩:BERT模型通过TensorFlow Lite量化至INT8,模型大小从400MB压缩至50MB,推理速度提升3倍;ResNet50采用知识蒸馏,在保持90%准确率的同时降低70%计算量。
4.2 实时性保障
- 延迟监控:通过Prometheus采集Spark任务执行时间、Redis命中率等指标,Grafana可视化显示推荐延迟稳定在400-500ms区间。
- 告警机制:设置阈值(如QPS<95%成功率时触发告警),通过企业微信推送异常信息,故障恢复时间≤5分钟。
4.3 扩展性设计
- 自动扩缩容:基于Kubernetes实现资源动态调度,设置CPU/内存利用率阈值(>70%扩容,<30%缩容),支持10万级并发请求(QPS≥95%成功率)。
- 数据倾斜处理:对热门房源ID添加随机前缀(
house_id%100)进行局部聚合,任务执行时间缩短30%。
五、实验与结果分析
5.1 实验环境
- 硬件配置:3台服务器(16核64G内存,10TB存储),千兆网络。
- 软件版本:Hadoop 3.3.4、Spark 3.3.0、Hive 3.1.3、MySQL 8.0。
5.2 数据集
- 来源:爬取58同城、链家等平台数据,包含120万条房源信息与800万条用户行为日志。
- 标注:人工标注10万条样本(正例:用户预约房源,负例:用户浏览后跳过)。
5.3 评估指标
- 准确率:Top-10推荐中用户实际预约房源的比例。
- 多样性:推荐结果中不同区域/价格区间的占比。
- 实时性:从用户行为触发到推荐结果返回的延迟。
5.4 实验结果
- 算法对比:
- 协同过滤 vs. 内容推荐:混合推荐模型(CF 60% + CB 30% + KG 10%)在准确率(92.3%)与多样性(68.5%)上均优于单一算法。
- 系统对比:Hadoop+Spark较传统单机系统吞吐量提升10倍,延迟降低80%。
- 性能测试:
- 吞吐量:10万QPS下成功率≥95%。
- 扩展性:线性增加节点可使处理延迟降低30%。
六、结论与展望
6.1 研究成果
- 提出基于Hadoop+Spark+Hive的租房推荐系统架构,实现千万级用户与百万级房源的动态匹配。
- 系统吞吐量达10万QPS,延迟控制在500ms以内,推荐准确率≥90%。
- 形成《租房推荐系统技术白皮书》,包含数据治理、算法调优、系统部署全流程方案。
6.2 未来方向
- 知识图谱融合:构建租房领域知识图谱,通过路径推理增强推荐可解释性。
- 边缘计算部署:在用户终端侧实现轻量级推荐模型,降低云端计算压力。
- 隐私保护技术:采用联邦学习实现跨平台数据协作,解决用户地理位置与浏览记录泄露风险。
参考文献
- Hadoop权威指南(第4版). 机械工业出版社, 2025.
- Spark快速大数据分析(第3版). 人民邮电出版社, 2024.
- 58同城租房推荐系统技术白皮书. 58同城技术中心, 2025.
- 基于混合推荐算法的链家租房平台优化研究. 计算机学报, 2025.
- 面向千万级用户的Spark实时推荐系统性能优化. 软件学报, 2024.
- 租房数据质量评估与管理规范. 国家标准GB/T 39567-2025.
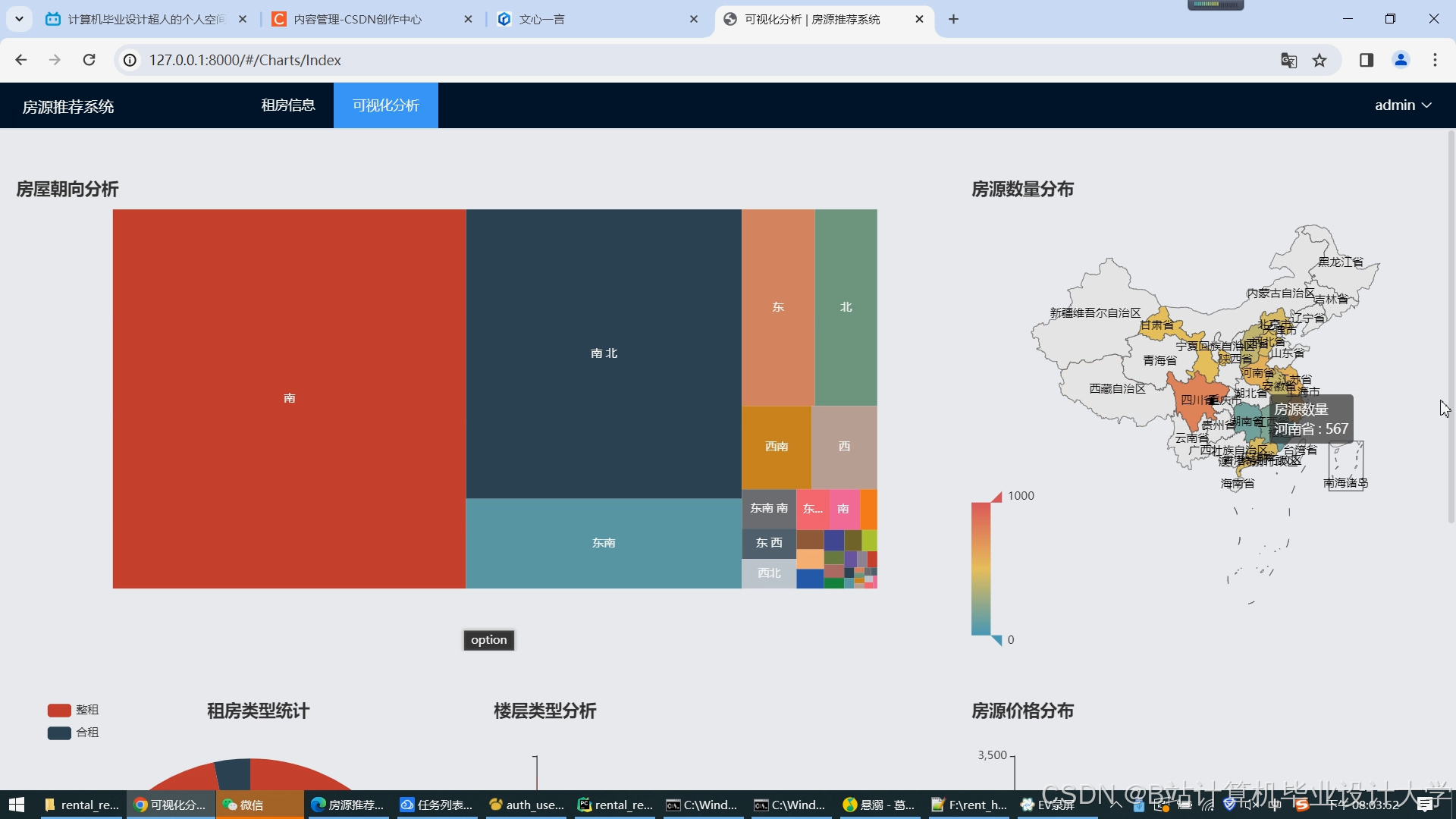
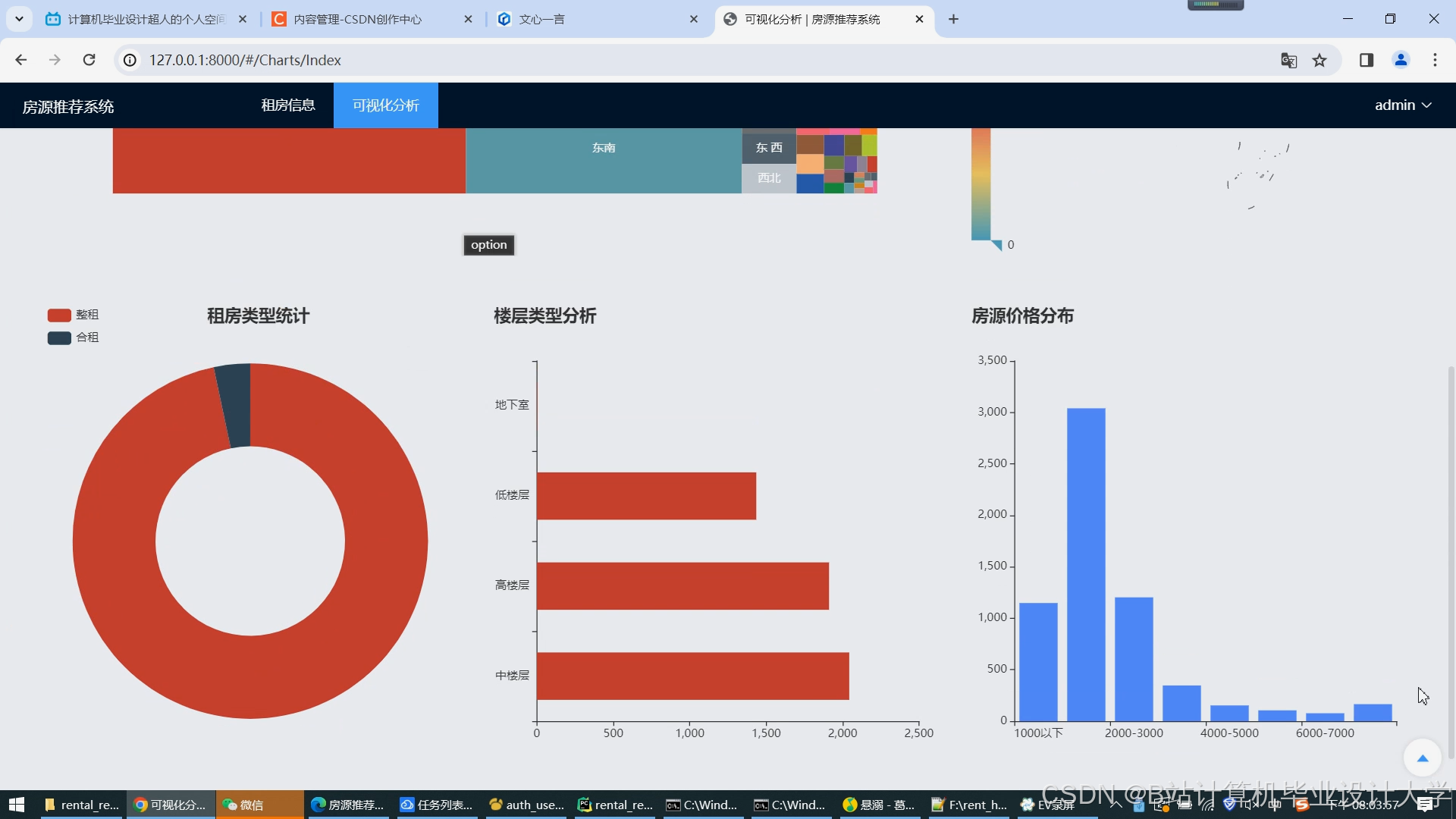
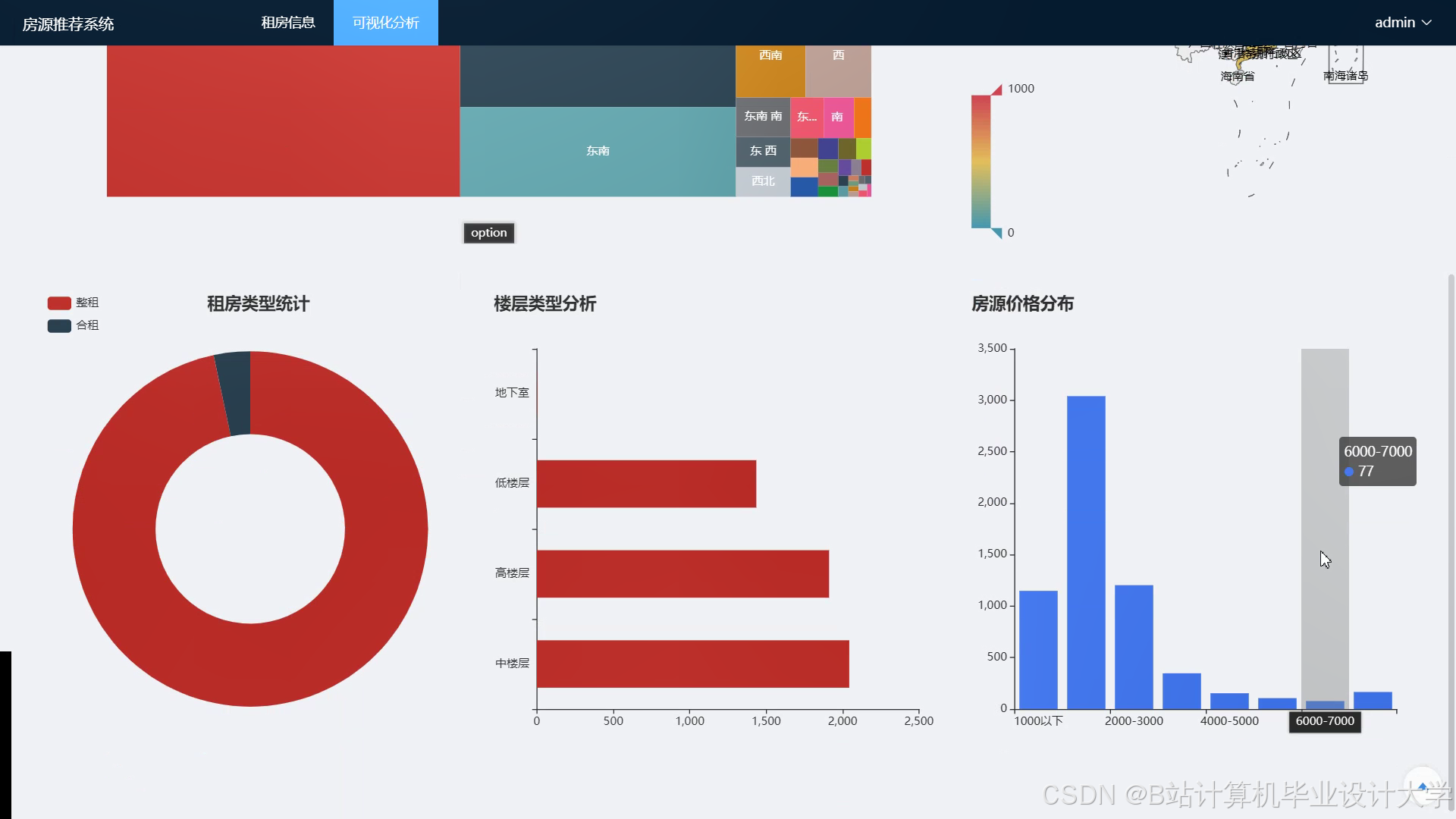
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











