




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python 技术实现中华古诗词知识图谱可视化与情感分析技术说明
一、引言
中华古诗词作为中华民族的文化瑰宝,承载着丰富的历史、文化和情感内涵。然而,传统的学习与欣赏方式难以全面挖掘古诗词的价值。借助 Python 技术构建中华古诗词知识图谱并进行可视化展示,同时开展情感分析,能够以直观、交互的方式呈现古诗词的知识结构和情感特征,为古诗词的研究、教学与传承提供新的途径。本技术说明将详细阐述基于 Python 实现中华古诗词知识图谱可视化与情感分析的技术流程和方法。
二、技术架构概述
整个系统主要由数据采集与预处理模块、知识图谱构建模块、情感分析模块和可视化模块组成。数据采集与预处理模块负责从网络获取古诗词数据并进行清洗和格式化;知识图谱构建模块提取实体和关系,构建知识图谱并存储;情感分析模块对古诗词进行情感分类;可视化模块将知识图谱和情感分析结果以图形化方式展示。
三、各模块技术实现
(一)数据采集与预处理
- 数据采集
- 使用 Python 的
requests库发送 HTTP 请求,获取古诗词网页内容。例如,要获取古诗文网上的古诗词数据,可以通过以下代码发送请求:
- 使用 Python 的
python
import requests | |
url = 'https://www.gushiwen.org/shiwenv_xxxx.aspx' # 具体诗词页面 URL | |
headers = {'User-Agent': 'Mozilla/5.0'} | |
response = requests.get(url, headers=headers) | |
html_content = response.text |
- 利用 `BeautifulSoup` 或 `lxml` 库解析 HTML 文档,提取古诗词的标题、作者、朝代、正文、注释等信息。以 `BeautifulSoup` 为例: |
python
from bs4 import BeautifulSoup | |
soup = BeautifulSoup(html_content, 'html.parser') | |
title = soup.find('h1').text # 假设标题在 h1 标签中 | |
author = soup.find('p', class_='source').a.text # 假设作者信息在特定 p 标签的 a 标签中 | |
poem_content = '\n'.join([p.text for p in soup.find_all('p', class_='cont')]) # 假设正文在特定 p 标签中 |
- 数据预处理
- 文本清洗:去除 HTML 标签、特殊字符、多余的空格等。可以使用正则表达式实现:
python
import re | |
# 去除 HTML 标签 | |
clean_content = re.sub(r'<[^>]+>', '', poem_content) | |
# 去除多余空格 | |
clean_content = re.sub(r'\s+', ' ', clean_content).strip() |
- **分词与词性标注**:使用 `jieba` 库对古诗词文本进行分词,并结合自定义词典提高分词准确性。同时,利用 `jieba.posseg` 进行词性标注。 |
python
import jieba | |
import jieba.posseg as pseg | |
jieba.load_userdict('custom_dict.txt') # 加载自定义词典 | |
words = pseg.cut(clean_content) | |
for word, flag in words: | |
print(f'{word}/{flag}') |
- **停用词过滤**:构建停用词表,去除无意义的停用词,如“的”“了”“是”等。 |
python
stopwords = set() | |
with open('stopwords.txt', 'r', encoding='utf-8') as f: | |
for line in f: | |
stopwords.add(line.strip()) | |
filtered_words = [word for word, flag in words if word not in stopwords] |
(二)知识图谱构建
- 实体识别
- 采用基于规则和机器学习相结合的方法识别实体。例如,通过定义规则识别诗人、朝代等实体,同时利用
sklearn库中的机器学习算法(如决策树、支持向量机等)对标注好的训练数据进行学习,构建实体识别模型。
- 采用基于规则和机器学习相结合的方法识别实体。例如,通过定义规则识别诗人、朝代等实体,同时利用
python
from sklearn.feature_extraction.text import TfidfVectorizer | |
from sklearn.tree import DecisionTreeClassifier | |
from sklearn.model_selection import train_test_split | |
from sklearn.metrics import accuracy_score | |
# 假设有标注好的训练数据 | |
X_train, X_test, y_train, y_test = train_test_split(train_texts, train_labels, test_size=0.2) | |
vectorizer = TfidfVectorizer() | |
X_train_vec = vectorizer.fit_transform(X_train) | |
X_test_vec = vectorizer.transform(X_test) | |
clf = DecisionTreeClassifier() | |
clf.fit(X_train_vec, y_train) | |
y_pred = clf.predict(X_test_vec) | |
print(f'Accuracy: {accuracy_score(y_test, y_pred)}') |
- 关系抽取
- 通过分析诗词文本中的语法结构和语义信息,抽取实体之间的关系。例如,利用依存句法分析工具(如
LTP或HanLP)获取词语之间的依存关系,从而确定“诗人 - 作品”“作品 - 朝代”等关系。
- 通过分析诗词文本中的语法结构和语义信息,抽取实体之间的关系。例如,利用依存句法分析工具(如
python
# 以 LTP 为例 | |
from ltp import LTP | |
ltp = LTP() | |
seg, hidden = ltp.seg([poem_content]) | |
postag = ltp.postag(hidden) | |
ner = ltp.ner(hidden) | |
dep = ltp.dep(hidden) | |
# 根据依存关系抽取关系 | |
for head, deprel, dependent in zip(dep[0][:, 0], dep[0][:, 1], dep[0][:, 2]): | |
if deprel == 'SBV' and ner[0][head] == 'PER' and ner[0][dependent] == 'ORG': # 假设诗人是 PER,作品所属机构(朝代等)可视为 ORG 的变体处理 | |
print(f'诗人 - 作品关系:{seg[0][dependent]} 是 {seg[0][head]} 的作品所属朝代相关实体') |
- 知识图谱存储
- 选择
Neo4j图数据库进行存储。使用Py2neo库连接 Python 和Neo4j,将识别出的实体和关系存储到数据库中。
- 选择
python
from py2neo import Graph, Node, Relationship | |
graph = Graph("bolt://localhost:7687", auth=("username", "password")) | |
# 创建节点 | |
poet_node = Node("Poet", name=author, dynasty=dynasty) | |
poem_node = Node("Poem", title=title, content=poem_content) | |
# 创建关系 | |
rel = Relationship(poet_node, "CREATE", poem_node) | |
# 提交到数据库 | |
graph.create(poet_node) | |
graph.create(poem_node) | |
graph.create(rel) |
(三)情感分析
- 情感词典构建
- 收集通用情感词典和古诗词领域情感词典,合并并去重,构建适合古诗词情感分析的情感词典。为每个情感词赋予情感极性(正向、负向、中性)和情感强度值。
- 情感分类模型
- 采用深度学习模型(如
BiLSTM结合Attention机制)对古诗词进行情感分类。使用transformers库加载预训练模型,在古诗词数据上进行微调。
- 采用深度学习模型(如
python
from transformers import BertTokenizer, BertForSequenceClassification | |
from transformers import Trainer, TrainingArguments | |
import torch | |
from torch.utils.data import Dataset | |
# 自定义数据集类 | |
class PoemDataset(Dataset): | |
def __init__(self, texts, labels, tokenizer, max_length): | |
self.texts = texts | |
self.labels = labels | |
self.tokenizer = tokenizer | |
self.max_length = max_length | |
def __len__(self): | |
return len(self.texts) | |
def __getitem__(self, idx): | |
text = self.texts[idx] | |
label = self.labels[idx] | |
encoding = self.tokenizer.encode_plus( | |
text, | |
add_special_tokens=True, | |
max_length=self.max_length, | |
padding='max_length', | |
truncation=True, | |
return_tensors='pt' | |
) | |
return { | |
'input_ids': encoding['input_ids'].flatten(), | |
'attention_mask': encoding['attention_mask'].flatten(), | |
'labels': torch.tensor(label, dtype=torch.long) | |
} | |
# 加载预训练模型和分词器 | |
model_name = 'bert-base-chinese' | |
tokenizer = BertTokenizer.from_pretrained(model_name) | |
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=3) # 假设有 3 种情感类别 | |
# 准备数据 | |
train_texts = [...] # 训练文本列表 | |
train_labels = [...] # 训练标签列表 | |
val_texts = [...] # 验证文本列表 | |
val_labels = [...] # 验证标签列表 | |
train_dataset = PoemDataset(train_texts, train_labels, tokenizer, max_length=128) | |
val_dataset = PoemDataset(val_texts, val_labels, tokenizer, max_length=128) | |
# 定义训练参数 | |
training_args = TrainingArguments( | |
output_dir='./results', | |
num_train_epochs=3, | |
per_device_train_batch_size=8, | |
per_device_eval_batch_size=8, | |
evaluation_strategy='epoch', | |
save_strategy='epoch', | |
logging_dir='./logs', | |
) | |
# 创建 Trainer 并训练模型 | |
trainer = Trainer( | |
model=model, | |
args=training_args, | |
train_dataset=train_dataset, | |
eval_dataset=val_dataset | |
) | |
trainer.train() |
(四)可视化
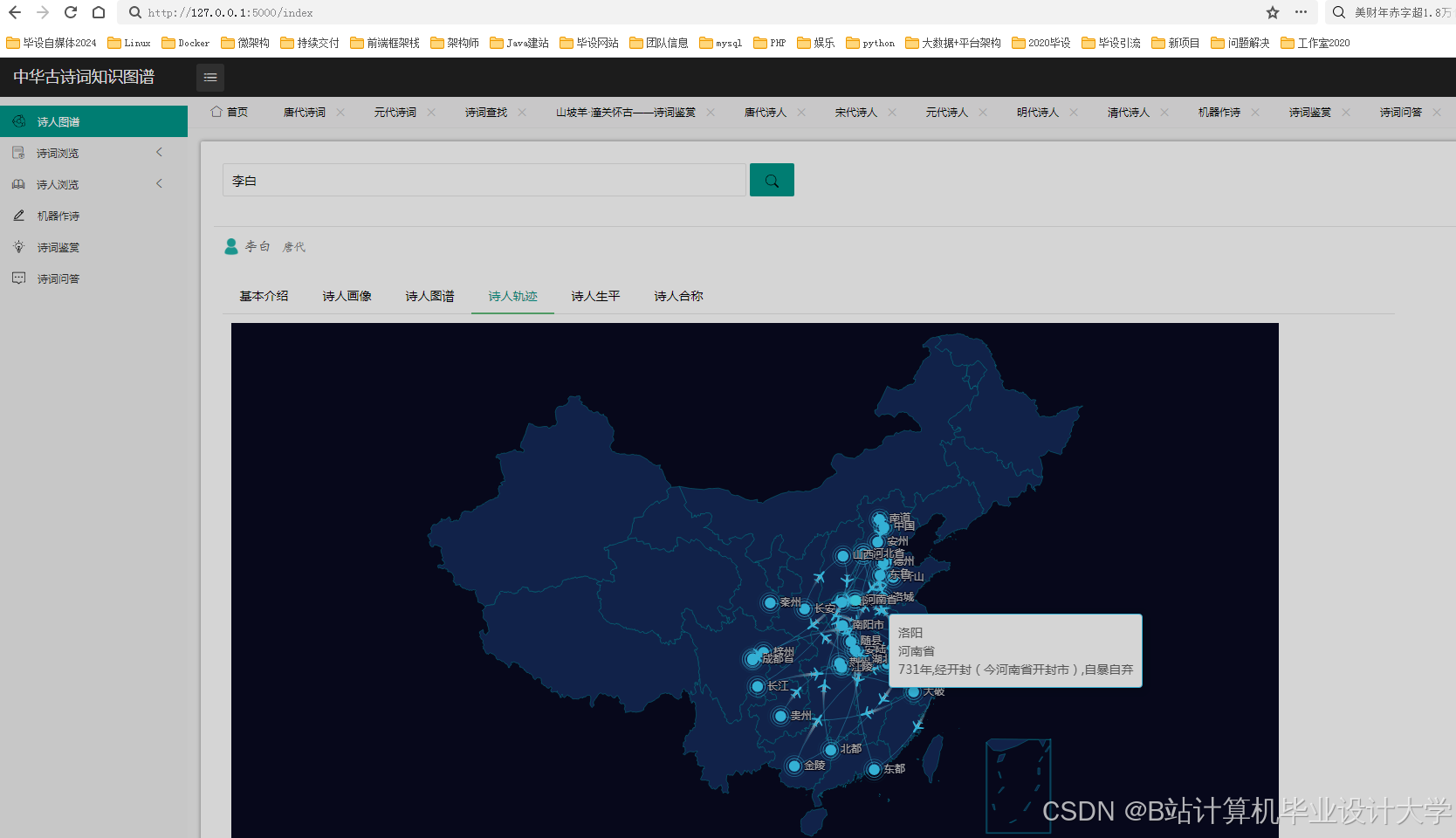
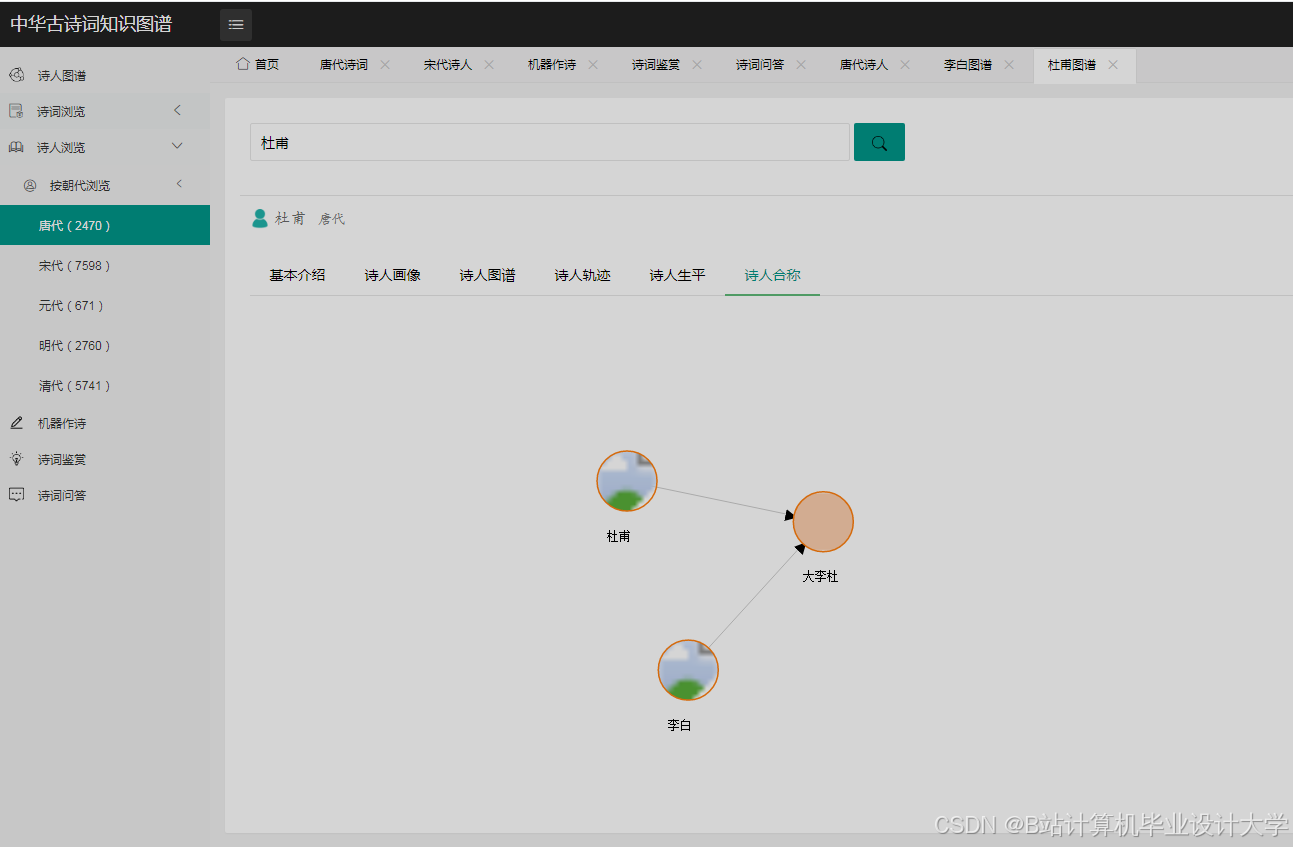
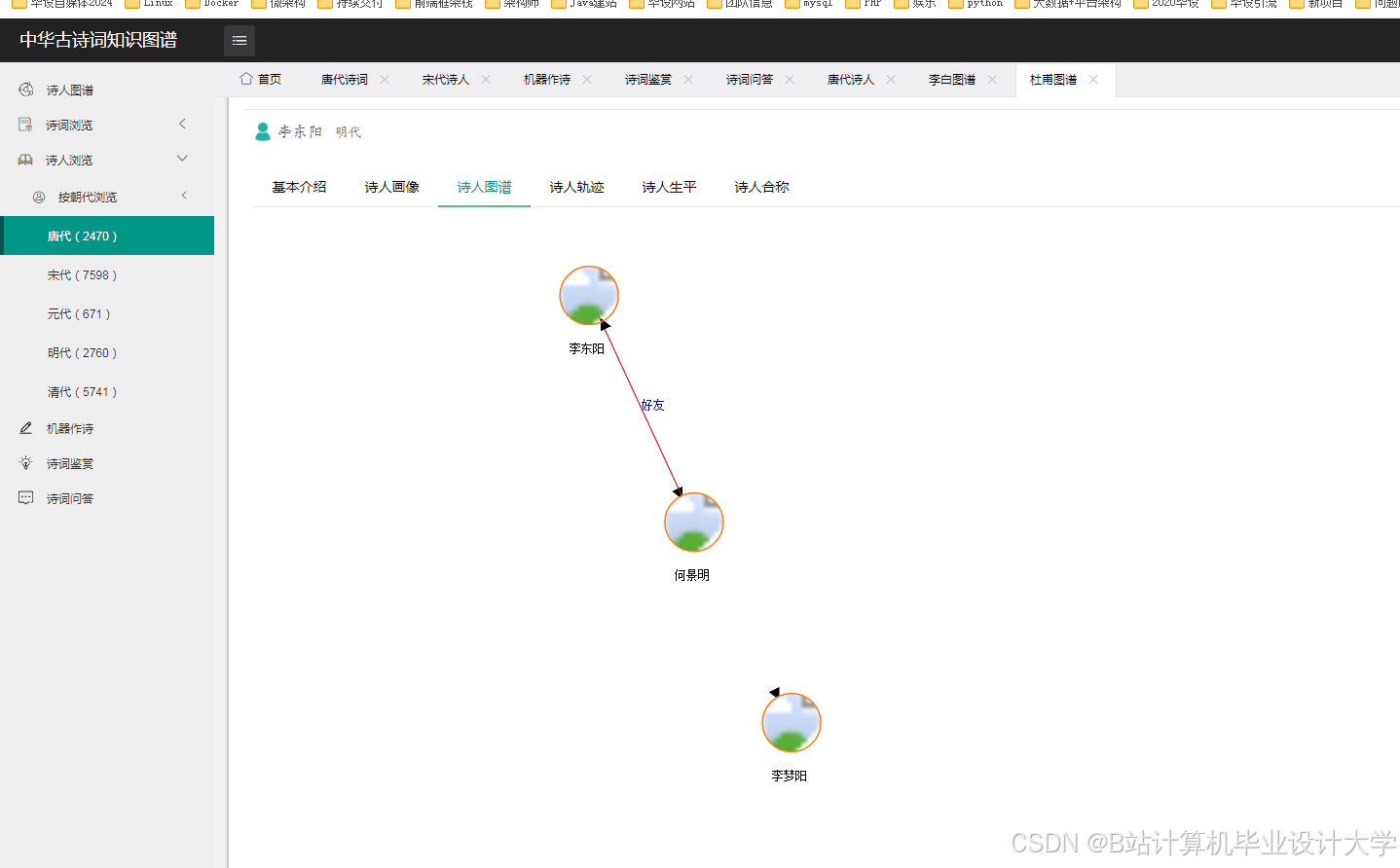
- 知识图谱可视化
- 使用
D3.js或Pyecharts库将Neo4j中的知识图谱数据以图形化方式展示。以Pyecharts为例:
- 使用
python
from pyecharts import options as opts | |
from pyecharts.charts import Graph | |
# 从 Neo4j 获取节点和边数据 | |
nodes = [...] # 节点列表,包含节点名称、类别等信息 | |
links = [...] # 边列表,包含源节点、目标节点等信息 | |
# 创建 Graph 对象 | |
graph = ( | |
Graph() | |
.add( | |
"", | |
nodes, | |
links, | |
repulsion=8000, | |
linestyle_opts=opts.LineStyleOpts(curve=0.2), | |
label_opts=opts.LabelOpts(position="right"), | |
) | |
.set_global_opts(title_opts=opts.TitleOpts(title="中华古诗词知识图谱")) | |
) | |
# 渲染图表到 HTML 文件 | |
graph.render("poem_knowledge_graph.html") |
- 情感分析结果可视化
- 使用
Matplotlib或Pyecharts将情感分析结果以柱状图、饼图等形式展示。
- 使用
python
from pyecharts.charts import Bar | |
# 假设有不同情感类别的诗词数量统计 | |
sentiment_labels = ['Positive', 'Negative', 'Neutral'] | |
sentiment_counts = [10, 5, 8] | |
bar = ( | |
Bar() | |
.add_xaxis(sentiment_labels) | |
.add_yaxis("Number of Poems", sentiment_counts) | |
.set_global_opts(title_opts=opts.TitleOpts(title="Poem Sentiment Analysis")) | |
) | |
bar.render("poem_sentiment_bar.html") |
四、系统部署与应用
- 系统部署
- 将 Python 代码部署到服务器上,可以使用
Flask或Django框架构建 Web 应用,提供用户界面。例如,使用Flask创建一个简单的 Web 应用:
- 将 Python 代码部署到服务器上,可以使用
python
from flask import Flask, render_template | |
app = Flask(__name__) | |
@app.route('/') | |
def index(): | |
return render_template('index.html') # 包含知识图谱和情感分析可视化结果的页面 | |
if __name__ == '__main__': | |
app.run(host='0.0.0.0', port=5000) |
- 应用场景
- 教育领域:教师可以将该系统作为教学工具,帮助学生更好地理解古诗词的知识结构和情感内涵。
- 文化研究:研究人员可以利用知识图谱和情感分析结果,深入研究古诗词的发展脉络和文化价值。
- 文化传播:通过 Web 应用的形式,向广大用户展示中华古诗词的魅力,促进文化的传承和传播。
五、总结
本技术说明详细介绍了利用 Python 实现中华古诗词知识图谱可视化与情感分析的技术流程和方法。通过数据采集与预处理、知识图谱构建、情感分析和可视化等模块的协同工作,能够有效地挖掘古诗词的知识和情感信息,并以直观的方式呈现给用户。未来,可以进一步优化模型性能,拓展数据来源,提高系统的实用性和稳定性,为中华古诗词文化的传承和发展做出更大的贡献。
运行截图
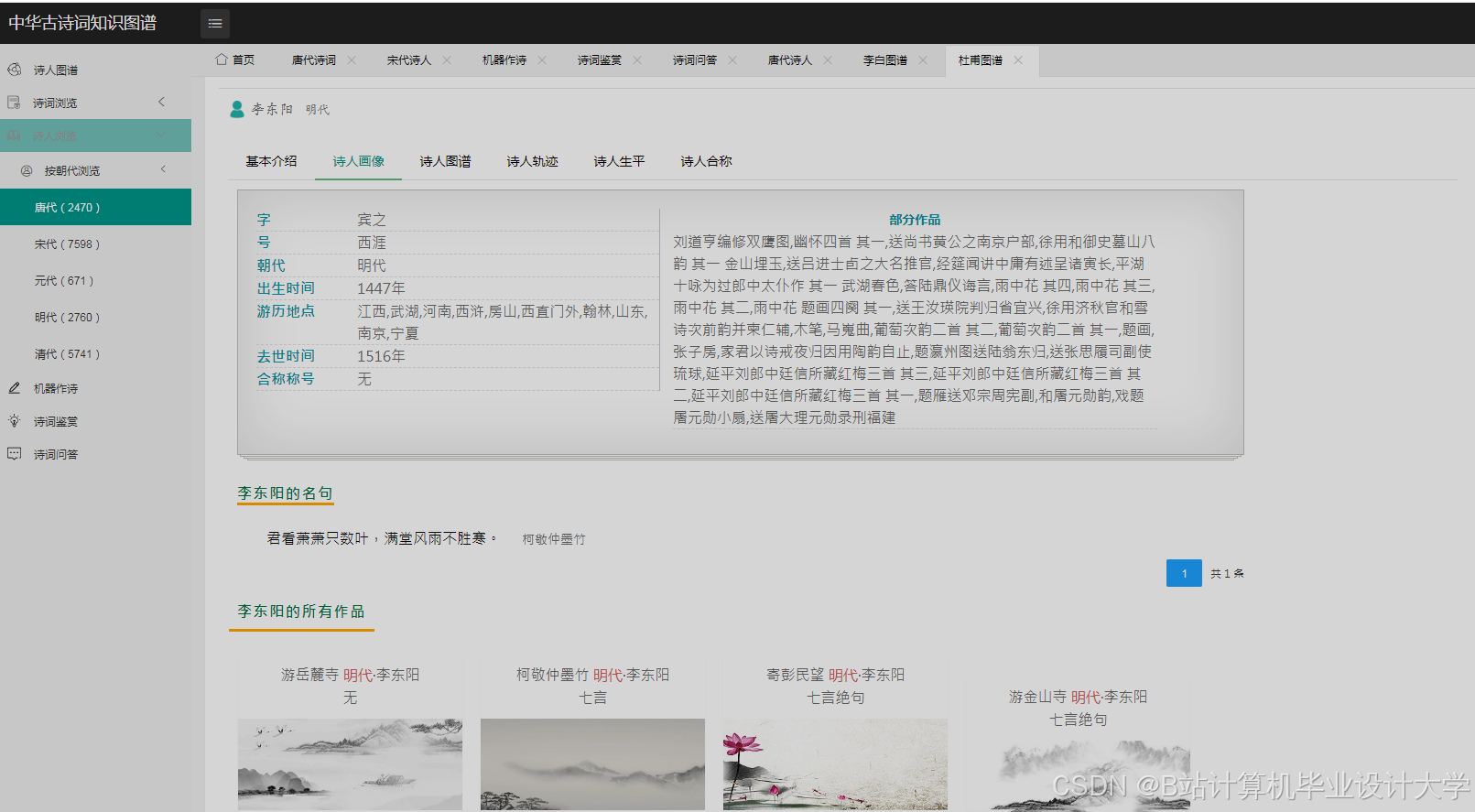
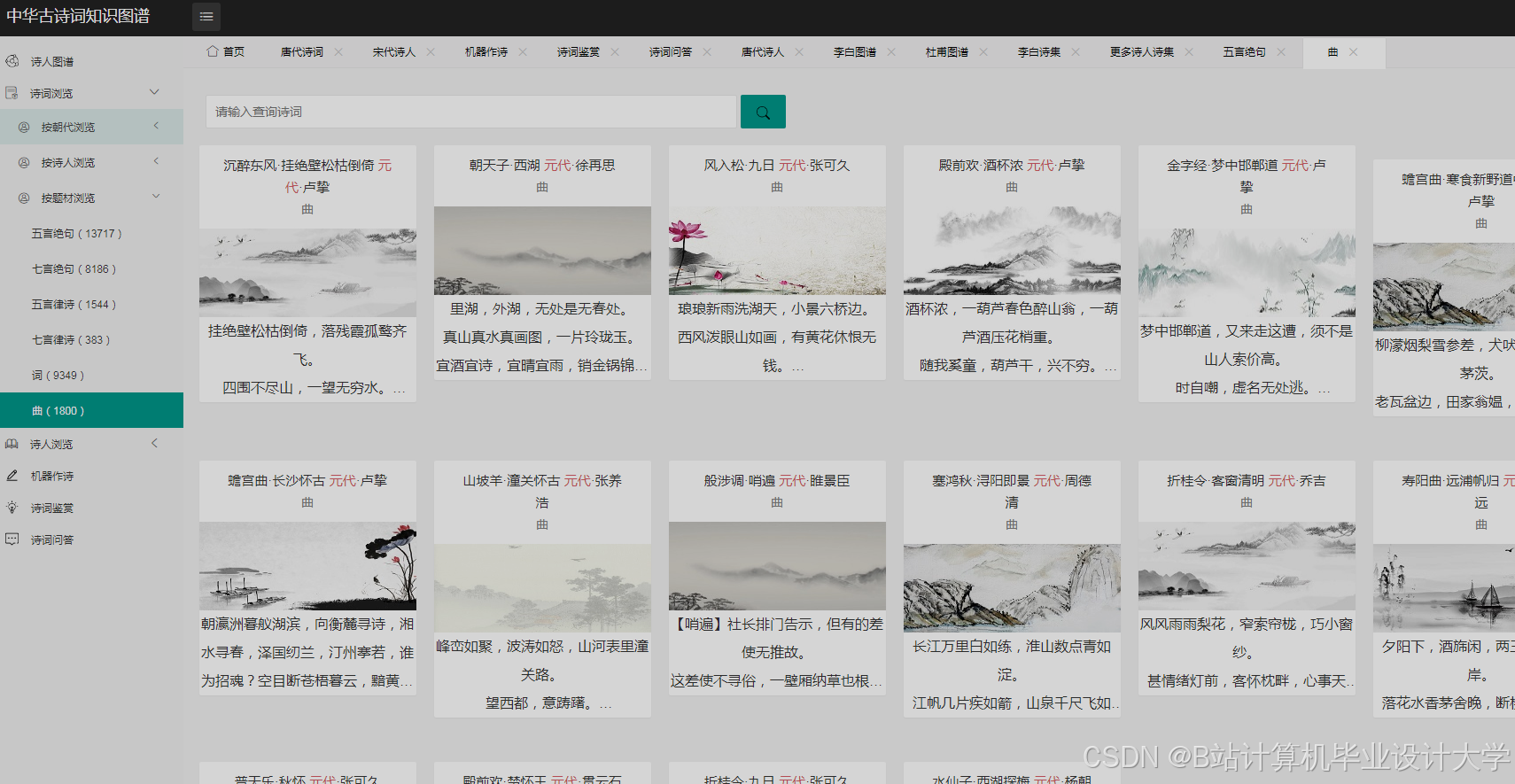
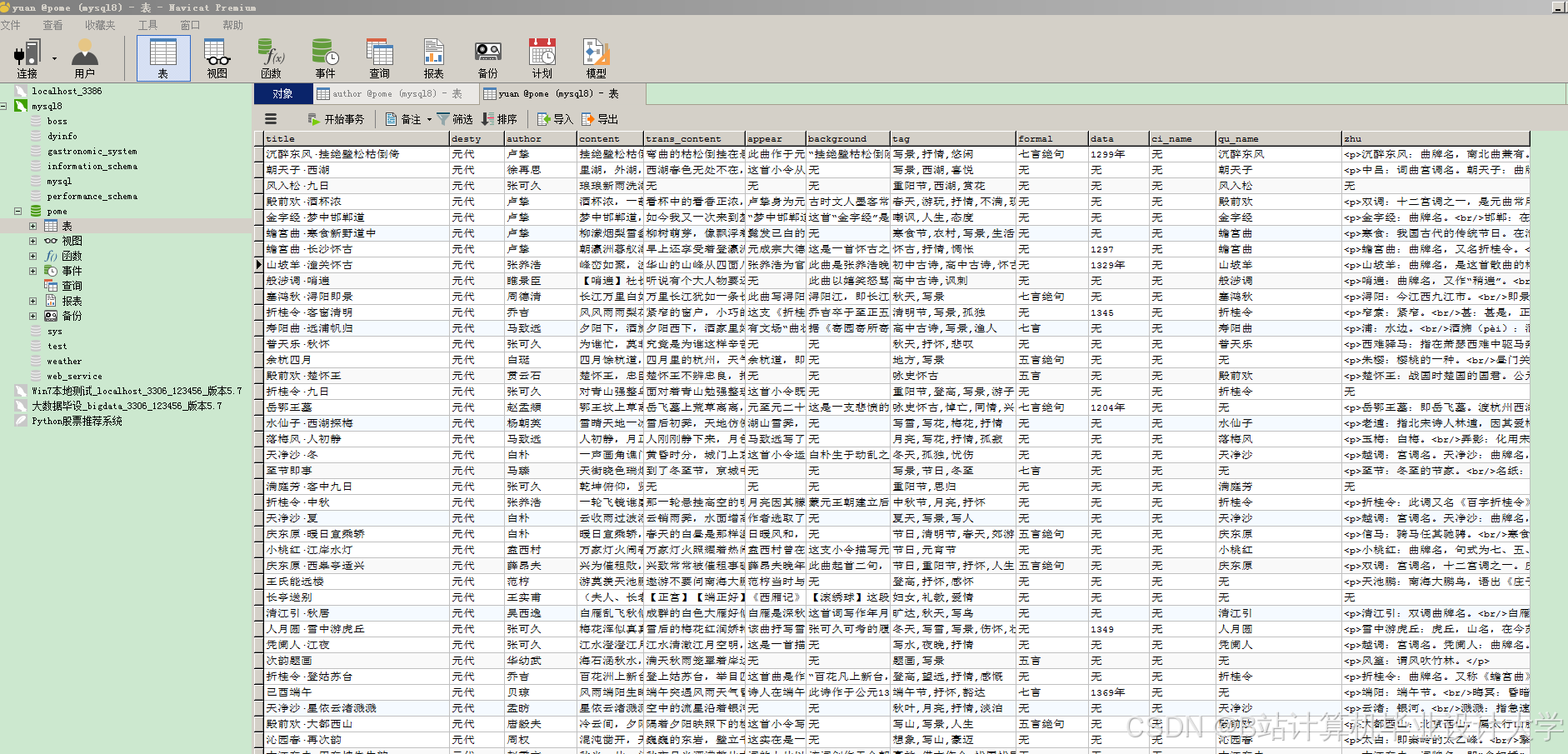
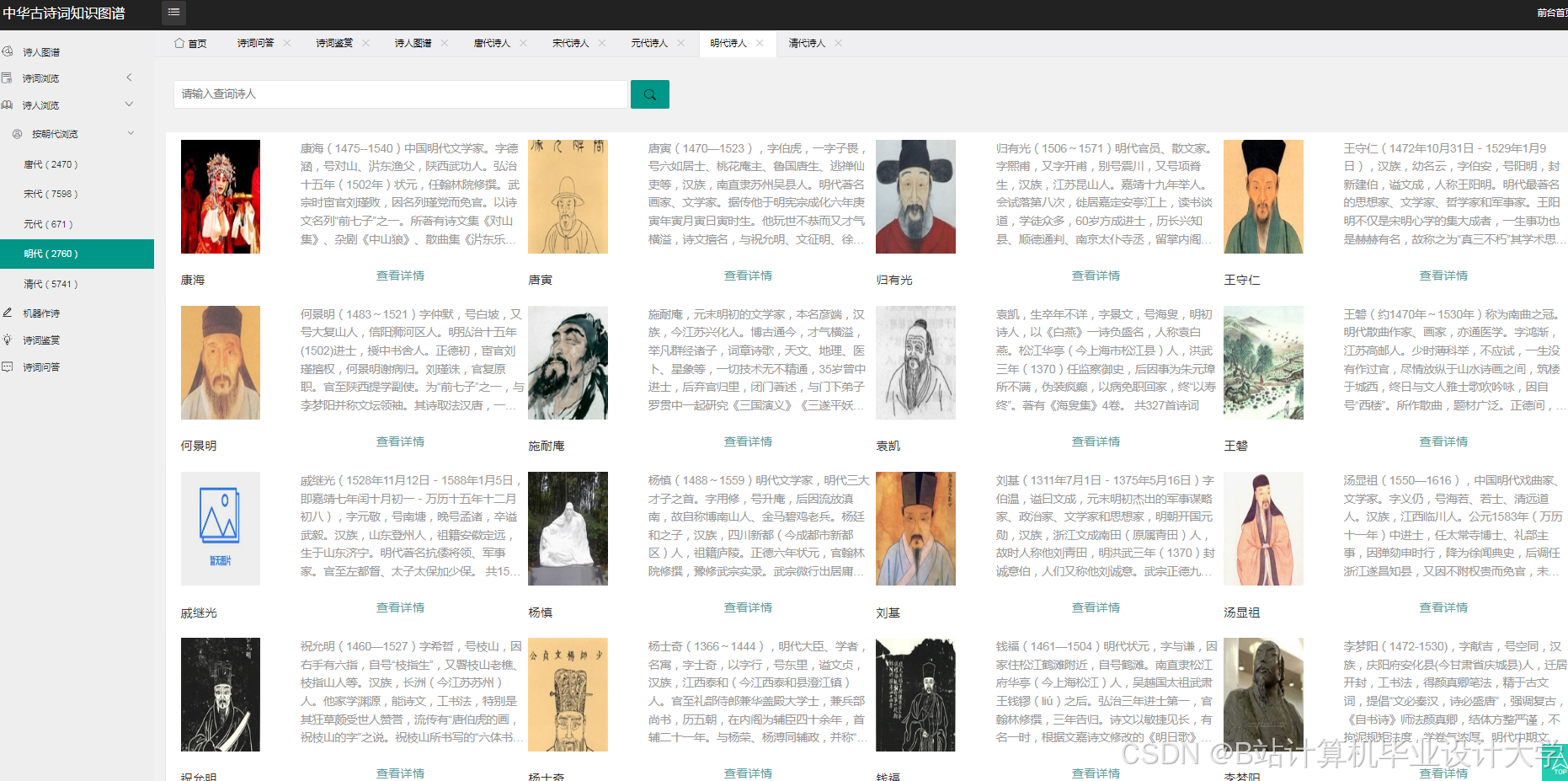
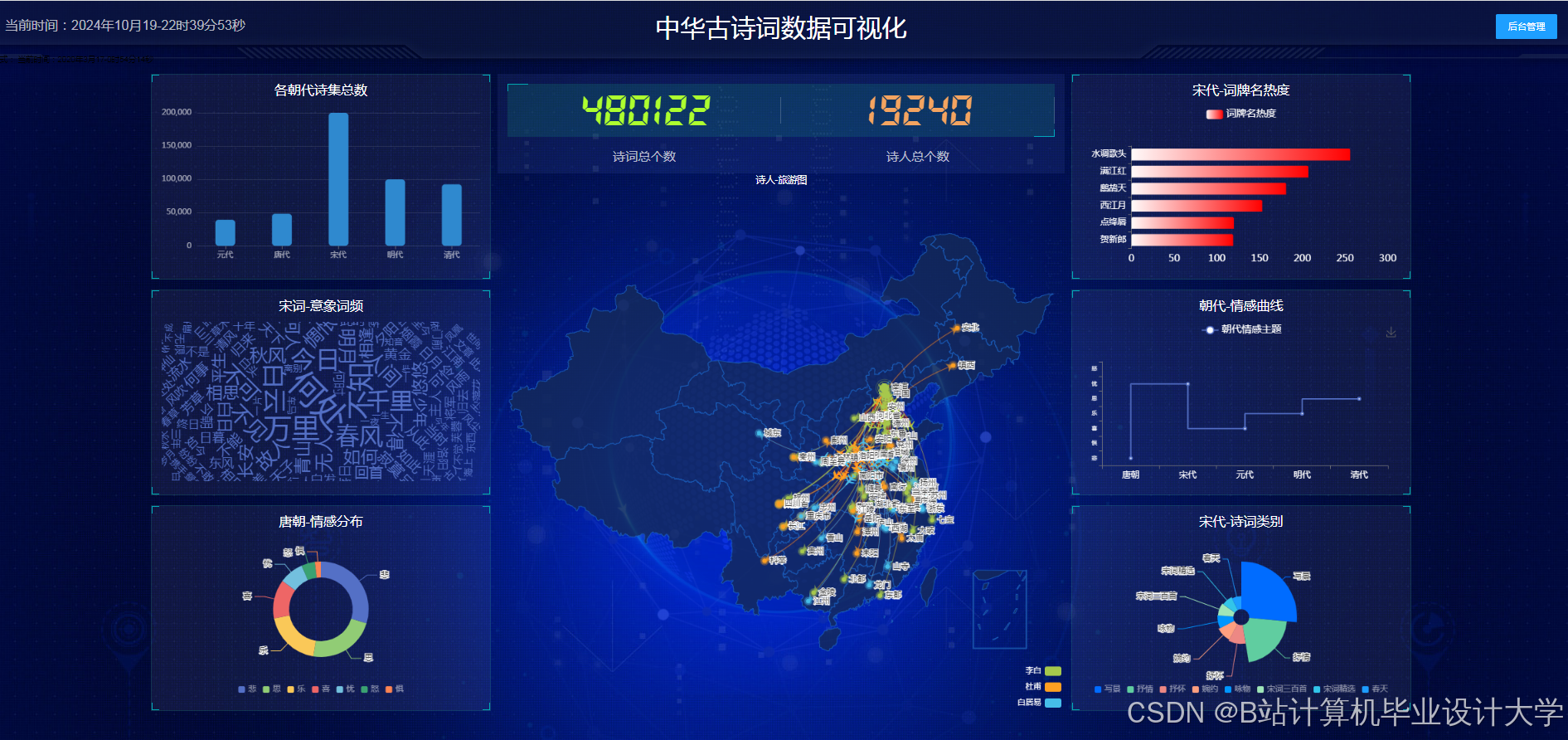
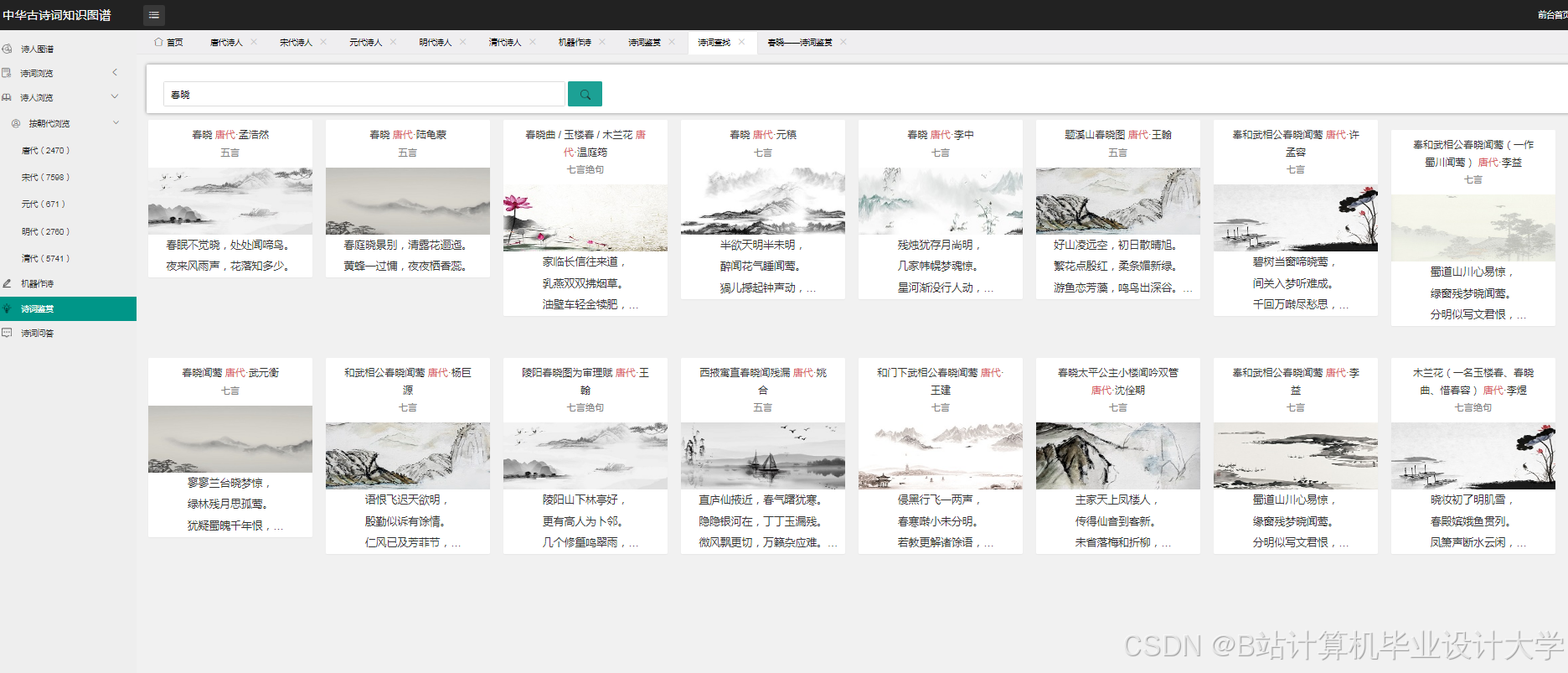
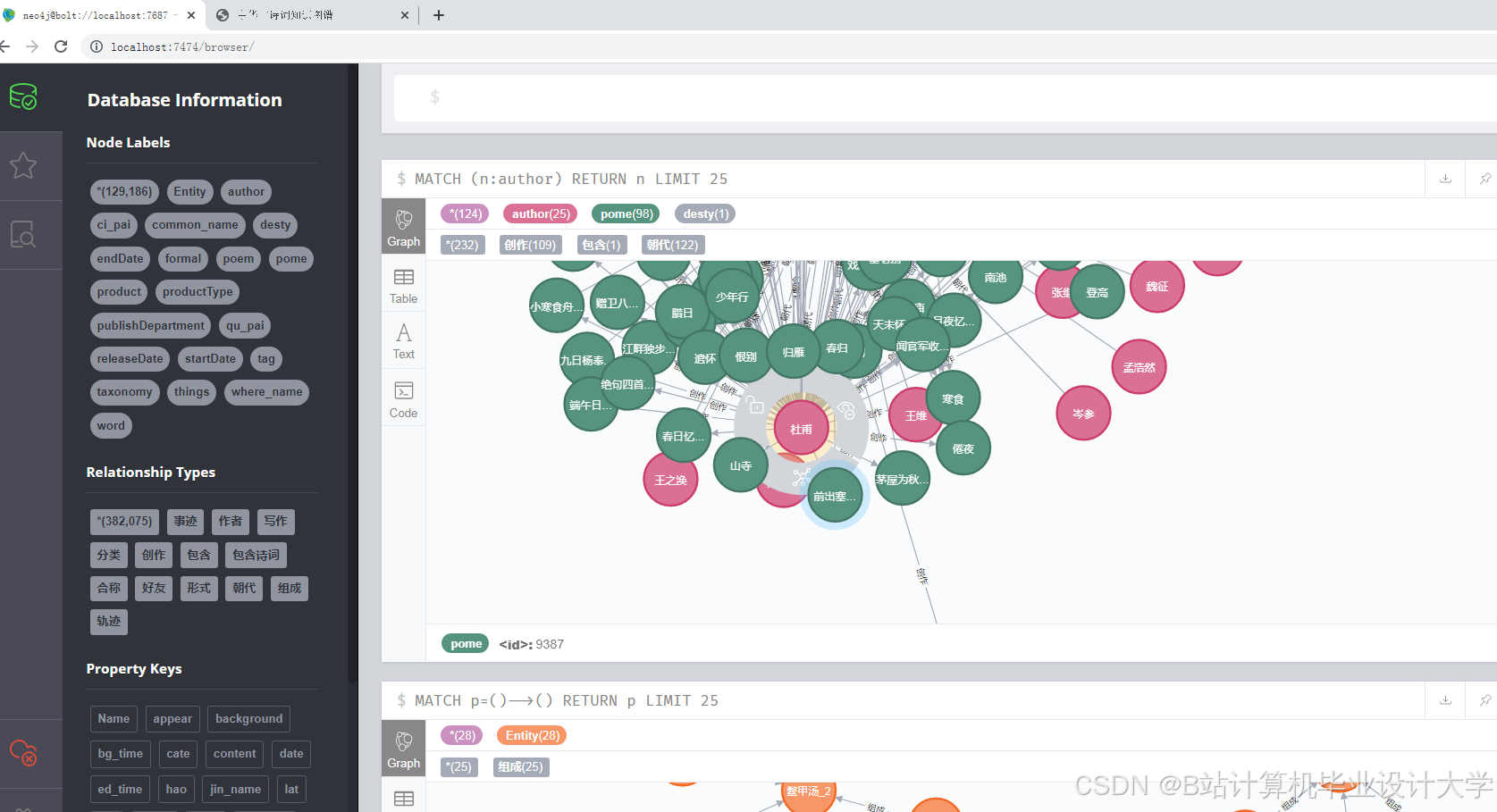
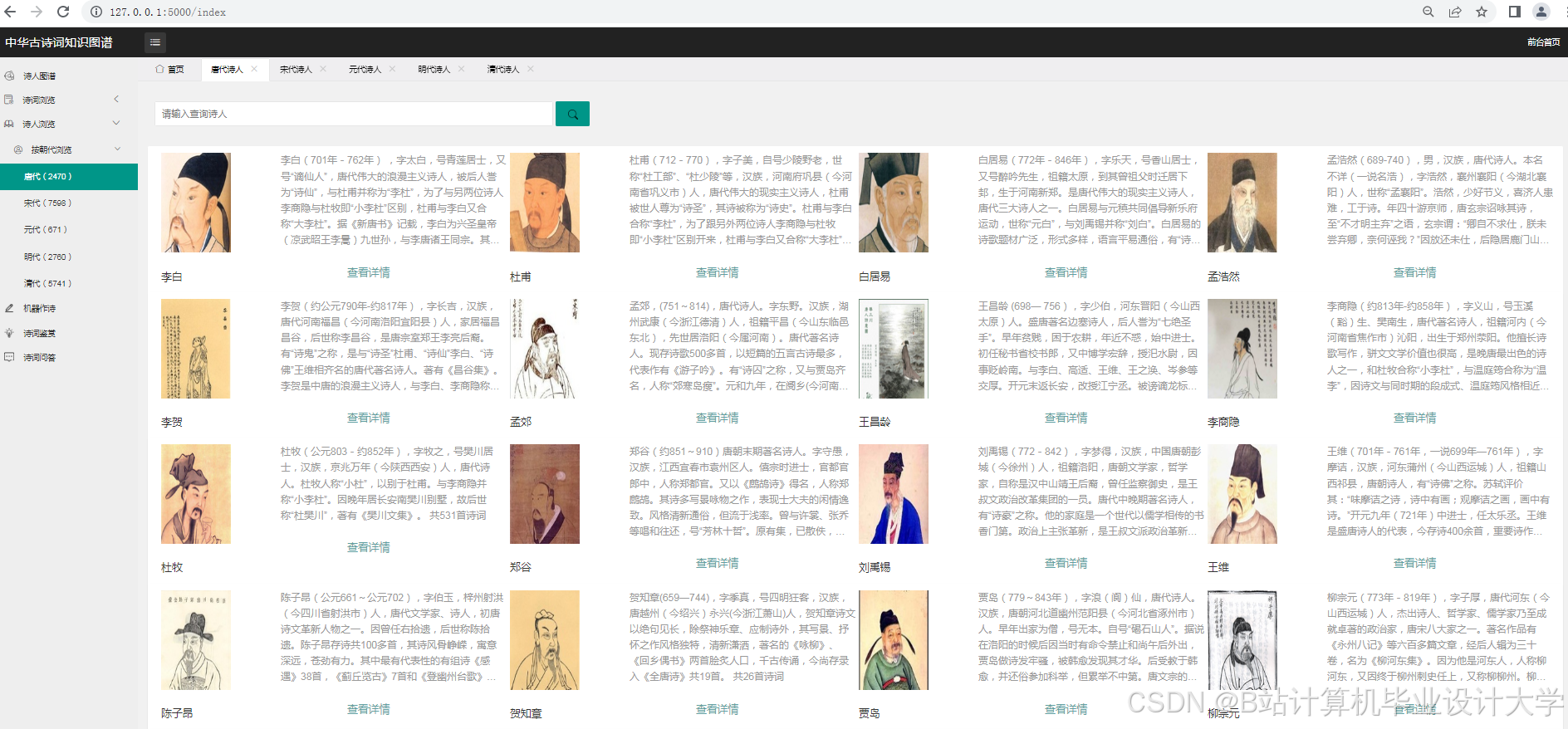
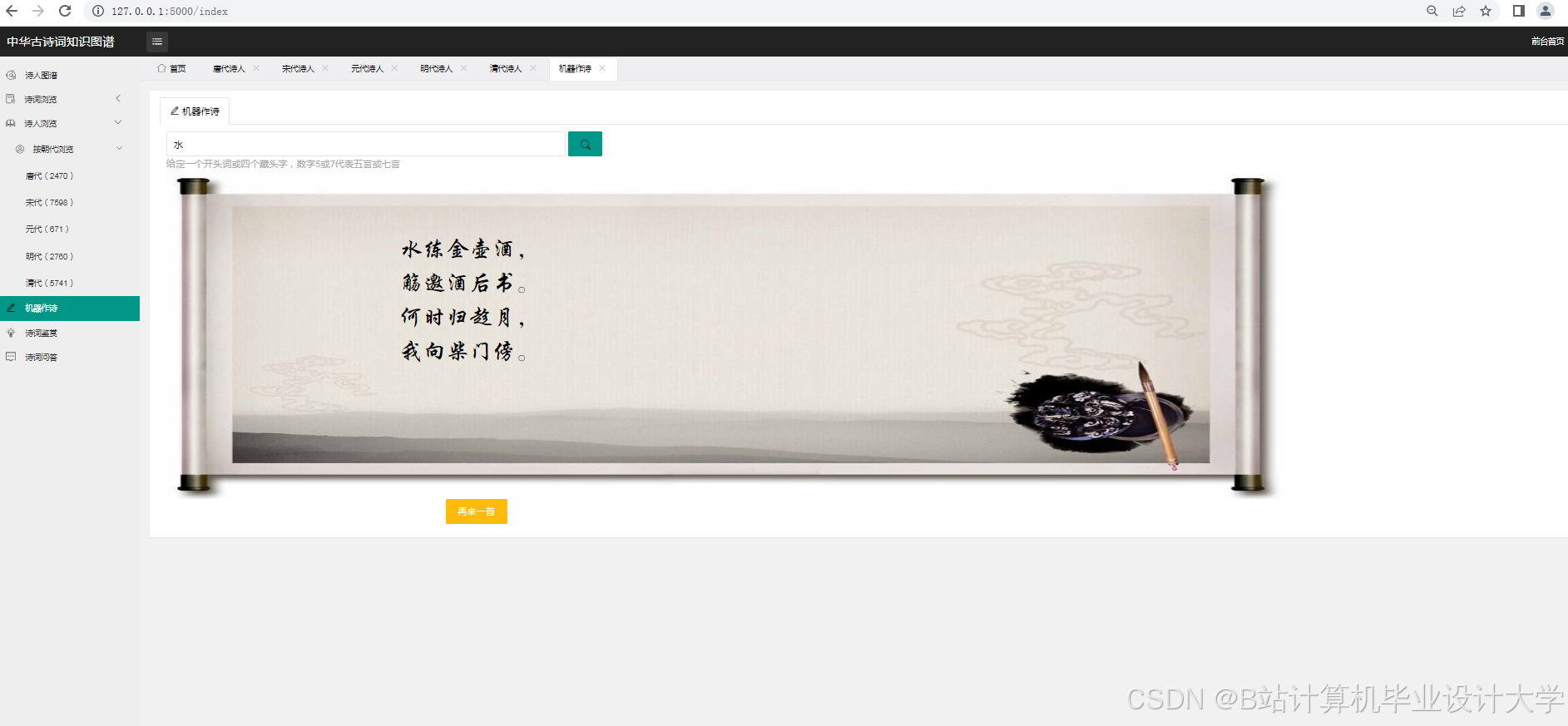
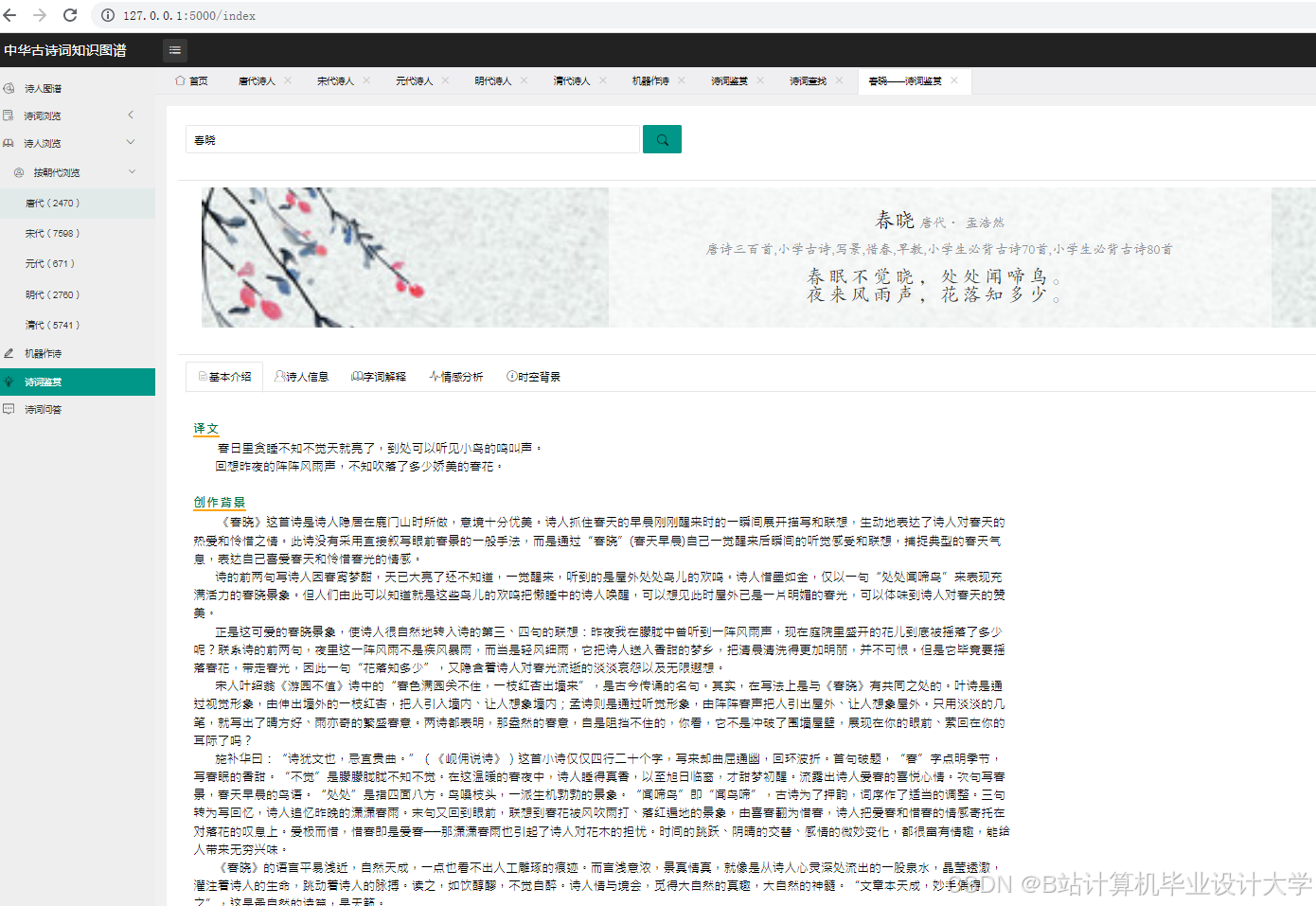
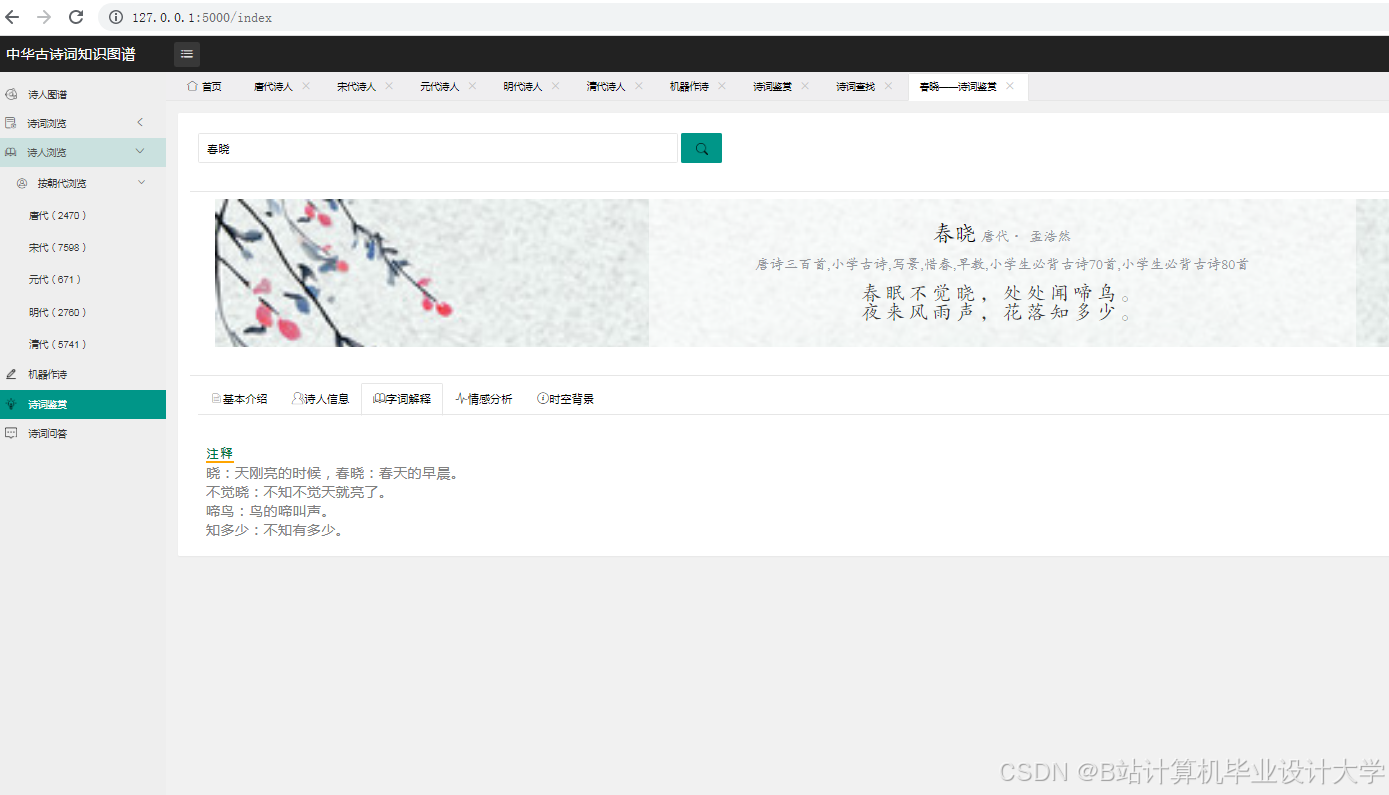
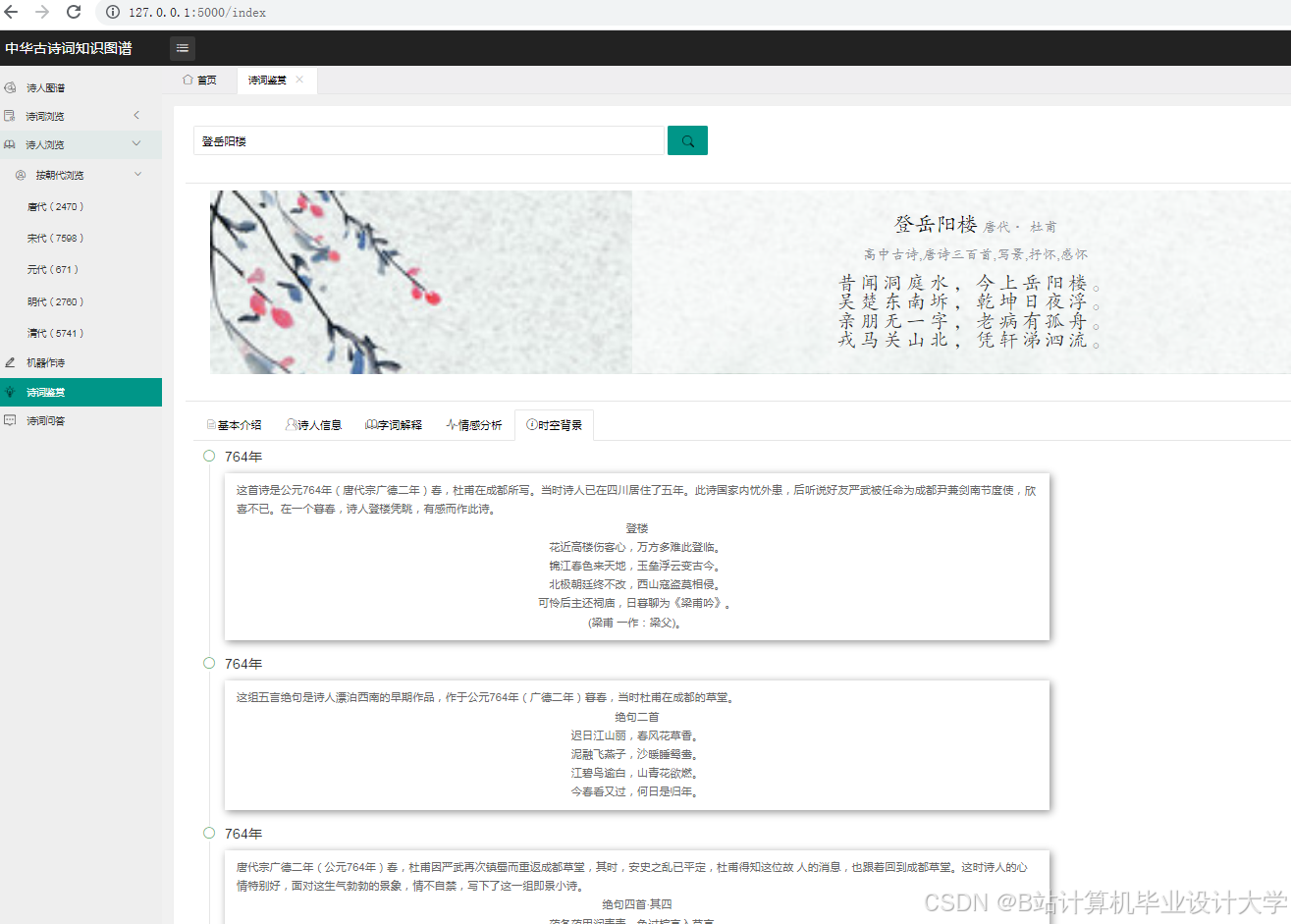
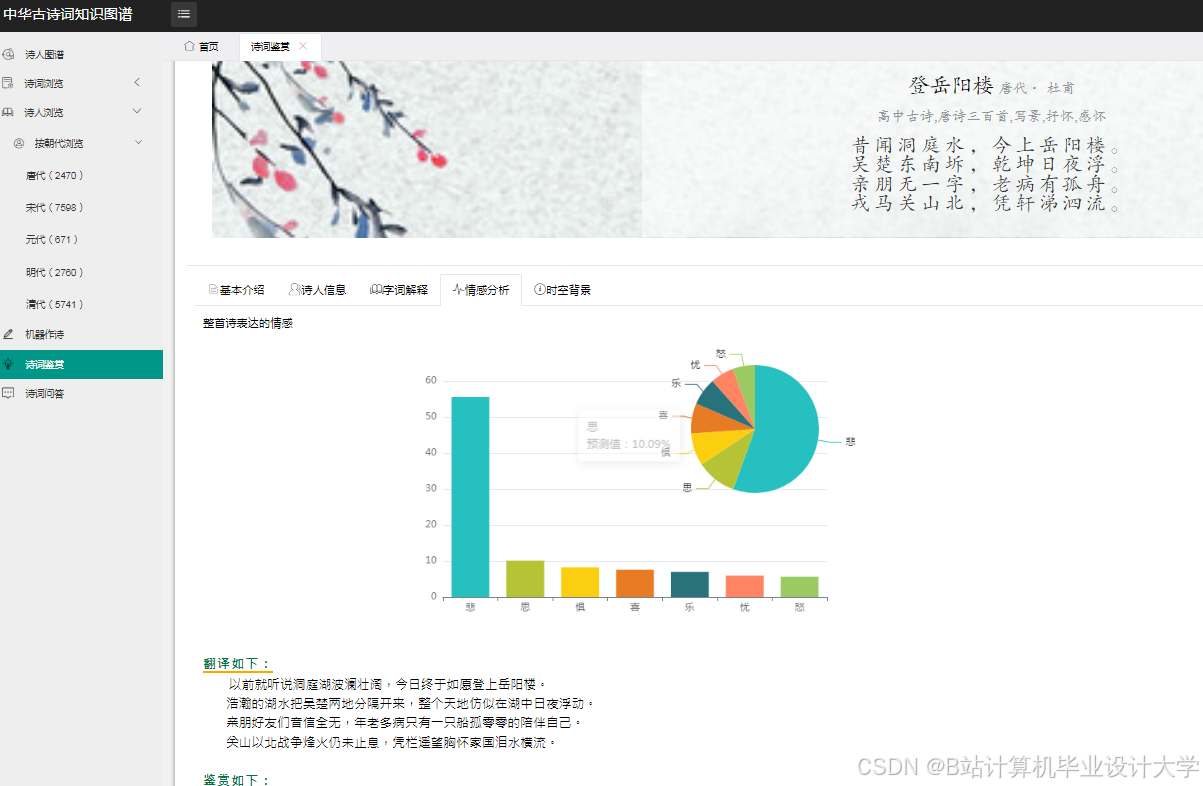
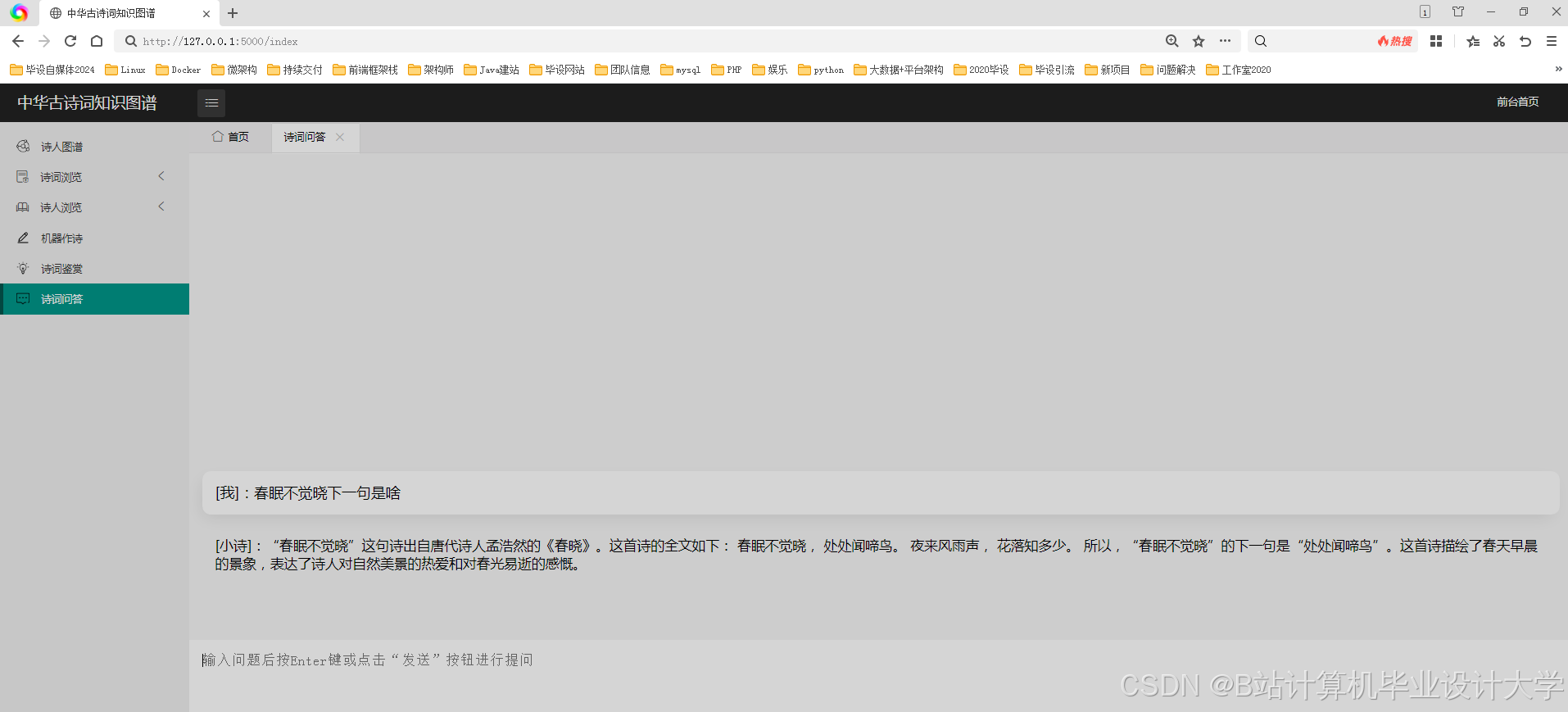
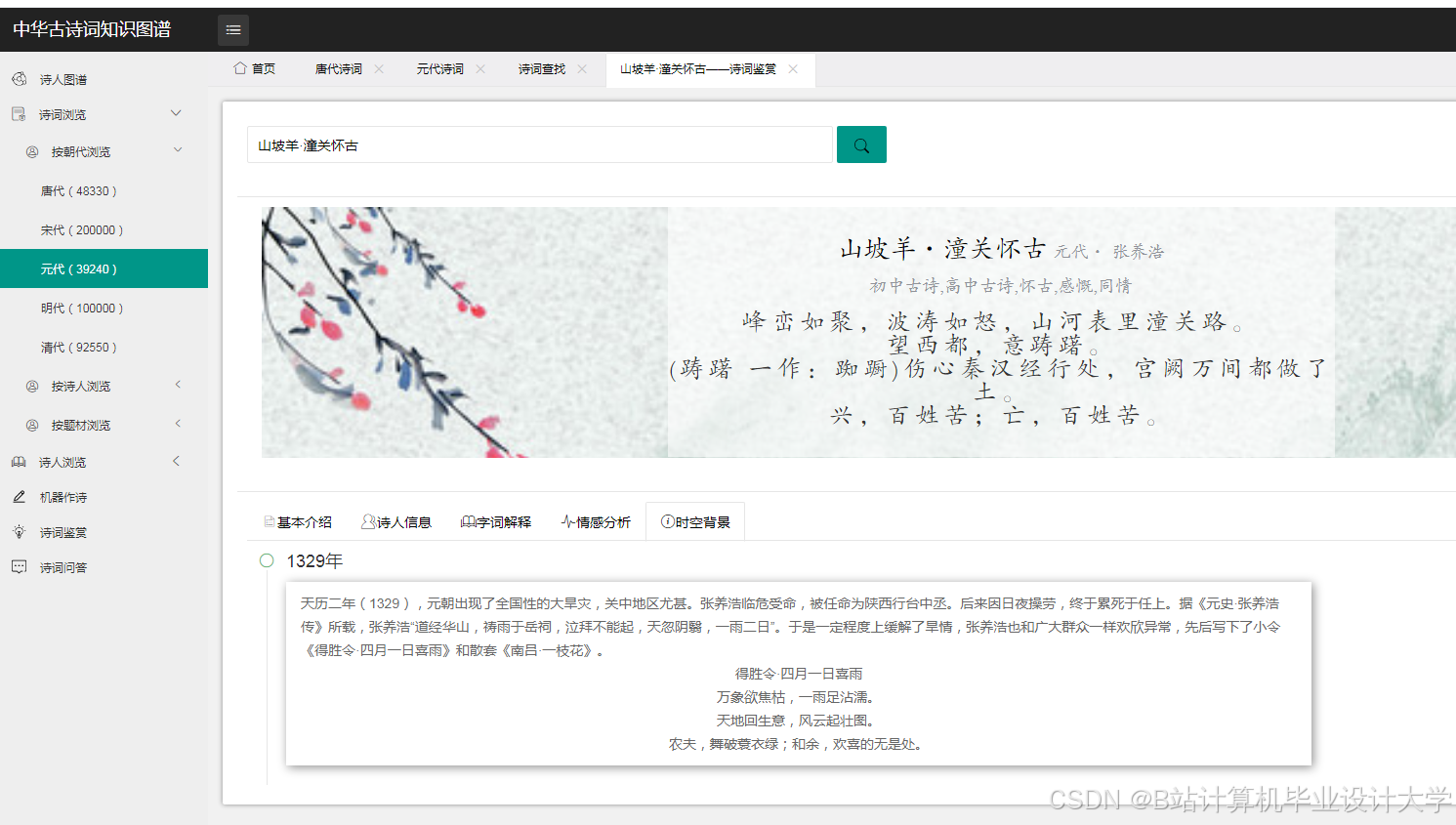
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











