




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python知识图谱中华古诗词可视化技术说明
一、引言
中华古诗词作为中华民族的文化瑰宝,承载着丰富的历史、文化与情感内涵。然而,在信息爆炸的时代,如何高效地挖掘、展示和传播古诗词的内在价值成为亟待解决的问题。Python凭借其强大的数据处理、自然语言处理和可视化能力,为构建中华古诗词知识图谱并进行可视化展示提供了有力支持。本技术说明旨在详细阐述利用Python实现中华古诗词知识图谱可视化的技术流程和方法。
二、技术架构概述
整个技术架构主要由数据采集与预处理模块、知识图谱构建模块和可视化展示模块组成。数据采集与预处理模块负责从多个渠道收集古诗词数据,并进行清洗、分词等操作,为后续的知识图谱构建提供高质量的数据基础。知识图谱构建模块通过实体识别、关系抽取等技术,将古诗词中的实体和关系以图结构的形式存储起来。可视化展示模块则利用各种可视化库,将知识图谱以直观、交互式的方式呈现给用户。
三、各模块技术实现
(一)数据采集与预处理
- 数据采集
- 网页爬取:使用Python的
requests库发送HTTP请求,获取诗词网站、古籍数据库等网页的HTML内容。例如,通过设置请求头模拟浏览器访问,避免被网站的反爬机制拦截。 - HTML解析:借助
BeautifulSoup或lxml库解析HTML文档,提取所需的古诗词数据,如诗词原文、作者信息、创作背景等。例如,利用BeautifulSoup的CSS选择器或XPath语法定位特定的HTML元素,提取其中的文本内容。 - 数据存储:将采集到的数据存储到本地文件(如CSV、JSON格式)或数据库中,以便后续处理。
- 网页爬取:使用Python的
- 数据预处理
- 数据清洗:去除HTML标签、特殊字符、重复内容等噪声数据。可以使用正则表达式(通过
re模块)进行字符串匹配和替换,例如去除<p>、</p>等标签。 - 分词处理:采用
jieba分词库对诗词文本进行分词。为了提高分词的准确性,可以添加自定义词典,将古诗词中特有的词汇(如人名、地名、典故等)加入词典中。同时,结合停用词表,去除无意义的停用词,如“的”“了”“和”等。
- 数据清洗:去除HTML标签、特殊字符、重复内容等噪声数据。可以使用正则表达式(通过
(二)知识图谱构建
- 实体识别
- 基于规则的方法:定义一系列规则模板,如“[诗人姓名] + [创作相关动词] + [诗词名称]”,通过字符串匹配的方式从文本中抽取实体。例如,对于句子“李白创作了《静夜思》”,根据规则可以识别出“李白”为诗人实体,“《静夜思》”为诗词实体。
- 基于机器学习的方法:使用标注好的训练数据,训练实体识别模型。可以选择决策树、支持向量机等传统机器学习算法,也可以利用深度学习中的循环神经网络(RNN)及其变体(如LSTM、GRU)进行实体识别。例如,使用
scikit-learn库中的决策树算法,将分词后的文本作为特征,实体标签作为目标变量,训练模型进行实体识别。
- 关系抽取
- 依存句法分析:利用依存句法分析工具(如
LTP、Stanford Parser等)获取词语之间的语法关系,进而抽取出实体关系。例如,对于句子“杜甫在成都创作了《茅屋为秋风所破歌》”,通过依存句法分析可以确定“杜甫”与“《茅屋为秋风所破歌》”之间存在“创作”关系。 - 模板匹配:根据古诗词的常见表达方式,定义关系抽取模板。例如,“[诗人]于[时间]在[地点]创作了[诗词]”可以作为一个模板,用于抽取诗人、时间、地点和诗词之间的关系。
- 依存句法分析:利用依存句法分析工具(如
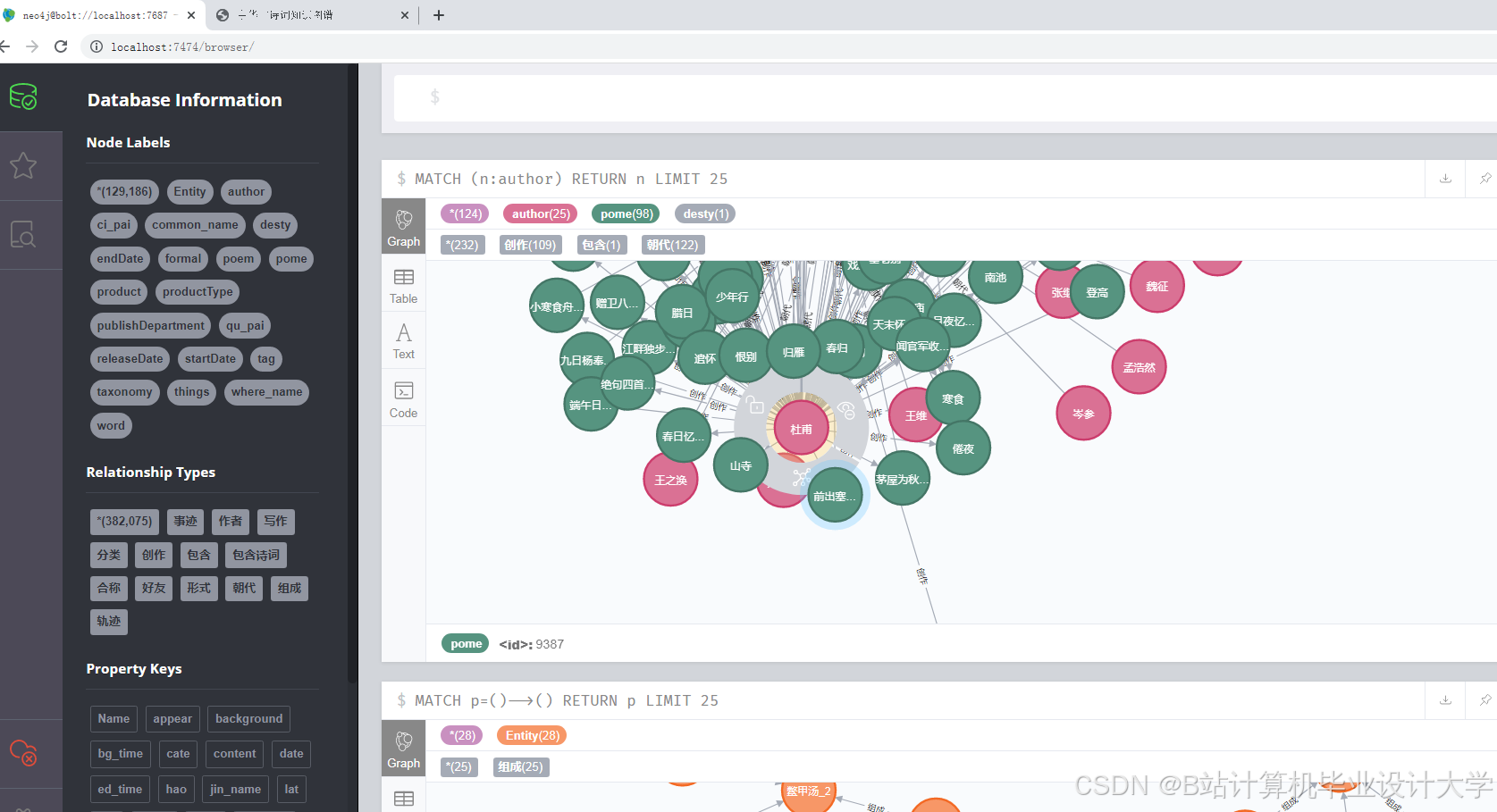
- 图谱存储
- 选择图数据库:Neo4j是一种常用的图数据库,具有高效的查询性能和良好的可扩展性,适合存储知识图谱数据。
- 数据导入:将识别出的实体作为节点,抽取的关系作为边,定义节点和边的属性(如诗人的朝代、生平事迹,诗作的创作时间、风格流派等),然后将数据导入Neo4j图数据库中。可以使用Neo4j的Cypher语言进行数据导入和查询操作。
(三)可视化展示
- 可视化库选择
- D3.js:D3.js是一个基于数据驱动文档的JavaScript库,能够创建高度定制化的可视化图表。通过Python的
pyecharts库(基于ECharts的Python接口)或plotly库与D3.js结合,实现知识图谱的可视化展示。 - ECharts:ECharts提供了丰富的可视化图表类型和交互功能,支持将知识图谱与柱状图、折线图等结合展示。可以使用
pyecharts库直接调用ECharts的功能,快速生成可视化图表。
- D3.js:D3.js是一个基于数据驱动文档的JavaScript库,能够创建高度定制化的可视化图表。通过Python的
- 可视化实现
- 节点和边的定义:在可视化库中定义知识图谱的节点和边,设置节点的大小、颜色、形状等属性,以及边的粗细、颜色等属性,以区分不同类型的实体和关系。
- 布局算法选择:选择合适的布局算法(如力导向布局、圆形布局、层次布局等)来展示知识图谱。力导向布局可以使节点之间的连接更加自然,便于用户观察实体之间的关系。
- 交互功能实现:为用户提供交互功能,如鼠标悬停查看节点和边的详细信息、点击节点展开相关子图等。通过JavaScript代码与可视化库进行交互,实现这些功能。
四、技术优势
- 高效的数据处理能力:Python的丰富库和工具能够快速、准确地完成数据采集、预处理和知识图谱构建等任务,大大提高了工作效率。
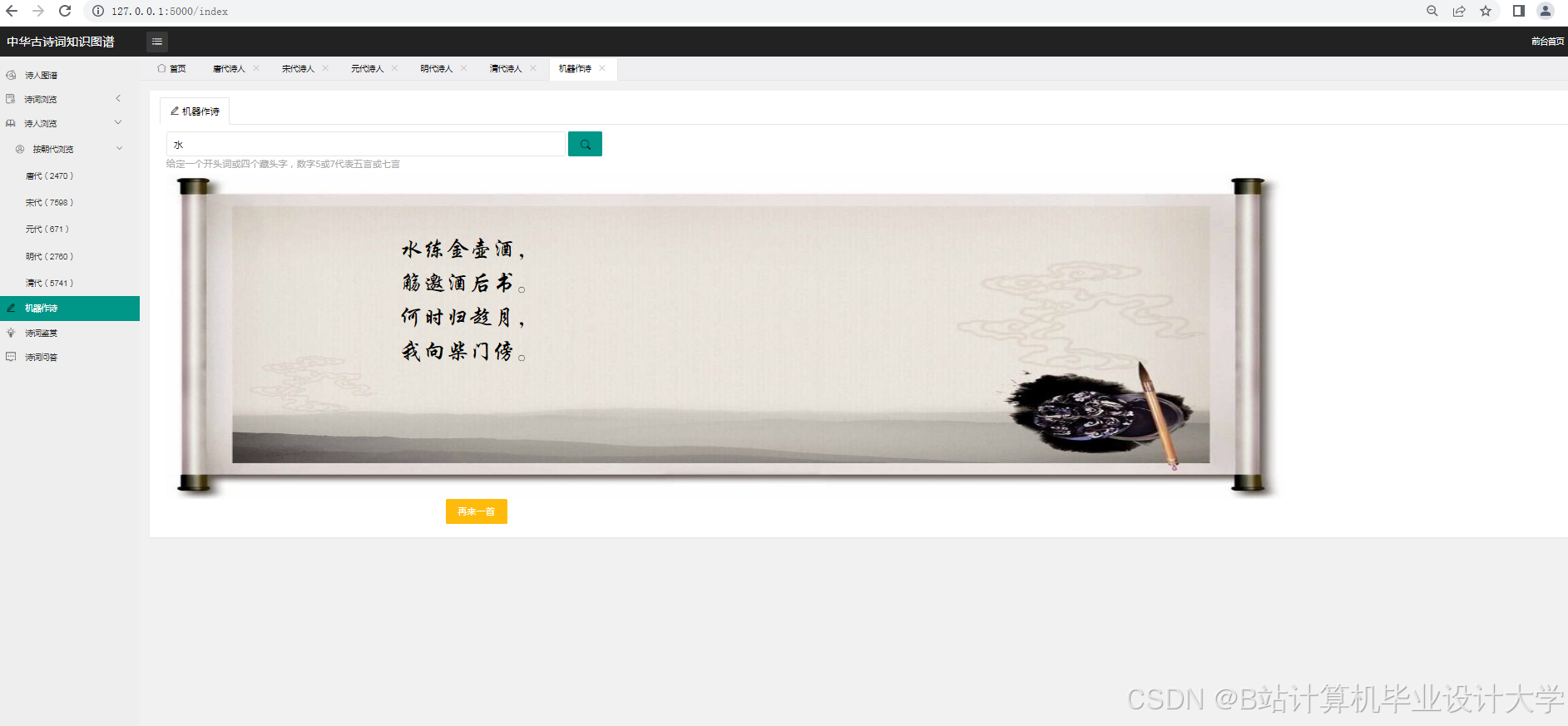
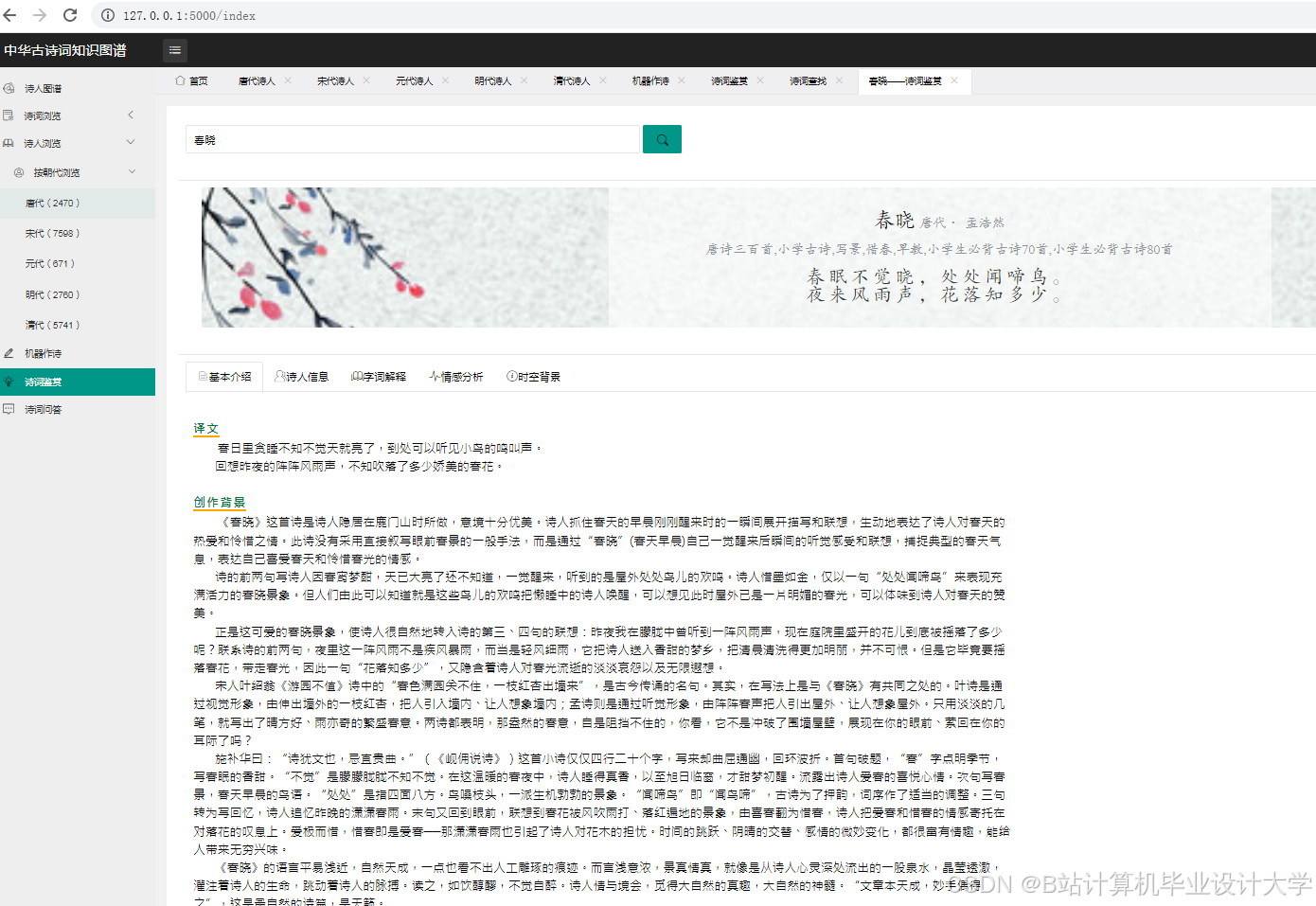
- 直观的可视化展示:通过可视化技术,将复杂的古诗词知识图谱以直观的图形方式呈现出来,降低了用户理解古诗词关系的难度,增强了用户体验。
- 灵活的交互功能:用户可以通过交互功能自由探索知识图谱,深入了解古诗词的内涵和关联,满足不同用户的需求。
五、应用场景与价值
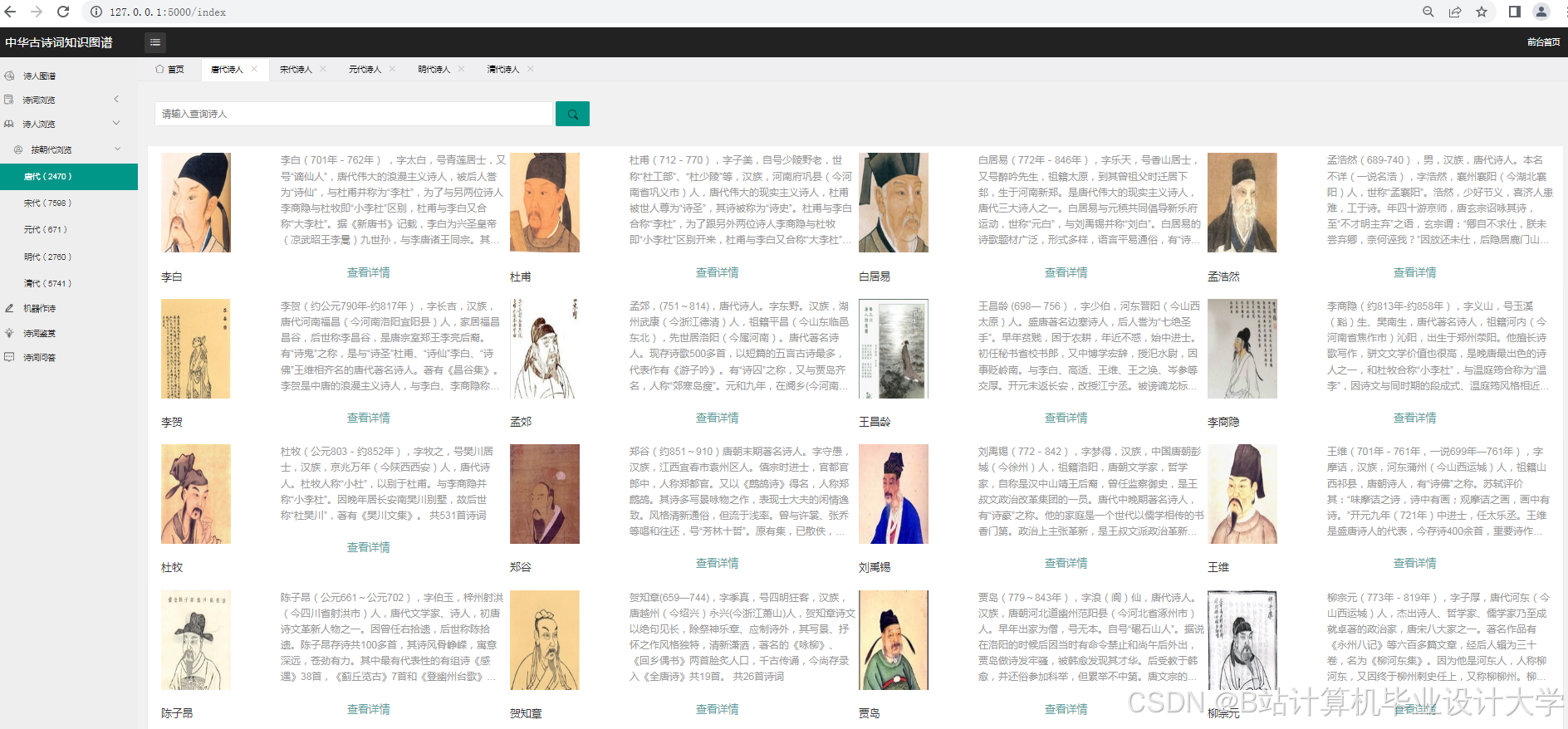
- 文化传承与教育:在教育领域,可作为语文教学资源,辅助教师讲解古诗词。学生可以通过可视化界面直观地了解诗人、诗作及其关系,提高学习兴趣和效果。同时,有助于传承和弘扬中华优秀传统文化。
- 学术研究:为古诗词研究提供新的视角和方法,帮助学者更系统地分析古诗词中的知识关联与情感表达,推动相关学术研究的深入发展。
- 文化旅游与数字娱乐:在文化旅游方面,可开发基于古诗词知识图谱的旅游导览系统,为游客提供更加丰富的文化体验。在数字娱乐方面,可开发古诗词主题的游戏、动画等产品,让更多人了解和喜爱古诗词。
六、技术挑战与解决方案
- 数据质量问题
- 挑战:古诗词文本中存在大量的生僻字、古汉语词汇和语法结构,给数据采集和预处理带来困难。
- 解决方案:建立专门的古汉语词典和停用词表,优化分词算法,提高数据预处理的准确性。同时,对采集到的数据进行人工审核和修正,确保数据质量。
- 模型泛化能力不足
- 挑战:在实体识别、关系抽取等任务中,模型的泛化能力有待提高,对一些复杂的古诗词内容处理效果不佳。
- 解决方案:增加训练数据的多样性和规模,采用迁移学习、集成学习等技术提高模型的泛化能力。同时,结合人工标注和专家知识,对模型进行优化和调整。
- 跨学科融合困难
- 挑战:古诗词研究涉及文学、历史等多个学科,Python技术与这些学科的融合存在一定难度。
- 解决方案:加强与文学、历史专家的合作,建立跨学科的研究团队。在模型训练和知识图谱构建过程中,充分听取专家意见,确保知识的准确性和完整性。
七、结论
Python知识图谱中华古诗词可视化技术通过数据采集与预处理、知识图谱构建和可视化展示等环节,实现了古诗词知识的直观展示和交互探索。该技术具有高效、直观、灵活等优势,在文化传承、学术研究和数字娱乐等领域具有重要的应用价值。尽管面临一些技术挑战,但通过不断优化和改进,有望推动中华古诗词文化的数字化传承与创新。
运行截图
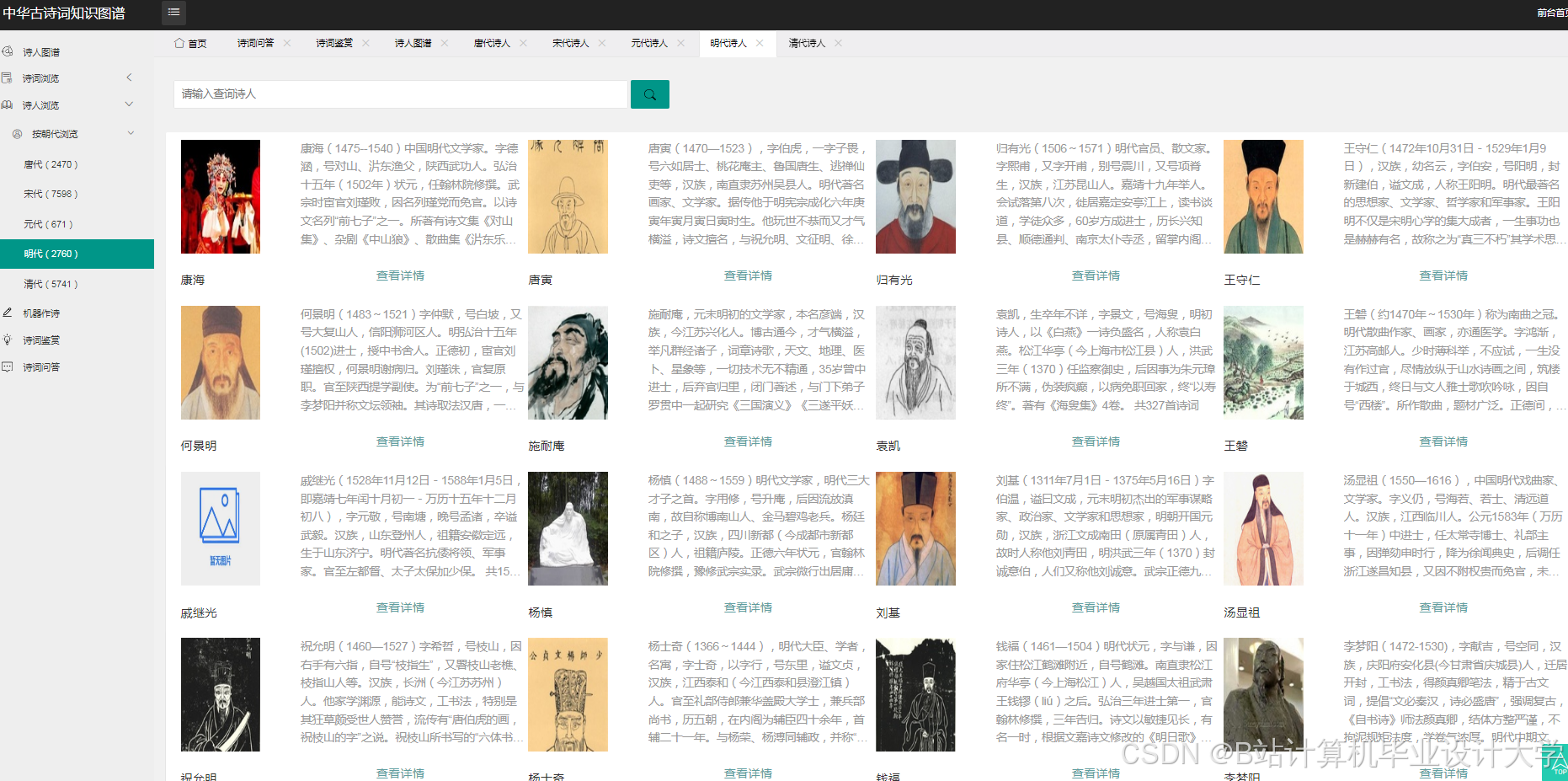
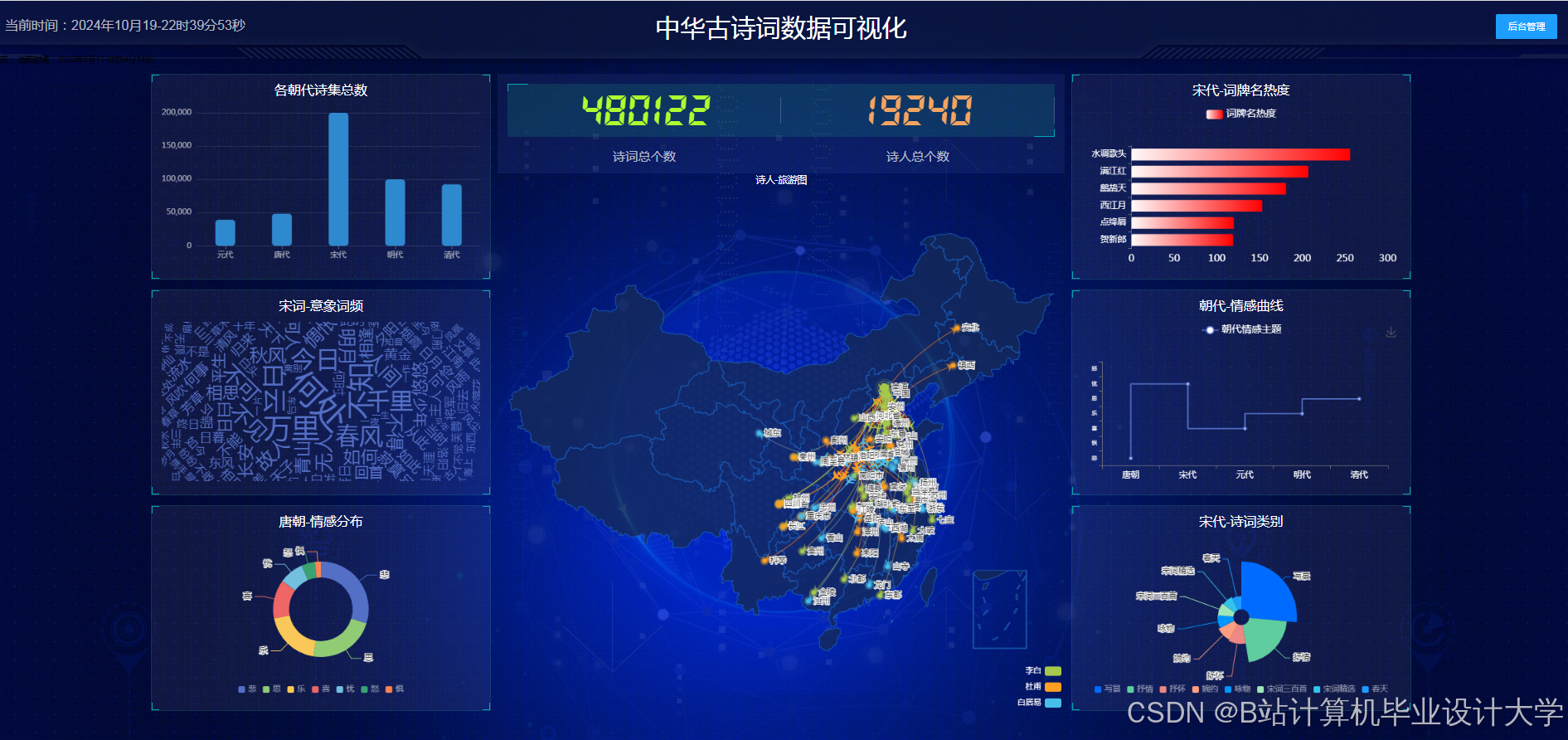
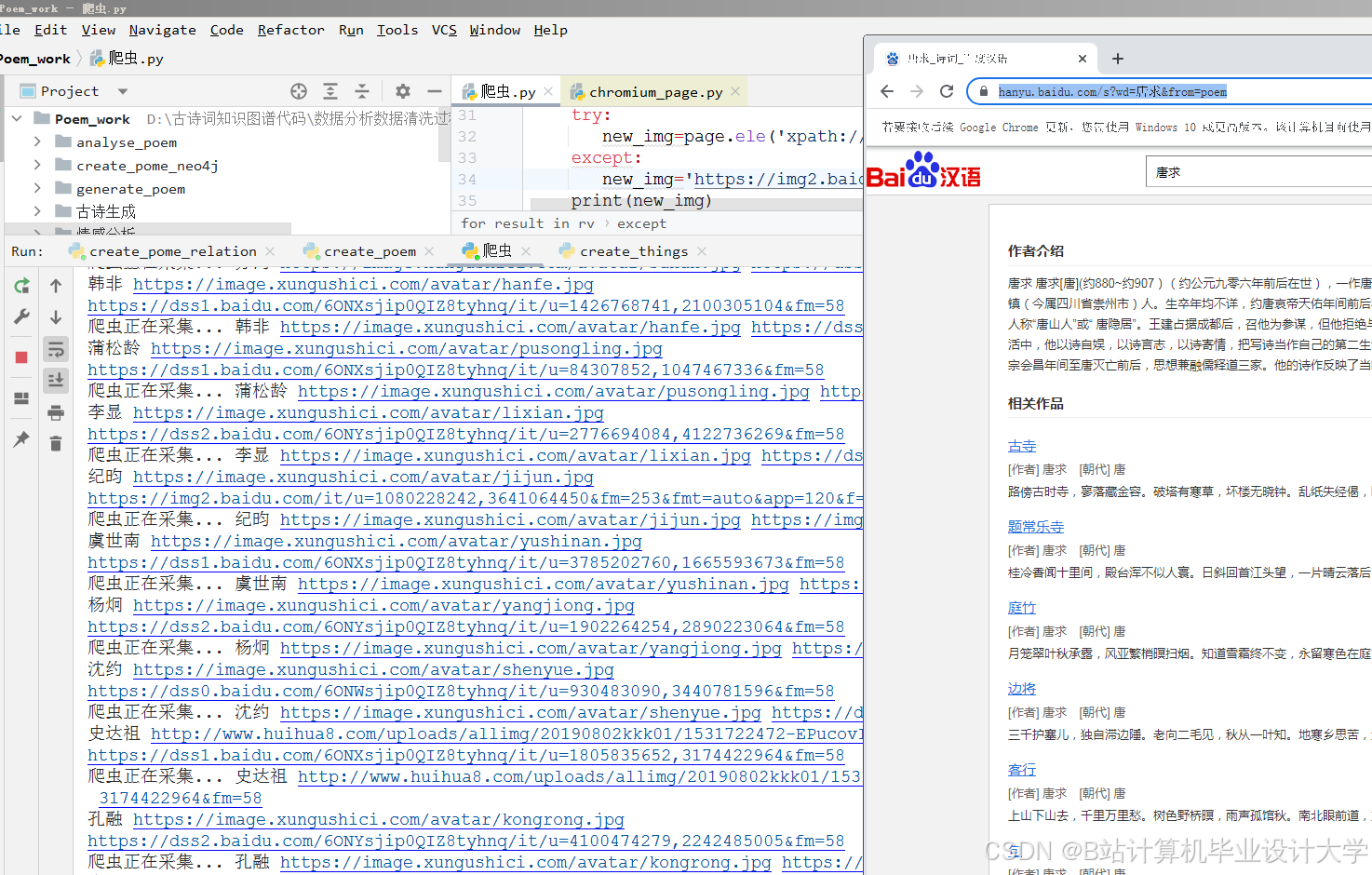
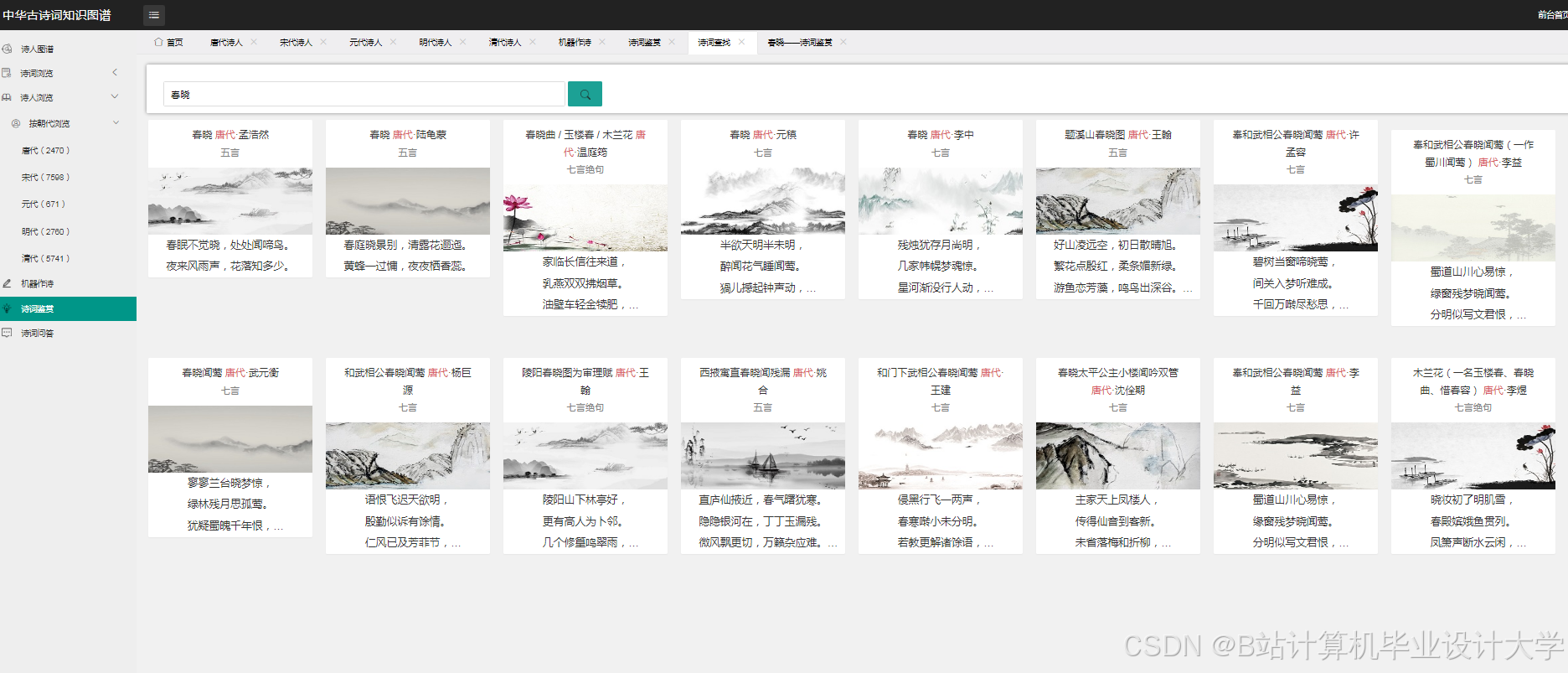
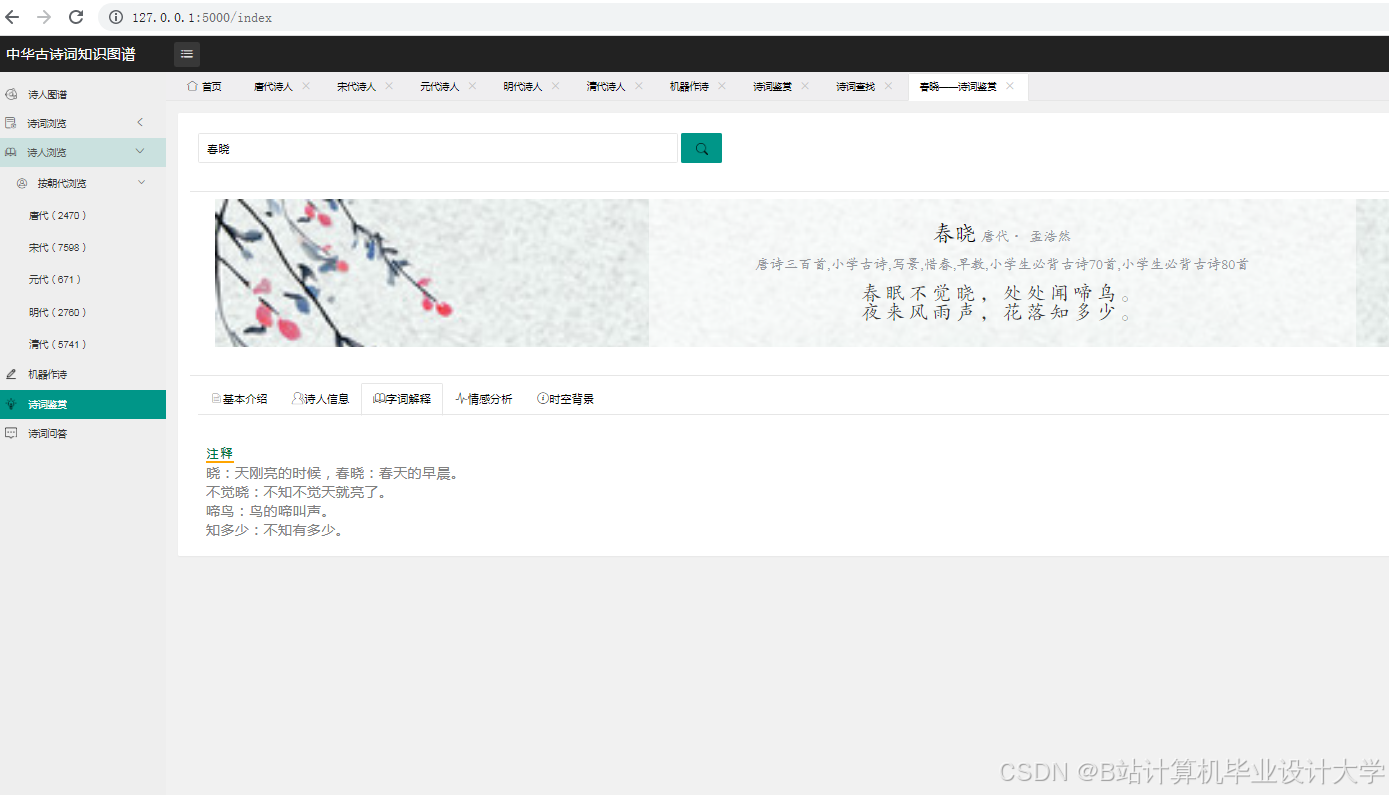
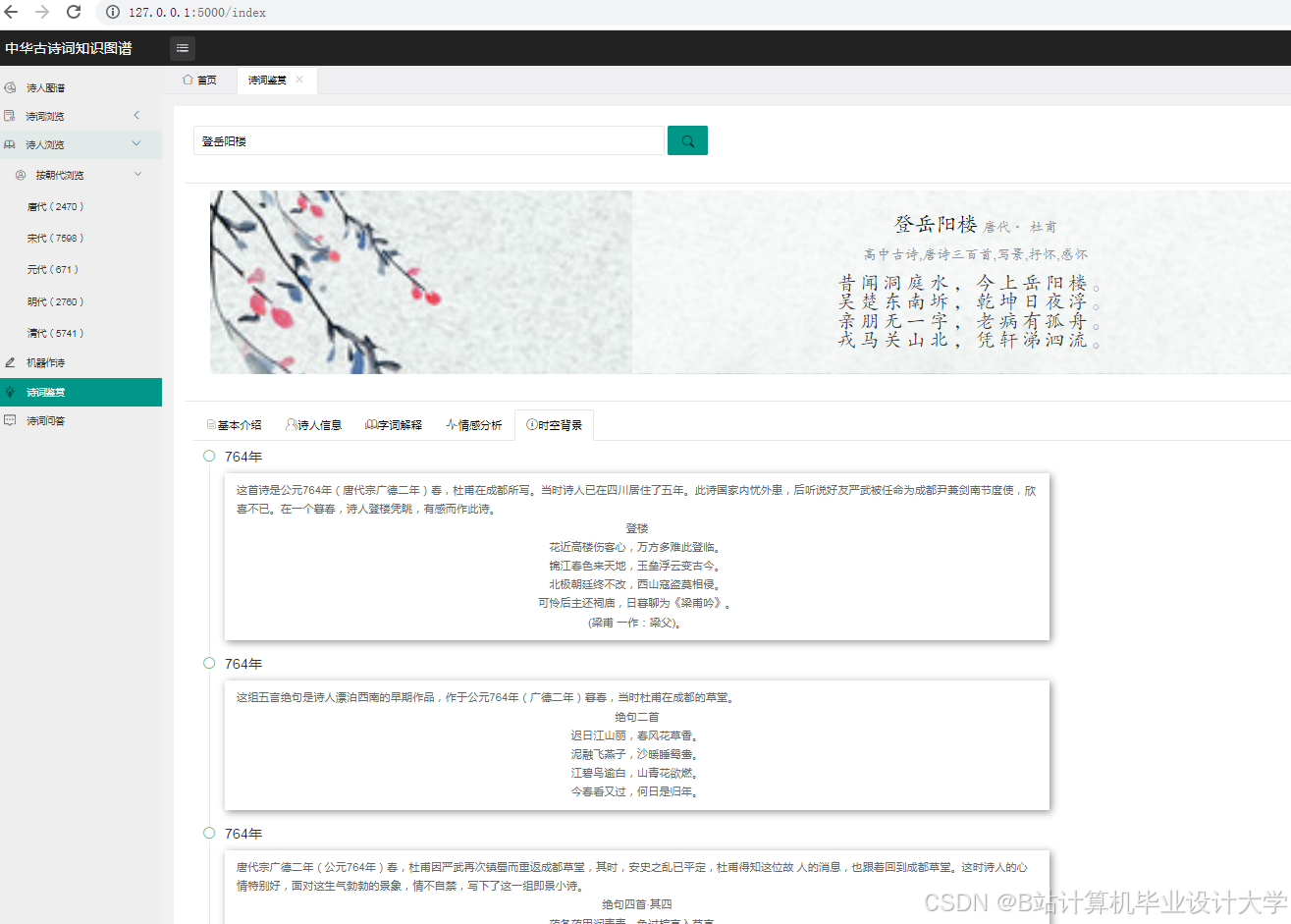
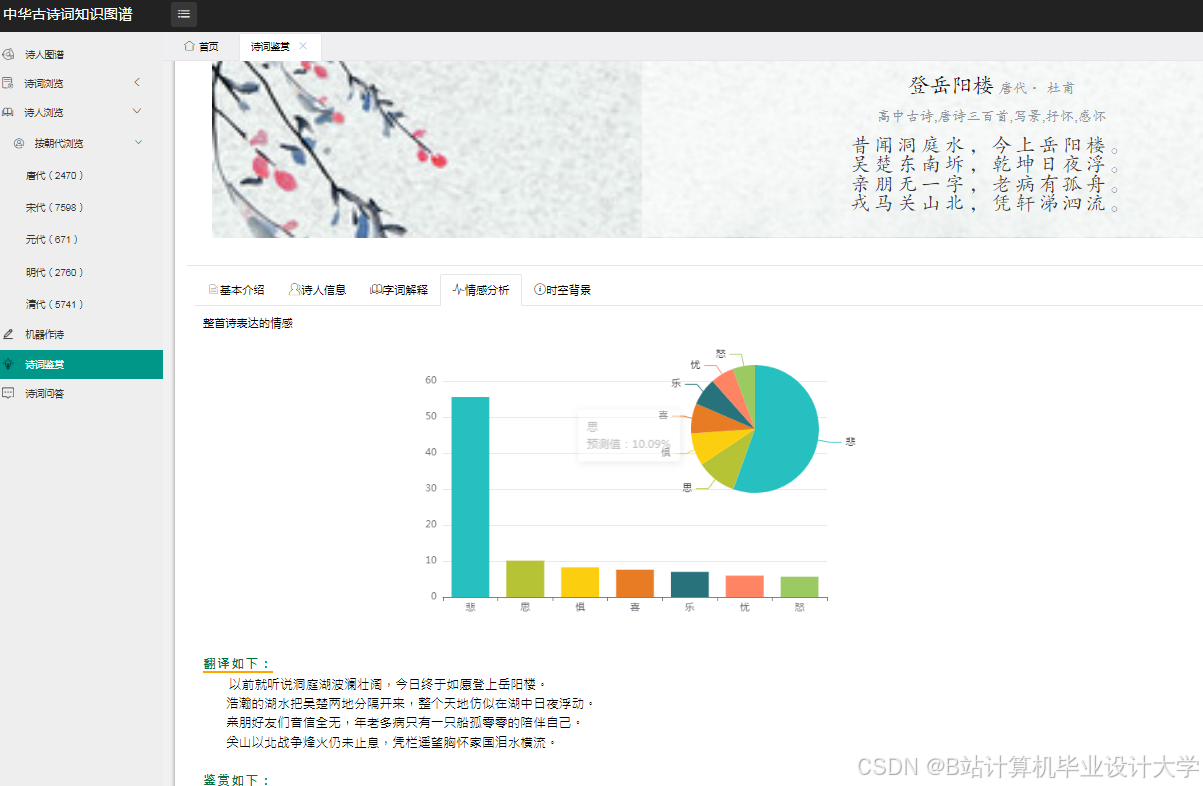
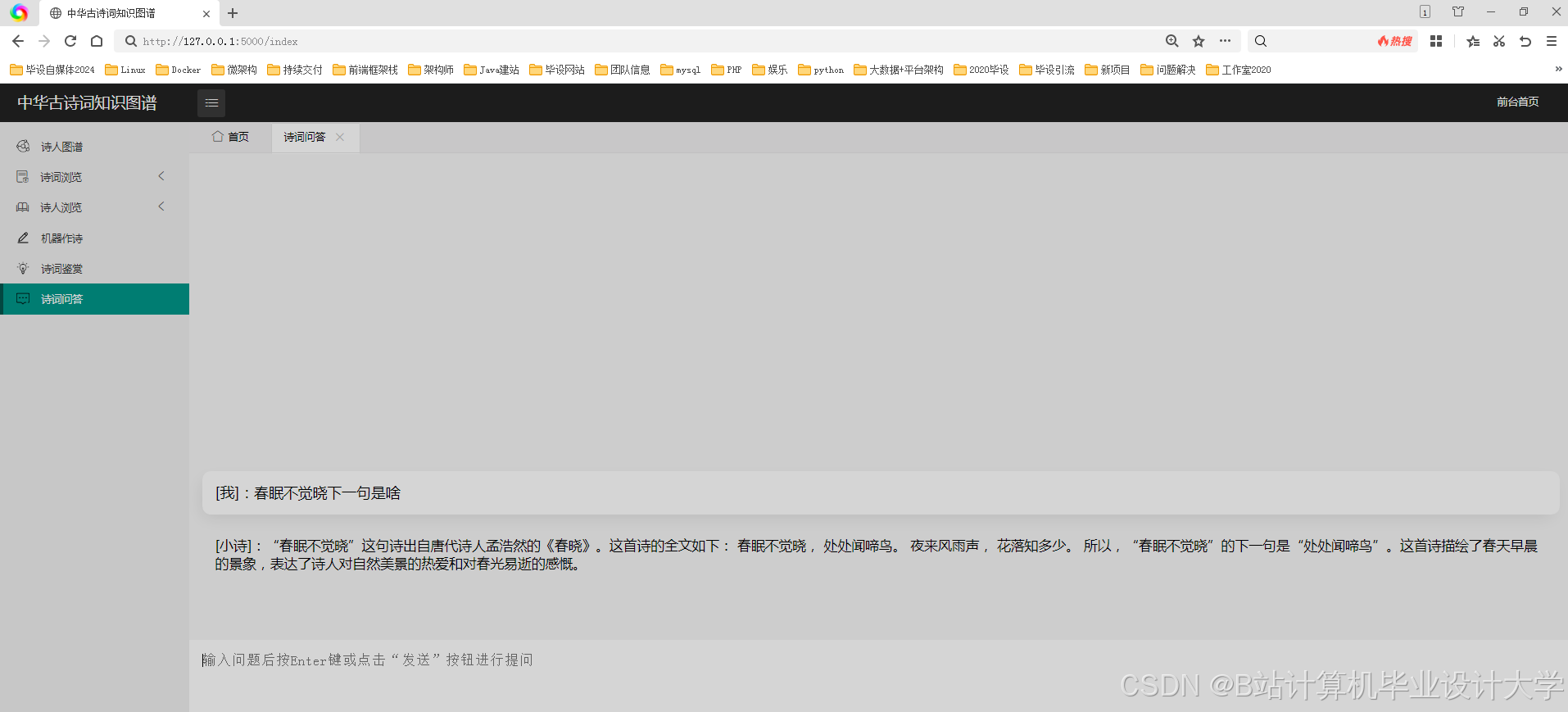
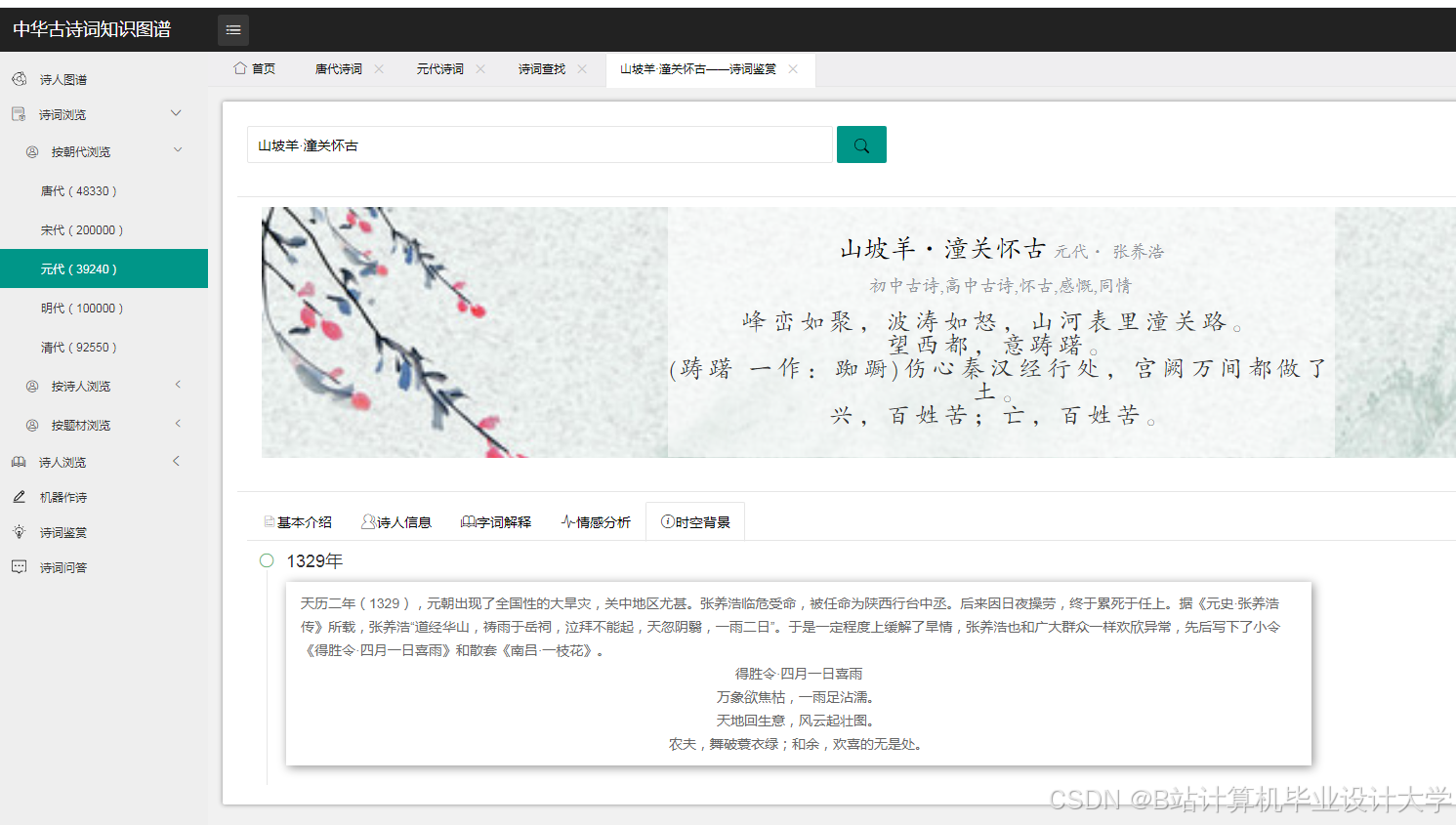
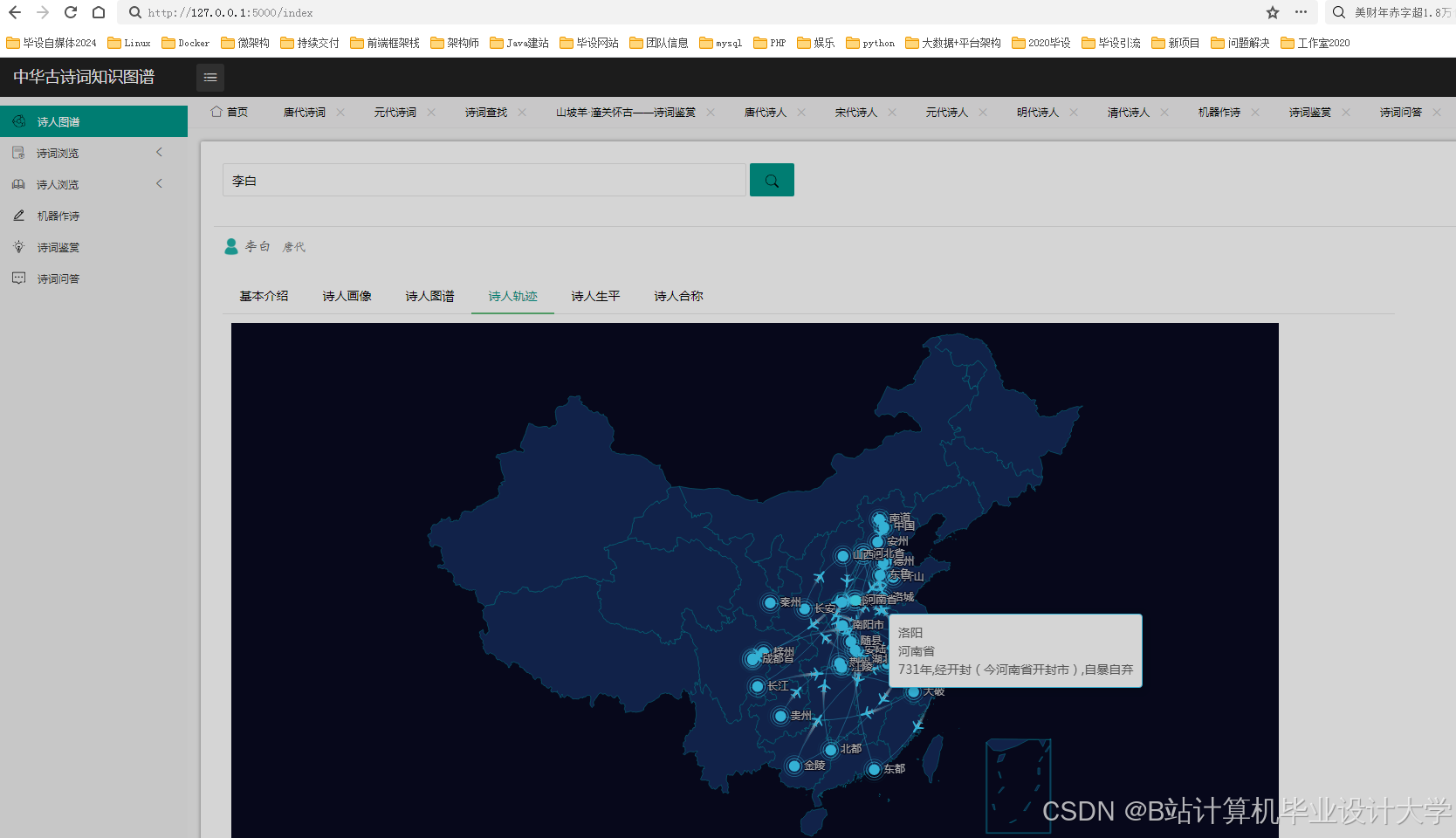
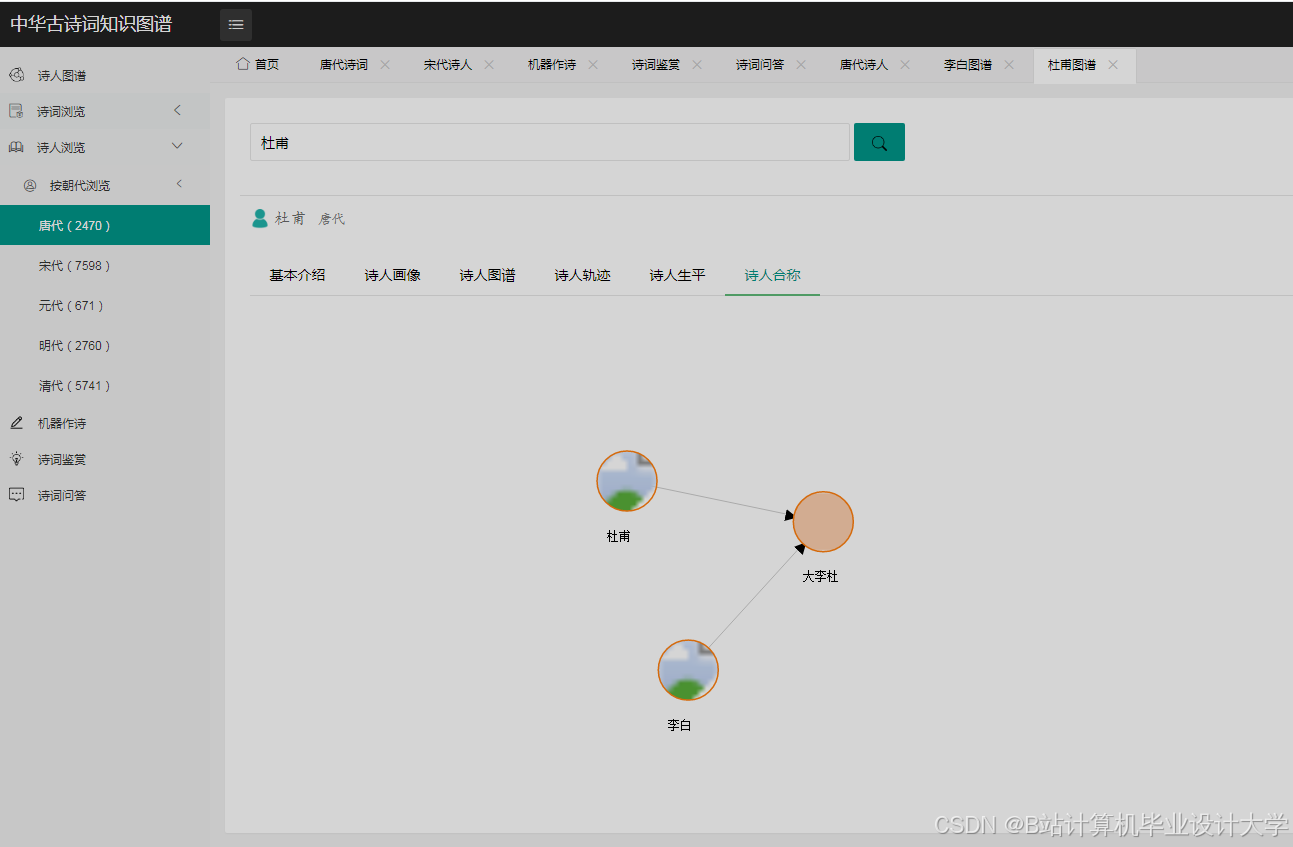
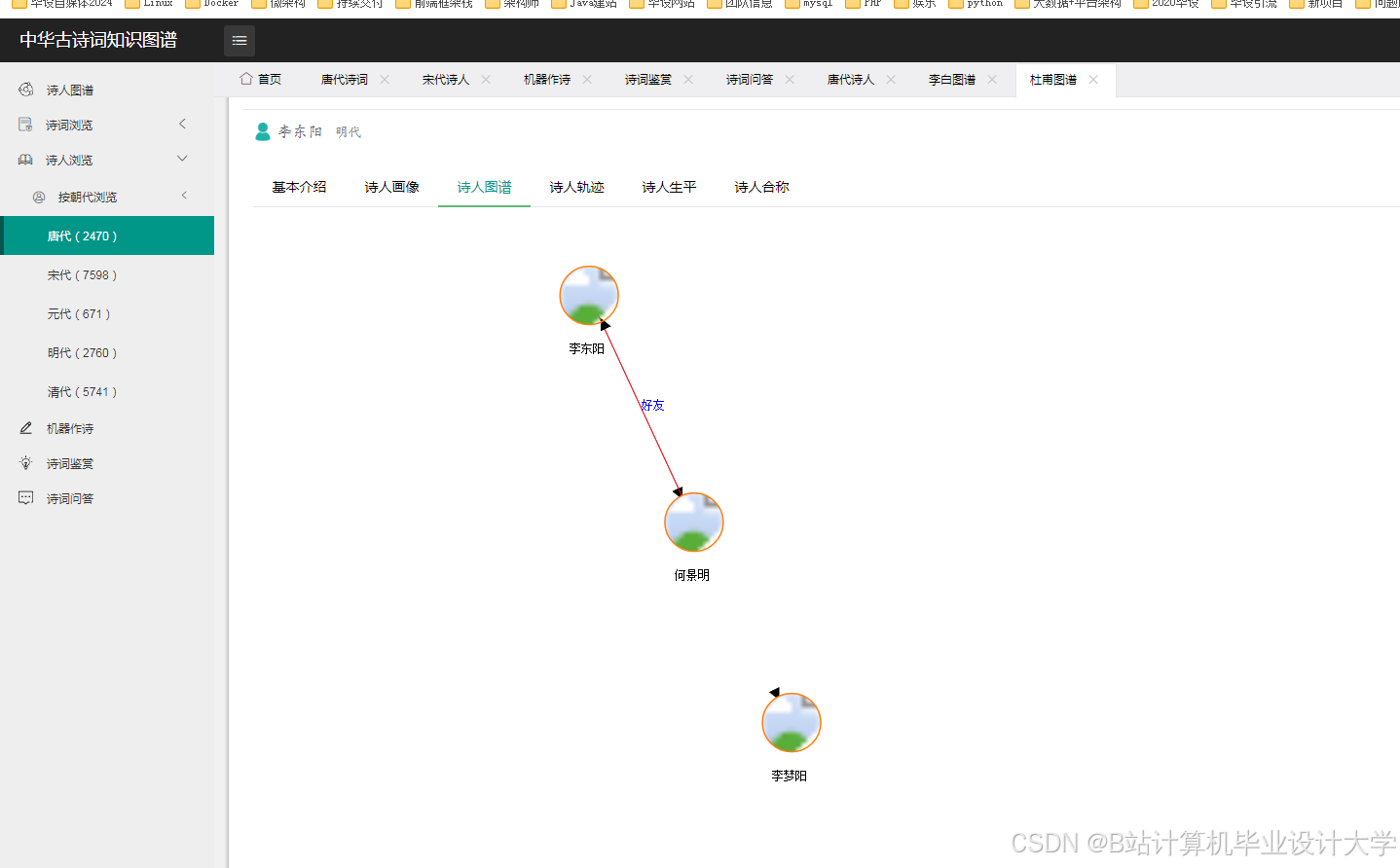
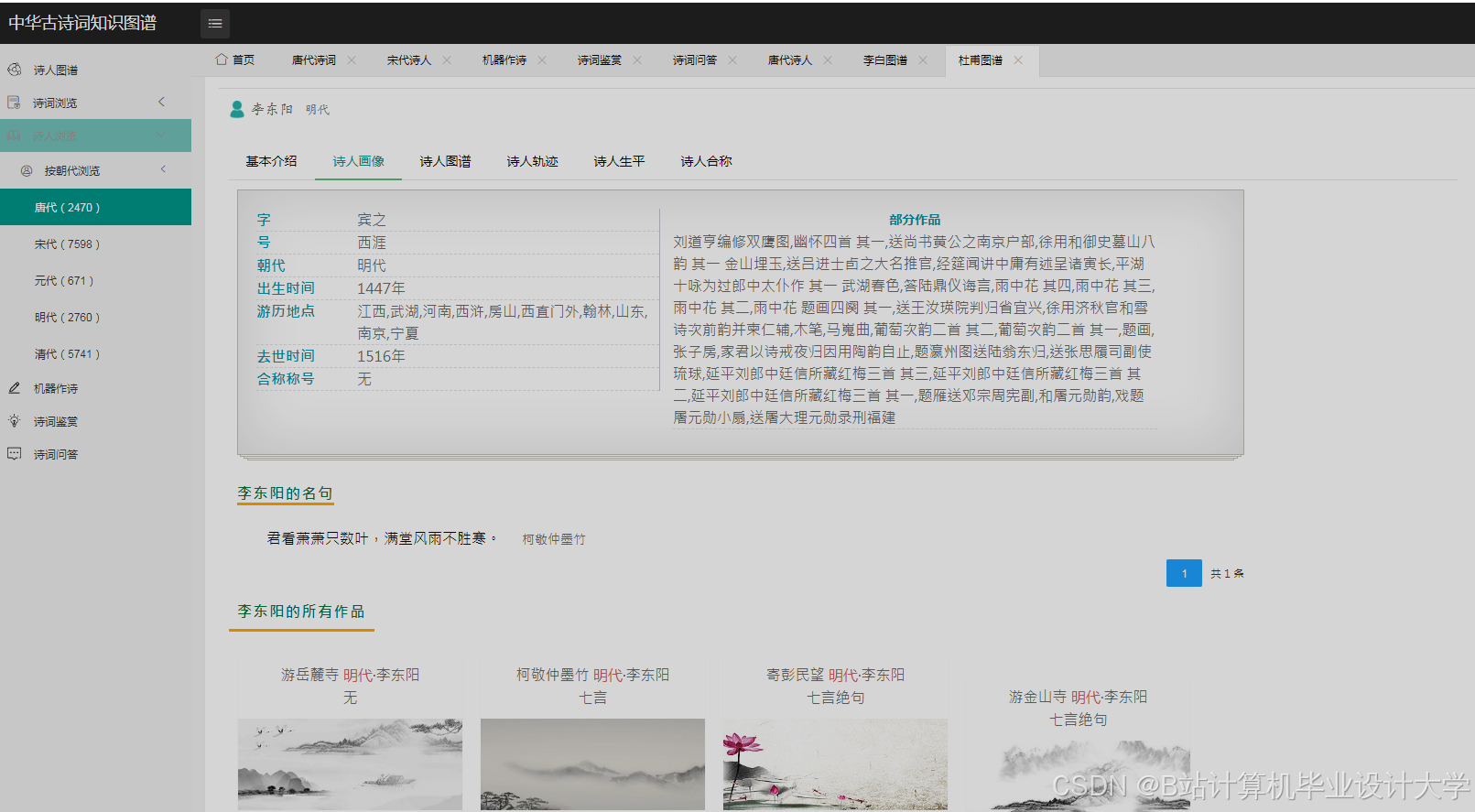
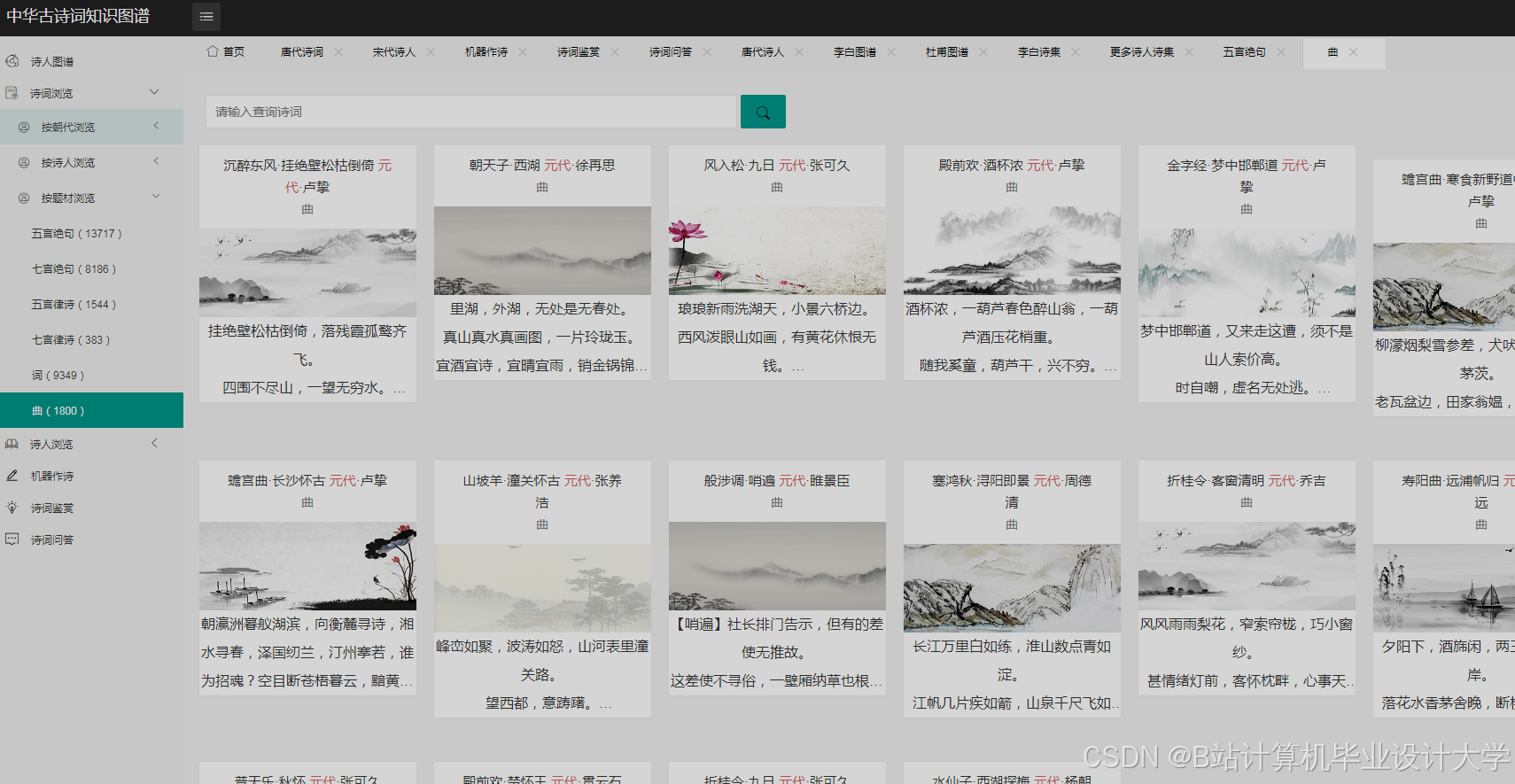
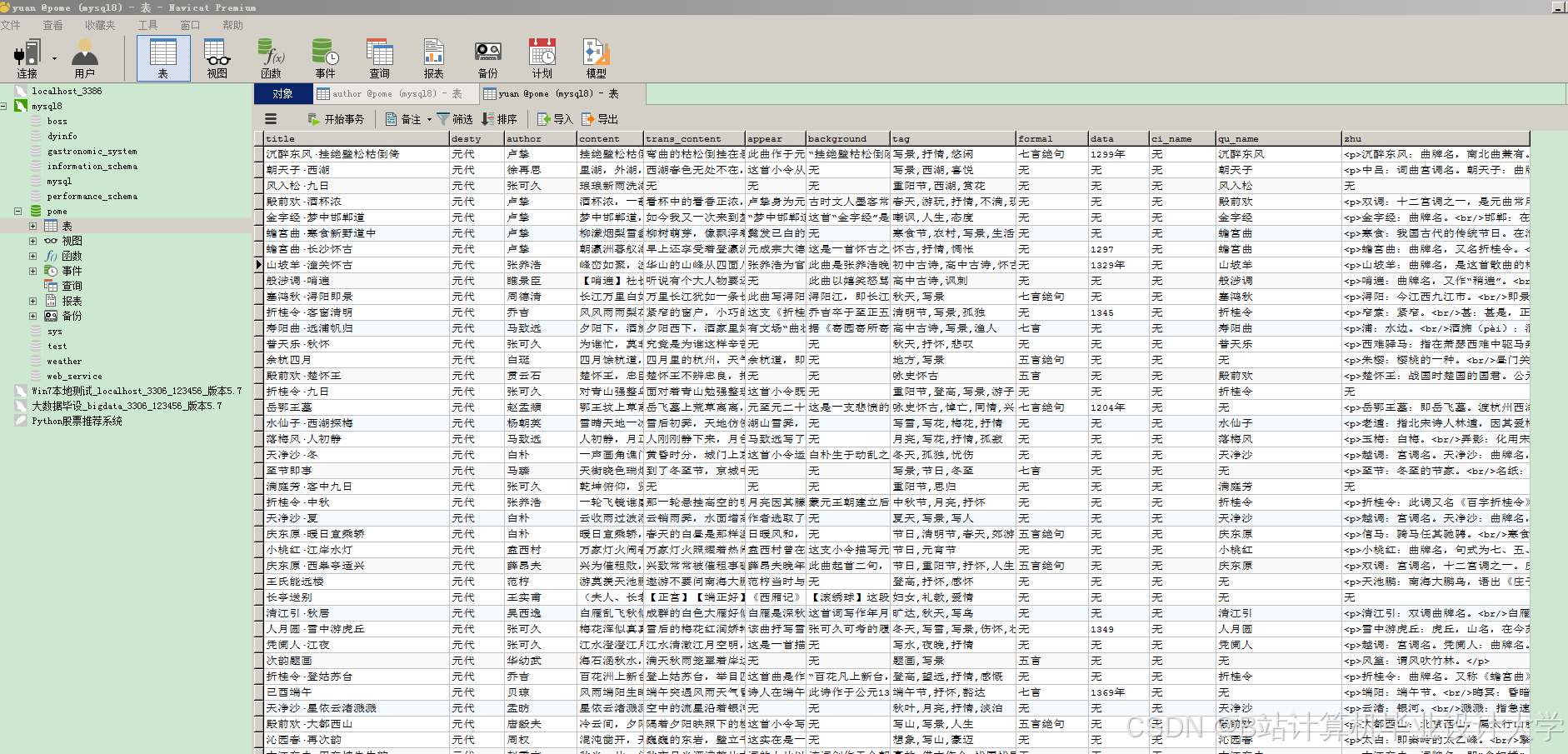
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











