 B站视频情感分析
B站视频情感分析





开发技术
python django requests jieba echarts vue element-plus axios vue-router 朴素贝叶斯算法分析情感分类 爬虫抓取Bilibili视频弹幕
创新点
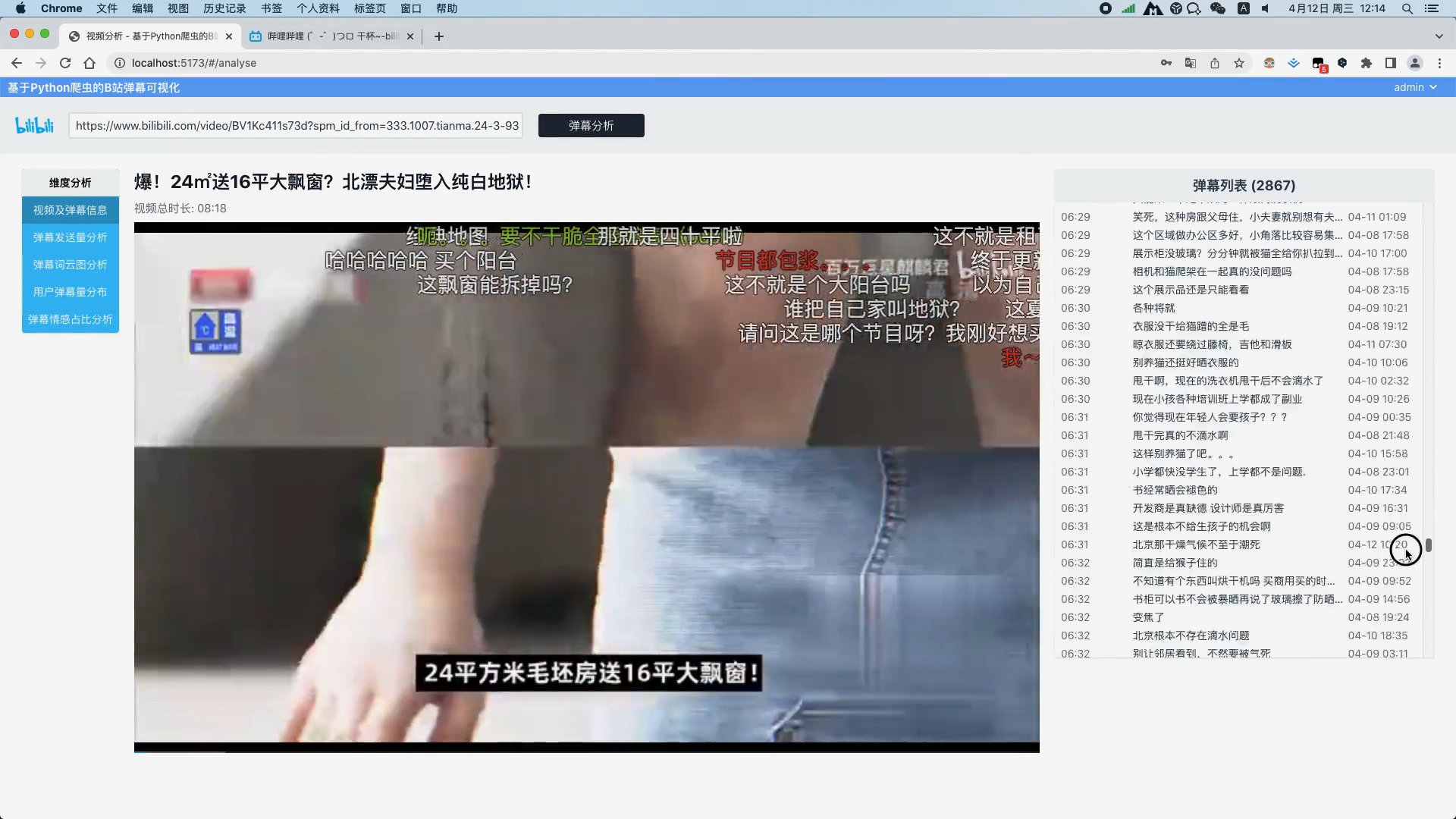
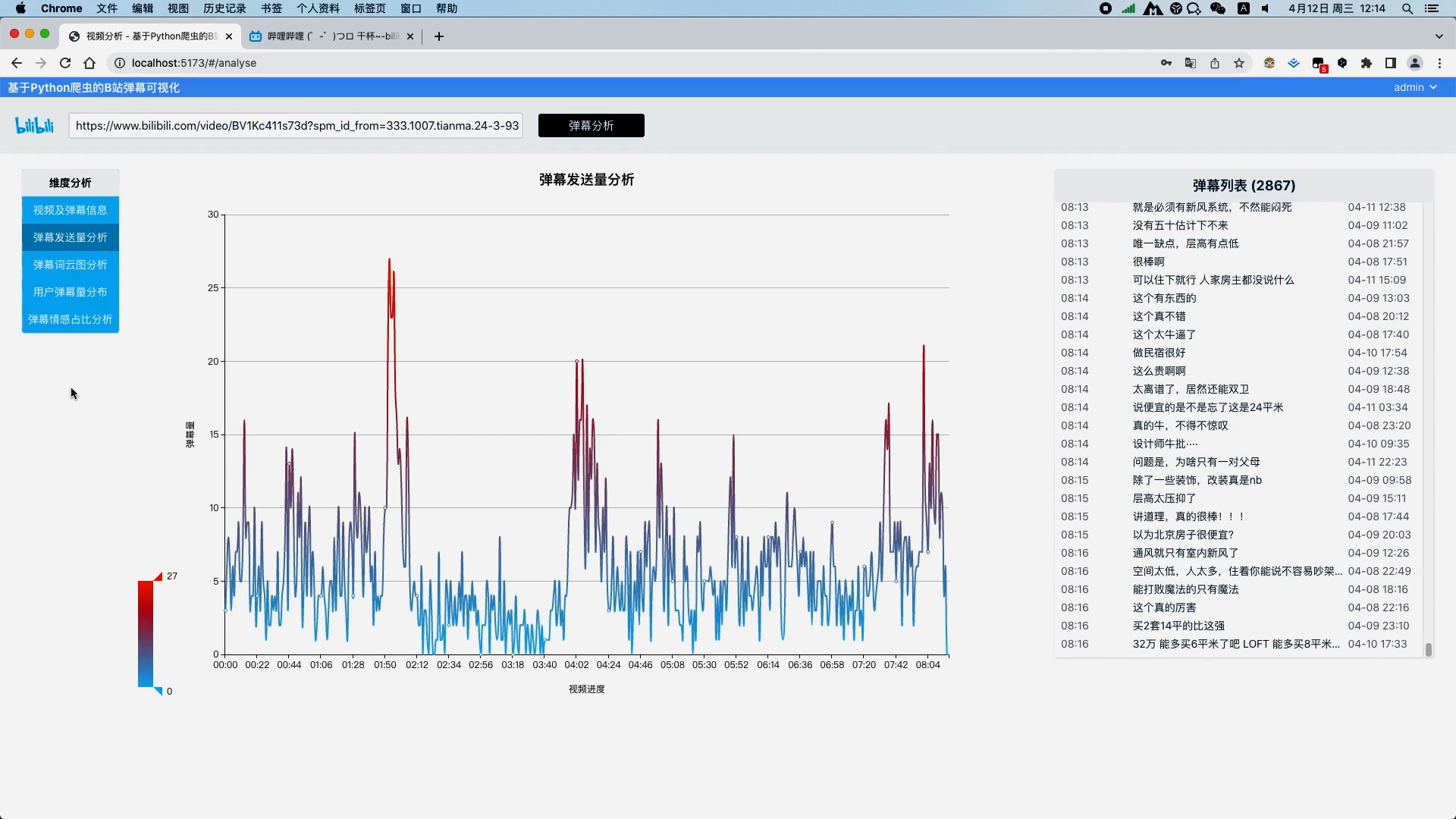
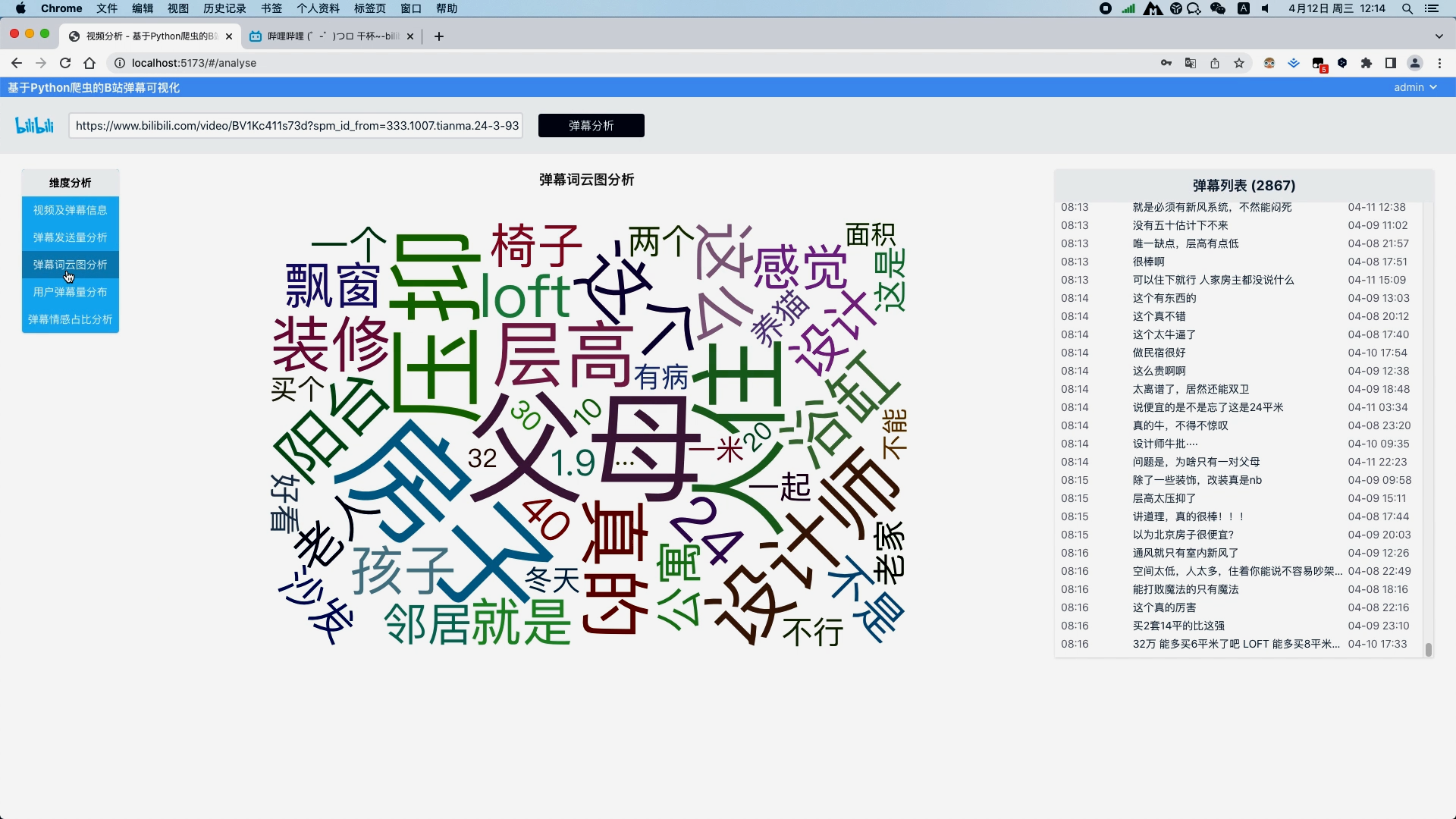
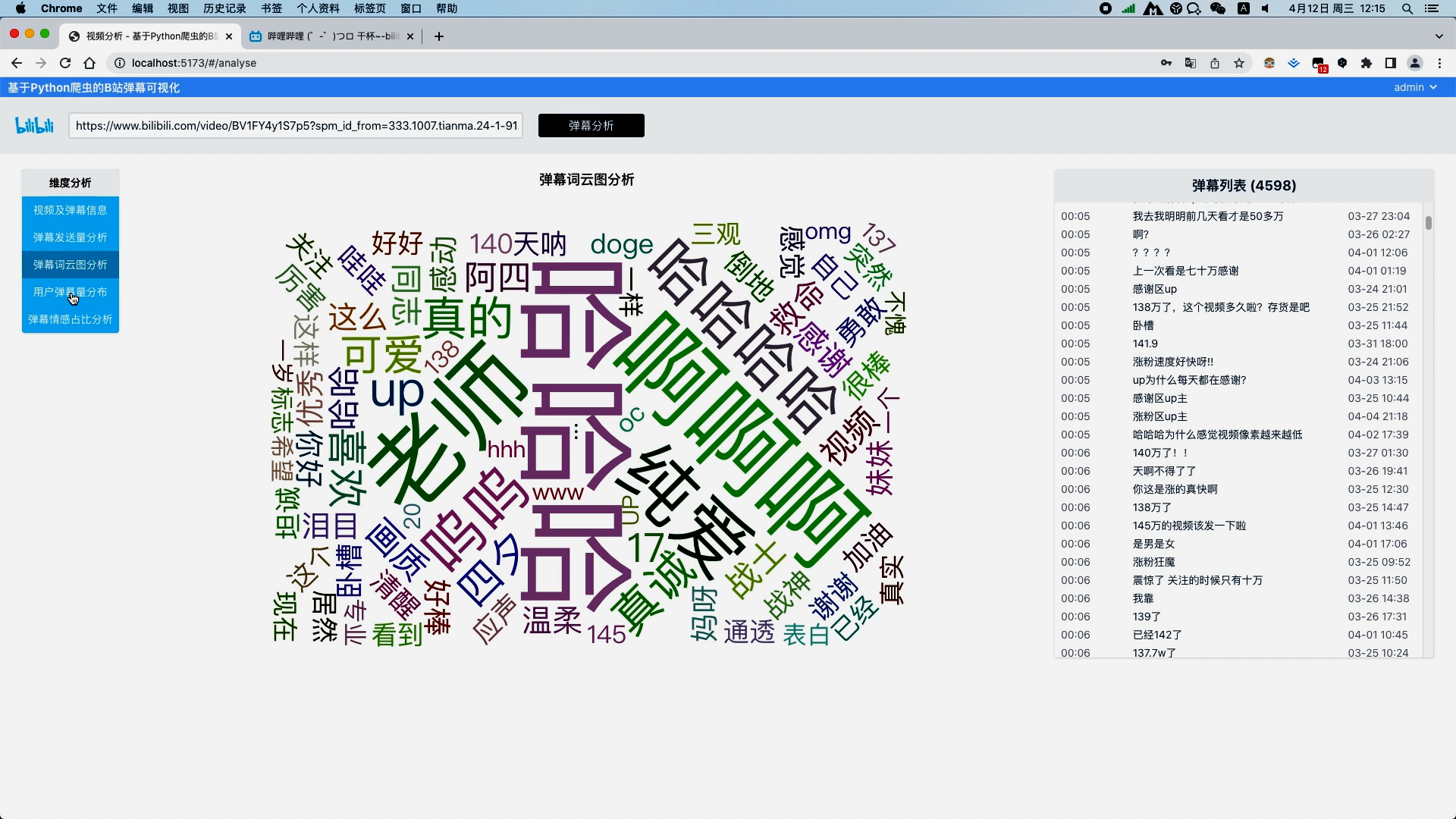
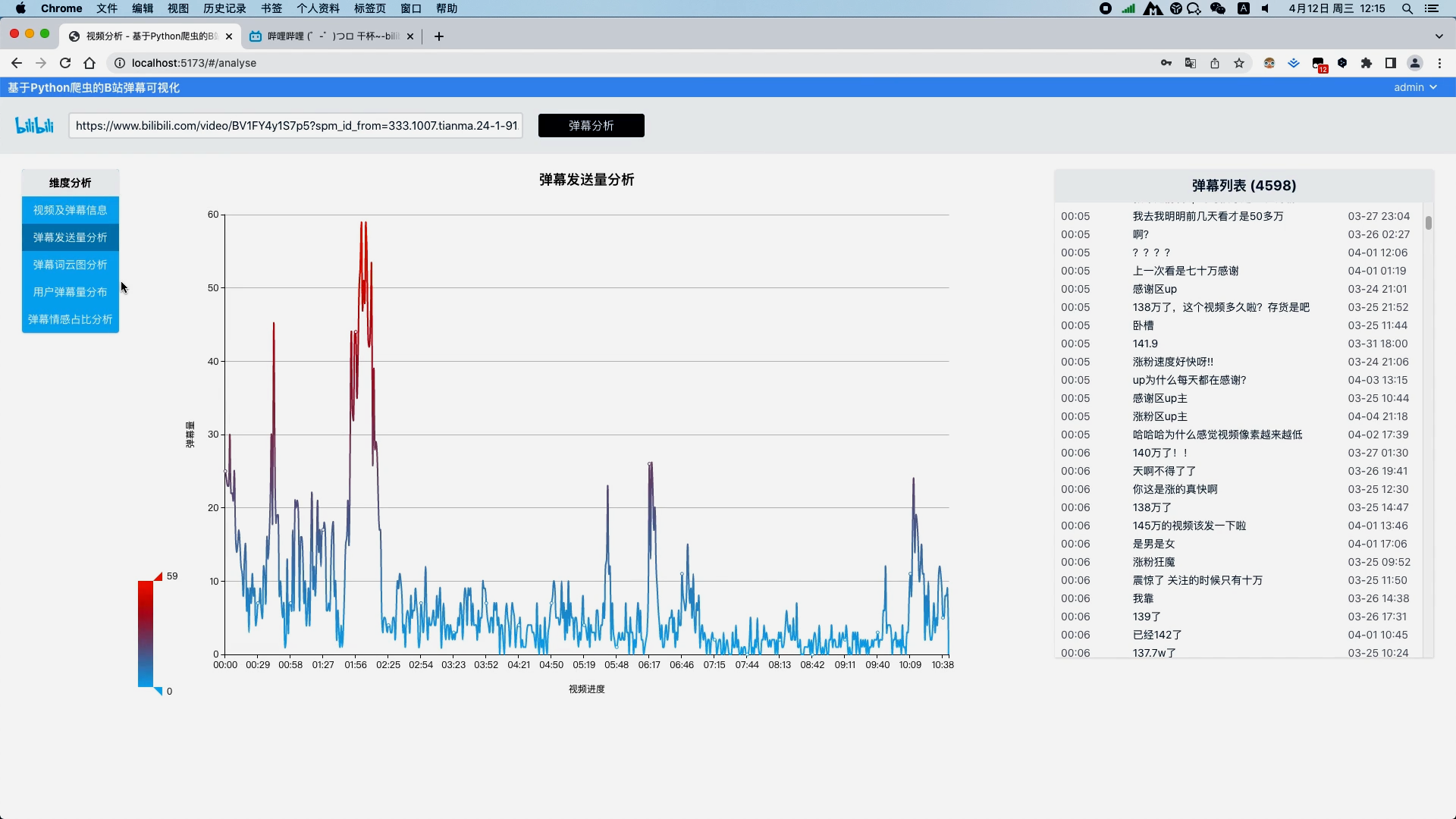
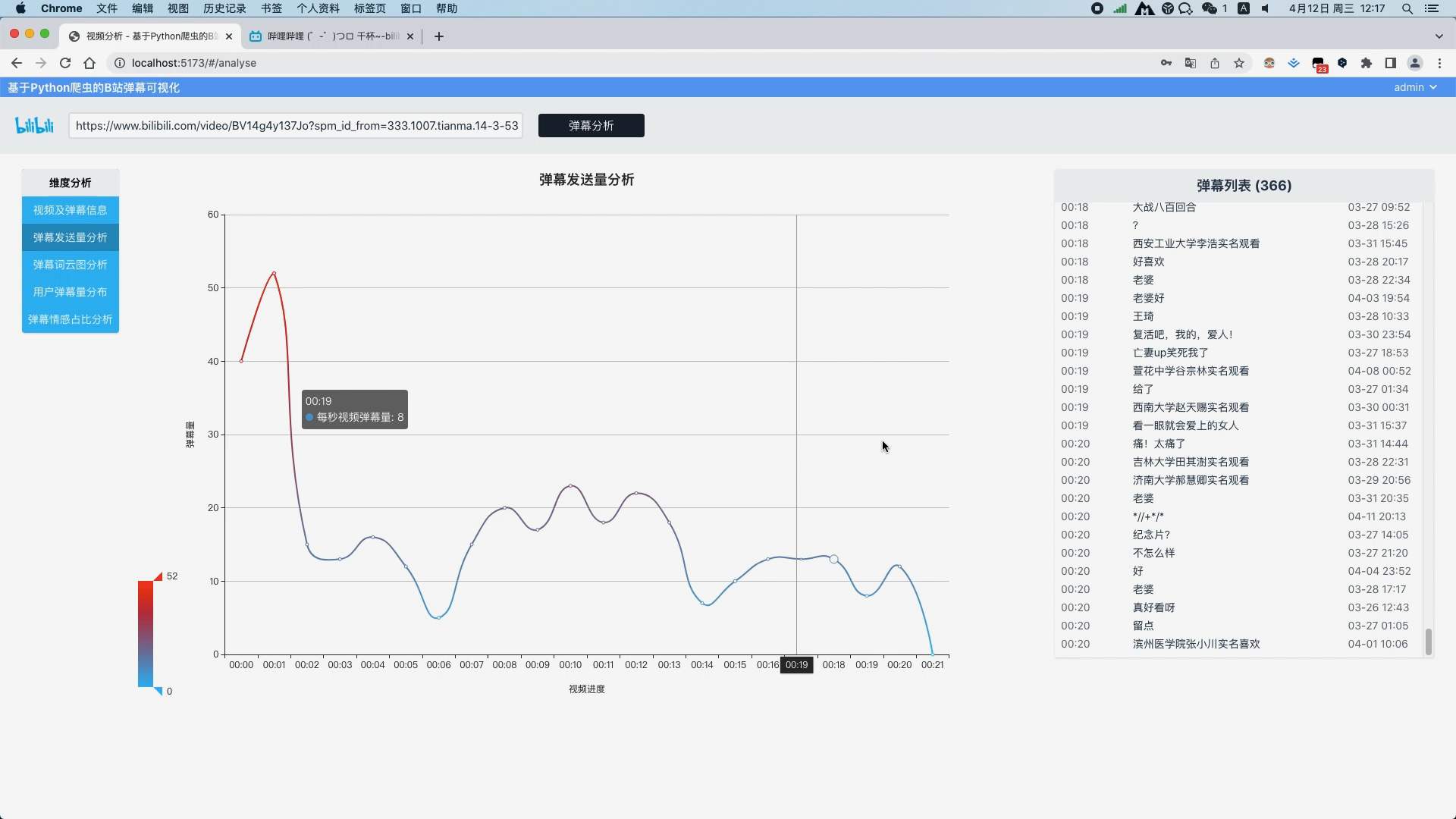
弹幕文本清洗 弹幕文本分词 去除弹幕文本停用词 弹幕发送量分析并以折线图展示视频过程中每一秒的弹幕量 弹幕文本分词分析并以词云图展示关键词
使用朴素贝叶斯算法分析弹幕情感并以饼图进行可视化 通过爬虫可以得到视频的标题、视频总时长、封面图,视频地址以及所有弹幕数据等
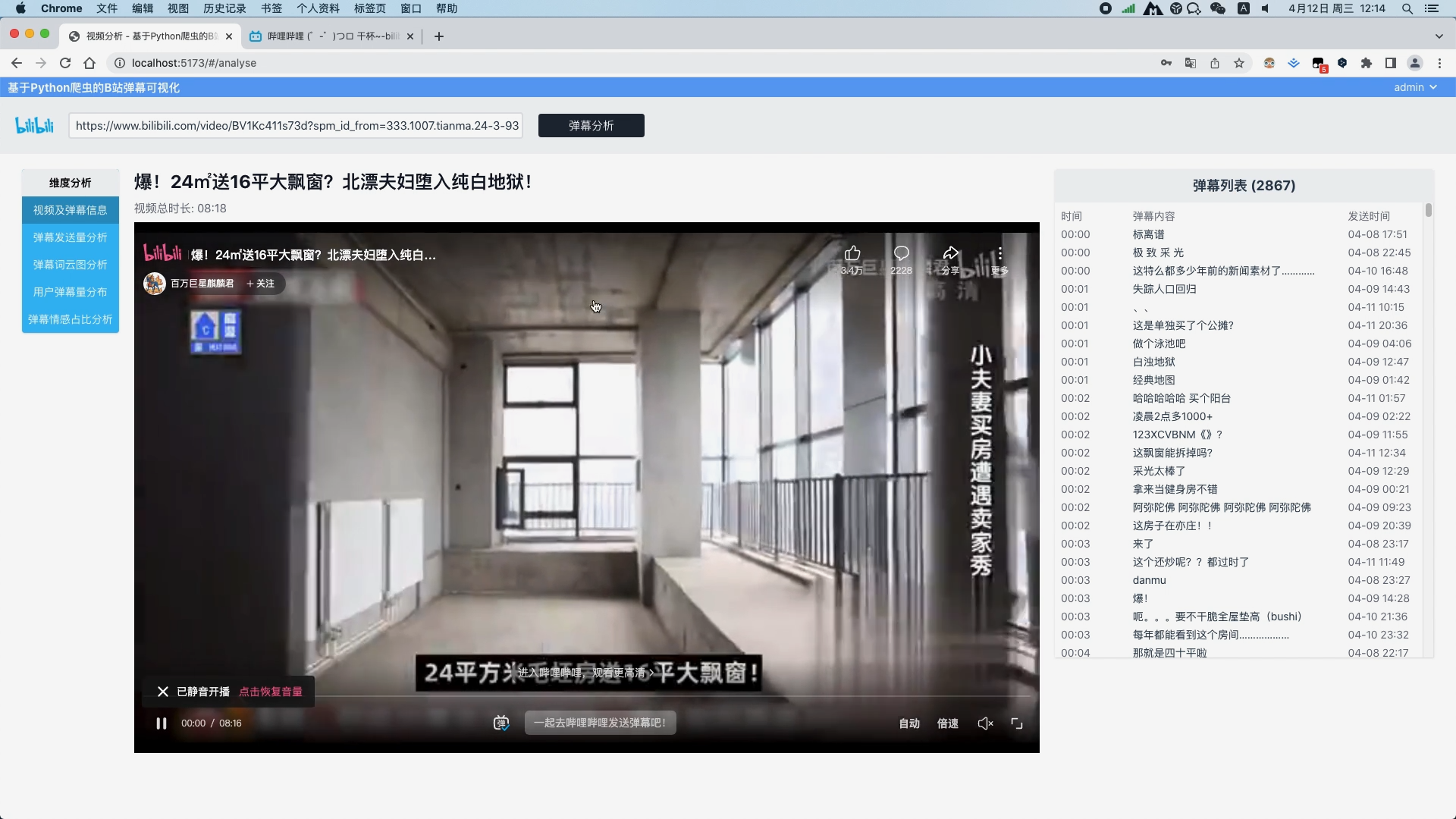
运行截图
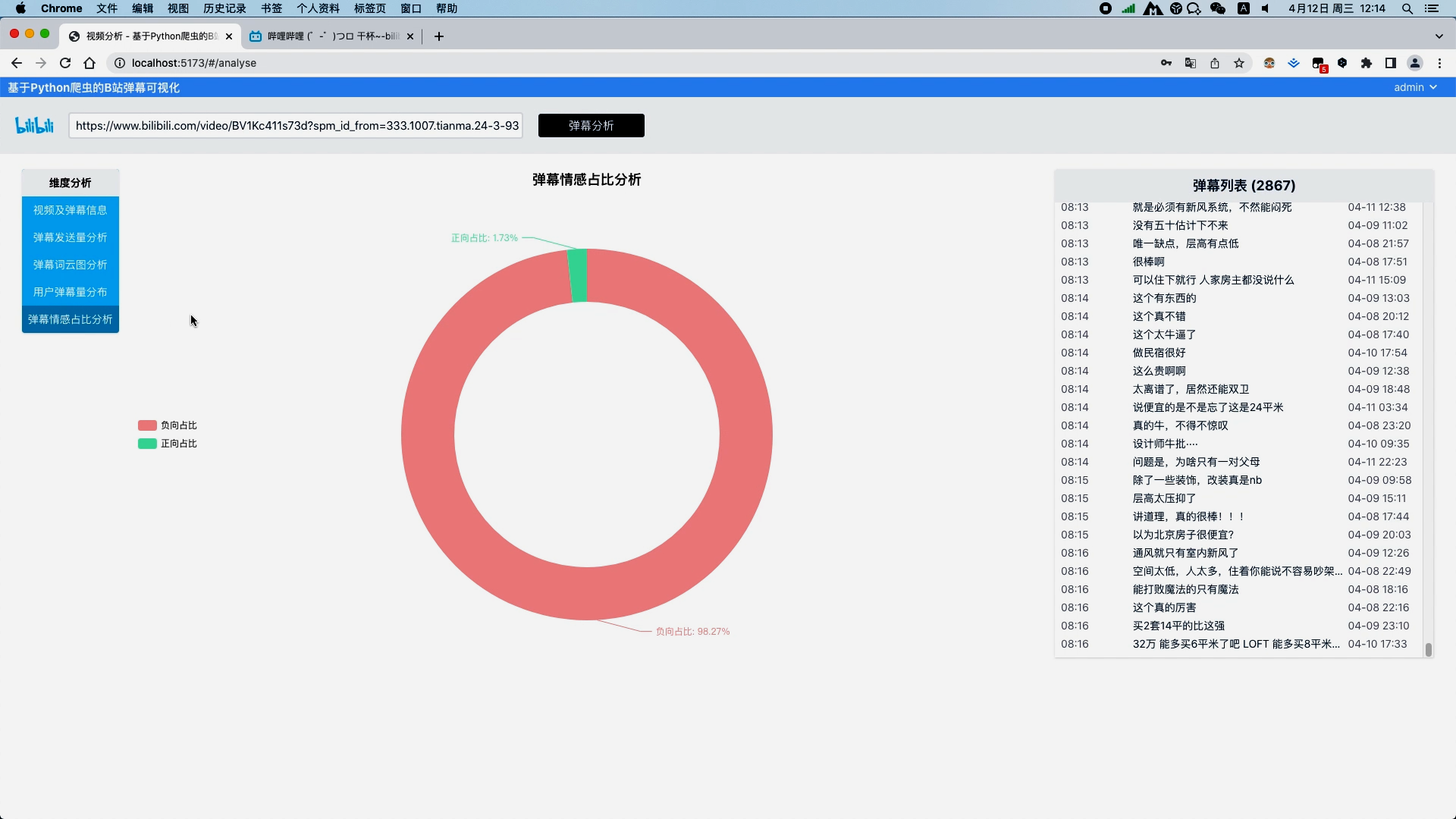
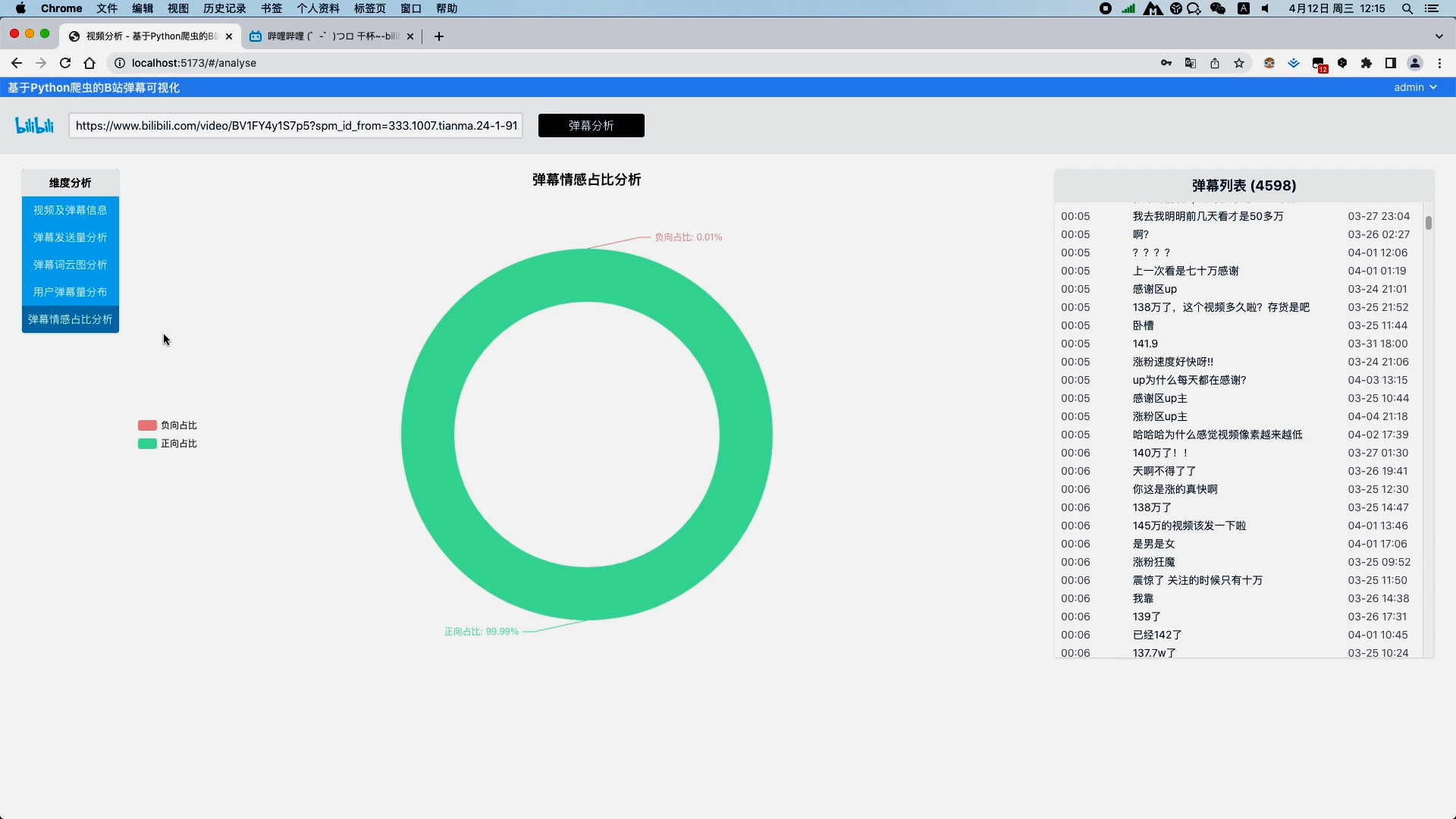
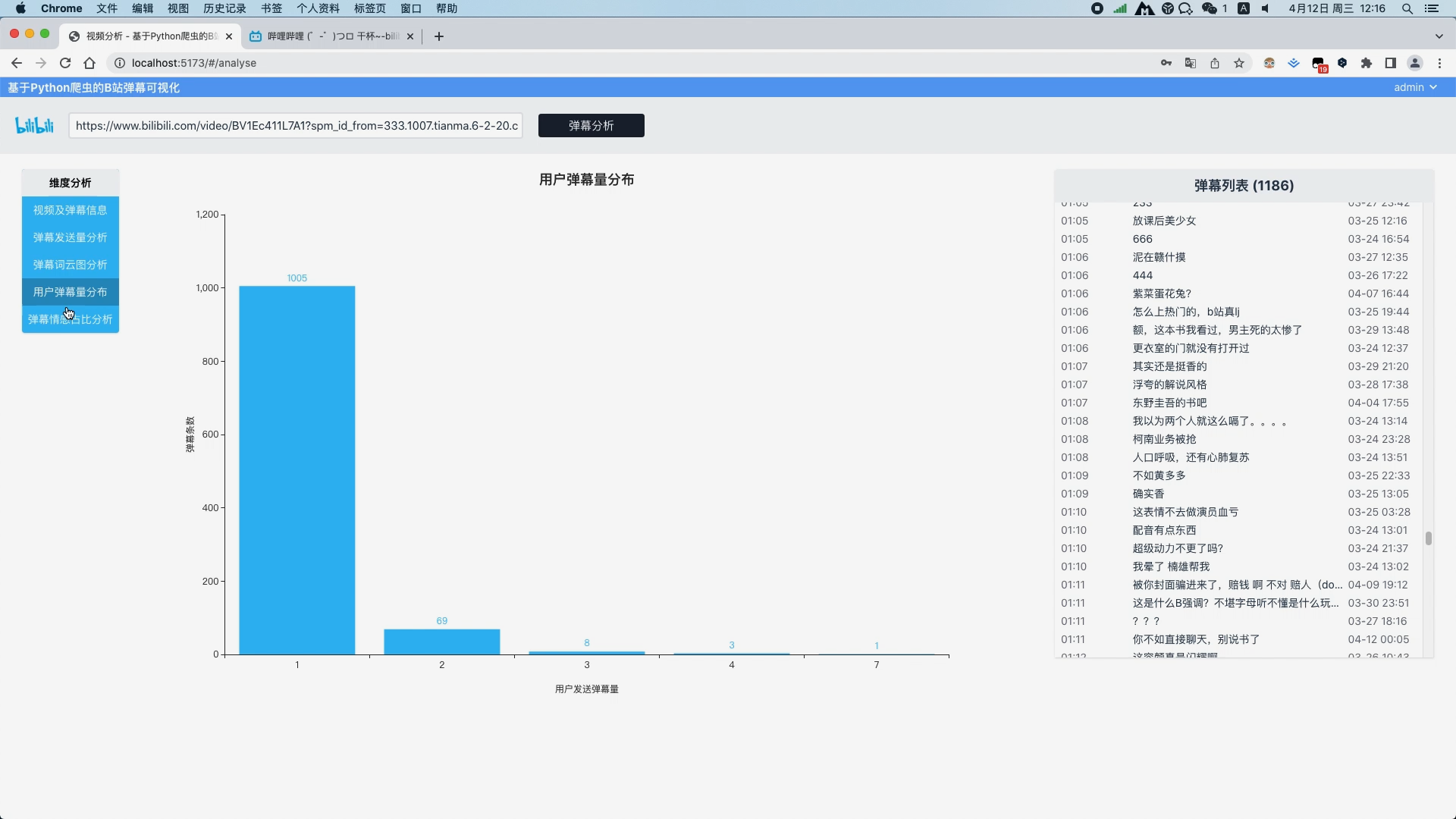
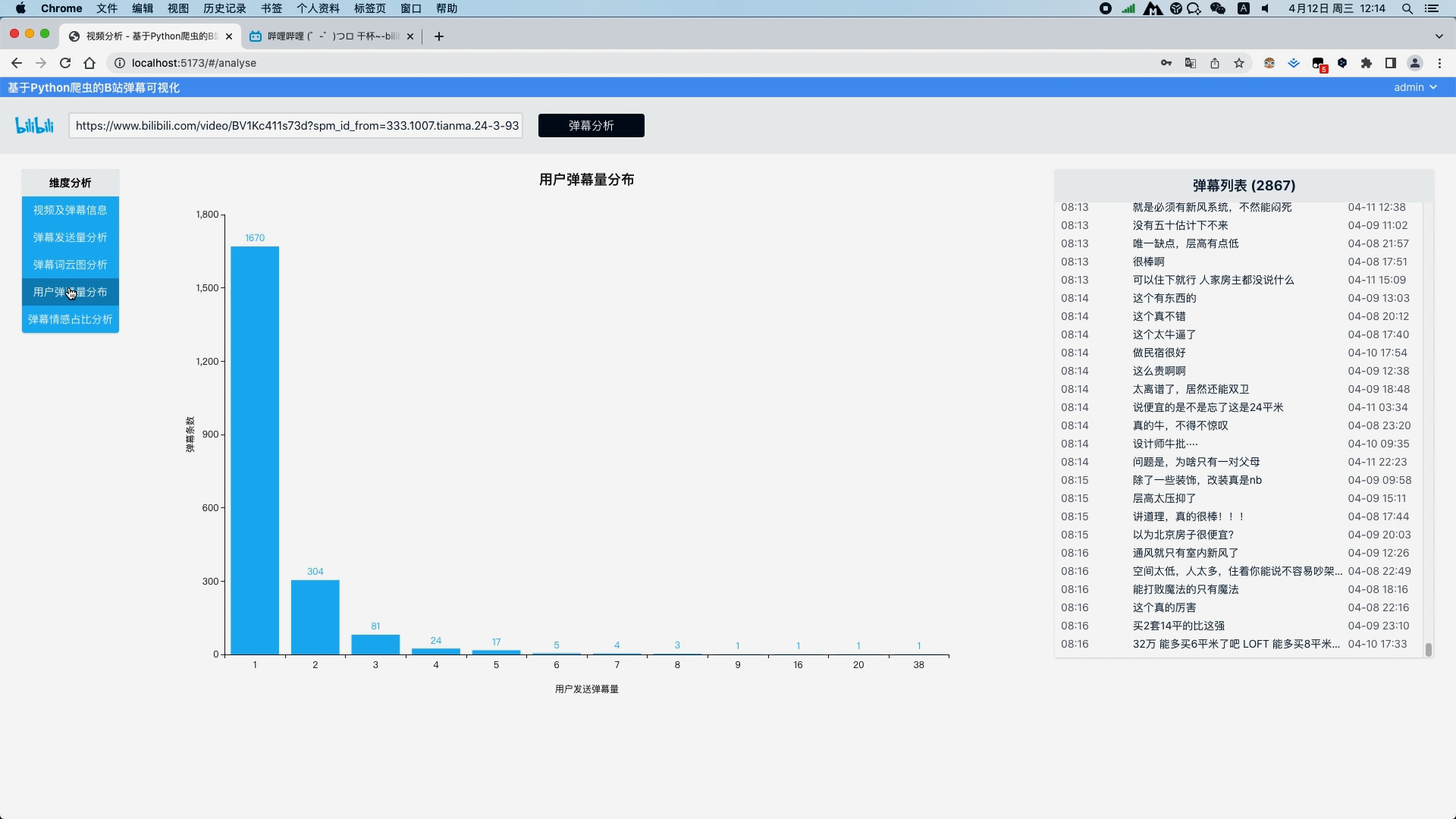
核心算法代码分享如下:
为了编写一个基于B站视频的情感分析深度学习模型,我们可以使用Python语言,并借助一些流行的库如TensorFlow或PyTorch。这里,我将给出一个简化的例子,使用PyTorch和BERT(一个预训练的Transformer模型)来进行视频标题或评论的情感分析。虽然直接分析视频内容(如视频帧)需要更复杂的模型和更多的计算资源,但通过分析视频标题或相关评论来预测情感是一个可行的起点。
首先,确保你已经安装了必要的库,包括torch, transformers 等。如果没有安装,可以使用pip来安装它们:
bash复制代码
pip install torch transformers torchvision |
接下来,我们将编写一个简单的代码示例,使用BERT模型来分类视频标题的情感(例如,正面或负面):
python复制代码
import torch | |
from transformers import BertTokenizer, BertForSequenceClassification | |
from torch.utils.data import DataLoader, Dataset | |
class BertDataset(Dataset): | |
def __init__(self, encodings, labels): | |
self.encodings = encodings | |
self.labels = labels | |
def __getitem__(self, idx): | |
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()} | |
item['labels'] = torch.tensor(self.labels[idx]) | |
return item | |
def __len__(self): | |
return len(self.labels) | |
def train(model, data_loader, optimizer, device): | |
model.train() | |
for batch in data_loader: | |
batch = {k: v.to(device) for k, v in batch.items()} | |
outputs = model(**batch) | |
loss = outputs.loss | |
loss.backward() | |
optimizer.step() | |
optimizer.zero_grad() | |
# 示例数据 | |
texts = ["这个视频太棒了!", "这个视频很无聊..."] | |
labels = [1, 0] # 假设1是正面,0是负面 | |
# 初始化tokenizer和模型 | |
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') | |
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2) | |
# 编码数据 | |
encodings = tokenizer(texts, padding=True, truncation=True, return_tensors="pt") | |
# 创建数据加载器 | |
dataset = BertDataset(encodings, labels) | |
data_loader = DataLoader(dataset, batch_size=2, shuffle=True) | |
# 设定设备和优化器 | |
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |
model.to(device) | |
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5) | |
# 训练模型 | |
train(model, data_loader, optimizer, device) | |
# 注意:这只是一个非常简化的例子,实际使用中需要更多的数据处理、模型评估和验证步骤。 |
注意:
- 上面的代码示例仅用于演示如何设置和训练一个基本的BERT模型用于情感分类。
- 在实际应用中,你需要一个包含大量带标签数据的数据集来训练模型,并可能需要进行更复杂的预处理和模型调优。
- 你还可以考虑使用其他预训练的模型或架构,如RoBERTa、ELECTRA等,它们可能在特定任务上表现更好。
- 由于直接分析视频内容(如视觉和情感)通常比文本分析更复杂,你可能需要使用视频处理库(如OpenCV)和深度学习模型(如卷积神经网络CNN)来提取视频特征,并结合文本分析的结果。



















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











