




基于Python/flask的微博舆情数据分析可视化系统
python爬虫数据分析可视化项目
编程语言:python
涉及技术:flask mysql echarts SnowNlP情感分析 文本分析
系统设计的功能:
①用户注册登录
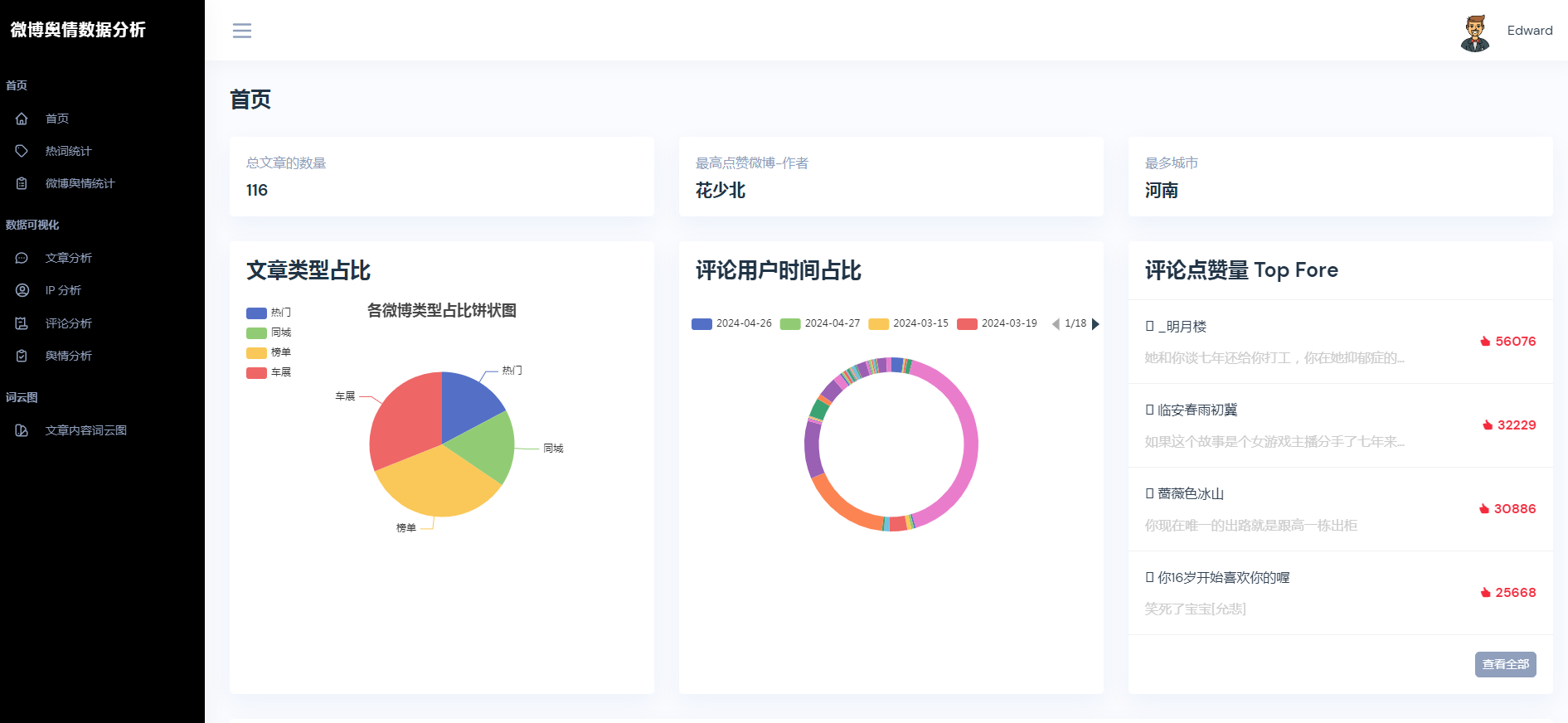
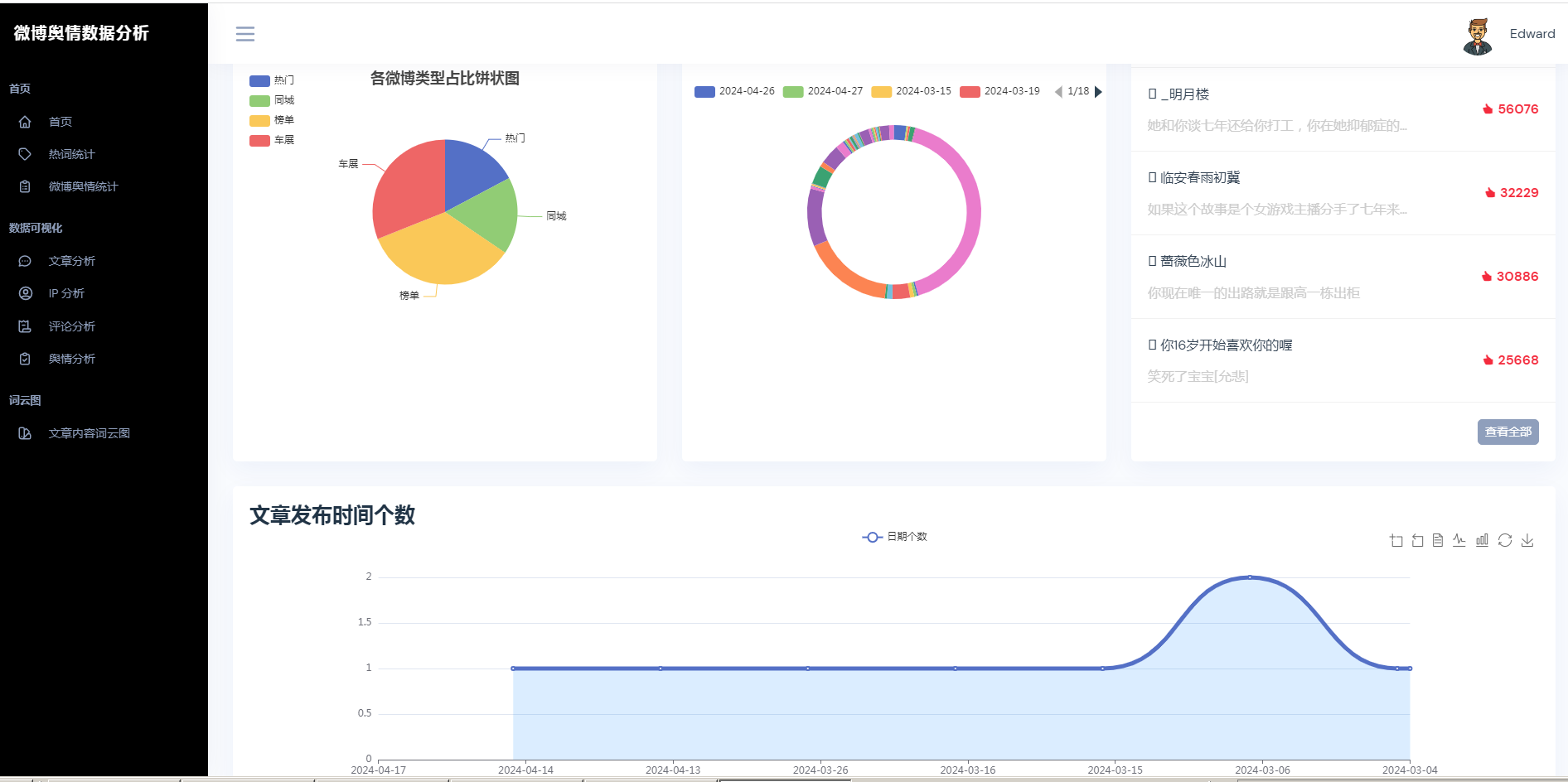
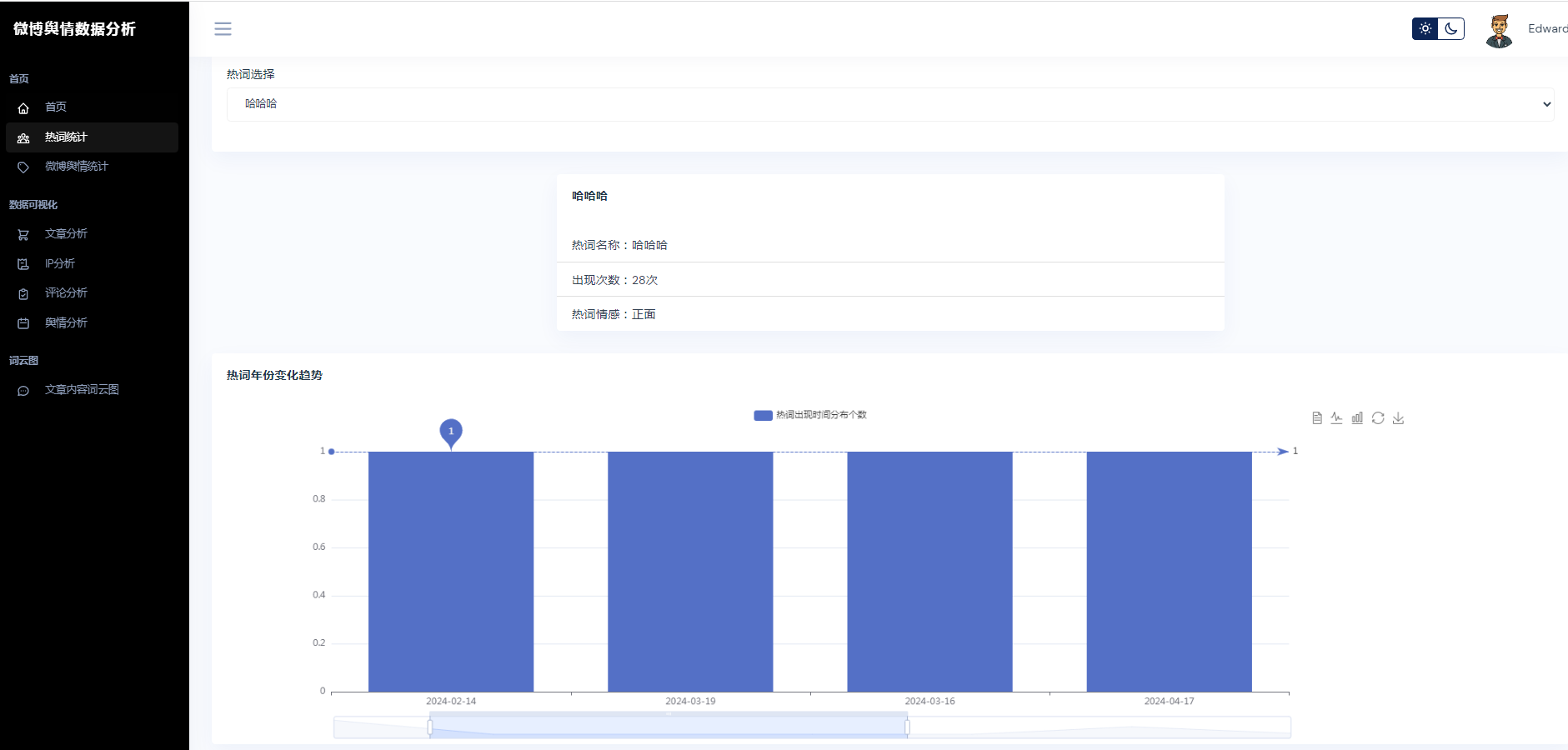
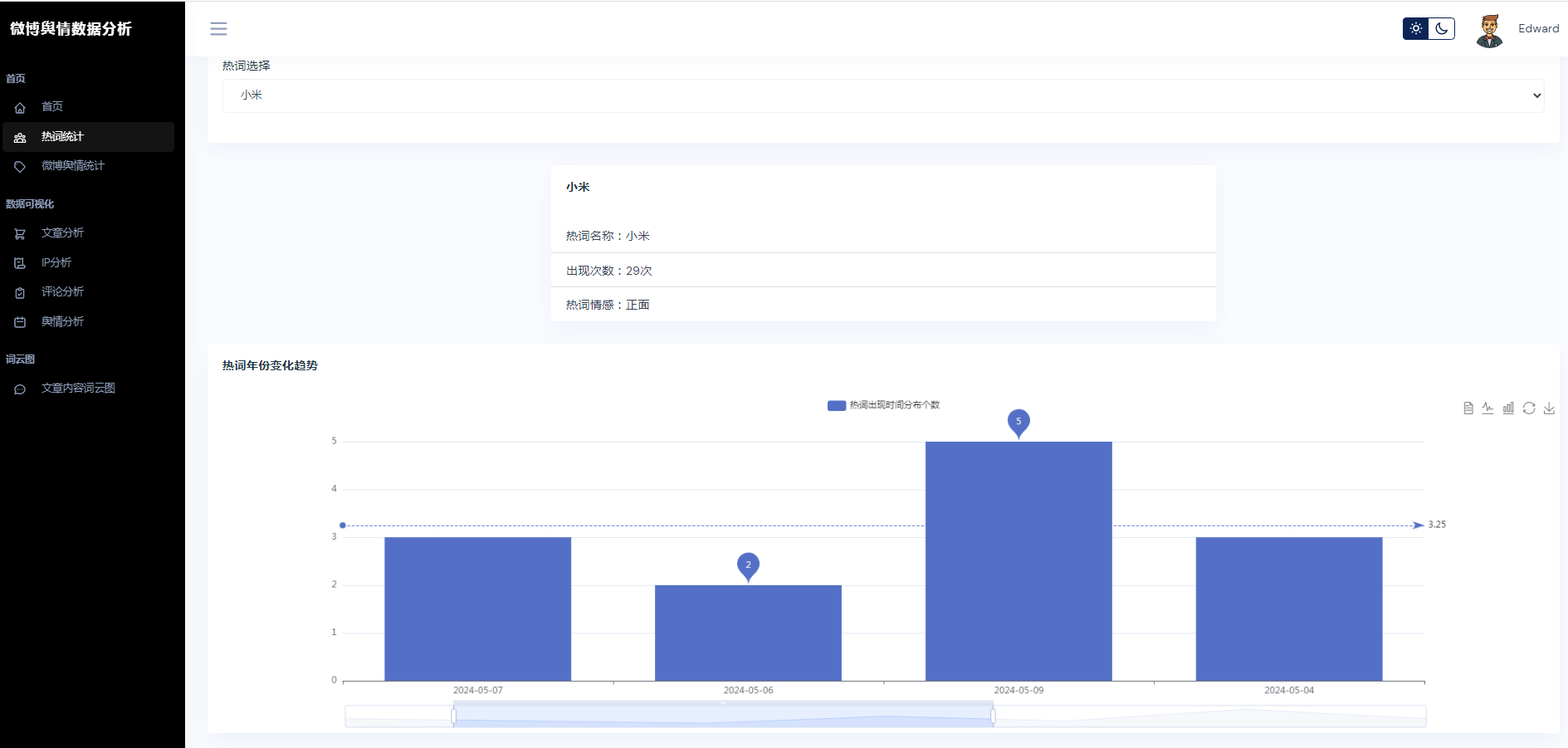
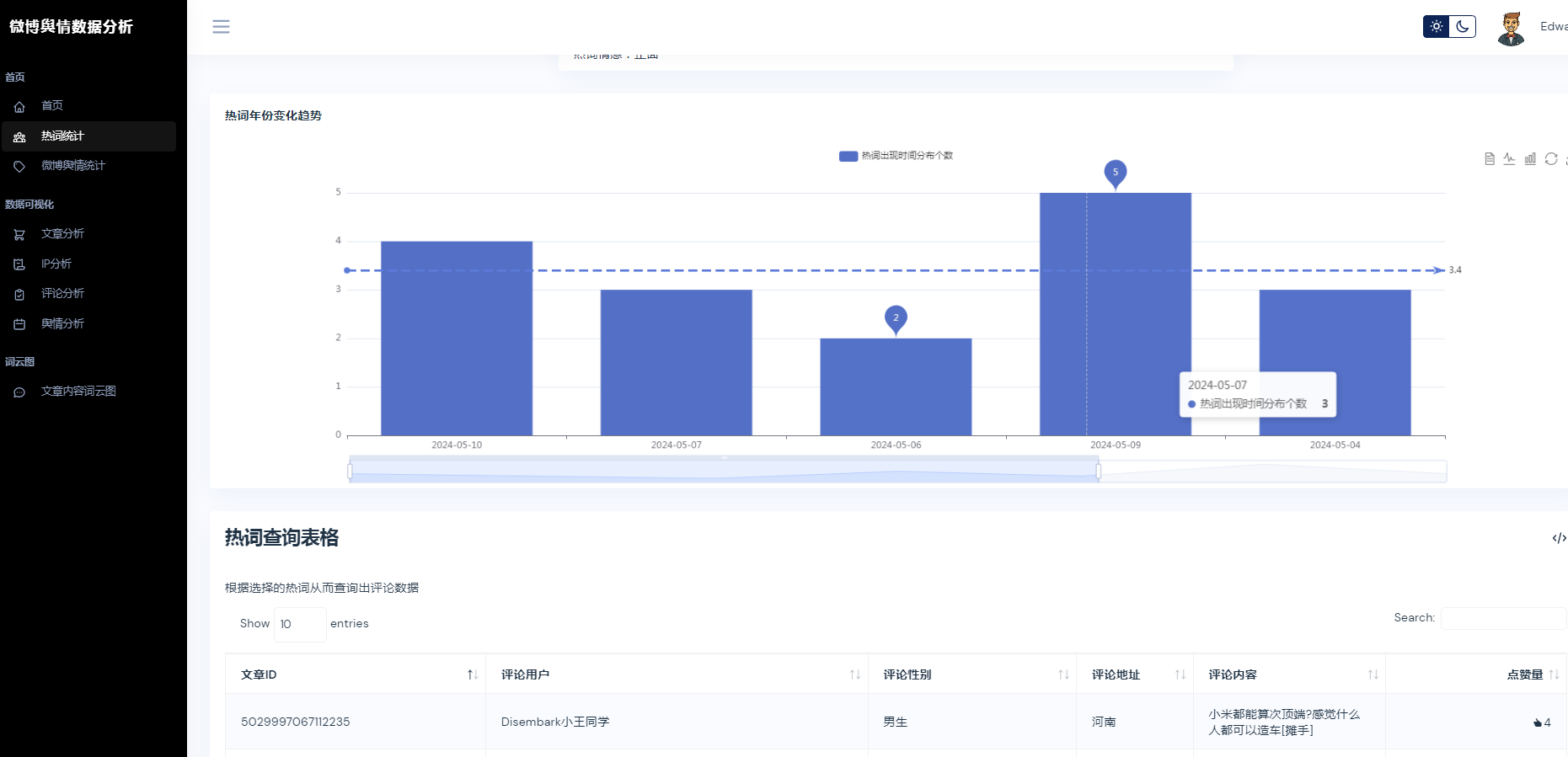
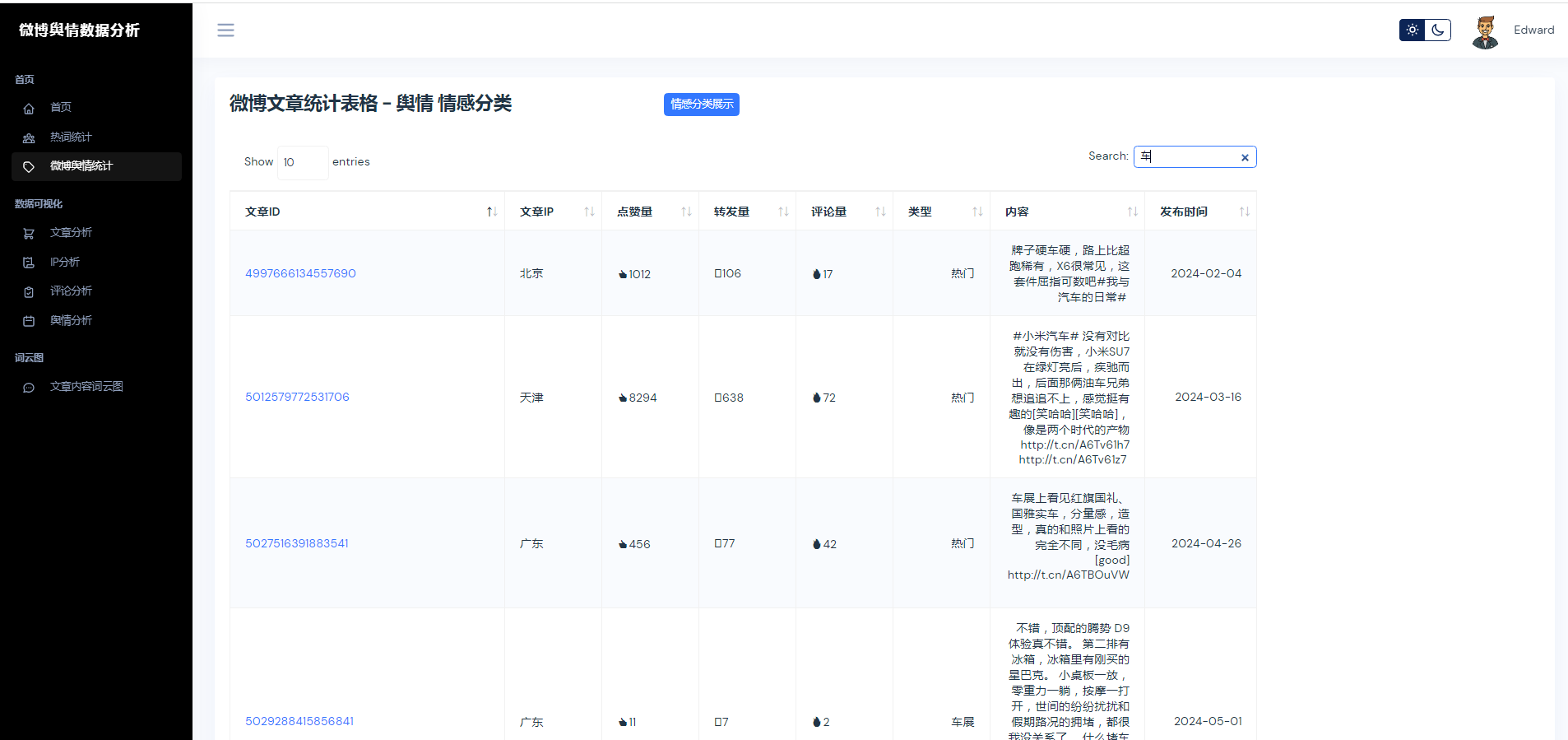
②微博数据描述性统计、热词统计、舆情统计
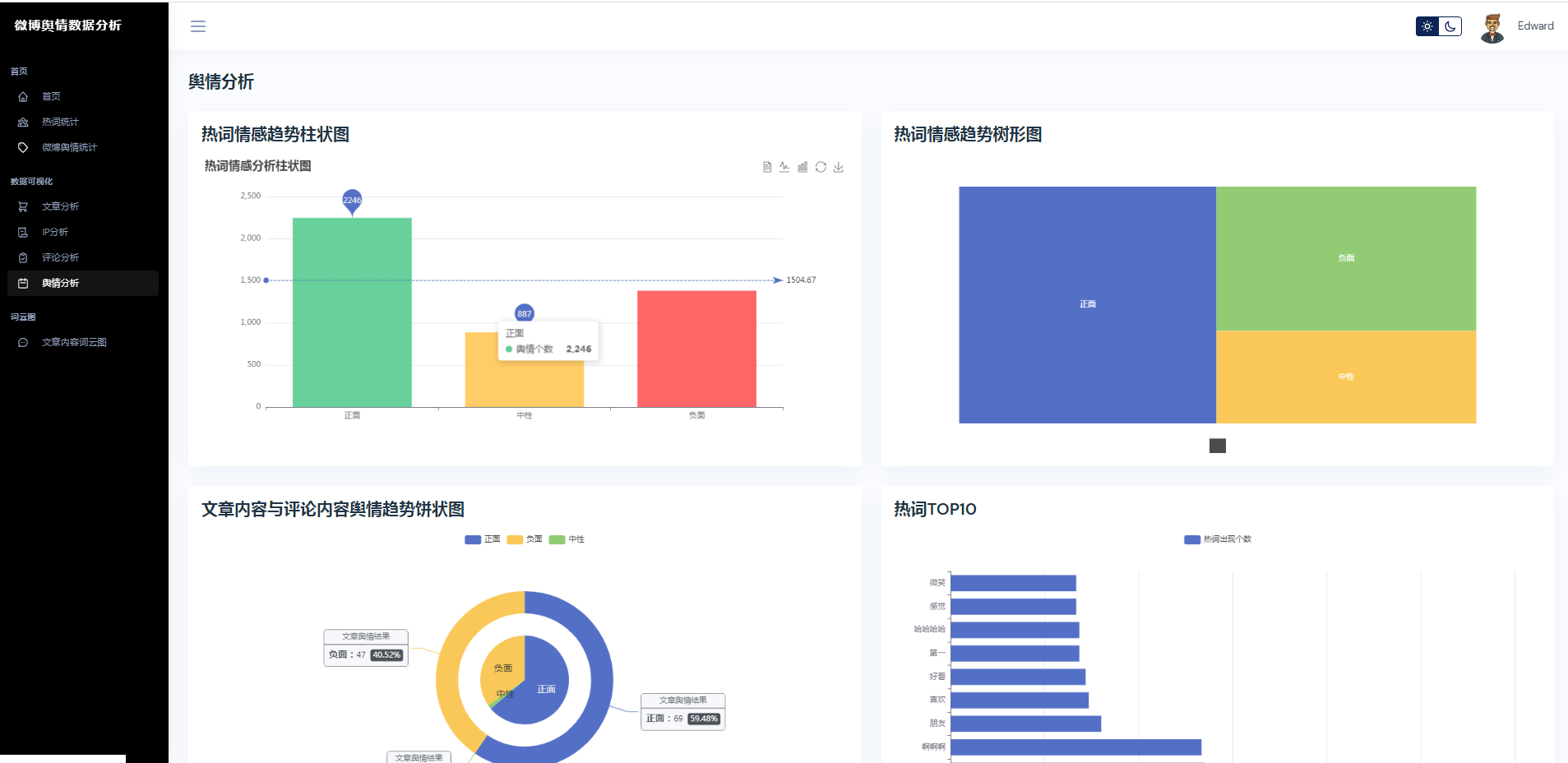
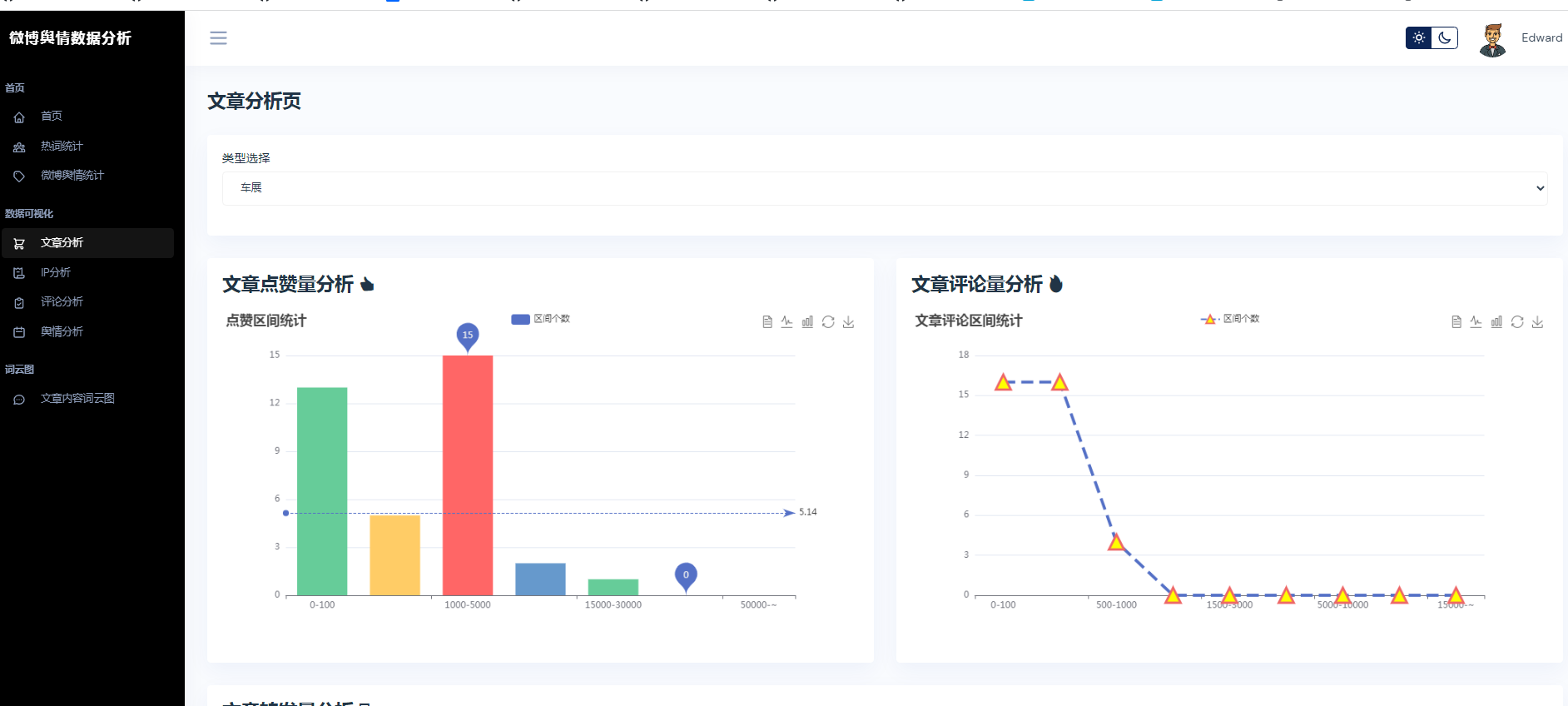
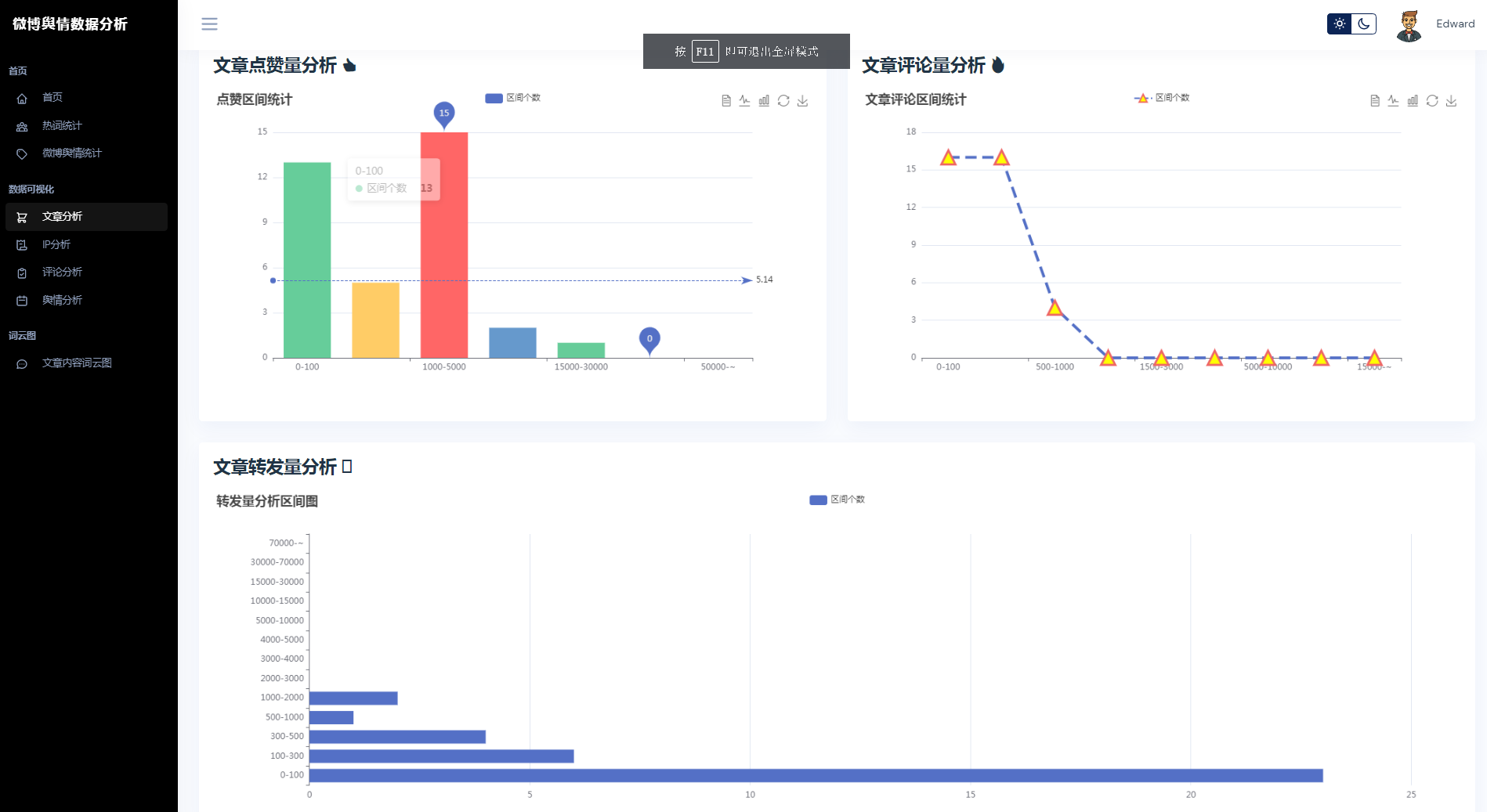
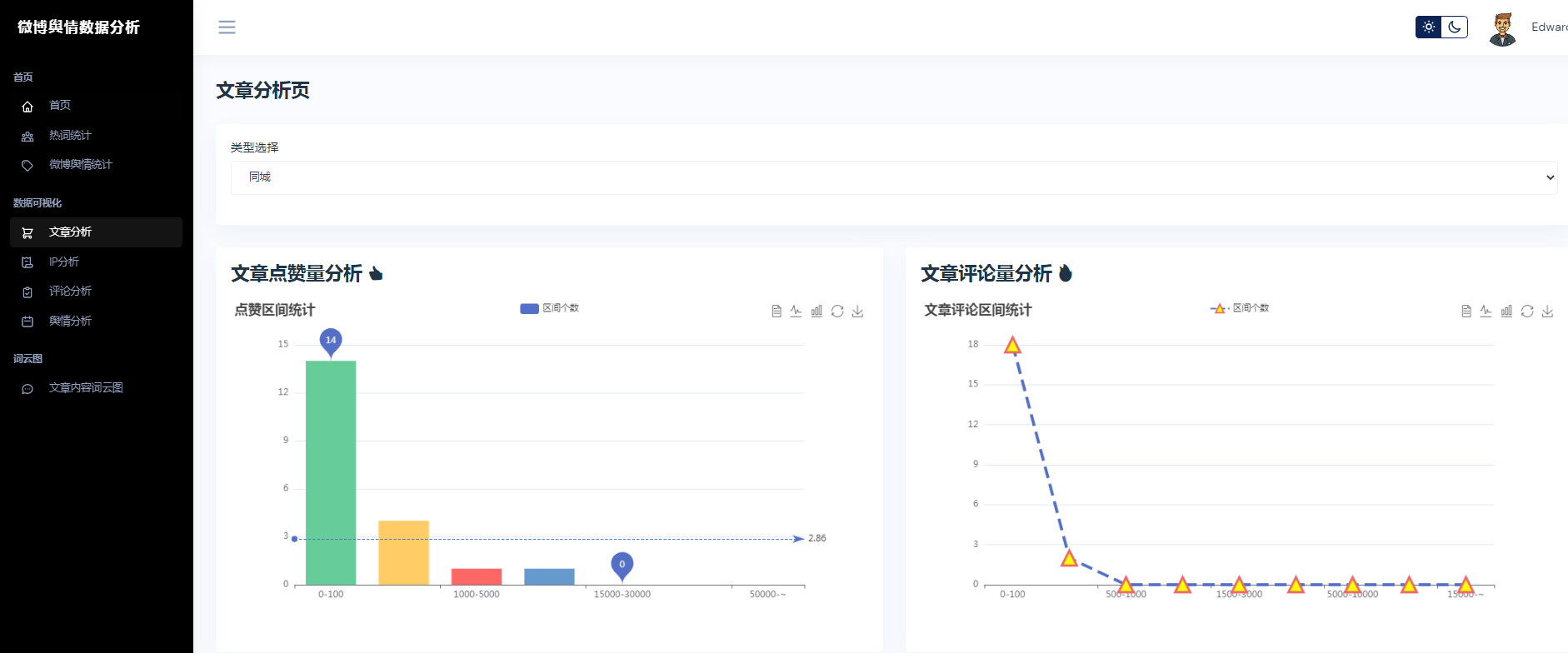
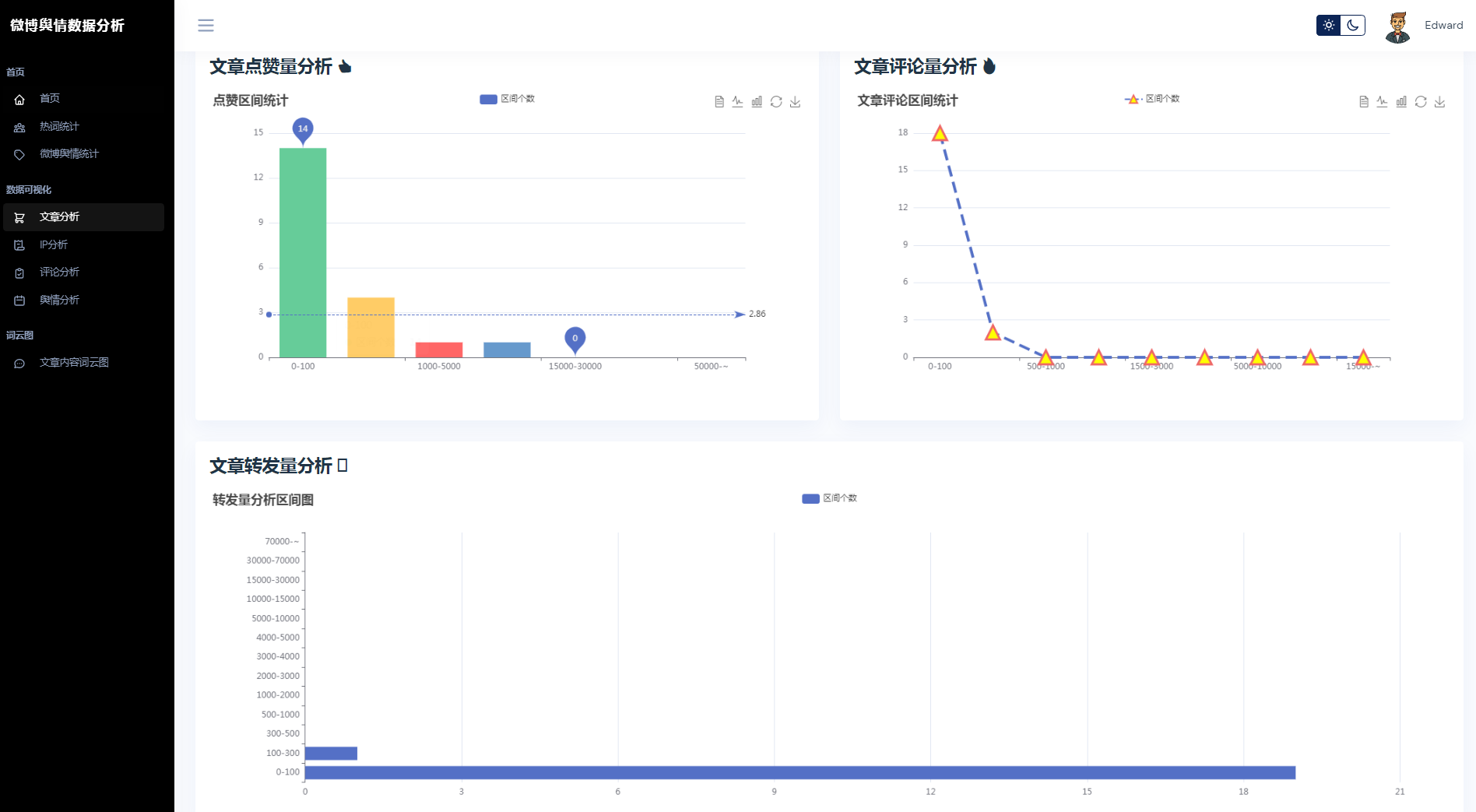
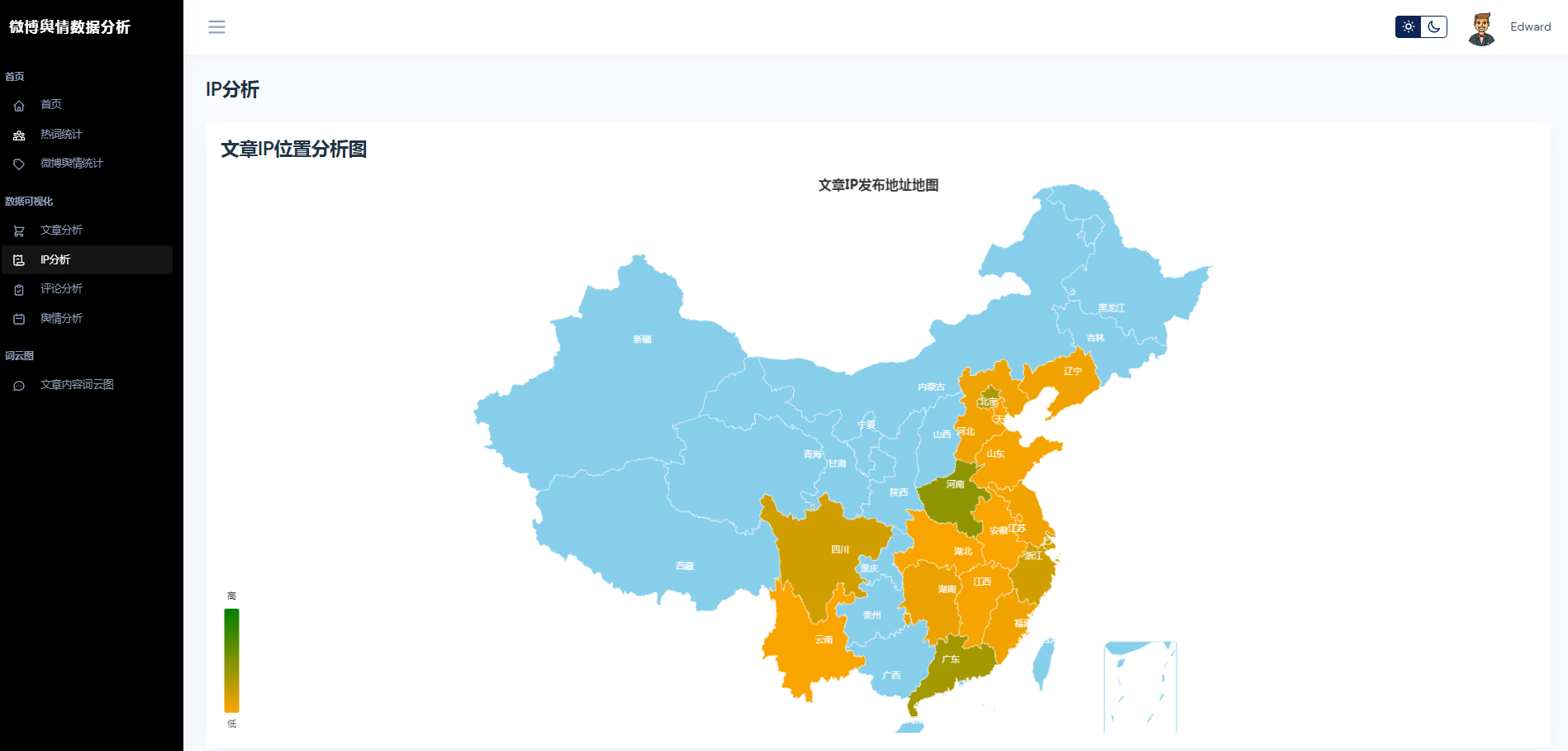
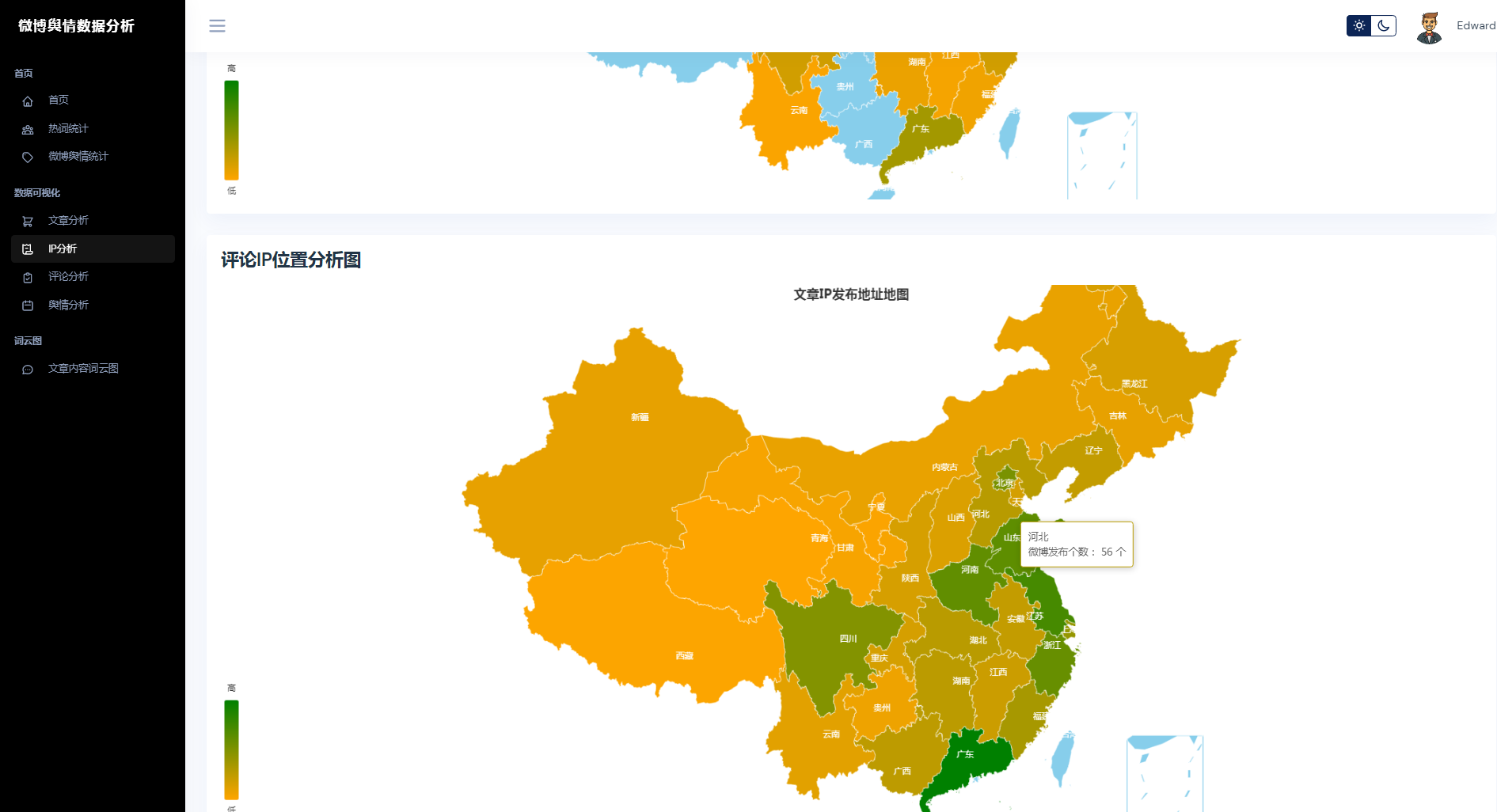
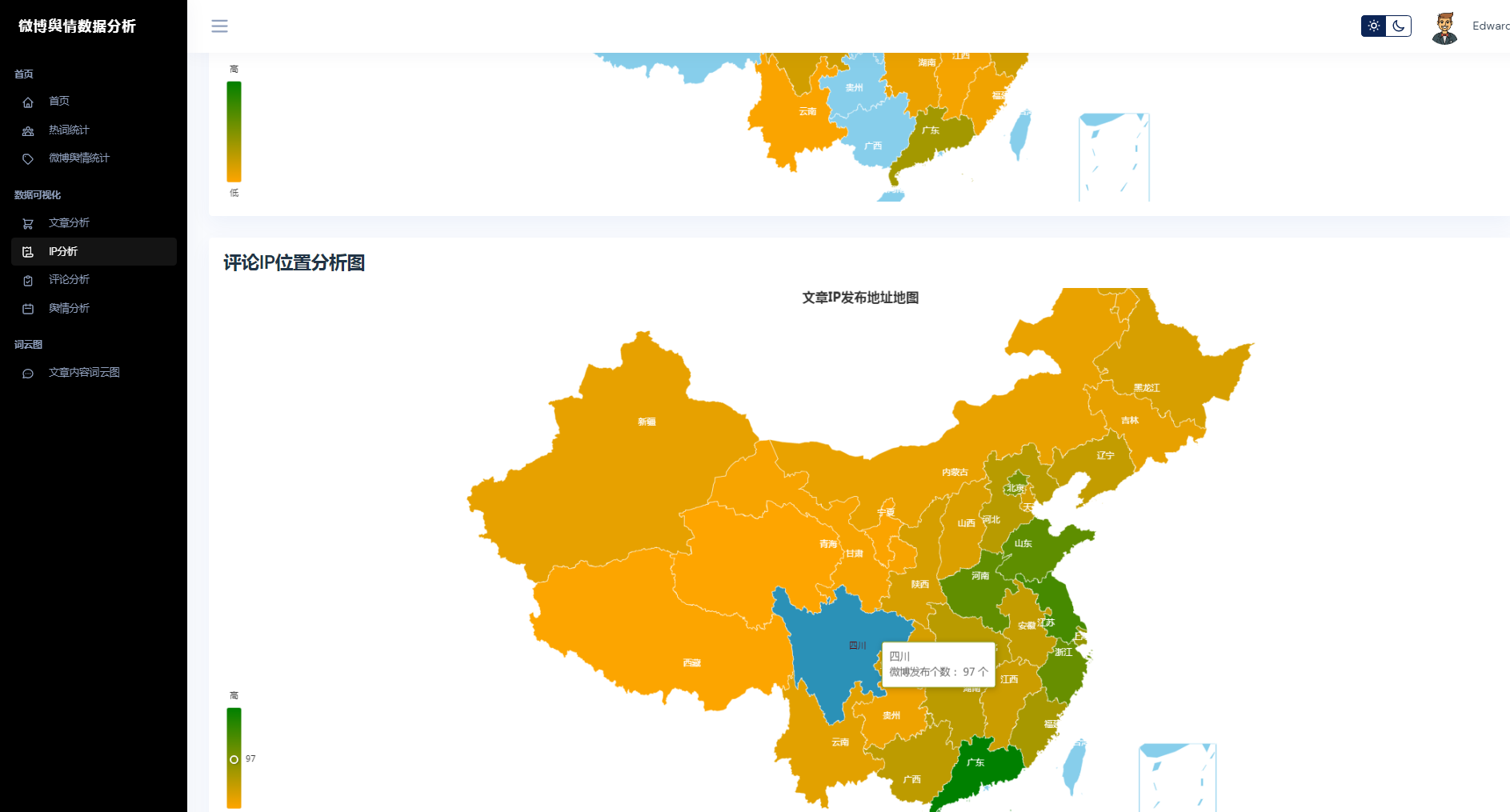
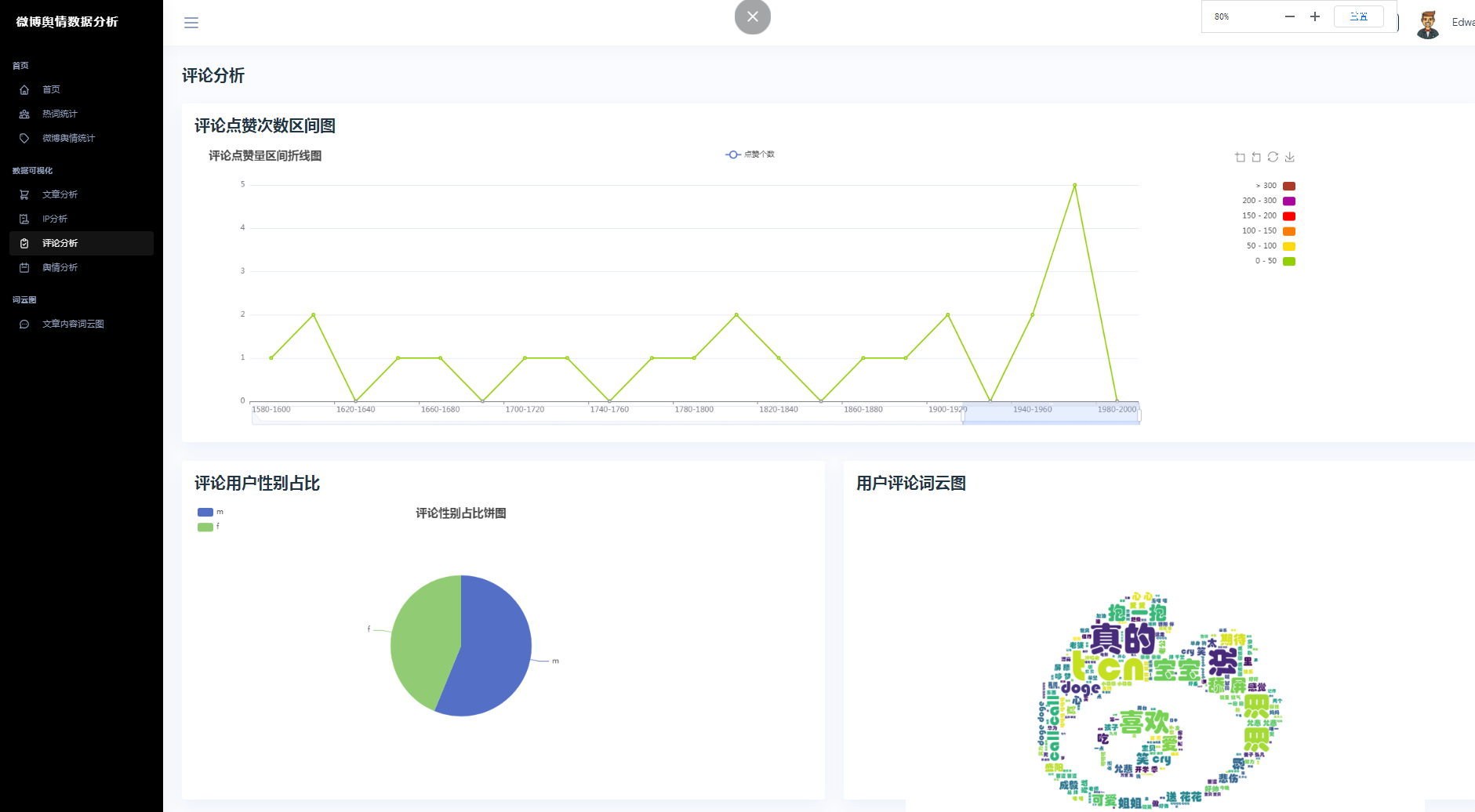
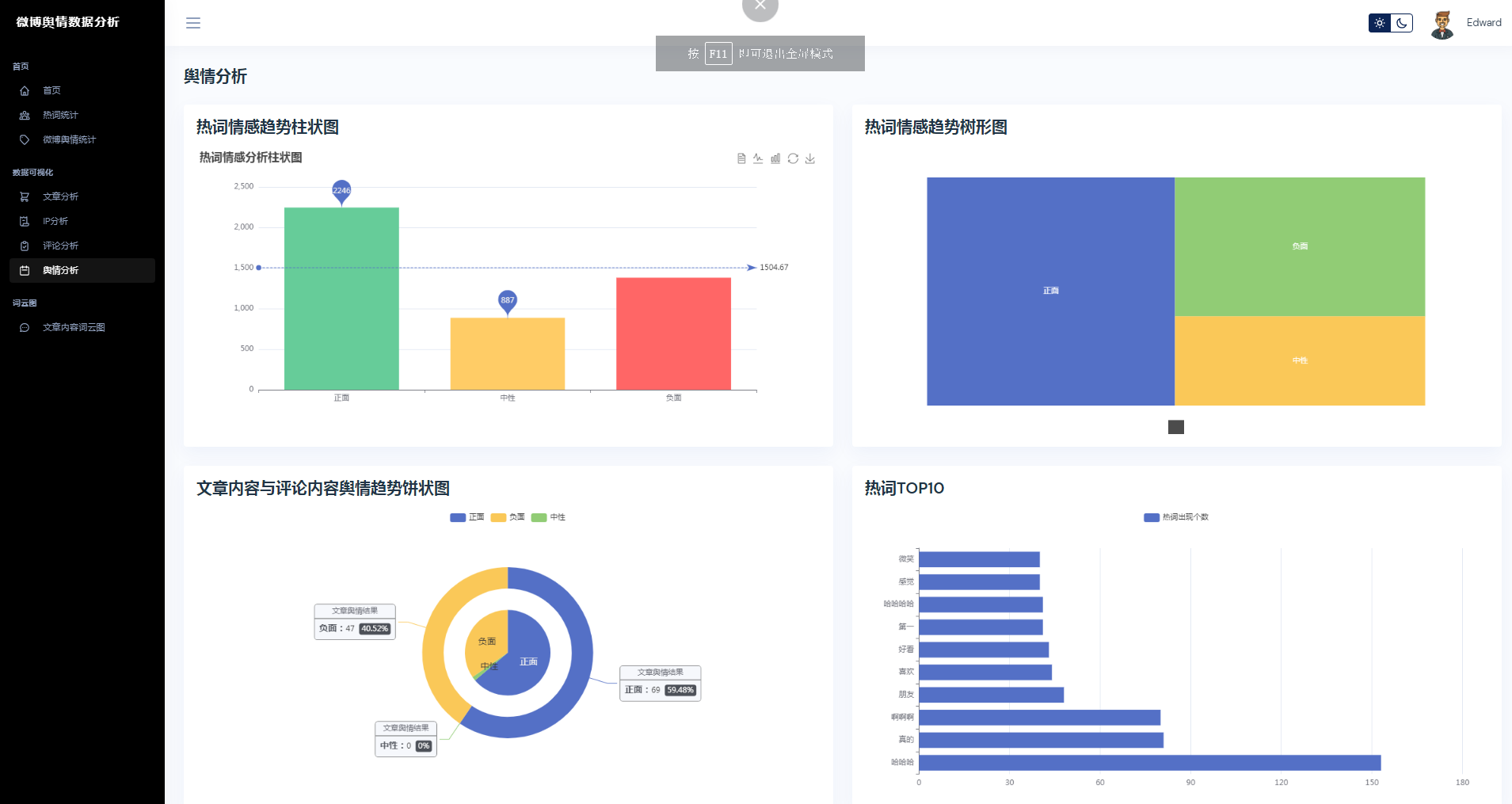
③微博数据分析可视化,文章分析、IP分析、评论分析、舆情分析
④文章内容词云图
黄河科技学院毕业设计开题报告表
|
课题名称 |
基于Bert模型对微博的言论情感分析设计与实现 | ||||
|
课题来源 |
课题类型 |
BY |
指导教师 | ||
|
学生姓名 |
专 业 |
计算机科学与技术 |
学 号 | ||
|
开题报告内容:(调研资料的准备,设计/论文的目的、要求、思路与预期成果;任务完成的阶段内容及时间安排;完成设计所具备的条件因素等。) 一、选题背景 互联网技术的高速发展和人们在社交媒体上的活跃群体数量日益增加,人们已经习惯于采用社交媒体平台来创建各种话题进行讨论,最终形成海量的数据。其中,以新浪微博为主的社交媒体平台每天都产生大量的文本信息,用户在平台上的大量交互,使得部分文本中蕴含的观点在互联网上广泛传播。一些负面的,甚至是有害的信息若长期存在于网络且被广泛传播,这对网络空间生态的影响不言而喻,因此需要进行文本情感分类分析。当前,情感分析的研究主要是微博文本[1]、外卖评论[2]、中文新闻文本[3]等方面,情感分析对于深入探究社会问题,提高社会满意度方面也具有重要意义。本研究利用BERT自注意力的优点,将BERT当作embedding接入到CNN模型,进行微博文本情感分类,并在同一个数据集进行训练和验证,最后将各个模型的指标进行比较。 二、设计目的和要求 设计目的:
设计要求:
三、设计内容和思路 设计内容:
设计思路:
四、预期成果 (1)编写系统源代码; (2)毕业设计说明书。 五、设计时间安排 第1周:查阅相关资料,完成文献综述。 第2周:结合课题要求,提交开题报告,并完成开题答辩。 第3~5周:进行系统分析、总体设计和详细设计。 第6~9周:实现系统编码、调试及软件测试;撰写毕业设计。 第10~12周:修改毕业设计至定稿,资格审查。 第13~14周:毕业设计答辩及资料归档。 六、完成设计所需要的条件 (1)软硬件环境:硬件环境有win10笔记本电脑配置有16G内存、256G固态硬盘(用于存储、计算、开发);软件环境有Python、JDK1.8、Hadoop、Spark、Hive、Maven、nodejs等。 (2)数据库:MySQL数据库 (3)开发环境与工具:Vmvare、IDEA、Pycharm、Navicat 七、参考文献 [1] 融合知识图谱与Bert+CNN的图书文本分类研究[J]. 孔令蓉;迟呈英;战学刚.电脑编程技巧与维护,2023(01) [2] 基于CNN与Bi-LSTM混合模型的中文文本分类方法[J]. 王佳慧.软件导刊,2023(01) [3] 基于BERT-CNN的新闻文本分类的知识蒸馏方法研究[M]. 叶榕;邵剑飞;张小为;邵建龙.电子技术应用,2023(01) [4] 基于BERT变种模型的情感分析实现[J]. 毛银;赵俊.现代计算机,2022(18) [5] 基于文本分词朴素贝叶斯分类的图书采访机制探索[J]. 王红;王雅琴;黄建国.现代情报,2021(09) [6] 基于改进的BERT-CNN模型的新闻文本分类研究[J]. 张小为;邵剑飞.电视技术,2021(07) [1] 融合知识图谱与Bert+CNN的图书文本分类研究[J]. 孔令蓉;迟呈英;战学刚.电脑编程技巧与维护,2023(01) [2] 基于CNN与Bi-LSTM混合模型的中文文本分类方法[J]. 王佳慧.软件导刊,2023(01) [3] 基于BERT-CNN的新闻文本分类的知识蒸馏方法研究[M]. 叶榕;邵剑飞;张小为;邵建龙.电子技术应用,2023(01) [4] 基于BERT变种模型的情感分析实现[J]. 毛银;赵俊.现代计算机,2022(18) [5] 基于文本分词朴素贝叶斯分类的图书采访机制探索[J]. 王红;王雅琴;黄建国.现代情报,2021(09) [6] 基于改进的BERT-CNN模型的新闻文本分类研究[J]. 张小为;邵剑飞.电视技术,2021(07) [7] 基于BERT模型的文本情感分类研究[D]. 王杭涛.桂林电子科技大学,2022 [8] 面向文本分类的BERT-CNN模型[M]. 秦全;易军凯.北京信息科技大学学报(自然科学版),2023 [9] 基于BERT-CNN中间任务转移模型的短文本讽刺文本分类研究[J]. 周海波;李天.智能计算机与应用,2023 [10] 基于BERT-BiLSTM-CRF的SPECT诊断文本病灶提取研究[J]. 张淋均.信息与电脑(理论版),2021 [11] 基于BERT模型的文本评论情感分析[J]. 杨杰;杨文军.天津理工大学学报,2021 [12] 一种基于BERT的文本实体链接方法[J]. 谢世超;黄蔚;任祥辉.计算机与现代化,2023 [13] 结合Bert与超图卷积网络的文本分类模型[J]. 李全鑫;庞俊;朱峰冉.计算机工程与应用,2023 [14] 分层文本分类在警情数据中的应用[J]. 殷小科;王威;王婕;张沛然;乐汉;林基伟;张海婷.现代计算机,2021 [15] 基于BERT的金融文本情感分析模型[M]. 朱鹤;陆小锋;薛雷.上海大学学报(自然科学版),2023 [16] 基于文本双表示模型的微博热点话题发现[J]. 刘梦颖;王勇.计算机与现代化,2021 [17] 基于BERT的文本情感分析[J]. 刘思琴;冯胥睿瑞.信息安全研究,2020 指导教师签名: 指导教师手签 2023.1.6-1.13(定稿时删除该说明) 年 月 日 | |||||
课题来源:(1)教师拟订;(2)学生建议;(3)企业和社会征集;(4)科研单位提供
课题类型:(1)A—工程设计(艺术设计);B—技术开发;C—软件工程;D—理论研究;E—调研报告
(2)X—真实课题;Y—模拟课题;Z—虚拟课题
要求(1)、(2)均要填,如AY、BX等。



核心算法代码分享如下:
from utils.getPublicData import getAllCommentsData
import jieba
import jieba.analyse as analyse
targetTxt = 'cutComments.txt'
# stopWords 停用词
def stopWordList():
stopWords = [line.strip() for line in open('./stopWords.txt',encoding='utf8').readlines()]
return stopWords
def seg_depart(sentence):
sentence_depart = jieba.cut(" ".join([x[4] for x in sentence]).strip())
print(sentence_depart)
stopWords = stopWordList()
outStr = ''
for word in sentence_depart:
if word not in stopWords:
if word != '\t':
outStr += word
return outStr
def writer_comments_cuts():
with open(targetTxt,'a+',encoding='utf-8') as targetFile:
seg = jieba.cut(seg_depart(getAllCommentsData()),cut_all=True)
output = ' '.join(seg)
targetFile.write(output)
targetFile.write('\n')
print('写入成功')
if __name__ == '__main__':
# print(stopWordList())
writer_comments_cuts()


















 3975
3975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











