




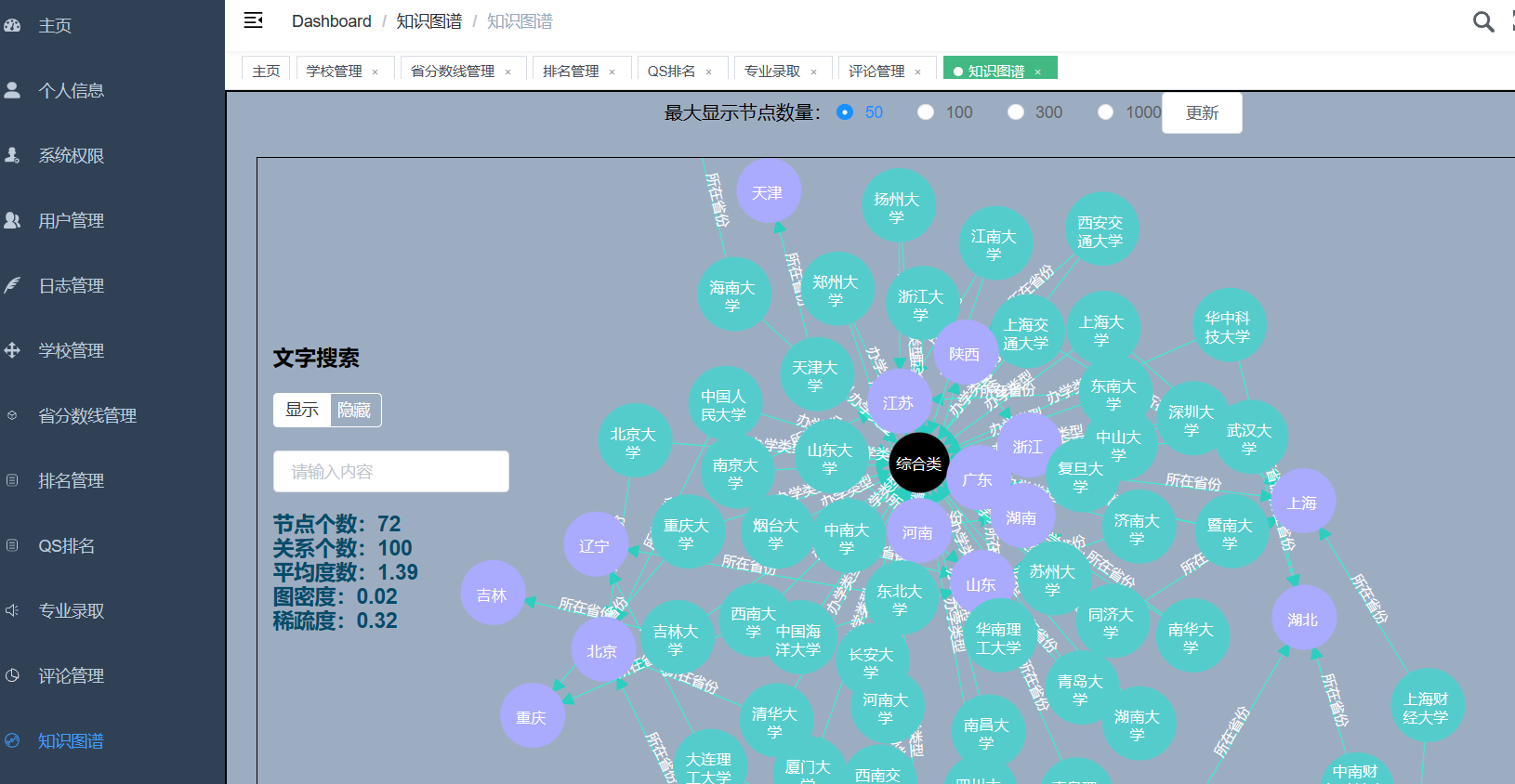
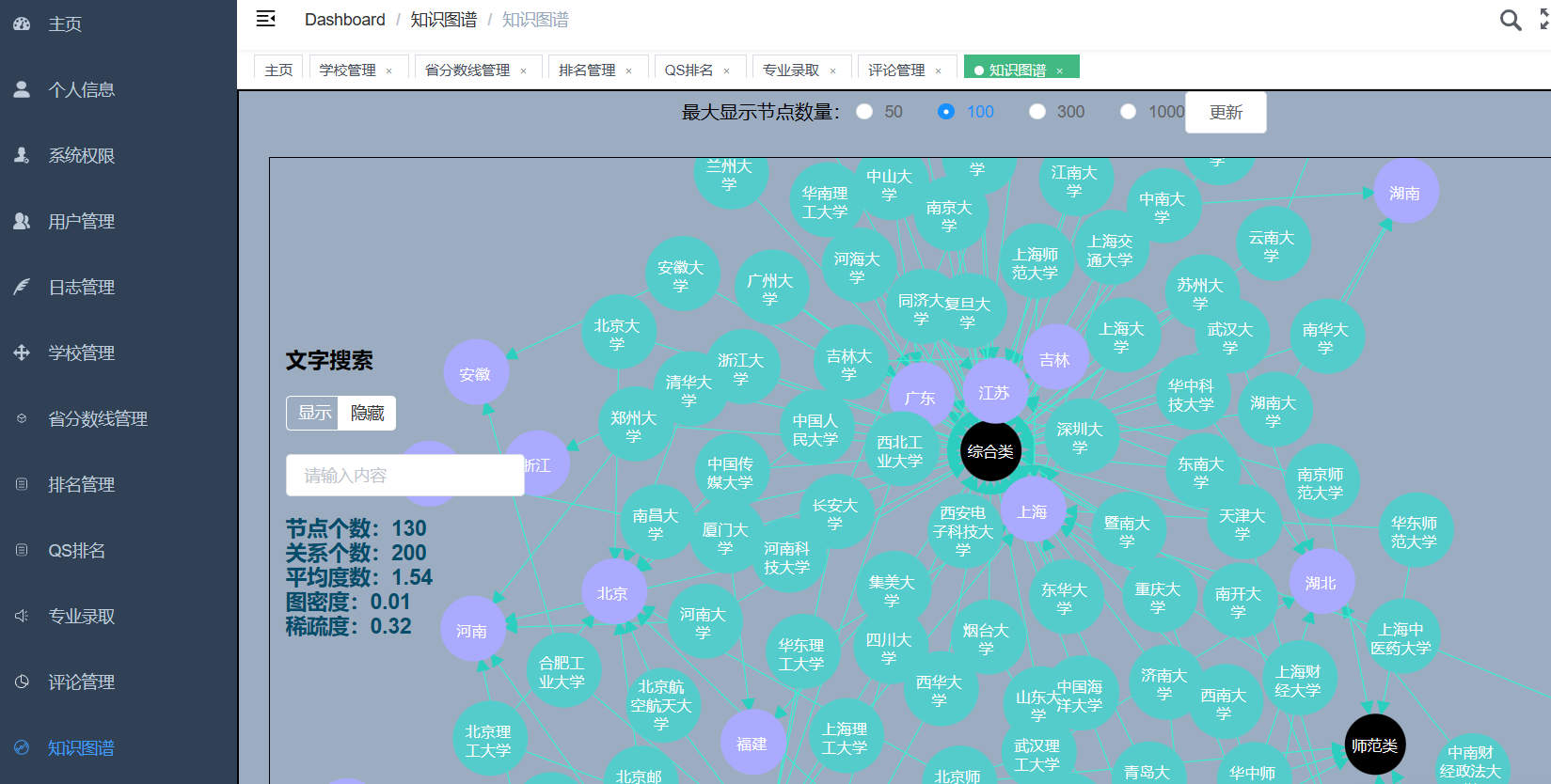
流程:爬取阳光高考约50-100W历年高考数据(含2023年)存入mysql;使用dump命令将省控线、专业线、专业、学校、省份、软科排名、QS排名等表导出csv存到hdfs上;使用hive基于CSV文件建立数据仓库;一部分数据使用Spark进行实时分析,一部分数据使用Hive进行离线分析;分析结果使用sqoop导入mysql;使用flask+echarts进行可视化大屏实现。
开发技术:spark hadoop hive sqoop echarts flask requests爬虫技术 mysql
为啥不直接分析mysql中的数据?海量上百万的数据加上连表查询的话mysql不如hive数据仓库可靠和稳定,mysql很容易宕机以及响应慢!
创新点:爬虫、大屏、hadoop+hive离线计算+spark实时计算双实现、海量真实数据


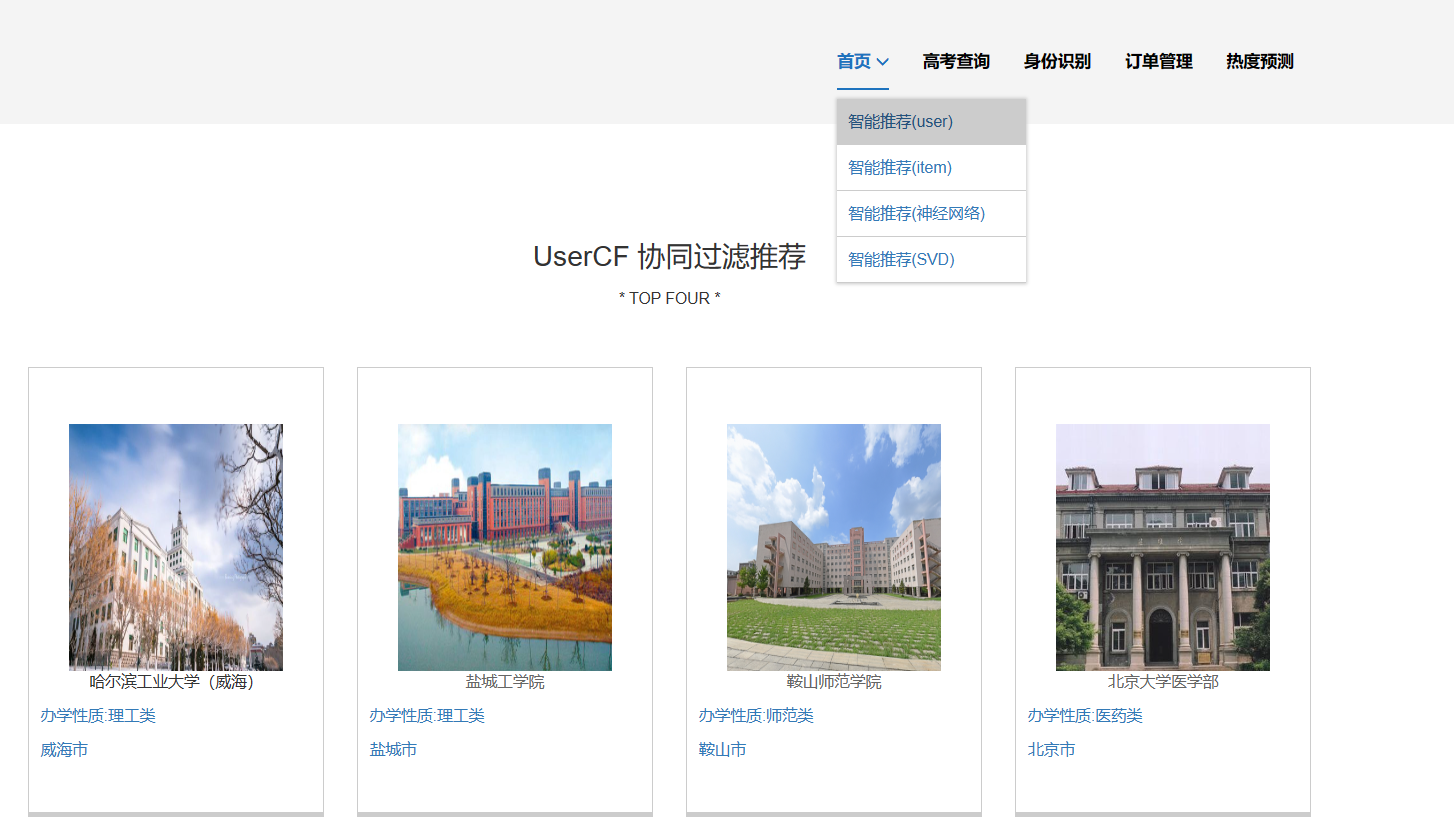
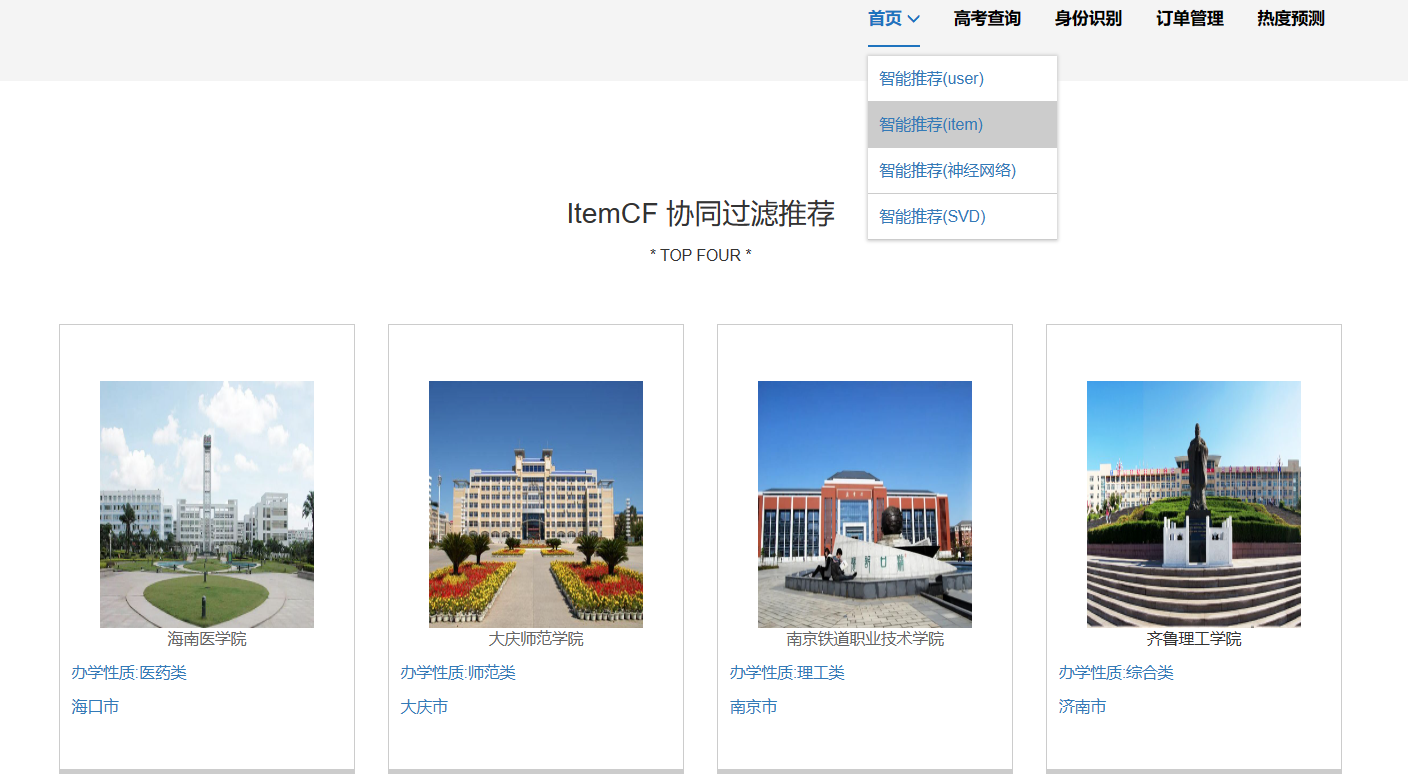
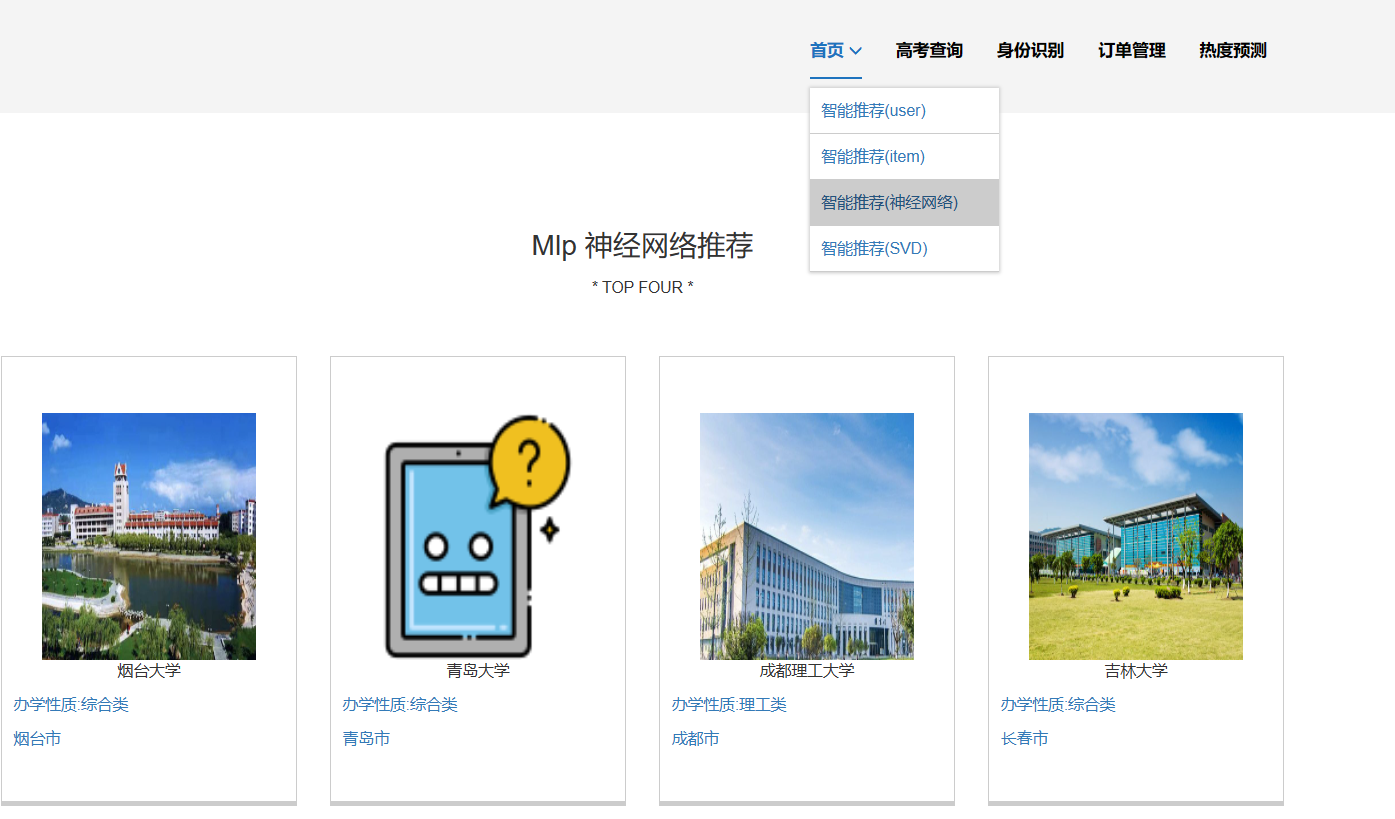
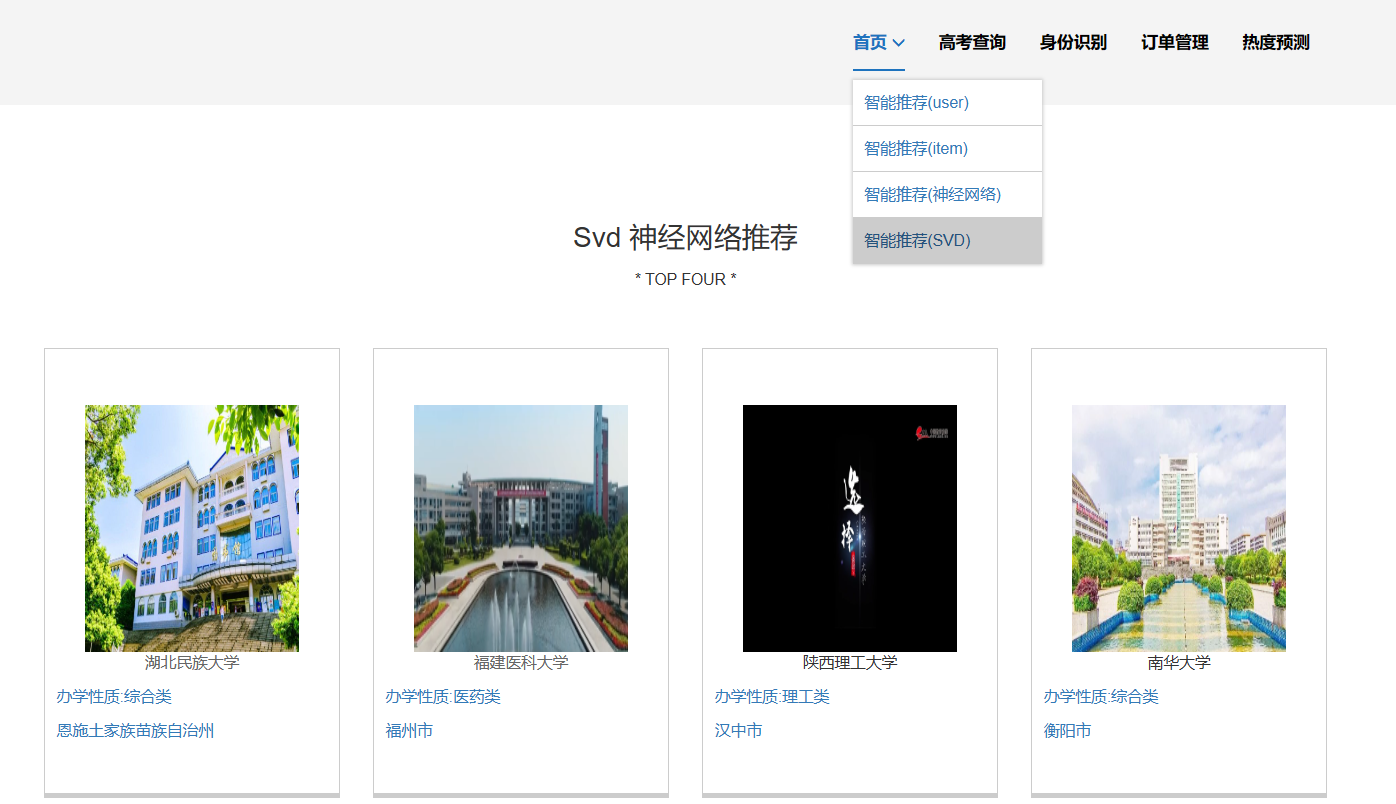
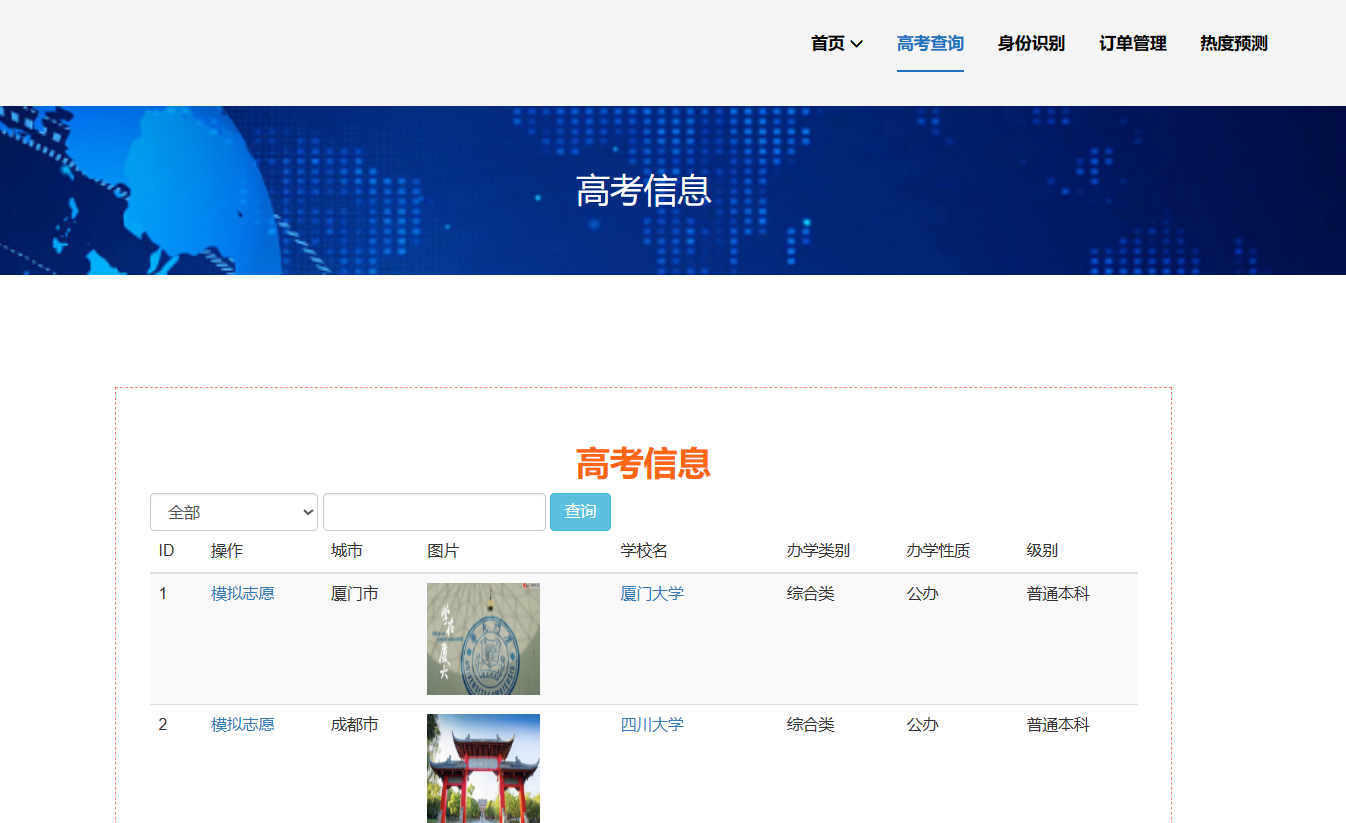
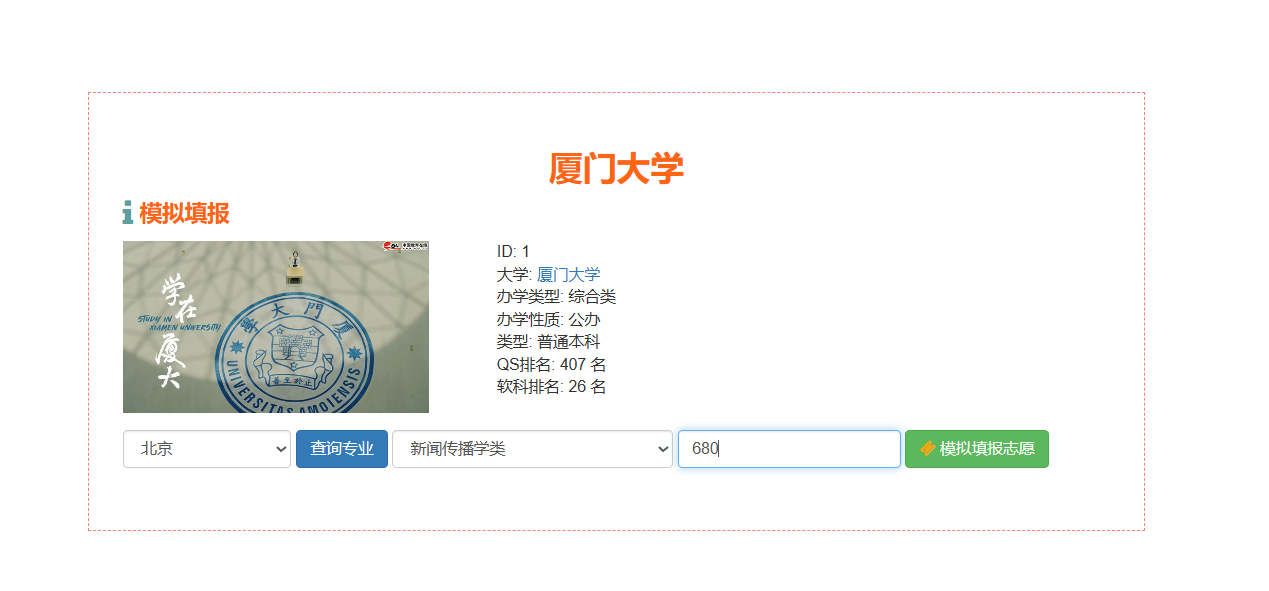

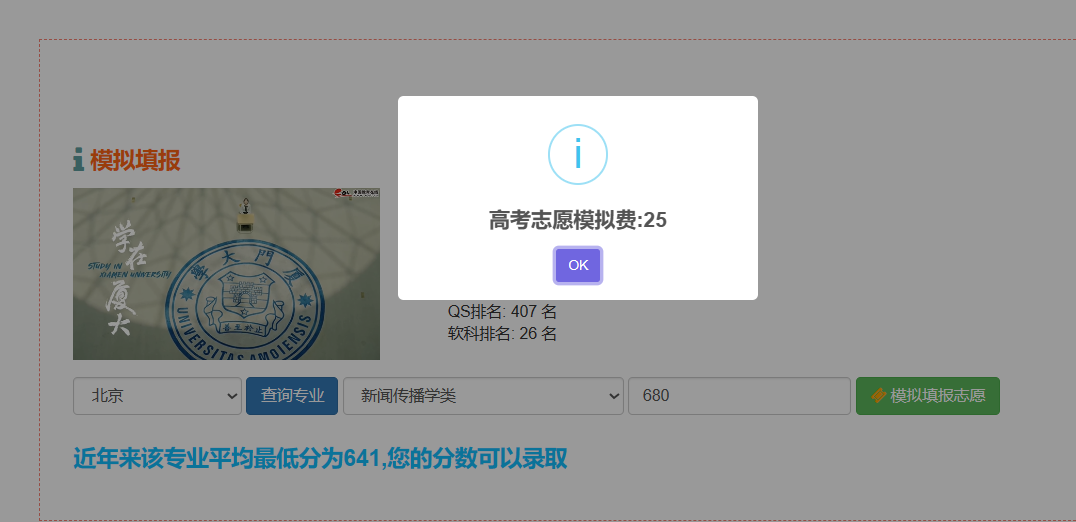

核心算法代码分享如下:
# -*- codeing = utf-8 -*-
# 创建预测所需要的数据用
#
import datetime
import numpy as np
import pandas as pd
import json
from db import db_util
d = db_util()
db, cursor = d.get_conn()
def insert_flow(name, n, v):
sd1 = datetime.date(2023, 1, 1) # 把数字字符变换成日期类型,赋值给一个变量
v1 = v
for i in range(1, n + 1):
# sd1 = sd1 + datetime.timedelta(days=1) # 加某个天数相加之后的日期
sd1 = sd1 + datetime.timedelta(days=30) # 加某个天数相加之后的日期
# print(i)
v1 = v1 + np.random.randint(50, high=100)
sql = "replace into tb_flow(name,name2, v) values('%s', '%s', %f)"\
% (sd1.strftime('%Y%m%d'), name, v1)
cursor.execute(sql)
db.commit()
print("end..")
if __name__ == '__main__':
v = 400
#t = '换成学校名称'
t = '武汉大学'
insert_flow(t, 7, v)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











