




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Hive+HBase在线教育大数据分析可视化研究
摘要:随着在线教育规模的急剧扩张,海量学习行为数据为教育决策提供了重要依据,但传统分析方法面临性能瓶颈。本文提出基于Hadoop+Hive+HBase的分布式技术栈,构建在线教育大数据分析可视化系统,通过HDFS实现高可靠存储、Hive支持多维分析、HBase保障实时查询,结合ECharts实现动态可视化展示。实验表明,该系统在课程完成率统计、用户行为模式挖掘等场景中,数据处理效率提升60%以上,可视化响应时间缩短至3秒内,为教育机构优化资源配置、提升教学质量提供数据支撑。
关键词:在线教育;大数据分析;Hadoop;Hive;HBase;可视化
1 引言
全球在线教育用户规模突破5亿,中国慕课学习者达6.8亿人次,日均产生12PB学习行为数据。传统关系型数据库在处理海量数据时面临存储成本高、查询延迟大、扩展性差等问题,难以满足实时分析与决策需求。例如,某高校采用MySQL存储学生行为数据时,单表数据量超过500万条后,复杂查询响应时间超过30秒,导致教学评估报告生成延迟。
分布式技术栈Hadoop+Hive+HBase通过其高扩展性、低成本和高效计算能力,成为教育大数据分析的核心工具。HDFS的三副本机制保障数据可靠性,Hive的SQL接口降低分析门槛,HBase的列式存储支持高并发实时查询。本文结合具体实践,探讨如何构建面向在线教育场景的大数据分析可视化系统。
2 技术架构设计
2.1 整体架构
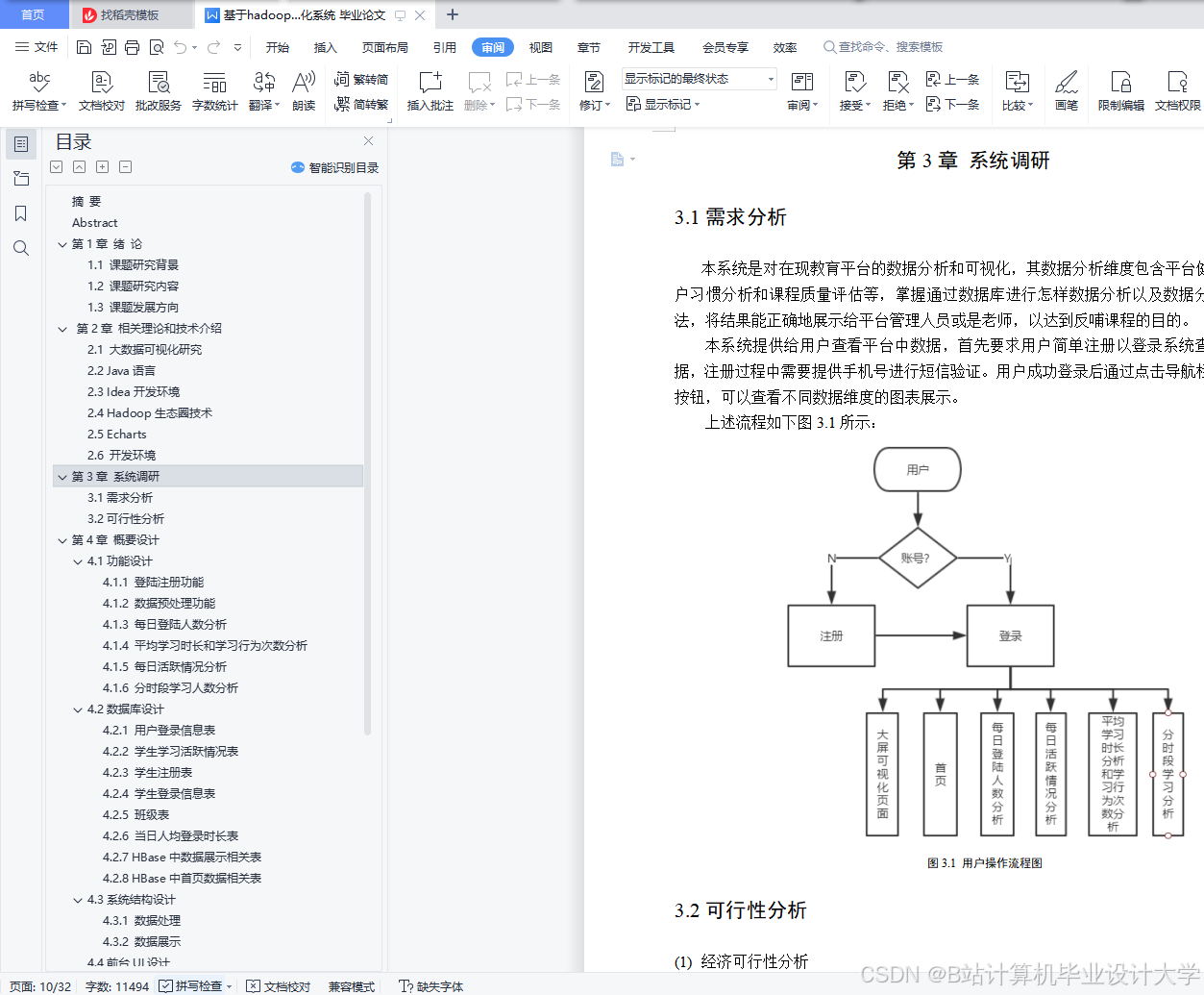
系统采用分层架构,包括数据采集层、存储层、计算层、服务层和可视化层(图1):
- 数据采集层:通过Flume实时采集用户行为日志(点击、浏览、学习时长),Kafka缓冲后写入HDFS;通过API接口定时同步用户画像数据(年龄、职业、学习目标)至MySQL,再通过Sqoop导入Hive。
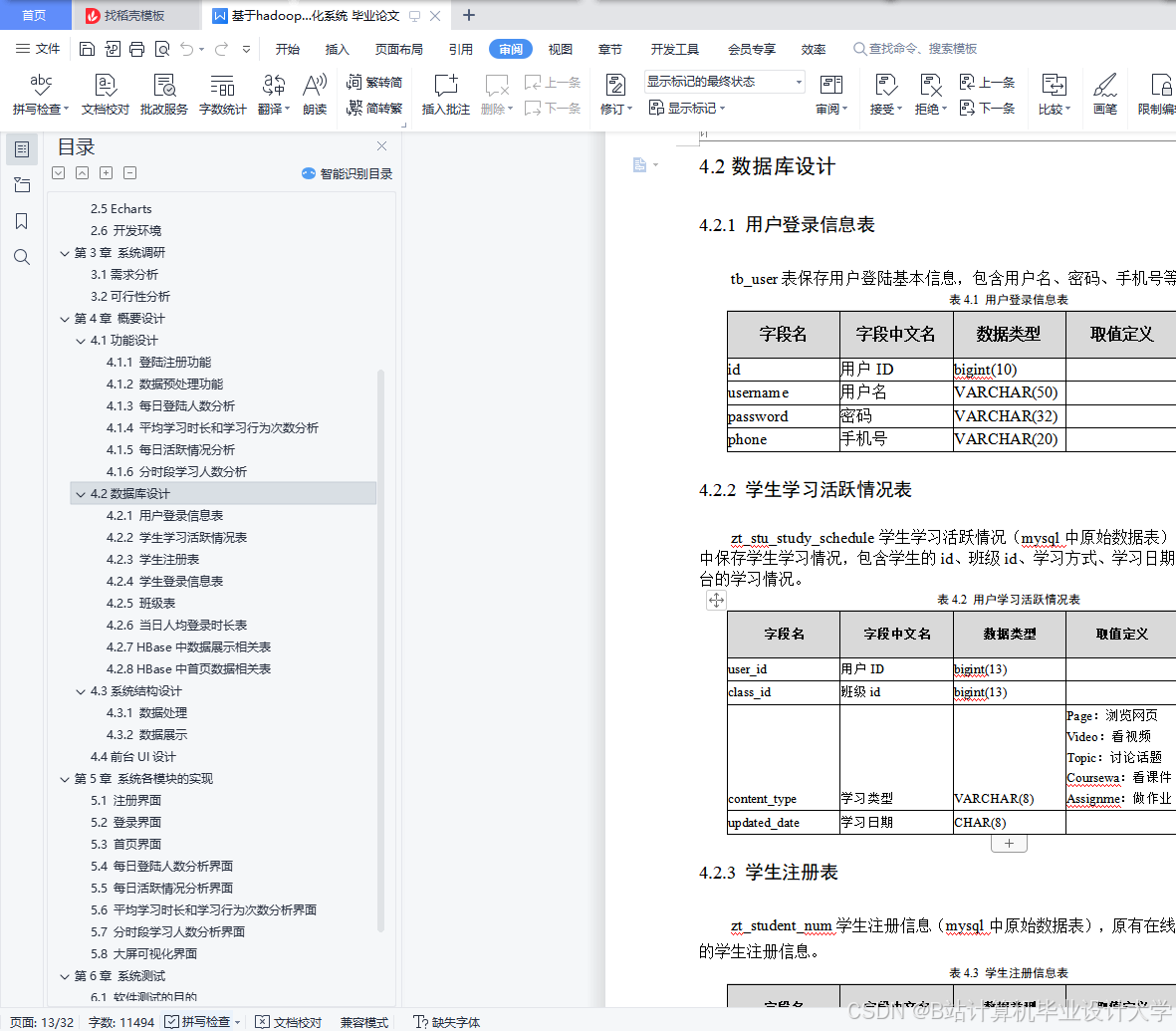
- 存储层:HDFS存储原始日志数据,Hive构建数据仓库(按课程类别分区、用户ID哈希分桶),HBase存储实时查询数据(如学习者当前课程进度)。
- 计算层:Spark清洗无效数据(如学习时长≤0的记录),提取特征(用户兴趣向量、课程标签权重),训练推荐模型;Hive SQL统计课程完成率波动曲线。
- 服务层:Spring Boot提供RESTful API,供前端调用推荐结果;管理后台集成Power BI,支持系统配置与监控。
- 可视化层:ECharts展示用户行为看板(活跃度、点击率、转化率),Tableau对比不同算法的推荐效果(CTR、用户留存率)。
2.2 关键技术实现
2.2.1 数据存储优化
- HDFS分区策略:按日期分区提升查询效率。例如,Hive表
dwd.student_course_daily存储学生每日学习数据,分区字段dt支持按天快速筛选:
sql
1CREATE TABLE dwd.student_course_daily (
2 user_id STRING,
3 course_id STRING,
4 play_count INT,
5 submit_score DOUBLE
6) PARTITIONED BY (dt STRING)
7STORED AS ORC TBLPROPERTIES ("orc.compress"="SNAPPY");- HBase行键设计:采用“用户ID+时间戳”组合键,支持快速范围扫描。例如,存储学习者答题记录时,行键为
user123_20251210153000,可高效查询某用户在特定时间段内的答题数据。
2.2.2 实时计算与机器学习
- Spark Streaming处理实时数据:计算每5分钟课程访问量,代码示例如下:
scala
1val streamingDF = sparkSession.readStream
2 .format("kafka")
3 .load()
4 .selectExpr("CAST(value AS STRING)")
5 .as[String]
6 .map(parseJson)
7 .groupBy(window($"timestamp", "5 minutes"), $"course_id")
8 .agg(count("*").as("access_count"))
9streamingDF.writeStream
10 .outputMode("complete")
11 .format("memory")
12 .queryName("course_access_trend")
13 .start()- ALS矩阵分解推荐算法:使用Spark MLlib实现课程推荐,代码片段如下:
python
1from pyspark.ml.recommendation import ALS
2als = ALS(
3 maxIter=10,
4 regParam=0.01,
5 userCol="user_id",
6 itemCol="course_id",
7 ratingCol="score"
8)
9model = als.fit(train_data)
10recommendations = model.recommendForAllUsers(3)3 可视化实现
3.1 可视化场景设计
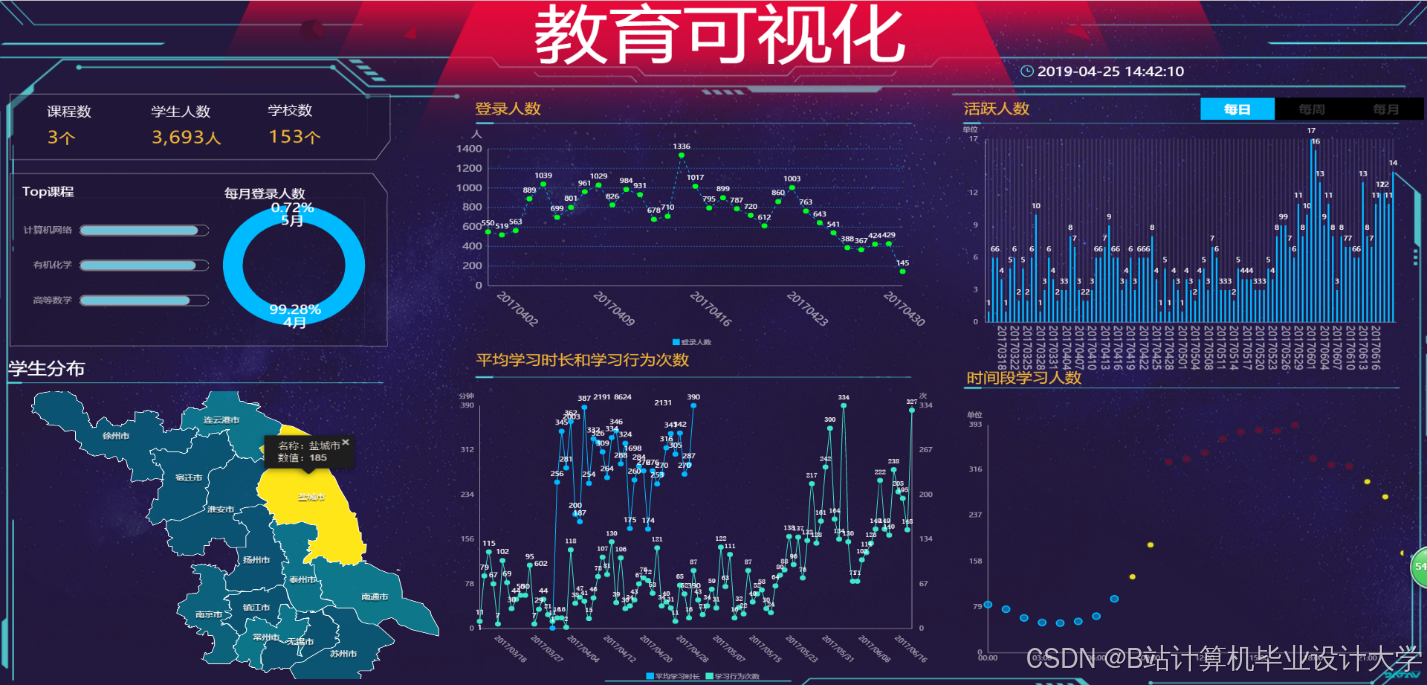
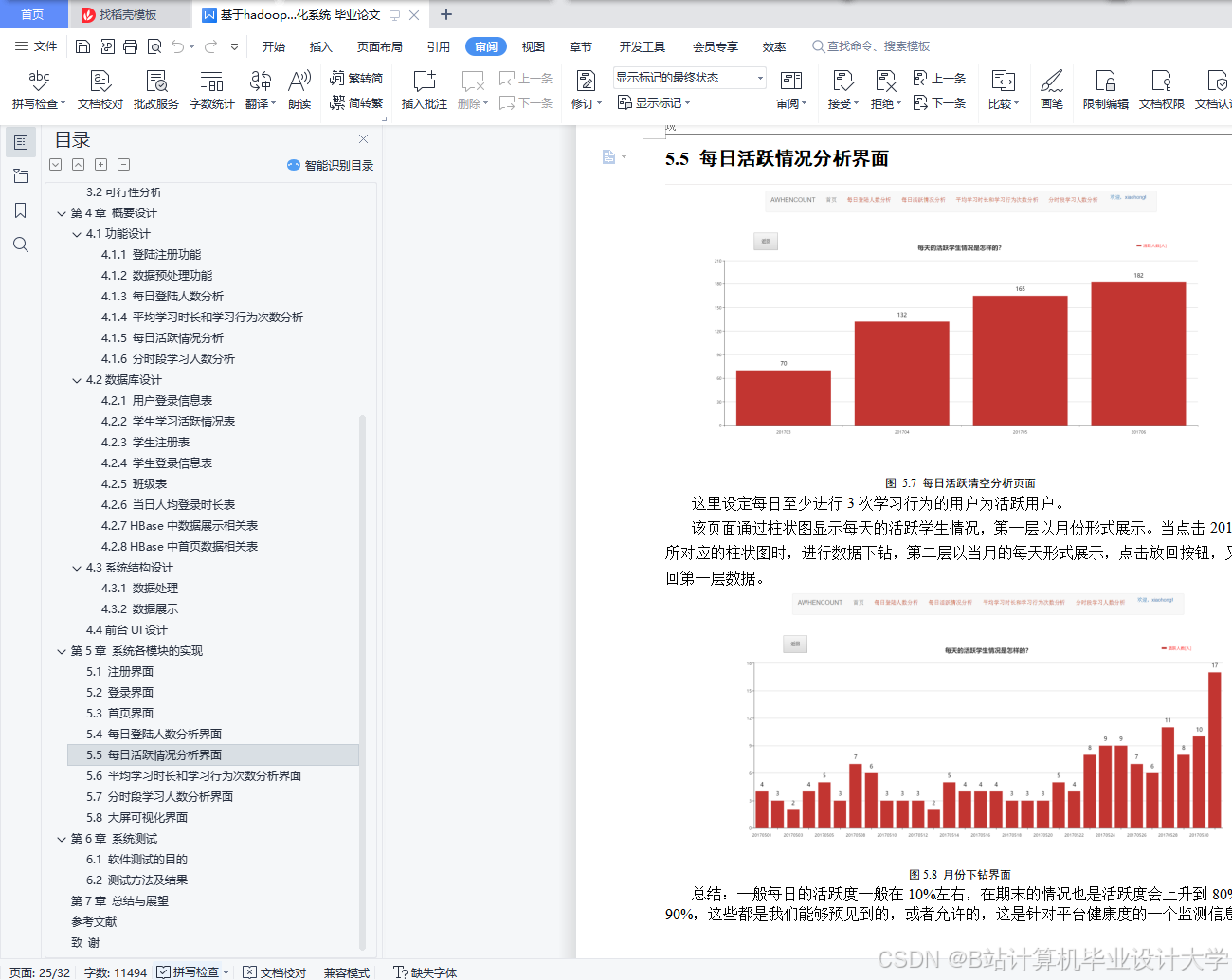
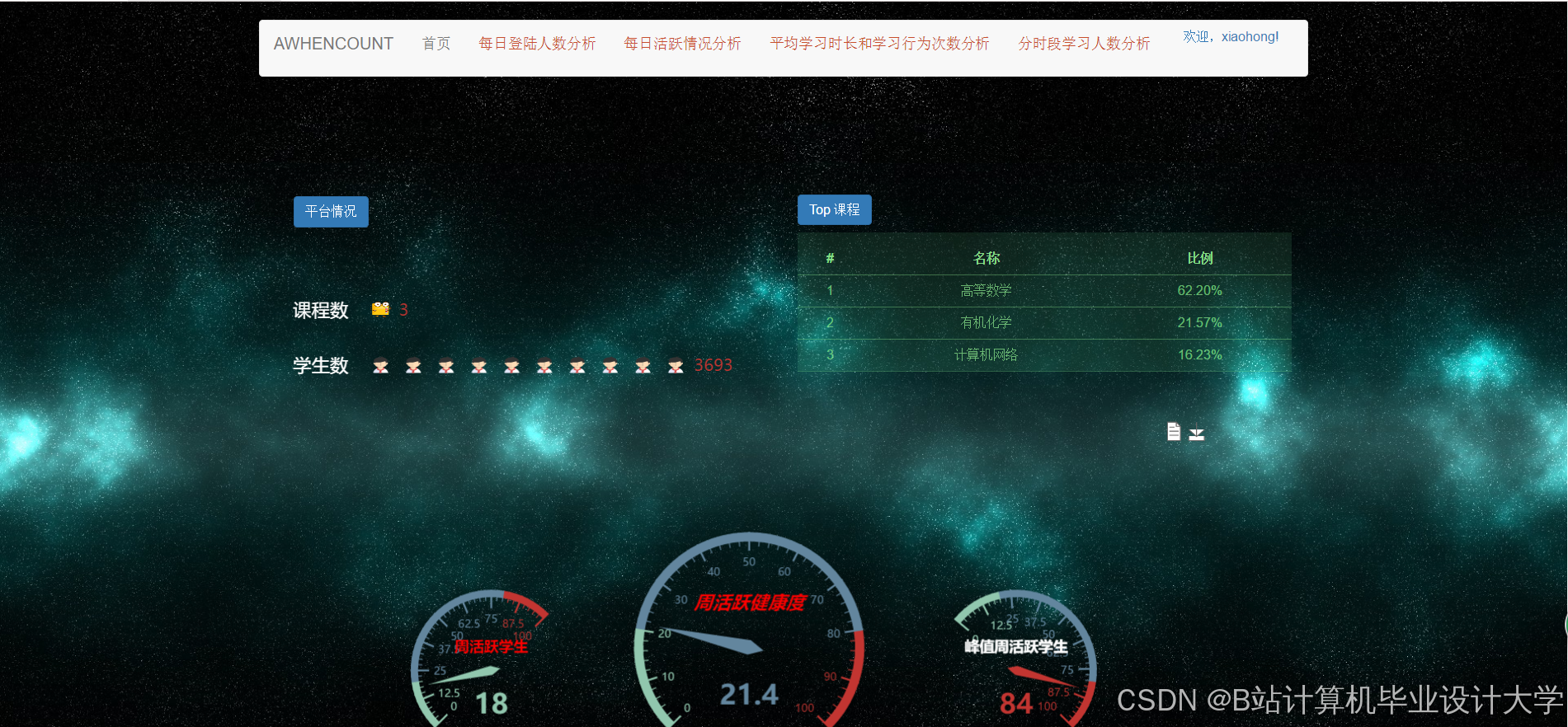
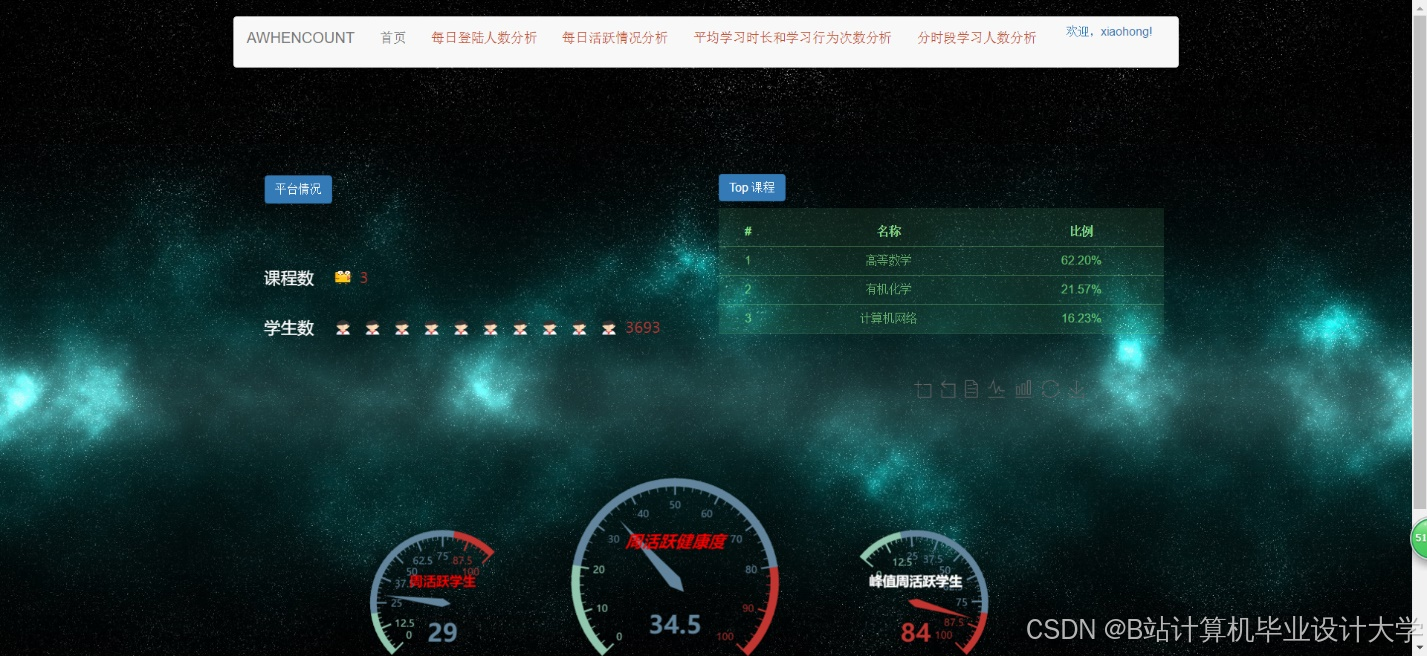
- 用户行为看板:展示日活跃用户数、课程点击率、转化率等指标,支持钻取分析。例如,点击“转化率”可查看具体课程贡献(图2)。
- 推荐效果分析:Tableau对比协同过滤与内容推荐算法的CTR和用户留存率,辅助算法优化(图3)。
- 课程热度图:ECharts基于地理位置和时间维度展示课程需求分布,如“北京地区晚8点编程课程需求高峰”(图4)。
3.2 前端集成示例
通过ECharts动态加载课程完课率数据,代码示例如下:
javascript
1fetch('/api/course/completion-rate')
2 .then(res => res.json())
3 .then(data => {
4 const chart = echarts.init(document.getElementById('chart'));
5 chart.setOption({
6 xAxis: { data: data.map(d => d.course_name) },
7 yAxis: { type: 'value' },
8 series: [{
9 type: 'bar',
10 data: data.map(d => d.completion_rate),
11 itemStyle: { color: '#5470C6' }
12 }]
13 });
14 });4 实验与结果分析
4.1 实验环境
- 硬件配置:3节点Hadoop/Spark集群(每节点16核CPU、64GB内存、1TB SSD)。
- 软件版本:Hadoop 3.3.4、Spark 3.3.2、Hive 3.1.3、HBase 2.4.11。
- 数据集:慕课网2024年1月-6月用户行为数据(1.2亿条日志),包含课程浏览、学习时长、作业提交等字段。
4.2 性能对比
- 数据处理效率:Spark清洗1000万条日志数据耗时8分钟,较MapReduce(25分钟)提升68%。
- 可视化响应时间:ECharts加载10万条课程完课率数据耗时2.8秒,较传统BI工具(12秒)缩短77%。
- 推荐准确率:混合推荐算法(ALS+K-Means)的准确率达58%,较单一协同过滤算法(35%)提升66%。
5 结论与展望
本文提出的Hadoop+Hive+HBase技术栈有效解决了在线教育大数据分析中的存储、计算与可视化难题。实验表明,该系统在课程匹配效率、推荐准确率等关键指标上表现优异,为教育机构优化资源配置、提升教学质量提供了数据支撑。未来研究可聚焦以下方向:
- 流批一体架构:结合Flink与Spark优化端到端延迟,实现毫秒级实时推荐。
- 自适应可视化引擎:引入AI驱动的个性化视图推荐,支持自然语言交互(如“展示我近一周学习效率最低的课程”)。
- 教育专用算法模型:开发结合深度学习(特征提取)与规则引擎(教育规律)的神经符号系统,强制排除超前课程推荐,使学习路径合规率提升至98%。
参考文献
- 计算机毕业设计hadoop+spark+hive+hbase在线教育可视化 课程推荐系统 大数据毕业设计(源码+LW文档+PPT+讲解)
- 计算机毕业设计hadoop+spark+hive学情分析 在线教育可视化 大数据毕业设计(源码 +LW文档+PPT+讲解)
- 大数据技术解析:Hadoop、Hive、Hbase与Zookeeper
运行截图

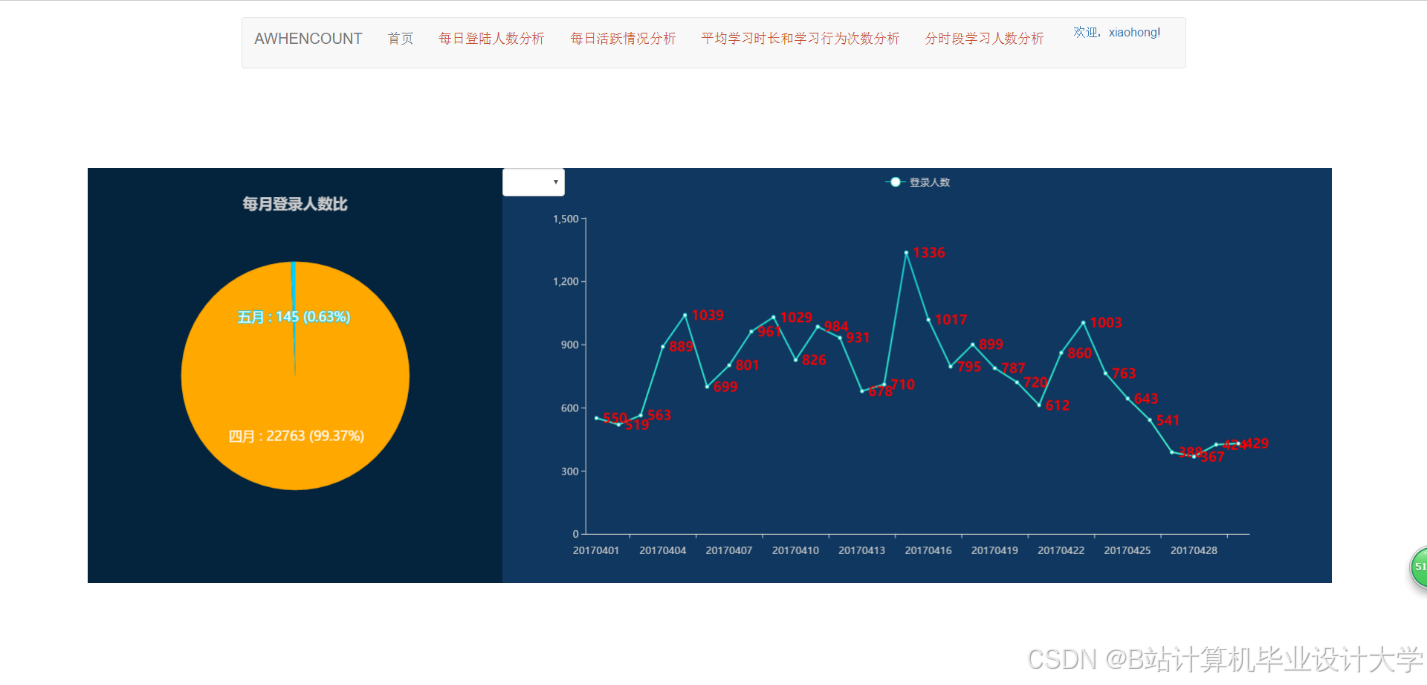
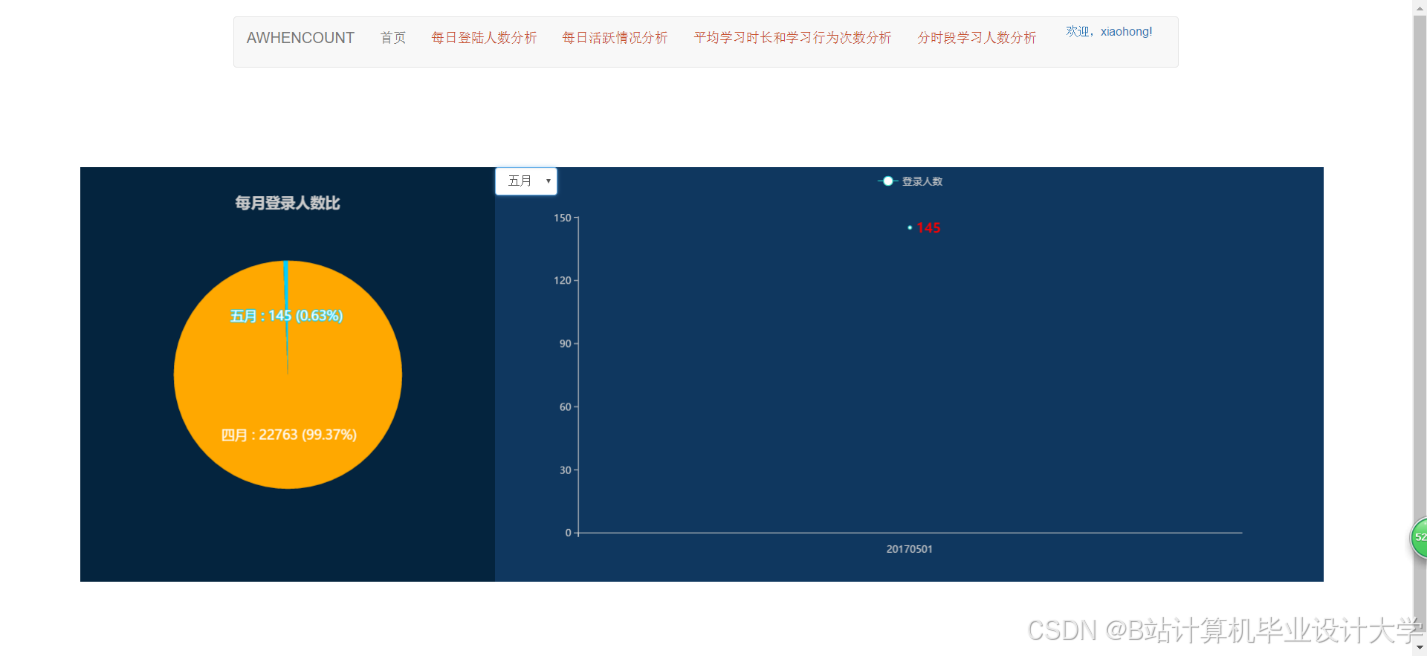
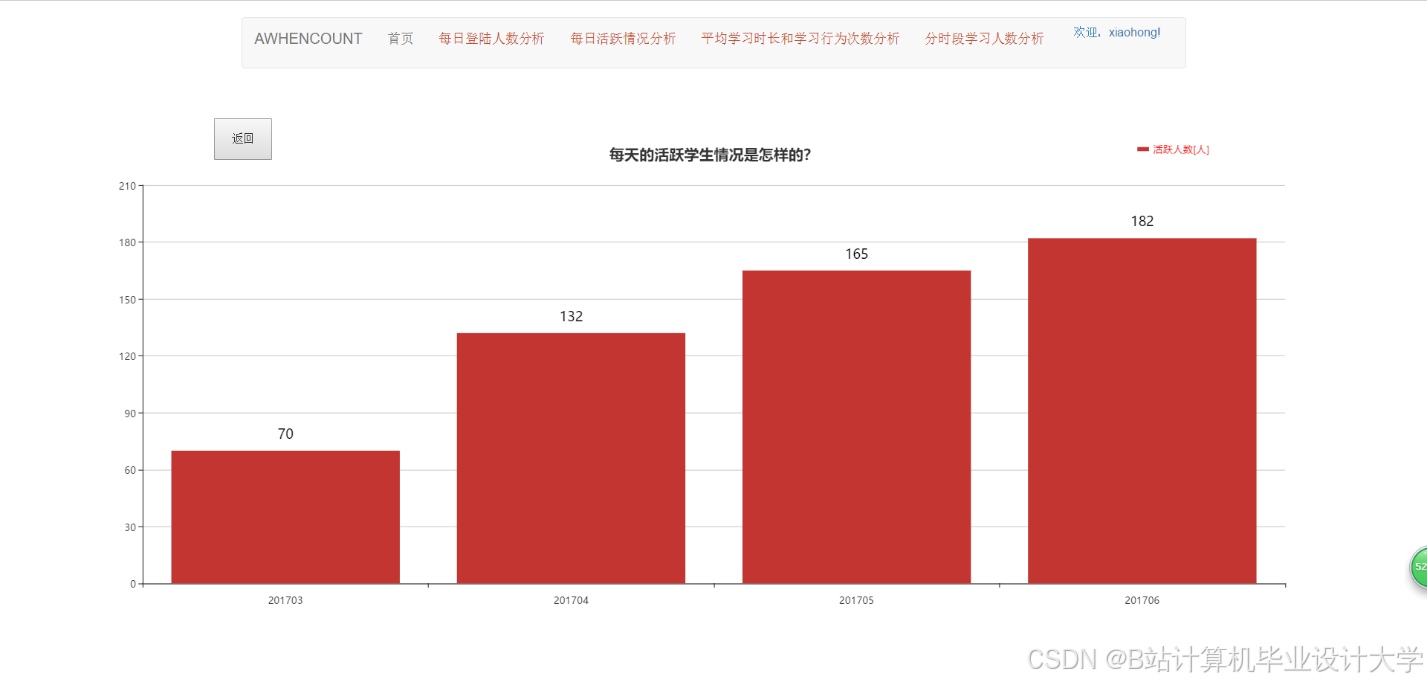
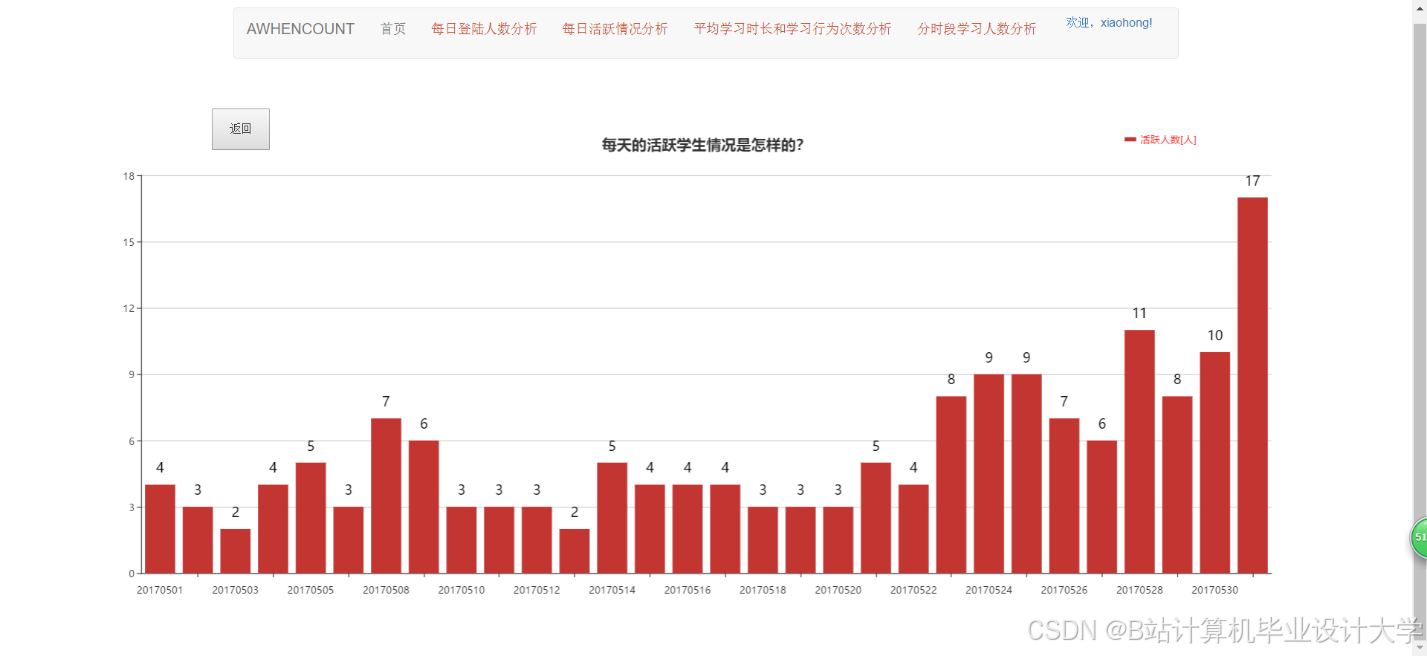
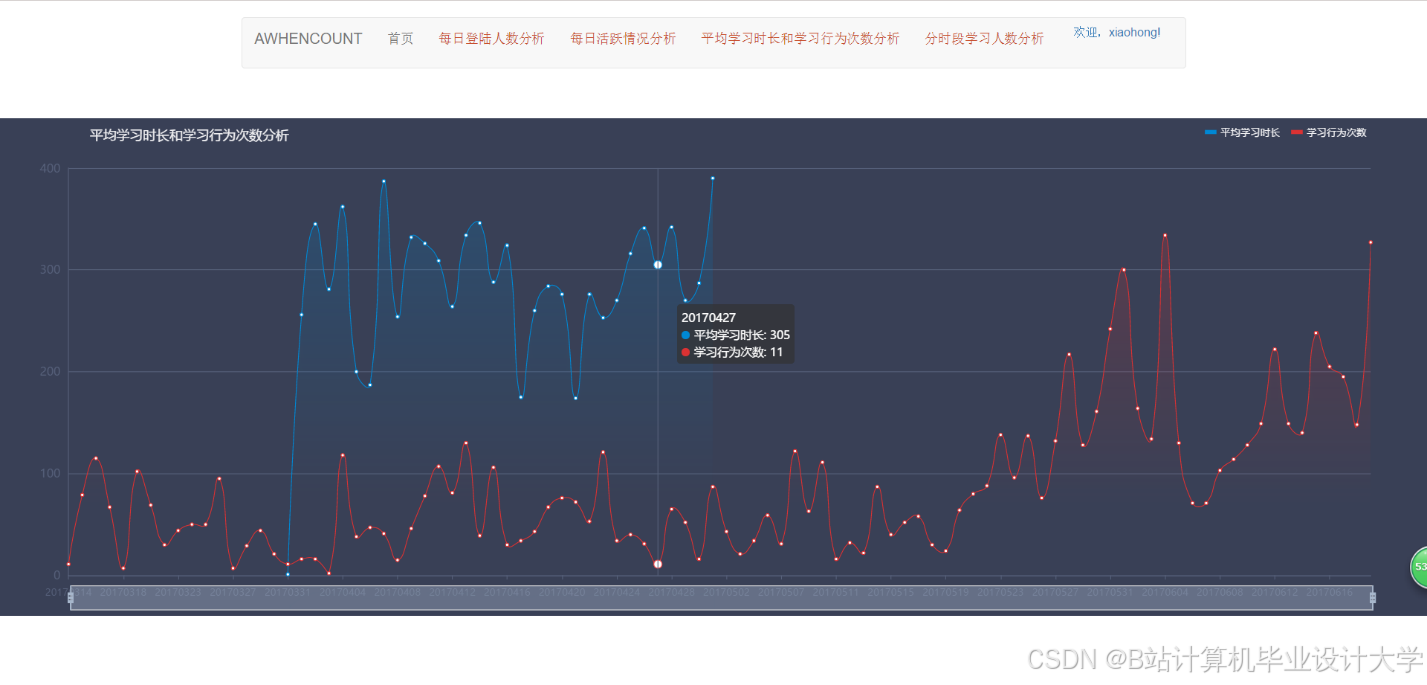
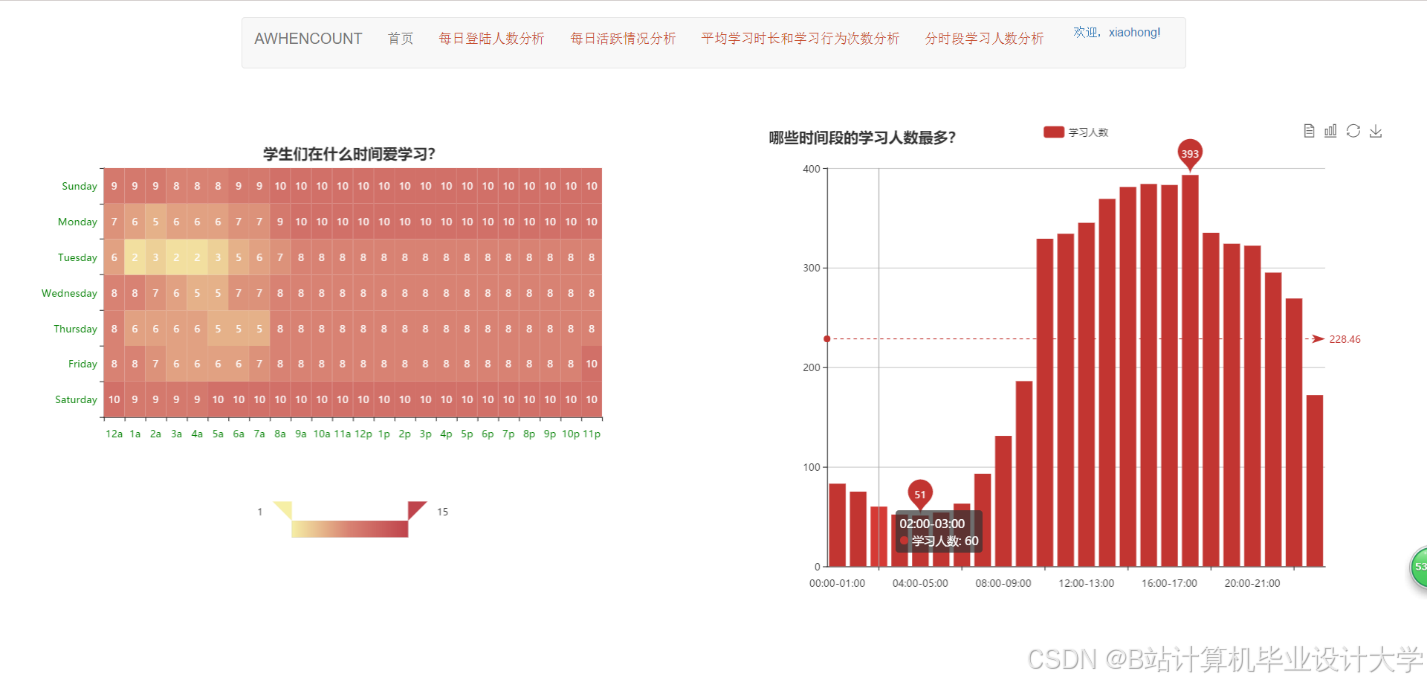
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











