




| 姓 名 | 班级 | 学号 | |||
| 题 目 | 基于hadoop+spark的动漫视频推荐系统 | ||||
| 选题的意义: 随着互联网的快速发展,人们面临着海量的视频内容,如何从这些繁杂的视频中找到自己感兴趣的内容成为一个重要的问题。推荐系统作为一种解决信息过载问题的重要工具,能够根据用户的历史行为和偏好,预测用户可能感兴趣的内容,并对其进行推荐。在视频推荐领域,基于Hadoop和Spark的大数据框架的应用越来越广泛,它们能够处理大规模的视频数据,并对其进行深入的分析和挖掘。 本文旨在研究并设计一个基于Hadoop+Spark的视频推荐系统,该系统能够有效地利用大数据技术,对海量的视频数据进行处理和分析,并根据用户的行为和偏好进行视频推荐。与传统的推荐系统相比,基于Hadoop+Spark的视频推荐系统具有更高的处理能力和准确性,能够提供更加个性化的视频推荐服务。 | |||||
| 研究综述: 在基于Hadoop和Spark的视频推荐系统方面,一些国内外的研究机构和企业在大数据处理和分析方面进行了深入研究,并取得了一定的成果。例如,国外的Netflix利用Hadoop和Spark构建了一个大规模的推荐系统,能够处理海量的用户行为数据和视频数据,并为其用户推荐相关的视频内容。在国内,一些企业如阿里巴巴、腾讯等也在大数据处理和分析方面进行了深入研究,并推出了一些基于Hadoop和Spark的大数据产品和服务。 综上所述,推荐系统在国内外得到了广泛应用,不仅在视频领域,还在其他领域得到应用。在基于Hadoop和Spark的视频推荐系统方面,一些国内外的研究机构和企业已经取得了一定的成果,但是随着大数据技术的不断发展,还需要进一步研究和探索更加准确、高效的视频推荐算法和系统。 | |||||
| 论文(设计)写作提纲:
| |||||
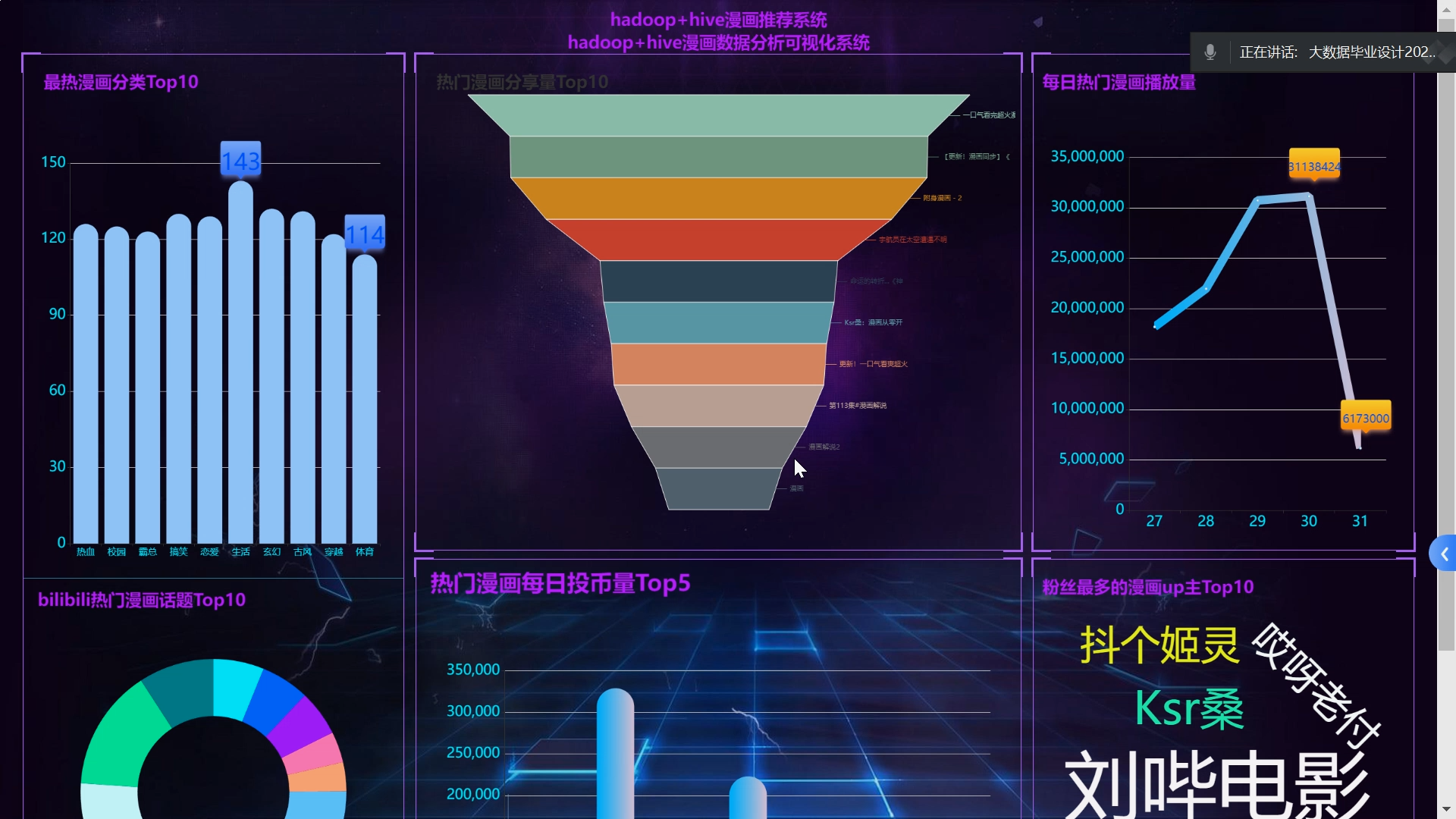






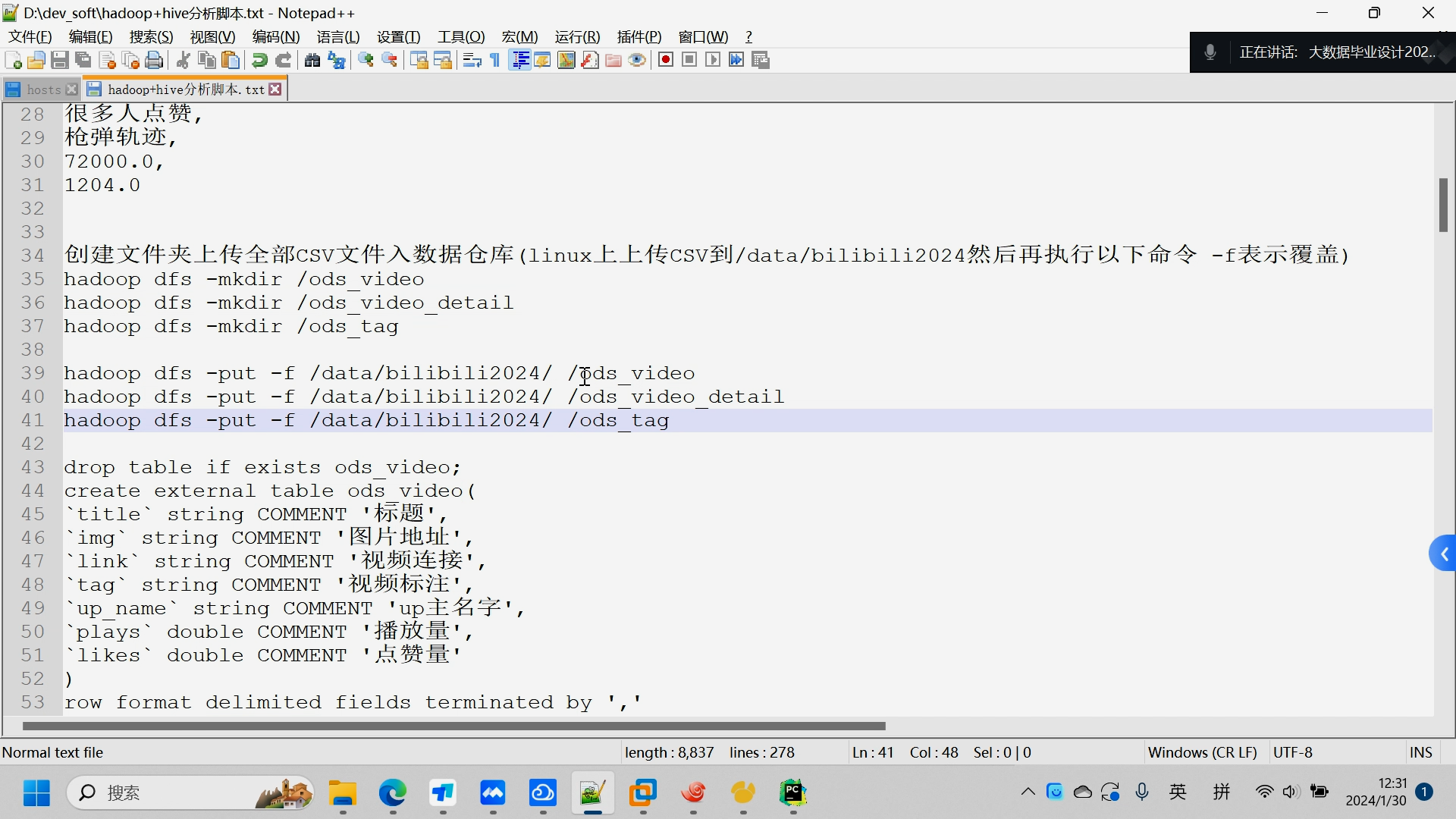
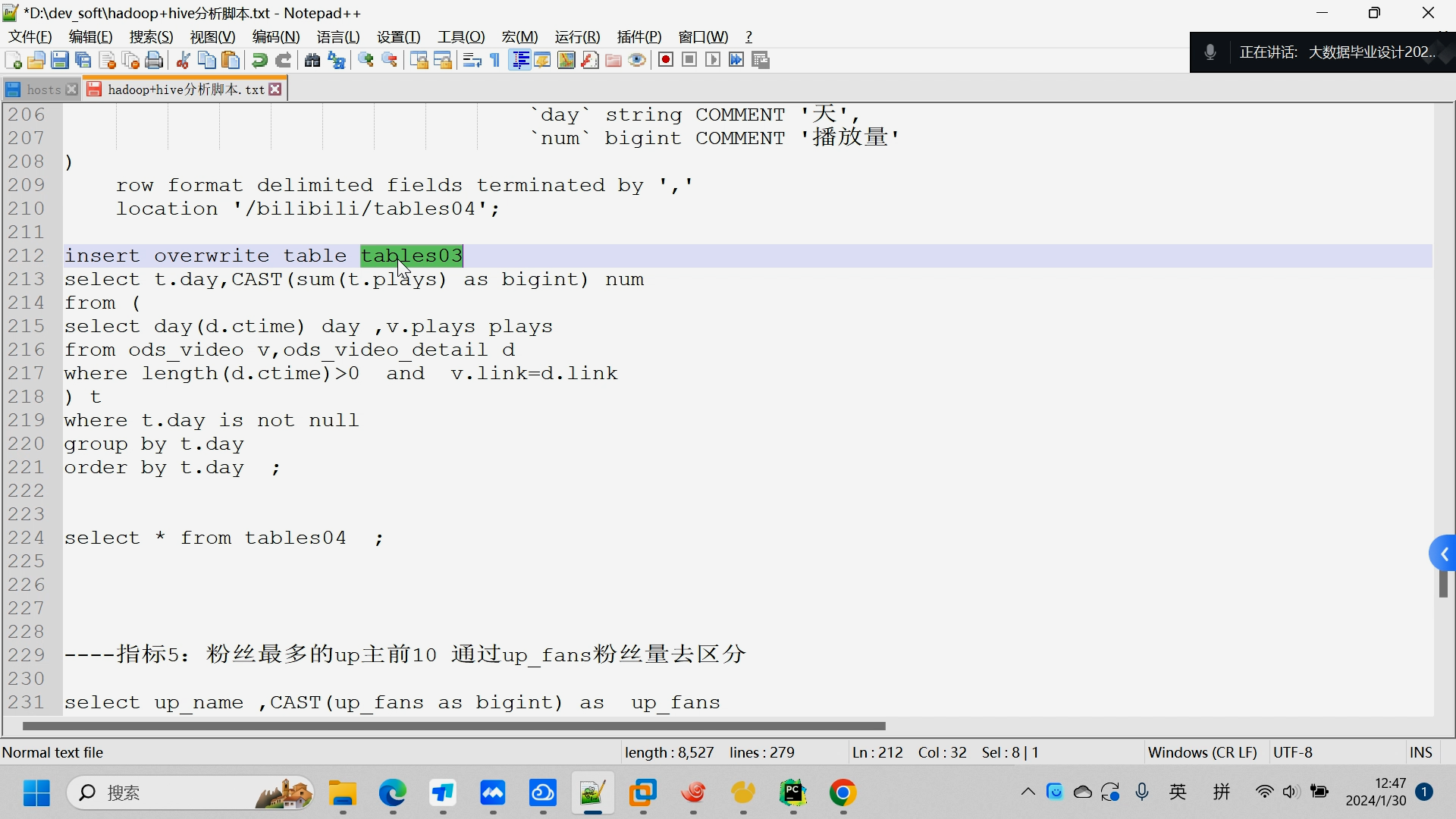
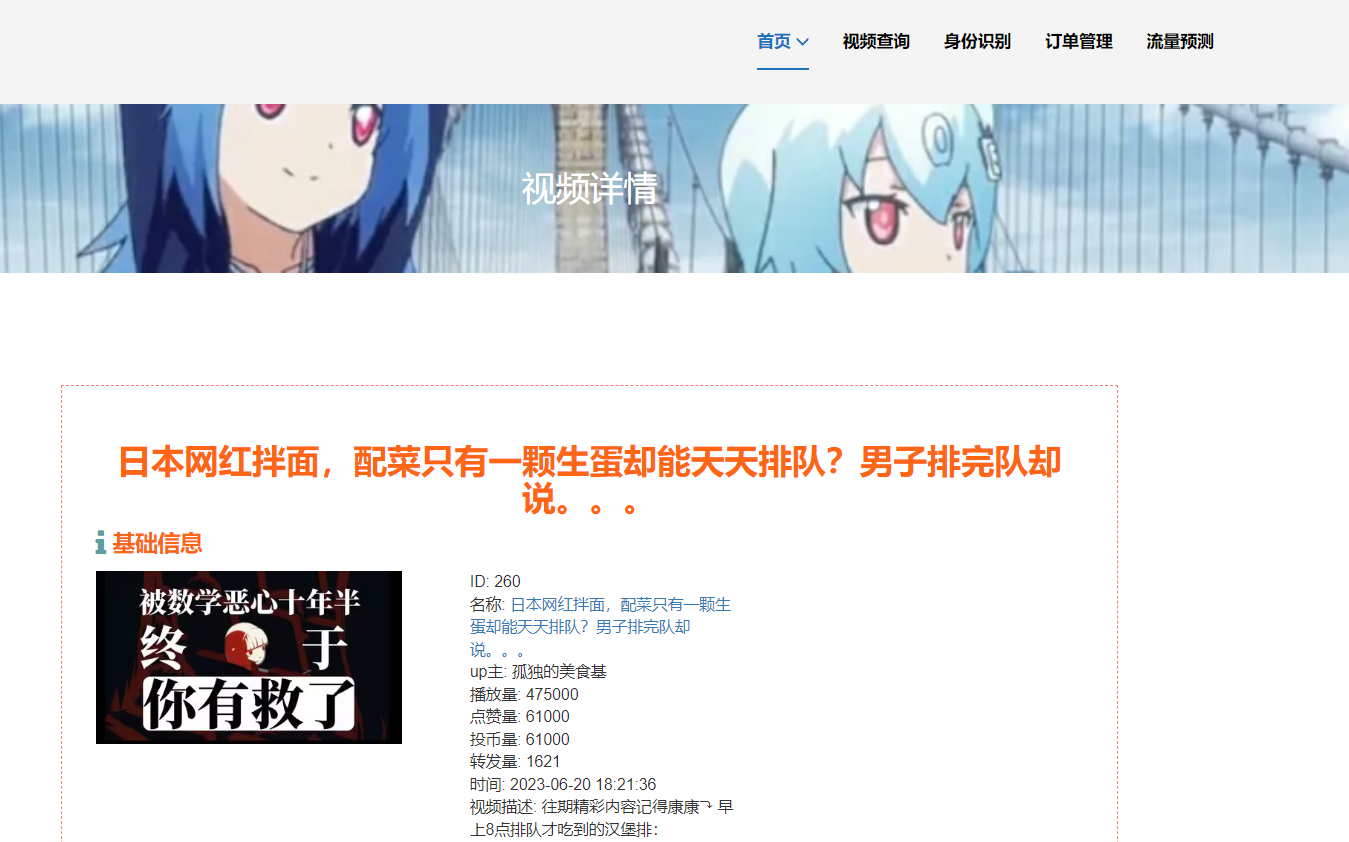
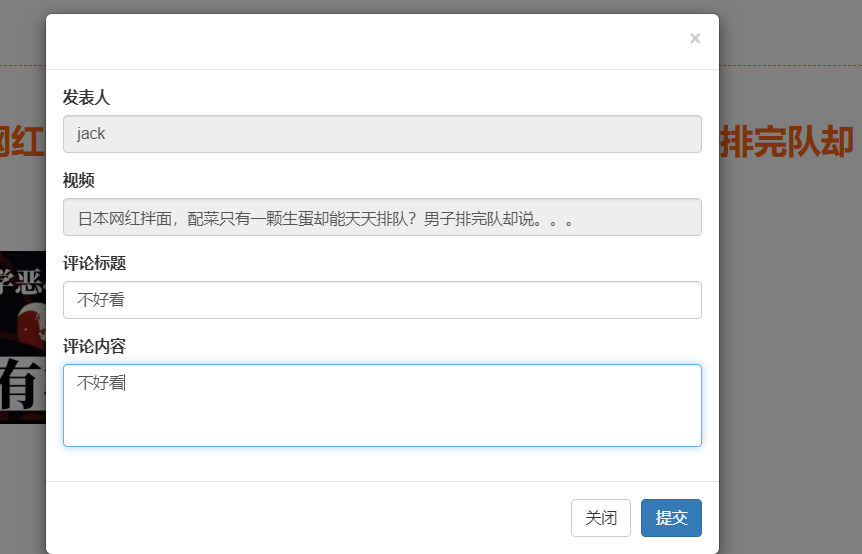
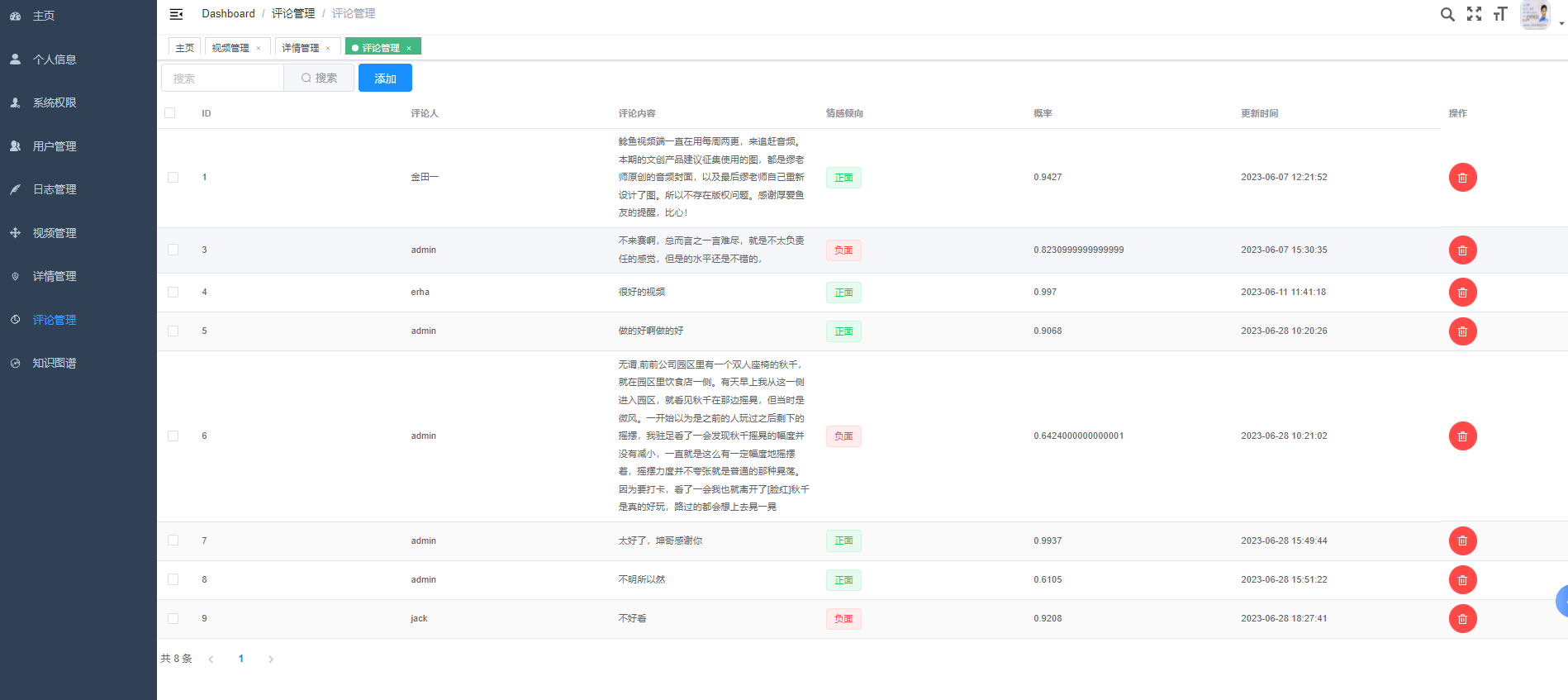
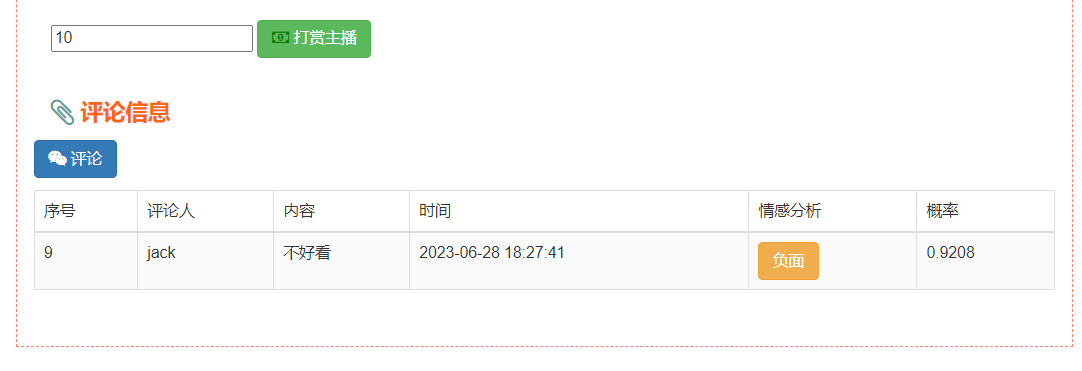
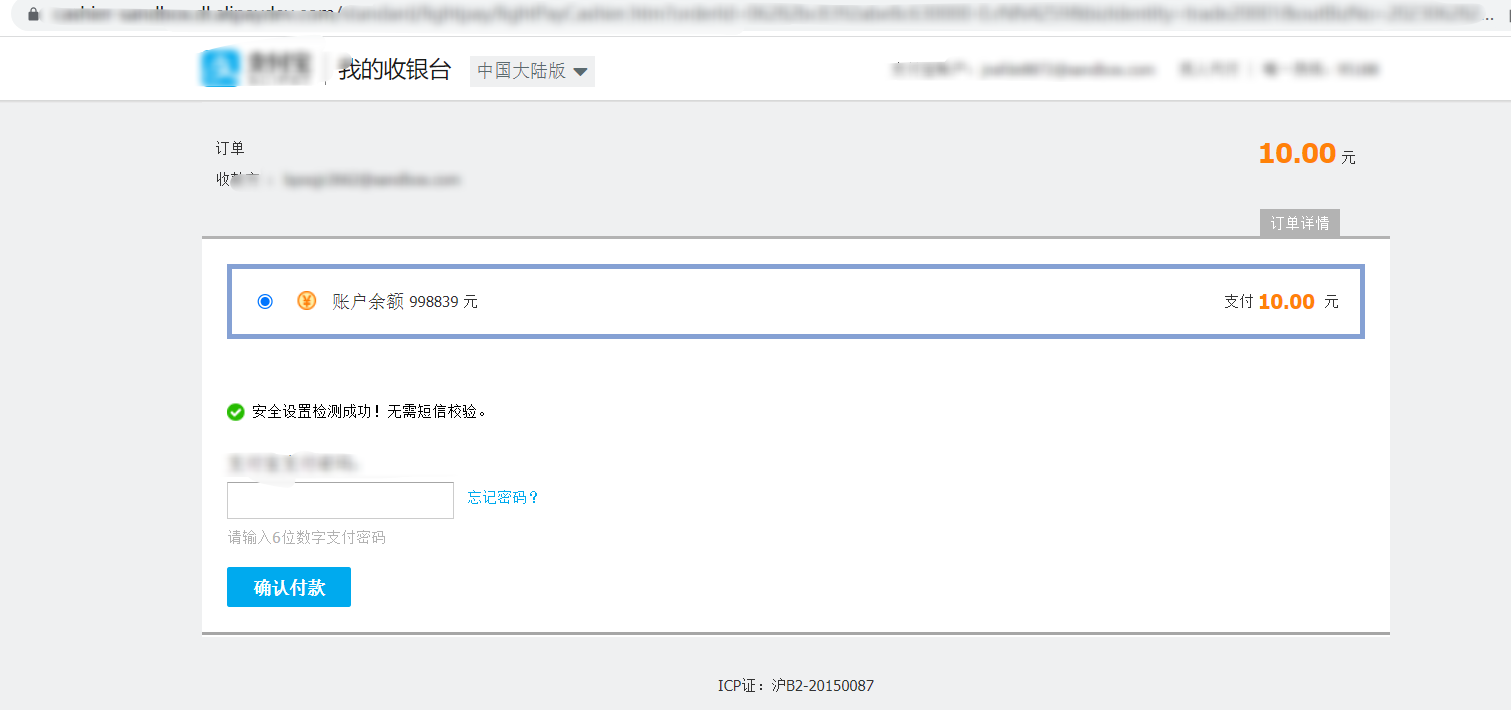

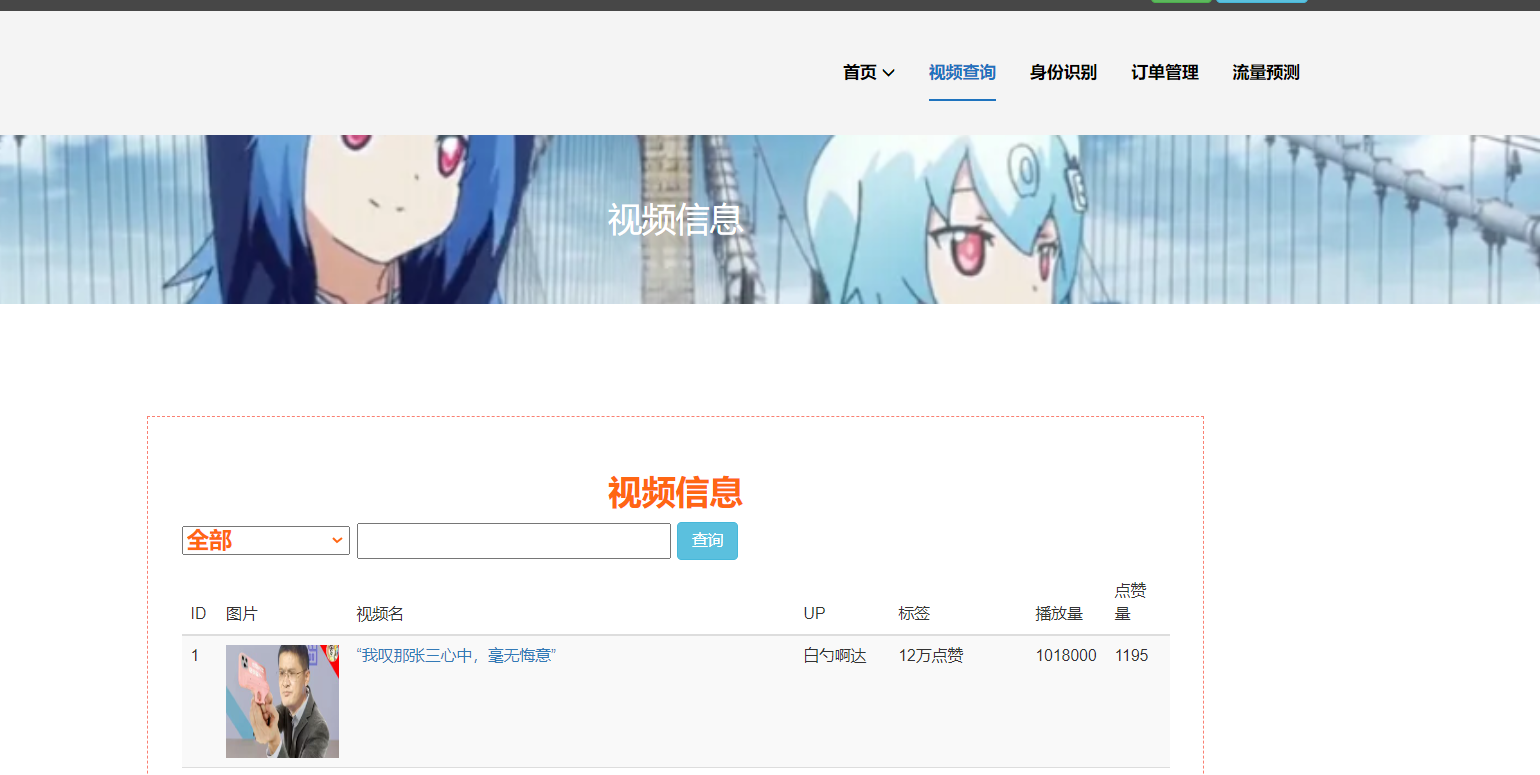

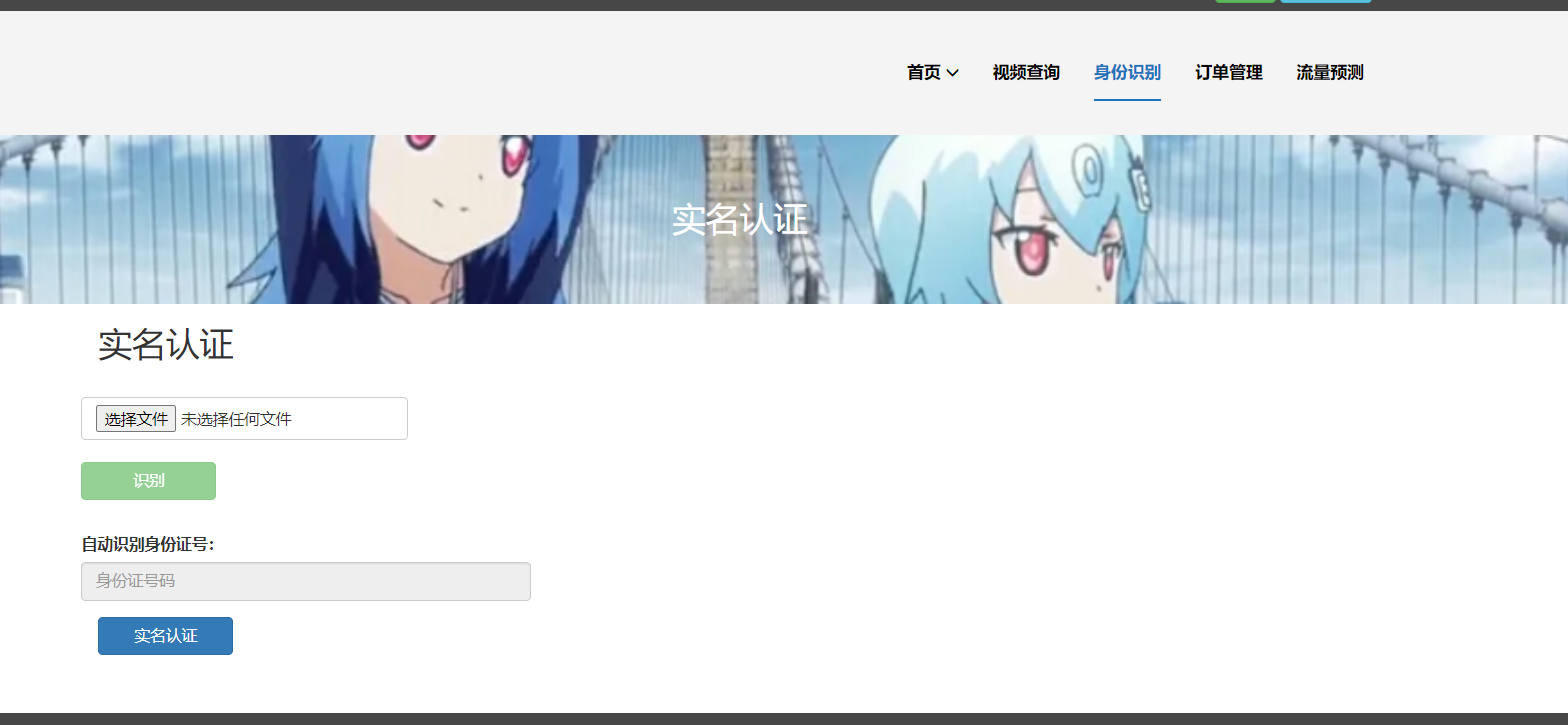

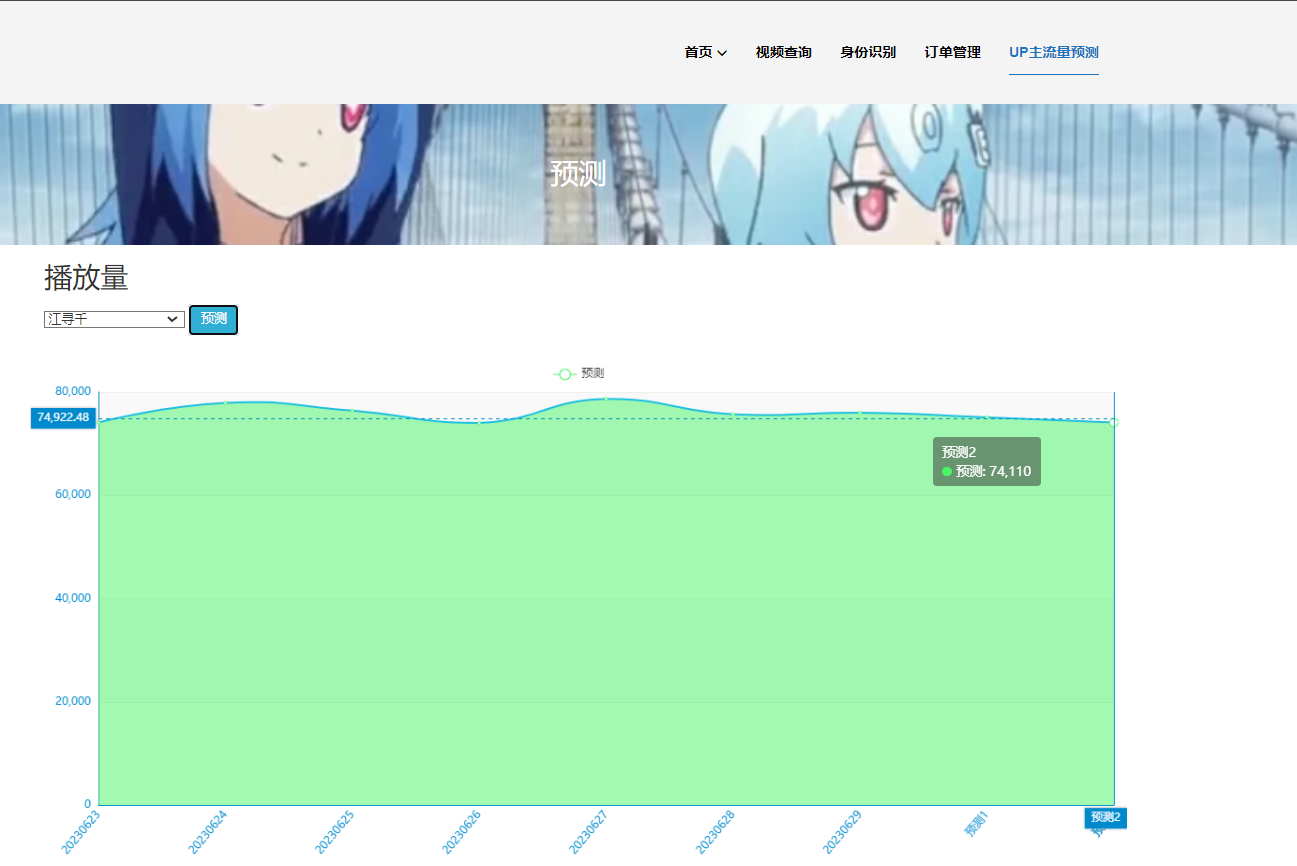

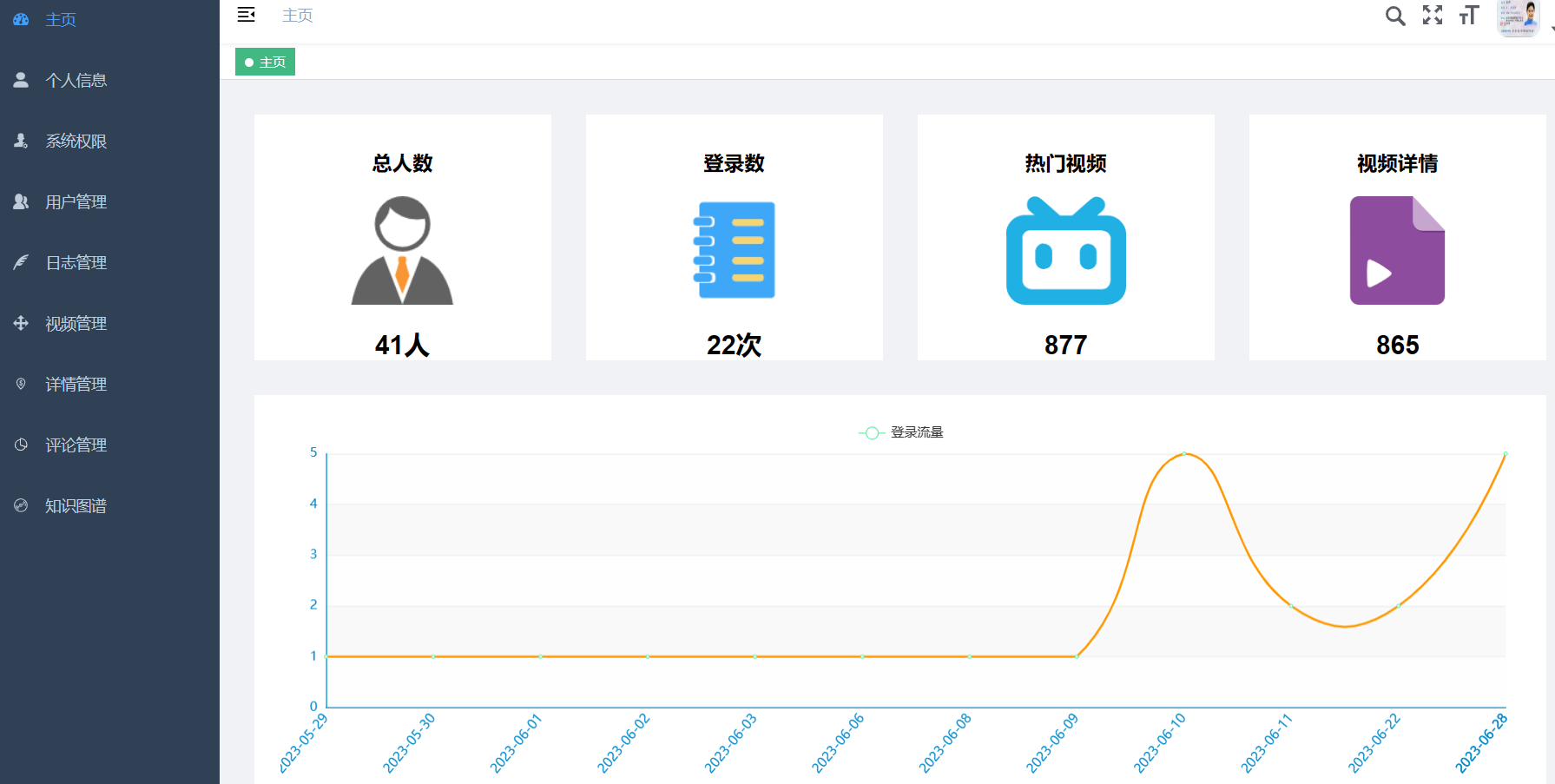
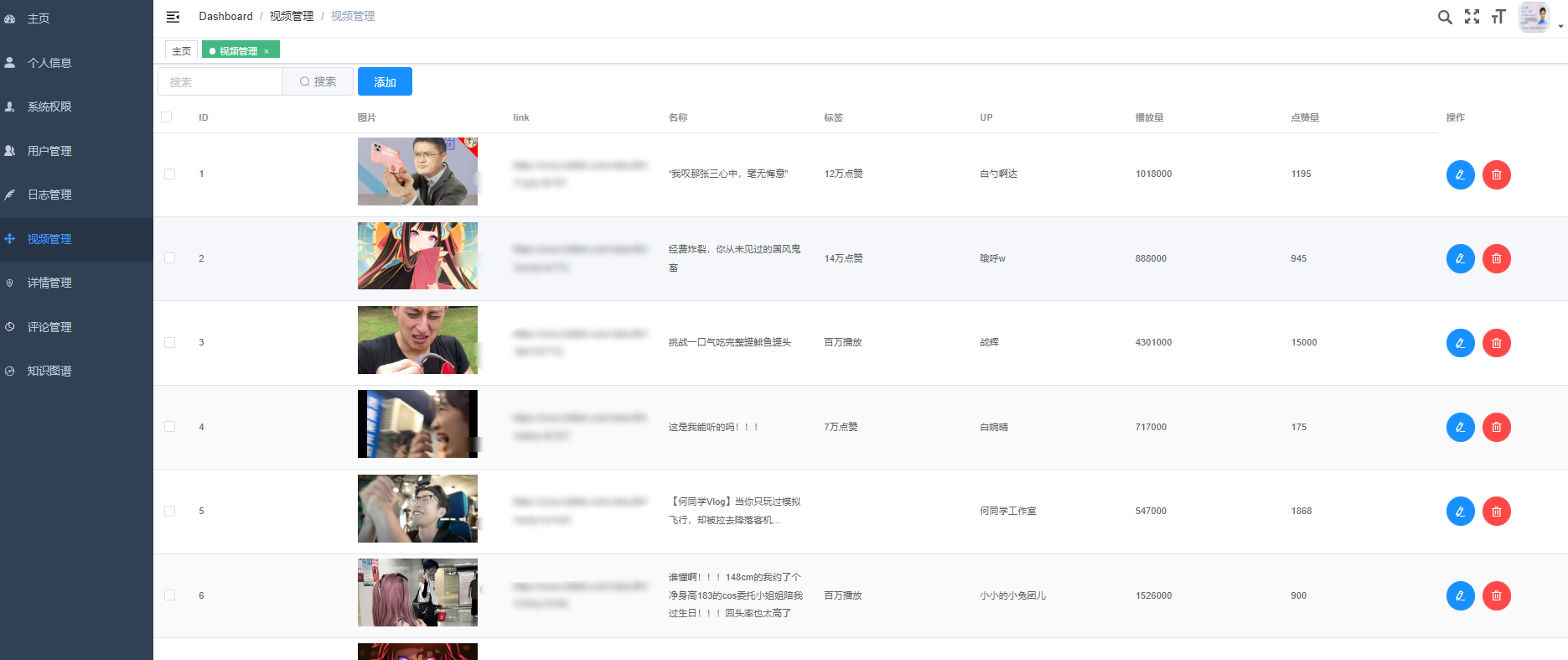

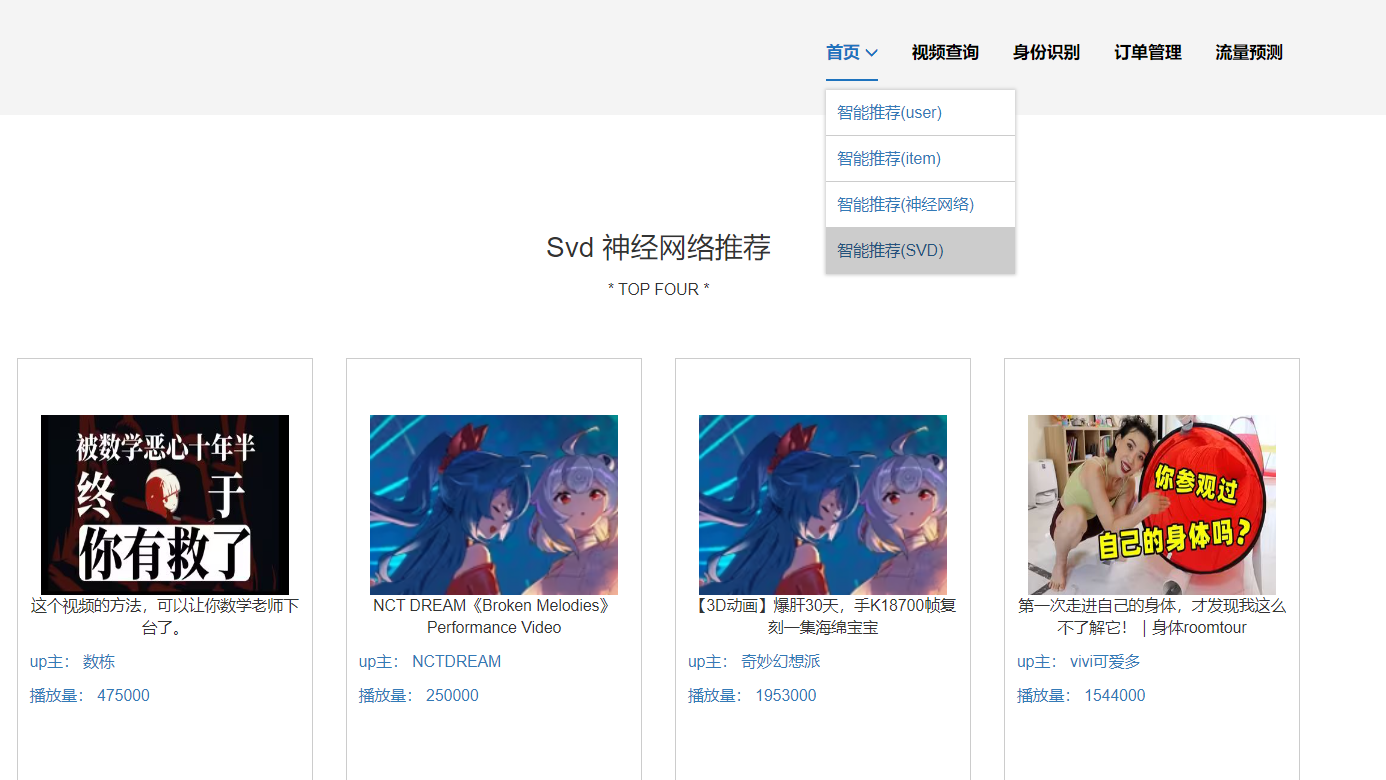
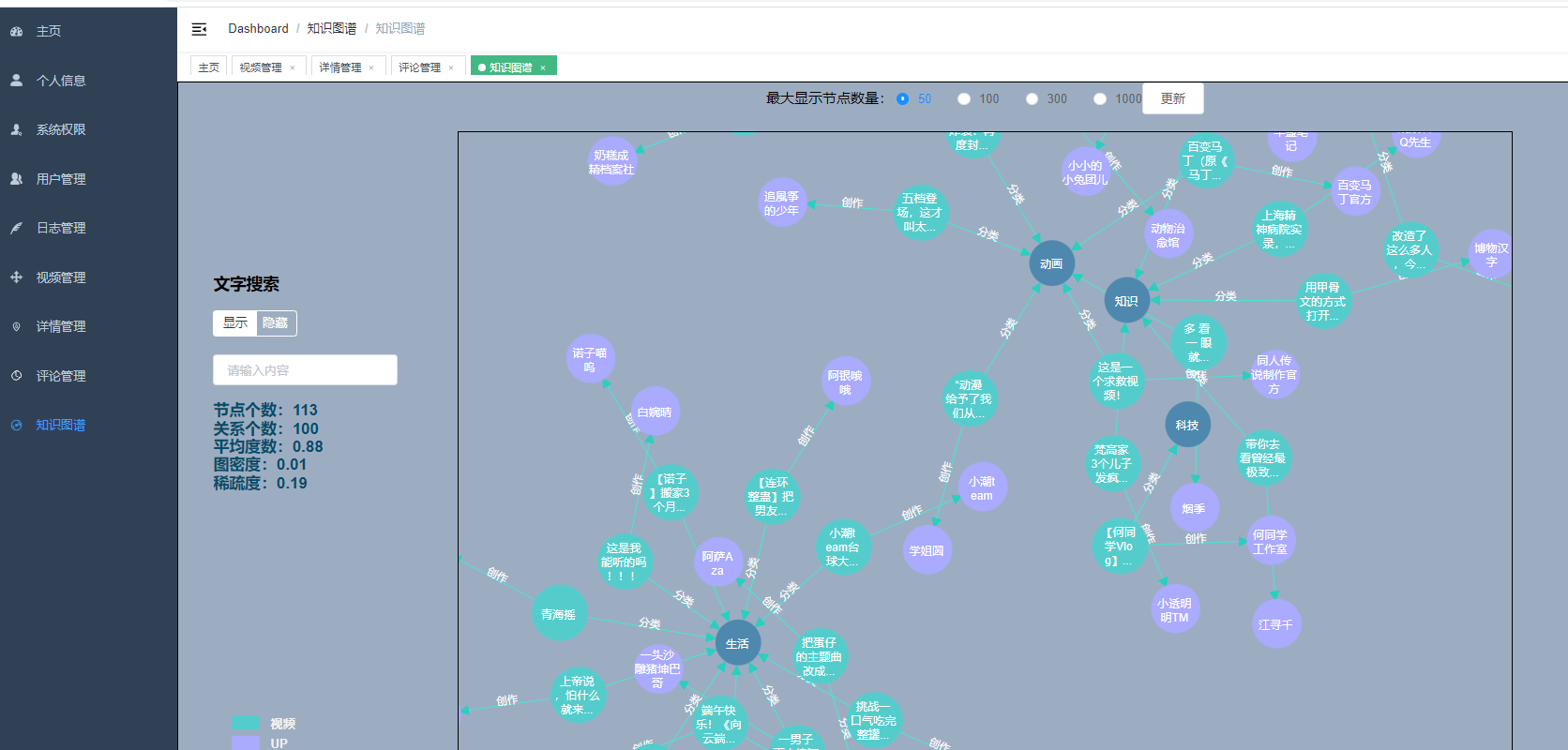
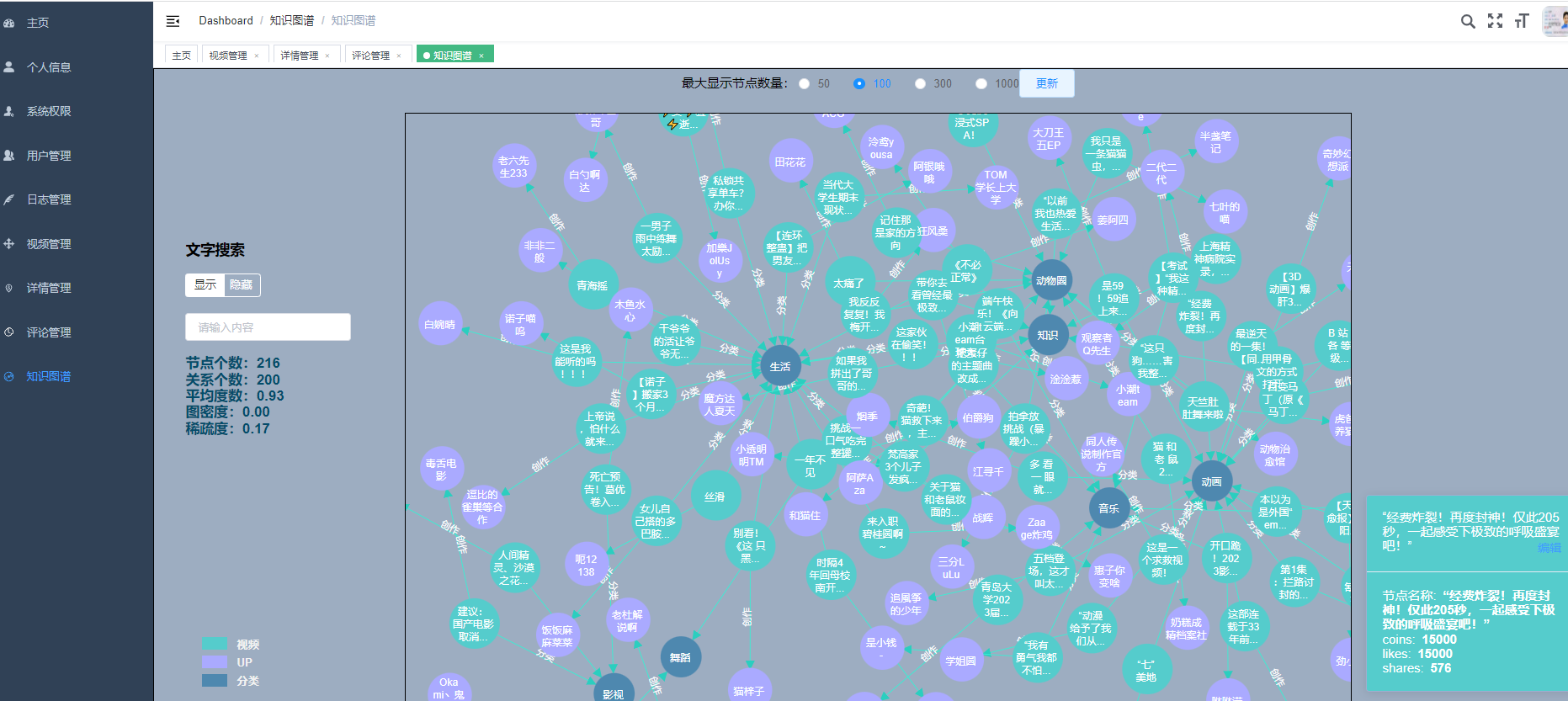
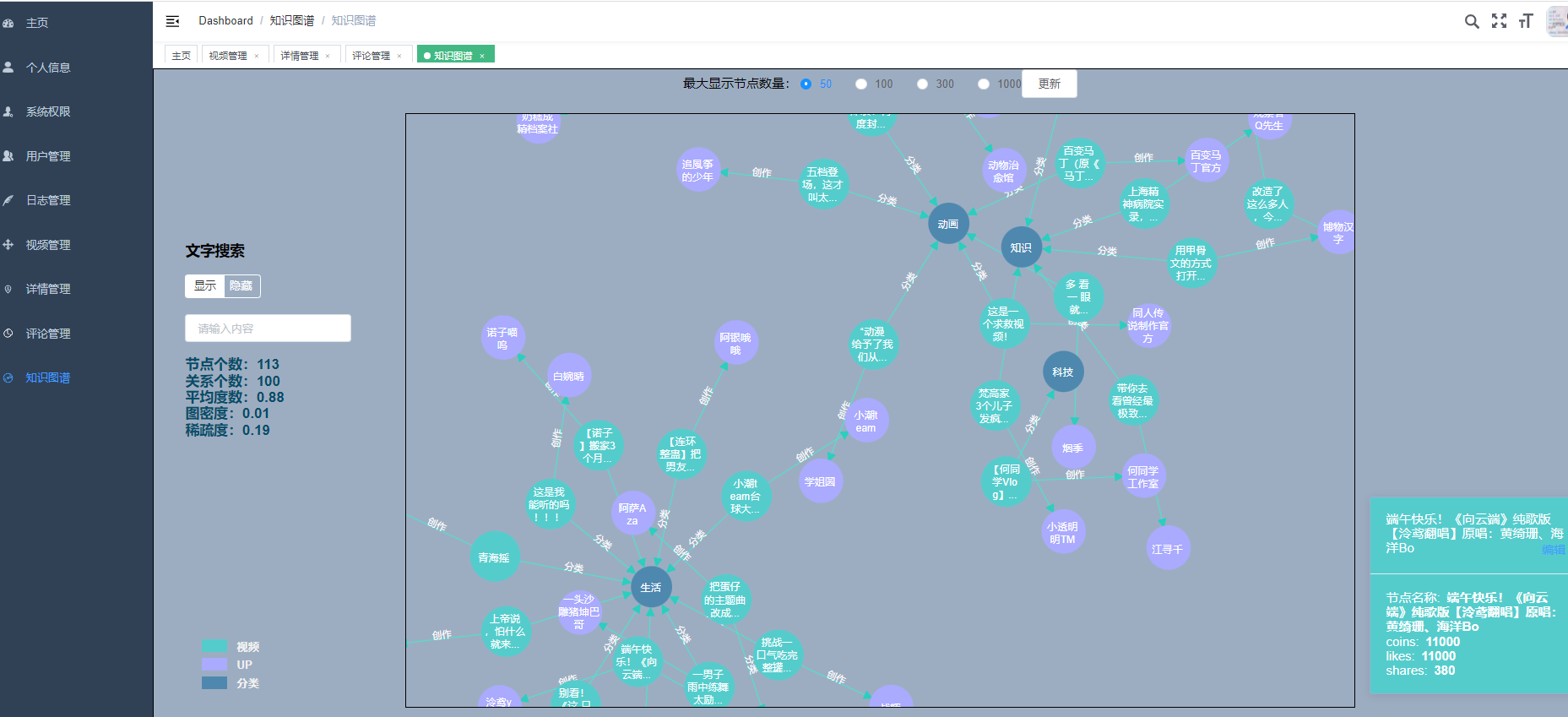
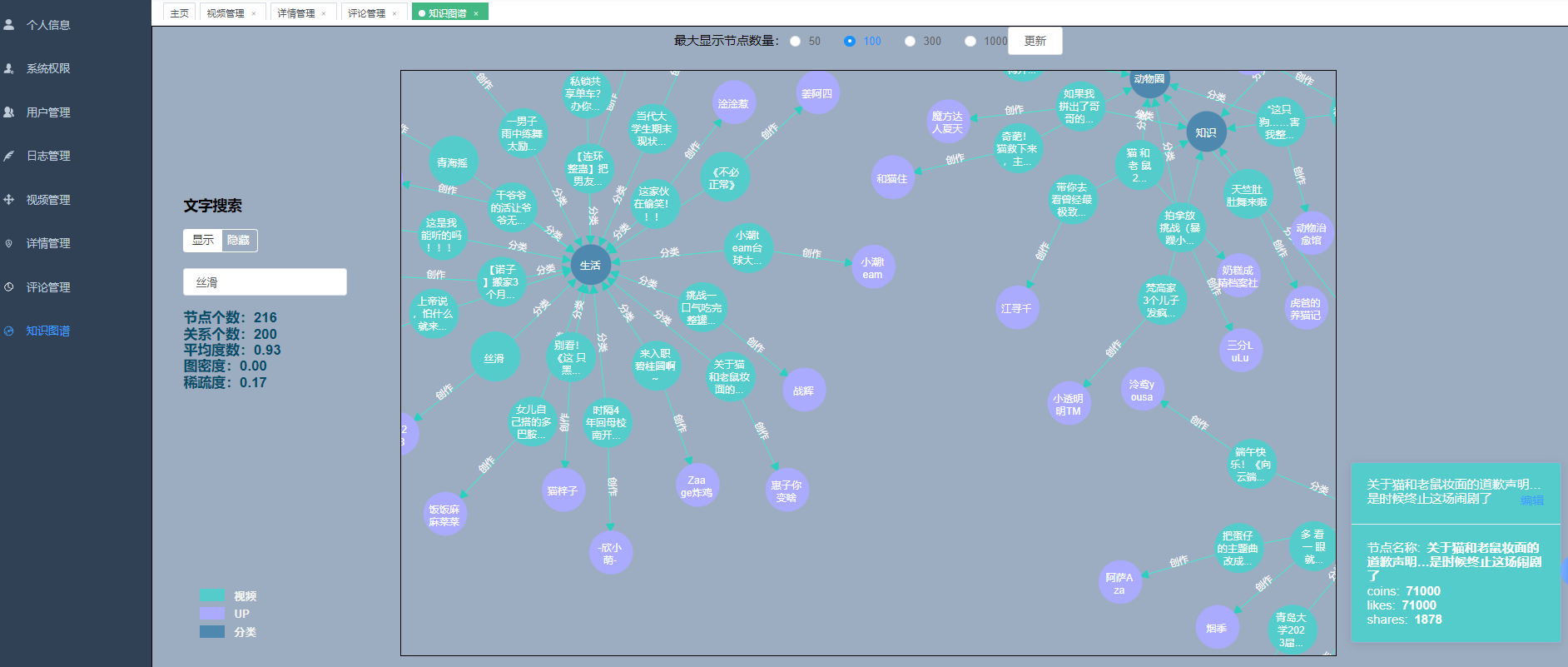
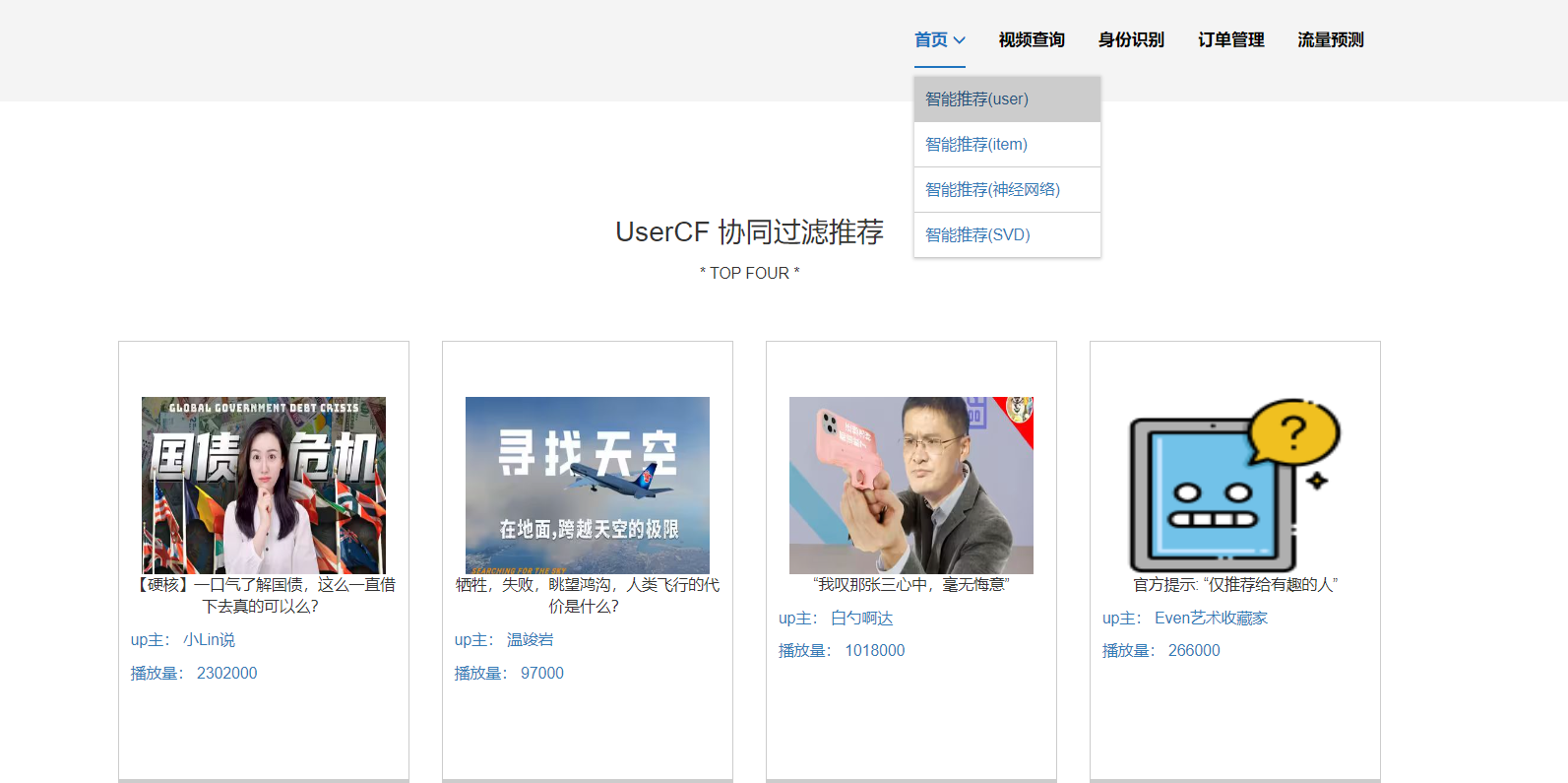
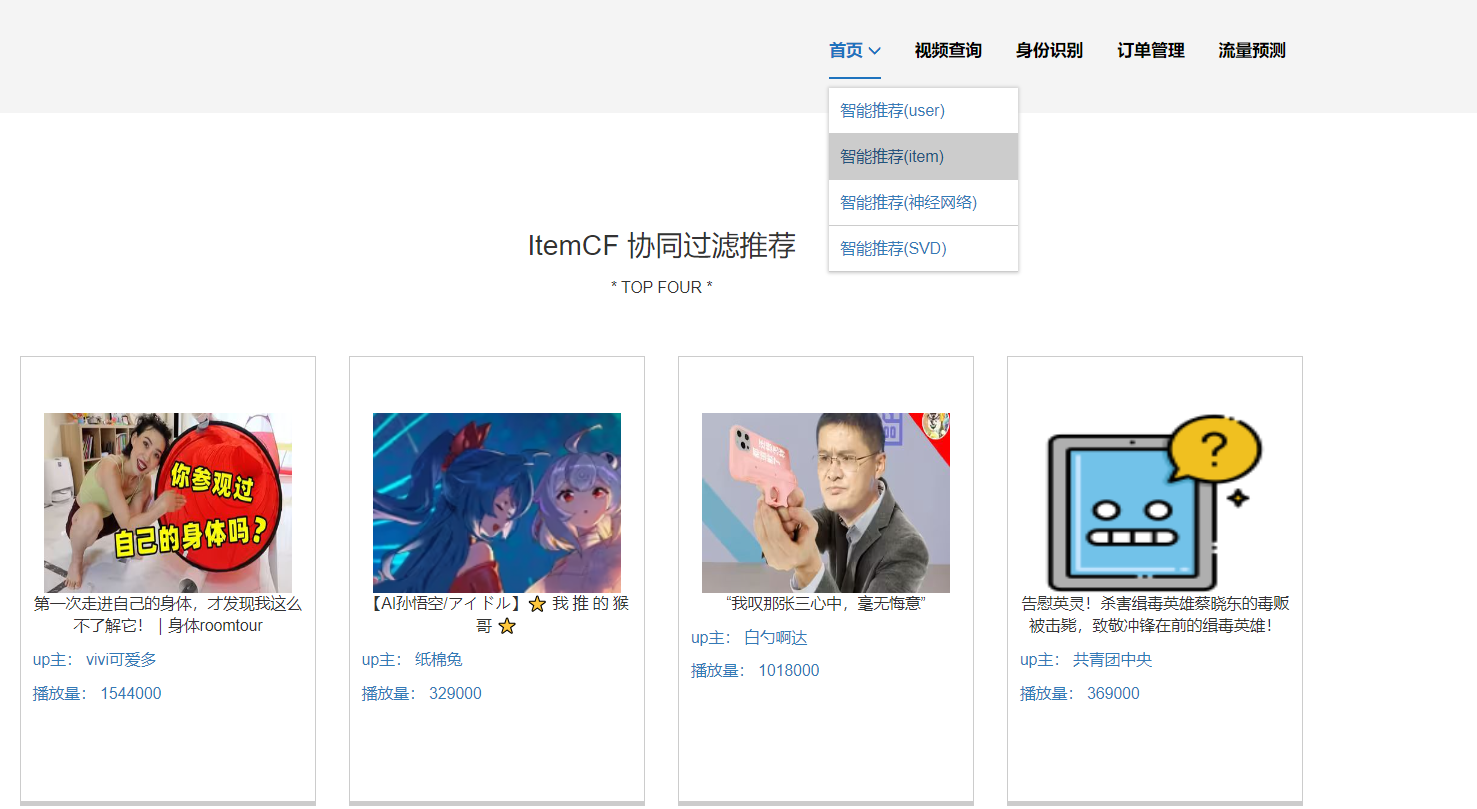
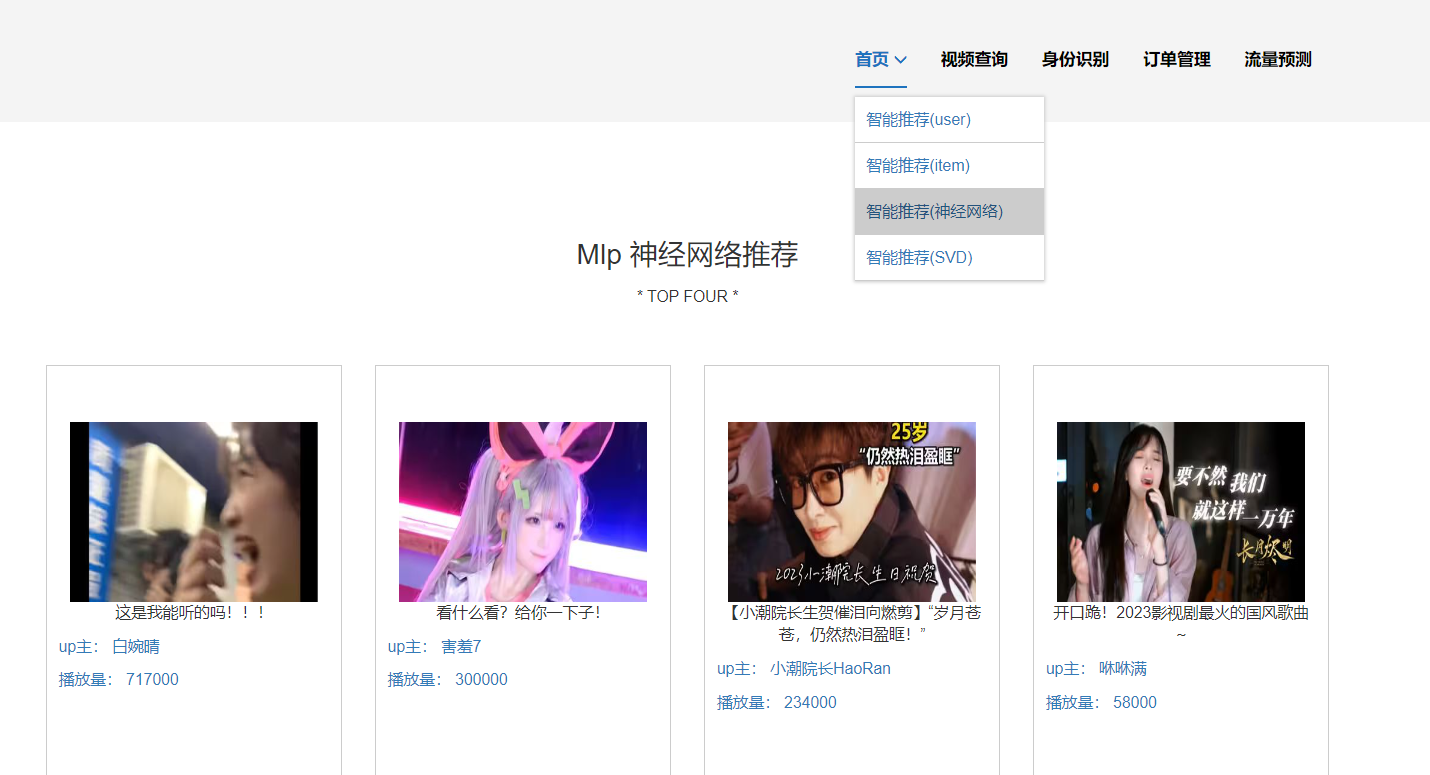
核心算法代码分享如下:
package com.bigdata.storm.kafka.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @program: storm-kafka-api-demo
* @description: redis工具类
* @author: 小毕
* @company: 清华大学深圳研究生院
* @create: 2019-08-22 17:23
*/
public class JedisUtil {
/*redis连接池*/
private static JedisPool pool;
/**
*@Description: 返回redis连接池
*@Param:
*@return:
*@Author: 小毕
*@date: 2019/8/22 0022
*/
public static JedisPool getPool(){
if(pool==null){
//创建jedis连接池配置
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//最大连接数
jedisPoolConfig.setMaxTotal(20);
//最大空闲连接
jedisPoolConfig.setMaxIdle(5);
pool=new JedisPool(jedisPoolConfig,"node03.hadoop.com",6379,3000);
}
return pool;
}
public static Jedis getConnection(){
return getPool().getResource();
}
/* public static void main(String[] args) {
//System.out.println(getPool());
//System.out.println(getConnection().set("hello","world"));
}*/
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











