




 文章探讨了在中药材领域应用推荐系统的需求,介绍了使用Python爬取数据、协同过滤算法、Spark实时计算、情感分析等技术构建的中药材推荐与数据分析原型系统,包括数据库管理、智能推荐、数据可视化等功能。
文章探讨了在中药材领域应用推荐系统的需求,介绍了使用Python爬取数据、协同过滤算法、Spark实时计算、情感分析等技术构建的中药材推荐与数据分析原型系统,包括数据库管理、智能推荐、数据可视化等功能。
|
现今,人们从网络上获取的消息越来越多,推荐系统应运而生并广泛应用于各行各业。但在中药材领域的应用却很少。近年来,人们对中药材的重视程度逐渐提高,购买量和相关研究也随之增多,一般的中药材购买网站不能满足人们生活和科研工作的需求,因此论文研究了基于大数据的中药材推荐与数据分析系统需要的关键技术,同时设计并完成了一个中药材推荐与数据分析原型系统。 |
|
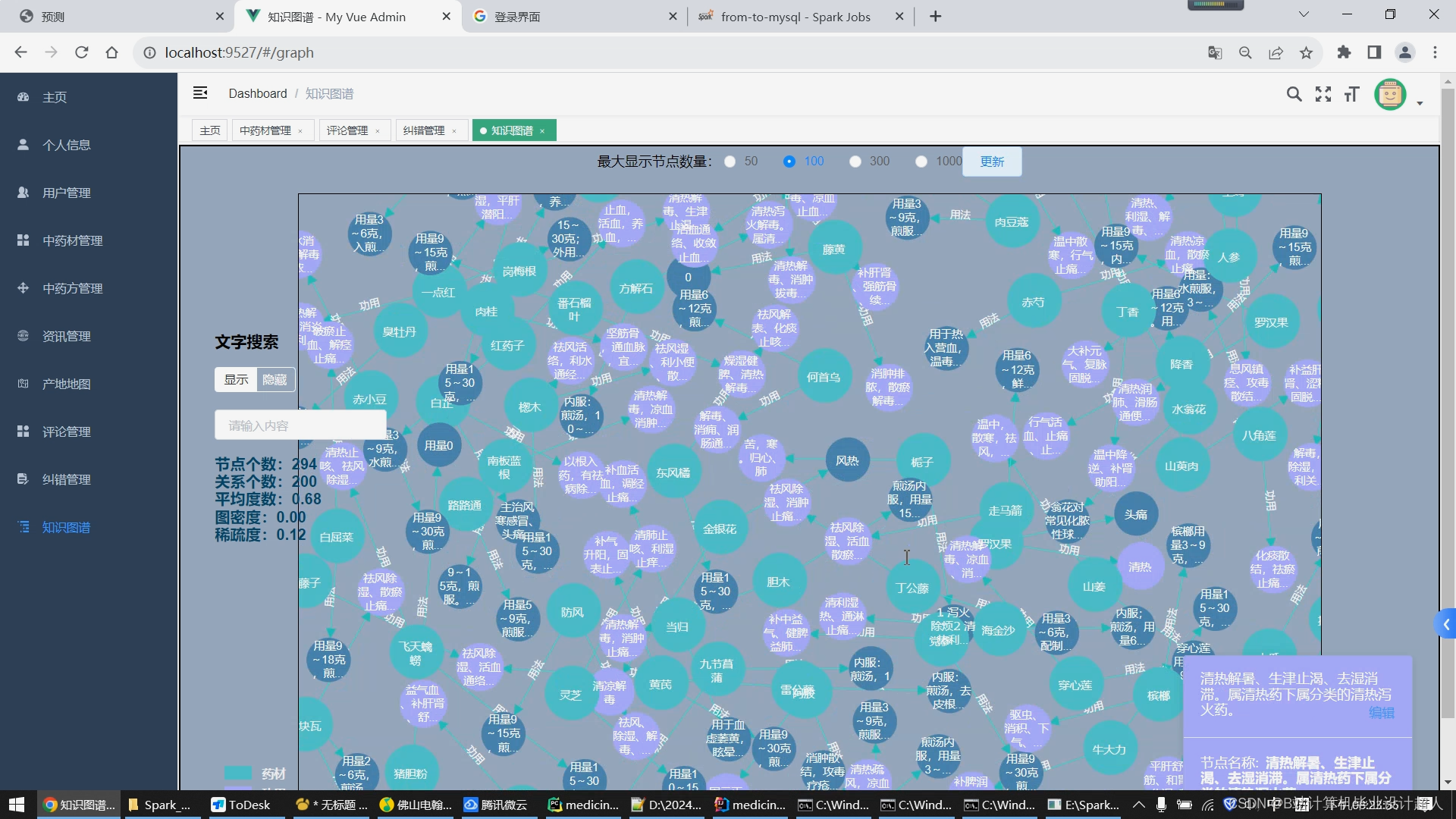
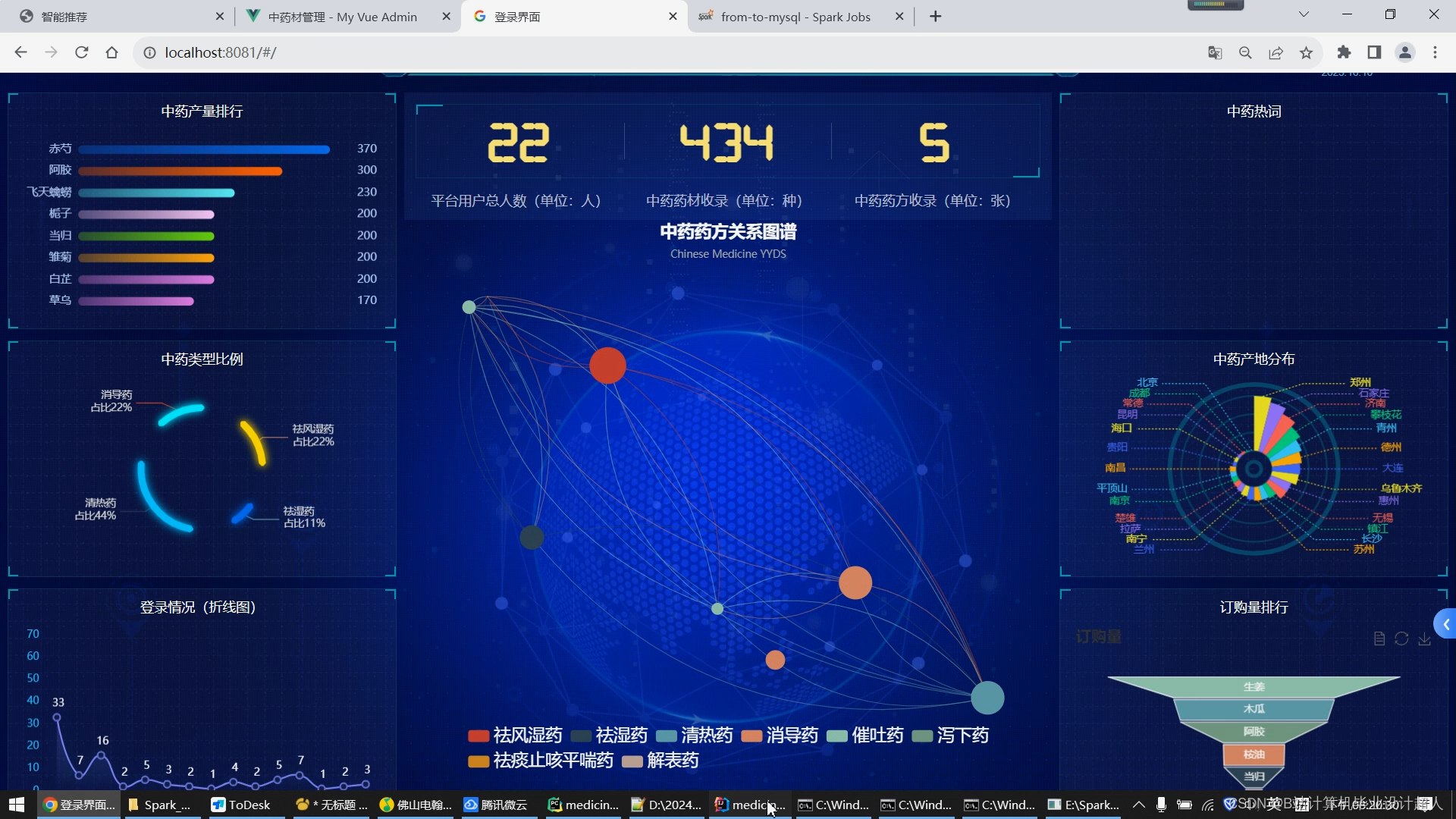
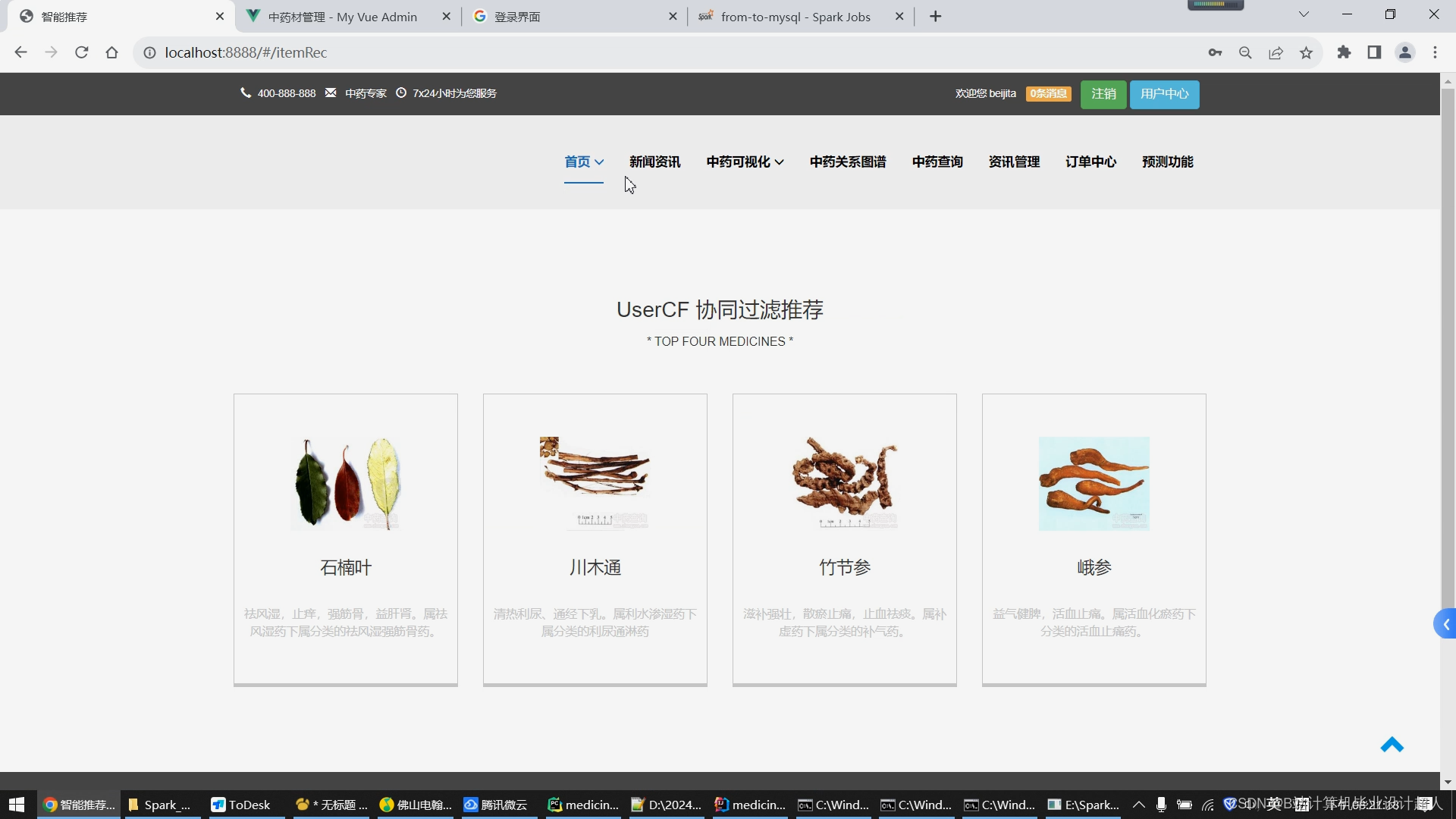
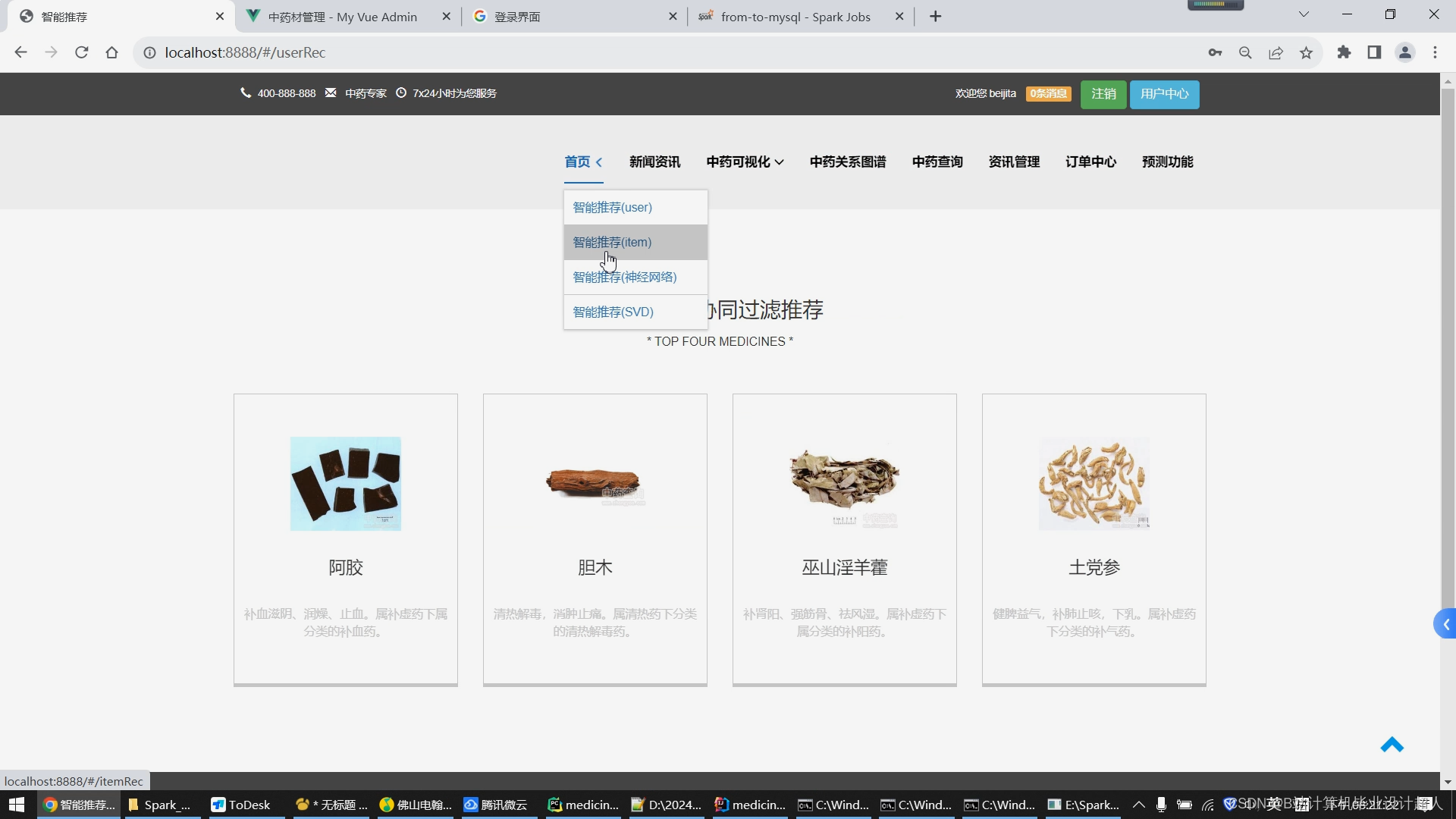
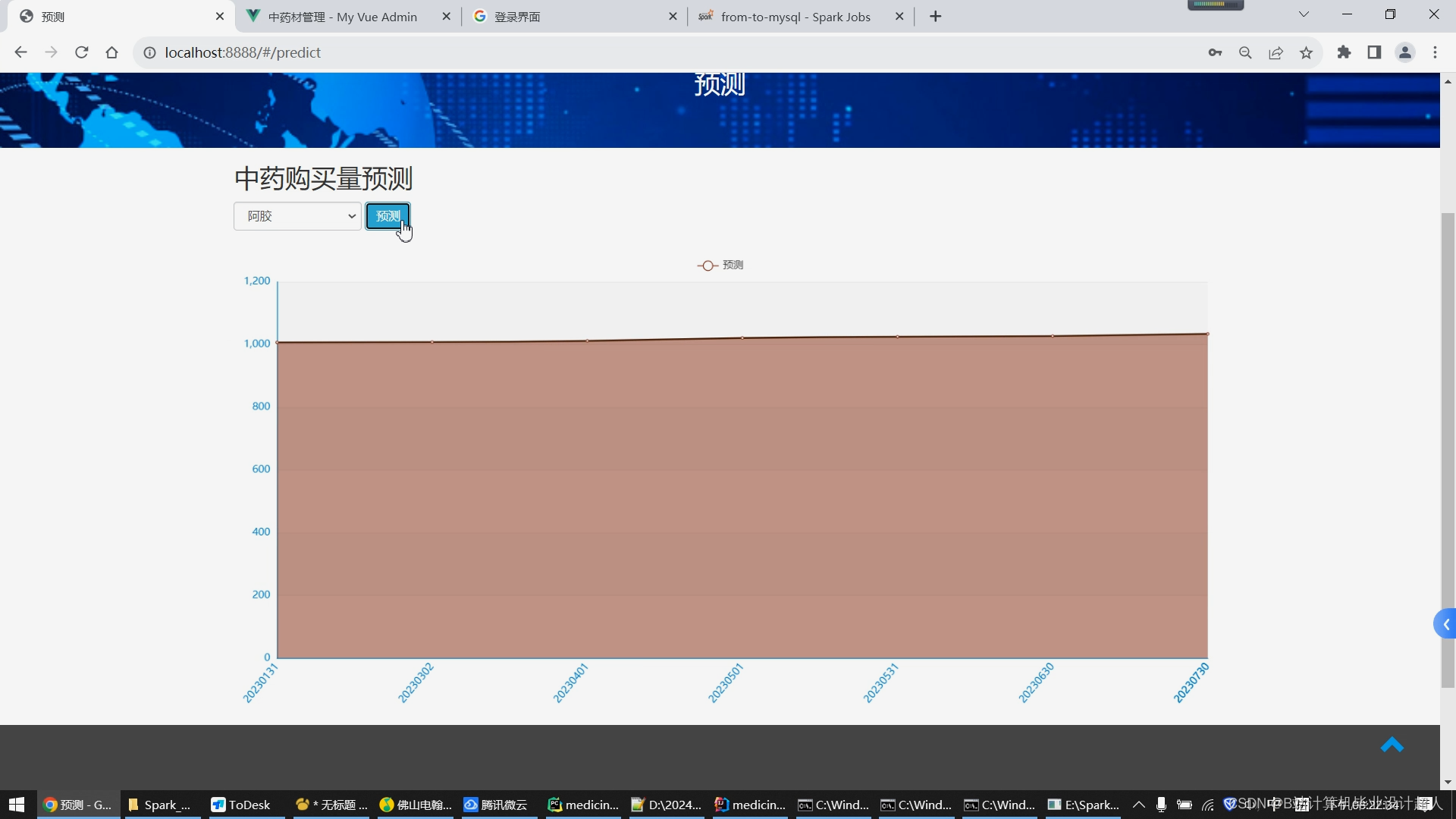
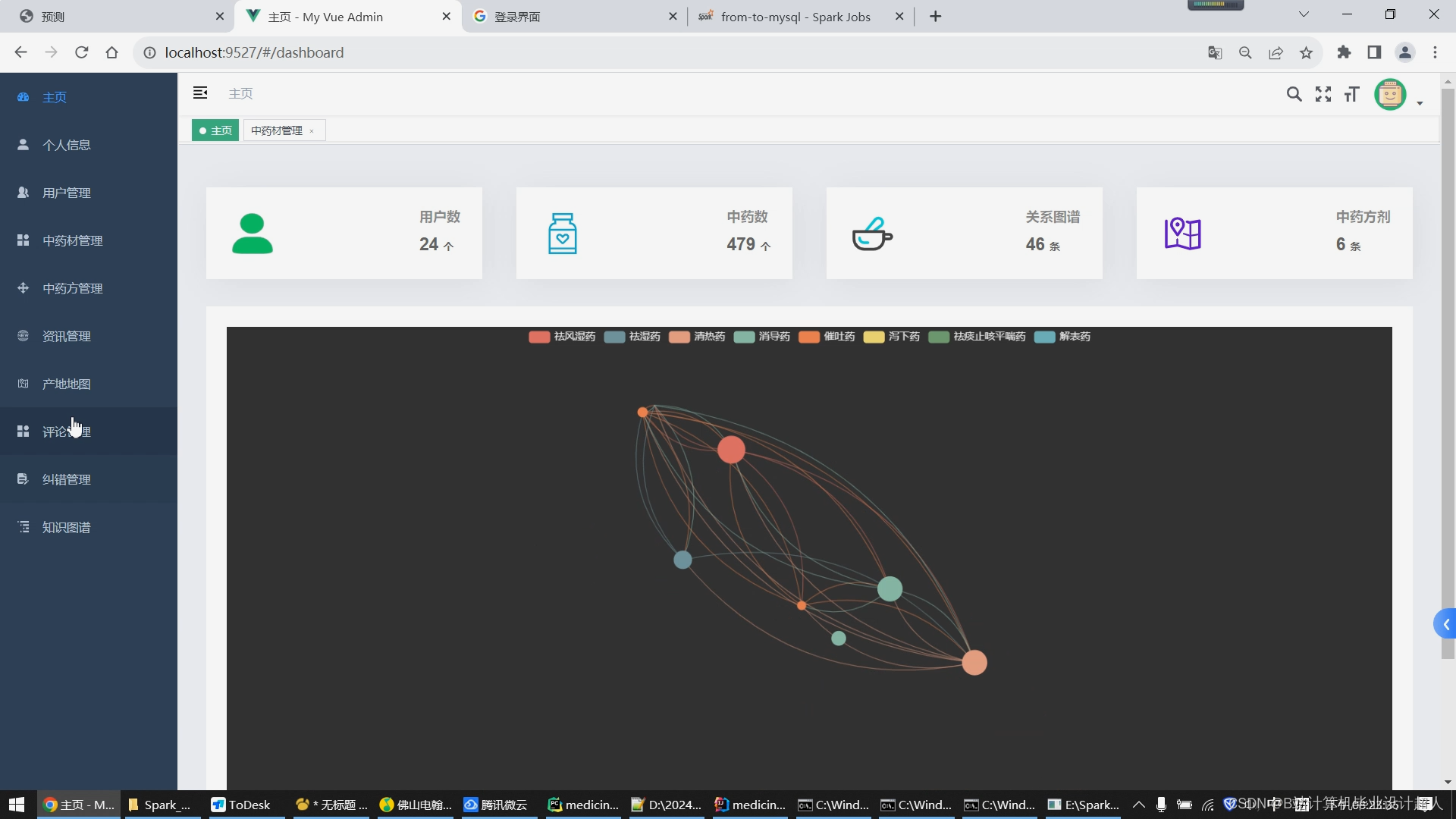
1.使用Python脚本爬取完整的中药材信息存储到mysql数据库/hive数仓; 2.学习Python完成协同过滤算法的实现,并将实现封装成.py脚本集成到springboot+vue.js搭建的web界面提供智能推荐(基于用户、基于物品全部实现),后期考虑推荐算法增加到4种,增加中药预测模型算法的实现; 3.学习Spark实时计算框架,尝试使用SparkSQL完成大屏统计的数据接口实现; 4.使用lstm情感分析模型实现对用户评论进行情感分析; 5.将短信验证码、中药材识别等基础特色功能集成到系统中,实现《中药材推荐与数据分析系统》的基础业务; 6.使用echarts实现大屏驾驶舱,springboot+vue.js实现门户系统、后台管理系统的web功能,后期考虑增加知识图谱可视化。 |
|
[1]郭安邦.面向农产品的电子商务推荐系统Grecs的研究和实现[D].吉林大学.2022. [2]何志红包秀莉.虚拟数字化中药材3D模型库展示系统构建].数字技术与应用,2021.37(05):171-172. [3]瑶瑟婷.基于shopex系统的陇西药材商城网站设计与实现[D1南昌大学,2020. [4]李征.段垒.基于用户兴超评分填充的改进混合推荐方法[J].工程科学与技术2022.51(01):189-196. [5]刘莉.简应权,王海洋.尚秘.吴睿.中药药材种植与少数民族地区区域经济发展思考]中西医结合心血管病电子杂志.2022.5(09):9. [6]罗水平,彭任辉.2000版中国药典载中药材自然分类索引编制],中药材,2023(03):229-232. [7]马宏伟,张光卫,李鹏.协同过滤推荐算法综述J].小型微型计算机系统,2023.30(07):1282-1288. [8]马健,感魁,朱庆友,闫磊.基于遗传模拟退火三次指数平滑模型的中药材价格预测研究J],佳木斯大学学报(自然科学版).2020.35(05):857-860+874. [9]苗开超.指数平滑模型在农产品价格预测中的应用IC]中国仪器仪表学会微型计算机应用学会,2021:183-187. [10]彭洁,徐剑晖.陈超.电子商务中基于潜在类回归模型的农产品个性化推荐方案J].江苏农业科学,2022(12):274-278. [11]荣辉桂.火生旭胡春华.英进侠.基于用户相似度的协同过滤推荐算法]通信学报,2023.35(02):16-24. |
核心算法代码分享如下:
try:
r = requests.get(url, headers=headers, timeout=20)
r.encoding='gbk'
except Exception as e:
print(url)
print(e)
return
try:
medicine = dict()
# print(r.text)
html = etree.HTML(r.text)
ps = html.xpath('//div[@class="gaishu"]/div[@class="text"]/p')
# 取当前的strong内容
for pNode in ps:
# print('取节点')
pTitle = pNode.xpath('strong/text()')
# 正则提取
if len(pTitle) == 0:
continue
# print('取当前节点的内容')
# 取当前节点的内容
pContent = pNode.xpath('text()')
# print(pContent)
# print(pTitle, pContent)
# medicine[pTitle[0]] = pContent[0]
# print('原始:', pContent[1])
# content = re.sub(r"】","", pContent[1]) # 使用正则表达式提取ID
try:
# 这里如果在本文内容中包含超链接,那就应该提取所有的内容了,不仅仅是pContent[1]这个节点
content = ''
for iContent in pContent:
temp = re.findall(
r"([\w\s\u4e00-\u9fa5\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b~()]+)",
iContent)
content = content + temp[0]
content = content.replace('\r', '').replace('\n', '').replace('\t', '').replace('\u3000', '')
# content = re.findall(r"([\w\s\u4e00-\u9fa5\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b~()]+)", pContent[1])
medicine[pTitle[0]] = content
except Exception as ex:
medicine[pTitle[0]] = ''
# print(pContent[0])
# print(content)
if pTitle[0] == '中药名' or pTitle[0] == '正名' or pTitle[0] == '药名':
nameNode = pNode.xpath('u/a/text()')
if len(nameNode)>=1:
medicineName = pNode.xpath('u/a/text()')[0]
else:
# pContent = pNode.xpath('text()')
# medicineName = re.findall(r"([\s\u4e00-\u9fa5\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b~()]+)", pContent[2])[0]
content = ''
for iContent in pContent:
# 药材名中的空格和拼音过滤掉,去掉\w\s
temp = re.findall(
r"([\u4e00-\u9fa5\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b~()]+)",
iContent)
if len(temp)>0:
content = content + temp[0]
medicineName = content.replace('\r', '').replace('\n', '').replace('\t', '').replace('\u3000',
'')
print(medicineName)
if medicineName != '':
medicine['中药名'] = medicineName
mid = re.findall(r"_(\d+?).html", url)[0] # 使用正则表达式提取ID
medicine['mid'] = mid



















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











