




 本文详细解读了匹配网络在一次学习任务中的代码实现,包括数据读取、学习过程和图形表示。通过提取图像的embeddings,构建任务特征表示,计算相似度并进行预测,最终实现one-shot learning。文章深入探讨了实验流程,从数据预处理到模型训练,为理解匹配网络提供了清晰的路径。
本文详细解读了匹配网络在一次学习任务中的代码实现,包括数据读取、学习过程和图形表示。通过提取图像的embeddings,构建任务特征表示,计算相似度并进行预测,最终实现one-shot learning。文章深入探讨了实验流程,从数据预处理到模型训练,为理解匹配网络提供了清晰的路径。
目录
2.2.1 读取train,evaluation和test图片至变量data中。
2.2.2 设计one shot learning的学习过程
2.2.3 真实数据的one shot learning过程
1. 代码中所有Classes和类之间的调用关系
如下:
| 类 | 调用类 | 再调用类 | 所在文件 |
| Class MiniImageNetDataSet | - | - | data.py |
| Class Classifier | Class MetaConvolution | Class MetaNetwork | meta_matching_network.py |
| Class TaskContextEncoder | Class TaskTransformer | - | |
| Class DistanceNetwork | - | - | |
| Class Extractor | - | - | |
| Class AttentionClassify | - | - |
2. 代码思路解析
2.1 代码的入口
train_meta_matching_network.py
在data.py中设置图片路径和csv路径:
resizetargetpath
csv_file_dir2.2 数据读取
2.2.1 读取train,evaluation和test图片至变量data中。
data = dataset.MiniImageNetDataSet(batch_size=batch_size, classes_per_set=classes_per_set, samples_per_class=samples_per_class, shuffle_classes=True)data.datasets["train"] size:[64,600,84,84,3] # 共64类,每个类600张图片,共38400张图片。[84,84,3]是图片的长宽和3个channels data.datasets["eval"] size:[16,600,84,84,3] # 共16类,每个类600张图片,共9600张图片 data.datasets["test"] size:[20,600,84,84,3] # 共20类,每个类600张图片,共12000张图片
2.2.2 设计one shot learning的学习过程
experiment = ExperimentBuilder(data) # experiment和data完全一样
one_shot_miniImagenet, losses, c_error_opt_op, init = experiment.build_experiment(batch_size, classes_per_set, samples_per_class)可以注意到如上的代码并没有使用到真实的数据(data或者experiment),都是使用placeholder和构建的Tensor。
1) 进入到experiment.build_experiment()中,首先构建了8个placeholders,后面写的是各变量的大小。
self.support_set_images (batch_size, way, shot, 84, 84, 3)
self.support_set_labels (batch_size, way, shot)
self.target_image (batch_size, 84, 84, 3)
self.target_label (batch_size,)
self.training_phase bool
self.rotate_flag bool
self.keep_prob float32
self.learning_rate float322)初始化meta_matching_network.py中所有类
self.one_shot_learner = MetaMatchingNetwork(batch_size=batch_size,
support_set_images=self.support_set_images,
support_set_labels=self.support_set_labels,
target_image=self.target_image,
target_label=self.target_label,
keep_prob=self.keep_prob,
is_training=self.training_phase,
rotate_flag=self.rotate_flag,
num_classes_per_set=classes_per_set,
num_samples_per_class=samples_per_class,
learning_rate=self.learning_rate)
_, self.losses, self.c_error_opt_op = self.one_shot_learner.init_train()3)进入到meta_matching_network.py文件中
def init_train(self):
"""
Get all ops, as well as all losses.
:return:
"""
losses = self.loss()
c_error_opt_op, trainable_variables = self.train(losses)
......4) 先来看下loss()中的代码,完成的构建Matching Network。
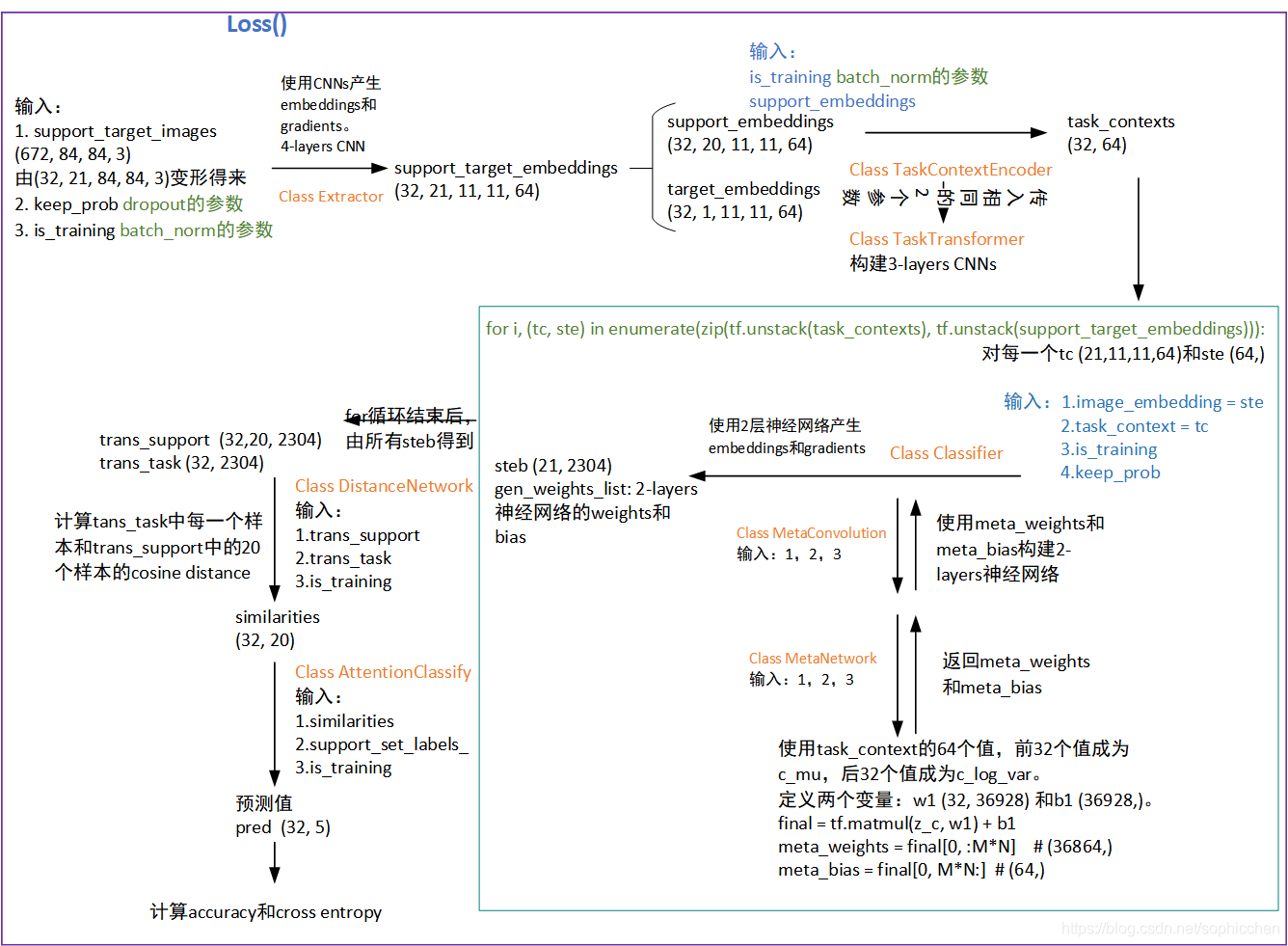
4.1)产生embeddings
support_target_embeddings = self.extractor(support_target_images, training=self.is_training, keep_prob=self.keep_prob)输入的support_target_images是support set和target set组成的大小为(batch_size,21,84,84,3)的图片矩阵。其中,batch_size=32,当way=5,shot=4时,support set的样本数为20,target set样本数为1,所以总样本数为21。
Extractor的作用是:在support_target_images上使用4层CNNs产生embeddings,大小为(32,21,11,11,64)。
4.2)产生task feature representation
task_contexts = self.tce(support_target_embeddings[:, :-1], training=self.is_training)使用的输入是support set 的embeddings(32,20,11,11,64),方法是TaskContextEncoder(其又调用了TaskTransformer)。TaskTransformer使用了3层CNNs。task_contexts大小为(32,64),即使用64维向量表示support set中20张图片的特征。
4.3)针对每一个task计算embeddings
trans_support_images_list = []
trans_target_images_list = []
tasks_gen_weights_list = [] # todo test generated weights distribution
for i, (tc, ste) in enumerate(zip(tf.unstack(task_contexts), tf.unstack(support_target_embeddings))):
print("============ In task instance ", i)
# support task image embeddings for one task
steb, gen_weights_list = self.Classifier(image_embedding=ste, task_context=tc, training=self.is_training, keep_prob=self.keep_prob) # (6, 4608)
trans_support_images_list.append(steb[:-1])
trans_target_images_list.append(steb[-1])
tasks_gen_weights_list.append(gen_weights_list)
trans_support = tf.stack(trans_support_images_list)
trans_target = tf.stack(trans_target_images_list)Classifier中的工作请见下图1描述。
steb 大小(21,2304),gen_weights_list保存MetaConvolution两层网络的weights和bias。
trans_support大小(32,20, 2304),trans_target大小(32,2304)。
4.4)计算target set和support set之间的相似度
similarities = self.dn(support_set=trans_support, input_image=trans_target, name="distance_calculation",training=self.is_training)
#get similarity between support set embeddings and target计算trans_target的每一个样本和trans_support中20个样本的cosine distance。similarities大小(32,20),记录trans_target与trans_support中20个样本的相似度值。
4.5)根据相似度输出预测值
preds = self.classify(similarities, support_set_y=self.support_set_labels_, name='classify', training=self.is_training)preds大小为(32,5)。
4.6)返回值
在得到preds后,计算accuracy和cross entropy。
返回内容为
return {
'losses': tf.add_n(tf.get_collection('crossentropy_losses'), name='total_classification_loss'),
'accuracy': tf.add_n(tf.get_collection('accuracy'), name='accuracy'),
'preds': preds, # added for ensemble training
't_label': self.target_label,
'tasks_gen_weights_list': tasks_gen_weights_list
}即是3)中loss的值。
5)再来看下train(),定义优化器
对于3)中的代码
c_error_opt_op, trainable_variables = self.train(losses)train()中定义了优化器
c_opt = tf.train.AdamOptimizer(beta1=0.9, learning_rate=self.learning_rate)
c_error_opt_op = c_opt.minimize(losses['losses'], var_list=train_variables)6)init_train()运行完成
return summary, losses, c_error_opt_op至此,获得了2)中代码的返回值。
2.2.3 真实数据的one shot learning过程
至此获得了2.2.2下面第二条代码的返回值
return self.one_shot_learner, self.losses, self.c_error_opt_op, init #experiment.build_experiment返回值此时回到 train_meta_matching_network.py
total_c_loss, total_accuracy, lr = experiment.run_training_epoch(total_train_batches=total_train_batches,sess=sess)1)对真实数据的整理
进入到函数experiment.run_training_epoch()
x_support_set, y_support_set, x_target, y_target = self.data.get_train_batch(augment=True)进入Class MiniImageNetDataSet(或者data.py)中,从2.2.1节中介绍的data中随机选择出如下4个变量,后面表示各变量的大小。
x_support_set (32, 5, 4, 84, 84, 3)
y_support_set (32, 5, 4)
x_target (32, 84, 84, 3)
y_target (32,)x_target图片的类别再x_support_set中有,只是类的样本不同。
对support set中的所有图片进行了随机角度的旋转,target set的图片也进行了随机旋转。
2)训练模型
_, c_loss_value, acc = sess.run(
[self.c_error_opt_op, self.losses['losses'], self.losses['accuracy']],
feed_dict={self.keep_prob: 1.0, self.support_set_images: x_support_set,
self.support_set_labels: y_support_set, self.target_image: x_target, self.target_label: y_target,self.training_phase: True, self.rotate_flag: False, self.learning_rate: self.current_learning_rate})3. 代码思路的图形表示
主要描述loss()函数中的one shot learning过程。


















 3248
3248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









