 模型性能度量及评估指标介绍
模型性能度量及评估指标介绍








📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
AI 模型评估
3.2 模型的性能度量
对模型的泛化性能进行评估还需要衡量模型的泛化能力,这个过程就是所谓的性能度量。
性能度量反映了任务需求,在对比不同模型的泛化能力的时候,使用不同的性能度量可能会导致不同的评估结果,这说明模型的泛化能力是要在对应的任务需求中体现的,抛开模型的任务需求将很难评估模型的泛化能力。
这也能解释为什么要在3.3节中介绍多种基准测试,这也是针对不同泛化能力而建立的。在评估过程中,需要使用各种指标评估模型的准确性和效果,例如精度、召回率、F1分数等。
精度(Precision)是指模型正确预测的样本数量占总样本数量的比例,如式(3-1)所示。

(3-1)
其中,TruePositive(真阳性)指被分类器正确判断为正例的样本数量,FalsePositive(假阳性)指被分类器错误判断为正例的样本数量。
精度越高,说明模型的分类效果越好。
召回率(Recall)是指模型正确预测的正例样本数量占所有正例样本数量的比例,如式(3-2)所示。
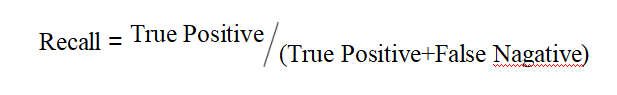
(3-2)
其中,FalseNegative(假阴性)指被分类器错误判断为负例的样本数量。召回率越高,说明模型对正例样本的覆盖率越高。
F1分数是指精度和召回率的调和平均值,如式(3-3)所示。

(3-3)
F1分数综合了精度和召回率两个指标,是一个综合性的评价指标。F1分数越高,说明模型的效果越好。
精度越高,说明模型的测试结果通常越可靠和准确;召回率越高,说明模型能够越好地捕捉到正例,即模型能够越多地识别出真正的正例;而F1分数是用于综合反映整体的指标。
我们当然希望检索结果精度越高越好,同时召回率也越高越好,但事实上它们在某些情况下是矛盾的。
比如极端情况下,只检索出了一个结果,且该结果是准确的,那么精度就是100%,但是召回率就很低;而如果我们把所有结果都返回,那么召回率是100%,但是精度就会很低。
因此在不同的情况下,你需要自行判断是希望精度比较高还是召回率比较高。在实验研究的情况下,可以绘制精度—召回率曲线来辅助分析。
现在仅仅完成了对精度、召回率、F1分数的介绍,读者可能还是很难理解如何使用这些指标来评估一个LLM。
在自然语言处理的评估中,有两个评估指标:一个是ROUGE,用于评估模型生成摘要的质量;另一个是BLEUSCORE,用于评估模型生成翻译的质量。这两个指标就是对如上指标的应用。
在详细解释这两个指标的使用方法之前,我们先给出如下定义:英文句子中,每一个单词叫作Unigram,连续两个单词叫作Bigram,连续3个单词叫作3-gram,以此类推,连续n个单词叫作n-gram。
假设有一个阅读并给出摘要的任务,人类阅读完成后给出的摘要是“the weather is very sunny”,模型生成的摘要是“the weather is fine”。
计算ROUGE-1的精度、召回率、F1分数,具体计算过程如下。

ROUGE-1的3个指标表示人类给出摘要和模型生成摘要的单词的不一致程度,但是有时候往往某个单词虽然不一样,表达的意思却相似。
我们可以使用Bigram来计算上面的3个指标,首先对人类给出的摘要和模型生成的摘要进行一些处理,如图3-7所示。
这样就按照Bigram对原来的摘要进行了划分,然后计算ROUGE-2的3个指标,具体计算过程如下。

图3-7 按照Bigram对原来的摘要进行划分的示意

可以看出ROUGE-2的指标相比ROUGE-1的指标都变小了,摘要越长,这个变化越大。如果要计算其他ROUGE的指标,可以执行相同的操作。
例如通过n-gram计算对应的ROUGE-n的指标,显然,n-gram越大,各指标越小。
为了避免这种无意义的计算,可以采用最长公共子序列
(LongestCommonSubsequence,LCS)划分摘要,如图3-8所示。

图3-8 采用LCS对原来的摘要进行划分的示意
按照LCS计算ROUGE-L的指标,具体计算过程如下。


虽然有多种ROUGE指标,但是不同的ROUGE指标没有可比性。n-gram的大小是由模型的训练团队通过多次实验决定的。
BLEUSCORE也是评估模型性能的指标之一,是n-gram计算精度指标的再计算,要得到BLEUSCORE,需要对一系列n-gram的精度指标进行求平均值的计算。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】




















 3518
3518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









