



特征工程的本质是:利用数据领域的相关知识,将原始数据转换为更能代表问题本质的特征(Feature),从而提升机器学习模型的预测性能。
1、特征工程过程
特征工程是一个综合性的过程,主要包括以下几个核心任务,其工作流和产出目标如下图所示:
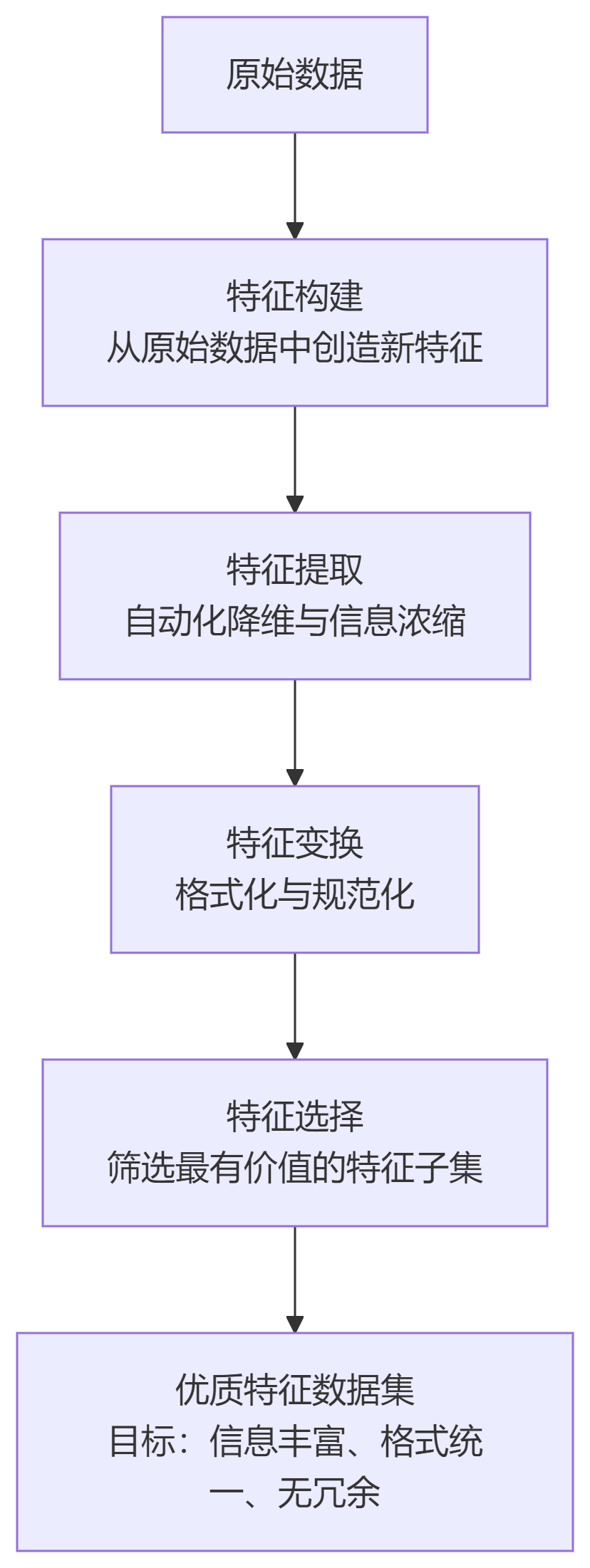
1.1、特征构建(Feature Creation)
-
做什么:将原始数据转化为模型可理解、可用的有效特征的过程。这需要领域知识和创造力。
-
目的:原始数据可能缺少明显的关系,新构建的特征可以更好地表达问题的本质。
-
例如:
-
从日期中提取:
年、月、日、星期几、是否周末、是否节假日。 -
从地址中提取:
城市、邮编、区号。 -
组合特征:在电商中,用“用户点击次数” / (“曝光次数” + 1) 来构建一个“点击率”特征,比单独使用两个特征更有效。
-
1.2、特征提取(Feature Extraction)
-
做什么:使用一些自动化的、通常是降维的方法,从高维、复杂的数据中提取出一组更少、但信息更密集的特征。
-
目的:处理非结构化的、高维的数据(如文本、图像),大幅减少计算量。
-
例如:
-
文本处理:使用TF-IDF或词嵌入(Word2Vec)将一篇文章转换为一个固定长度的数值向量。
-
图像处理:使用主成分分析或深度学习卷积层从图像像素中提取出“边缘”、“纹理”等高级特征。
-
1.3、特征变换(Feature Transformation)
-
做什么:对特征的数值或分布进行转换,使其符合模型的假设或提升性能。
-
目的:许多模型对数据的分布和尺度(量钢)有要求。
-
常见方法:
-
标准化:将数据变换为均值为0、标准差为1的分布。
(X - mean(X)) / std(X)。适用于许多基于距离的模型(如SVM、KNN)。 -
归一化:将数据缩放到一个固定的范围,通常是[0, 1]。
(X - min(X)) / (max(X) - min(X))。 -
对数变换:对偏态分布(如收入)的数据进行变换,使其更接近正态分布,同时稳定方差
-
1.4、特征选择(Feature Selection)
-
做什么:从所有特征中筛选出一个对目标变量预测最有效的特征子集。
-
目的:
-
减少过拟合:减少冗余特征和无关特征,使模型泛化能力更强;
-
提升效率:减少训练时间和计算资源;
-
增强可解释性:模型更简单,更容易理解。
-
-
常见方法:
-
过滤法:基于特征与目标的相关性(如卡方检验、相关系数)进行排序筛选。
-
包裹法:通过不断尝试不同的特征子集来训练模型,根据模型性能好坏来决定特征取舍(如递归特征消除RFE)。效果更好,但计算成本高。
-
嵌入法:将特征选择过程嵌入到模型训练中(如L1正则化/Lasso回归,它会自动将不重要特征的系数压缩为0)。
-
2、特征⼯程实例
2.1、数据集介绍
例如:使⽤ 乳腺癌威斯康⾟数据集:
- 样本数量:569 个
- 特征数量:30 个数值特征
- ⽬标变量:⼆分类(恶性/良性)
from sklearn.datasets import load_breast_cancer
if __name__ == '__main__':
X, y = load_breast_cancer(return_X_y=True)
print(f"特征矩阵形状: {X.shape}") # (569, 30)
print(f"⽬标向量形状: {y.shape}") # (569,)
2.2、特征标准化
数据标准化(归一化)的主要目的,是消除不同特征变量量纲级别相差太大,进而造成的不利影响,提高算法性能。数据标准化主要有两种实现方法:
2.2.1、Z-score标准化
也称均值归一化,通过原始数据的均值和标准差对数据进行标准化。标准化后的数据符合标准正态分布,即均值为0,标准差为1。
数学公式:
其中:
- μ是特征均值
- σ是特征标准差
from sklearn.datasets import load_breast_cancer
if __name__ == '__main__':
X, y = load_breast_cancer(return_X_y=True)
print(f"特征矩阵形状: {X.shape}") # (569, 30)
print(f"⽬标向量形状: {y.shape}") # (569,)
# 计算统计量
mu = X.mean(axis=0) # 各特征均值
sigma = X.std(axis=0) # 各特征标准差
# 标准化
X_standardized = (X - mu) / sigma
print(f"standard={X_standardized}")
或者(使用StandardScaler):
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
if __name__ == '__main__':
X, y = load_breast_cancer(return_X_y=True)
print(f"特征矩阵形状: {X.shape}") # (569, 30)
print(f"⽬标向量形状: {y.shape}") # (569,)
# 标准化
X_standardized = StandardScaler().fit_transform(X_train)
print(f"standard={X_standardized}")
标准化效果:
- 均值变为 0
- 标准差变为 1
- 消除量纲影响
2.2.2、其他规范化⽅法
Min-Max 标准化:利用原始数据的最大值和最小值,把原始数据转换到[0, 1]的区间内
# Min-Max 规范化到 [0,1] 区间
X_minmax = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
或者(使用MinMaxScaler):
from sklearn.preprocessing import MinMaxScaler
# Min-Max标准化
X_minmax = MinMaxScaler().fit_transform(X)
3、特征工程要点
标准化必要性:消除特征间的量纲差异
数据泄露防范:始终用于训练集统计量处理测试集
标准化方法:根据数据分布选择合适方法Z-score vs Min-Max等


















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











