




LightGBM(Light Gradient Boosting Machine)是微软开发的一个基于决策树算法的分布式梯度提升框架(也可以理解为XGBoost的分布式版本),专为高效性和大规模数据设计。
1、LightGBM算法原理
LightGBM 和 XGBoost 都是优秀的梯度提升决策树(GBDT)实现,但在速度和内存效率上,LightGBM 通常展现出显著优势。这主要源于LightGBM是一个实现GBDT算法的分布式高效框架。
- 树生长策略
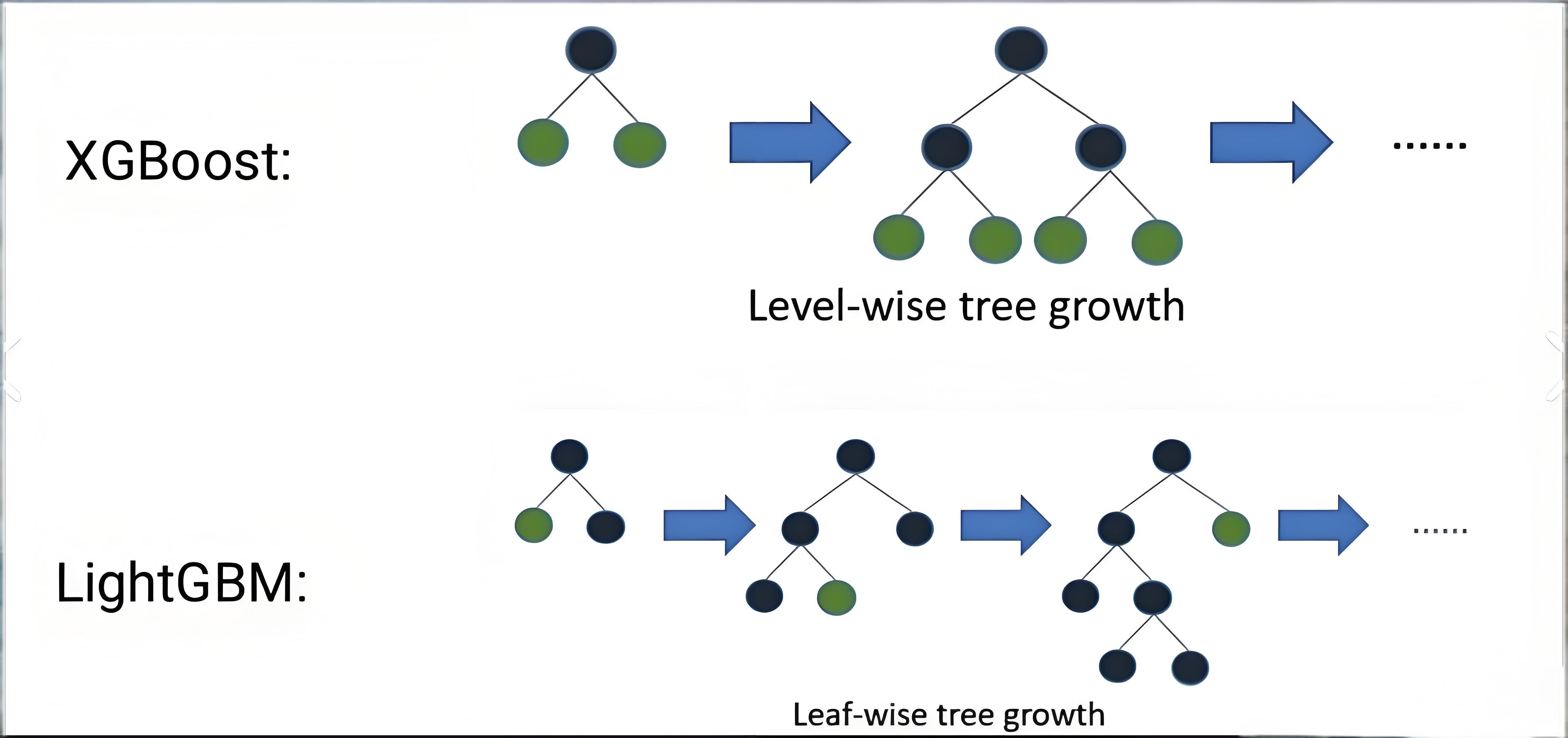
- 内存消耗更低
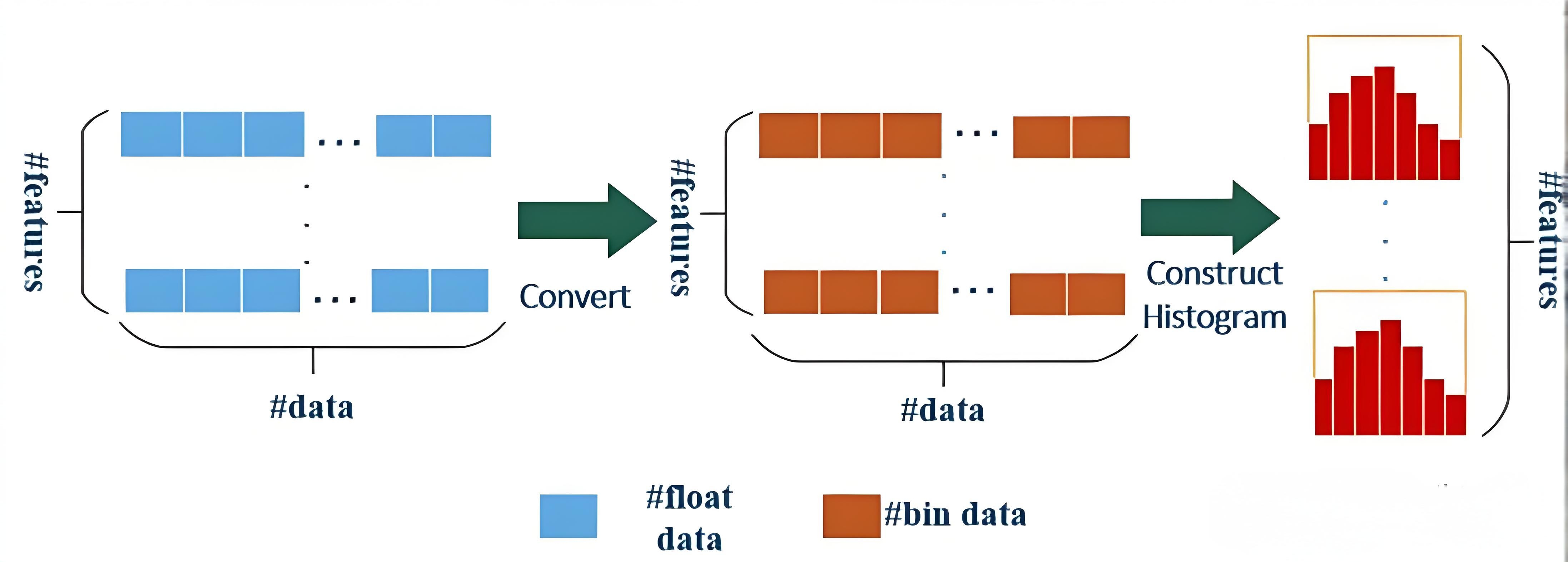
相较于XGBoost算法,LightGBM在内存和速度方面具有可观的优势:
| 特性维度 | XGBoost | LightGBM |
|---|---|---|
| 训练速度 | 相对较慢(尤其在大数据集上) | 更快(通过直方图、GOSS、EFB等技术优化,大数据集优势明显) |
| 内存消耗 | 相对较高 | 更低(直方图算法将特征值转变为bin值,且不需要记录特征到样本索引,极大减少了内存消耗) |
| 树生长策略 | Level-wise (按层生长) | Leaf-wise (按叶子生长) |
| 逐层分裂,平衡树结构,但计算开销大 | 每次分裂当前损失下降最多的叶子,效率高,但能加深树深度 | |
| 分裂点查找 | 预排序 (Pre-sorted) | 直方图 (Histogram-based) |
| 精确贪心算法,遍历所有特征和可能的分裂点 | 将连续特征离散化到桶中,只需遍历桶,大幅提速 | |
| 对类别特征支持 | 需手动处理(如独热编码),增加维度和计算负担 | 原生支持,可自动处理,更高效 |
| 大数据集优化 | 块结构(Block)存储支持并行 | GOSS(基于梯度的单边采样)和 EFB(互斥特征捆绑) |
| 适用场景 | 中小规模数据集,对精度和稳 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











