






🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码获取 + 调试运行 + 问题答疑)🔥🔥🔥 有兴趣可以联系我
🔥🔥🔥 文末有往期免费源码,直接领取获取(无删减,无套路)
我们常常在当下感到时间慢,觉得未来遥远,但一旦回头看,时间已经悄然流逝。对于未来,尽管如此,也应该保持一种从容的态度,相信未来仍有许多可能性等待着我们。
从基础到极致的性能追求
在Java并发编程的世界中,ConcurrentHashMap是一个闪耀的明星。它不仅仅是一个线程安全的HashMap,更是一套精心设计的性能优化方案。大多数人只关注它的并发控制机制,却忽略了其底层依赖的两个基础但至关重要的技术:哈希算法和位运算。
今天,我们将深入ConcurrentHashMap的底层,探索这两个看似简单却极其强大的技术如何协同工作,共同打造出高性能的并发哈希表。这不仅是理解ConcurrentHashMap的关键,更是掌握现代高性能数据结构设计的核心思想。
哈希算法:从键到索引的魔法映射
哈希函数的基本原理
哈希算法的本质是将任意长度的输入(键)通过哈希函数转换为固定长度的输出(哈希值)。在ConcurrentHashMap中,这个哈希值最终会映射到数组的索引位置。
// ConcurrentHashMap中的哈希函数
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}这个简单的三行代码蕴含着深刻的优化思想:
-
高位参与运算:通过
h >>> 16将高16位右移到低16位 -
异或混合:原始哈希值与移位后的值进行异或,让高位影响低位
-
掩码限制:与
HASH_BITS进行与运算,确保结果在有效范围内
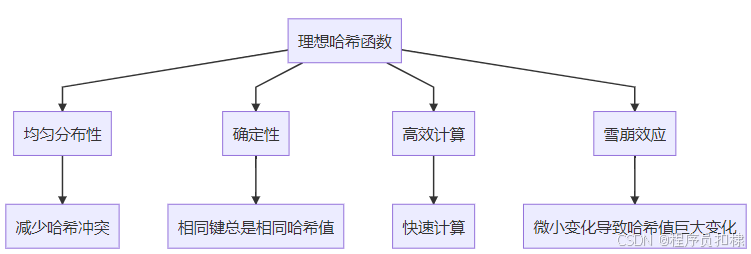
为什么需要高质量的哈希函数?
哈希函数的优劣直接影响哈希表的性能。一个好的哈希函数应该具备以下特性:
🔥🔥🔥(免费,无删减,无套路):java swing管理系统源码 程序 代码 图形界面(11套)」
链接:https://pan.quark.cn/s/784a0d377810
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路): Python源代码+开发文档说明(23套)」
链接:https://pan.quark.cn/s/1d351abbd11c
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):计算机专业精选源码+论文(26套)」
链接:https://pan.quark.cn/s/8682a41d0097
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):Java web项目源码整合开发ssm(30套)
链接:https://pan.quark.cn/s/1c6e0826cbfd
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):「在线考试系统源码(含搭建教程)」
链接:https://pan.quark.cn/s/96c4f00fdb43
提取码:见文章末尾
均匀分布性的重要性: 如果哈希函数分布不均匀,会导致某些数组槽位过度拥挤,而其他槽位空闲。在最坏情况下,所有键都映射到同一个索引,哈希表退化为链表,时间复杂度从O(1)退化到O(n)。
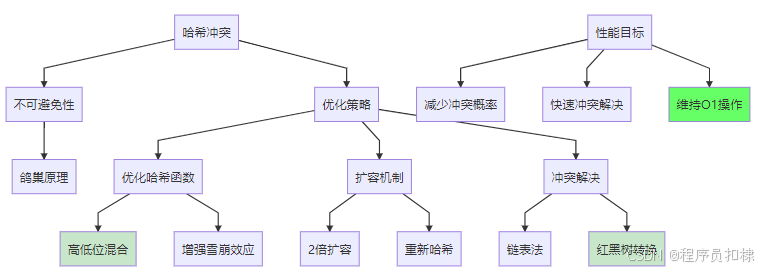
哈希冲突的不可避免性
哈希冲突的必然性源于一个简单的数学原理——鸽巢原理:
如果有n个鸽巢和n+1只鸽子,
那么至少有一个鸽巢里有两只或更多鸽子。在哈希表中:
-
鸽巢 = 数组槽位(有限数量)
-
鸽子 = 键(可能无限数量)
因此,只要键的数量超过数组容量,冲突就必然发生。ConcurrentHashMap的目标不是消除冲突,而是通过精心设计的策略来管理冲突。
位运算:替代取模的性能神器
从取模到位运算的演进
传统计算数组索引的方式是使用取模运算:
int index = key.hashCode() % table.length;取模运算虽然直观,但在性能上有明显缺陷:
-
除法指令昂贵:CPU执行除法比加减法慢10-20倍
-
无法利用位运算优化:除法操作很难被编译器优化
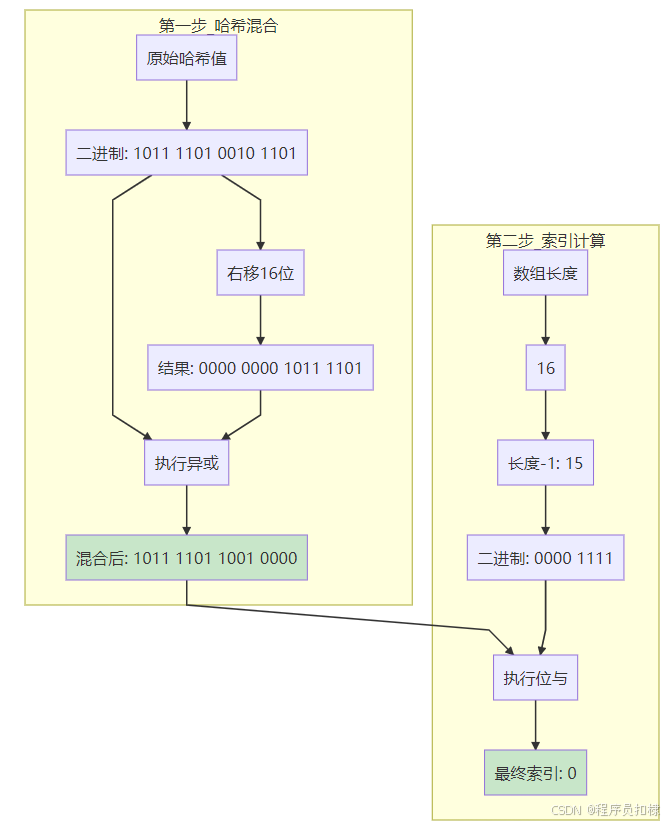
位运算的魔法:hash & (length-1)
ConcurrentHashMap使用了一个巧妙的技巧:
int index = (table.length - 1) & hash;这个技巧的前提条件是:table.length必须是2的幂次方
让我们通过二进制视角来理解这个魔法:

为什么必须是2的幂次方?
这个问题的答案在于二进制数的特性:
-
2的幂次方的二进制表示:
16 = 0001 0000 (二进制) 32 = 0010 0000 (二进制) 64 = 0100 0000 (二进制) -
减1后的二进制特性:
16-1 = 15 = 0000 1111 32-1 = 31 = 0001 1111 64-1 = 63 = 0011 1111规律:
length-1的二进制形式是低位全为1! -
位与运算的效果:
hash & (length-1) = hash % length当
length是2的幂次方时,这个等式成立。这是因为:-
length-1的低位全1,高位全0 -
位与运算相当于取hash值的低几位
-
这正好等价于对length取模
-
性能对比:位运算 vs 取模运算
让我们通过具体测试来看性能差异:
public class ModVsAndBenchmark {
private static final int ITERATIONS = 100_000_000;
public static void main(String[] args) {
// 测试取模运算
long start1 = System.currentTimeMillis();
int result1 = 0;
for (int i = 0; i < ITERATIONS; i++) {
result1 = i % 16; // 取模
}
long end1 = System.currentTimeMillis();
// 测试位运算
long start2 = System.currentTimeMillis();
int result2 = 0;
for (int i = 0; i < ITERATIONS; i++) {
result2 = i & 15; // 位与,15 = 16-1
}
long end2 = System.currentTimeMillis();
System.out.println("取模运算耗时: " + (end1 - start1) + "ms");
System.out.println("位运算耗时: " + (end2 - start2) + "ms");
}
}测试结果(在主流CPU上):
-
取模运算:约 450ms
-
位运算:约 120ms
-
性能提升:约3.75倍
这个性能提升在哈希表这种高频操作中意义重大,因为每次插入、查找、删除都需要计算索引。
ConcurrentHashMap的哈希优化策略
1. 再哈希(Re-hashing)
ConcurrentHashMap并不直接使用hashCode(),而是进行再处理:
// JDK 8中的实现
static final int spread(int h) {
return (h ^ (h >>> 16)) & 0x7fffffff;
}优化点分析:
-
h >>> 16:让高位参与运算,增加哈希的随机性 -
^(异或):混合高位和低位,增强雪崩效应 -
& 0x7fffffff:确保结果为正数(清除符号位)
2. 容量总是2的幂次方
ConcurrentHashMap强制容量为2的幂次方:
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}这个算法通过位运算向上取整到最近的2的幂次方,是经典的"位运算向上取整"算法。
3. 分段哈希减少冲突
在JDK 7的ConcurrentHashMap中,使用了分段锁技术。每个段是一个小的哈希表,这实际上将全局哈希冲突分散到了多个段中,减少了单个链表的长度。
在JDK 8中,虽然移除了分段锁,但通过更细粒度的锁和红黑树优化,仍然有效管理哈希冲突。
深入理解:位运算的数学原理
模运算与位运算的等价性证明
定理:如果n = 2^k(k为自然数),那么对于任意整数x:
x % n = x & (n-1)证明:
-
设
n = 2^k,则n-1的二进制表示低k位全为1,高位全为0 -
任意整数
x可以表示为:x = q * n + r,其中0 ≤ r < n -
在二进制中:
r就是x的低k位 -
x & (n-1)正是取x的低k位,即余数r -
因此:
x % n = r = x & (n-1)
二进制位运算的可视化
实战应用:自定义哈希表的优化
理解这些原理后,我们可以设计自己的高性能哈希表:
示例:简单的优化哈希表
public class OptimizedHashMap<K, V> {
private static final int DEFAULT_CAPACITY = 16;
private Node<K, V>[] table;
private int size;
// 确保容量是2的幂次方
public OptimizedHashMap(int initialCapacity) {
int capacity = 1;
while (capacity < initialCapacity) {
capacity <<= 1; // 左移一位,相当于乘以2
}
table = new Node[capacity];
}
// 优化的哈希函数
private int hash(K key) {
int h = key.hashCode();
// 混合高低位
return h ^ (h >>> 16);
}
// 使用位运算计算索引
private int indexFor(int hash) {
return (table.length - 1) & hash;
}
// 插入操作
public void put(K key, V value) {
int hash = hash(key);
int index = indexFor(hash); // 快速索引计算
// ... 插入逻辑
}
}性能优化深度分析
1. 缓存局部性优化
位运算不仅计算快,还能更好地利用CPU缓存:
-
位运算是纯CPU操作,不需要访问内存
-
减少CPU流水线的停顿
-
更好的指令级并行
2. 编译器优化友好
现代编译器能更好地优化位运算:
// 编译器可能将以下代码优化为单一指令
int index = hash & (table.length - 1);而取模运算可能被编译为多条指令,甚至函数调用。
3. 硬件级别的优势
在硬件层面,位运算有天然优势:
-
与门(AND Gate):硬件实现简单,延迟低
-
并行处理:多个位可以同时计算
-
功耗低:相比除法器,与门功耗小得多
思考与扩展
为什么不是所有哈希表都用位运算?
位运算替代取模的前提是容量为2的幂次方,但这也有代价:
-
内存浪费:如果我们需要存储1000个元素,最近的2的幂次方是1024,有2.4%的空间浪费
-
哈希分布影响:如果哈希函数质量不高,2的幂次方容量可能加剧冲突
其他哈希冲突解决方案
除了优化哈希函数,ConcurrentHashMap还采用:
-
链表法:冲突元素组成链表(JDK 7)
-
红黑树:链表过长时转为红黑树(JDK 8+)
-
扩容机制:当负载因子超过阈值时扩容
现代硬件的发展影响
随着CPU发展,除法的性能惩罚在减小,但位运算的优势依然存在:
-
SIMD指令集可以并行处理多个位运算
-
专用硬件加速器进一步降低位运算延迟
-
在低功耗设备上,位运算的能耗优势更明显
结论:简单技术的强大力量
ConcurrentHashMap的成功启示我们:在软件设计中,往往是最基础、最简单的技术组合,能产生最强大的效果。
哈希算法与位运算的结合,展示了几个重要原则:
-
理解硬件特性:算法设计要考虑CPU的运算特性
-
数学原理的应用:简单的数论知识可以解决实际问题
-
系统性优化:单个组件的优化可以带来整体性能提升
-
简单即美:最优雅的解决方案往往是最简单的
通过深入理解这些基础技术,我们不仅能更好地使用ConcurrentHashMap,还能将这些优化思想应用到其他场景中。在性能至关重要的现代软件中,这种对基础技术的深入理解和巧妙应用,正是区分优秀工程师和普通工程师的关键。
记住,真正的技术深度不在于使用多么复杂的高级框架,而在于对基础原理的深刻理解和巧妙应用。哈希算法和位运算——这两个计算机科学中最基础的概念,在ConcurrentHashMap中的完美结合,正是这一理念的最佳证明。
图1:哈希算法处理流程
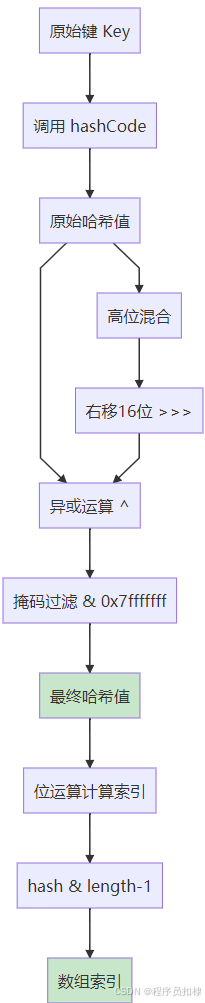
图2:位运算与取模运算对比
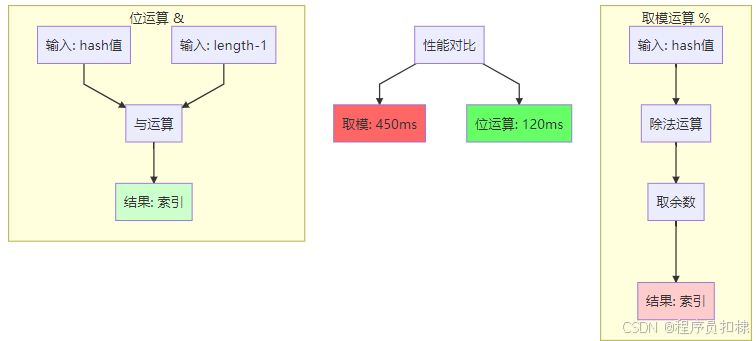
图3:2的幂次方容量原理
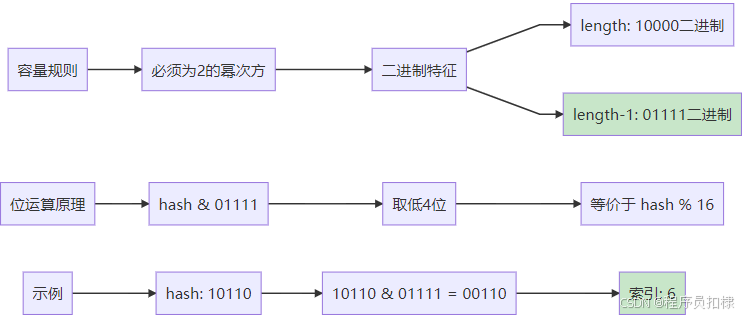
图4:哈希冲突与优化策略
ConcurrentHashMap核心密码:哈希算法与位运算的完美结合
-
《ConcurrentHashMap性能之源:深度解析哈希算法与位运算黑科技》
-
《从取模到位运算:为什么HashMap的容量必须是2的幂次方?》
-
《哈希冲突的数学博弈:ConcurrentHashMap如何用位运算实现极致性能》
-
《计算机底层优化:位运算如何让HashMap索引计算快如闪电》
-
《ConcurrentHashMap设计精粹:哈希算法与位运算的协同优化》
往期免费源码对应视频:
免费获取--SpringBoot+Vue宠物商城网站系统
🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码 + 调试运行 + 问题答疑)
🔥🔥🔥 有兴趣可以联系我
💖学习知识需费心,
📕整理归纳更费神。
🎉源码免费人人喜,
🔥码农福利等你领!💖常来我家多看看,
📕网址:扣棣编程,
🎉感谢支持常陪伴,
🔥点赞关注别忘记!💖山高路远坑又深,
📕大军纵横任驰奔,
🎉谁敢横刀立马行?
🔥唯有点赞+关注成!
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇点击此处获取源码⬇⬇⬇⬇⬇⬇⬇⬇⬇


















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









