



都2025年了,如果你还不懂什么是Token,可能就真的out了。这玩意儿堪称AI世界的硬通货、通行证、基础粒子——随便你怎么比喻都不为过。说人话就是:Token就是大模型处理文本时使用的最小单位。它不是汉字,不是词语,不是英文单词,而是一种介于字、词、字母之间的"三不像"。(是不是每次调用大模型必须碰到:消耗了多少Token?本文给大家八卦下Token到底是何方神圣)
首先想象一下乐高积木(举个栗子):
-
你要拼一个城堡,你不会直接用一个巨大的塑料块,而是用成百上千个标准的小积木块来拼接。
-
这些小积木块就是 Token。
-
整个城堡就是你输入或模型输出的一整段话。
模型的工作就是:看到你给的一堆积木(输入Tokens),然后预测下一块最应该放什么积木(输出下一个Token),如此反复,直到拼出完整的城堡(回复完整答案)。
Token 到底是什么样子的?(实际例子)
Token的拆分规则不完全等于我们生活中的“词”或“字”。它是由模型的分词器根据算法和大量数据训练后决定的。
规则1:常见的词通常是一个Token
-
猫->["猫"](1个token) -
apple->["apple"](1个token)
规则2:长词、不常见的词会被拆分成更小的部分
-
人工智能->["人工", "智能"](2个tokens) -
unfortunately->["un", "fortunately"](2个tokens)或
["un", "for", "tun", "ate", "ly"](更多tokens,取决于分词器)
规则3:标点符号、空格也可能是Token
-
你好!->["你", "好", "!"](3个tokens) -
"hello world"->["hello", " world"](注意第二个token前面有个空格)
规则4:单个字符(尤其是汉字)通常是独立的Token
-
我喜欢编程。->["我", "喜", "欢", "编", "程", "。"](6个tokens)
让我们看一个更复杂的例子:
输入句子: Transformer模型很强大!
可能会拆分为:["Transform", "er", "模", "型", "很", "强", "大", "!"]
英文单词 Transformer 被拆成了 "Transform" 和 "er",而中文“模型”被拆成了两个独立的字 "模" 和 "型"。
为什么要把文字变成Token?(为什么这么麻烦?)
-
效率与一致性:处理固定大小的“块”比处理可变长度的字符串对计算机来说更高效。
-
应对巨大词汇量:尤其是像中文这样的语言,字和词的组合几乎是无限的。通过拆分,模型只需要学习几千到几万个基本的Token,就可以组合出无数种表达,大大减少了模型需要学习的参数量。
-
处理未知词汇:如果模型遇到一个从来没见过的长词(比如一个新发明的科技术语),如果它认识组成这个词的各个部分(Token),它仍然可以尝试去理解和生成它。
这对我们使用大模型有什么实际影响?
理解Token非常重要,因为它直接关系到:
-
计算和成本:模型处理(读取和生成)的Token数量直接决定了计算量、API调用的费用(比如 OpenAI 按Token数收费)和响应速度。生成的文本越长,Token越多,耗时越长,花费越多。
-
上下文窗口限制:你肯定听说过“上下文长度”,比如“支持128K上下文”。这个128K指的就是模型能同时处理的Token总数(你的问题 + 历史对话 + 模型的回答全部加起来)。
-
例如,GPT-4 Turbo 的上下文窗口是 128k Tokens。一本中等长度的书大约有 10万个单词,约合 13万个Tokens。这意味着你几乎可以把整本书扔给模型让它处理。
-
如果你的对话(问题+回答)超过了这个Token限制,最早的那部分对话就会被“遗忘掉”。
-
-
中英文差异:一个重要提示:通常,一个汉字平均约占 1.5 ~ 2 个Tokens,而一个英文单词平均约占 1.3 个Tokens。
-
例如:“你好” 是 2个Tokens。
-
而同样意思的英文 “hello” 是 1个Token。
-
这意味着,用中文和模型交流,可能会“更费Token”,从而可能更耗资源/更贵。
-
如何查看一段话有多少个Token?
OpenAI 官方提供了一个非常方便的工具:Tokenizer工具
链接:https://platform.openai.com/tokenizer(可能被墙)
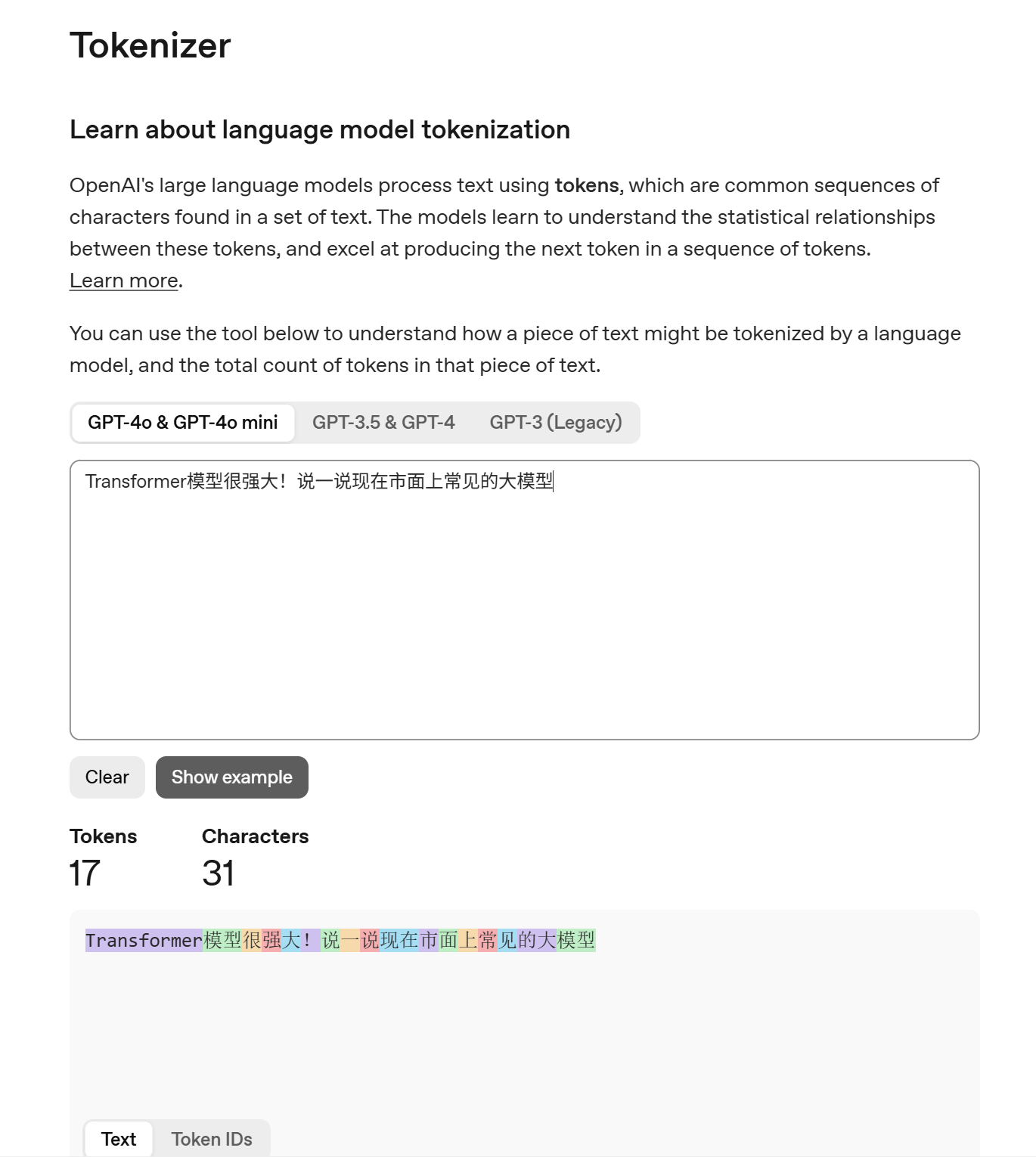
效果见上图,不同的色块代表的就是不同的Token。
总结下:Token就是大模型用来理解和生成文本的“基本积木块”。它不完全等于汉字或英文单词,而是根据算法拆分出的子词单元。Token的数量直接决定了模型的计算成本、记忆能力和响应限制。
收!下一篇给大家带来模型是怎么使用Token的!
欢迎大家关注我的公众号(优趣AI),后续给大家带来更多AI相关的知识分享!


















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











