



导读
在具身智能的研究版图中,视觉和语言已经成为“显学”。无论是让机器人看懂环境,还是通过指令理解任务,这两个模态几乎撑起了大多数热点工作。然而,如果机器人要真正走出实验室,在真实世界中稳定而灵巧地完成操作,仅靠“看”和“说”还远远不够。
人类之所以能够稳稳端起一杯水、精准拧开一个瓶盖,靠的并不仅是眼睛和大脑,还包括随时在反馈的触觉系统。触觉让我们在黑暗中也能找到开关,在复杂表面上分辨出软硬粗细。相比之下,今天的大多数机器人几乎是“无感之手”,缺乏这种被低估的能力。
因此,本文将聚焦于触觉这一模态在具身智能中的角色:它如何补足视觉与语言的不足、如何通过多模态融合提升机器人操作与交互能力,以及未来触觉可能引领的新方向。

▲图1|触觉在具身智能机器人的未来图景概览,重点突出在感知、处理与仿真方面的关键进展。材料与传感器转换器的创新将提升触觉数据采集能力,包括波形信号、触觉阵列(如电容阵列或磁性阵列)的数据,以及基于视觉的触觉传感器生成的触觉图像。触觉传感器预计将从指尖拓展至整个机器人身体,形成密集的触觉感知网络。该网络将支持本地与集中式处理,使机器人能够理解接触信息并相应地调整动作。触觉仿真也被预期将发挥越来越重要的作用,不仅支持新型传感器设计,还能实现预测性规划。总体而言,这些发展将推动机器人迈向类人化的触觉灵巧性,并展现广阔的应用潜力

相比于视觉和语言,触觉往往被忽视,但它对具身智能的重要性不言而喻。触觉不仅不同于单点的力/力矩传感器,更强调在空间上分布的接触信息。这意味着机器人可以像人类一样感知压力分布、摩擦变化和滑动趋势,从而在动态交互中获得实时反馈。
正是这些能力,让触觉成为机器人完成精细操作和安全交互的基础:它能避免物体滑落,判断材料的软硬,甚至在视觉受限的环境中独立支撑探索。换句话说,如果说视觉让机器人“看到”,语言让机器人“理解”,那么触觉就是让机器人真正“做得稳、做得巧”的关键一环。
在接下来的部分里,我们将具体盘点触觉模态的发展与方法,并重点探讨它如何与具身智能结合,推动机器人在操作、探索与人机交互中的突破。

在自然界中,皮肤是最庞大的感官系统:它不仅覆盖全身,还能感知压力、温度、疼痛与形变。受到启发,研究者们尝试为机器人打造“人工皮肤”,让它们也能通过触觉与外部世界互动。
1. 触觉材料:仿生的“机器人皮肤”
● 早期尝试使用泡棉、橡胶等柔软材料作为外层包覆,保证灵活性和可塑性;
● 后来发展出 电子皮肤(e-skin),在柔性材料中嵌入电阻、电容或压电元件,能够检测压力、温度和湿度;
● 光学触觉则使用透明弹性体,结合内部相机捕捉表面形变(如 GelSight、TacTip)。
这些设计让机器人不仅能“感受到”接触,还能在不同任务中获得差异化反馈。例如,柔软皮肤适合人机安全交互,而光学皮肤则更适合需要高分辨率的精细操作。
2. 传感方式:将物理刺激转化为“信号”
在具身智能应用中,最为常见的几种触觉传感器为:
● 压阻/压电传感:通过电阻或电荷的变化感知压力,响应快,适合动态信号;
● 电容式传感:大面积布设电容阵列,可覆盖机器人手臂或躯干;
● 磁传感:利用磁体位移感知接触力,反应灵敏响应速度极快;
● 光学触觉:最常见的研究方向,通过光照变化或标记点位移来重建接触形态,分辨率高,和视觉模态天然兼容。
每种方式都有优缺点:光学触觉能提供丰富图像数据,但需要较强算力实时解析;电容和压电传感成本低,但灵敏度或鲁棒性受限。因此在具身智能场景中,往往需要 混合与分布式设计,就像人类不同部位的皮肤有不同密度的感受器一样。

▲图2|由Daimon Robotics 公司联合研发的触觉传感器,其通过高分辨率的光学机构,感知接触表面微小的图像变化,生成高密度的触觉“图像”,从而让机器人具备类人的触觉能力
3. 与具身智能的关系
这些材料和传感方式并不是“孤立的工程成果”。它们决定了机器人在执行具身任务时的触觉表现:
● 在操作任务中,高分辨率的光学触觉可以帮助机器人精确感知滑动和力矩,避免“夹碎”或“掉落”;
● 在人机交互中,大面积分布的柔性皮肤能实时检测接触,保障安全;
● 在探索任务中,触觉传感可以补全视觉的盲区,让机器人在黑暗、烟雾或水下环境中依然能获得反馈。
可以说,触觉的基本形态就是具身智能触觉系统的“硬件地基”。有了这些“机器人皮肤”和“感知神经”,后续的数据解释、多模态融合和主动探索才有可能发生

▲图3|在灵巧手的技术演示中,一个非常直观体现性能的展示方式就是利用灵巧手去抓取非常“脆弱”的物体,比如说鸡蛋。这样的Demo可以展示出灵巧手在VLA等技术的加持下对于不同物体的通用抓取能力,而要保证灵巧手在抓取的过程中不会“用力太猛”,则需要触觉传感器的力反馈传感技术加持

如果说视觉和语言让机器人能够“看懂”和“听懂”,那么触觉则是让机器人能够真正“稳稳地做”。在具身智能的任务中,触觉的价值主要体现在三个方面:精细操作、复杂环境探索,以及人机交互与安全。
1. 精细操作:从“能抓住”到“抓得好”
视觉语言模型(VLM、VLA)可以为机器人提供目标信息,例如“去拧开瓶盖”。但在真正执行动作时,机器人往往会遇到力控上的瓶颈:要多大力度?什么时候停止?物体是否即将滑落?
● 力与滑动检测:触觉信号能捕捉压力分布与切向力的变化,从而判断物体是否稳定。比如通过检测振动或皮肤表面拉伸来识别“打滑”,让机器人在掉落前进行力的调整。
● 软硬度与材质辨别:按压时的受力变化可以区分软橡胶与硬塑料;触觉图像的细微纹理则能帮助机器人识别布料差异。对于需要柔顺处理的任务(如医疗机器人夹持组织、服务机器人端送玻璃杯),这种能力至关重要。
● 三维重建与姿态估计:一些光学触觉传感器(如 GelSight、TacTip)甚至能在局部接触下重建物体表面形状,结合视觉模型修正三维几何信息。这让机器人不仅能“摸出边界”,还能根据边缘姿态进行闭环控制。
这些能力共同弥补了视觉单模态的不足,使机器人从“能完成抓取”迈向“能稳定、精准地操作”。
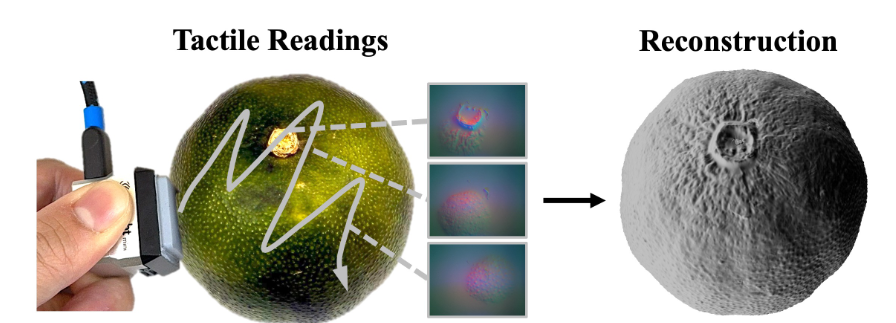
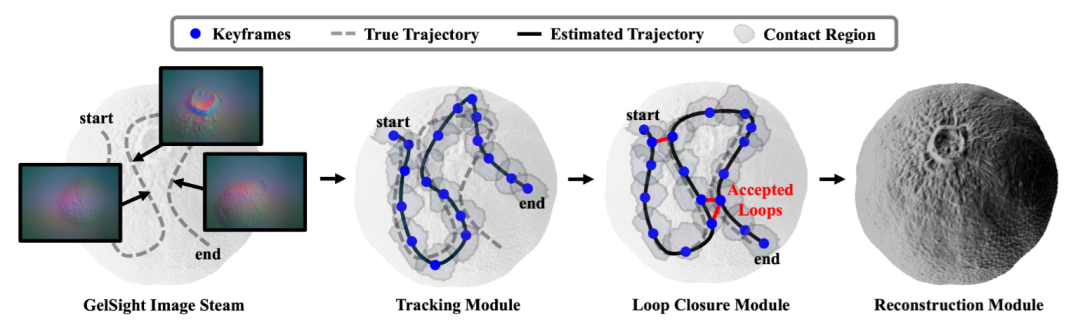
▲图4|一个基于触觉的SLAM 及重建流程:首先,图像流经过跟踪模块处理,用于估计物体位姿并在轨迹中选择关键帧。每一个新的关键帧会传递至回环检测模块,用于识别重复访问(回环)。随后,通过结合跟踪与回环信息的位姿图优化,计算得到全局一致的轨迹。最后,重建模块利用优化后的位姿对局部触觉片段进行配准,并将其融合为最终的三维模型
2. 探索与导航:在视觉失效时依然可靠
人类在黑暗中会用手沿墙摸索前进,机器人也可以如此。触觉在探索类任务中,是视觉的关键补充:
● 在遮挡和极端环境下生效:农业采摘中,叶片常常遮挡水果;灾后救援或地下矿井场景中,烟雾与灰尘让相机失灵。触觉传感器则能直接通过接触来定位物体,避免视觉盲区。
● 主动触觉探索:“active touch”概念——机器人通过挤压、滑动、轮廓跟随等主动动作获取更多信息。这种“边摸边学”的策略,不仅让机器人获得纹理与几何信息,还能在交互中建立更稳健的环境模型。
● 与控制闭环结合:触觉数据往往需要实时处理,例如在多指手操作时,每一次接触都可能改变整体受力分布。借助深度学习或贝叶斯推理,触觉信号可以直接驱动控制策略,让机器人能在不确定环境中保持稳定。
因此,触觉不仅是“备用方案”,更可能在极端环境下成为机器人具身智能的核心感知。
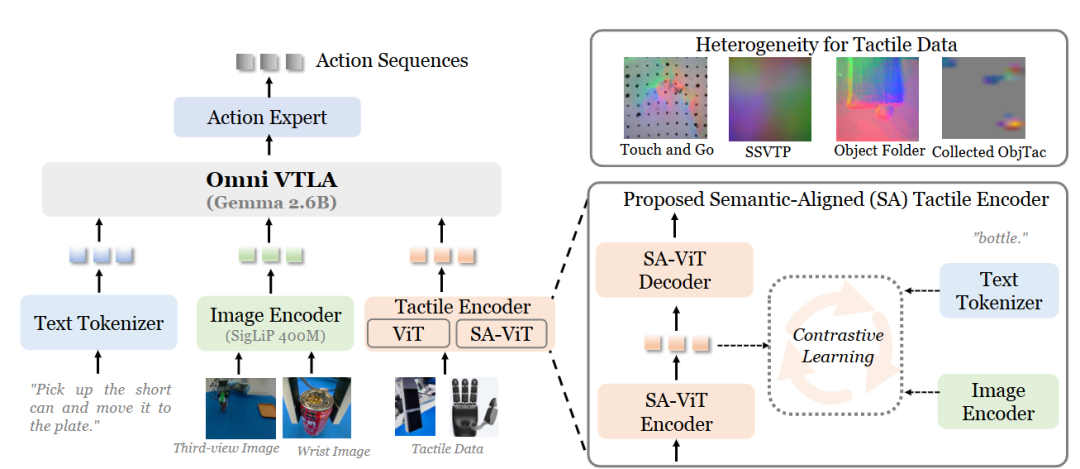
▲图5|VTLA(结合了触觉信息的VLA)框架:该方法集成了双 ViT 编码器以处理触觉数据,旨在解决视觉与触觉数据之间以及不同触觉传感器之间的固有异质性。第一个 ViT 利用预训练的视觉编码器,从大规模图像数据中继承丰富的语义表征。第二个 ViT(SA-ViT)通过跨模态对比学习进行专门训练,实现触觉、视觉和文本模态之间的语义对齐
3. 多模态融合:从“视觉+语言”到“三模态智能”
视觉和语言在过去几年被证明可以结合出强大的语义理解能力,但在实际执行时,触觉的缺席导致了“纸上谈兵”。实际上,视觉和触觉具有天然互补性:
● 视觉提供全局、远距离的信息;触觉提供局部、细节的反馈。
● 融合方式包括特征拼接、对比学习、注意力机制,甚至点云对齐(用触觉修正物体姿态)。
● 在跨模态生成上,已有工作能从视觉图像合成触觉信号,或者反过来从触觉预测视觉效果。
未来的方向,则是构建 触觉-视觉-语言三模态大模型。想象一下,机器人不仅能理解指令“请把桌子上的玻璃杯递过来”,还能在执行过程中实时用语言反馈:“杯子有些湿滑,我换一种握法更安全。” 这种语义化触觉能力,将是具身智能迈向“自然交互”的关键。
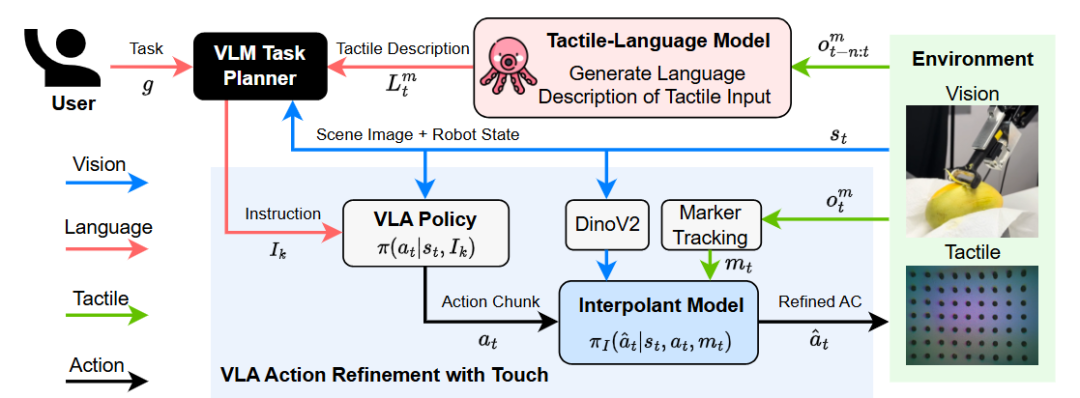
▲图6|一个结合了触觉的多模态融合框架,基本架构和当前的VLA非常类似,但是通过独有的Tactile-Language Model对触觉输入进行了额外的编码,最终将触觉这一模态与语言模态对其,从而赋予了模型对触觉的理解能力
4. 人机交互与安全:赋予机器人“感受力”
随着人形机器人和服务机器人的发展,安全性和自然交互愈发重要。全身覆盖的触觉皮肤,让机器人能:
● 在与人接触时感知力度,避免危险碰撞;
● 在协作时检测和顺应人的动作;
● 在医疗康复等场景中实现柔顺、可靠的物理交互。
实际上类似的人机交互场景还有很多很多,如果说视觉+语言能够让机器人逐渐从实验室走向社会,从定制走向通用,那么触觉则可以赋予机器人更高层的与人类生活的物理世界进行交互的能力。

▲图7|由Meta与GelSight公司联合研发的一种人造手指形状的触觉传感器,它通过以人类级别的精度对触摸进行数字化,能够提供丰富而详细的触觉数据,赋能各种类型的具身智能任务

尽管触觉在具身智能中的潜力已经被广泛认可,但要真正发挥这一模态的价值,仍面临几方面的关键挑战:
1. 硬件层面:耐用性与规模化不足
目前的触觉传感器在灵敏度和分辨率上已有显著进步,但仍存在耐久性差、制造成本高、加工依赖人工等问题。对于需要长时间运行的人形机器人或群体机器人来说,触觉皮肤必须既轻便又坚固,并能在全身范围内大规模布设。
2. 数据层面:缺乏大规模、标准化的触觉数据集
视觉和语言的突破离不开大数据的支撑,但触觉数据的获取极其昂贵,还容易因传感器损坏而中断。目前的触觉数据集往往规模有限、场景单一,缺乏统一的基准。如何构建开放、可复现的触觉数据集,是推动触觉进入“大模型时代”的关键前提。
3. 算法层面:建模复杂且实时性不足
触觉信号具有强烈的时空特征:同一个动作中,压力分布、滑动趋势和力矩变化往往交织在一起。这种复杂性使得建模困难,更对实时推理提出了挑战。相比视觉和语言,触觉的深度模型不仅算力消耗大,还难以迁移到不同类型的传感器
4. 未来展望
触觉与视觉、语言并非竞争关系,而是互补关系。未来的具身智能有望在统一的表示空间内整合三类信息:
● 视觉负责场景全局理解;
● 语言提供语义目标与任务约束;
● 触觉在执行过程中实时补充细节与安全反馈。
随着传感器制造、仿真平台和多模态学习的不断进步,触觉或将成为继视觉、语言之后的第三个主流模态,让机器人不再是“眼高手低”,而是真正具备 看、说、做、感 的全能体

触觉并不是机器人研究里的“新鲜词”,但在具身智能的语境下,它正被重新认识。没有触觉,机器人就像蒙着手套完成任务,始终难以达到人类的灵巧和稳健;而当触觉与视觉、语言融合在一起时,机器人才真正拥有了“感受世界”的完整能力。
未来,我们或许会看到更多具备“皮肤”的机器人:它们能分辨物体的软硬粗细,能在黑暗或遮挡下摸索前进,也能在人机交互中做到安全而自然的协作。触觉,这个曾经被低估的模态,正在成为具身智能走向成熟的关键拼图。
那么问题来了——在你看来,机器人最应该先在哪些场景里具备触觉?是医疗操作、服务协作,还是极端环境探索?欢迎在评论区聊聊你的看法。
参考文献
VLA-Touch: Enhancing Vision-Language-ActionModels with Dual-Level Tactile Feedback【https://arxiv.org/pdf/2507.17294】
OmniVTLA: Vision-Tactile-Language-Action Modelwith Semantic-Aligned Tactile Sensing【https://arxiv.org/pdf/2508.08706】
GelSLAM: A Real-time, High-Fidelity, and Robust3D Tactile SLAM System【https://arxiv.org/pdf/2508.15990】
Tactile Robotics: An Outlook【https://arxiv.org/pdf/2508.11261】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









