



传统的机器人操作系统普遍采用分阶段的开发模式:数据收集--模型训练--任务评估的流水线模式,每个环节都需要定制化设备、人工整理数据,还要针对具体任务反复调试,这种碎片化的架构增加了开发复杂度,延长了迭代周期,也限制了系统的可扩展性。 然而,由智元Genie团队推出的Genie Envisioner平台,将未来帧预测、策略学习与仿真评估首次整合进以视频生成为核心的闭环架构,使机器人在同一世界模型中完成从“看”到“想”再到“动”的端到端推理与执行。Genie Envisioner可以分解为4个核心部分,简单来说就是:
GE-Base:该部分是Genie Envisioner架构的感知基础,可以根据指令、视觉观测和历史记忆来“脑补”出未来机器人执行的视频
GE-Act:该部分是Genie Envisioner的动作生成模块,它将从GE-Base“脑补”的视频中提取出合理的执行动作
GE-Sim:该模块是一个仿真器,用于闭环评估和可控数据生成
EWMBench:世界模型的标准化评估套件
项目主页:https://genie-envisioner.github.io/
代码地址:https://github.com/AgibotTech/Genie-Envisioner
项目代码的核心结构如下:
Genie-Envisioner/
├── configs/ltx_model/ # 模型配置文件
│ ├── video_model.yaml # GE-Base配置
│ └── policy_model_lerobot.yaml # GE-Act配置
├── models/ # 模型实现
│ ├── ltx_models/ # 基于LTX-Video的模型
│ └── pipeline/ # 生成流程
├── scripts/ # 训练和推理脚本
├── data/ # 数据处理工具
└── main.py # 主程序入口

接下来,小编将详细解说下Genie Envisioner的四大核心模块:
GE-Base
GE-Base是整个平台的"地基",它采用视频扩散模型(Video Diffusion Model),并在AgiBot-World-Beta数据集上进行训练,这个数据集包含了100多万个真实世界机器人操作episode(总时长近3000小时),涵盖household任务(做饭、擦桌子)和工业任务(包装、搬运)。简单来说,这个模型的作用就是以语言指令和多视角视觉观测(头、左手、右手摄像头)为条件,自回归地生成未来的视频片段,以帮助GE-Act从中生成具身动作轨迹。所以整个过程可以表示成:
用直白的语言解说下上面的公式:左边其实就是预测的未来t步的视频,
是GE-Base的世界模型,可以无缝集成多种基于扩散Transformer(DiT)的视频生成模型,参数
就是长期历史帧构建的稀疏记忆,
分别就是几个摄像头采集的图像和用户指令了,这个公式表达的是:利用世界模型,结合稀疏记忆、用户指令、多图像观测信息,生成预测视频的过程
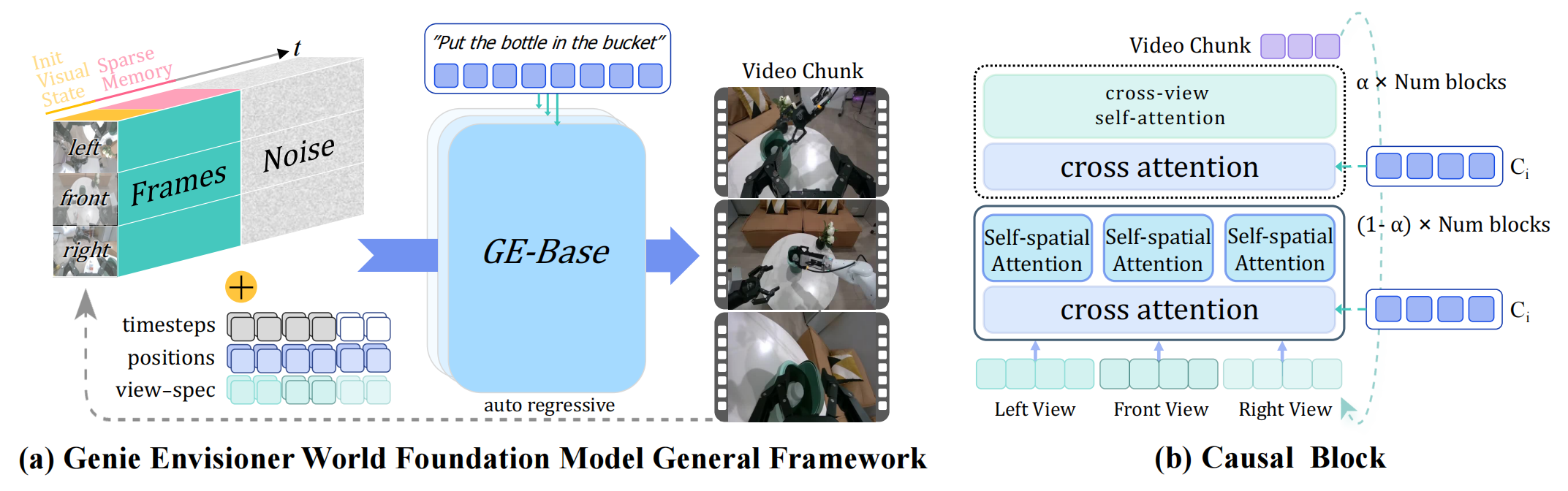
▲图1|这是GE-Base世界基础模型的概述。(a)部分是自回归视频生成过程示意图。给定多视图视觉条件(包括初始观测和稀疏记忆),以及相应的噪声和位置嵌入,模型会在语言指令的条件下生成下一个多视图视频块。(b)部分是一个专用的因果块可促进不同视图之间的信息交换,确保在多视图视频块生成过程中实现空间一致性。
● 训练
GE-Base的训练采用了两阶段策略:
第一阶段:多分辨率时序自适应 (Multi-Resolution Temporal Adaptation)
首先在3-30Hz的多分辨率采样频率下进行时序适应训练(GE-Base-MR),使模型对不同运动速度具有鲁棒性;
第二阶段:低频策略对齐 (Low-Frequency Policy Alignment)
随后在5Hz固定采样率下进行策略对齐微调(GE-Base-LF),与下游动作建模的时序抽象保持一致,为后续的策略学习奠定基础。
代码实现
在configs/ltx_model/video_model.yaml中配置GE-Base的训练参数:
data:
train / val:
# 数据集的根目录路径
data_roots: ["path/to/agibot-world/AgiBotWorld-Beta", ]
# 任务信息的存储路径,包含每条数据对应的自然语言指令、子任务标注等语义信息,用于将视频序列与任务指令对齐
task_info_root: ["path/to/agibot-world/AgiBotWorld-Beta/task_info", ]
# 数据集所属的领域标签(此处为"agibotworld"),用于区分不同来源的数据集(如其他机器人平台或场景的数据),方便后续扩展多领域训
domains: ["agibotworld", ]
# 数据集元信息(如视频长度、帧速率、任务类型等)的缓存路径。首次加载数据时会生成这些元信息,缓存后可加速后续训练的启动速度。
dataset_info_cache_path: "path/to/save/dataset_meta_info_cache"
# 预训练模型路径
pretrained_model_name_or_path: PATH/TO/PRETRAINED_WEIGHTS_OF_VAE_AND_TOKENIZER
# 生成视频的扩散模型配置
diffusion_model:
model_path: PATH/TO/GE_base_{version}.safetensors
训练GE-Base的脚本命令:
bash scripts/train.sh main.py configs/ltx_model/video_model.

▲图2|GE-Base训练过程概述。GE-Base在AgiBot-World-Beta数据集上进行预训练,该数据集是一个大规模的真实世界双臂机器人操作数据集,包含100万个与指令对齐的多视图视频序列。训练第一阶段多分辨率时序自适应 (Multi-Resolution Temporal Adaptation) ,利用高帧率序列和混合采样策略将通用视频生成能力迁移到机器人领域,以增强鲁棒性。第二阶段:低频策略对齐 (Low-Frequency Policy Alignment) ,目的是使模型与下游动作策略训练所需的时间分辨率保持一致。在整个过程中,视频编码器和视频解码器保持固定。
GE-Act
GE-Act负责把GE-Base生成的视频潜变量,转化为机器人能执行的具体动作轨迹。
它的设计非常巧妙,关键的创新在于异步推理机制,即GE-Act与GE-Base的视觉主干并行,GE-Base视频DiT以5Hz的频率执行单步流匹配去噪,生成的视觉潜在标记被缓存复用;而GE-Act动作模型则以30Hz的高频运行,基于缓存的视觉表征进行5步去噪。这种"慢-快"双层优化策略,实现了视觉处理与动作生成的高效解耦,不仅显著降低了视频潜在空间的维度计算开销,更确保系统能在机载NVIDIA RTX 4090 GPU上,以200毫秒的延迟完成54步动作轨迹推理,为实时机器人控制提供了坚实的技术支撑。
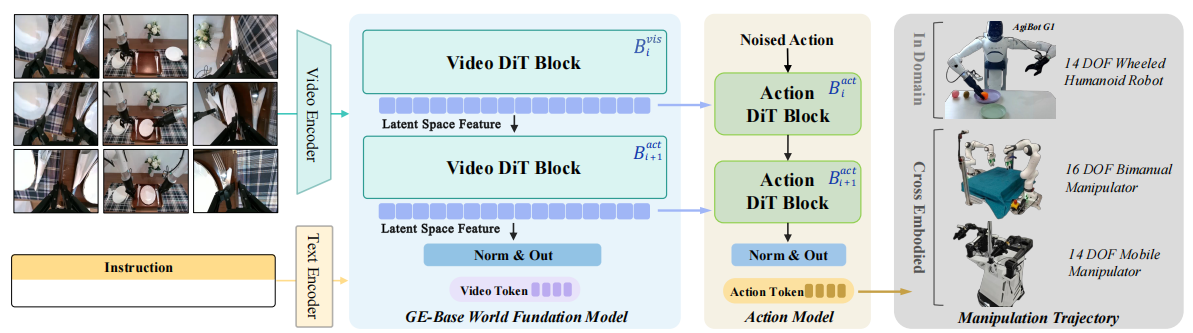
▲图3|这是GE-Act世界动作模型概述。GE-Act通过纳入一个并行动作分支对GE-Base基础模型进行了扩展,该分支可将视觉潜在表征转化为结构化的动作策略轨迹。它采用与GE-Base相同的模块设计和深度,但减小了隐藏维度以提高效率。视觉潜在特征通过交叉注意力机制整合到动作路径中,确保动作的语义接地。最终的动作预测通过基于扩散的去噪流匹配管道生成,将带噪声的动作预测优化为连贯的动作轨迹。
● 训练
GE-Act的训练体系采用三阶段递进式设计:
● 在动作预训练阶段,通过优化视觉主干网络,将视频序列的视觉表征精准投射至潜在的动作策略空间;
● 进入任务特定视频适应阶段后,仅更新世界模型的视觉生成组件,使其适配特定任务的视觉特征;
● 最终在面向特定任务的动作微调阶段,对包含GE-Base主干与动作模块的完整模型进行专属训练,以捕捉细粒度的控制动态。
代码实现
数据预处理:参考lerobot官方文档(https://github.com/huggingface/lerobot)构建数据集格式,结合AgiBot-World的convert_to_lerobot(https://github.com/OpenDriveLab/AgiBot-World/blob/main/scripts/convert_to_lerobot.py)计算数据集中的动作的静态信息(标准差),然后填到data/utils/statistics.py里面
再进行GE-Act的配置文件configs/ltx_model/policy_model_lerobot.yaml关键设置:
data:
train / val:
# 数据集的根目录路径
data_roots: [ROOT_PATH_TO_YOUR_DATASETS, ]
# 数据集所属领域标签,用于区分不同任务或场景的数据集
domains: [DATASETNAME, ]
# 有效的相机视图列表,指定模型需要处理的视觉输入来源
# "observation.images.top_head":头显相机(全局场景视角)
# "observation.images.hand_left":左臂腕部相机(左侧操作视角)
# "observation.images.hand_right":右臂腕部相机(右侧操作视角)
valid_cam: ["observation.images.top_head", "observation.images.hand_left", "observation.images.hand_right"]
# 数据集中动作数据的字段名(此处为"action")
action_key: "action"
# 机器人状态数据的字段名
state_key: "observation.state"
# 动作的表示类型
# "absolute":绝对坐标(如末端执行器在世界坐标系中的位置)
# "delta":相对变化量(当前动作相对于上一步的位移 / 旋转)
# "relative":相对目标的偏移(相对于目标位置的差距)
action_type: "absolute" # 可选"absolute", "delta"或"relative"
# 动作空间类型(此处为"joint"),表示动作基于关节控制(如关节角度、扭矩)
# 若为"eef",则表示动作基于笛卡尔空间(如末端执行器的位姿)。
action_space: "joint"
# 配置模型输出动作轨迹(而非视频),这是GE-Act的核心功能:将视觉潜在映射为可执行的动作指令,而非生成视频片段
return_action: True
# 禁用视频生成功能,减少计算开销(GE-Act专注于动作预测,无需显式生成视频)。
return_video: False
diffusion_model:
config:
# 启动动作专家,使模型专注于学习精细动作轨迹的特征,确保运动平滑,灵巧
action_expert: True
训练 GE-Act 的命令:
bash scripts/train.sh main.py configs/ltx_model/policy_model_
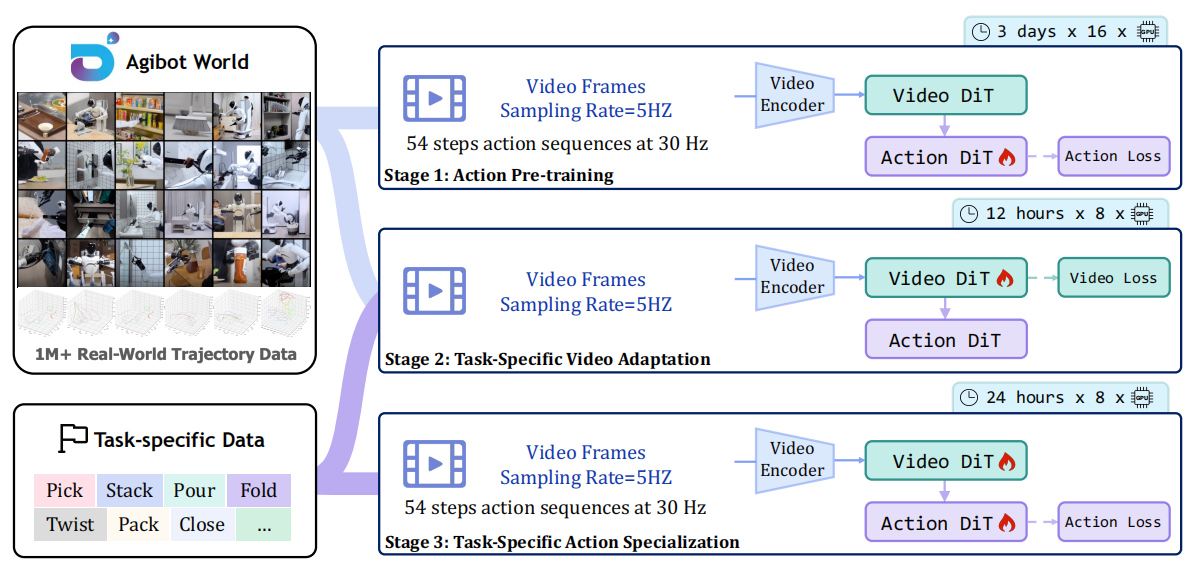
▲图4|GE-Act训练流程概述。GE-Act源自GE-Base基础模型,其训练过程分为三个阶段,利用了AgiBot-World-Beta数据集中的文本-视频-策略三元组。第一阶段进行动作空间预训练,对视觉主干网络进行优化,以将视频序列投射到潜在的动作策略空间中。随后,执行两阶段的任务适配流程,使模型专门适用于各种下游任务。在此阶段中,首先利用特定任务的视觉数据对视频编码器进行适配,之后再利用相应的控制信号对动作头进行微调。
GE-Sim
在真实世界训练机器人成本高、风险大(比如打翻热水),GE-Sim就是一个动作条件神经模拟器,它能让机器人在虚拟世界"练手"。该模块包含了两个关键组件:
Pose2Image条件:将7维末端执行器姿态(位置、姿态、夹爪状态)投影到图像空间,通过相机标定生成空间对齐的姿态图像;
运动向量条件:计算连续姿态间的运动增量,编码为运动令牌并通过交叉注意力注入到每个DiT块中。
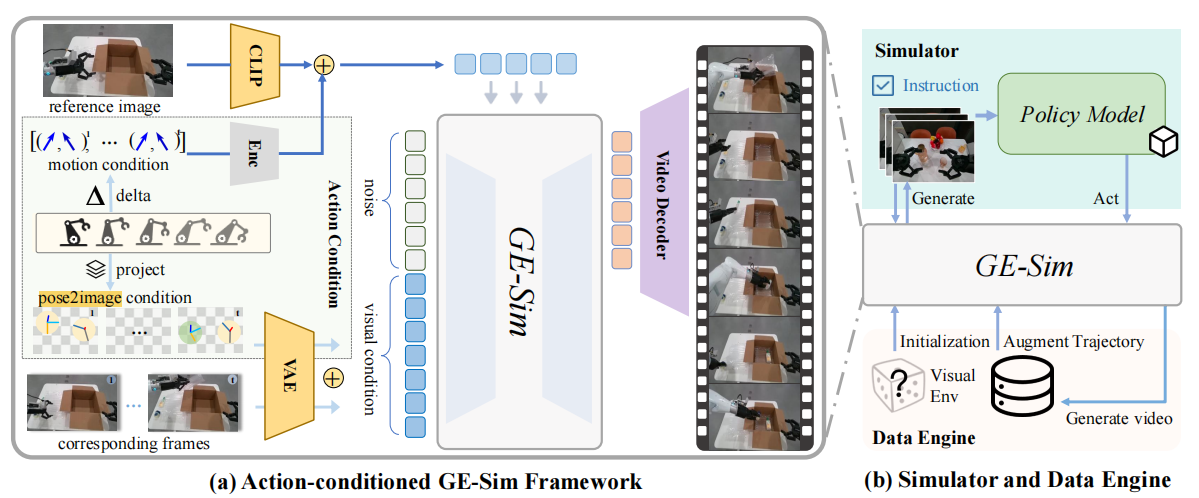
▲图5|GE-Sim世界模拟器概述。(a)GE-Base被转化为一个动作条件视频生成器,用于在给定预测动作的情况下模拟机器人行为。空间姿态条件被投射到图像空间,并与历史视觉输入融合,而时间运动增量则与参考图像拼接以保持风格一致性,并通过交叉注意力注入生成模型。(b)GE-Sim通过生成动作条件的视频滚动序列,实现闭环策略评估和可控数据生成,支持在不同视觉环境下遵循指令并进行一致的轨迹重放。
EWMBench
为了评估面向具身任务的世界模型质量,团队在GE核心组件之外还开发了EWMBench,EWMBench是一套标准化评估套件,它从三个维度严格打分:
● 视觉保真度:生成的视频画面是否清晰、多视角是否一致?
● 物理一致性:动作是否符合物理规律?比如抓起物体后不会凭空漂浮。
● 指令-动作对齐:是否真的按指令完成任务?比如"红色糖果用红色印章"不会搞错。
更重要的是,它的评分和人类判断高度一致,避免了"机器觉得好但实际用不了"的问题。

● 模型预测动作验证命令:
bash scripts/infer.sh main.py \
configs/ltx_model/policy_model_lerobot.yaml \
path/to/trained/checkpoint.safetensors \
path/to/save/outputs \
DATASETNAME
● 项目提供了一个简单的部署脚本,启动一个websocket服务和基于openpi的客户端,web服务接收客户端的观测信息后,调用模型完成推理
启动GE-Act服务器:
# 修改$IP_ADDRESS_OF_SERVER为实际IP,$DOMAIN_NAME为数据集名称
bash web_infer_scripts/run_server.sh
启动客户端:
bash web_infer_scripts/run_simple_client.sh

Genie Envisioner的意义,在于它为机器人操作提供了一个统一、可扩展的基础平台。过去,机器人可能需要为每个任务单独训练;未来,基于这个平台,机器人能像人类一样"举一反三",通过少量数据适应新任务、新环境。团队表示,所有代码、模型(目前已开源)和EWMBench评估套件都将开源,这意味着全球研究者能在这个基础上继续优化,让机器人更快走进家庭、工厂、服务场景。或许不久的将来,我们家里的机器人不仅能做饭、打扫,还能看懂菜谱创新菜式;工厂里的机械臂能快速切换生产线,应对柔性制造需求。Genie Envisioner,正让"通用机器人助手"的梦想越来越近。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









