



在刚刚落幕的 2025 世界人工智能大会(WAIC)上,一项突破性成果引发广泛关注:
北京人形机器人创新中心首次公开展示的工业级「多智能体协同系统」,凭借四台机器人在分布式 “慧思开物” 平台支撑下,实现了异步任务分发、动态调度与自然语言沟通的高效协同,成功覆盖电控柜操作、质检、封装全流程,据悉任务成功率超 90%。

▲图例:机器人在电控柜操作区,接收到“慧思开物”的指令后,自主完成开柜、点按旋钮、合闸等灵巧作业。
众所周知,近年来,深度学习、强化学习及 LLMs 的成熟,推动了具身智能在单智能体任务(如无人机避障、机械臂操作)上的突破。
然而,现实世界的复杂挑战——
如智能制造中的多机械臂协作、自动驾驶中的多车辆动态协调——往往超出单智能体的能力范畴。
这些场景要求智能体不仅能感知环境,更要与其他智能体(包括人类)高效协作,从而催生了多智能体具身智能(Multi-Agent Embodied AI)研究的兴起。
本文将系统性的解析多智能体具身智能,包括7项关键技术、8大基准测试,并探讨其面临的挑战与未来方向。

多智能体系统研究主要侧重于如何实现高效的多机协作。
本节内容将从:基于控制的方式、基于学习的方式和基于大模型的方式这3个方面进行阐述,分析多智能体协作的研究进展。
基于控制的方式
在多智能体协作系统中,基于传统控制的方法是结合任务约束下的一种高精度、实时决策的基础手段,其控制任务的分配方式包括:集中式控制、分布式控制和混合式控制。
-
集中式控制
早期的集中式控制通过全局控制器来统一规划所有智能体的行动,这种方案适用于小规模系统。
例如,仓库中3-5台机器人的路径规划问题中,可通过集中式算法(如混合整数规划)实现最优调度。
但该方法的局限性显著——当智能体数量增至数十个时,计算复杂度呈指数增长,难以满足实时性要求。
-
分布式控制
为解决集中式控制面临的瓶颈,分布式控制策略应用而生——独立控制多智能体系统中的每个智能体,使其更适用于大规模多智能体系统。不过,这种完全去中心化的方法往往难以解决各智能体之间的冲突。
MADER 1
MADER通过构建去中心化且异步的规划框架来解决各智能体的分布式控制问题:各智能体独立求解优化问题。

将其他智能体的轨迹作为约束条件纳入优化过程,并利用 MINVO基生成体积更小的轨迹外多面体表示,降低其保守性;
通过引入分离平面参数作为决策变量,确保与其他动态障碍物或智能体轨迹的多面体表示不相交,实现实时避障。
优化后执行“碰撞检查-重新检查”机制,验证轨迹与优化期间其他智能体轨迹的可行性,若冲突则继续执行上一可行轨迹。
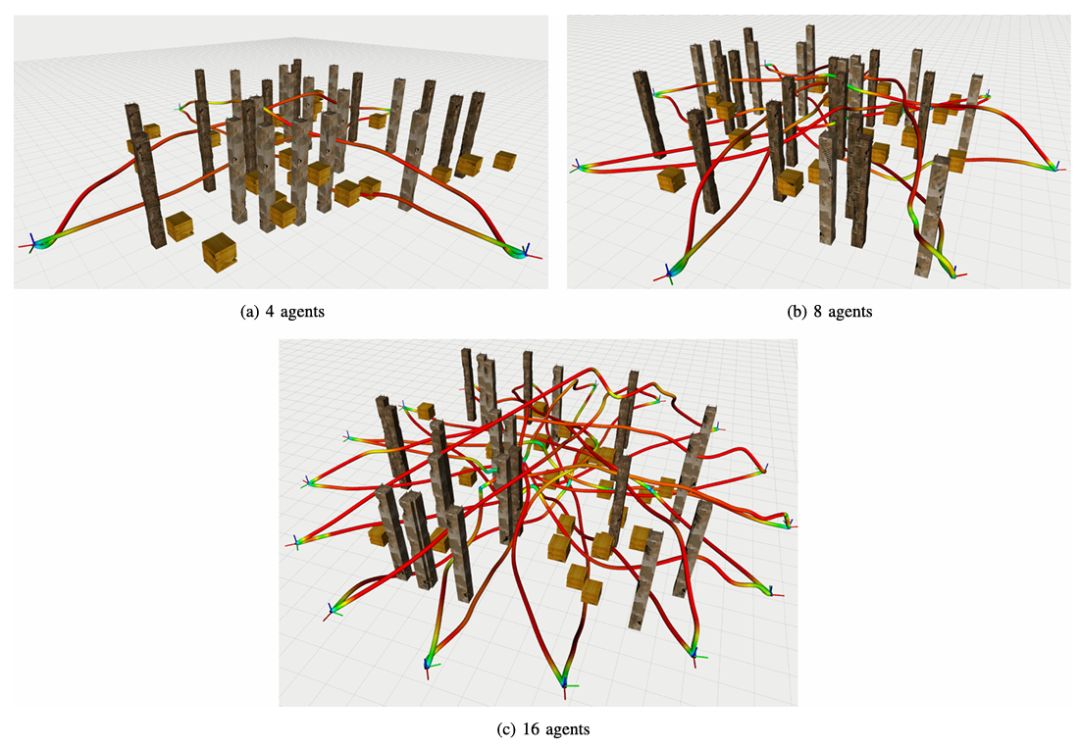
▲图例:多智能体同时规划效果
-
混合式控制
混合式控制则结合集中与分布式的优势,通过动态分组来平衡效率与复杂度。
EDG-TEAM 2
该系统依据智能体在空间的分布进行动态分组。
分组时,各智能体共享起始与局部目标位置及局部地图,通过ECBS的高效多智能体路径查找(EMAPF),在三维网格图上进行高低层焦点搜索,结合平局打破函数生成无碰撞路径,后端基于MINCO进行轨迹联合优化,生成安全且动态可行的轨迹,最终交由控制器执行,实现对每个智能体的协同控制。
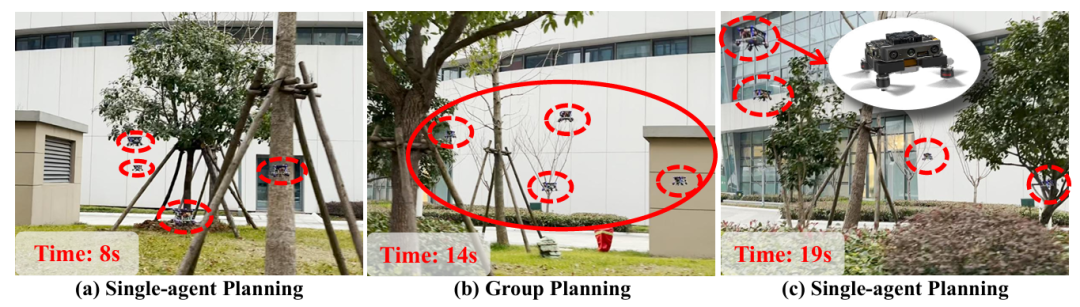
▲图例:多智能体室外效果
基于学习的控制
多智能体系统中基于传统控制的方法需要预先设定规则或优化目标,当环境出现未知变化(如障碍物突然移动、任务目标临时调整)时,这些方法可能因模型失配而失效。
基于学习的方法(如强化学习RL、模仿学习IL等)从数据中直接学习策略,能够更好的适应动态环境。
-
多智能体强化学习(MARL)
VIKI-R 3
VIKI-R是一个两阶段的多智能体强化学习框架。它先利用思维链注释对预训练视觉语言模型进行微调,再通过多级奖励信号下的强化学习进行优化。
该方案的优势在于:首次引入分层基准策略来支持细粒度的多智能体团队合作,并结合视觉语言模型来增强视觉推理,通过强化学习促进异构智能体的合作模式,促进了多智能体具身AI系统的推进。
▲图例:VIKI-R架构图
-
模仿学习(IL)
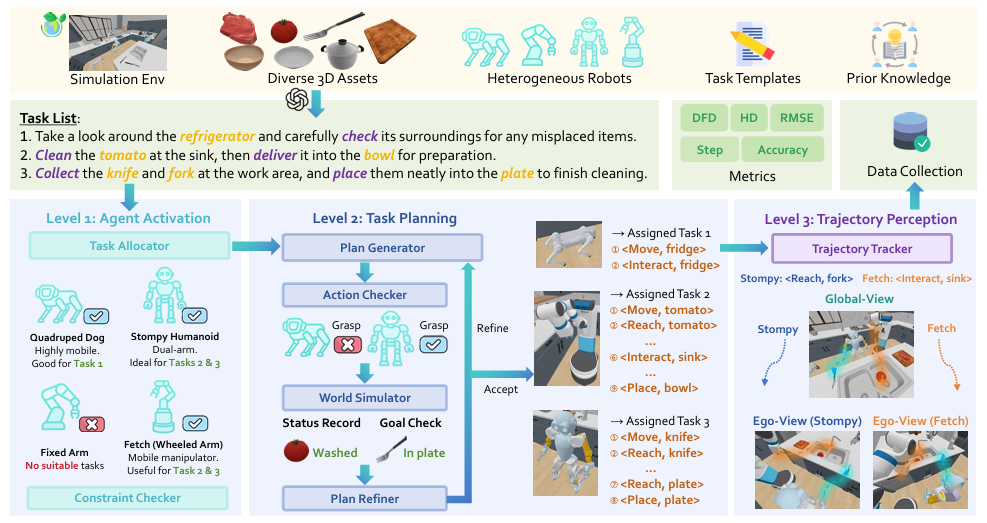
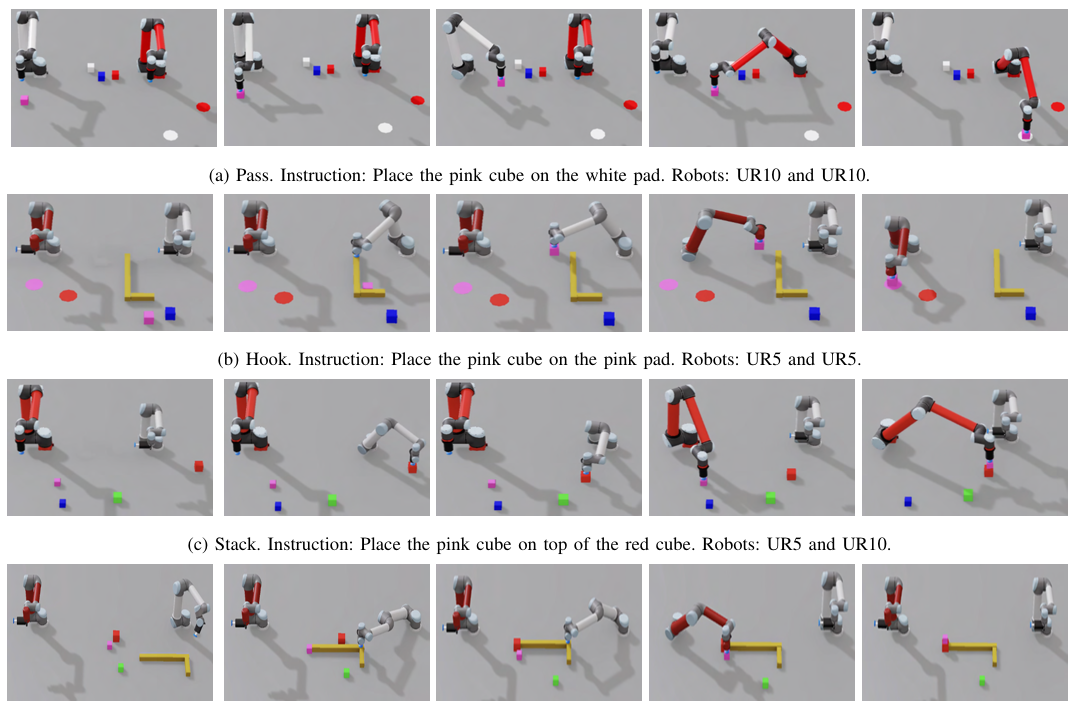
RoboFactory 4
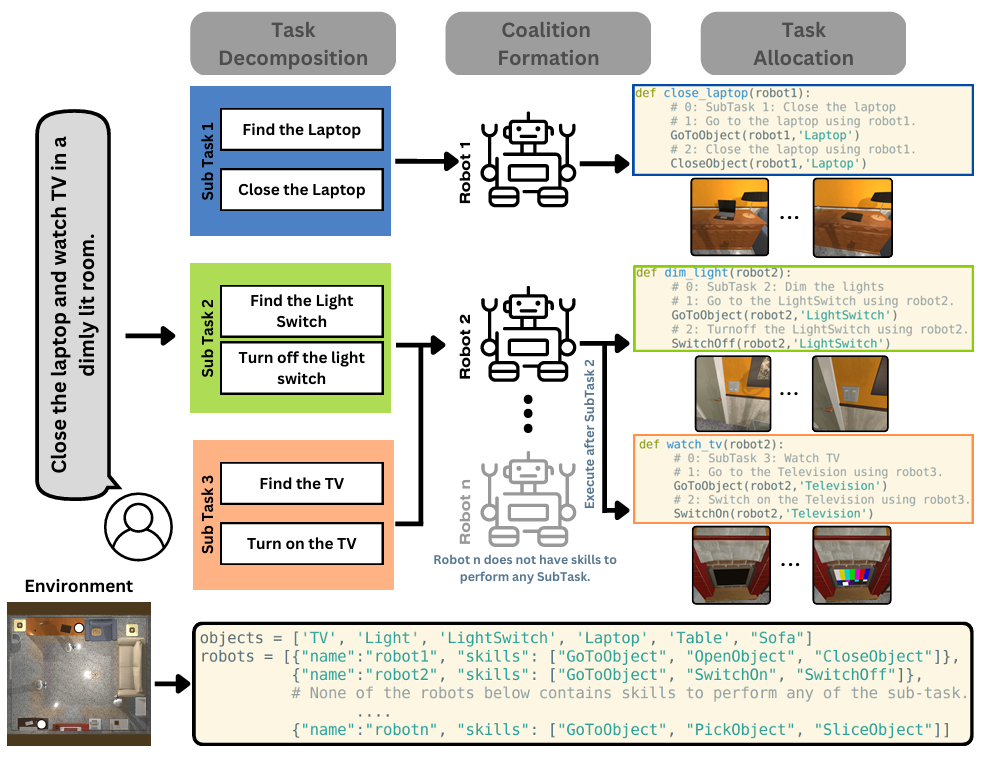
RoboFactory聚焦于探索具身智能体在组合约束下的协作问题。
其核心是:引入逻辑、空间和时间这三类组合约束,以此解决多智能体协作时的安全与效率难题,并开发了自动化数据收集框架,构建了首个具身多智能体操作基准。

它优势在于:通过设计适配不同约束的接口,将文本约束转化为可与物理世界交互的形式,实现了安全高效的数据生成;同时基于此基准对模仿学习方法进行适配与评估,探索多智能体模仿学习的架构和训练策略,填补了多智能体协作操作领域基准和高效数据生成方法的空白。
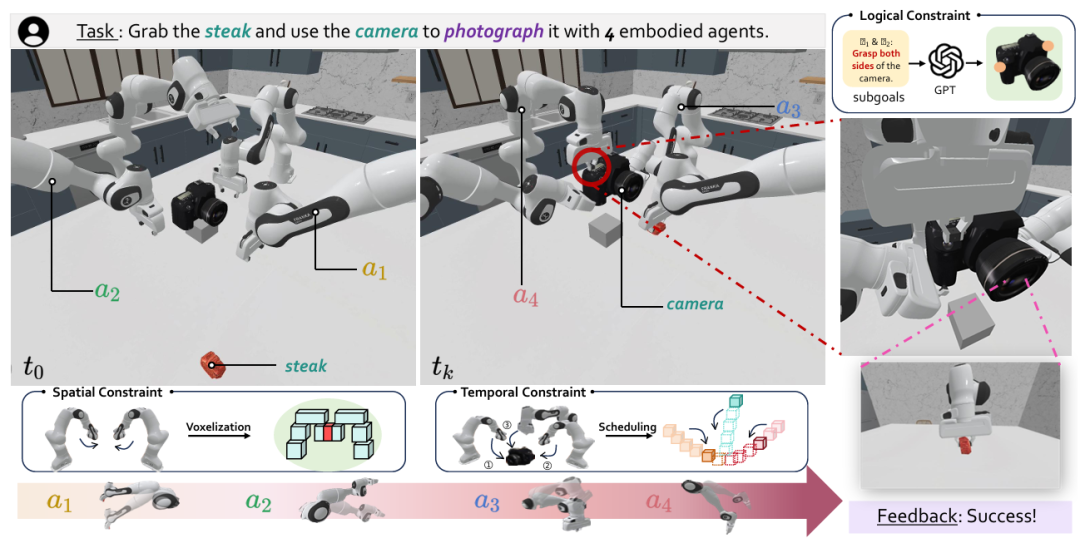
▲图例:RoboFactory使用4条机械臂进行拍照
-
分层学习
Say-Can 5
SayCan利用LLMs提供任务的高层知识,将指令分解为可行的子任务序列,同时借助强化学习训练的价值函数作为技能的affordance函数,判断每个技能在当前环境中的执行可行性。
通过结合两者概率选出最优技能,形成可解释的执行计划。该方法在101个真实机器人任务中表现出色,且能通过提升底层语言模型性能增强机器人表现,还具备集成新技能、支持链式思维推理和多语言查询等优势,为机器人理解和执行复杂指令提供了有效途径。
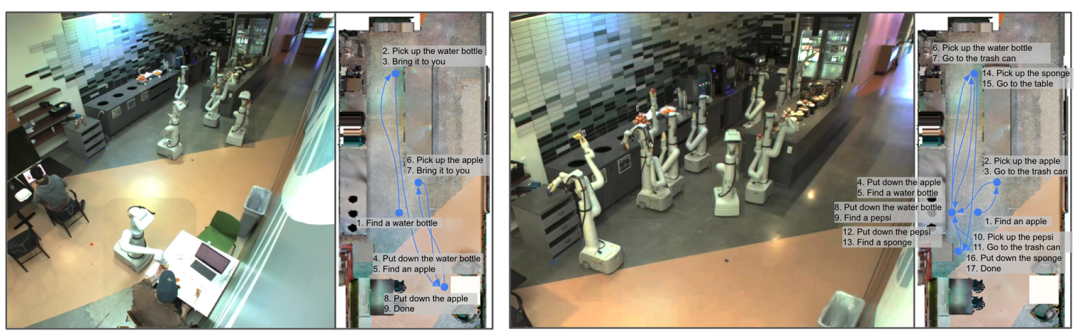
▲图例:在异构机器人上的长程任务表现
基于多模态大模型的控制
在多智能体系统中,不仅涉及自主智能体,还可能包括人类。
由于大型语言模型(LLMs)与视觉-语言模型(VLMs)对语言具有强大的跨模态表征与语义理解能力,可显著改善基于人类意图的多智能体协作任务(例如:基于人类指令的多智能体协作任务)。
下面将介绍基于多模态大模型的多智能体控制方法:
-
操作类任务
SMART-LLM 6
大型语言模型(LLMs)凭借强大的语义理解与推理能力,可将自然语言指令分解为可执行的子任务,并分配给不同智能体。
▲图例:SMART-LLM的概括图
SMART-LLM框架通过以下步骤实现多智能体之间的协作:
Step1:解析全局目标(如“整理房间”),分解为“移动椅子、清扫地面、摆放物品”等子任务;
Step2:根据每个智能体的能力(如机械臂擅长抓取,移动机器人擅长运输)进行子任务分配;
Step3:生成时序约束(如“先移开椅子再清扫”)。
SMART-LLM在MAP-THOR基准测试中,将多智能体任务完成率提升了35%

-
导航类任务
Multi-LLM-Agent 7
Multi-LLM-Agent中多LLM智能体通过自然语言通信补全局部观测信息,并完成分布式协作。
在部分可观测环境中(如多机器人搜救),每个智能体将自身观测信息(如“发现幸存者在A区域”)转化为文本消息并发送给其它智能体,其他智能体基于这些信息来调整行动。
研究者通过引入“共享反思模块”来进一步优化协作:即智能体定期汇总观测,由一个全局LLM评估当前策略的合理性,并提出改进建议(如“机器人B应向A区域靠拢以扩大搜索范围”)。
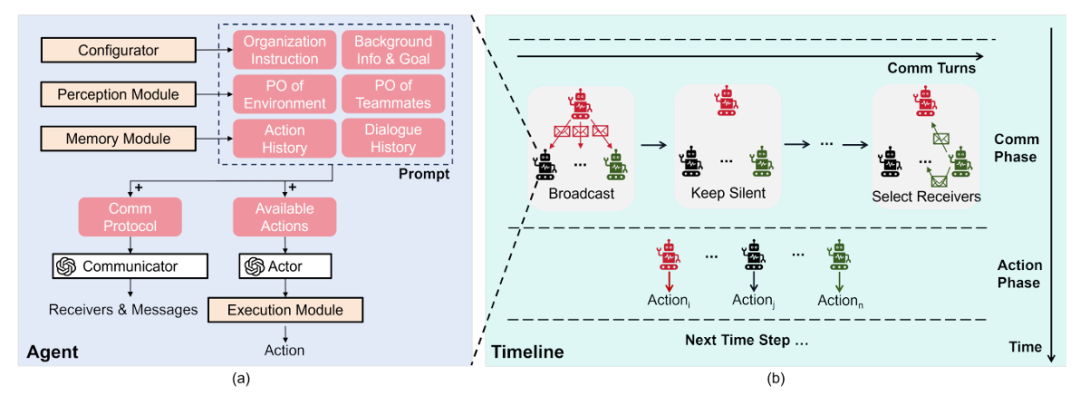
▲图例:Multi-LLM-agent框架图

在真实环境中搭建测试验证环境的成本较高,不同项目之间,因其研究的方向相同,因此测试验证往往可以复用。
构建统一的基准测试,为多智能体测试提供了标准化的评估方法,不仅可以降低测试成本,还可以避免重复造轮子。
目前多智能体具身智能的基准测试可分为以下四类:协作任务类、感知与导航类、人机交互类、动态与对抗类。
协作任务类
-
MAP-THOR8
该测试基准基于AI2-THOR模拟器,包含45个长周期任务以及5种不同场景的工作环境。
在该测试基准中,多智能体需根据自然语言指令(例如:“你拿牛奶,我烤面包”)在部分可观测的环境中协作工作,评估指标包括任务成功率、行动效率等。
该基准的核心挑战在于处理语言歧义(例如:“把盘子放在那里”中的“那里”需结合上下文进行推断)和动态角色分配。

▲图例:MAP-THOR的仿真场景
-
LEMMA9
该基准测试专注于基于语言指令的双机械臂协作任务,它包含了8个桌面操作任务(例如:“组装玩具车,强制要求2只手臂协作完成任务,比如其中一个机械臂需要好固定零件后,另一个手臂才能拧紧螺丝”)。
该基准提供了6400条专家示范语言指令,用于评估多智能体写作对时序约束和角色分工的理解能力。
▲图例:LEMMA中双臂写作任务的专家演示与高层指令展示
感知与导航类
-
V2X-Sim10
该测试基准主要面向于自动驾驶的多智能体协作感知,它主要基于CARLA与SUMO进行联合仿真。
车辆与路侧单元通过V2X通信共享传感器数据(如摄像头图像、激光雷达点云)来共同完成3D目标检测、轨迹预测等任务。
该基准包含了不同天气(雨、雾)和交通密度的场景,其评估指标包括检测精度、通信效率等,重点考察多智能体在传感器噪声与通信延迟下的协作鲁棒性。
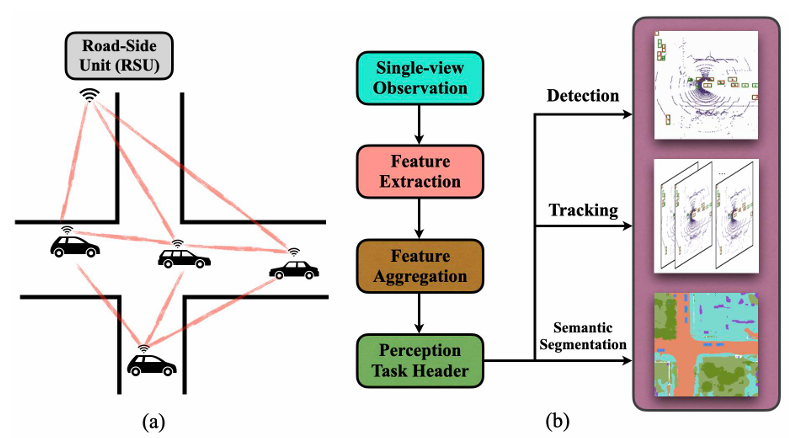
▲图例:V2X-Sim基准测试说明
-
MRP-Bench11
该基准主要评估多机器人的路径规划,集成ROS2与Gazebo仿真环境,包含仓库、家庭等复杂场景。
智能体之间需解决相互之间的冲突(如狭窄通道会车)、任务分配(如多机器人覆盖式巡逻)等问题,其评估指标包括规划时间、路径长度、碰撞率等。该基准支持集中式与分布式算法的对比,推动了动态避障与资源调度技术的发展。
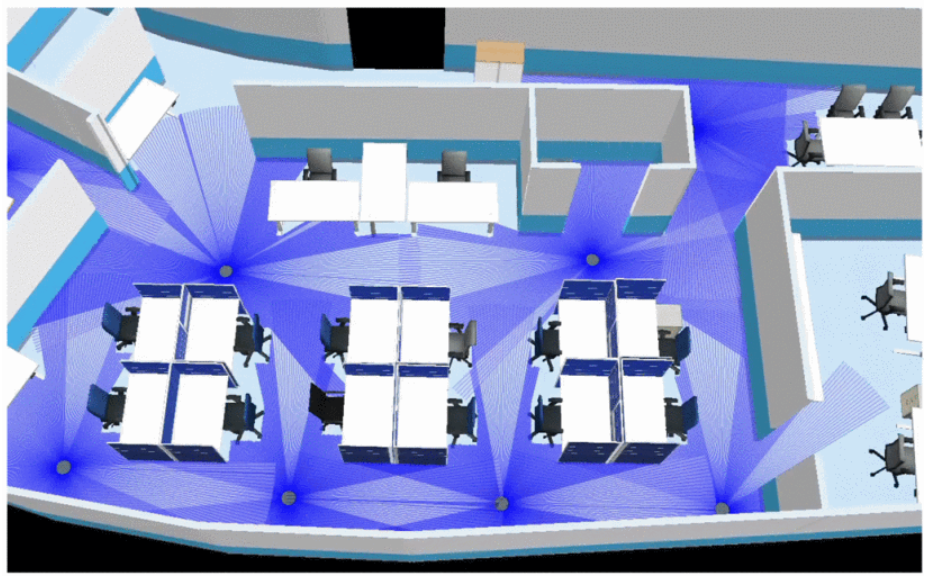
▲图例:办公室环境下9个机器人的导航协作任务
人机交互类
-
CHAIC12
CHAIC是首个关注“包容性”的智能社交的基准,它模拟了辅助机器人与行动受限人类(如轮椅使用者、儿童)之间的相互协作。
该基准的任务包括日常活动(如“协助上下楼梯”)与紧急避险(如“火灾逃生引导”),智能体需通过RGB-D感知推断人类的物理限制(如轮椅的转弯半径),并生成适应性策略。该基准的评估指标不仅包括任务成功率,还包括“人性化程度”(如动作的平稳性、指令的简洁性)。
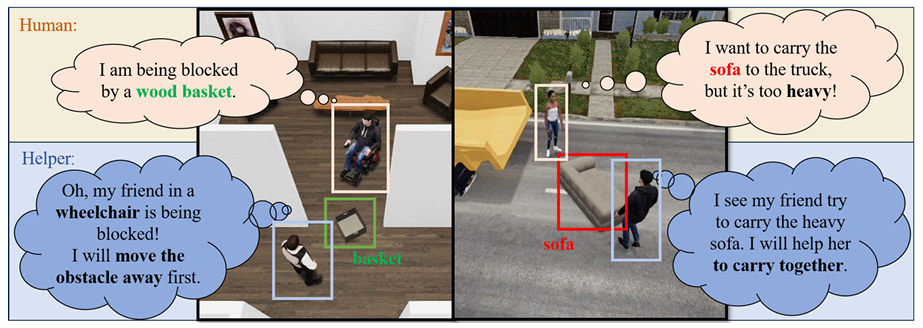
▲图例:CHAIC人机交互测试效果
-
PARTNR13
PARTNR是一个大型人机协作基准,它包含了10万个任务,分布在60个包含多个房间的住宅环境中。
任务类型涵盖空间约束(如“把书放在最高的架子上”)、时间约束(如“先做饭再洗碗”)和异质性(如“人搬重物,机器人递工具”)。
该基准通过自动生成的评估函数来量化任务完成度,揭示了当前LLM驱动的智能体在长周期规划上与人的差距。
▲PARTNR人机交互测试效果
动态与对抗类
-
SMARTS14
SMARTS是一个用于自动驾驶多智能体强化学习的基准,它支持复杂交通场景(如无保护左转、高速公路合并)。
智能体需和异质社会车辆(如出租车、货车)交互,并平衡交互过程中的安全性(无碰撞)、效率(行驶速度)与协作(如保持车道秩序)。
该基准提供了Social Agent Zoo,包含不同驾驶风格的虚拟车辆,用于测试智能体的适应性。
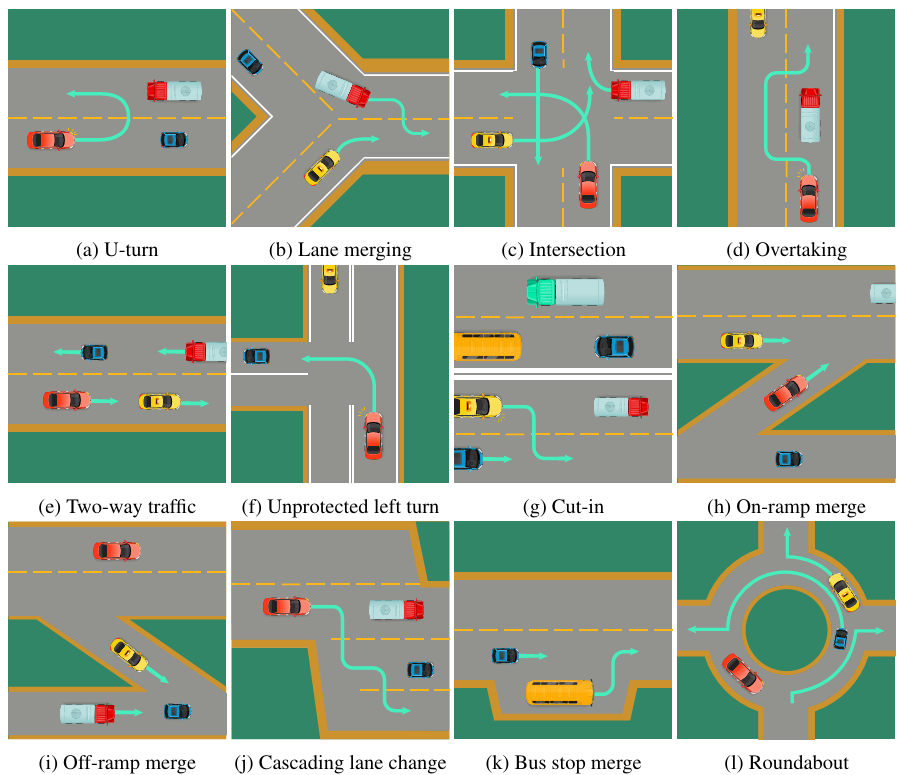
▲图例:多车交互场景
-
T2E15
T2E是一个多机器人围捕基准,它模拟“捕捉者”与“目标者”之间的相互对抗——捕捉者需协作形成包围圈,目标者则试图逃脱。
该基准通过“绝对安全区”(ASZ)来量化围捕效果,评估智能体之间的策略协同(如分工封堵不同出口)与环境利用(如利用障碍物限制目标移动)的能力。
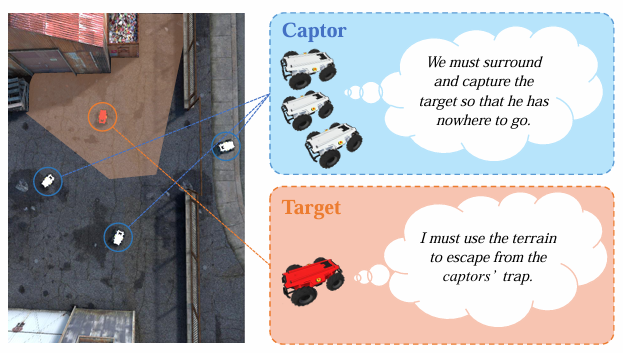
▲图例:捕获目标车任务

综合前面提到的内容来看,尽管多智能体具身智能取得显著进展,但其在复杂真实环境中的应用仍面临多重挑战:
系统复杂度指数增长、智能体信息去中心化、全局状态难获取、异构智能体协作难度大、开放环境下适应性差、多智能体交互导致探索空间激增、难以迁移到未训练场景……
而这些挑战的突破点可能体现在三个方面:
一是完善“通用协作智能体”:现在的多智能体技术的鲁棒性还不足以覆盖各种环境和多样性任务,通过不断完善“通用协作智能体”,来实现在不同环境与不同伙伴协作完成各种各样的任务的目标;
二是实现“自主进化的群体”:现在的多智能体技术在遇到未预见的困难后将陷入整体性灾难性宕机的情况,未来或许通过实现“自主进化的群体”,或许可以动态调整团队结构来持续提升性能,使多智能体系统在面对未预见的问题时也能持续的自我进化;
三是构建“人机共生系统”:现在的多智能体技术还未能覆盖大范围的人机写作共生的生态体系,未来或许通过构建全球化的“人机共生系统”,实现人类与智能体无缝协作应对全球性挑战。
参考资料:
1. MADER: Trajectory Planner in Multiagent and Dynamic Environments
2. Enhanced Decentralized Autonomous Aerial Robot Teams With Group Planning
3. VIKI-R: Coordinating Embodied Multi-Agent Cooperation via Reinforcement Learning
4. RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









