



今天,我们首先来讨论一个,具身智能行业发展的重要议题:
具身智能,究竟该All in模仿学习、强化学习和大模型闭环系统;
还是应该老老实实打磨硬件、建模型、做控制,把机器人先用起来?
最近,一场关于“具身智能该怎么发展”的学术思辨,在互联网上“悄悄”热闹了一阵。
清华大学助理教授、机器人企业星海图联合创始人许华哲,与南方科技大学助理教授、IEEE T-RO最佳论文奖得主周博宇,先后在知乎平台上发表了一篇个人观点性文章。起初有点针尖对麦芒的意思,但如此难得的学界观点碰撞,无疑值得深入探究。
简单来说,就是我们开篇问的:
具身智能,到底该怎么走?
他们的观点背后,又都代表着哪些技术路径?

▲图1 | 左:周博宇(南方科技大学助理教授),图右:许华哲(清华大学助理教授),评论:高飞(浙江大学副教授)(图源:许华哲老师小红书)
本文希望通过此类思辨,从行业的技术理想主义面纱之下,在产业狂热的表象下探寻被隐藏的理性洞见。(不表达任何“站队”立场)

两位老师从不同的出发点,讲的其实是同一个问题:今天我们谈论的“智能”,到底是不是“真的智能”?
许华哲老师的观点(下称观点A)可以概括成一句话:没有身体的智能,是不完整的智能。
大语言模型虽然能写文章、解题、画图,甚至具备某种“智慧”,但它对物理世界几乎一无所知,缺乏感知、没有交互,更谈不上经验。这也是为什么具身智能必须被重视——让智能体“亲身”感知、行动、犯错并修正,才有可能真正理解这个世界,而不是纸上谈兵。
周博宇老师则把目光放在了现实工程(下称观点B):别被“通用智能”这四个字冲昏头脑。
智能不只是大脑,离不开材料、结构、电机、控制这些看似“传统”的基础支撑。“真正推动具身智能前进的,是那些看起来不那么‘性感’的工作——比如改进电机散热、提升执行精度、解决工厂线束整理这种具体难题。而不是只靠炫酷的模型Demo,或者空谈“人形机器人终将通用”。
两位老师的原文很长,为了方便没有读过的读者快速了解,我们也将两位老师的观点总结成了表格。
(若有总结不到位或偏差之处,也请大家批评指正)
▲图2 | 观点总结

当前的大模型智能虽然强大,但它停留在“读”和“说”的层面,缺乏与物理世界的真实交互。
因此,具身智能的关键不在于继续堆数据、涨参数,而在于让智能体拥有身体,能主动去感知、行动并反馈,形成一个闭环的自我校正系统。
这个观点背后,指向的是一条非常明确的技术路径:感知—决策—行动—反馈的闭环具身智能架构,而这条路径中的技术支点主要包括:
更丰富、更主动的感知系统
二维视觉虽易获取,但对于构建世界模型与操作任务,缺乏空间与结构感知能力。尤其在数据稀缺或新场景下,单目图像很难区分物体的距离、形状与几何关系。
因此深度图,点云这类三维的感知信息非常重要,同时触觉传感也是实现具身智能不可获取的一部分,甚至是“最后一块拼图”。
视觉可以告诉你物体在哪里,触觉才知道“它滑不滑”“软不软”“拿没拿住”。尤其在物体操作任务中,没有触觉,控制策略很难对“力”进行反馈调整。因此构建更加丰富和主动的感知系统,是具身智能实现过程中非常重要的一环,也是第一环。

▲图3|能够增强视觉感知和动作预测之间关键耦合的H3DP框架©️【深蓝具身智能】编译
从模仿走向强化:构建闭环反馈
模仿学习虽易部署,但存在结构性缺陷:
其数据来源是人类演示,学习过程是“记住过去”,模型不会主动反思为什么成功,也不会从失败中纠偏。
具身智能的核心在于能否主动试错,而这就需要强化学习机制。
强化学习能构建奖励函数与策略优化之间的闭环,也就是说:机器人自己做事 → 环境给反馈(成功/失败) → 调整行为策略。
例如,当前流行的VLA模型虽然强大,但数据是“离线的”,无法对扰动状态进行自我调整。这种缺乏因果反馈的训练方式,只能让智能体“模仿外部”,却很难形成“内在理解”。
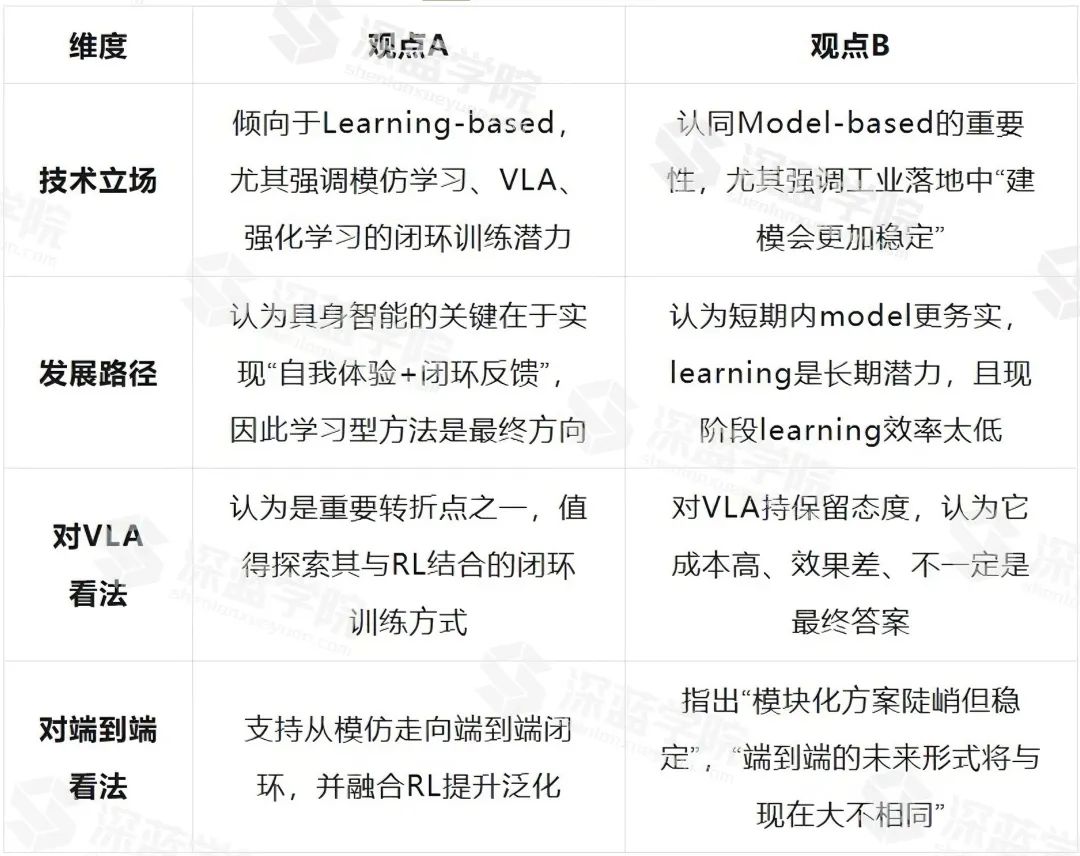
▲图4|通过微调大模型显著提升机器人操作鲁棒性和泛化性的OpenVLA框架©️【深蓝具身智能】编译
强化学习正是在修补这一点。通过构造任务驱动的 reward function(哪怕是稀疏的),让机器人对行为后果形成因果关联,从而达到真正意义上的感知与行为对齐(grounding)。
多模态融合与世界模型
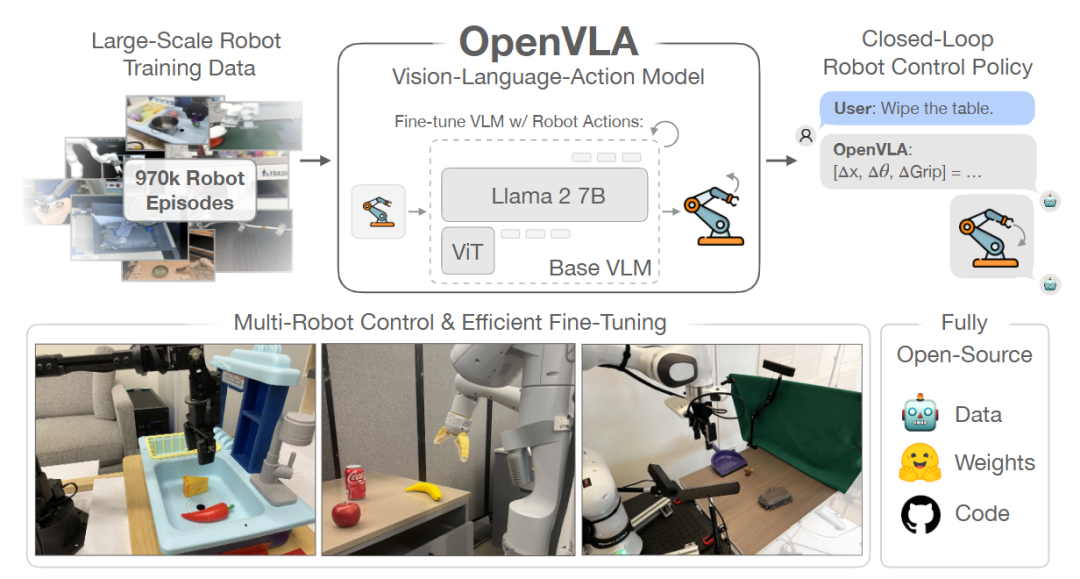
真正的具身智能不仅需要感知,还需要构建一个可推理的世界模型(World Model)。
这可以理解为:智能体在大脑中对物理世界的“模拟器”。
▲图5|世界模型简要发展历程©️【深蓝具身智能】编译
为了构建这个模型,光靠图像不够,还需要语言、深度、动作轨迹、触觉等多种模态联合训练。这就是VLA模型的设计初衷:
-
从语言中提取目标;
-
用视觉理解场景;
-
利用世界模型预测不同动作的未来结果,选择最优策略;
-
最终执行动作。
但该观点也指出当前 VLA 模型存在结构割裂的问题,如某些框架中的自回归视觉语言模块与后续扩散控制模块拼接生硬。因此,从结构融合、多模态编码一致性与空间对齐性出发优化 VLA 架构,是未来重要技术方向。
观点小结
观点A背后的具身智能技术方向和实现路径,在于是否能真正闭环:
感知 → 决策 → 动作 → 反馈 → 调整,每一环节都需要技术创新推动。
从更强的三维感知,到低成本触觉采集,再到强化学习的自我修正机制,以及跨模态世界模型的构建——这条路线清晰、难度极高,但确实代表了具身智能通向“自我理解”的方向。

通往智能的路,从来不是一场炫酷Demo的竞赛,而是一场工程系统的马拉松。
相比构建超大模型、堆参数、调奖励函数,身处“大模型+端到端学习”的热潮之下,更重要的是谁在解决真实问题、谁在把机器人真正落地到工厂、医院、仓库!这个观点的背后,强调的是具身智能的发展,不能忽略以下几个关键的技术路径和基础设施:
工程本体优先级:没有稳定硬件,一切学习都是空谈
当今很多具身智能研究还停留在“L0阶段”,连本体形态都尚未稳定。
以人形机器人马拉松为例:多数机器人连完整跑完一场比赛都做不到,还谈何高级智能?这背后凸显出一个长期被低估的事实:
没有一个稳定、耐用、可控的机器人本体,AI系统根本没法部署,更不用谈具身智能。

▲图6|机器人马拉松中,由于机器人的硬件发热问题,工作人员不得不时刻给机器人喷涂冷却液降温,才能够保证机器人继续完赛©️【深蓝具身智能】编译
因此,这个观点背后的具身智能实现路径可以总结为:
机器人本体结构优化是当下关键任务,尤其在人形机器人中,如何解决电机发热、结构松动、动态稳定性等问题,决定了智能系统的“可执行性”。
技术上涉及的包括:高扭矩电机控制、刚柔混合关节设计、低延迟传动系统、能量回收机制等。
“如果将具身智能比作‘智能建筑’,那么:不懂混凝土配比的建筑师,只会画空中楼阁”。
这句话本质在讲:具身智能的“body”,决定了它的“mind”能不能落地。
模块化控制与模型驱动:系统稳定性的保障机制
现在很多机器人公司真正投入使用的解决方案,其实大多依赖model-based架构,也就是明确建模、物理可解释、反馈可控的系统。这背后的技术路径和具身智能的实现方向实际上涵盖着:
-
模型驱动方法更稳定、更可控、更容易调试。比如:用动力学模型+PID控制的方式控制夹爪,不依赖训练数据即可获得确定性动作。
-
在数据稀缺、高稳定性要求的场景(比如汽车线束整理、精密封装),端到端方法泛化性差,难以部署。
对应的技术路径包括:
-
基于物理的控制模型(MPPI、MPC、CEM 等)
-
系统辨识与反馈线性化(feedback linearization)
-
软硬件协同控制架构(例如 ROS + 控制器侧加速)

▲图7|通过高效的模块化控制和驱动,多个无人机能够完美配合实现对于复杂建筑物的表面扫描与重建©️【深蓝具身智能】编译
但这条技术路径下,并不意味着全盘否定 learning,而是强调:
“如果不能解释一个模型的行为,它就难以用于工程。”
从工程视角出发,这是一种模块化设计主张——感知、控制、决策、规划各自独立调试,再逐步集成。也是一种“低风险、强稳定”的智能构建方式,特别适用于当前尚未收敛的具身系统。
观点总结
观点B提供了一条以工程落地为起点、以系统建模为抓手、以跨学科协作为支撑的具身智能路径。
它没有排斥学习,而是强调学习系统需要“载体”——如果没有能稳定执行的机器人平台,再强的智能也只能停留在纸面上。这一路径的核心在于让具身智能真正实现 “有用、可用、能用”,而非与 AI 发展方向形成对立。

从具身智能实现方向来看:
一个强调从“感知-反馈”的闭环出发,让智能体真正“动手”理解世界;
另一个则提醒我们,别忽视那些看起来“不够性感”的工程细节,真正推动具身智能落地的,往往是结构、电机、控制这些基础能力。
但从技术路径来看,也指向了具身智能发展的两个维度:
一个是向内扎根,把身体做得稳、执行得准、系统能跑起来;
另一个是向外生长,让智能体能看、能听、能学,能自己理解任务目标。
一个是地基,一个是屋顶。前者没有,后者搭不起来;后者缺位,前者也只能永远是毛坯房。
具身智能的未来既不靠天才横空出世,也不靠模型参数飙升,而是要在“算法”与“螺丝钉”之间找到平衡。
把抽象的智能落在一块真实的金属板上,让它真的动起来,做事、犯错、学会,然后再做得更好一点。
这是一条很难的路,但好在,已经有越来越多的人,愿意认真走下去了。

















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









