



摘要
在真实世界中部署自动驾驶系统,依赖于对各种驾驶行为的高保真模拟能力,尤其是在面对非专家行为和潜在危险场景时。然而,现有的世界模型大多基于现实中的安全驾驶数据进行训练,难以覆盖稀有但关键的“非专家行为”——这严重限制了它们在策略评估和规划推理中的应用范围。
©️【深蓝AI】编译
为破解这一局限,该研究提出了 ReSim 框架:一种能够模拟多样驾驶行为、具备高控制性与高保真度的视频生成世界模型。它融合了来自模拟器(如 CARLA)中采集的非专家驾驶数据,并基于扩散式 Transformer 构建出支持行为调控的视觉生成器。为进一步支持策略评估任务,ReSim还引入了Video2Reward模块,能够从预测视频中推断出奖励信号,完成从模拟到评估的闭环。
实验表明,ReSim 在图像质量上提升高达44%,在专家与非专家行为的控制精度上提升超过50%,并在自动驾驶任务中实现高达25%的策略选择性能提升。这一工作为构建更可靠、更具风险覆盖能力的智能驾驶系统提供了全新范式。
论文标题:ReSim: Reliable World Simulation for Autonomous Driving
论文作者:Jiazhi Yang, Kashyap Chitta, Shenyuan Gao, Long Chen, Yuqian Shao,
Xiaosong Jia, Hongyang Li, Andreas Geiger, Xiangyu Yue, Li Chen
论文链接:https://arxiv.org/pdf/2506.09981
引入
学习一个能够预测合理未来结果的世界模型,正被视为实现自主智能系统的关键一步。过去十年中,研究者在多个领域利用视觉世界模型来压缩状态表示、引导测试时的路径规划,并辅助训练强化学习智能体。与强调视觉质量与泛化能力的视频生成器不同,世界模型的目标是精准模拟未来情景,并对自身动作具备精确控制能力。
在自动驾驶领域,近年来的世界模型通过大规模数据集与前沿视频生成技术的结合,显著提升了图像质量与泛化能力。然而,要准确追踪和执行特定动作仍然是难点,而这恰恰是实现高质量奖励估计和有效路径规划所必不可少的能力。一个核心问题随之而来:现实驾驶数据本身是否足以支撑高可靠性的未来模拟?
现实数据存在天然的偏差。大多数真实驾驶记录仅包含安全、规训性的专家行为,导致训练数据中的状态-动作空间受限,而那些危险或违规行为(如碰撞、偏离道路)极度稀缺。这种失衡在模型面对未见的“非专家行为”时容易引发预测错误,从而削弱了其鲁棒性与可信度。
为此,该研究提出了 ReSim:一个可控、可靠的驾驶世界模型,能够在保持高模拟质量的同时响应包括“非专家动作”在内的多样行为。作者将来自模拟器(如 CARLA)的非专家驾驶数据引入训练中,与现实数据融合,构建出一个覆盖更广泛状态与行为的异构数据集。基于大规模文本到视频生成器,ReSim 采用多阶段训练策略,融合视觉与动作条件,并引入了不均衡噪声采样与动态一致性损失,以强化对“非专家行为”下的运动连续性建模。
相比已有方法(如 VISTA 等)在复杂场景下无法正确执行偏离指令的局限,ReSim 可准确模拟诸如偏离车道等行为。此外,为支持以奖励驱动的任务评估,该研究还设计了 Video2Reward 模块,能够将 ReSim 生成的视频序列转化为真实场景中的奖励信号,从而完成从模拟到评估的闭环路径。
作者进一步展示了 ReSim 在现实自动驾驶场景中的多种应用潜力。在无动作条件输入时,ReSim 的预测未来可作为视觉规划参考,从中提取可执行轨迹。在 NAVSIM 规划基准测试中,基于视频预测的策略相较于当前主流世界模型规划器性能提升了 2.0,相比端到端监督模型提升了 2.6。此外,将 ReSim 与 Video2Reward 模块结合,还可在多个候选策略中自动选择预估奖励最高的轨迹,从而优化最终决策。在实验中,该策略选择机制带来了高达 55.3% 的性能提升。更直观地说,ReSim 为研究者提供了一个合成环境,支持在“模型想象”中闭环验证驾驶策略。
核心贡献如下:
1. 首次系统性整合模拟与现实数据,用于训练世界模型,解决了现实数据中缺乏危险行为的问题,提升了模型在真实场景中对动作的可控性与泛化能力;
2. 提出了 ReSim 框架:一个可控的世界模型,能够在多样输入动作条件下可靠地模拟高保真未来场景,并设计了改进的损失函数与训练策略来建模复杂动态;
3. 推出 Video2Reward 模块,将模拟结果转化为奖励评估信号,实现从视觉预测到策略优化的闭环控制;并通过多个数据集与任务验证 ReSim 在真实自动驾驶任务中的有效性,全面超越现有方法。
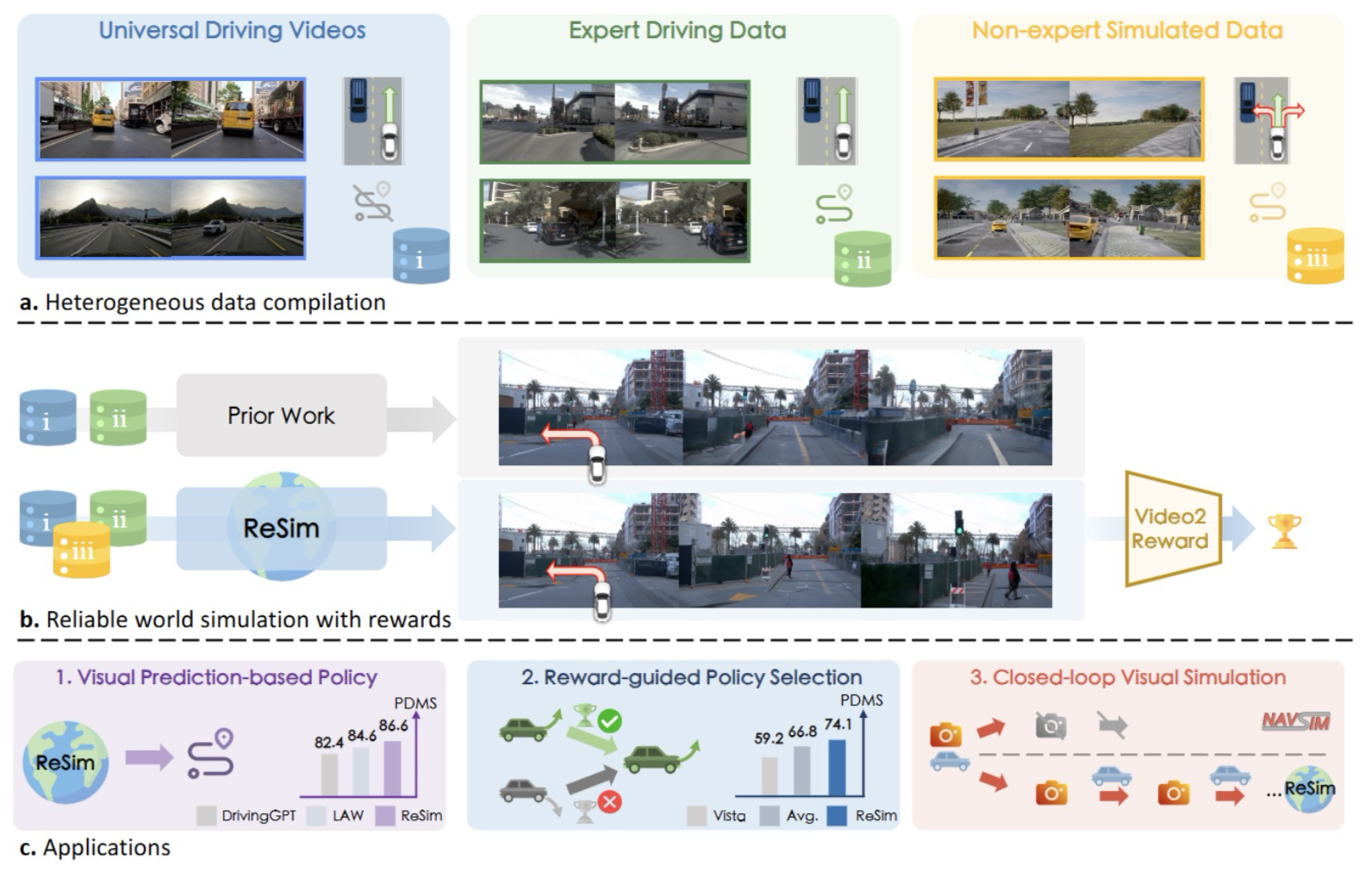
图1|全文方法总览:(a) 异构驾驶数据包含:(i)(ii) 专家安全驾驶日志,(iii) 来自模拟环境的潜在危险(非专家)驾驶行为。(b) 以往的驾驶世界模型仅在专家数据上训练,导致模型预测结果虽然“安全”,但往往偏离真实场景;而 ReSim 融合多种数据来源,能够模拟更可靠、贴近现实的未来场景,并构建出在开放世界中也具备泛化能力的奖励模型。(c) ReSim 拥有高保真的视频预测能力、准确的动作执行效果,以及可靠的奖励估计机制,可广泛应用于策略部署与虚拟仿真等自动驾驶任务中©️【深蓝AI】编译
具体方法与实现
该研究提出的 ReSim 框架旨在实现一个具备高度可控性的驾驶世界模型,支持模拟多样化的驾驶行为,尤其是常见数据中缺失的非专家行为。整个方法由四个关键部分组成:异构数据构建、可控的视频生成模型、奖励估计模块以及实际应用探索,接下来小编把这几个模块逐个进行介绍。
异构数据构建:模拟与现实融合的行为库
现有大多数驾驶世界模型主要依赖真实专家驾驶数据或网页视频(如 NAVSIM 和 OpenDV 数据集),但这类数据存在显著偏差——以人类安全驾驶为主,缺乏碰撞、偏航等“非专家行为”的真实记录,导致模型在遇到未见行为时表现不稳定,难以判断策略好坏、提供可靠奖励。
为突破这一瓶颈,该研究引入了 CARLA 模拟器作为补充数据源。通过构建可控虚拟环境,研究者采集了两类行为数据:
● 一类由规则化策略(PDM-Lite)控制,生成专家轨迹;
● 一类则通过随机采样方向角与速度,生成高度多样的非专家行为,包括意外、偏离路线、速度异常等情况。
最终形成了一个规模覆盖广泛的数据集,包含 OpenDV(400 万条视频)、NAVSIM(8.5 万条)与 CARLA(8.8 万条)。每条视频长度为 4.9 秒,前 9 帧为输入上下文,后 40 帧为预测目标。
可控视频生成模型:融合轨迹与文本指令的扩散式预测器
ReSim 以大容量的扩散式视频生成器 CogVideoX 为基础进行改造,使其从仅支持文本条件扩展为支持视觉上下文与轨迹信息。核心设计包括:
● 替换历史帧的噪声输入为其“干净”版本;
● 引入可学习的轨迹编码器,将未来路径信息(如自车轨迹点)与视频潜变量一起输入到 Transformer 中。
训练过程中使用了两种损失:
① 视频扩散损失
用于监督模型生成未来帧的视频内容,使其尽可能接近真实轨迹下的结果。
② 动态一致性损失
标准的视频扩散损失只对每一帧独立优化,忽略了时间连贯性。为提升运动的真实感,该研究额外设计了动态一致性损失,用于约束潜变量在不同时刻的运动变化,使得模型学习到“行为之间的连续性”。
此外,作者还提出了一种“不均衡噪声采样策略”:偏向采样高噪声时间步,避免模型在低噪声状态下仅通过“邻帧平均”完成简单复原,从而促进更复杂的动态学习,提升非专家行为下的拟真度。
训练分为三个阶段逐步进行:
1. 阶段一:仅在 OpenDV 上训练,使模型初步掌握视频上下文与语言指令引导下的预测能力;
2. 阶段二:加入含有动作标注的 NAVSIM 与 CARLA 数据,通过可学习 Transformer 编码器引入轨迹条件;
3. 阶段三:使用更高分辨率进行全量微调,最终生成长度为 4 秒、帧率为 10Hz 的未来视频序列。
奖励估计模块:Video2Reward 实现闭环评估
除了高质量的视频生成,自动驾驶系统还需要评估每条模拟轨迹的“好坏”,即为其分配奖励。这在传统驾驶世界模型中往往被忽略,因为真实场景中的目标状态不明确、环境复杂,难以手工定义奖励函数。
为此,该研究提出了名为 Video2Reward(V2R) 的奖励估计模块,利用 CARLA 提供的细粒度惩罚信号(如碰撞、过慢行驶等)作为监督信号,训练一个视频到奖励的映射模型。
● V2R 构建在 冻结的 DINOv2 特征提取器 上,配有轻量级的预测头;
● 它不需要三维结构、相机姿态等复杂先验,仅通过视觉序列即可输出对整条轨迹的评估;
● 在推理阶段,任意策略生成的未来轨迹可以通过 ReSim 转换为视频序列,再输入 V2R 得到对应的奖励值。
这种设计实现了模拟-奖励一体化的闭环,使 ReSim 不仅能“想象未来”,还能“评估选择”,为策略学习与优化提供基础。
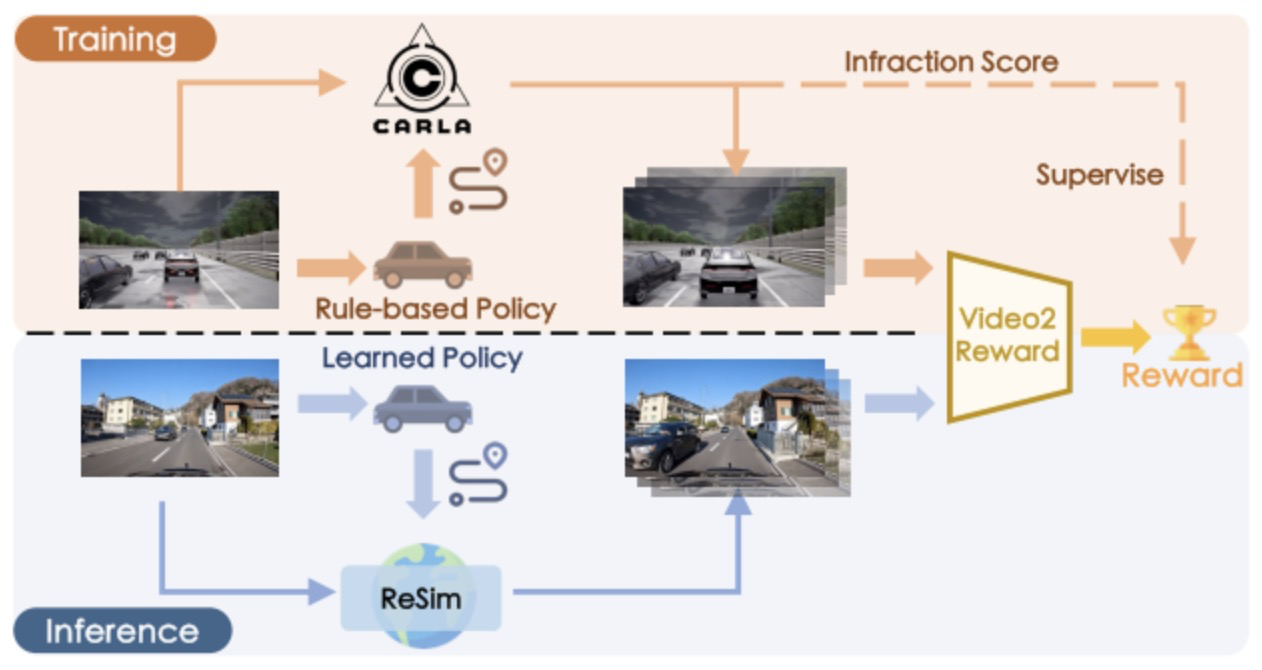
图2|V2R模型说明:上图:V2R 在训练阶段以模拟环境中安全与危险行为对应的违章评分作为监督信号,从驾驶视频中学习奖励估计。下图:在现实世界的推理阶段,ReSim 根据某一候选动作生成的预测视频将被输入 V2R,用于估算该动作的奖励值。©️【深蓝AI】编译
应用探索:让模拟真正服务于自动驾驶策略
1)基于视频预测的策略生成
借助从大规模人类驾驶视频中学到的未来预测能力,ReSim 可被转换为一个视觉预测驱动的策略模块,类似于近年来在机器人控制中广泛采用的“感知即策略”范式。与传统策略单纯模仿自车轨迹不同,预测未来观测图像的方式可以:
● 利用更大规模的无标注视频数据;
● 更好地理解周围环境中的多智能体互动,尤其是稀疏轨迹数据难以覆盖的意图信息。
在部署阶段,ReSim 作为策略模块不再接受预定义动作,而是将历史视觉观测序列与高层次语言指令作为输入,“想象”出未来的视觉状态序列。接着,这一预测图像序列会被输入一个逆动力学模型(Inverse Dynamics Model, IDM),将视觉信息转换为对应的自车未来轨迹。
如图 3 所示,在关键事件(如转弯、避障等)处,ReSim 能有效提供预测视觉内容,为后续路径推理与策略控制提供更具上下文感知能力的输入。

图3|ReSim的视频预测展示©️【深蓝AI】编译
2)基于奖励的多策略选择机制
复杂驾驶环境中,往往需要维护多个策略候选,以增强对不同情境的鲁棒性。然而,一个重要挑战是:如何在多个备选轨迹中选择最优路径?
为此,作者提出了基于 ReSim 与 Video2Reward 的策略选择方法:
● 首先,将每条候选轨迹输入 ReSim,生成对应的未来视频;
● 然后,将这些视频输入 Video2Reward 模型,得到每条轨迹的奖励分数;
● 最后,选择奖励最高的策略作为执行结果。
这种奖励引导的轨迹选择机制能够显著提升整体性能,通过充分利用各个候选策略在不同场景下的局部优势,实现组合策略优于任一单一策略的效果
3)闭环视觉仿真环境
当前的视觉驱动自动驾驶模型,多数仍处于“开环评估”阶段,依赖静态数据集或预设轨迹进行验证。这种方式存在明显局限:
● 只能评估模型在单步决策上的表现,无法反映多步滚动执行中的误差累积问题;
● 被动接受预设状态,缺乏自主行为后的“反馈”与新状态再决策过程,这与现实驾驶脱节。
得益于 ReSim 对动作条件的精准响应与高保真视觉生成能力,该研究提出了一种闭环视觉仿真机制:
每一次模型预测的动作,都会通过 ReSim 生成新的视觉状态,作为下一轮决策的输入,形成“模拟-决策-再模拟”的循环过程。
这让研究者可以在无实车的情况下,持续测试、优化和验证驾驶策略在动态交互场景下的鲁棒性与可靠性,为未来闭环训练与安全验证提供了坚实基础。
实验
作者在实验部分对方法进行了充分的验证,工作量非常大,感兴趣的读者推荐大家仔细去阅读原文,在这里小编有的放矢的介绍比较重要的部分,分别对应上面提到的几个模块,一起来看看吧~
动作可控性结果
为了验证 ReSim 对动作指令的响应能力,作者在未见过的 Waymo Open 数据集上进行了测试。评估采用“轨迹差异指标”(Trajectory Difference),衡量模型预测的未来轨迹与输入指令轨迹之间的匹配程度。
结果显示,ReSim 在无动作指令和专家指令下的表现分别提升了 80% 和 54%,显著优于基准模型 Vista。当从训练中移除 CARLA 模拟数据(ReSim w/o sim.)后,性能下降,进一步说明模拟数据对训练动作响应能力的重要性。
此外,针对“非专家行为”的可控性验证,作者进行了人类偏好测试。参与者在多个方法生成的视频中选择更真实和更符合输入轨迹的样本。结果显示,ReSim 在视觉真实性与动作匹配性两个维度上均大幅领先(详见 图4、5),并且具备零样本泛化能力,可迁移到新数据集上(图 6)
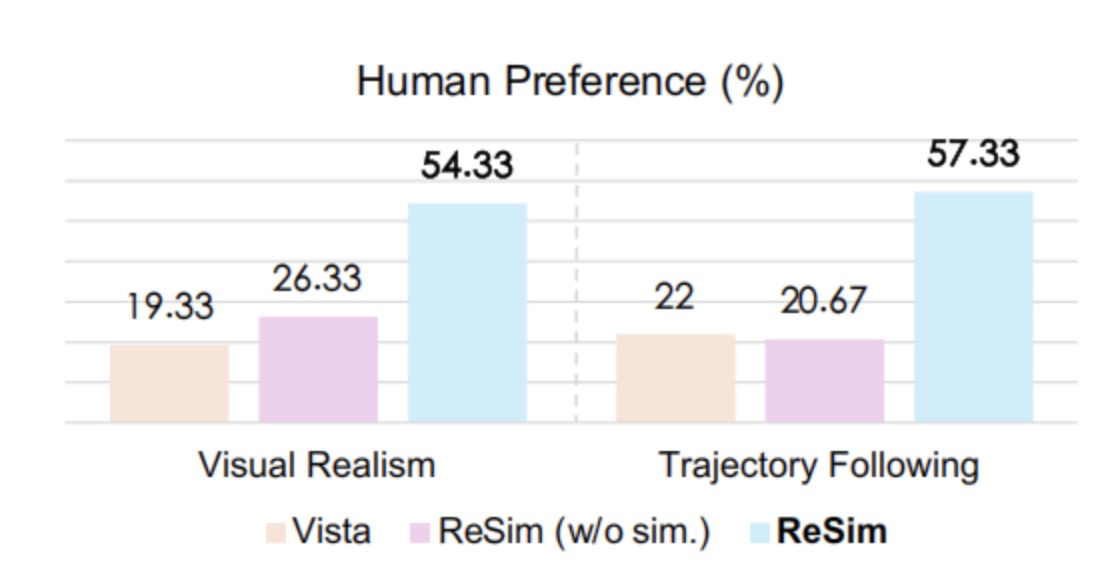
图4|人对非专家行为可控性的评价©️【深蓝AI】编译

图5|非专家行为可控性的定性比较©️【深蓝AI】编译

图6|零样本动作可控性实验展示©️【深蓝AI】编译
视频生成质量对比
为了评估预测视频的图像质量,作者在 nuScenes 验证集上使用 FID 和 FVD 两个主流指标进行对比。ReSim 即便未在 nuScenes 上训练,也展现出出色的视觉保真度,证明了其良好的泛化能力。
奖励估计效果
作者还评估了 Video2Reward 模型的奖励判别能力。方法是在 CARLA 和 NAVSIM 数据集中,分别选取“专家轨迹”和可能存在违规行为的“非专家轨迹”,然后比较奖励模型是否能正确区分它们。共测试了 250 对样本,结果显示,ReSim + Video2Reward 能在模拟与真实场景中准确赋予更高奖励给专家行为,显著优于其他对比方法(见图7)
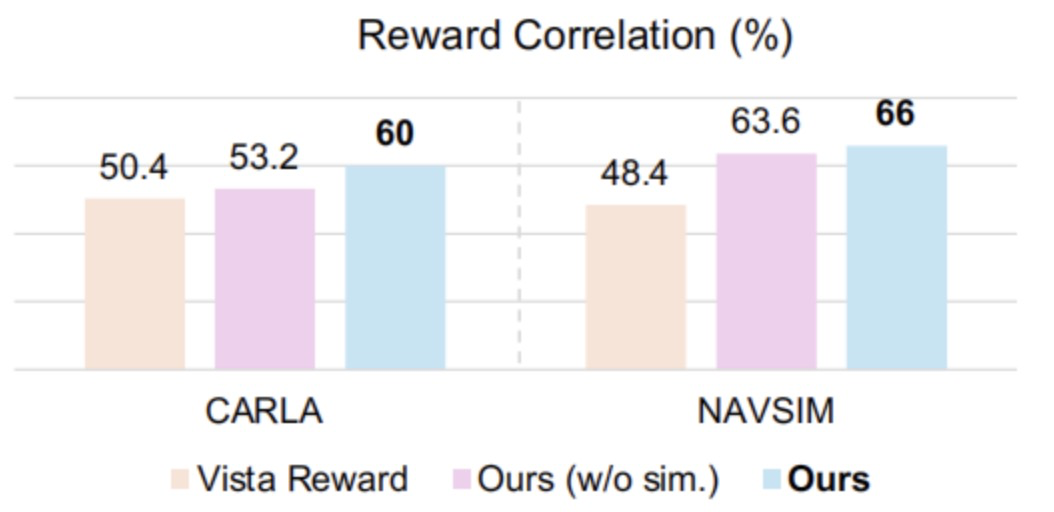
图7|奖励判别能力实验结果©️【深蓝AI】编译
随后作者在应用效果的层面也对方法进行了评价,首先是在 NAVSIM 的 navtest 测试集中,作者评估了由 ReSim 和逆动力学模型(IDM)组成的策略模块性能。与端到端方法(如 UniAD、Transfuser)和其他世界模型方法(如 DrivingGPT)相比,该方法在无需额外传感器或标注的前提下取得更优表现(详见 图8)
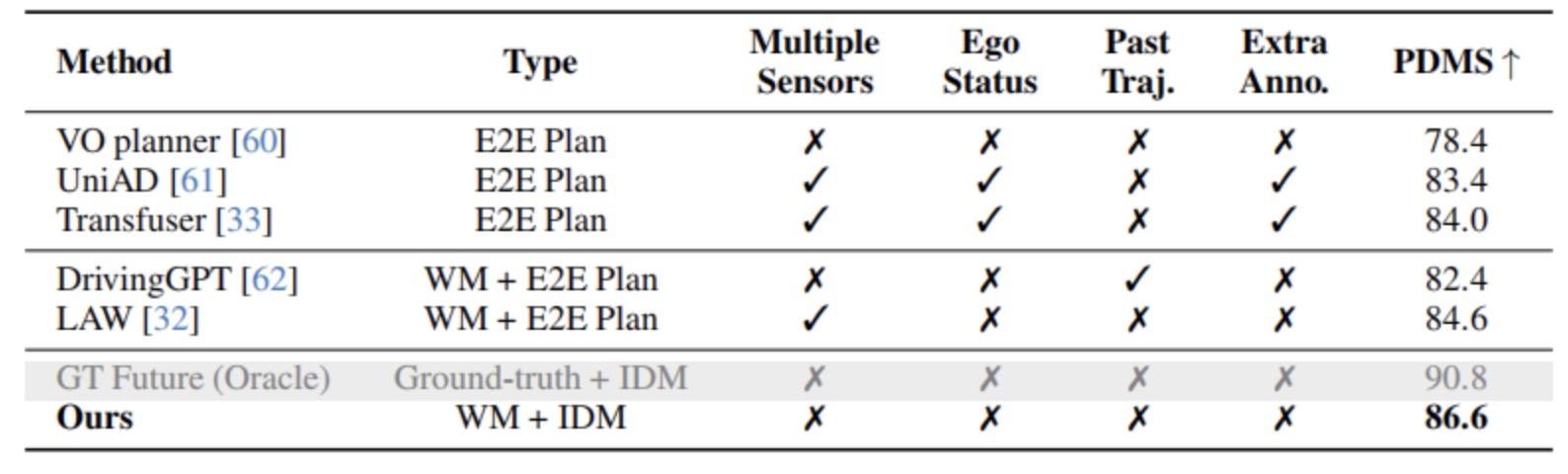
图8|在NAVSIM的测试集上的规划实验结果©️【深蓝AI】编译
特别地,这一策略仅依赖历史观测与高层指令作为输入,进一步证明 ReSim 在构建轻量级策略系统方面的优势。接下来作者对基于奖励的策略选择也进行了实验验证。在 NAVSIM 的挑战场景中,作者比较了不同策略融合方法(Transfuser 与 LTF)下的动作选择性能。在 300 个双策略对比样本中,结果如下:
● 单独使用 Transfuser 或 LTF 的得分为 47.7 和 47.2;
● 简单平均融合提升至 66.8;
● Vista 奖励机制提升至 59.2;
● 而使用 ReSim + Video2Reward 进行奖励引导选择后,得分达到 74.1,接近于最优策略选择下的上限(详见 图9);
● 若移除模拟数据训练,性能显著下降,进一步说明 ReSim 构建中的模拟数据至关重要
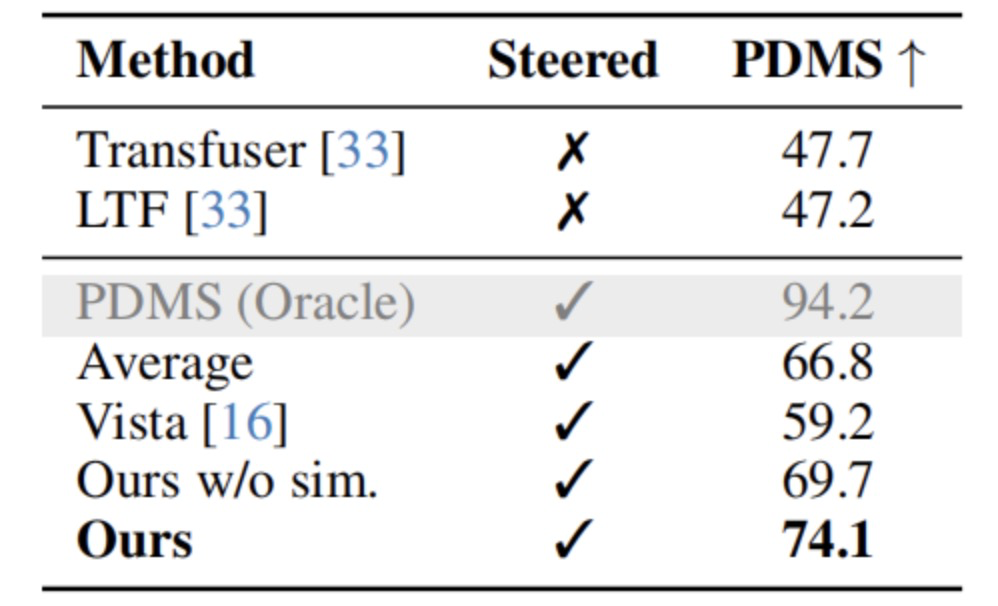
图9|Reward导向的策略选择实验结果©️【深蓝AI】编译
最后作者验证了 ReSim 支持的“闭环视觉仿真”机制。在两个 NAVSIM 场景中,策略输出的动作用于生成未来 4 秒的视频,这些预测图像再输入到策略中形成闭环决策链。
在此过程中,ReSim 能生成策略历史中从未遇到的视觉状态,使得策略被动态置于多样情境中,体现其对泛化与鲁棒性的支持能力(图9所示)。
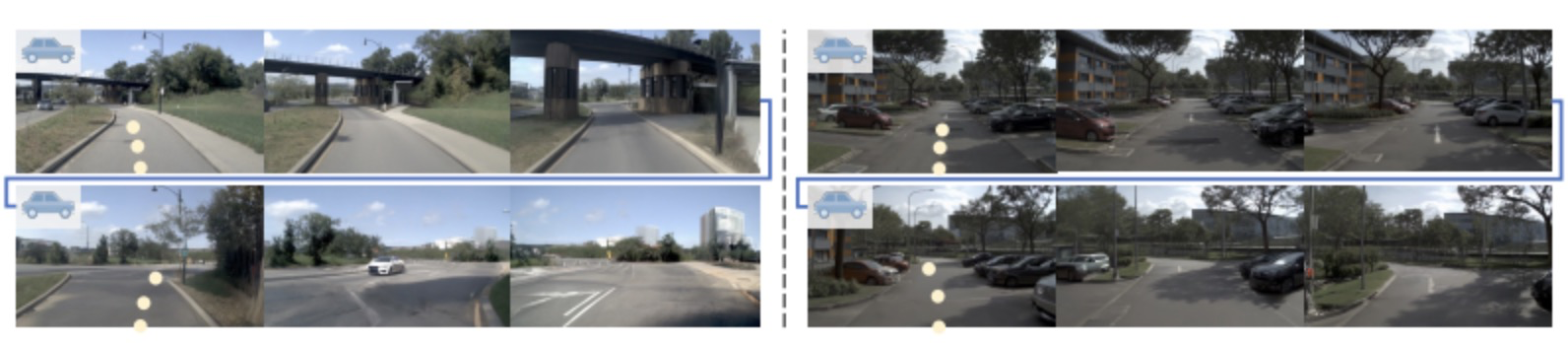
图10|闭环视觉仿真实验演示©️【深蓝AI】编译
总结
在本研究中,作者提出了 ReSim ——一个具备高可靠性、能够在开放环境中模拟多样驾驶行为的世界模型。该方法通过引入来自成熟驾驶模拟器的非专家行为数据,弥补了现实人类驾驶数据中过于“安全”的偏差,显著拓展了模型对危险场景的理解与泛化能力。
此外,ReSim 在训练过程中融合了多项关键策略,包括动态一致性损失函数、不均衡噪声采样机制与分阶段多任务学习,显著提升了模型的动作控制能力与视频预测的时空连贯性。
为了进一步支持基于奖励的策略优化,研究者还设计了 Video2Reward 模块,能够从模拟未来视频中估算出对应动作的奖励信号,从而将 ReSim 扩展为一个闭环策略评估与优化系统。
大量实验证明,ReSim 在视觉保真度、动作跟踪准确性与策略部署性能上均取得了全面领先,展示了其在下一代自动驾驶系统中的强大潜力与广泛适用性。

















 2402
2402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









