



在具身智能领域,机器人系统的泛化能力始终是核心挑战。当语言模型和视觉模型在海量数据驱动下不断突破边界时,机器人领域却面临着一个残酷现实——
端到端通用型机器人策略的训练数据量,比语言模型少了十万倍以上。
数据稀缺性,正成为制约机器人智能化发展的关键瓶颈,这也并非偶然,而是技术路径的必然结果。

因为当前主流的人工远程操作数据收集方式,不仅需要高昂的人力成本,还受限于物理机器人的可获取性,难以规模化。物理仿真虽然能够提供高效的数据生成途径,但在模拟复杂对象交互时往往力不从心,需要大量的参数调整和精密的建模工作。
其本质矛盾在于:要么依赖高成本的物理实体,要么受制于仿真的不可靠性。这使得机器人学习始终无法突破 “小数据” 范式,通用型策略发展举步维艰。
伯克利团队提出的Real2Render2Real (R2R2R),彻底打破了这一困局。其核心思想是:如何不依赖物理仿真或真实机器人硬件,大规模生成高质量的机器人训练数据。
视频演示demo:
不碰真机也不仿真?(伪代码)伯克利最新:仅用一部手机,生成大规模高质量机器人训练数据!
R2R2R首次实现了完全脱离物理仿真与实体硬件的数据规模化生成。
具体是如何做到的?
本文将深度解析这一实现过程的三个关键阶段:资产与轨迹提取、数据增强处理,以及并行渲染生成,并配合代码深入解读这一模型。
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

关键技术解析
在理解了R2R2R的创新价值后,让我们深入探讨这一突破性方法的技术实现细节。
R2R2R的核心在于构建了一个完整的数据生成管道,将真实世界的单次演示转化为大规模的机器人训练数据。整个方法可以分为三个关键阶段:资产与轨迹提取、数据增强处理,以及并行渲染生成。

▲图 1 | Real2Render2Real(R2R2R)为“将马克杯放在咖啡机上”任务生成机器人训练数据。R2R2R 以多视图对象扫描和单目人类演示视频为输入。然后通过并行渲染合成多样化、领域随机化的机器人执行,并输出用于策略训练的成对图像-动作数据。该流程无需远程操作或对象动力学仿真,即可实现跨任务和跨机器人形态的可扩展学习。©️【深蓝具身智能】编译
核心Pipeline文件(伪代码)
from .reconstruction import GaussianSplatting3Dfrom .trajectory import TrajectoryExtractor, TrajectoryInterpolatorfrom .grasp import GraspSamplerfrom .kinematics import DifferentialIKSolverfrom .rendering import IsaacLabRendererfrom .training import PolicyTrainerclassR2R2RPipeline:"""Real2Render2Real 数据生成管道"""def__init__(self):self.gaussian_splatting = GaussianSplatting3D() # 3D高斯泼溅重建self.trajectory_extractor = TrajectoryExtractor() # 轨迹提取器self.grasp_sampler = GraspSampler() # 抓取采样器self.ik_solver = DifferentialIKSolver() # 微分逆运动学求解器self.renderer = IsaacLabRenderer() # 渲染引擎defgenerate_robot_data(self, phone_scan: List[torch.Tensor],demo_video: torch.Tensor,robot_urdf: str) -> Dict:"""主要数据生成流程"""# 阶段1: 真实到模拟的资产和轨迹提取print("阶段1: 提取3D资产和物体轨迹...")object_assets = self._extract_3d_assets(phone_scan)object_trajectory = self._extract_object_trajectory(demo_video, object_assets)# 阶段2: 数据增强和轨迹适配print("阶段2: 生成多样化轨迹...")diverse_trajectories = self._generate_diverse_trajectories(object_trajectory)# 阶段3: 并行渲染和机器人数据生成print("阶段3: 渲染机器人执行数据...")robot_data = self._render_robot_executions(diverse_trajectories, robot_urdf)return robot_data
阶段一:从真实到数字的精确重建
-
3D资产提取:捕捉物体的几何与外观
R2R2R的第一步是将真实世界的物体转化为数字资产。这里采用了3DGS技术,这一选择并非偶然。与传统的多视角立体视觉方法相比,3DGS不仅能够重建物体的几何结构,还能实现背景-前景分离和部件分解。
具体而言,对于智能手机捕获的多视角扫描数据,系统首先应用GARField技术将2D掩码提升到3D空间进行语义分割。这个过程将原始的高斯点云组织成有意义的部件群组,为后续的轨迹提取奠定基础。随后,系统将这些高斯组转换为带纹理的三角形网格,确保与下游渲染引擎的兼容性。

▲图 2 | 使用基于特征聚类的部分级分割进行3DGS物体重建。使用GARField将物体重建并分割成刚性或关节组件。©️【深蓝具身智能】编译
3D重建模块(伪代码)
import torchimport torch.nn as nnfrom typing import List, Tuple, Dictimport numpy as npclass GaussianSplatting3D(nn.Module):"""3D高斯泼溅重建模块"""def __init__(self):super().__init__()self.feature_extractor = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 128, 3, padding=1))def reconstruct_object(self, multi_view_images: torch.Tensor) -> Dict:"""从多视角图像重建3D物体"""# 提取DINO特征用于部件分割features = self.feature_extractor(multi_view_images)# 生成3D高斯点云gaussians = self._fit_gaussians(features)# 使用GARField进行部件分割part_segmentation = self._segment_parts(gaussians)# 转换为三角网格用于渲染mesh = self._convert_to_mesh(gaussians, part_segmentation)return {'gaussians': gaussians,'parts': part_segmentation,'mesh': mesh}
-
4D轨迹提取:从视频到精确运动
轨迹提取是整个方法的核心技术难点。
R2R2R采用4D可微分部件建模(4D-DPM)来追踪演示视频中物体部件的6自由度运动。这个过程涉及复杂的优化问题:
对于每个物体部件,系统使用预训练的DINO特征来嵌入每个3DGS对象部件,建立视觉特征与几何结构的对应关系。通过可微分渲染技术,系统能够优化部件在每个时间步的姿态参数。

轨迹处理模块(伪代码)
class TrajectoryExtractor:"""4D轨迹提取器"""def extract_6dof_trajectory(self, video: torch.Tensor,object_parts: Dict) -> torch.Tensor:"""从演示视频提取6自由度物体轨迹"""T, H, W, C = video.shapetrajectory = torch.zeros(T, 7) # [x, y, z, qx, qy, qz, qw]for t in range(T):frame = video[t]# 使用4D-DPM进行姿态优化pose_t = self._optimize_pose(frame, object_parts, t)trajectory[t] = pose_t# 应用平滑性约束trajectory = self._apply_smoothing(trajectory)return trajectorydef _optimize_pose(self, frame: torch.Tensor, parts: Dict, t: int) -> torch.Tensor:"""通过可微分渲染优化物体姿态"""# 损失函数: L = L_render + λ * L_smoothrender_loss = self._compute_render_loss(frame, parts)smooth_loss = self._compute_smoothness_loss(t)total_loss = render_loss + 0.1 * smooth_lossreturn self._gradient_descent_step(total_loss)class TrajectoryInterpolator:"""轨迹插值器"""def interpolate_trajectory(self, original_traj: torch.Tensor,new_start: torch.Tensor,new_end: torch.Tensor) -> torch.Tensor:"""将原始轨迹适配到新的起始和终止位置"""# 计算仿射变换矩阵transform = self._compute_affine_transform(original_traj, new_start, new_end)# 对平移分量应用线性插值new_positions = self._interpolate_positions(original_traj[:, :3], transform)# 对旋转分量使用球面线性插值 (Slerp)new_rotations = self._slerp_rotations(original_traj[:, 3:], new_start[3:], new_end[3:])return torch.cat([new_positions, new_rotations], dim=1)def _slerp_rotations(self, original_rots: torch.Tensor,start_rot: torch.Tensor,end_rot: torch.Tensor) -> torch.Tensor:"""球面线性插值处理旋转"""# R_new(s) = R_start * Slerp(I, R_start^(-1) * R_end, s) * R_offset(s)T = original_rots.shape[0]interpolated = torch.zeros_like(original_rots)for t in range(T):s = t / (T - 1) # 插值参数 [0, 1]interpolated[t] = self._slerp_single(start_rot, end_rot, s)return interpolated
阶段二:智能数据增强与轨迹适配
-
轨迹插值:适应多样化初始条件
原始演示轨迹只适用于特定的初始配置,而实际应用需要处理各种起始位置。R2R2R开发了一套巧妙的轨迹插值方案来解决这一挑战。

这种插值策略不仅保持了轨迹的语义一致性,还确保了运动的物理合理性。
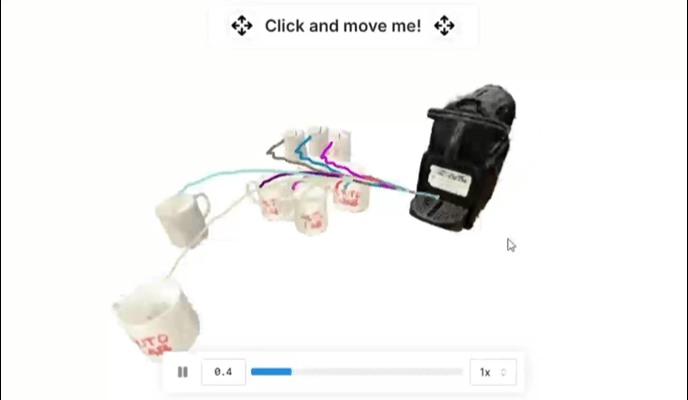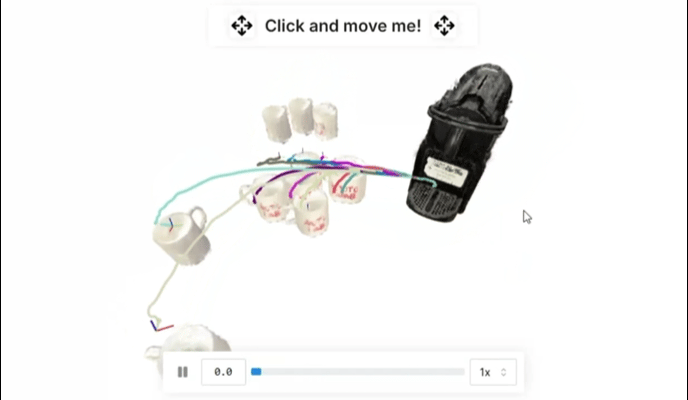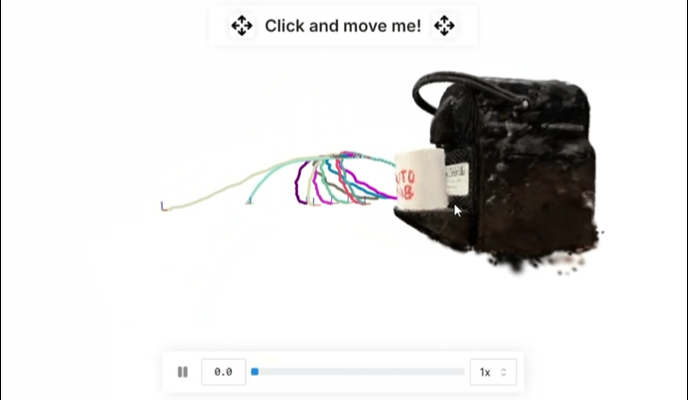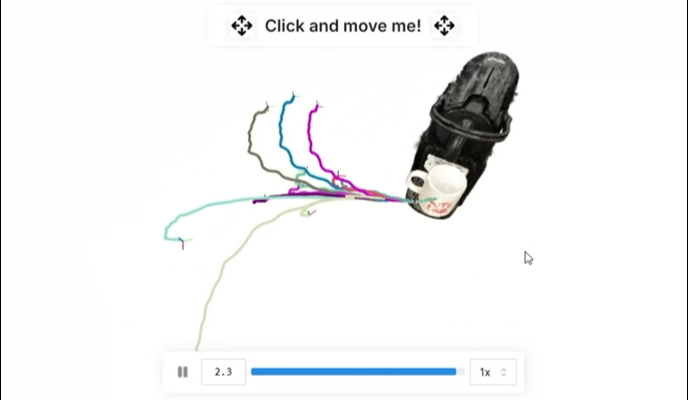
▲图 3 | 通过单次演示,R2R2R 通过插入 6-DoF 部分运动来生成合理轨迹的分布。
-
抓取姿态的智能采样
确定何时何地进行抓取是机器人操作的关键问题。
R2R2R通过分析人类演示中的手部关键点来解决这一问题。系统首先从演示视频中估计3D手部关键点,特别关注食指指尖和拇指的位置。

系统选择在整个轨迹中与手部距离最小的部件作为抓取目标, 并在该部件表面采样候选抓取点。为了获得高质量的抓取姿态, 系统对 3DGS 点云进行表面平滑和抽稀处理, 然后使用解析对趾抓取采样器确定最优的抓取轴向。
抓取和运动模块(伪代码)
class GraspSampler:"""抓取姿态采样器"""def sample_grasps(self, demo_video: torch.Tensor,object_parts: Dict) -> List[torch.Tensor]:"""从演示视频中采样抓取姿态"""# 估计3D手部关键点hand_keypoints = self._estimate_hand_keypoints(demo_video)# 计算手部与物体部件的距离矩阵distances = self._compute_hand_object_distances(hand_keypoints, object_parts)# 选择最近的部件作为抓取目标grasp_part = self._select_grasp_part(distances)# 在选定部件表面采样抓取点grasp_candidates = self._sample_surface_grasps(grasp_part)return grasp_candidatesclass DifferentialIKSolver:"""微分逆运动学求解器"""def solve_ik_trajectory(self, object_trajectory: torch.Tensor,grasp_poses: List[torch.Tensor],robot_urdf: str) -> torch.Tensor:"""求解机器人关节轨迹"""T = object_trajectory.shape[0]joint_trajectory = torch.zeros(T, 7) # 7自由度机械臂for t in range(T):target_pose = object_trajectory[t]# 微分逆运动学: q̇ = J†(q) * ẋ + (I - J†J) * zjacobian = self._compute_jacobian(joint_trajectory[t-1] if t > 0 else torch.zeros(7))jacobian_pinv = torch.pinverse(jacobian)# 计算关节速度pose_velocity = self._compute_pose_velocity(target_pose, t)joint_velocity = jacobian_pinv @ pose_velocity# 积分得到关节位置if t > 0:joint_trajectory[t] = joint_trajectory[t-1] + joint_velocity * 0.01 # dt=0.01selse:joint_trajectory[t] = joint_velocity * 0.01return joint_trajectory
阶段三:高效渲染与策略训练
-
微分逆运动学求解
得到物体轨迹和抓取点后,系统需要计算相应的机器人关节轨迹。
R2R2R采用微分逆运动学方法,避免了复杂的动力学建模。这里的核心假设是物体在接触期间刚性地跟随轨迹,将复杂的多体动力学问题简化为纯几何问题。
微分逆运动学的求解可以表示为:

-
并行渲染与策略学习
最终的渲染阶段采用IsaacLab作为渲染引擎,支持基于瓦片的渲染、深度学习超采样(DLSS)和网格资产实例化。通过域随机化技术,系统在光照条件、相机参数和物体初始姿态方面引入变化,增强生成数据的多样性。

▲图 4 | 随机化初始物体姿势、光照和相机姿势,为每个物体任务组合生成不同的合成展开
在单个NVIDIA RTX 4090上,系统平均每分钟可以渲染51个完整的机器人演示,比人类远程操作快27倍。这种高吞吐量使得大规模数据生成成为可能,为训练现代模仿学习策略提供了充足的数据基础。
生成的数据直接用于训练两种主流架构:Diffusion Policy采用100k步从零训练,输入4时间步的本体感知和448px RGB观测,输出16个未来绝对末端执行器姿态;π0-FAST使用LoRA进行30k步微调,输入单个224px图像,预测10步相对关节角度动作块。这种端到端的训练流程确保了从数据生成到策略部署的无缝衔接。
渲染模块(伪代码)
class IsaacLabRenderer:"""高性能并行渲染器"""def render_robot_executions(self, joint_trajectories: List[torch.Tensor],object_meshes: Dict,num_variations: int = 1000) -> Dict:"""并行渲染多样化的机器人执行过程"""rendered_data = {'rgb_observations': [],'actions': [],'success_labels': []}for i in range(num_variations):# 领域随机化scene_config = self._randomize_scene(object_meshes)# 渲染RGB观测序列rgb_sequence = self._render_rgb_sequence(joint_trajectories[i % len(joint_trajectories)],scene_config)# 记录动作序列action_sequence = self._extract_actions(joint_trajectories[i % len(joint_trajectories)])rendered_data['rgb_observations'].append(rgb_sequence)rendered_data['actions'].append(action_sequence)rendered_data['success_labels'].append(1) # 假设生成的轨迹都成功return rendered_datadef _randomize_scene(self, meshes: Dict) -> Dict:"""场景随机化:光照、相机、物体姿态"""return {'lighting': torch.rand(3) * 0.5 + 0.5, # 随机光照强度'camera_pose': torch.randn(6) * 0.02, # 随机相机扰动 (±2cm, ±5°)'object_pose': torch.randn(6) * 0.1 # 随机物体初始姿态}
训练模块(伪代码)
class PolicyTrainer:"""策略训练器"""def train_policy(self, synthetic_data: Dict,policy_type: str = "diffusion") -> nn.Module:"""使用合成数据训练机器人策略"""if policy_type == "diffusion":policy = DiffusionPolicy(obs_dim=448*448*3, action_dim=16)# 训练100k步,输入4时间步观测,输出16个末端执行器姿态elif policy_type == "pi0_fast":policy = Pi0FastPolicy(obs_dim=224*224*3, action_dim=10)# LoRA微调30k步,输入单张图像,输出10步关节角度# 训练循环for epoch in range(100000 if policy_type == "diffusion" else 30000):batch = self._sample_batch(synthetic_data)loss = policy.compute_loss(batch)loss.backward()# 优化器步进...return policy# 主要使用示例def main():"""R2R2R使用示例"""# 初始化管道r2r2r = R2R2RPipeline()# 输入数据:智能手机扫描 + 演示视频phone_scan = torch.rand(20, 3, 512, 512) # 20张多视角图像demo_video = torch.rand(100, 480, 640, 3) # 100帧演示视频robot_urdf = "franka_panda.urdf"# 生成大规模机器人训练数据print("开始生成机器人训练数据...")robot_data = r2r2r.generate_robot_data(phone_scan, demo_video, robot_urdf)# 训练策略trainer = PolicyTrainer()diffusion_policy = trainer.train_policy(robot_data, "diffusion")print(f"成功生成 {len(robot_data['rgb_observations'])} 个机器人演示")print("策略训练完成,可部署到真实机器人!")if __name__ == "__main__":main()

实验
-
大规模实验验证
R2R2R方法的有效性通过一系列严格的物理机器人实验得到了充分验证。研究团队在ABB YuMi IRB14000双臂机器人上进行了1,050次物理评估,这一规模在机器人学习领域堪称罕见。
值得注意的是,这个机器人平台在π0-FAST预训练过程中从未见过,这为实验结果的泛化性提供了有力保证。实验设计巧妙地涵盖了五个不同类型的操作任务:单物体抓取("拿起玩具老虎")、多物体交互("把杯子放在咖啡机上")、铰接物体操作("关闭水龙头"和"打开抽屉")以及双臂协调("用双手拿起包裹")。这些任务直接对应了R2R2R在部件级分割、铰接物体重建和多臂抓取规划方面的核心能力,部分任务可视化如下。

▲图 5 | 将杯子放在咖啡机上-演示视频帧

▲图 6 | 将杯子放在咖啡机上-示例R2R2R框架

▲图 7 | 将杯子放在咖啡机上-在真实物理机器人上执行策略以收集数据的过程

▲图 8 | 真机展示
-
性能缩放
实验结果揭示了一个重要规律:R2R2R生成数据的性能表现与数据集规模呈现可预测的单调递增关系,如图5所示。以"把杯子放在咖啡机上"任务为例(见图2b),当训练数据从150个演示增加到1000个时,基于扩散策略的成功率从33.3%提升到53.3%,而π0-FAST的表现更是从33.3%跃升至80.0%。
这种性能缩放特性正是大规模机器学习的核心优势。

▲图 9 | 物理实验比较 Real2Render2Real 和人工远程操作的数据效率 任务成功率与数据生成时间(小时)之间的关系被绘制成图。实线表示在 π0-FAST 和 Diffusion Policy 上的性能平均值。Real2Render2Real 的曲线(蓝色方块)包括由单个 Nvidia RTX 4090 生成的 50、100、150 和 1000 条轨迹对应的点。人工远程操作的曲线(金色方块)包括 50、100 和 150 条轨迹对应的点。Real2Render2Real 的数据生成时间包括 10 分钟的设置成本,而人工远程操作时间基于 150 次演示的真实轨迹采集时间计算。©️【深蓝具身智能】编译
虽然在小规模数据集上,真实遥操作数据仍然具有明显优势(如π0-FAST在150个真实演示上达到73.3%,而在150个R2R2R演示上仅为33.3%,如上图b所示),但随着规模扩展到1000个演示,R2R2R生成的数据在多个任务上达到了与遥操作数据相当甚至更优的性能。
这些发现表明,虽然真实数据在单个演示的效率上更高,但R2R2R的生成能力使得轨迹多样性的扩展远超人类生成速度,最终以更少的收集工作量实现了具有竞争力的性能。

总结
传统方法面临的三重困境——遥操作数据收集缓慢、物理仿真复杂难调、3D资产创建耗时——在R2R2R的框架下得到了系统性解决。通过将复杂的多体动力学问题简化为几何约束问题,R2R2R避开了传统仿真方法的技术陷阱,同时保持了足够的物理真实性。
这种"化繁为简"的设计,正如研究者们所强调的,这并非对物理引擎的批评,而是一个积极发现:在许多机器人操作任务中,精确的动力学建模可能并非必需,基于几何约束的轨迹生成已经足以支撑有效的策略学习。
R2R2R提供的大规模数据生成能力有望为通用型机器人策略的发展注入新的动力:通过计算化的数据生成来突破传统数据获取的瓶颈。
尽管R2R2R在机器人学习数据生成方面取得了显著突破,但该方法仍存在一些需要进一步改进的技术局限性。
-
重建与仿真保真度的权衡
R2R2R依赖基于视觉的重建方法,虽然能产生高保真度的外观效果,但往往缺乏防水密封或物理上合理的几何结构。
-
场景多样性与碰撞感知不足
当前的轨迹生成采用几何插值方法,没有考虑环境上下文,如干扰物体或障碍物。在杂乱或多物体场景中,缺乏快速运动规划技术的集成影响了碰撞避免和鲁棒性。
-
操作任务范围的限制
R2R2R目前专注于使用抓取操作处理刚体和铰接物体,不支持可变形物体处理或非抓取策略(如推动、倾倒或滑动)。
-
抓取通用性受限
当前的抓取生成模块使用对跖抓取采样,限制了与平行夹爪的兼容性,排除了多指或拟人手等更复杂的末端执行器。
-
跟踪鲁棒性挑战
R2R2R在快速运动、严重遮挡、纹理匮乏或反射表面等情况下容易出现跟踪失败。这些失败可能导致物体重建和姿态跟踪不准确,进而影响数据质量,产生无效抓取或难以迁移到真实世界的轨迹。
随着真实到仿真管道在物理真实性方面的不断成熟,未来版本的R2R2R有望集成仿真层,更好地支持滑移检测、手内校正或可变形物体交互等任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









