



导读
随着自动驾驶技术的发展,如何让AI做出更可靠、透明的驾驶决策一直是业界难题。最新研究X-Driver将多模态大语言模型与思维链推理相结合,创建了一个全新的端到端自动驾驶框架。这一创新方法不仅能解释其决策过程,还在闭环评估中取得了突破性成果。本文深入解析X-Driver如何通过结构化推理提升自动驾驶安全性与性能,为行业带来全新思路。
1. 研究背景
端到端自动驾驶作为一种新兴的范式,它将感知、预测和决策整合到单一框架中。虽然传统的模块化流程提供了可解释性,但它们常常遭受错误传播的困扰,并且在多样化环境中泛化能力较弱。近期多模态大语言模型(MLLMs)的进展为利用多样化输入模态(如自然语言指令和视觉数据)来增强自动驾驶决策提供了新的机会。
尽管MLLMs显示出巨大潜力,现有方法仍面临关键限制。首先,传统自动驾驶系统依赖模块化设计和固定格式的传感器输入,使有效整合多模态数据变得具有挑战性。其次,当前基于MLLM的框架在闭环评估中表现不佳,在实际驾驶场景中显示出幻觉和缺乏稳健性。这些挑战凸显了明确推理机制对增强可解释性和可靠性的必要性。
为解决这些问题,作者提出了X-Driver,一个统一框架,无缝集成感知、推理和决策于自动驾驶中。X-Driver利用自回归Transformer进行多模态融合。受DriveCoT启发,作者采用了思维链(Chain-of-Thought, CoT)提示,这种方法将模型的推理过程结构化,以增强决策透明度和稳健性。通过使用给定的提示和思维链训练模板,并将它们应用于物体检测、交通检测、交通标志检测和车道检测等任务,系统能基于数据进行逐步推理,最终做出决策。实验表明,X-Driver能够明确提供其决策背后的理由。广泛的闭环评估证明,这种方法显著改善了相比现有框架的性能。
论文的主要贡献可概括为:
1)MLLM和CoT融合:将思维链推理整合到自动驾驶中可以进一步减轻模型幻觉,显著降低决策错误的可能性。
2)统一的闭环自动驾驶框架:X-Driver支持多模态数据输入,超越了对固定格式传感器数据的依赖。这种灵活性改善了系统的泛化能力,使其能更有效地适应多样化和复杂的驾驶环境。并且作者已经完成了闭环实验。
2. 研究方法
X-Driver系统的核心是LLaVA,这是一种多模态模型,它将视觉编码器与大型语言模型对齐,使其能够理解图像并基于视觉和文本输入进行对话和推理。
在多模态大语言模型(MLLMs)中,一个典型的推理过程可以表示为:
对于整个时间序列,MLLM以自回归方式生成输出命令:
其中T代表文本输入,所有提示、导航命令和场景描述被统一到单个文本序列中,以充分利用MLLM的理解和生成信息的能力;表示每个时间步的帧图像输入;
是作者使用的MLLM,即LLaVA。在这个系统中,作者对LLaVA进行了监督式微调,以增强其处理自动驾驶任务的能力。
2.1 系统概述
如图1所示,X-Driver系统利用了集成了思维链(CoT)推理机制的多模态大语言模型,以增强自动驾驶决策制定。系统处理多模态输入,包括来自摄像头数据的图像向量和代表导航命令和提示的文本向量。通过使用CoT推理,MLLM执行场景理解、导航指令解释和交通规则理解,以生成适当的决策来实现精确的驾驶动作。系统以闭环方式运行,执行的动作影响现实环境,产生新的感知数据用于持续优化。这种方法提高了决策的可解释性,增强了在不同场景中的泛化能力,并加强了端到端自动驾驶的安全性和稳健性。

图1:系统概述
2.2 MLLM和CoT的融合
在作者的MLLM中,他们通过利用高质量CoT提示数据的监督式微调(SFT)增强了自动驾驶场景中的推理和决策能力。具体来说,他们将精心设计的逐步推理示例整合到模型输入中,以鼓励结构化、逻辑性思考,而不是让模型仅输出孤立的决策。他们的CoT推理框架建立在模型对两个关键维度的全面理解之上:
1)它包括对复杂3D驾驶环境的准确感知和解释,包括对动态物体位置、速度和轨迹的精确预测。这些物体包括具有不同行走速度和意图的行人,可能突然改变方向的骑车人,以及呈现不同驾驶行为(如加速、制动或变道)的各种尺寸车辆(如汽车、卡车、摩托车)。此外,它确保实时障碍物识别,如道路碎片、施工障碍物和静止车辆,并精确进行空间定位以维持安全导航。
2)它涉及对导航指令的深入理解和对交通规则的遵守,包括识别交通灯状态,区分标准红、黄、绿信号以及更复杂的变体,如闪烁的黄灯或行人控制的信号。此外,它需要解释交通标志,包括监管标志(如停止、让行、限速)、警告标志(如急转弯、行人过街)和信息标志(如高速公路出口、距离标记)。准确的车道检测和决策也至关重要,包括在各种条件下检测车道边界(如褪色标记、被车辆遮挡),区分实线和虚线以进行合法变道,以及识别特殊车道如公交车道、自行车道和转弯专用车道,以确保合法高效驾驶。
为确保更高的性能和对图像的理解,作者避免使用VQ-VAE等离散编码方法,这可能导致场景表示中的信息丢失。相反,他们采用连续图像编码方法,首先将原始图像通过ViT编码器传递,获得低维特征图。这一策略保留了更丰富的场景信息。例如,在实验中,当交通灯出现在远处场景时,使用VQ-VAE编码可能导致关于交通灯的关键信息丢失。相反,利用VAE编码有效地保留了这一必要信息。
如图2所示,这是SFT训练过程的详细示例。作者的CoT方法本质上将原始任务分解为四个子任务,如物体检测、交通灯状态、交通标志和车道信息。然后,模型将这些中间结果作为历史令牌和当前传感器输入整合起来,生成最终驾驶决策并预测下一个航点。这种结构化推理使端到端自动驾驶中的输出更具可解释性和可控性。
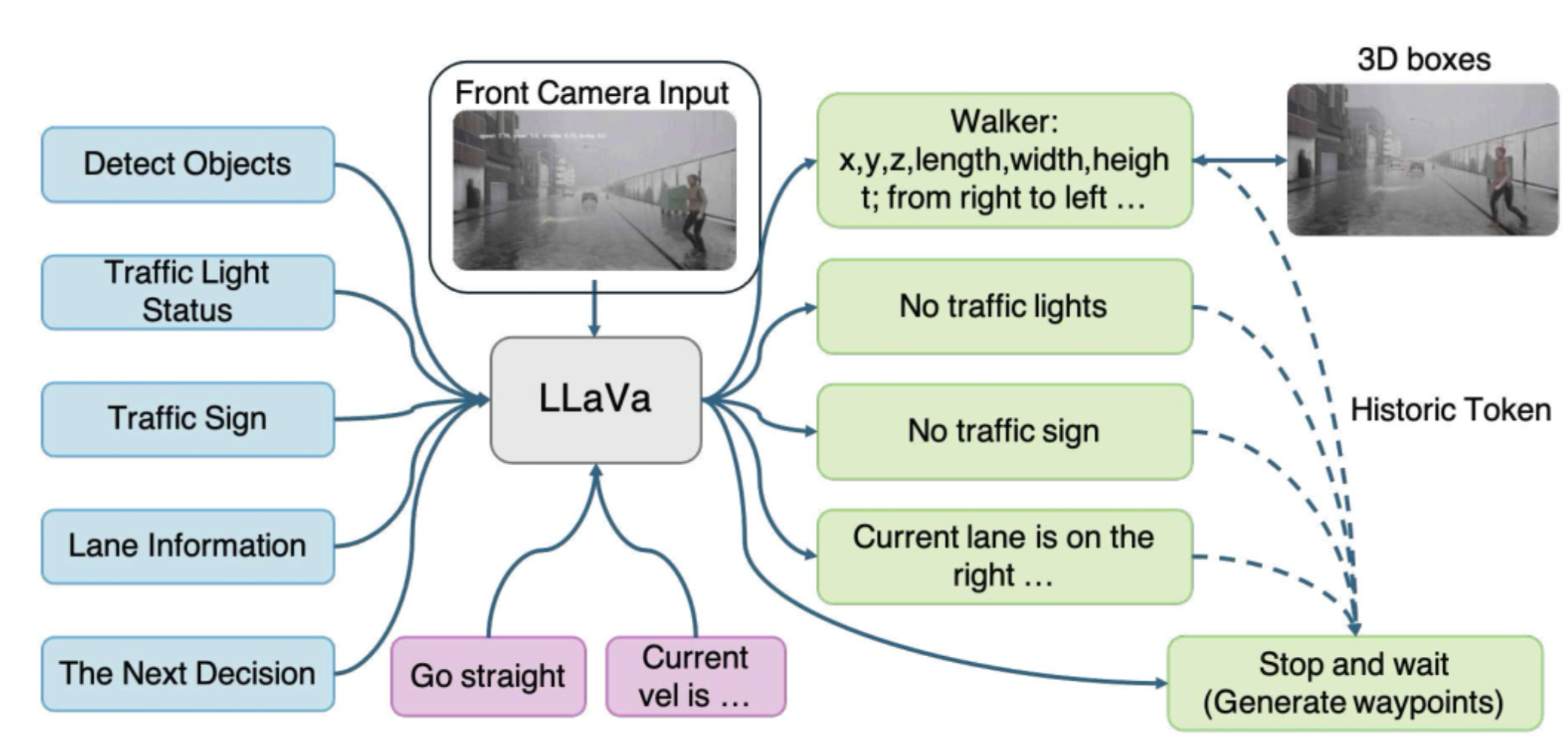
图2:训练过程
2.3 CoT推理过程
如图1所示,X-Driver的方法始于生成高质量CoT训练数据,整合了摄像机输入和当前车辆速度。随后,MLLM对这些传感器输入进行深度多模态融合和分析,由CoT提示系统性地引导,清晰地阐述出一个逐步的推理过程。
为什么CoT推理如此有效,它在大型语言模型的推理过程中扮演什么角色?以CoT中的物体检测为例,如图3所示,模型首先确定物体的位置、运动方向和类别。然后分析该物体是否根据上下文线索值得关注。如果需要关注,模型提供基于推理的解释,说明为什么关注该物体,并相应地更新其最终决策。
表1展示了自动驾驶中遇到的典型驾驶场景,以及引导MLLM通过明确、逻辑决策步骤的详细提示。这些提示指导模型纳入全面的情境意识,严格遵守安全准则和交通规则,显著提高驾驶安全性并减少错误模型行为。
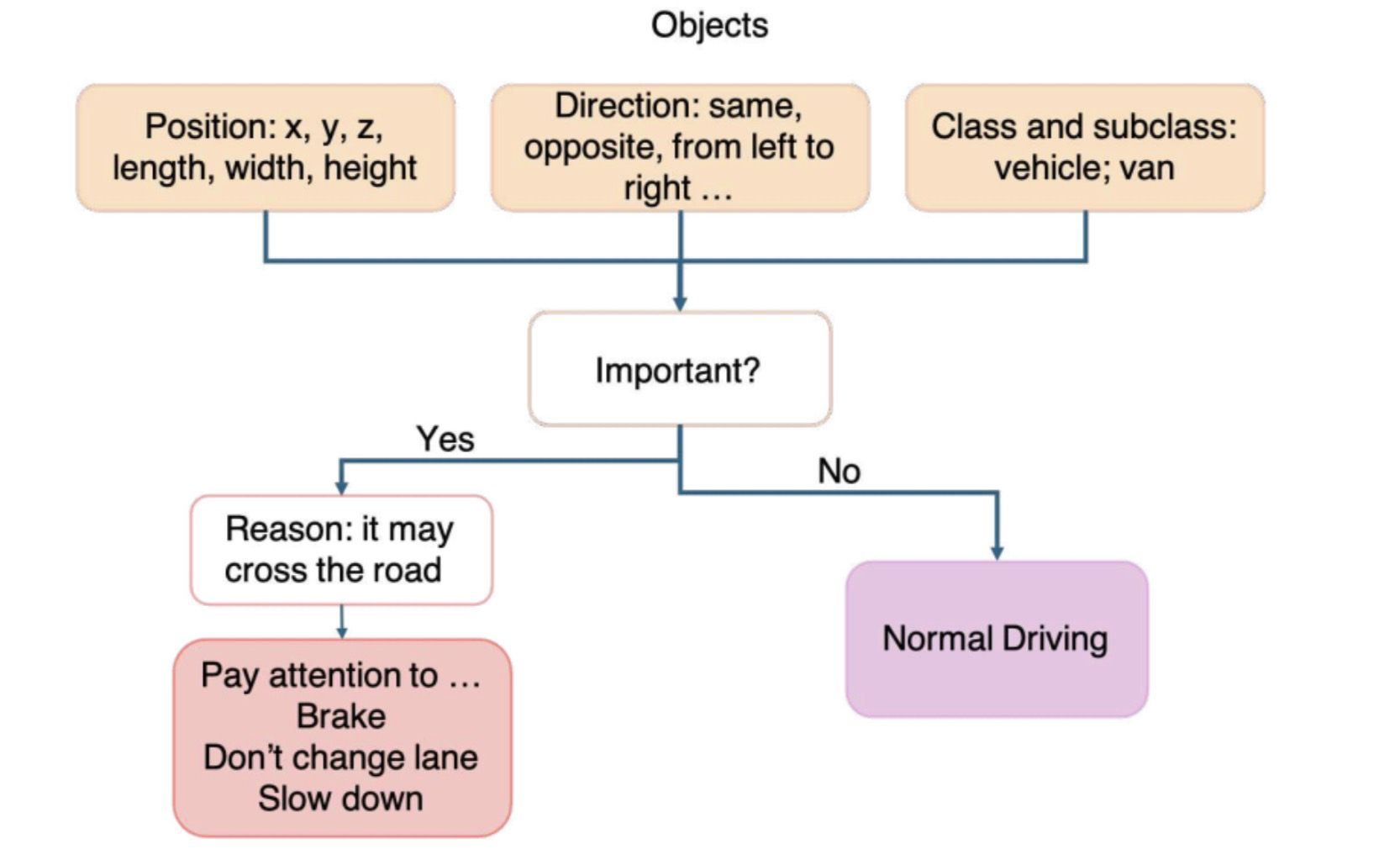
图3:思维链如何影响决策
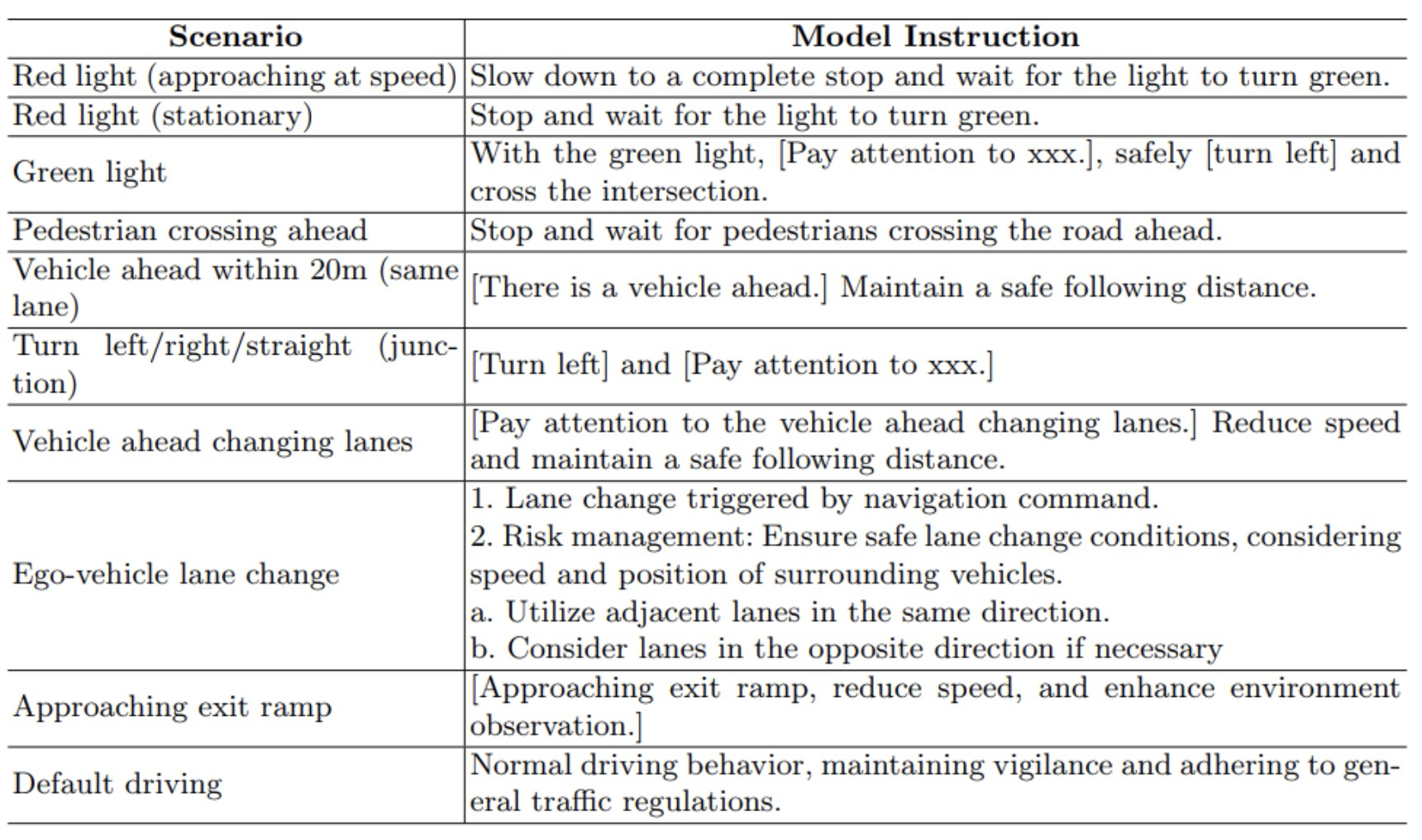
表1:自动驾驶场景
2.4 闭环自动驾驶框架
如图1所示,X-Driver框架系统地通过基于导航指令和图像数据的综合理解和推理生成驾驶决策。这种方法不仅输出可行动的决策,还提供每个决策背后的明确推理,确保CARLA模拟环境中驾驶动作的可解释性和稳健性。具体而言,MLLM基于当前传感器输入和车辆速度,生成实时驾驶命令和相应的航点预测。随后,自车根据这些航点和决策命令动态调整其移动,从而维持闭环控制机制。作者的方法在Bench2Drive数据集上达到了最先进(SOTA)性能,展示了自动驾驶能力的显著进步。
3. 试验
3.1 基准和数据集
Bench2Drive:一个具有200多万帧的模拟基准,评估不同条件下(城市、高速公路、恶劣天气)的闭环驾驶性能。
3.2 开环实验
在CoT部分,作者比较了CoT不同阶段的识别性能。
3D物体识别
在3D物体识别实验中,作者通过计算IoU测试了3D边界框识别的准确性。实验的定量结果如表2所示。

表2:3D物体识别
在该表中,IoU(sample)和IoU(box)测量预测框和真实框之间的重叠,前者是样本级评估,后者是框级评估。精确度表示预测为正的样本中真正例的比例,召回率表示被正确预测的真正例比例。Pred(total)是模型预测的物体数量,gt(total)是数据集中真实物体的数量。
从该表可以看出,作者的物体识别方法达到了相当高的准确率。
航点准确性
为评估模型在未来轨迹预测的准确性,作者进行了关于航点误差的开环实验。实验结果如表3所示。
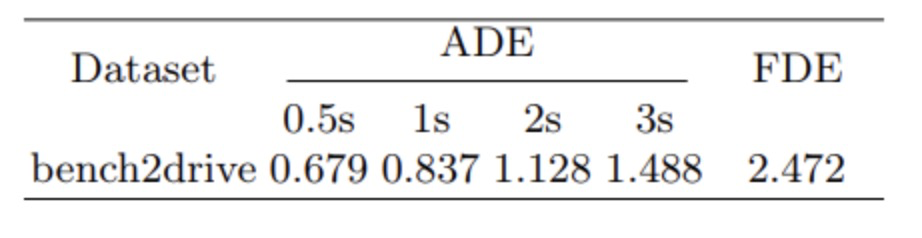
表3:航迹点准确性
ADE(平均位移误差)和FDE(最终位移误差)是两个关键评估指标,用于测量预测轨迹与真实轨迹之间的偏差。实验结果表明,作者的大型模型对未来轨迹的预测准确率达到了不到1%的水平,展示了出色的性能。
3.3 闭环实验
作者使用CARLA模拟环境在闭环设置中评估了他们的方法,重点关注驾驶得分和成功率作为关键性能指标。驾驶得分通过考虑路线遵循、速度控制和交通规则遵守等因素评估整体驾驶质量,而成功率测量成功完成驾驶任务的百分比,确保车辆在没有碰撞或重大违规的情况下到达目的地。
定性研究
在图4所示的闭环消融实验中,CoT方法的明显优势是显而易见的。具体来说,CoT版本成功识别了过马路的行人,并及时启动制动以避免碰撞。相比之下,基于辅助任务的版本未能检测到行人,导致了碰撞。

图4:CoT对比试验
定量研究
作者在Bench2Drive数据集上与当前最先进的UniAD进行了评估,该数据集包含500K和2.2M样本。表4中的结果表明,作者的方法在多个数据集的关键指标上始终优于SOTA,进一步证实了CoT推理可以显著提高MLLMs的决策准确性。
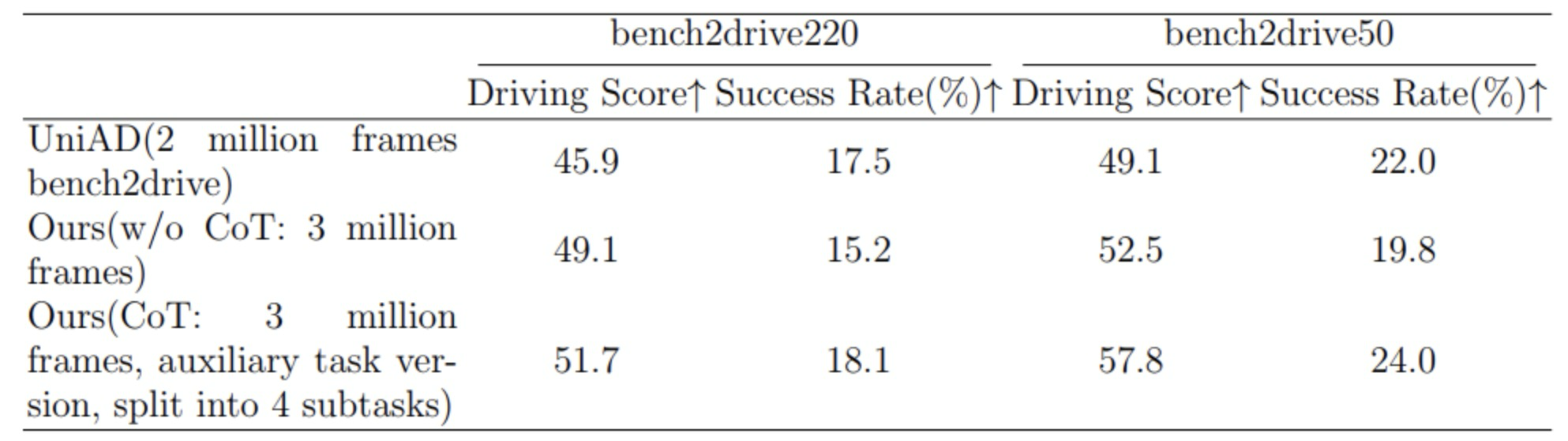
表4:对比试验
4. 结论
总体而言,作者提出了一个统一的端到端自动驾驶框架,该框架利用MLLM进行决策,同时整合CoT推理以增强可解释性。通过明确建模推理过程,他们的方法有效减轻了幻觉和决策错误,导致更一致、可靠和符合人类期望的驾驶行为。此外,该框架通过增强模型理解复杂驾驶场景、遵守交通规则以及实时做出知情、上下文感知决策的能力,显著改善了自动驾驶系统中的闭环驾驶性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









