



引言
强化学习与最优化是两种常见的策略设计方法,广泛应用于自动控制、机器人学等领域。它们在无人机轨迹控制、机器人操作等任务中展现了各自的优势。
例如,如图1所示,浙江大学发表在《Science Robotics》上的“Swarm of micro flying robots in the wild”[1]和香港大学发表在《IEEE Transactions on Robotics》上的“FAPP: Fast and Adaptive Perception and Planning for UAVs in Dynamic Cluttered Environments”[2]利用最优化方法分别实现了无人机轨迹规划穿越竹林、密集环境动态避障。
而如图2所示,苏黎世大学发表在《Nature》上的"Champion-level Drone Racing using Deep Reinforcement Learning”[3]则通过强化学习训练无人机,使其在竞速中击败了人类冠军。清华大学发表在《CoRL》上的“Learning to Manipulate Anywhere: A Visual Generalizable Framework For Reinforcement Learning”[4]则展示了强化学习在跨视角操作任务中的潜力。这些研究表明,强化学习和最优化在不同场景下各有优劣。本文将从两者的区别以及效果差异出发,探讨如何在实际应用中选择合适的方法。
©️【深蓝AI】编译

▲图1 | (a)无人机轨迹规划穿越竹林,(b)密集环境动态避障©️【深蓝AI】编译

▲图2 | (a)强化学习无人机在竞速比赛中击败人类冠军,(b)强化学习控制机械臂实现跨视角操作任务©️【深蓝AI】编译
强化学习与最优化的区别
1.模型依赖性
最优化方法通常依赖于精确的系统模型和明确的性能指标。它需要对系统的动态特性进行数学建模,例如通过微分方程、状态空间模型或传递函数来描述系统行为。基于这些模型,最优化方法通过求解数学问题(如凸优化、动态规划或线性二次调节器)来设计控制策略。例如,在无人机轨迹规划中,最优化方法需要精确的动力学模型和环境模型来生成最优路径。
强化学习不依赖于精确的系统模型,而是通过与环境的交互来学习策略。它通过试错和奖励信号来优化行为,适合模型未知或高度复杂的场景。例如,在无人机竞速中,强化学习可以通过与仿真环境或真实环境的交互,学习如何在复杂动态环境中飞行,而无需预先知道环境的精确模型。
2.学习方式
最优化方法通常是离线设计的,即在系统运行之前,基于预先定义的模型和优化算法求解最优控制策略。例如,在工业过程控制中,最优化方法可以离线计算最优控制参数,然后在实际系统中应用。
强化学习是一个在线学习过程,能够通过试错和实时数据不断调整策略。它通过与环境的交互来收集数据,并利用这些数据更新策略。例如,在自动驾驶中,强化学习可以通过与仿真环境或实际道路的交互,实时调整驾驶策略以适应不同的交通状况。虽然近年来出现了一些离线强化学习算法,但是离线强化学习的数据仍然需要通过与环境在线交互获得。
3.计算复杂度
最优化方法在高维或非线性问题中可能面临“维度灾难”,计算成本较高。例如,在机器人运动规划中,如果状态空间或动作空间的维度很高,最优化方法的计算复杂度会急剧增加,导致求解时间过长甚至无法求解。
强化学习通过采样和近似方法(如深度强化学习)可以处理高维问题。例如,深度Q网络(DQN)和策略梯度方法能够利用神经网络近似值函数或策略,从而在高维状态空间和动作空间中学习有效策略。
4.适应性与鲁棒性
最优化方法在模型准确时表现优异,但在模型偏差或环境变化时可能失效。例如,在无人机控制中,如果环境风速或障碍物位置发生变化,基于最优化方法设计的轨迹可能不再适用。
强化学习具有较强的适应性和鲁棒性,能够应对动态环境和不确定性。例如,在动态障碍物环境中,强化学习可以通过在线学习调整飞行策略,避免碰撞并完成任务。如图3所示,强化学习在无人机穿越门框的任务中值函数分布明显导向穿越门框任务,这说明策略学习到了更任务导向的行为(如偏离轨迹去通过目标门),这种目标可以提高对任务环境的适应性,从而增强鲁棒性[5]。
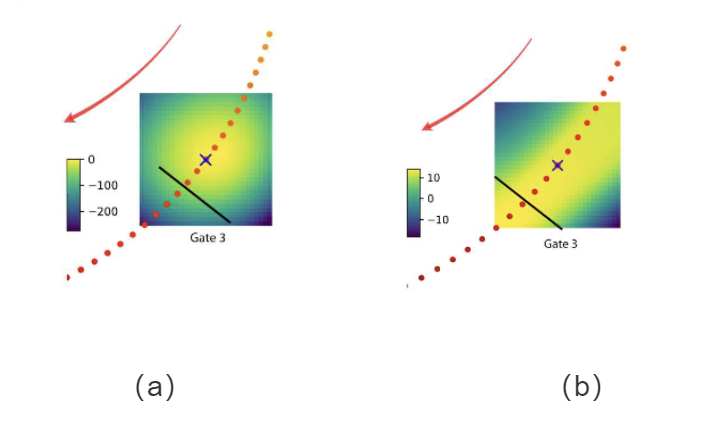
▲图3 | 无人机穿越门框俯视图,红点为无人机轨迹,箭头指示无人机飞行方向,不同颜色表示值函数不同的数值,(a)通过优化得到的最大化值函数分布,(b)通过强化学习得到的最大化值函数分布 ©️【深蓝AI】编译
5.探索与利用
最优化方法通常缺乏探索机制,直接基于模型和性能指标求解最优解。这种方法容易陷入局部最优,尤其是在非凸优化问题中。
强化学习通过探索新策略和利用已知策略来优化性能。例如,在SAC、Q-learning中,智能体通过探索未知状态和动作来发现更优的策略。如图3所示,值函数的分布中体现了强化学习的探索与利用能力,探索被引导至更能完成任务的区域。
使用指南
根据上述分析可知,最优化方法依赖于精确的数学模型,通过计算求解最优策略,适合模型已知且静态的场景,但在高维问题或环境变化时可能失效。强化学习则通过与环境的交互在线学习策略,不依赖精确模型,适合复杂、动态的任务,具有较强的适应性和鲁棒性,但需要大量数据和计算资源。在实际工程落地中,选择强化学习还是最优化方法需要取决于具体问题的特点:
-
具有精确的模型:如果系统的数学模型已知且精确,最优化方法通常能够提供高效且可靠的解决方案。例如,在工业控制、机器人轨迹规划等任务中,最优化方法可以通过计算生成最优控制策略。当然,在这种情况下也可以使用强化学习做数值仿真,并通过sim2real在现实场景下部署应用。但是,相比于不需要经过训练就可以应用的最优化方法,强化学习需要消耗更多的时间和计算资源。因此,在这种情况下可以通过权衡训练成本来选择最优化或者强化学习方法。
-
没有精确的模型但有精确的仿真环境:如果系统的数学模型未知或难以精确构建,但可以构建精确的仿真环境(如近期爆火的生成式物理殷引擎Genesis),强化学习是一个理想的选择。
通过仿真器,强化学习可以在虚拟环境中进行大量试错训练,学习到适应复杂动态环境的策略。例如,在无人机竞速或自动驾驶任务中,强化学习可以通过仿真器训练智能体,使其掌握在动态环境中的飞行或驾驶技能。即便存在sim2real的问题,但由于仿真环境足够精确,强化学习在真实环境中也可以较好地应用。虽然最优化方法可以通过系统辨识技术获得近似模型,但这种方法通常需要大量的实验数据,并且对噪声和不确定性较为敏感。
此外,系统辨识得到的模型可能无法完全捕捉系统的复杂动态特性,尤其是在高度非线性或高维问题中。相比之下,强化学习通过仿真环境直接学习策略,绕过了对精确数学模型的依赖,能够更好地适应复杂和动态的任务场景。因此,在仿真环境精确且可用的情况下,强化学习通常是更优的选择。 -
计算资源与时间成本要求较高:计算资源与时间成本要求可以从模型训练和模型部署两个方面进行分析:
a.如果模型训练阶段的计算资源有限或对时间成本有较高要求,最优化方法更具优势。最优化方法通常不需要大量的训练数据和计算资源,它通过数学建模和求解直接生成最优策略,适合快速原型开发和资源受限的场景。例如,在工业控制或机器人轨迹规划中,最优化方法可以通过离线计算快速生成控制策略,而无需长时间的试错训练。相比之下,强化学习需要大量的交互数据和训练时间,训练过程可能非常耗时,因此在训练资源有限的情况下,最优化方法通常是更实际的选择。
b.如果模型部署阶段的计算资源有限(如嵌入式设备或实时控制系统),强化学习更具优势。强化学习通过训练得到模型,部署时只需进行前向计算,计算开销相对较低。例如,在无人机控制或自动驾驶中,强化学习可以将训练好的策略模型部署到嵌入式系统中,实时生成控制指令。而最优化方法在部署时可能需要在线求解优化问题(如模型预测控制 MPC),计算复杂度较高,难以满足实时性要求。因此,在部署资源有限的情况下,强化学习通常是更合适的选择。 -
环境扰动与不确定性:如果任务需要应对环境扰动(如风速变化、传感器噪声)或系统不确定性,强化学习由于其较强的适应性和鲁棒性,通常表现更优。例如,在无人机控制中,强化学习可以通过在线学习调整飞行策略,适应突发的风速变化或障碍物移动。而最优化方法在模型偏差或环境变化时可能失效。
参考文献
[1] Zhou X, Wen X, Wang Z, et al. Swarm of micro flying robots in the wild[J]. Science Robotics, 2022, 7(66): eabm5954.
[2] Lu M, Fan X, Chen H, et al. Fapp: Fast and adaptive perception and planning for uavs in dynamic cluttered environments[J]. IEEE Transactions on Robotics, 2024.
[3] Kaufmann E, Bauersfeld L, Loquercio A, et al. Champion-level drone racing using deep reinforcement learning[J]. Nature, 2023, 620(7976): 982-987.
[4] Yuan Z, Wei T, Cheng S, et al. Learning to manipulate anywhere: A visual generalizable framework for reinforcement learning[J]. arXiv preprint arXiv:2407.15815, 2024.
[5] Song Y, Romero A, Müller M, et al. Reaching the limit in autonomous racing: Optimal control versus reinforcement learning[J]. Science Robotics, 2023, 8(82): eadg1462.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









