



论文标题:
Diffusion for World Modeling:Visual Details Matter in Atari
论文作者:
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, François Fleuret
项目地址:
https://github.com/eloialonso/diamond
导读:
最近的世界模型主要是在离散潜在变量序列上操作来模拟环境动力学。然而,这种压缩成紧凑的离散表示可能会忽略对强化学习很重要的视觉细节,同时扩散模型也已经成为了图像生成的主要方法。在这种范式转变的推动下,通过引入在扩散世界模型中训练强化学习智能体DIAMOND
(DIffusion As a Model Of eNvironment Dreams)所需的关键设计选择,在Atari
100K基准测试中,DIAMOND达到了1.46的人类标准化平均分。©️【深蓝AI】编译
1. 引言
最近的世界建模方法经常将环境动力学建模作为一系列离散潜在变量。潜在空间的离散化有助于避免多步时间范围内的复合误差。然而,这种编码可能会丢失信息,从而导致通用性和重建质量的损失。对于任务所需的信息不太明确的现实场景,例如训练自动驾驶汽车场景,这可能会带来一些问题。在这种情况下,视觉输入中的小细节(如交通灯或远处的行人)可能会改变代理的策略。增加离散电位的数量可以减轻这种有损压缩,但随之而来的是计算成本的增加。
扩散模型已经成为高分辨率图像生成的主导范式,同时易于调节,可以灵活地模拟复杂的多模态分布而不会发生模态崩溃。这些属性有助于进行世界建模,因为遵守条件作用应该允许世界模型更紧密地反映代理的行为,从而产生更可靠的信用分配,并且建模多模态分布应该为代理提供更大的训练场景多样性。
基于这些特征,研究者提出了在扩散世界模型中训练的强化学习智能体DIAMOND(DIffusion As a Model Of eNvironment Dreams),谨慎的设计选择以确保我们的扩散世界模型在长期内是有效和稳定的。DIAMOND在公认的Atari 100K基准上达到了1.46的人类标准化平均分,是完全在世界模型中训练的特工新技术。此外,在图像空间中操作的好处是使扩散世界模型能够替代环境,从而更深入地了解世界模型和代理行为。
2. 前提知识
2.1 强化学习和世界模型
将环境建模为标准的部分可观察马尔可夫决策过程(POMDP:S,A,O,T,R,O,γS,A,O,T,R,O,γS,A,O,T,R,O,γ),其中SSS是状态的集合,aaa是离散动作的集合,OOO是图像观测的集合。跃迁函数T:S×A×S→[0,1]T:S \times A \times S \to [0,1]T:S×A×S→[0,1]描述环境动态p(st+1∣st,at)p(s_{t+1}|s_t,a_t)p(st+1∣st,at),并且奖励函数R:S×A×S→RR:S \times A \times S \to \mathbb{R}R:S×A×S→R将转换映射到标量奖励。由于中间过程不能直接访问状态sts_tst,只能通过图像观测值xtϵOx_t \epsilon OxtϵO看到环境,这些观测值是根据观测概率p(xt∣st)p(x_t |s_t)p(xt∣st)发出的,由观测函数描述O:S×O→[0,1]O:S \times O \to [0,1]O:S×O→[0,1]。目标是获得一个策略π,它将观测映射到行动,以最大化预期收益Eπ[∑t≥0γrrt]\mathbb{E}_ \pi [ {\textstyle \sum_{t\ge 0} \gamma ^r r_t} ]Eπ[∑t≥0γrrt],其中γ∈[0,1]γ∈[0,1]γ∈[0,1]是折扣因子。世界模型是环境的生成模型,即p(st+1,rt∣st,at)p(s_{t+1},r_t|s_t,a_t)p(st+1,rt∣st,at)模型。这些模型可以用作模拟环境,以样本高效的方式训练强化学习代理。在这种范例中,训练过程通常由以下三个步骤组成:
· 在真实环境中使用RL代理收集数据;
· 在所有收集到的数据上训练世界模型;
· 在世界模型环境中训练RL智能体。
2.2 基于分数的扩散模型
扩散模型是一类受非平衡热力学启发的生成模型,通过反转噪声过程生成样本。考虑一个由连续时间变量τ∈[0,T]τ∈[0,T]τ∈[0,T]索引的扩散过程{xτ}τϵ[0,τ]\left \{ {x^\tau } \right \} _{\tau \epsilon[0,\tau ] }{xτ}τϵ[0,τ],其相应的边际{pτ}τϵ[0,τ]\left \{ {p^\tau } \right \} _{\tau \epsilon[0,\tau ] }{pτ}τϵ[0,τ],以及边界条件po=pdatap^o = p^{data}po=pdata和pτ=ppriorp^\tau = p^{prior}pτ=pprior,其中ppriorp^{prior}pprior一个可处理的非结构化先验分布。这个扩散过程可以被描述为标准随机微分方程(SDE)的解:
dx=f(x,τ)dτ+g(τ)dw(1)dx=f(x,\tau )d\tau +g(\tau )dw\qquad(1)dx=f(x,τ)dτ+g(τ)dw(1)
其中www是Wiener过程(布朗运动),fff是作为漂移系数的矢量值函数,ggg是称为过程扩散系数的标量值函数。
为了获得从噪声映射到数据的生成模型,必须逆转这个过程。Anderson(1982)表明逆向过程也是一个扩散过程,在时间上是向后运行的,并由以下SDE描述:
dx=[f(x,τ)−g(τ)2▽xlogpτ(x)]dτ+g(τ)dwˉ(2)dx=[f(x,\tau )-g(\tau)^2 \bigtriangledown _xlogp^\tau (x)]d\tau +g(\tau )d\bar{w}\qquad(2)dx=[f(x,τ)−g(τ)2▽xlogpτ(x)]dτ+g(τ)dwˉ(2)
wˉ\bar{w}wˉ是逆时Wiener过程,▽xlogpτ(x)\bigtriangledown _xlogp^\tau (x)▽xlogpτ(x)为Stein函数,对数边际相对于支撑的梯度。因此,为了逆转前向噪声过程,只需要定义函数fff和ggg,并估计未知Stein函数。在实践中,可以使用单个时间相关的分数模型Sθ(x,τ)S_\theta (x,\tau )Sθ(x,τ)来估计这些分数函数。
在任何时间点,估计分数函数都不是微不足道的,因为无法访问真实的分数函数。但是,Hyvärinen引入了分数匹配目标,可以在不知道底层分数函数的情况下从数据样本中训练分数模型。为了从边际pτp^\taupτ获取样本,需要模拟从时间0到时间τ的前向过程,因为只有干净的数据样本。一般来说,代价较大,但如果f是仿射,可以通过对清洁数据样本应用高斯扰动核poτp^{o\tau}poτ,在单步正演过程中解析地达到任意时间τ。由于核是可微的,分数匹配简化为去噪分数匹配目标:
L(θ)=E[∣∣Sθ(xτ,τ)−▽xτlogp0τ(xτ∣xo)∣∣2](3)L(\theta ) =\mathbb{E }[|| S_\theta (x^{\tau },\tau )-\bigtriangledown _{x^\tau} logp^{0\tau}(x^{\tau}|x^o)||^2]\qquad(3)L(θ)=E[∣∣Sθ(xτ,τ)−▽xτlogp0τ(xτ∣xo)∣∣2](3)
其中期望是扩散时间τττ,噪声样本xτ∼p0τ(xτ∣xo)x^{\tau }\sim p^{0\tau }(x^\tau |x^o)xτ∼p0τ(xτ∣xo),通过将τττ级扰动核应用于干净样本xo∼pdata(xo)x^o \sim p^{data}(x^o)xo∼pdata(xo),重要的是,由于核p0τp^{0\tau}p0τ是一个已知的高斯分布,这个目标变成了一个简单的L2重建损失:
L(θ)=E[∣∣Dθ(xτ,τ)−xo∣∣2](4)L(\theta ) =\mathbb{E }[|| D_\theta (x^{\tau },\tau )-x^o||^2]\qquad(4)L(θ)=E[∣∣Dθ(xτ,τ)−xo∣∣2](4)
参数Dθ(xτ,τ)=Sθ(xτ,τ)σ2(τ)−xτD_\theta (x^{\tau },\tau )= S_\theta (x^{\tau },\tau )\sigma ^2(\tau) -x^\tauDθ(xτ,τ)=Sθ(xτ,τ)σ2(τ)−xτ,其中σ(τ)\sigma(\tau)σ(τ)为τττ级扰动核的方差。
2.3 世界建模的扩散
上一小节中描述的基于分数的扩散模型提供了pdatap_{data}pdata的无条件生成模型。世界模型需要一个环境动力学的条件生成模型p(xt+1∣x≤t,a≤t)p(x_{t+1}|x \leq t,a \leq t )p(xt+1∣x≤t,a≤t)。考虑POMDP的一般情况,其中马尔可夫状态StS_tSt是未知的,可以从过去的观察和行为近似。我们可以在此历史上设置扩散模型的条件,以直接估计和生成下一个观测值,如图1所示。将方程4修改为:
L(θ)=E[∣∣Dθ(xt+1τ,τ,x≤to,a≤t)−xo∣∣2](5)L(\theta ) =\mathbb{E }[|| D_\theta (x^{\tau }_{t+1},\tau ,x^o_{\le t},a_{\le t} )-x^o||^2]\qquad(5)L(θ)=E[∣∣Dθ(xt+1τ,τ,x≤to,a≤t)−xo∣∣2](5)
在训练过程中,从智能体的重播数据集中采样x≤to,a≤t,x≤t+1ox^o_{\le t},a_{\le t} ,x^o_{\le t+1}x≤to,a≤t,x≤t+1o的轨迹段,并通过应用τ级扰动核获得带噪声的下一个观测值xt+1τ∼poτ(xt+1τ∣xt+1o)x^{\tau }_{t+1}\sim p^{o\tau}(x^\tau_{t+1}|x^o_{t+1})xt+1τ∼poτ(xt+1τ∣xt+1o)。总之,世界建模的扩散过程类似于3.2节中描述的标准扩散过程,其分数模型以过去的观察和行为作为条件。
为了对下一个观测值进行采样,迭代地求解方程2中的反向SDE,如图1所示。虽然原则上可以使用任何ODE或SDE求解器,但抽样质量和函数评估数(NFE)之间存在内在的权衡,这直接决定了扩散世界模型的推断成本。

图1|随时间推移,对DIAMOND的想象©️【深蓝AI】编译
3. 方法
3.1 扩散范式的实际选择
考虑扰动核poτ(xt+1τ∣xt+ao)=N(xt+1τ;xt+1o,σ2(τ)I)p^{o\tau}(x^\tau_{t+1}|x^o_{t+a})=\mathcal{N} (x^\tau_{t+1};x^o_{t+1},\sigma ^2(\tau)\mathrm {I} )poτ(xt+1τ∣xt+ao)=N(xt+1τ;xt+1o,σ2(τ)I),其中σ(τ)\sigma(\tau)σ(τ)是扩散时间的实值函数,称为噪声调度。这对应于将漂移和扩散系数设置为f(x,τ)=0(affine)及g(τ)=2σ˙(τ)σ(τ)f(x,\tau)=0(affine)及g(\tau)=\sqrt{2\dot{\sigma} (\tau) \sigma (\tau) }f(x,τ)=0(affine)及g(τ)=2σ˙(τ)σ(τ)。
通过引入网络预处理,并相应地将式5中的DθD_{\theta}Dθ参数化为神经网络FθF_{\theta}Fθ的带噪观测值和预测值的加权和:
Dθ(xt+1τ,ytτ)=cskipτxt+1τ+coutτFθ(cinτxt+1τ,ytτ)(6)D_\theta (x^\tau_{t+1},y^\tau_t )=c^\tau_{skip}x^\tau_{t+1}+c^\tau_{out}F_\theta (c^\tau _{in} x^\tau_{t+1},y^\tau_t )\qquad(6)Dθ(xt+1τ,ytτ)=cskipτxt+1τ+coutτFθ(cinτxt+1τ,ytτ)(6)
为了简洁,定义ytτ:=(cnoiseτ,x≤to,a≤t)y^\tau_t :=(c^\tau_{noise} ,x^o_{\le t},a_{\le t})ytτ:=(cnoiseτ,x≤to,a≤t)以包括所有条件变量。
选择预调节器cinτc^\tau _{in}cinτ和coutτc^\tau _{out}coutτ使网络的输入和输出在任意噪声水平σ(τ)\sigma(\tau)σ(τ)下保持单位方差,cnoiseτc^\tau _{noise}cnoiseτ噪声是噪声水平的经验变换,cskipτc^\tau _{skip}cskipτ以σ(τ)\sigma(\tau)σ(τ)和数据分布σdata\sigma_{data}σdata的标准差表示。结合公式5和6,可以深入了解FθF_{\theta}Fθ的训练目标
L(θ)=E[∣∣Fθ(cinτxt+1τ,ytτ)−1coutτ(xt+1o−cskipτxt+1τ)∣∣2](7)L(\theta ) =\mathbb{E }[|| F_\theta (c^\tau_{in} x^{\tau }_{t+1},y^{\tau }_{t} ) -\frac{1}{c^\tau_{out}} (x^{o }_{t+1} - c^\tau_{skip}x^{\tau }_{t+1}) ||^2]\qquad(7)L(θ)=E[∣∣Fθ(cinτxt+1τ,ytτ)−coutτ1(xt+1o−cskipτxt+1τ)∣∣2](7)
网络训练目标根据退化程度σ(τ)\sigma(\tau)σ(τ)自适应混合信号和噪声。当σ(τ)≫σdata\sigma(\tau)\gg \sigma_{data}σ(τ)≫σdata,存在有σskipτ⟶0\sigma^\tau_{skip} \longrightarrow 0σskipτ⟶0,并且FthetaF_{theta}Ftheta的训练目标以干净信号xt+1ox^o_{t+1}xt+1o为主。相反,当噪声水平较低时,存在σskipτ⟶1\sigma^\tau_{skip} \longrightarrow 1σskipτ⟶1,其目标是成为干净信号和扰动信号之间的差值,即添加的高斯噪声,有利于防止训练目标在低噪声状态下消失。在实践中,这个目标是在噪声在极端情况下的高方差,因此Karras等人从经验中选择对数正态分布中的采样噪声水平σ(τ)\sigma(\tau)σ(τ),以便将训练集中在中等噪声区域周围。
同时,使用标准的U-Net 2D矢量场FθF_\thetaFθ,保留了L个过去的观察和行动的缓冲用来调节模型。将这些过去的观测结果连接到下一个有噪声的观测通道,并通过U-Net的残差块中的自适应组归一化层输入动作。
3.2 想象中的强化学习
考虑到3.1节的扩散模型,现在用奖励和终止模型来完成世界模型的最终搭建,这是在想象中训练RL代理所需的。由于估计奖励和终止是标量预测问题,使用由标准CNN组成的单独模型RψR_\psiRψ和LSTM层处理部分可观测性。RL代理涉及参与者-评论家网络,该网络由具有策略和值头的共享CNN-LSTM参数化。策略πϕ\pi_\phiπϕ使用基线强化训练,我们使用具有λ-返回的Bellman误差来训练值网络vϕv_\phivϕ。代理仅与真实环境交互以进行数据收集。在每个收集阶段之后,通过对迄今收集的所有数据进行训练来更新当前的世界模型。接着,在更新的世界模型环境中使用RL训练智能体,并重复以上步骤。
4. 实验
4.1 Atari 100k基准
为了对DIAMOND进行全面评估,使用既定的Atari 100k基准,该基准由26个游戏组成,测试了广泛的代理能力。对于每一款游戏,智能体只被允许在环境中采取10万次行动,这大约相当于人类2小时的游戏玩法,以便在评估之前学会玩游戏。与表1中完全在世界模型内训练智能体的其他近期方法进行了比较,包括STORM(2023)、dreamamerv3(2023)、IRIS(2023)、TWM(2023)和SimPle(2019)。
4.2 Atari 100K基准上的结果
表1提供了所有游戏的得分,以及人类归一化得分(HNS)的平均值和四分位数平均值(IQM)。遵循Agarwal等人的建议,关于点估计的局限性,在图2中为平均值和IQM提供了分层的自举置信区间。
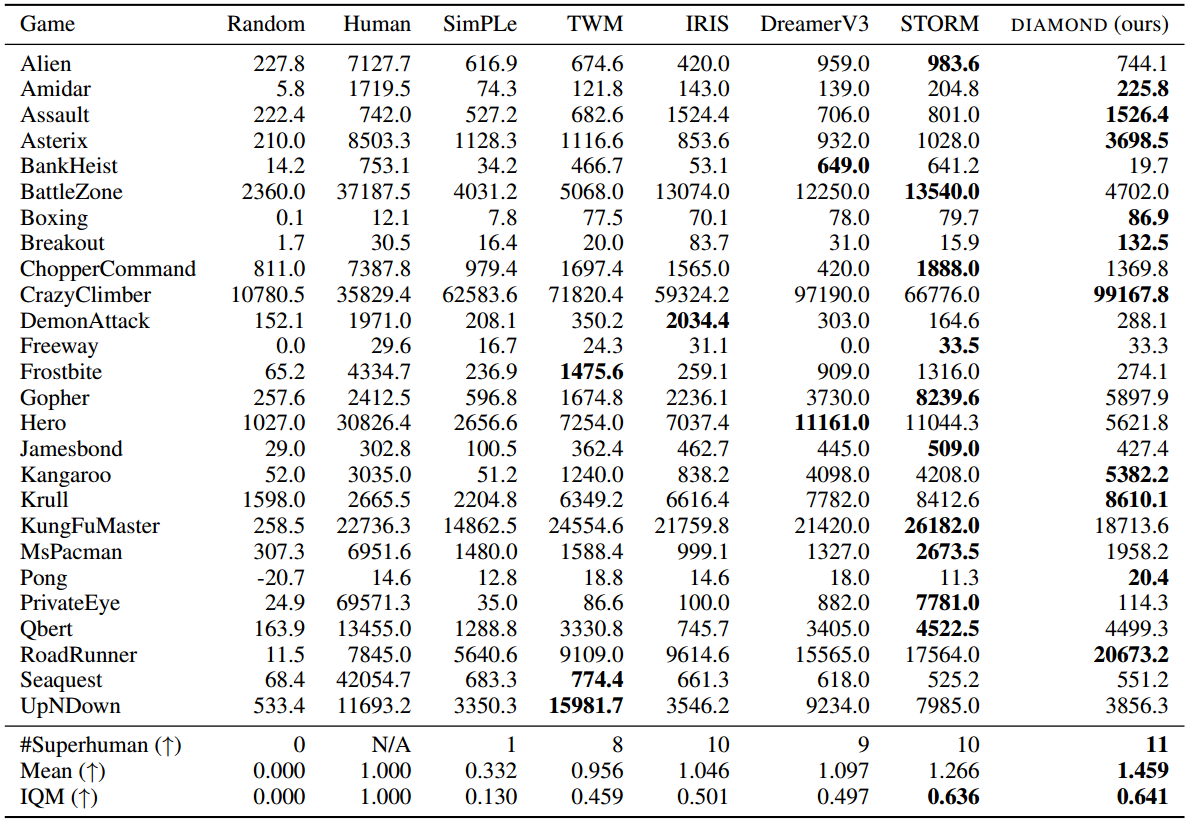
表1|2小时的实时体验和人类标准化的聚合指标,在Atari 100K基准测试的结果©️【深蓝AI】编译
结果表明,DIAMOND在基准测试中表现强劲,在11场比赛中超过了人类玩家,并实现了1.46的超人平均HNS,这是完全在世界模型中训练的智能体中的最佳成绩。DIAMOND也实现了与STORM相当的IQM,并且高于所有其他基线。同时发现DIAMOND在捕捉小细节很重要的环境中表现得特别好,比如《Asterix》、《Breakout》和《Road Runner》。同时在6.3节中对世界模型的视觉质量进行了进一步的定性分析。

图2|平均和四分位间平均人类标准化得分,用分层自举置信区间计算©️【深蓝AI】编译
5. 分析
5.1 扩散框架的选择
如第3节所述,原则上可以在世界模型中使用任何扩散模型变体。虽然DIAMOND如第4节所述使用EDM,但DDPM也是一个自然的候选者,已在许多图像生成应用中使用。为了提供DDPM与EDM实现的公平比较,研究者使用相同的网络架构在一个共享的静态数据集上训练两个变体,该数据集包含100k帧,并在游戏Breakout上使用专家策略收集。正如第3.3节所讨论的,去噪步骤的数量与世界模型的推理成本直接相关,因此更少的步骤将降低在想象轨迹上训练智能体的成本。为了使世界模型在计算上与其他世界模型基线相比较,最多需要几十个去噪步骤,最好更少;但如果去噪步骤数设置过低,视觉质量会下降,最终导致复合误差。
为了研究扩散变量的稳定性,图3显示了自回归生成的想象轨迹,直到t = 1000时间步长,对于不同的降噪步数n≤10。可以看到,在这种情况下使用DDPM(图3a)会导致严重的复合误差,导致世界模型迅速偏离分布。相比之下,基于电火花加工的扩散世界模型(图3b)在较长的时间范围内表现得更加稳定,即使对于单个去噪步骤也是如此。
这个结果是公式7中描述的改进训练目标的结果,与DDPM采用的更简单的噪声预测目标相比。虽然预测噪声对中间噪声水平效果很好,但这个目标导致模型学习恒等函数。当噪声占主导时(σnoise≫σdata⇒§θ(xt+1τ,ytτ)→xt+1τ)(\sigma _{noise}\gg \sigma _{data}\Rightarrow \S _\theta (x^ \tau_{t+1},y^\tau _t) \to x^ \tau_{t+1})(σnoise≫σdata⇒§θ(xt+1τ,ytτ)→xt+1τ),其中,§θ\S _\theta§θ为DDPM的噪声预测网络。这使得在采样过程开始时对分数函数的估计很差,从而降低了生成质量并导致复合误差。相比之下,3.1节中描述的EDM采用的自适应信号和噪声混合意味着,当噪声占主导地位时,训练模型来预测干净的图像(\sigma _{noise}\gg \sigma _{data}\Rightarrow F \theta (x^ \tau{t+1},y^\tau t) \to x^ o{t+1})$。这样可以在没有信号的情况下更好地估计分数函数,因此模型能够用更少的去噪步骤产生更高质量的代,如图3b所示。

图3|基于DDPM(左)和EDM(右)的扩散世界模型的想象轨迹©️【深蓝AI】编译
5.2 选择去噪步数
虽然基于EDM的世界模型只需要一个去噪步骤就可以十分稳定,如图3b第一行的Breakout所示,但这里讨论的这种选择在某些情况下如何限制模型的视觉质量。如3.2节所述,分数模型相当于用L2重构损失训练的去噪自动编码器。因此,最优的单步预测是对给定噪声输入的可能重建的期望,如果该后验分布是多模态的,则可能超出分布。虽然像《Breakout》这样的游戏具有确定性过渡,可以通过单个去噪步骤进行精确建模(见图3b),但在其他一些游戏中,部分可观察性会产生多模态观察分布。在这种情况下,需要一个迭代求解器来驱动采样过程走向特定模式,如图4中的游戏Boxing所示。因此,我们在所有实验中设置n=3。
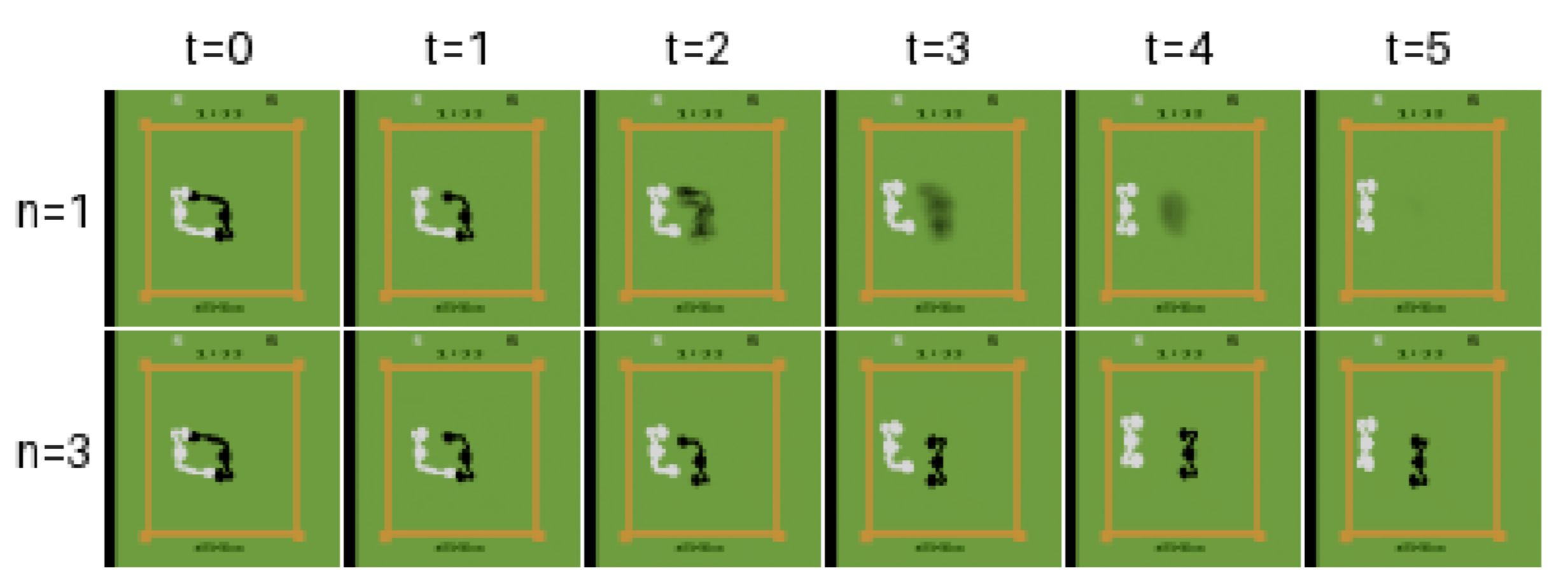
图4|装箱中的单步(第一行)和多步(第二行)采样©️【深蓝AI】编译
5.3 IRIS定性视觉比较
IRIS是一个成熟的世界模型,它使用离散自编码器将图像转换为离散令牌,并随着时间的推移使用自回归变压器将这些令牌组合起来。为了公平比较,研究者在用专家策略收集的10万帧的相同静态数据集上训练了两个世界模型,结果如图5所示。

图5|用IRIS(左)和DIAMOND(右)想象连续的画面©️【深蓝AI】编译
如图5所示,与IRIS想象的轨迹相比,DIAMOND想象的轨迹通常具有更高的视觉质量,并且更忠实于真实环境。特别是IRIS生成的轨迹包含帧之间的视觉不一致性(用白色方框突出显示),例如敌人被显示为奖励,反之亦然。这些不一致可能只代表生成图像中的几个像素,但可能对强化学习产生重大影响。例如,由于代理通常应该瞄准奖励并避开敌人,这些微小的视觉差异可能会使学习最佳策略更具挑战性。
这些视觉细节一致性的改进通常反映在这些游戏中更高的代理性能上,如表1所示。由于这些方法的代理组件很相似,因此这种改进可能是世界模型形成的。此外还可看出,这种改进不仅仅是计算量增加的结果。两个世界模型都以相同的分辨率(64 ×64)渲染帧,DIAMOND每帧只需要3 NFE,而IRIS每帧需要16 NFE。
6. 总结与展望
本文介绍了一个在扩散世界模型中训练的强化学习代理DIAMOND,并且解释了所做的关键设计选择,以适应世界建模的扩散,并使世界模型在很长一段时间内稳定,同时还减少了去噪步骤。DIAMOND在公认的Atari 100k基准上达到了1.46的人类标准化平均分,完全是世界模型中训练的代理中的新最佳。通过分析该模型在某些游戏中的表现,发现可能是由于对关键视觉细节进行了更好的建模。
当然,在未来研究工作上也存在三个主要限制或方向:
①本文的主要评估集中在离散控制环境上,将DIAMOND应用于连续领域可能会出现一些新见解。
②使用框架堆叠条件反射是提供过去观察记忆的最小机制。根据Peebles和Xie(2023)等方法,在环境时间内集成自回归变压器,将实现更长期的记忆和更好的可扩展性。
③将奖励/终止预测整合到扩散模型中,以供未来工作使用,因为结合这些目标并从扩散模型中提取表征并非易事,但这会使世界模型变得简单。
编译|William
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。

















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









