







 本文介绍了多模态图像生成技术在AI艺术创作中的应用,特别是Disco Diffusion工具。通过文本指导的扩散模型,AI能够生成多样化和高分辨率的图像,用于艺术创作。尽管存在质量问题、生成速度和参数调整的挑战,但通过数据和技术储备,可以优化生成效率和图像质量。展示了AI生成的城市地标、数字藏品、壁纸和艺术姓的实例,探讨了未来AI智能创作的可能性。
本文介绍了多模态图像生成技术在AI艺术创作中的应用,特别是Disco Diffusion工具。通过文本指导的扩散模型,AI能够生成多样化和高分辨率的图像,用于艺术创作。尽管存在质量问题、生成速度和参数调整的挑战,但通过数据和技术储备,可以优化生成效率和图像质量。展示了AI生成的城市地标、数字藏品、壁纸和艺术姓的实例,探讨了未来AI智能创作的可能性。
前言
什么是 AI?在你的脑海中可能浮现由一个个神经元堆叠起来的神经网络。那什么是绘画艺术?是达芬奇的《蒙娜丽莎的微笑》,是梵高的《星空夜》、《向日葵》,还是约翰内斯·维米尔的《戴珍珠耳环的少女》?当 AI 遇上绘画艺术,它们之间能擦出什么样的火花呢?
2021年初,OpenAI 团队发布了能够根据文本描述生成图像的 DALL-E 模型。由于其强大的跨模态图像生成能力,引起自然语言和视觉圈技术爱好者的强烈追捧。仅仅一年多的时间,多模态图像生成技术如雨后春笋般开始涌现,期间也诞生了许多利用这些技术进行 AI 艺术创作的应用,比如最近火得一塌糊涂的 Disco Diffusion。如今,这些应用正逐渐走进艺术创作者和普通大众的视野,成为了很多人口中的“神笔马良”。
本文从技术兴趣出发,对多模态图像生成技术与经典工作进行介绍,最后探索如何使用多模态图像生成进行神奇的 AI 绘画艺术创作。

笔者使用 Disco Diffusion 创作的 AI 绘画艺术作品
多模态图像生成概念
多模态图像生成(Multi-Modal Image Generation)旨在利用文本、音频等模态信息作为指导条件,生成具有自然纹理的逼真图像。不像传统的根据噪声生成图像的单模态生成技术,多模态图像生成一直以来就是一件很有挑战的任务,要解决的问题主要包括:
(1)如何跨越“语义鸿沟”,打破各模态之间固有的隔阂?
(2)如何生成合乎逻辑的,多样性的,且高分辨率的图像?
近两年,随着 Transformer 在自然语言处理(如 GPT)、计算机视觉(如 ViT)、多模态预训练(如 CLIP)等领域的成功应用,以及以 VAE、GAN 为代表的图像生成技术有逐渐被后起之秀——扩散模型(Diffusion Model)赶超之势,多模态图像生成的发展一发不可收拾。
多模态图像生成技术与经典工作
分类
按照训练方式采用的是 Transformer 自回归还是扩散模型的方式,近两年多模态图像生成重点工作分类如下:
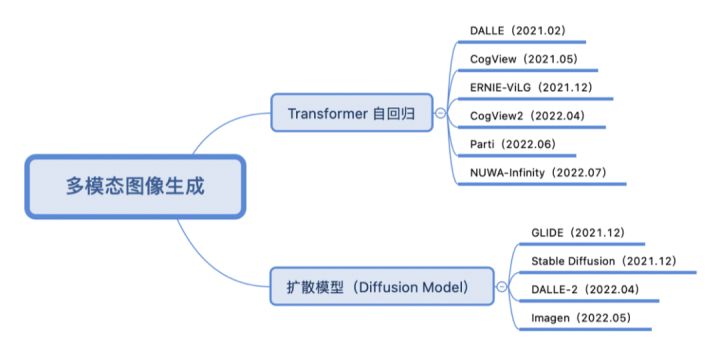
Transformer 自回归
采取 Transformer 自回归方式的做法往往将文本和图像分别转化成 tokens 序列,然后利用生成式的 Transformer 架构从文本序列(和可选图像序列)中预测图像序列,最后使用图像生成技术(VAE、GAN等)对图像序列进行解码,得到最终生成图像。以 DALL-E (OpenAI)[1] 为例:
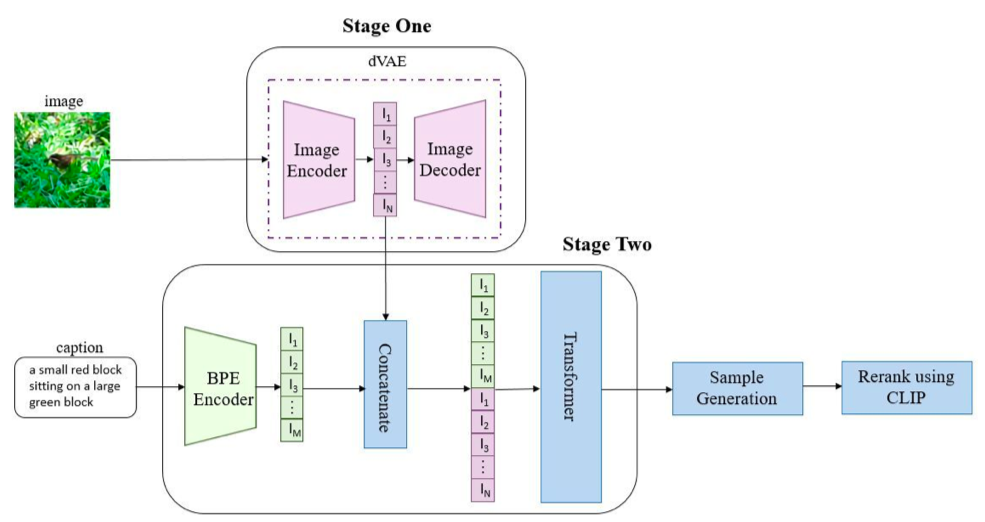
图像和文本通过各自编码器转化成序列,拼接到一起送入到 Transformer(这里用的是 GPT3)进行自回归序列生成。在推理阶段,使用预训练好的 CLIP 计算文本与生成图像的相似度,进行排序后得到最终生成图像的输出。与 DALL-E 类似,清华的 CogView 系列 [2, 3] 与百度的 ERNIE-ViLG [4] 同样使用 VQ-VAE + Transformer 的架构设计,谷歌的 Parti [5] 则将图像编解码器换成了 ViT-VQGAN。而微软的 NUWA-Infinity [6] 使用自回归方式可以做到无限视觉生成。
扩散模型
扩散模型(Diffusion Model)是一种图像生成技术,最近一年发展迅速,被喻为 GAN 的终结者。如图所示,扩散模型分为两阶段:(1)加噪:沿着扩散的马尔可夫链过程,逐渐向图像中添加随机噪声;(2)去噪:学习逆扩散过程恢复图像。常见变体有去噪扩散概率模型(DDPM)等。

采取扩散模型方式的多模态图像生成做法,主要是通过带条件引导的扩散模型学习文本特征到图像特征的映射
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









