




 该博客旨在根据用户app使用、流量、通话和短信记录判定是否为诈骗号码。先导入相关包,对train和test数据集进行预处理,包括特征衍生、缺失值处理、异常值检测和数据归一化。接着建模,通过交叉验证选优并调参,最后输出结果。
该博客旨在根据用户app使用、流量、通话和短信记录判定是否为诈骗号码。先导入相关包,对train和test数据集进行预处理,包括特征衍生、缺失值处理、异常值检测和数据归一化。接着建模,通过交叉验证选优并调参,最后输出结果。
- 研究目的 根据用户的app使用情况,用户的流量使用情况,用户通话记录,用户的短信记录,判定用户号码是否是诈骗号码。
- 数据集
- train:
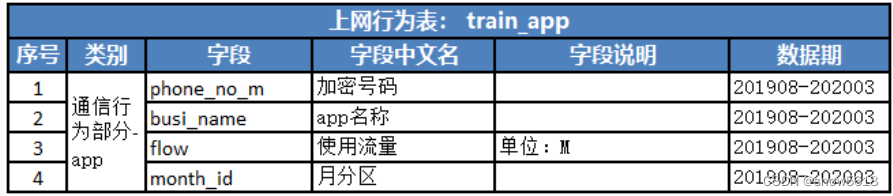
train_app.csv:app使用情况 .
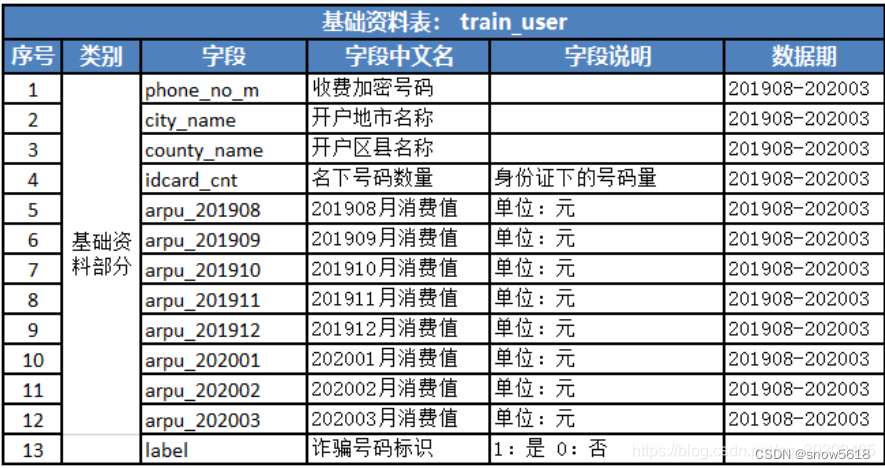
train_user.csv:基本信息 .
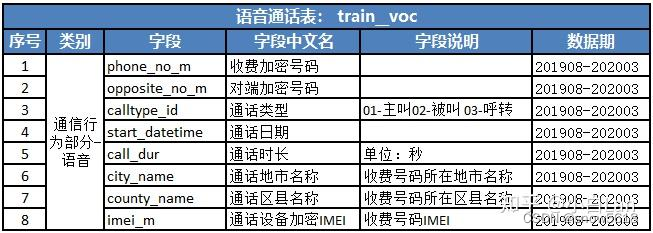
train_voc.csv:通话 .
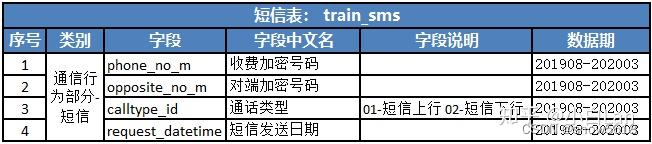
train_sms.csv:短信- test:
test_app.csv:app使用情况 .
test_user.csv:基本信息 .
test_voc.csv:通话
test_sms.csv:短信
2. 导入包
# 计算
import numpy as np
import pandas as pd
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
# 机器学习库
from sklearn.ensemble import RandomForestClassifier,ExtraTreesClassifier,AdaBoostClassifier,BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import StackingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.model_selection import train_test_split,cross_val_predict,StratifiedKFold
from sklearn import metrics
from scipy import stats
from scipy.cluster.hierarchy import dendrogram,linkage
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.family'] = ['SimHei']
train_user = pd.read_csv('train/train_user.csv')
train_app = pd.read_csv('train/train_app.csv')
train_voc = pd.read_csv('train/train_voc.csv')
train_sms = pd.read_csv('train/train_sms.csv')
train_user.shape,train_app.shape,train_voc.shape,train_sms.shape
3. 数据预处理
3.1 特征衍生
观察 数据发现 用户表中有6000多条数据,但是其他三个表中数据很大,为此我们对其他表数据进行预处理,特征工程。
- 1.1 train_app 表中包含 app,流量,月份的情况,我们可以转换成 .每个用户涉及的app个数 app_counts, .统计每个用户的流量使用情况,total_flow .统计每个用户活跃月份个数,months .统计每个用户活跃月流量使用情况
total_flow/months .统计每个用户平均app使用情况, app_flow- 1.2 voc通话数据处理:原有特征包括:对端通话号码,通话开始时间,通话时长,涉及城市,涉及乡镇,涉及设备编码
- 统计每个用户涉及的对端通话号码个数 nunique
- 统计每个用户每个对端平均通话时长 avg_user_call, sum
- 统计每个月平均通话时长 avg_month_call, total_call/month_count
- 涉及设备个数 imei_count,nunique
- 涉及城市个数 city_count,nunique
- 涉及乡镇个数 county_count,nunique
- 活跃月份个数 month_count,nunique
- 通话总时长 total_call sum
- count是统计所有次数,nunique统计唯一出现次数(每个类别只统计一次)
- 1.3 短信处理方式也类似。
1. app数据处理
train_app['month_id'] = pd.to_datetime(train_app['month_id'],format='%Y-%m-%d')
train_app['month'] = train_app['month_id'].dt.month
app_count = train_app.groupby(['phone_no_m'])['busi_name'].agg(app_count='nunique')
total_flow = train_app.groupby(['phone_no_m'])['flow'].agg(total_flow='sum')
total_month = train_app.groupby(['phone_no_m'])['month'].agg(total_month='nunique')
# 与用户表聚合
new_train_user = pd.merge(train_user,app_count,on='phone_no_m',how='left')
new_train_user = pd.merge(new_train_user,total_flow,on='phone_no_m',how='left')
new_train_user = pd.merge(new_train_user,total_month,on='phone_no_m',how='left')
new_train_user['avg_flow'] = new_train_user['total_flow']/new_train_user['total_month']
new_train_user['app_flow'] = new_train_user['total_flow']/new_train_user['app_count']
new_train_user.head()
# 2. voc通话记录
train_voc['start_datetime'] = pd.to_datetime(train_voc['start_datetime'],format='%Y-%m-%d %H:%M:%S')
train_voc['month'] = train_voc.start_datetime.dt.month
# 只考虑主叫
train_voc_1 = train_voc[train_voc['calltype_id']==1]
total_call = train_voc_1.groupby(['phone_no_m'])['call_dur'].agg(total_call='sum')
month_count = train_voc_1.groupby(['phone_no_m'])['month'].agg(month_count='nunique')
user_count = train_voc_1.groupby(['phone_no_m'])['opposite_no_m'].agg(user_count='nunique')
city_count = train_voc_1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









