







知识蒸馏
本文主要是根据该网站视频(https://www.bilibili.com/video/BV1s7411h7K2?t=906)进行总结,如有理解误差,望批评指点
1. 首次提出
首次提出:https://arxiv.org/pdf/1503.02531.pdf
作者的动机是想找到一个方法,把多个模型的知识提炼给单个模型。
虽然现在很多分类模型都采用交叉熵衡量预测值与真实值,然而真实值采用的one-hot向量所能提共的信息没有概率分布多。
原理:概率分布比onehot更能提供信息-暗知识。
loss=0.7KL散度(softmax_t(老师输出))+0.3交叉熵(oneHot)
两个分布的loss可以用KL散度。
2. 简单介绍
知识蒸馏,可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。知识蒸馏,可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。
例如:水果蔬菜分类

3.pytorch中的一些损失函数

log_softmax_p = torch.log(torch.softmax(p))
loss1= F.nll_loss(log_softmax_p ,target)
loss2 = F.cross_entropy(p,target))
loss1 == loss2

4. 核心
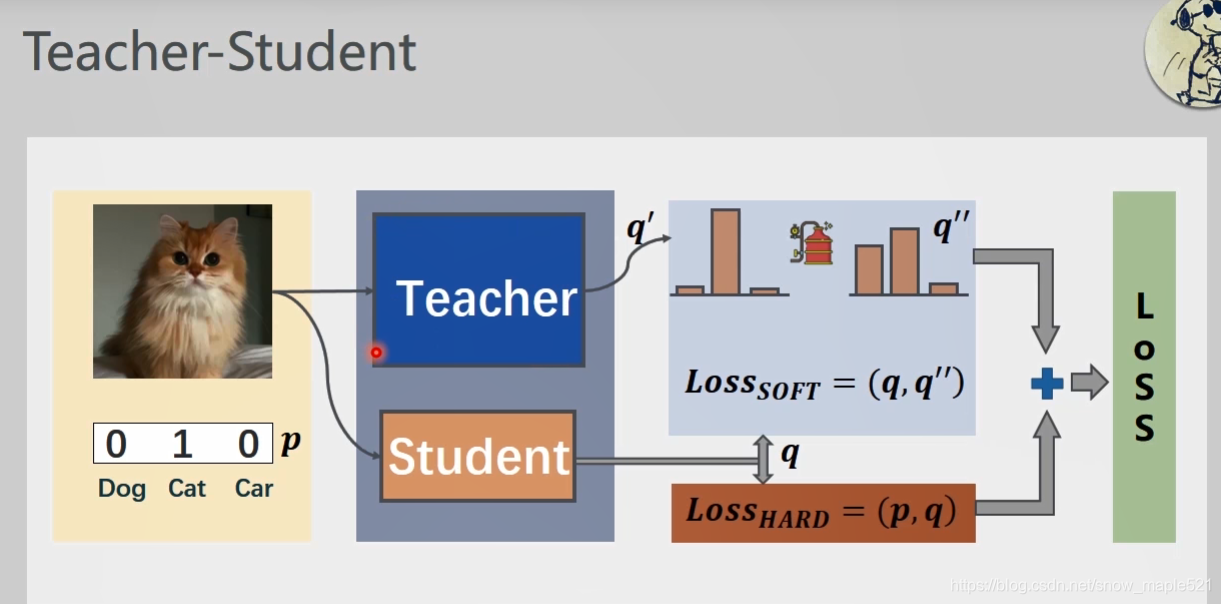
当没有老师网络时候,仅仅将图像经过student网络,softmax之后,输出概率分布值q,将q与真实值求loss就是称为Hard loss,因为这个p是真实值的one-hot向量,我们希望q和p越接近越好。
当有老师的帮助下的时候,loss来自student和teacher 网络。且,老师输出的q‘要经过蒸馏之后(让它更加平滑)得到q’‘再与q求loss,总loss,是它们之间的和。
5. 理论分析

通过引入软目标:soft-target作为total loss的一部分,诱导学生网络以精简,低复杂度的训练,实现知识迁移。
其中total loss的设计采用的是 交叉熵损失和kl散度(软目标,学生预测),如上图,如果软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献。这对训练初期是很有必要的。但是训练后期需要减少软目标的比重。
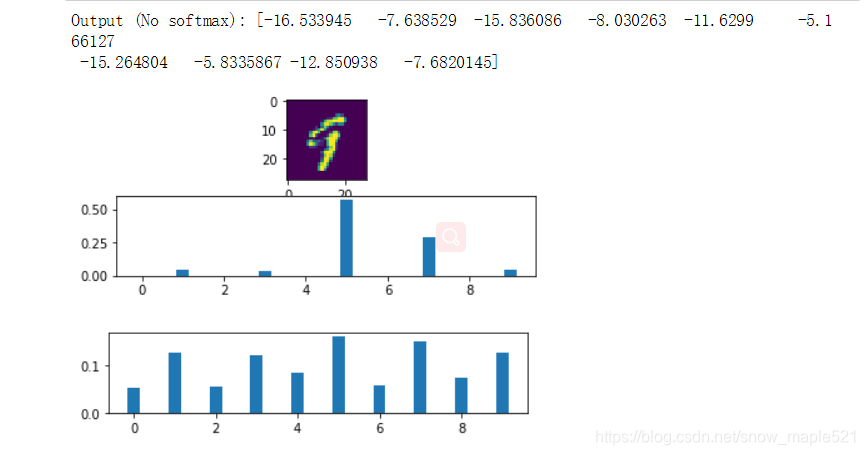
图中没加平滑时的数字识别是9,对应的概率中9的概率很小,加了平滑之后,9的比重相对而言大了。
6. 实例:知识蒸馏实现手写体识别
6.1 Teacher model
简单的卷积网络
class TeacherNet(nn.Module):
def __init__(self):
super(TeacherNet,self).__init__()
self.conv1 = nn.Conv2d(1,32,3,1)
self.conv2 = nn.Conv2d(32,64,3,1)
self.dropout1 = nn.Dropout2d(0.3)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216,128)
self.fc2 = nn.Linear(128,10)
#此处没有softmax
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x,2)
x = self.dropout1(x)
x = torch.flatten(x,1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
output = self.fc2(x)
return output
6.2 Student model
更简单的线形模型
class StudentNet(nn.Module):
def __init__(self):
super(StudentNet,self).__init__()
self.fc1 = nn.Linear(28*28,128)
self.fc2 = nn.Linear(128,64)
self.fc3 = nn.Linear(64,10)
def forward(self,x):
x = torch.flatten(x,1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
output = F.relu(self.fc3(x))
return output
6.3 Teacher 教 Student
KD的Loss
def distillation(y,labels,teacher_scores,temp,alpha):
return nn.KLDivLoss()(F.log_softmax(y/temp, dim=1),
F.softmax(teacher_scores/temp,dim=1))*(temp*temp*2.0*alpha)+F.cross_entropy(y,labels)*(1. - alpha)
老师教学生,前提是教师网络已经是训练好的,然后去教学生。
def train_student_kd(model,device,train_loader,optimizer,epoch):
model.train()
teacher_model.eval()
trained_samples = 0
for batch_idx,(data,target) in enumerate(train_loader):
data,target = data.to(device),target.to(device)
optimizer.zero_grad()
output = model(data)
teacher_output = teacher_model(data)
teacher_output = teacher_output.detach()
loss = distillation(output,target,teacher_output,temp=5.0,alpha=0.7)
loss.backward()
optimizer.step()
trained_samples += len(data)
progress = math.ceil(batch_idx / len(train_loader)*50)
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# print("\r Train epoch %d:%d/%d"%(epoch,trained_samples,len(train_loader.dataset)))
def test_student_kd(model,device,test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data,target in test_loader:
data,target = data.to(device),target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.argmax(dim=1,keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("\r Test average loss:{:.4f},accuracy:{}/{}({:.0f}%)".format(test_loss,correct,len(test_loader.dataset),100.*correct/len(test_loader.dataset)))
return test_loss, correct/len(test_loader.dataset)
def student_kd_main():
epochs = 10
batch_size = 64
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data/MNIST',train=True,download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data/MNIST',train=False,download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
model = StudentNet().to(device)
teacher_model = TeacherNet()
teacher_model.load_state_dict(torch.load('teacher.pth')) #加载老师网络参数
optimizer = torch.optim.Adadelta(model.parameters())
student_history = []
for epoch in range(1,epochs+1):
train_student_kd(model,device,train_loader,optimizer,epoch)
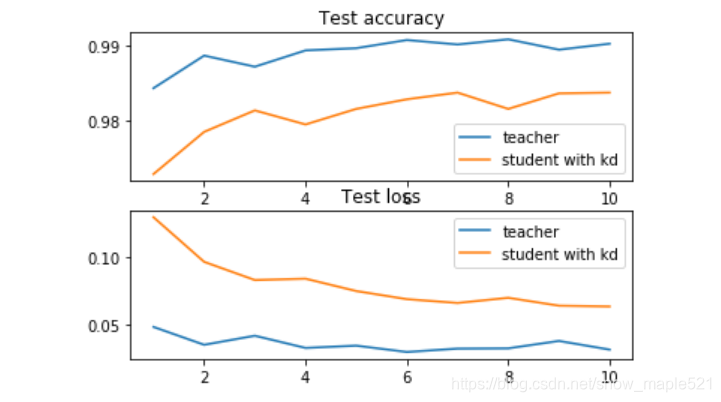
loss , acc = test_student_kd(model,device,test_loader)
student_history.append((loss,acc))
torch.save(model.state_dict(),'student.pth')
return model,student_history


















 662
662





 到【灌水乐园】发言
到【灌水乐园】发言







