




 本文围绕深层神经网络展开,介绍了其概述,包括层数计算;阐述前向传播和反向传播公式,强调核对矩阵维数的重要性;以人脸图像和语音识别为例说明深层表示的作用;还提及搭建神经网络块、参数与超参数,最后指出深度学习和大脑关联性是噱头。
本文围绕深层神经网络展开,介绍了其概述,包括层数计算;阐述前向传播和反向传播公式,强调核对矩阵维数的重要性;以人脸图像和语音识别为例说明深层表示的作用;还提及搭建神经网络块、参数与超参数,最后指出深度学习和大脑关联性是噱头。
目录
参数 VS 超参数(Parameters vs Hyperparameters)
深层神经网络
深层神经网络概述
计算算神经网络的层数时,不算输入层,我们只算隐藏层和输出层。
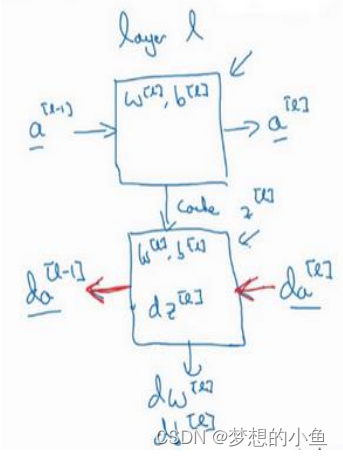
前向传播和反向传播


前向传播可以归纳为多次迭代zl=wlal-1+bl, al=g[l]z[l]![]()
核对矩阵的维数
在做深度神经网络的反向传播时,一定要确认所有的矩阵维数是前后一致的。
为什么使用深层表示?
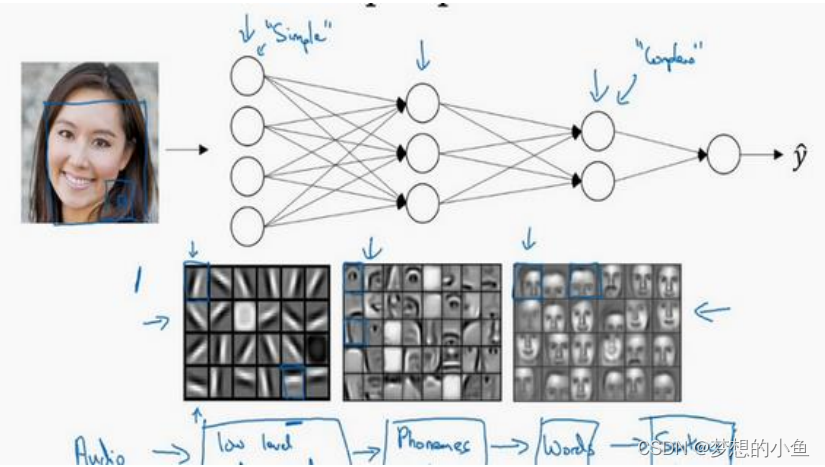
以人脸图像识别为例子,多层神经网络结构可以看成检测器,前面的浅层神经元相当于提取多个特征,这时是希望能将人脸的特征分得越多越好,后面的层级是将前面提取的小特征进行组合,去监测一些人可以去理解的特征部分—比如人的眼睛、鼻子等等。
这种从简单到复杂的金字塔状表示方法或者组成方法,也可以应用在图像或者人脸识别以外的其他数据上。比如当你想要建一个语音识别系统的时候,需要解决的就是如何可视化语音,比如你输入一个音频片段,那么神经网络的第一层可能就会去先开始试着探测比较低层次的音频波形的一些特征,比如音调是变高了还是低了,分辨白噪音,咝咝咝的声音,或者音调,可以选择这些相对程度比较低的波形特征,然后把这些波形组合在一起就能去探测声音的基本单元。
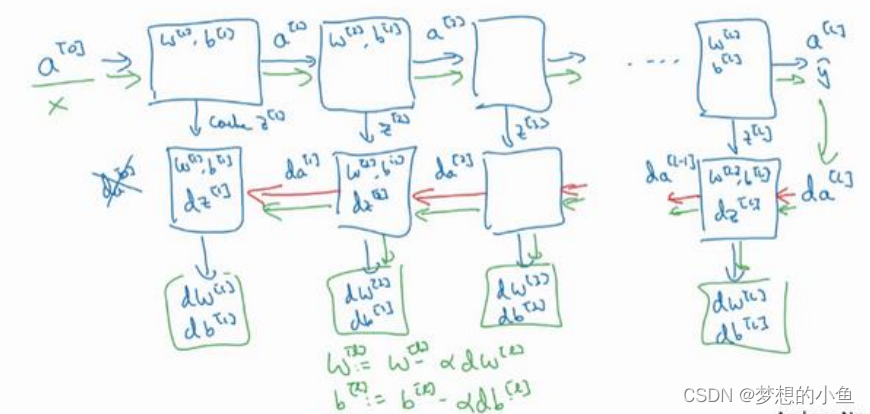
搭建神经网络块
参数 VS 超参数(Parameters vs Hyperparameters)
超参数:算法中的 learning rate 𝑎(学习率)、iterations(梯度下降法循环的数量)、𝐿(隐藏层数目)、𝑛[𝑙](隐藏层单元数目)、choice of activation function(激活函数的选择)
超参数的设置:调参、炼丹,各算法工程师的独家秘笈
深度学习和大脑的关联性
噱头,图一乐



















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











