






 本文探讨了从RankNet到LambdaRank再到LambdaMART的机器学习排序算法演进过程,详细解析了算法原理,包括损失函数、推力概念及特征选择,并对比了不同算法在计算效率和排序精度上的差异。
本文探讨了从RankNet到LambdaRank再到LambdaMART的机器学习排序算法演进过程,详细解析了算法原理,包括损失函数、推力概念及特征选择,并对比了不同算法在计算效率和排序精度上的差异。
RankNet与LambdaRank
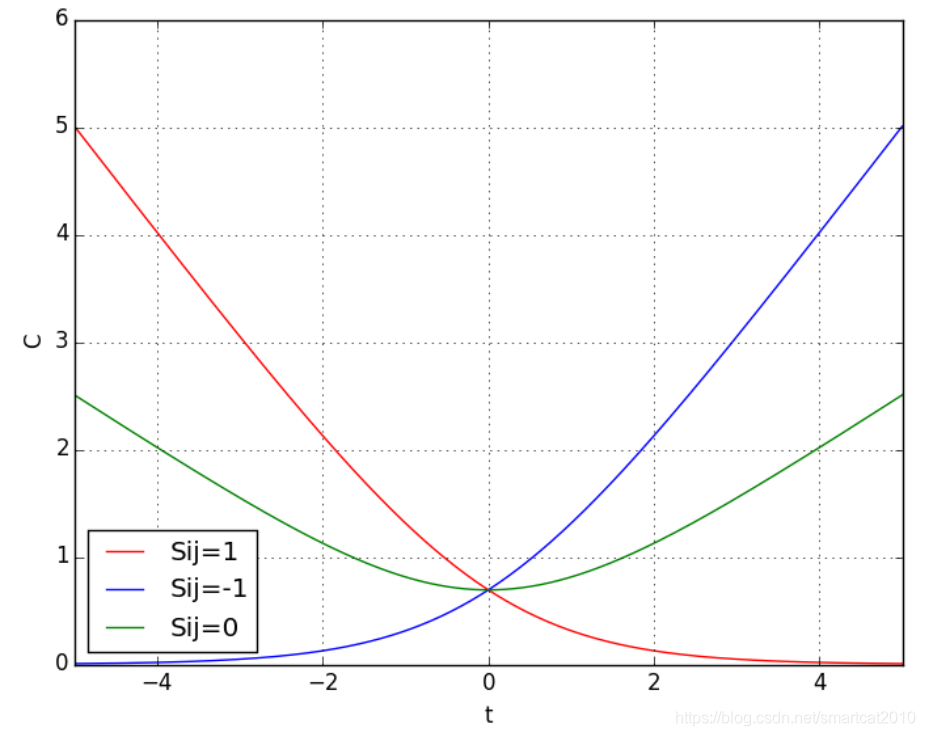
Sij=1表示i应该排在j前面(i和Query得相关性,比j和Query得相关性更大)
横轴t是;纵轴C是损失函数;
样本是2个Query-Doc Pair;Label是二值0/1, 表示是否比
更相关;
机器学习排序算法:RankNet to LambdaRank to LambdaMART
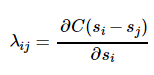
所以对于而言,
总是小于0的,
越小,C越大,梯度越负得厉害,对
的向大里推得动力越大;
RankNet中的可以看成是Ui和Uj中间的作用力,如果Ui⊳Uj,则Uj会给予Ui向上的大小为|
|的推动力,而对应地Ui会给予Uj向下的大小为|
|的推动力。
2.2里面的例子,很好,但是计算出的好像是错的,应该是正数,给向下的推力
LambdaRank就是在RankNet的基础上,增加了|ΔNDCG|做系数,使推力和位置有关(着重靠前位置的准确性)(交换后排序的NDCG与交换前排序的NDCG的差值)
LambdaRank使用了NDCG,所以从Pair-wise变成了List-wise
求解LambdaMART的疑惑?
RankNet使用每2个Doc来更新一次梯度,总共更新O(N^2)次;
LambdaRank把式子继续推导下去,每轮先计算好N个Doc两两之间的, 然后对每个Doc更新一次梯度,总共更新O(N)次;
From RankNet to LambdaRank to LambdaMART: An Overview
LambdaRank损失函数:
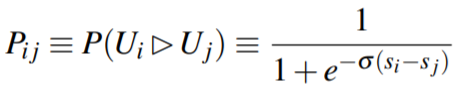
![]()
LambdaRank是一个Query的DOC列表,进行一次网络参数更新;LambdaMART是对所有Query的所有列表,同时建弱分类器MART树;
LambdaMART:一个Query-Doc叫,Query-Doc的相关性叫
, GBDT弱分类器树在
上的评价值的加和,就是F(
) (也就是
);
和同一列表的不如它相关性大的Query-Doc
的损失函数是C,同一列表里所有
的C的加和就是
的总损失函数C(
); C(
)对
求导结果就是
;然后C(
)对
求二阶导;最后套用牛顿迭代的公式,用分在该结点上的所有
们的一阶导和二阶导,得到该节点上的最优预测值r; 这个求得的最优预测值r,可以使得这些
们的F(
)+r也就是新预测值
们的损失函数值C们之和最小;
预测阶段,来了一个Query,所有候选们都输入到GBDT里面去求得预测结果值(也就是相关性值)F(
)们,从大到小排序,选前N个,输出;
LambdaMART拟合每个Query-Doc的相关性,目标是让他和同一列表里其他Doc形成的损失函数总值C[i]最小,具体到一个叶子节点,就是让落到该叶子节点的样本们的C[i]之和最小;每一棵树训练完,都要重新计算所有样本的
和相关的一阶导和二阶导(计算这些数据需要ListWise来做,这点和PointWise的GBDT不同),用这些数据去训练下一棵树;
LambdaMART所用的特征
使用LTR时会选取一系列文本特征,利用机器学习方法很好的融合到一个排序模型中,来决定最终结果的顺序,其中每一个特征我们称为一个“feature”。对于一个网页文本,feature所在的文档区域可以包括body域,anchor域,title域,url域,whole document域等。
文档的feature又可以分为两种类型:一是文档本身的特征,比如Pagerank值、内容丰富度、spam值、number of slash、url length、inlink number、outlink number、siterank等。二是Query-Doc的特征:文档对应查询的相关度、每个域的tf、idf值,bool model,vsm,bm25,language model相关度等。
综合上述的文档feature的两种类型和位于文档的不同域,我们可以组合出很多feature,当然有些feature是正相关有些是负相关,这需要我们通过学习过程去选取优化。
影响网页排序的因素:
查询词与文档的相关性
链接分析得到网页本身的权重,这个一般跟查询词无关
用户点击得到的权重
竞价推广。

















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









