






多模态上做了很多新功能
量化新增功能:

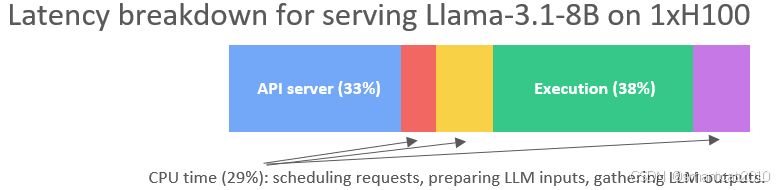
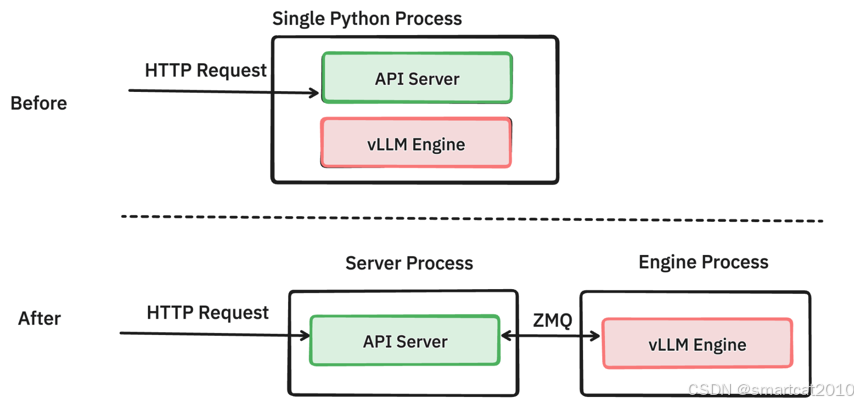
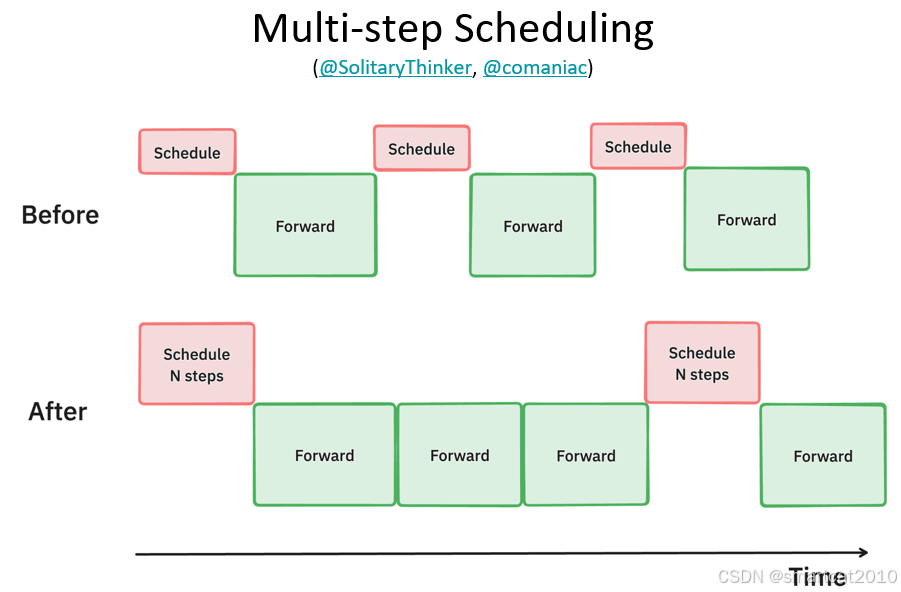
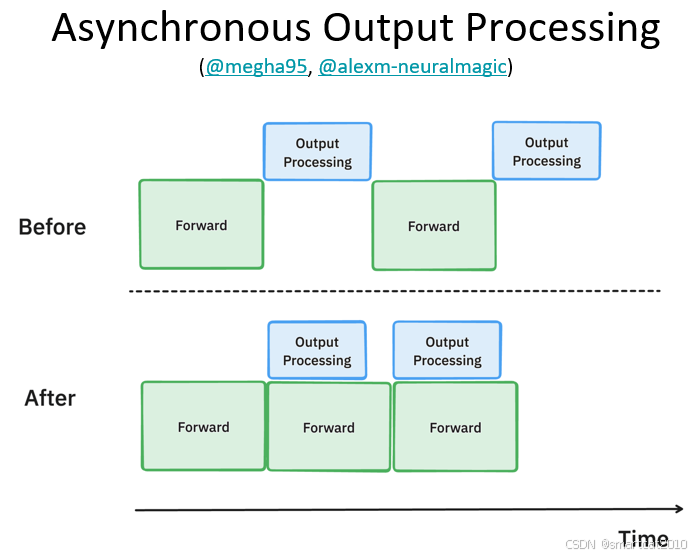
拆进程、CPU和GPU异步并行、调度等工程优化:
痛点:

TPU使用torch.compile来编译为静态图,加速执行:

为PD分离准备的KV cache缓存+读取

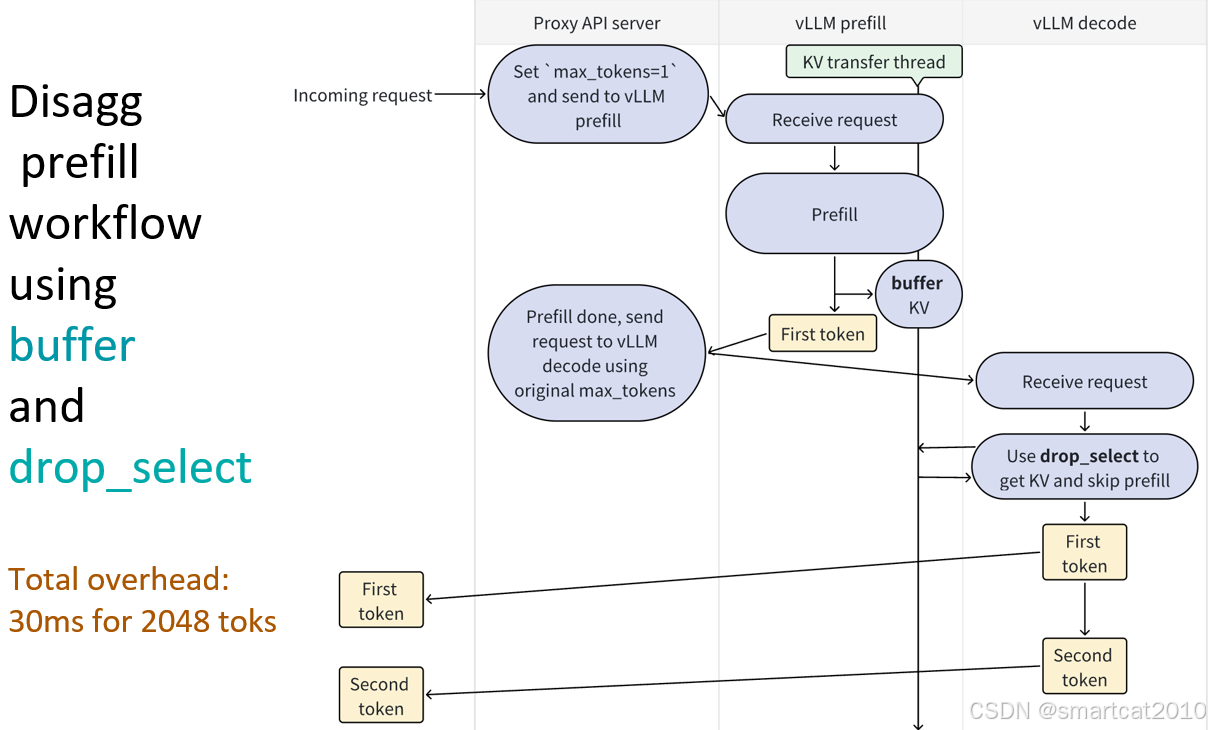
优化:
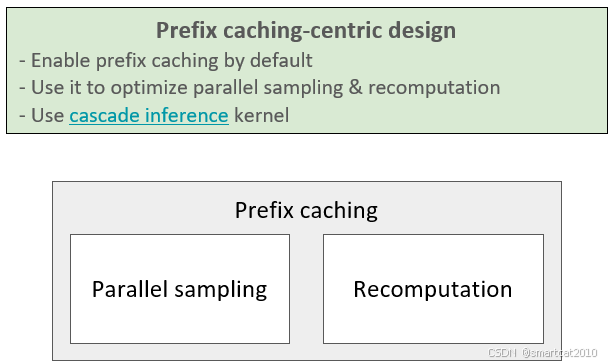
cascade inference: 优化self-attention部分的计算。针对batch里共享前缀的情况,可以使共享前缀树上的所有分支只计算一次,每个prompt途径的所有分支加叶子后缀,最后将计算结果进行归一化加和,类似FlashAttention用的原理,把每个分支的s结果和加和v结果,最后scaling并归一化加和。


















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









