






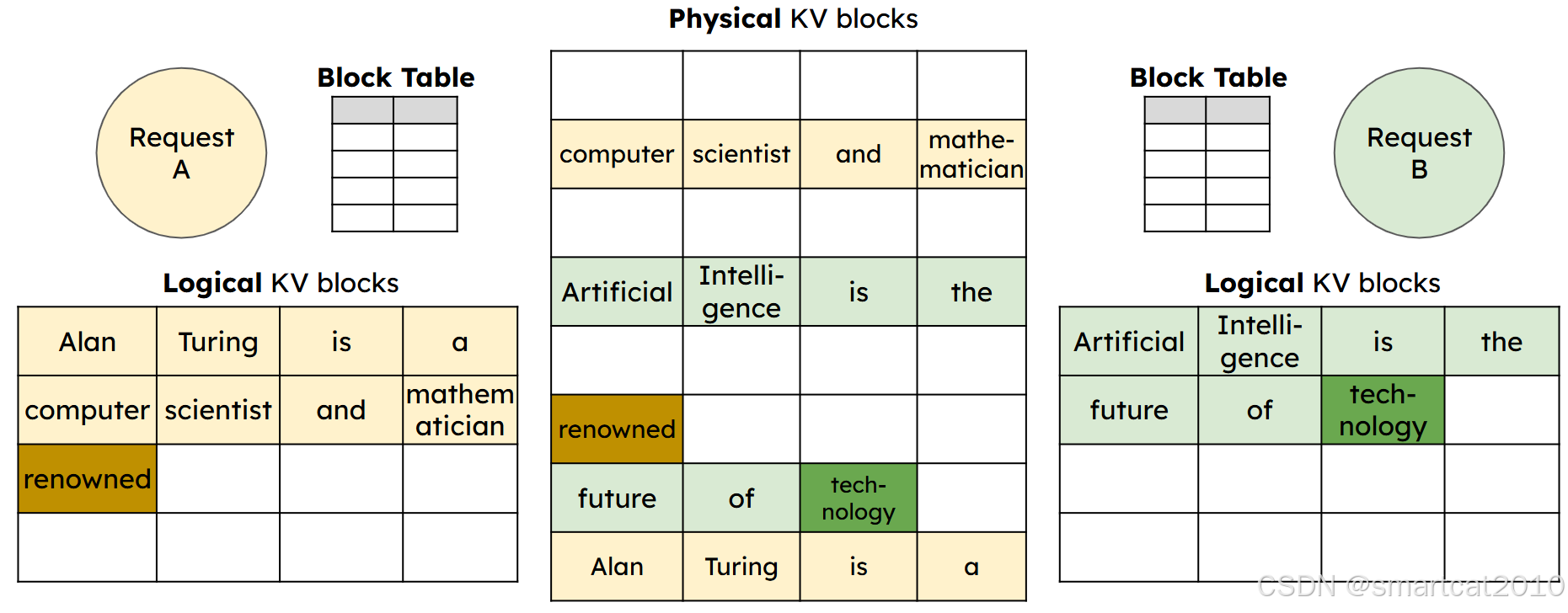
PagedAttention: 类似OS的虚存分页那样,管理KV Cache显存。
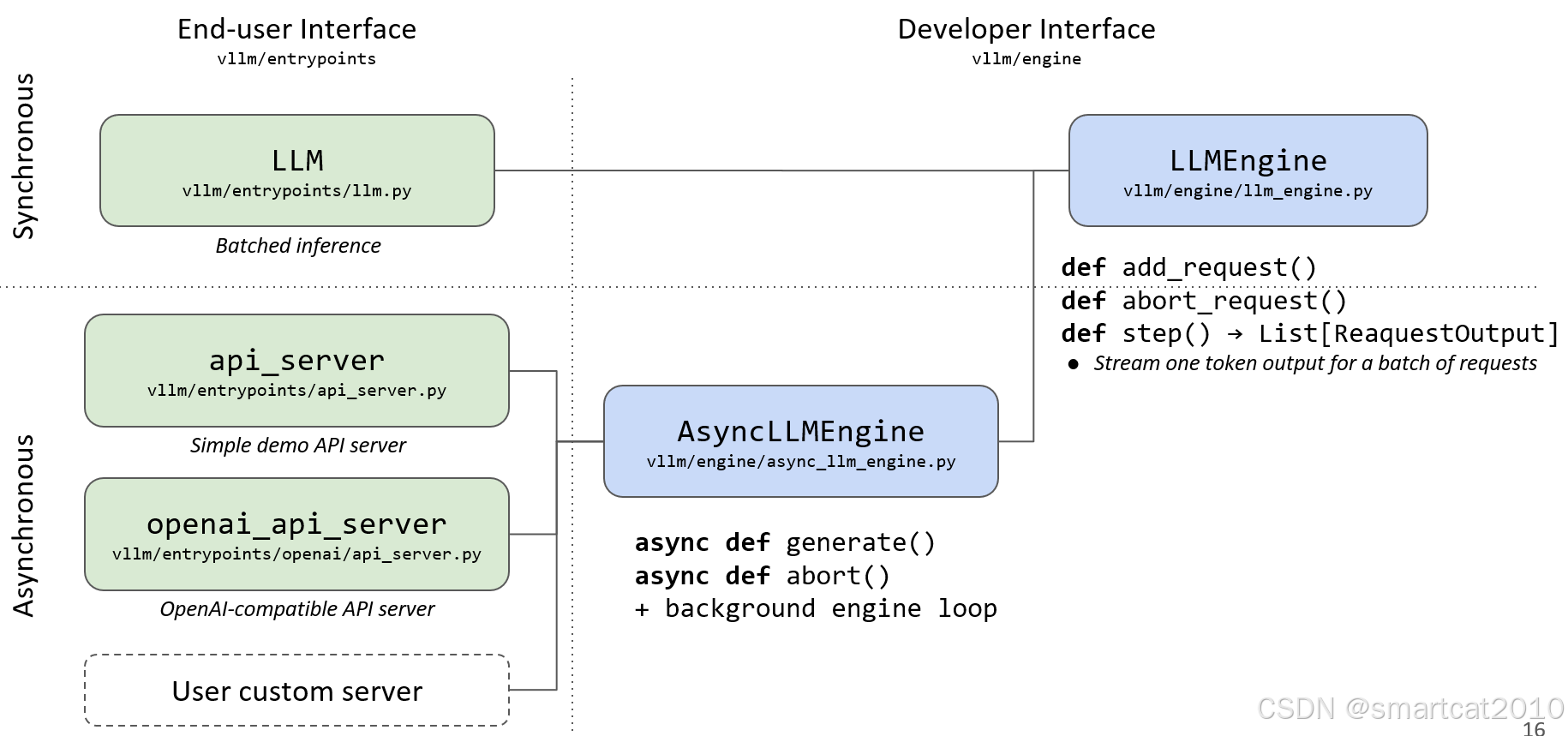
接口1:
LLM类,离线batch推理:

接口2:
FastAPI服务,openAI格式兼容的,适合线上产品环境:

介绍了初版VLLM的整体架构。
用户接口:
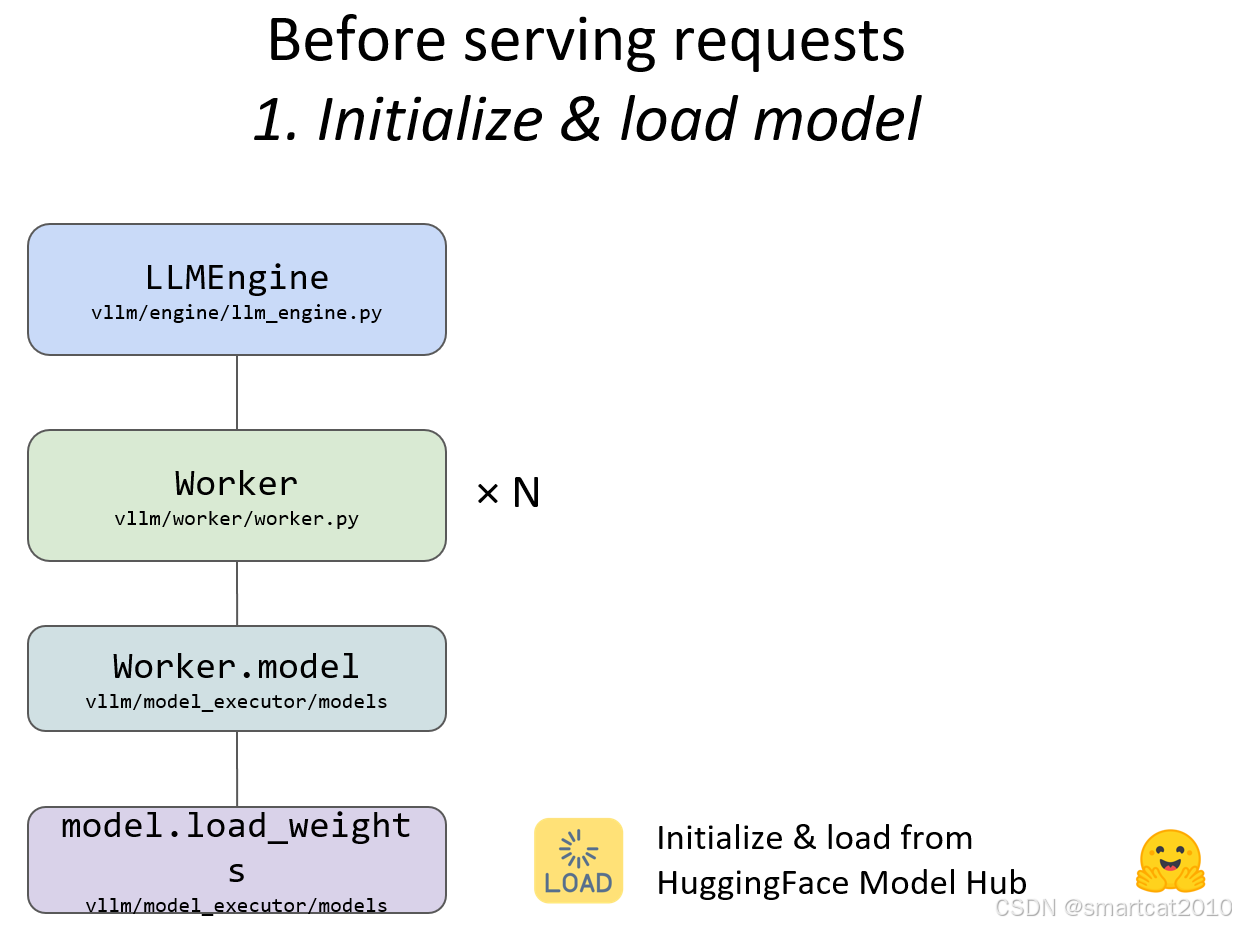
先加载模型:
这里我不明白为什么要profile,直接估算不可以吗?

PagedAttention: 类似OS的虚存分页那样,管理KV Cache显存。
接口1:
LLM类,离线batch推理:
接口2:
FastAPI服务,openAI格式兼容的,适合线上产品环境:
介绍了初版VLLM的整体架构。
用户接口:
先加载模型:
这里我不明白为什么要profile,直接估算不可以吗?

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























