










1. 如果开了accumulate gradient更新,则pipeline并行的bubble会变小很多。因为每foward好多个batch,才开始backward。
2. chat聊天任务上,可以把prefix KV cache reuse功能利用起来;然后把同一个session的对话,路由到同一张卡上。
但是实际上,用户的回复,往往比较慢。在等待用户回复期间,其他session的请求到达了很多,容易冲刷掉该session的KV cache,从而无法复用。
3. 如果不开CPU offload,Zero1、2、3,Optimizer状态、Gradient、Weight,都在显存上的。
4. 通信量:原始DP = Zero1 = Zero2 = 2S, Zero3=3S

原始DP,是1次对梯度的AllReduce,等价于1次Scatter-Reduce加1次All-Gather,所以是2S;
Zero1,是在所有层的梯度都计算完之后,进行1次梯度的Scatter-Reduce,更新完权重后,再对FP16的权重进行1次All-Gatther,所以是2S;
Zero2, 通信行为同上,不同之处,是在每个bucket的梯度计算完之后立即进行该bucket的Scatter-Reduce,因此通信量不变,仍是2S;但每张卡只保存自己负责的这部分梯度,其他梯度都是Scatter-Reduce完之后立即释放显存空间,因此梯度显存占用量除以N;
5. Zero1、2、3,都是按照layer进行Partition的。如下图:
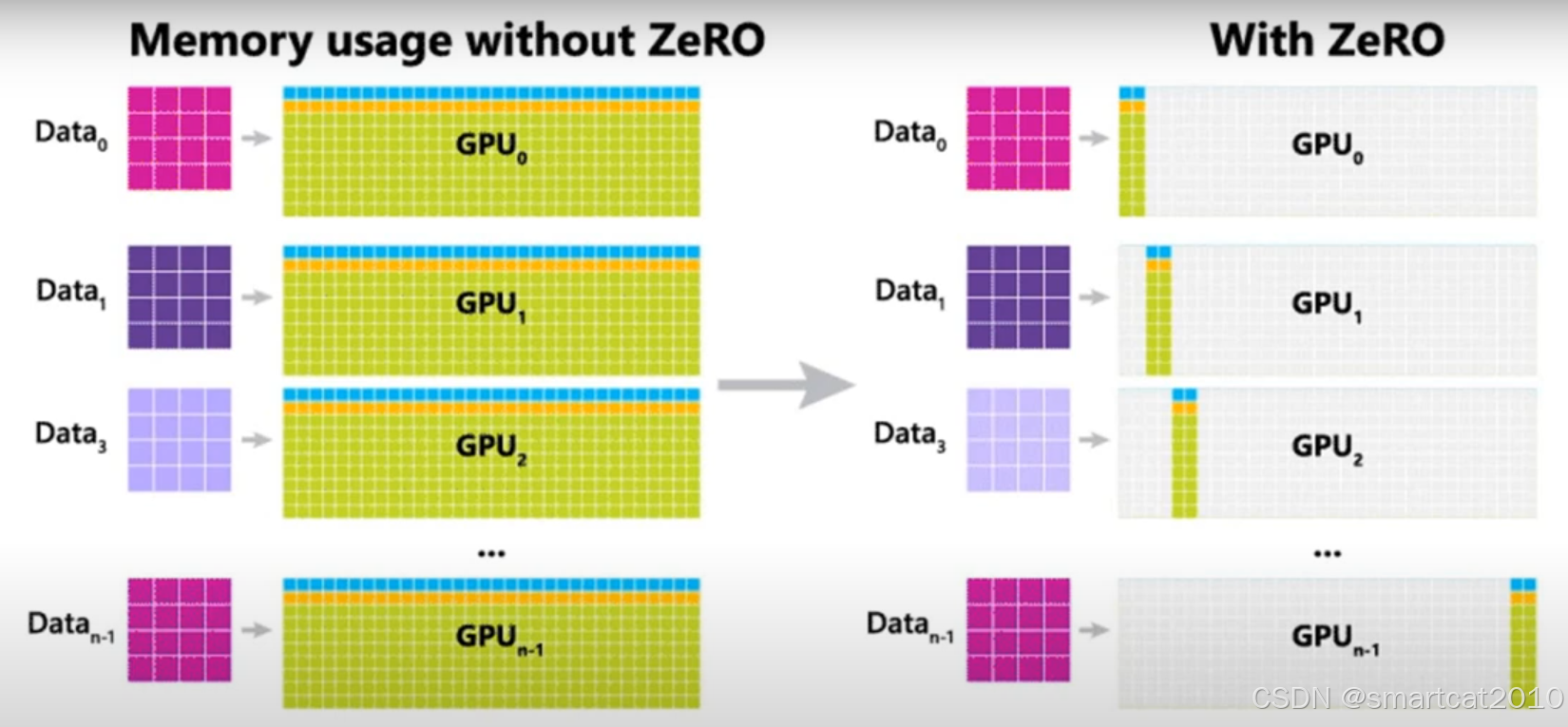
每个GPU上的几列,就代表几个完整的layer。

















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









