 Megatron论文精读
Megatron论文精读





总体目标:增大吞吐(减少气泡),减少显存(中间缓存的activation尽可能少),保持和原始计算的结果等价;
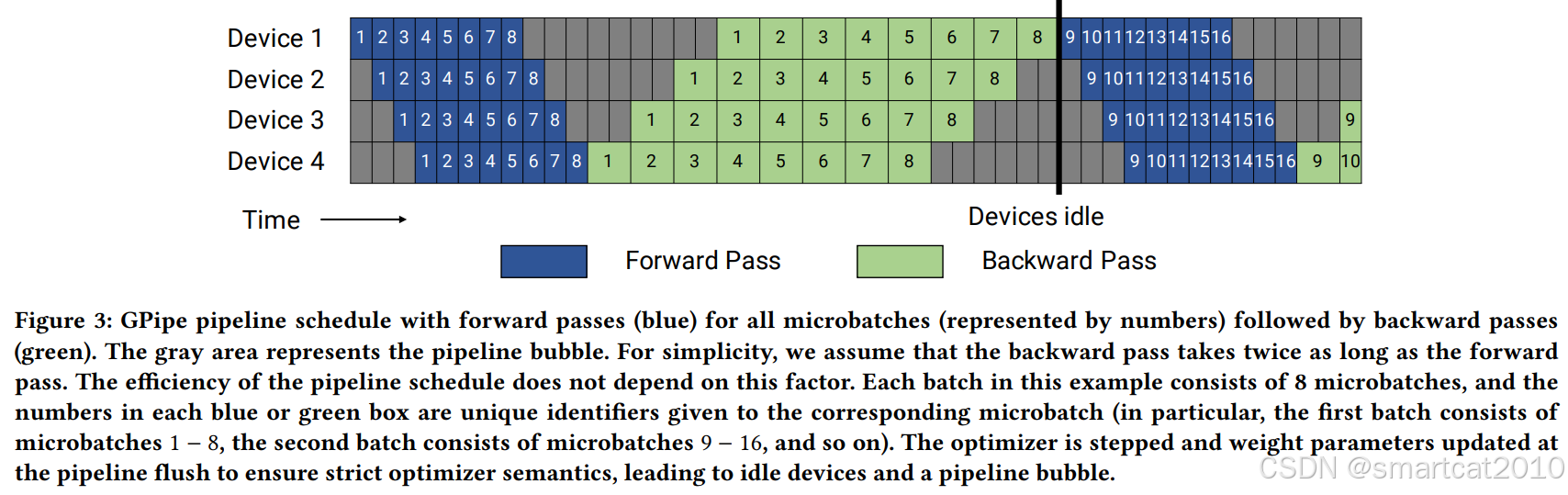
GPipe:
画出了backward时长大约是forward的2倍;
最后才更新weight,是为了保持和原始计算的等价,weight不能变;
缺点:forward激活保留的太多,占显存;或者activation checkpointing导致的重新计算太多,浪费GPU算力。
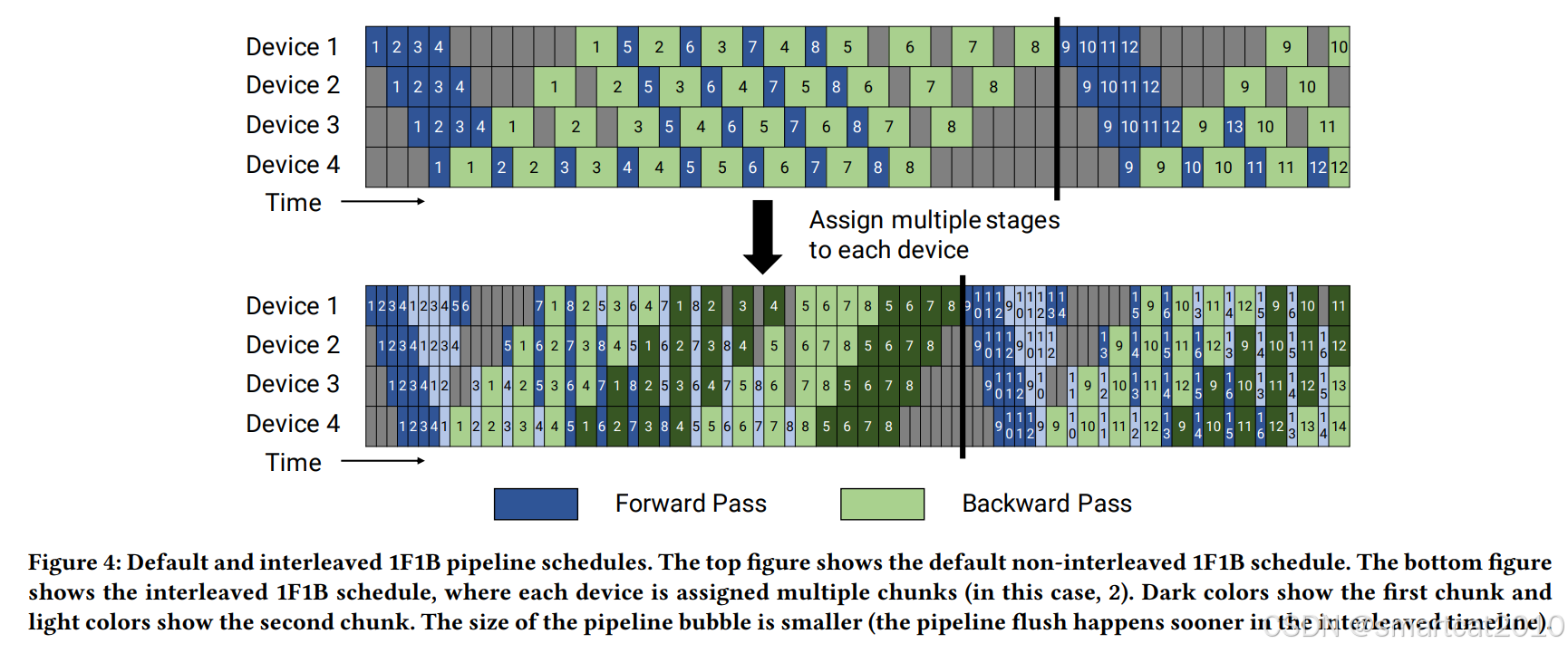
1F1B(PipeDream):
最多缓存一部分micro-batch的激活,优先处理backward,目的是释放activation的显存
整体时长,和GPipe一样,但降低了activation缓存所需的显存量;
Interleaved 1F1B:
1F1B等,是每个GPU负责连续的几个layers,例如:GPU1:[1,2,3,4], GPU2:[5,6,7,8], GPU3:[9,10,11,12], GPU4:[13,14,15,16]...
本方法,每个GPU负责多个小段的连续layers,例如: GPU1: [1,2,9,10], GPU2:[3,4,11,12],GPU3:[5,6,13,14],GPU4:[7,8,15,16]
上图第二个图,能看到,延迟可以缩短;
代价:通信量增大(2个连续小段,等于通信量翻倍)
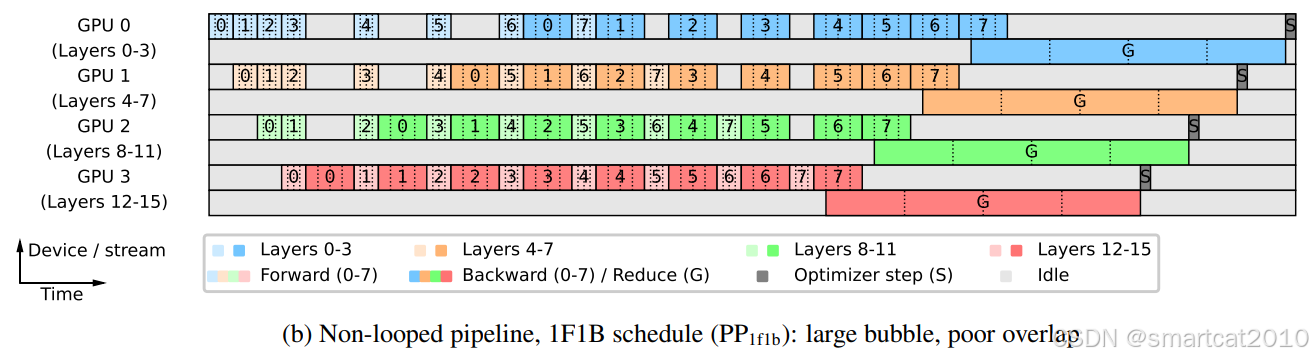
痛点:Data并行,随着GPU增大,batch-size也增大;但是,之前的研究表明,batch-size太大,会导致训练收敛变慢(达到相同train-loss所需的samples变多);因此,pipeline并行是既增大GPU又不增大batch-size的方案;
分析:因为和Zero-3一起使用,所以才有了耗时较长的Reduce操作;
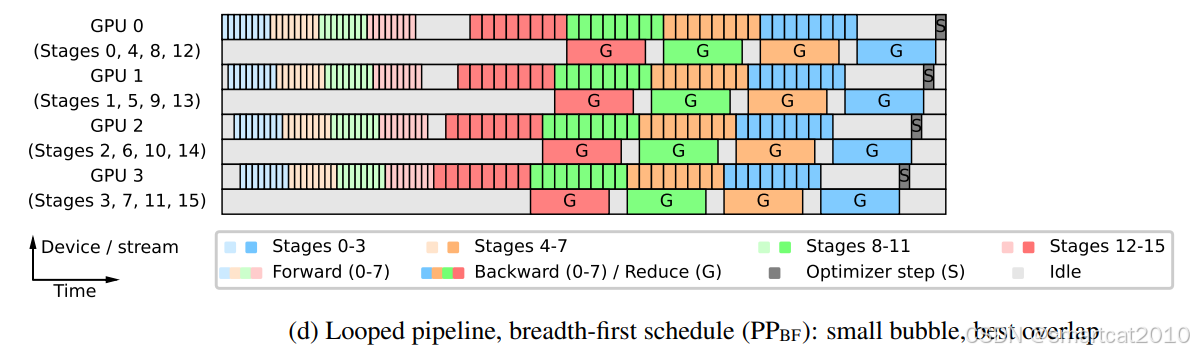
对一张GPU卡来说,训练完几层(同一个stage)的所有micro-batches,再训练其他几层;可以很好的和Zero-3结合使用,模型参数随用随off-load至GPU和all-gather凑齐;
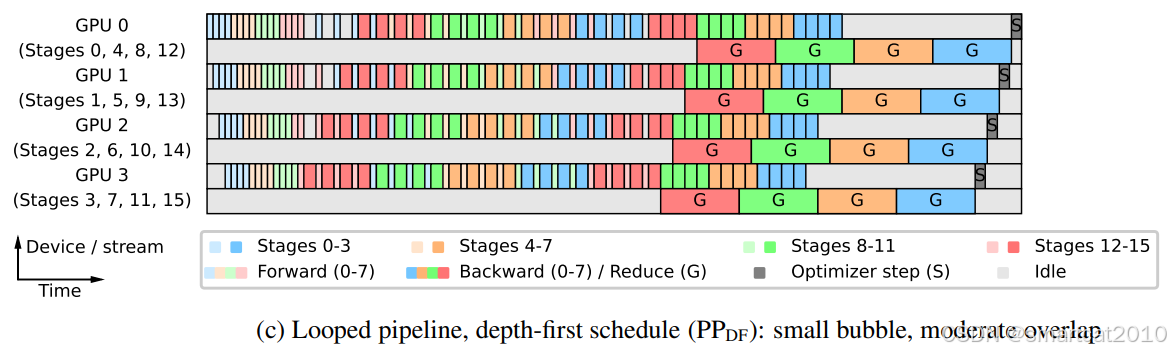
在Interleaved-1F1B的基础上,优先把所有micro-batches的forward都计算完毕,再计算backward;每次计算完1个stage的layers的backward,就立马reduce(应该是reduce-scatter) gradients,通过最大程度的重叠通信和backward计算,实现了耗时缩短;


















 1685
1685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









