







策略梯度:
痛点:
1. t时刻的动作
,其只会影响t时刻之后得到的Reward,和之前的无关。
2. t时刻的动作
改进:
1. 只累加t时刻之后的Reward。
2. 加入衰减r
得到:
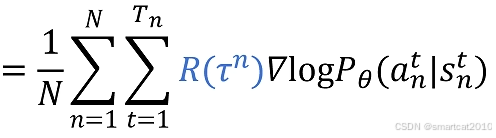
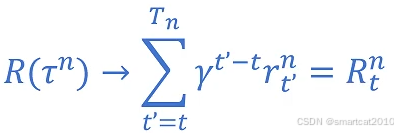
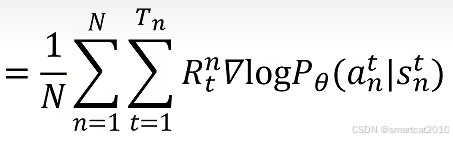
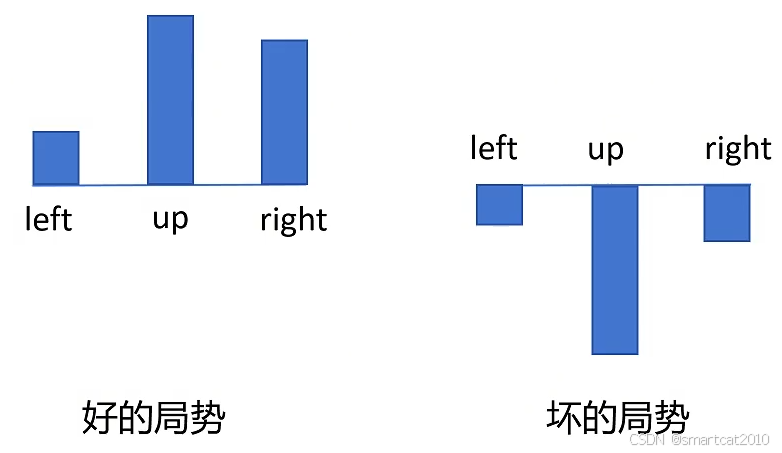
痛点:好的局势下,所有action产生的轨迹,都拿到正的reward;坏的局势下,都拿到负的reward;训练收敛速度会慢。
解决:Return减去"平均Return",用这个"差异"("优势"),代替纯的Return。
得到:
B是"平均Return"

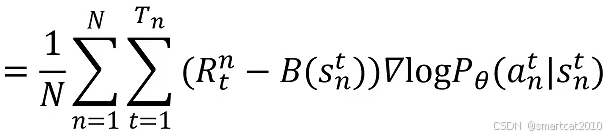
动作价值函数、状态价值函数、优势函数:
得到:
展开动作价值函数Q:
将Q带入优势A:
从而消掉了Q,只用V即可了。
多进行一步采样:(注意是约等于了)
进行不同步数的采样,得到不同的优势A:
为了式子简洁,加入中间变量:(第t步进行某动作得到的优势)
代入A:


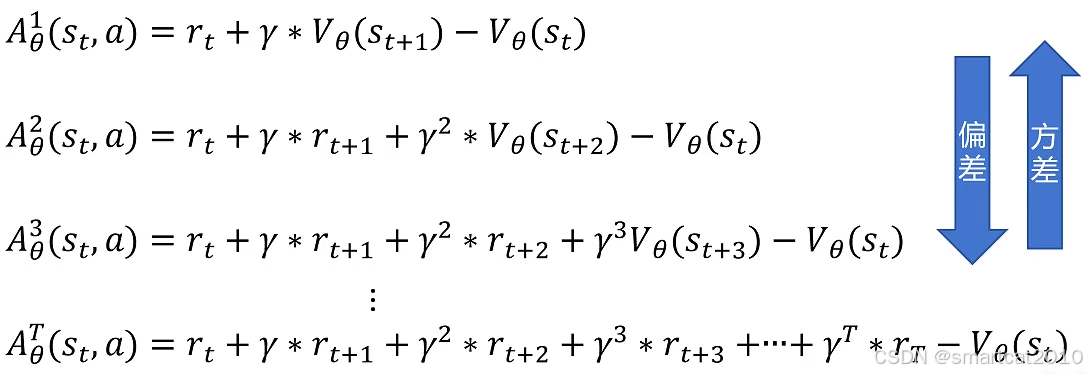
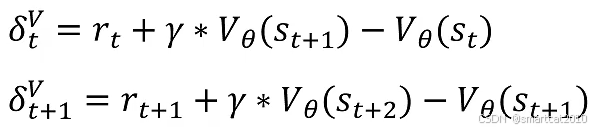
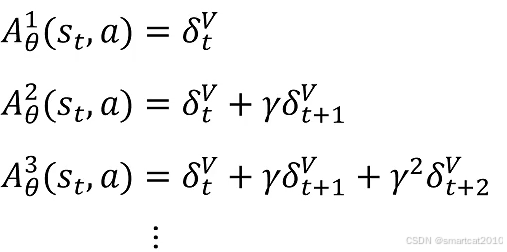
GAE优势函数:
综合了不同采样步数,折中考虑了方差和偏差
例如:
推导:
汇总:
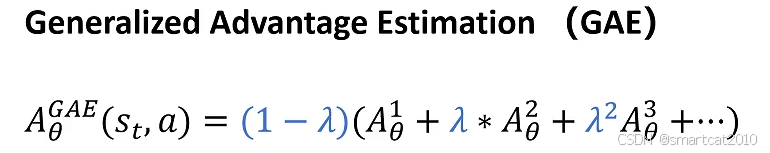
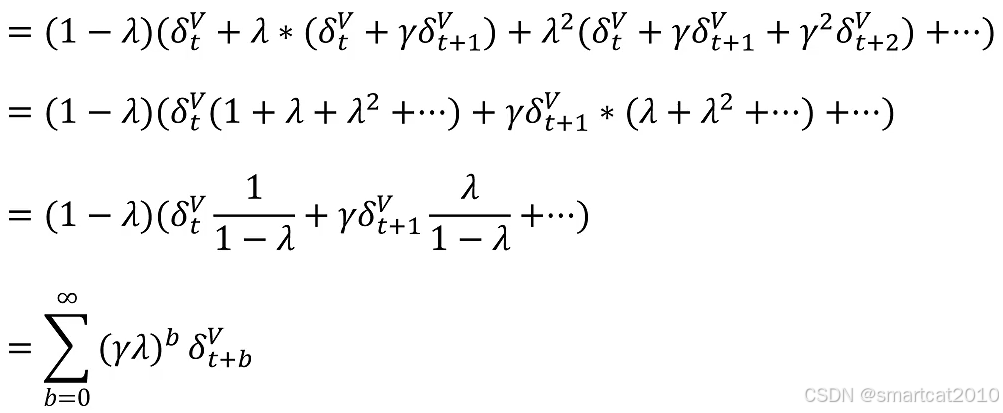

训练:
可以让状态价值函数V的计算网络,和动作action a的计算网络,共用前面的网络层;只在最后一层不同。
V的label,可以使用t时刻之后的return值。


















 1929
1929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









