




基于现有模型,继续pretrain大模型
PyTorch + Huggingface transformers的AutoModelForCausalLM和AutoTokenizer
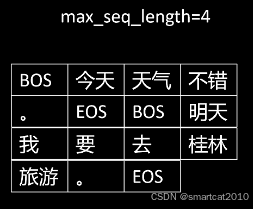
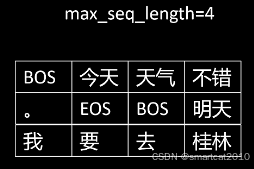
预训练样本打成batch:
1. 假设有2个样本:
2. 拼接起来
3. 按照sequence length来切分
4. 丢弃掉末尾长度不够的那个:
------------------------------------------
<EOS>、<BOS>那种标签,是可以把前后2个doc隔离开的,各自的self-attention不会受到corss-doc的影响。例如,LLama3:
原文:https://ai.meta.com/blog/meta-llama-3/
------------------------------------------
不考虑doc边界那种,更popular。
考虑doc边界的,效果更好。
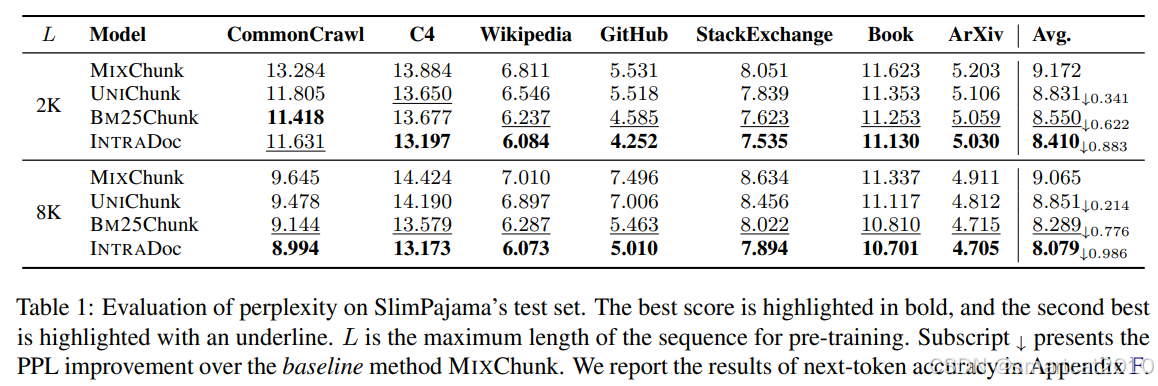
有人写了论文做了实验来对比:2402.13991
MIXChunk: 同一个chunk里的doc是随机选取的,可以跨来源。
UNIChunk: 同一个chunk里的doc是从同一个来源获取的(比如都从Wiki里)。
BM25Chunk: 同一个chunk里的doc是有相关性的doc组成的。
INTRADoc: 考虑了doc边界。即每个token只和本doc内,前面的tokens有关。(前面3种,是每个token和本chunk内所有前面的tokens有关)


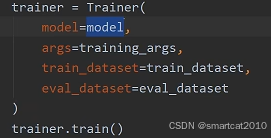
Huggingface的Trainer类:
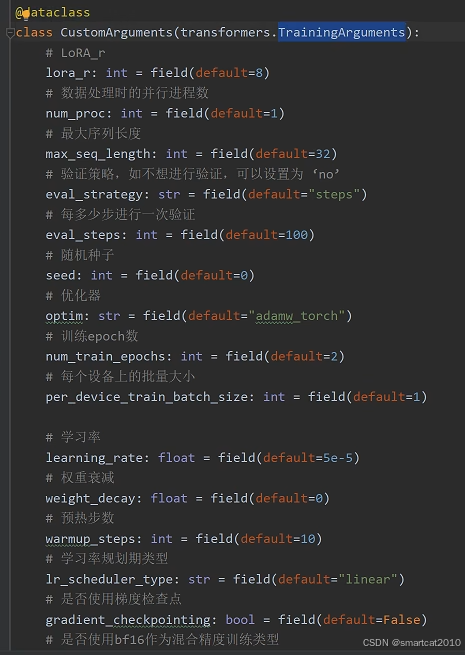
各种配置选项:
Huggingface accelerate来做并行训练:
大模型的能力,是在预训练阶段做好的。
如果直接使用预训练后的大模型,仍然是续写。
解决:使用SFT微调,教会大模型做各种任务。
Chat Template:
每种大模型,有自己的ChatTemplate。使用自己的特殊token和格式,来填充input sequence。
在tokenizer_config.json里:
填充模板:
这个参数,控制填不填assistant标签:
为True,则填上:




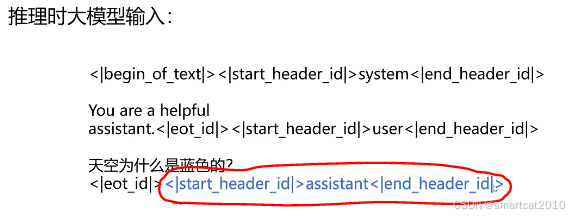

loss mask
只对Answer计算loss, 对input不计算loss:
loss mask为0的,是将0加入到整个句子的总loss里,反向传播到不了他们那里。
删掉最后1个token的logits:
inputs左移1个位置,得到labels:
最后logits和labels,计算交叉熵corss_entropy,乘以loss_mask,加和,得到总loss。



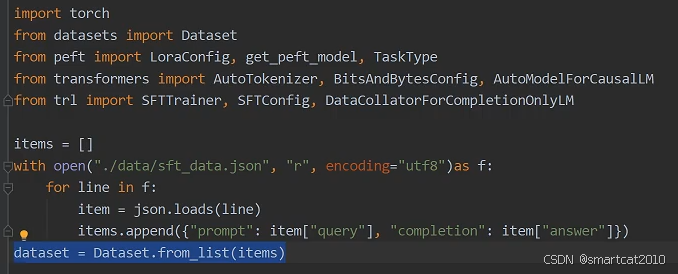
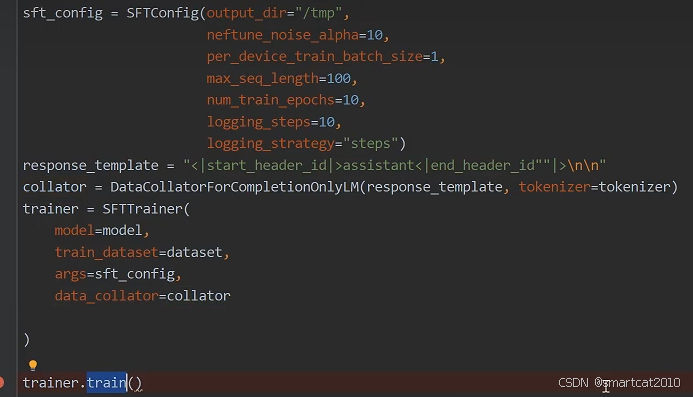
使用Huggingface自带的trl库的SFTTrainer
SFTTrainer会自动使用tokenizer配置自带的template来对dataset样本进行填充。
collator是控制只对completion(即answer)部分的tokens计算loss的。传入completion开始的字符串即可。


















 5795
5795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









