




论文:
《ORCA: A Distributed Serving System for Transformer-Based Generative Models》
之前的几大痛点:
1. 同一个batch里,先完成的短句子,要等到batch里最长的句子完成,才能返回给调用端;
2. input prompt长度相同时,才能batch执行;不同,则不能batch执行;(也能凑合batch执行:把短的句子,在左侧加上mask padding。缺点是将计算资源浪费在了无效计算上)
3. input prompt长度相同时,因为生成结果的长短不同,导致GPU资源浪费,先完成的短句子的GPU机时是空着的;
解决:
1. 以decoding token为单位,来调度(而不是以batch of request为单位);先完成的句子就先返回了(及时释放掉KV cache显存);
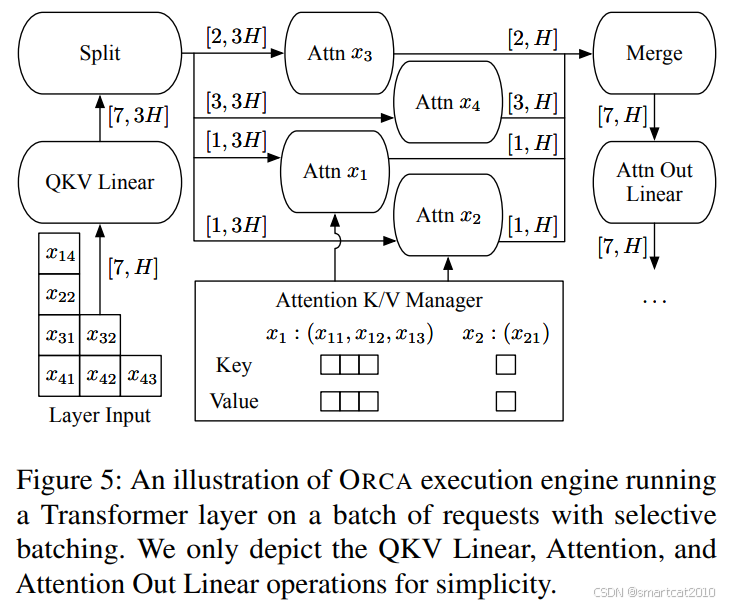
2. "和句子长度无关"的operator,可以任意打包batch;"和句子长度有关"的operator,即Attention,不并行,串行执行,每次执行1个request的attention计算;
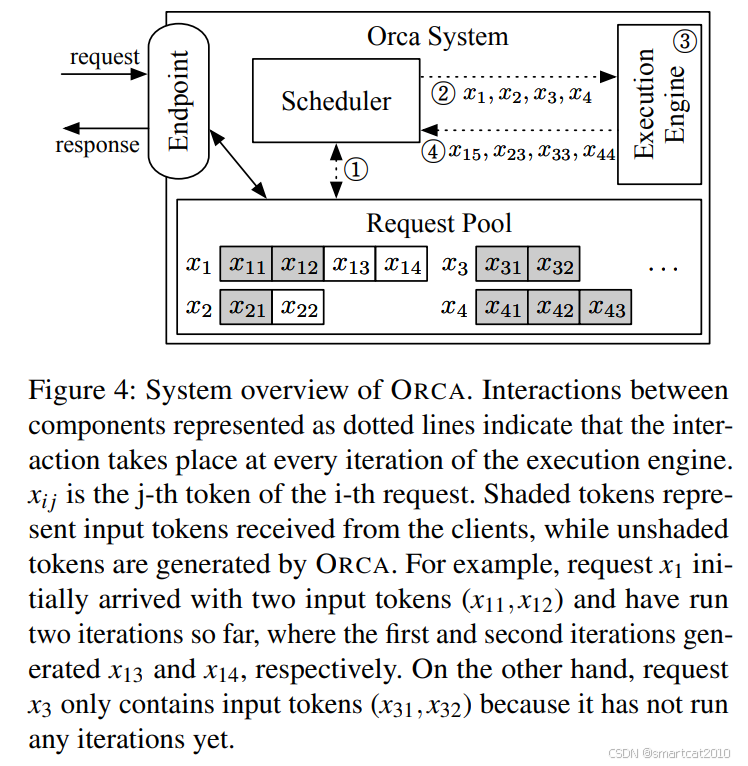
如上,灰色的是input prompt tokens, 空白的是output tokens;
其他细节:
1. 由用户指定max batch size,调度时凑满为止;
2. 估算每个request需要占用的KV cache显存,确保batch不把显存占满;
3. 先来先服务,先到的reqeust,优先被调度执行;
batch大一些的好处:
1. 增大GPU计算利用率;
2. 将多次读取显存(例如模型权重),合并为读取一次显存;
本方法中,prefill阶段的tokens,和decode阶段的tokens,可以打包到同一个batch中。如上例,4个样本被拉成了7个token组成的batch(计算attention时再变为4个样本)。
实际上,在decoding阶段的self-attention,batch里多个requests,仍然是可以并行计算的。
可以按request来划分至多个GPU SM上,还可将同一个request的多个head划分至多个GPU SM上。
实现时,可以把kernel放至不同的stream,并行执行;则每个kernel用其中一部分SM。
缺点:context长的request,会拖慢总体进度。
tensorrt-llm的--multi_block_mode选项的解释里,有说这样并行。它是更进一步,把context也划分到不同的SM里了。

















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









