




 本文探讨了多线程环境下L1-cache行冲突导致的性能损耗问题,通过实例解析了当两个线程分别访问相邻变量时,由于缓存行大小限制而引发的频繁缓存加载和失效现象。文章提出了通过增加Padding来避免缓存行冲突,从而提升多线程并发访问效率的解决方案。
本文探讨了多线程环境下L1-cache行冲突导致的性能损耗问题,通过实例解析了当两个线程分别访问相邻变量时,由于缓存行大小限制而引发的频繁缓存加载和失效现象。文章提出了通过增加Padding来避免缓存行冲突,从而提升多线程并发访问效率的解决方案。
L1-cache加载和失效的单位是64字节;
所以2个变量挨着放,线程1和线程2虽然两者访问的是不同地址的变量(至少有一个线程在写入),也会导致2个L1-cache该行不停的失效,不停的加载内存进L1-cache,导致速度损失。
解决方法:加padding,让不同线程访问的2个变量离得远些,不在同一cache行。
挨着和不挨着,人家测的性能对比,损失和线程个数基本成倍数:
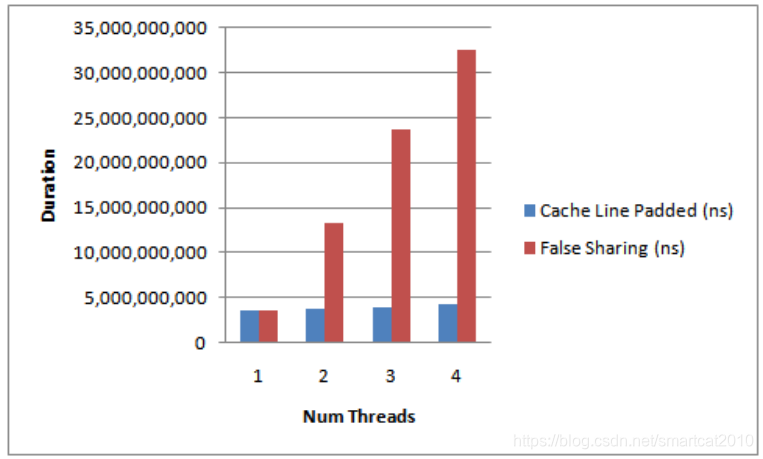
例:
struct { int x; int y; };1. 线程X读x;x和y被加载至同一个cache行;
2. 线程Y读y;复用该cache,不用读主存;
3. 线程X写x;写入内存,该cache行失效(每行有一个dirty-bit)
4. 线程Y读y; 发现该cache行已失效,则读内存并加载至cache,超慢;
5. 3和4反复进行,则无辜的线程Y本来可以享受只读数据放cache的快速,但受了x老被写入带来的cache-dirty失效;

















 677
677




 到【灌水乐园】发言
到【灌水乐园】发言







